Capacity allocation — совмещаем разработку, поддержку и выплату техдолга без смс и регистраций
Этот материал для тех, к кому когда-то подошли и сказали: «Некогда объяснять, ты теперь тимлид (или начальник отдела)». Может быть, теперь вы уже профессионал своего дела, знаете кучу различных инструментов для решения своих задачи. Но давайте посмотрим чуть-чуть с другой стороны и разберем, как вы управляете потоком своих задач. Как справляетесь с работой, которая к вам приходит. Возможно, это поможет немного ее пересмотреть.
Меня зовут Алексей Пименов, я сертифицированный инструктор альянса ICAgile, аккредитованный тренер и консультант Kanban University. Пионер Kanban-метода в России. Моя цель — развить и поднять уровень менеджмента. Kanban многие сопоставляют с DevOps-культурой и практиками DevOps, но это всего лишь один из инструментов, который должен быть в вашем менеджерском ящике.

Когда на вас взваливают управленческую ответственность, приходится отвечать на два очень важных вопроса:
Можете ли вы взять в свою команду еще один запрос (проект, задачу, фичу)?
Когда вы закончите делать то, что взяли?
В основном будем говорить про первый вопрос. При ответе на него есть несколько серьезных управленческих дисфункций. Первая из них — всегда отвечать «да». Вы можете бояться вашего заказчика или уважать и бояться обидеть, неважно. Если всегда говорить «да», то про ответ на второй вопрос можете просто забыть. Хотя казалось бы, у вас есть какой-то конвейер реализации запросов в команде, и они все встают в какую-то очередь. Но это только в теории — на практике очередей чаще всего не бывает. Приведу простой пример.

Это автомобильная пробка! Там всегда кто-то начинает шустрить — перестраивается между рядами, куда-то влезает. Кто-то цепляет мигалку и объезжает всех слева, другие наоборот двигаются правее правого ряда. В общем, есть много разных кейсов. В работе тоже бывают ситуации, когда не получится брать новую работу, строго соблюдая очередь — FIFO (first in, first out).
Чтобы более или менее предсказуемо справляться с работой, да еще понимать, можно ли брать новую — надо держать под контролем количество обещанной работы. То есть обязательства, которые вы на себя взяли. Это я рассказываю про некую сущность, которую все называют WIP-лимит (work in progress), то есть ограничения незавершенной работы.
Сколько должно быть задач
Об этом инструменте есть очень много мифов. А для того чтобы прийти к Capacity allocation, нужно разобраться с базовыми вещами.
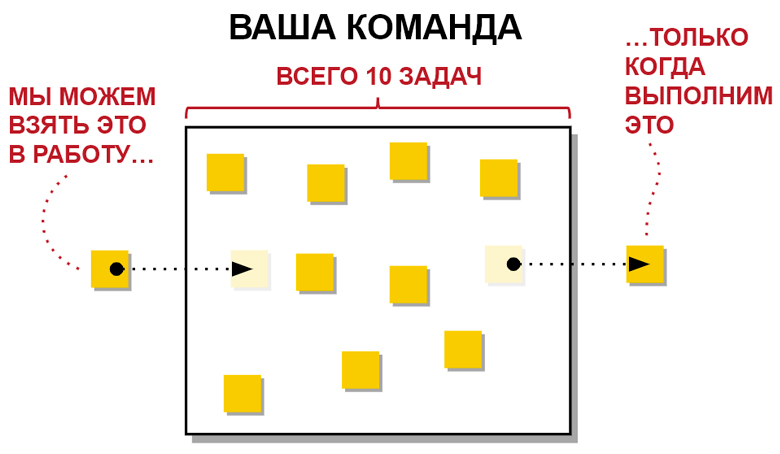
Представим, что в этом прямоугольнике ваши люди и работа. Каждый желтый квадрат обозначает задачу (фичу) — то, что вы реализуете. Лимитирование незавершенной работы заключается в следующем. Например, в вашей команде всего 10 задач, и одиннадцатую вы берете только тогда, когда выполняете одну из тех, которую уже взяли. Достаточно простая и логичная история. Многие ей пользовались и всё уже давно понятно и, вроде, очевидно. Но есть извечный вопрос сколько должно быть задач, а самое главное — как продать идею того, что система ограничена?
Начнем с простой контринтуитивной вещи: у вас уже есть WIP-лимит. Если поковыряться в вашей Jira и составить график, сколько одновременной работы у ваших людей. Окажется, что в какие-то периоды её было меньше (5–10–15 задач), в какие-то больше (40–45 задач). Но у этой кривой есть потолок, который никогда не пробивался.
Так получается потому, что сами разработчики говорят: «Порвёмся! Нам достаточно, больше не сможем!» — упираются лбом и не дают заказчику запихнуть в вас больше. Либо тимлид загораживает свою команду животом и говорит: «Больше туда не пущу!». Либо у заказчика есть понимание сытости: «Им достаточно. Они и так уже погибают!». Либо крайний случай, у него закончились идеи. Но такое бывает редко.

Получается, что фактически лимит уже есть. Он просто у вас не формализован. Никто об этом не задумывался. Поэтому проще всего признать, что этот предел вы еще никогда не нарушали, и попробовать превратить его в правило. Это легче, чем доказывать, что у вас должно быть N задач, и вы не будете брать новую работу.
После того, как этот предел будет формализован, можно попробовать покрутить регулятор — сделать поменьше или побольше. Но какое число задач все-таки будет оптимальным? Нет формулы, чтобы это рассчитать! Это может зависеть от количества людей или не зависеть. Число задач нужно искать эмпирическим путем, так же как ограничение незавершенной работы в вашем подразделении.
Как подтюнить количество задач
Когда вы уже поставили число, оно, скорее всего, большое. Чтобы его подтюнить надо, во-первых, обратить внимание на «брошенок». То есть ту работу, которой никто не занимается, иногда уже достаточно давно. Они игнорируются, например, потому что не предоставлены какие-то данные. А во-вторых, посмотреть на людей, оставшихся без работы. Я изобразил это на схеме:

Есть какая-то работа (желтые квадратики) и как-то распределены люди. Иногда они работают над одной задачей парами, тройками, может быть, всей толпой, но есть люди-«брошенки». Держать которых, скорее всего, вам не даст руководство или заказчик — если узнают.
Когда у вас накапливается достаточно много задач-«брошенок», это повод уменьшить количество незавершенной работы, чтобы у людей до всего доходили руки. Чаще всего слова типа Jira пугаются маркетологи. В одном из кейсов мы визуализировали их работу в Jira-подобном инструменте на доске. Они посмотрели, сколько есть задач, но когда через неделю мы собрали статусное собрание у этой доски, оказалось, что многие не могут ответить почему не выполнили свою задачу. Самый частый ответ — руки не дошли. Это объективная причина. Вы занимались чем-то другим. Но когда такой ответ возникает очень часто, получается, что вы не можете справиться с тем, что наобещали, и возникает много «брошенок».
Вопрос устранения брошенных задач спорный и зависит от контекста. Например, если пойти в Agile-сообщество, там скажут, что это зло — злее не придумать! Там все хотят высокой, плотной коллаборации, чтобы вся толпа брала один запрос и эпически его реализовывала. Наверняка, вы знакомы с инструментами типа mob programming. Это хорошие инструменты, но контексты всегда разные.
Например, вы — сеньор-специалист и вам надо подтягивать джуна. Для этого необходимо поработать в паре над какой-то задачей с определенной спецификой, чтобы показать механику работы. Для этого нужен выбор. Тут и пригождается задача-«брошенка», которую можно разобрать в паре — джуниор научится чему-то полезному, у вас произойдет какой-то improvement с точки зрения навыков.
Все перечисленное — легализовать максимум задач, брать новую работу — можно сделать, только когда вышло старенькое и снижено количество «брошенок». Но запросы-то бывают разные! Разве можно контролировать их по количеству?
Разберитесь в ассортименте
Надо посмотреть, какой ассортимент запросов у вас водится. Их типизация, даже кластеризация — очень разная. Например, в Jira у вас есть теги, которые связаны с тематикой задач, с какими-нибудь компонентами. Есть кластеризация: задачи на развитие инфраструктуры, продуктовой разработки или поддержки, а еще — дефекты, инциденты и прецеденты. Есть определенная кластеризация по заказчикам: эти идут от директора, эти — от второй линии поддержки. Есть задачи, которые понятны, а есть — с высоким уровнем неопределенности. Кластеризовать их можно разными способами, рассмотрев по типам работы. Посмотрим на примере:

На схеме задачи закодированы разными цветами. Например, в моей команде 10 задач: 5 желтых, 4 зеленых и 1 синяя. Как только я закончил синюю задачу, могу прийти к боссу или на предыдущий этап работы и запросить новую синюю задачу. Если закончил зеленую — то попрошу зеленую.
В каком процентном соотношении делятся задачи — это контекстная история. Возможно, вы сможете пронаблюдать и перебалансировать их количество. Например, найдете зависимости: реализация одной зеленой задачи порождает появление двух желтых. Вы выпустили что-то в прод, и сразу повалили баги. У вас в процентном соотношении их все больше и копится технический долг, потому что на вас давят и вам приходится делать задачи не так, как положено по гайдам. Это такой подход к разработке: «Стоять Над Душой Driven Development». Чем больше мы реализуем продуктовых запросов, тем больше растет технический долг и чаще прилетают критические баги с прода.
Вы можете изначально сопоставить процентное соотношение синих, зеленых и желтых задач — например, понимая, что, если не выплачивать технический долг, то появляется больше багов с прода. Если технический долг — это желтые задачи, тогда пусть зеленых будет 2, а желтых на 2 больше, то есть 7. Тогда можно больше выплачивать технический долг и снижать интенсивность прилета синих задач. Возможно, от этого снизится и количество желтых задач. С этим можно экспериментировать. На схеме всего одна кластеризация по задачам, а их может быть много: связанных с особенностью реализации, разным workflow, объемом знаний по задачам и источникам их возникновения.
Категоризация задач
Еще есть наше поведение с этими задачами.
Поведение №1 — прилетает запрос, мы всё бросаем и решаем только его, потому что он самый важный. Иначе компания будет терять миллионы долларов каждый день, либо, наоборот, если всё сделать — зарабатывать миллион долларов за один день.
Поведение №2 — делать всё по очереди. Которой не существует, как я уже говорил —, но хотя бы в какой-то последовательности.
Поведение №3 — когда освобождается минутка, делать фоновые работы: смотреть логи, читать, выполнять процедуру, чистить что-нибудь. Это неприоритетные и не настолько важные работы, но их надо делать.
Поэтому давайте теперь еще поделим нашу систему по категориям работы — №1, №2, №3… Разнесем по ним наши синие, зеленые и желтые задачи, но в сумме их будет снова десять. Такие категоризации можно делать по-разному. Главное, что мы начинаем делить емкость системы на различные кластеры задач. Решив задачу из определенного кластера, мы можем взять следующую, только соответствующую такому же кластеру:
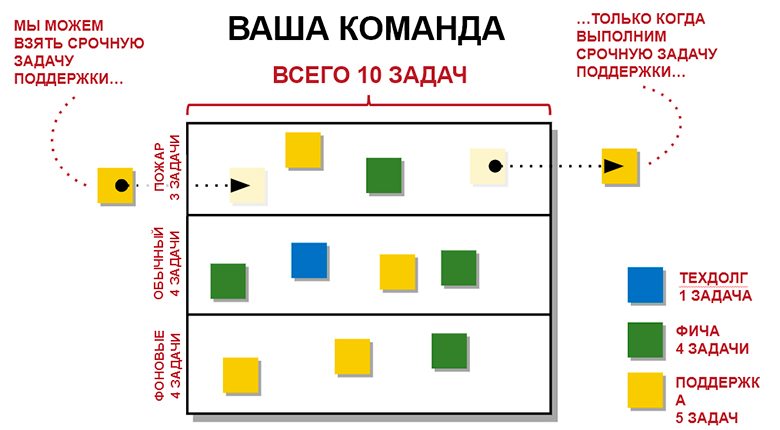
Пусть синие стикеры — это техдолг, зеленые — продуктовые фичи, желтые — задачи поддержки. Соответственно кластеризация будет такая:
Верхняя линейка — пожар — задачи, которые надо сделать в авральном режиме;
Посередине — обычные задачи, которые надо делать последовательно;
Внизу фоновые задачи.
Так появляется та самая многоуровневая кластеризация — Capacity allocation. Мы закладываем определенную емкость в нашей системе под задачи определенного типа.
Теперь вспомним, что задачи бывают разными: например, крупные проекты на полгода и мелкие. И если есть только два программиста — Василий и Иван, которые оба заняты огромными проектами, — то кто будет разбираться с потоком мелких задач? Они же не могут стоять и ждать. Как в таком случае лимитировать по количеству?
Давайте допустим, в команде есть всего 5 задач на этих Васю и Ваню. Каждому дано по большому проекту, и есть поток, где находятся еще 3 задачи, которые они выполняют, если хотят отвлечься от основного проекта. Еще можно поделить свой день так, что когда крупный проект встает на паузу — что-то не подвезли, не договорились, решаются мелкие задачи.
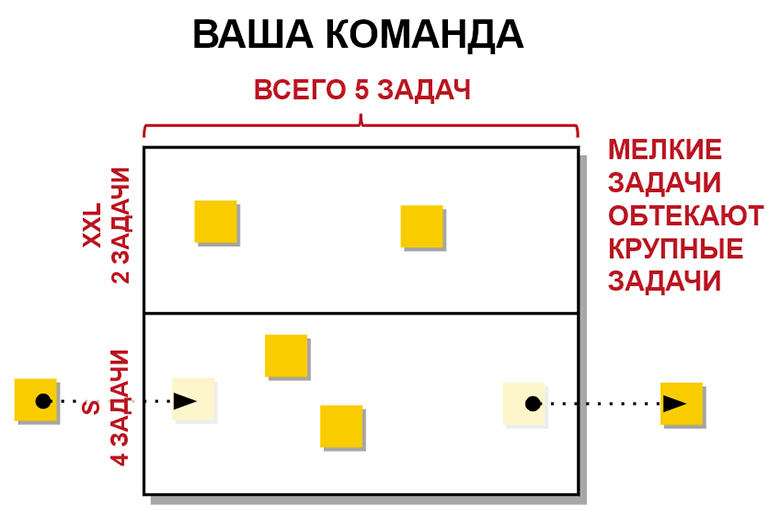
Главное — не переборщить, сильно развязав лимит ограничений незавершенной работы. Иначе может получиться, что «брошенками» станут большие задачи. До них просто не дойдут руки. Поэтому надо отрегулировать лимиты так, чтобы возможность добраться до этих задач была.
Как это продавать руководству
Это очень важный вопрос. Потому что обычно руководство спускает задачи сверху. Если с таким поведением заказчика ничего не делать, оно будет продолжаться всегда. Чтобы отойти от этой точки, можно использовать тот самый верхний порог, который никогда не пробивался. Надо прозрачно показывать свою работу в цифрах:
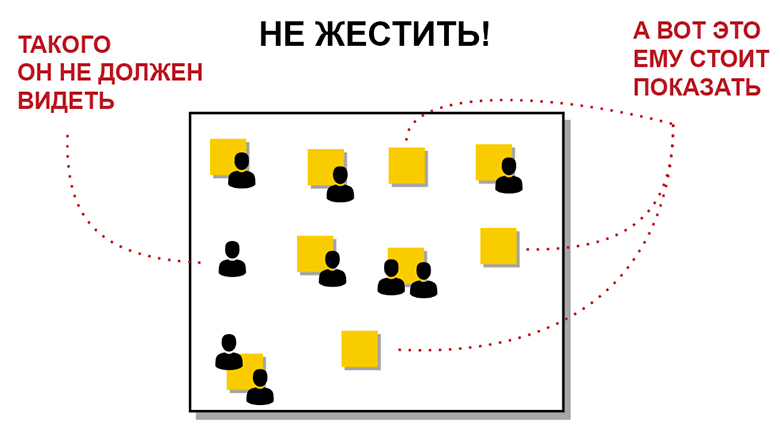
Например, если вы используете для визуализации доски Jira, заказчик может уточнить почему у одного из ваших сотрудников нет никакой задачи. И попытаться поставить ему задачу напрямую, через вашу голову. Появляется паттерн, который называется персональной очередью на каждого инженера в команде. Это убивает коллаборативность работы, возможность людей работать парами и учиться друг у друга. Такого подхода, особенно на первых порах, надо избегать. Заказчик не должен видеть, что у вас какой-то человек простаивает.
А вот количество работы, на которую не получается назначить человека, потому что они все заняты, показывать стоит. Как и все негативные эффекты: что какая-то задача в правом верхнем углу задерживается в реализации из-за того, что заказчик принес другую задачу и человека пришлось переключать. Когда заказчик видит совокупный отчет, то понимает, как его поведение повлияло на время реализации любого проекта, и он может начать вести себя по-другому.
Главное — не передавить! Не начать продавать идею о том, что так работать лучше или это стандарт отрасли. Сначала лучше показать что-то с большим лимитом, много «брошенок» и негативное воздействие. И затем постепенно транслировать: если станет меньше «брошенок», то это сократит время производства.
Есть один серьёзный миф — что пропускная способность (количество работы), которая выходит из команды в единицу времени (количество закрываемых задач в месяц) напрямую связана со временем, которое каждая из этих задач проводит в системе. Однако, ограничение незавершенной работы очень сильно влияет на время нахождения работы в вашей системе и почти никак не влияет на её пропускную способность.
Лимитирование системы не снижает пропускную способность. Мы можем ее снизить, только если совсем закрутим гайки и пять человек будут одновременно работать над одной задачей. Поэтому, когда вам предлагают увеличить скорость работы команды, всегда задавайте уточняющий вопрос. Это про количество работы, которая выходит из команды в месяц? Либо про время нахождения каждой отдельной задачи в системе? На эти два показателя (время, за которое делается работа и пропускная способность) влияют абсолютно разные управленческие действия:
Сократить время жизни запроса внутри системы можно, закрутив WIP-лимит, чтобы в системе находилось меньше работы. Так у вас возникает больше коллаборации и меньше простоев.
Если нжно увеличить пропускную способность — то меняйте технологический процесс, автоматизируя какие-то действия, либо нанимая людей. Пропускную способность по-другому повысить невозможно!
Как примирить заказчиков
Часто бывает, что заказчиков несколько и они друг с другом не дружат. Конечно, в компании это неформально — они здороваются и общаются. А когда вы не можете взять задачу, потому что уже заняты проектом другого заказчика, то здесь начинаются проблемы. От вас требуют, чтобы вы брали следующую задачу, независимо от обещаний. То есть перетягивают одеяло на себя и не хотят договариваться ни с вами, ни между собой.

Конечно, решением может послужить вариант с распределением мелких и крупных задач, который мы уже рассматривали. Грубо говоря, вы отдаете одну часть capacity под одного заказчика и другую часть — под второго. Поделить можно как поровну, так и в процентном соотношении. Причем людей делить не обязательно. Они могут кочевать в обе системы, что позволит растить их навыки.
Бывает другая история, когда мы не хотим все это делить. Тогда появляется револьвер. Но это не значит, что надо отстреливать заказчиков :)

Представьте, что ваша команда — это револьвер, и то, как она щелкает задачи — это выстрел, а то, как задачи к вам поступают — это барабан. У револьвера 6 слотов. Вы делите заказчиков так, что каждому достается какая-то квота в этом барабане и обслуживаете их по очереди. Механизм называется «Револьверное пополнение».
Чтобы с квотами не возникло проблем, особенно у крупных заказчиков на уровне стратегический инициативы в большом энтерпрайзе, надо обращать внимание на то, как барабан поделен между ними. Самое обычное деление — кто спонсирует, тот получает больше. Например, вы работаете в крупном банке и департаменты розничных и корпоративных продуктов делят вас 70 на 30. Причем эти квоты надо пересматривать хотя бы раз в квартал. Собираться вместе с заказчиками и вышестоящим менеджером, чтобы они не переругались друг с другом.
Второй момент: следите за тем, как работа покидает «ствол». Сами знаете, как бывает — вы пытаетесь что-то завершить, но приходит заказчик и говорит, что это недоработано и пытается вас убедить, что это не новый запрос, а неправильно понятый старый. Если не сопротивляться, то заказчик не даст пулям вылетать из револьвера и барабан начнет вращаться медленнее. Другие заказчики начнут копировать его поведение, и револьвер вообще перестанет стрелять. Поэтому необходимо вводить определенные формальные правила. Например, спросить, почему заказчик считает, что это должно быть доработано сейчас, на этапе приемки.
Теперь можно подвести итоги и еще раз уточнить пункты, которые помогают решить некоторые проблемы и совместить разработку, поддержку и выплату технического долга.
Резюмируя
Один из ключевых моментов — это ограничение незавершенной работы. Оно у вас уже есть, просто не формализовано. Формализуйте.
После этого поделите задачи на типы: либо по виду работы, либо по поведению с этой работой.
Сделайте это явными правилами с заказчиком. Для заказчика будет не так больно. Это проще, чем сказать: «Мы сейчас устроим революцию. Будет жизнь ДО и ПОСЛЕ». Постепенное введение правил не так сильно давит на идентичность, самоощущение и эго заказчика.
Открыт приём докладов на HighLoad++ 2022. Конференция для разработчиков высоконагруженных систем пройдёт в Москве 24 и 25 ноября. Тематика — всё, что актуально для разработки систем высоких нагрузок и реального времени, крупных и сложных проектов.
Заявки принимаются до 12 августа, всем спикерам Программный комитет помогает с подготовкой презентации и самого выступления, оплачивается (если нужно) проживание и дорога. Подавайте заявку, а все подробности — по ссылке.
