Быстрый старт: Go + Apache Kafka + Redis
В последнее время я, в силу необходимости, просмотрел все объявления о вакансиях Go-разработчиков, и в половине из них (как минимум) упоминается платформа для обработки потоков сообщений Apache Kafka и NoSQL база данных Redis. Ну и все, конечно, хотят, чтобы кандидат знал Docker и иже с ним. Все эти требования нам, повидавшим виды системным инженерам, кажутся какими-то мелочными что ли. Ну в самом деле, чем одна очередь отличается от другой? С NoSQL базами данных ситуация, конечно, более разнообразная, но всё равно они кажутся проще чем какой-нибудь MS SQL Server. Всё это, безусловно, мой личный, многократно на Хабре упоминавшийся, Эффект Даннинга — Крюгера.
Так что, раз все работодатели требуют, то нужно эти технологии изучить. Но начинать с прочтения всей документации от начала и до конца не очень интересно. На мой взгляд, продуктивнее прочитать введение, сделать рабочий прототип, поправить ошибки, столкнуться с проблемами, решить их. И вот после всего этого уже с пониманием читать документацию, или даже отдельную книжку.
Тех, кому интересно в короткий срок познакомиться с базовыми возможностями указанных продуктов, прошу читать дальше.
Учебно-тренировочная программа будет заниматься факторизацией чисел. Она будет состоять из генератора больших чисел, процессора чисел, очереди, колоночного хранилища и веб-сервера. По ходу разработки будут применены следующие шаблоны проектирования:
Архитектура системы будет выглядеть так: 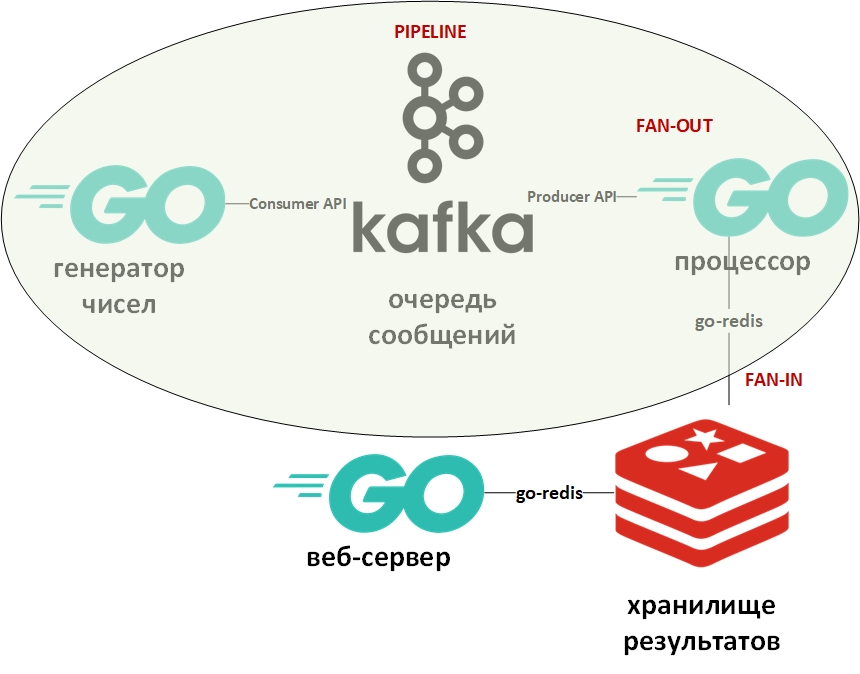
На картинке овалом обозначен шаблон проектирования «конвейер». Остановлюсь на нём подробнее.
Шаблон «конвейер» предполагает, что информация поступает в виде потока и обрабатывается этапами. Обычно существует некоторый генератор (источник информации) и один или несколько процессоров (обработчиков информации). В данном случае генератором будет программа на Go, помещающая в очередь случайные большие числа. А обработчиком (единственным) будет программа, забирающая данные из очереди, и проводящая факторизацию. На чистом Go этот шаблон довольно легко реализуется с помощью каналов (chan). Выше есть ссылка на мой Гитхаб с примером. Здесь же роль каналов будет исполнять очередь сообщений.
Шаблоны Fan-In — Fan-Out обычно используются вместе и применительно к Go означают распараллеливание вычислений с помощью горутин с последующим сведением результатов и передаче их, например, далее по конвейеру. Ссылка на пример также приведёна выше. Опять же, канал заменён на очередь, горутины остались на месте.
Теперь пару слов об Apache Kafka. Kafka — это система управления сообщениями, обладающая отличными средствами кластеризации, использующая транзакционный журнал (точь в точь как в РСУБД) для хранения сообщений, и поддерживающая одновременно и модель очереди и модель издатель/подписчик. Последнее достигается за счёт групп получателей сообщений. Каждое сообщение получает только один член группы (параллельная обработка), но при этом сообщение будет доставлено по одному разу в каждую группу. Таких групп, как и получателей внутри каждой группы, может быть много.
Для работы с Kafka я буду использовать пакет «github.com/segmentio/kafka-go».
Redis же представляет собой колоночную БД типа «ключ-значение» в памяти, поддерживающую возможность постоянного хранения данных. Основной тип данных для ключей и значений — строки, но есть и некоторые другие. Redis считается одной из самых быстрых (или самой) БД в своём классе. В ней хорошо хранить всяческую статистику, метрики, потоки сообщений и т.д.
Для работы с Redis я буду использовать пакет «github.com/go-redis/redis».
Поскольку данная статья — быстрый старт, то обе системы развернём с помощью Docker, используя готовые образы с DockerHub. Я использую docker-compose в Windows 10 в режиме контейнеров в ВМ Linux (автоматически созданная программой Docker ВМ) вот с таким вот файлом docker-compose.yml:
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka:latest
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_CREATE_TOPICS: "Generated:1:1,Solved:1:1,Unsolved:1:1"
KAFKA_DELETE_TOPIC_ENABLE: "true"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
redis:
image: redis
ports:
- "6379:6379"
Сохраните этот файл, перейдите в каталог с ним и выполните:
docker-compose up -d
Должны скачаться и запуститься три контейнера: Kafka (очередь), Zookeeper (сервер конфигурации для Kafka) и (Redis).
Убедиться, что контейнеры работают можно с помощь команды:
docker-compose ps
Должно быть что-то вроде:
Name State Ports
--------------------------------------------------------------------------------------
docker-compose_kafka_1 Up 0.0.0.0:9092->9092/tcp
docker-compose_redis_1 Up 0.0.0.0:6379->6379/tcp
docker-compose_zookeeper_1 Up 0.0.0.0:2181->2181/tcp, 22/tcp, 2888/tcp, 3888/tcp
Согласно yml-файлу, должны автоматически создаться три очереди, посмотреть их можно командой:
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-topics.sh --list --zookeeper zookeeper:2181
Должны быть очереди (topics — темы в терминах Kafka) Generated, Solved и Unsolved.
Генератор данных бесконечно записывает в очередь числа со случайной задержкой. Его код предельно прост. Убедиться в наличии сообщений в очереди Generated можно с помощью команды:
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Generated --from-beginning
Далее процессор — тут следует обратить внимание на распараллеливание обработки значений из очереди в следующем блоке кода:
var wg sync.WaitGroup
c := 0 //counter
for {
// создайм объект контекста с таймаутом в 15 секунд для чтения сообщений
ctx, cancel := context.WithTimeout(context.Background(), 15*time.Second)
defer cancel()
// читаем очередное сообщение из очереди
// поскольку вызов блокирующий - передаём контекст с таймаутом
m, err := r.ReadMessage(ctx)
if err != nil {
fmt.Println("3")
fmt.Println(err)
break
}
wg.Add(1)
// создайм объект контекста с таймаутом в 10 миллисекунд для каждой вычислительной горутины
goCtx, goCcancel := context.WithTimeout(context.Background(), 10*time.Millisecond)
defer goCcancel()
// вызываем функцию обработки сообщения (факторизации)
go process(goCtx, c, &wg, m)
c++
}
// ожидаем завершения всех горутин
wg.Wait()
Поскольку чтение из очереди сообщений блокирует программу, то я создал объект context.Context с таймаутом в 15 секунд. Этот таймаут завершит работу программы, если очередь будет долго пустовать.
Также для каждой горутины, которая проводит факторизацию числа также задано максимальное время работы. Я хотел чтобы числа, которые удалось факторизовать, записывались в одну БД. А числа, которые факторизовать за отведённое время не удалось — в другую БД.
Для определения примерного времени использовался бенчмарк:
func BenchmarkFactorize(b *testing.B) {
ch := make(chan []int)
var factors []int
for i := 1; i < b.N; i++ {
num := 2345678901234
go factorize(num, ch)
factors = <-ch
b.Logf("\n%d раскладывется на %+v\n\n", num, factors)
}
}
Бенчмарки в Go являются разновидностями тестов и помещаются в файл с тестами. На основе этого замера было подобрано максимальное число для генератора случайных чисел. На моём компьютере часть чисел успевала разложиться на множители, а часть — нет.
Те числа, которые удавалось разложить, писались в БД №0, неразложенные числа — в БД №1.
Тут надо сказать, что в Redis нет схемы и таблиц в классическом понимании. По умолчанию СУБД содержит 16 баз данных, доступных программисту. Эти базы отличаются своими номерами — от 0 и до 15.
Ограничение времени для горутин в процессоре обеспечивалось использованием контекста и оператора select:
// собственно факторизация
go factorize(n, outChan)
var item data
select {
case factors = <-outChan:
{
fmt.Printf("\ngoroutine #%d, input: %d, factors: %+v\n", counter, n, factors)
item.Number = n
item.Factors = factors
err = storeSolved(item)
if err != nil {
fmt.Println("6")
log.Fatal(err)
}
}
case <-ctx.Done():
{
fmt.Printf("\ngoroutine #%d, input: %d, exited on context timeout\n", counter, n)
err = storeUnsolved(n)
if err != nil {
fmt.Println("7")
log.Fatal(err)
}
return nil
}
}
Это ещё один из типовых приёмов разработки на Go. Смысл его заключается в том, что оператор select перебирает каналы, и выполняет код, соответствующий первому активному каналу. В данном случае или горутина выдаст результат в свой канал, или закроется канал контекста с таймаутом. Вместо контекста можно использовать произвольный канал, который будет выполнять роль управляющего и обеспечивать принудительное завершение горутин.
Подпрограммы записи в БД выполняют команду выбора нужной БД (0 или 1) и записывают пары вида (число — множители) для разобранных чисел или же (число — число) для неразложенных чисел.
func storeSolved(item data) (err error) {
// переключаемся на БД 0
cmd := redis.NewStringCmd("select", 0)
err = client.Process(cmd)
b, err := json.Marshal(item.Factors)
err = client.Set(strconv.Itoa(item.Number), string(b), 0).Err()
return err
}
Последней частью будет веб сервер, который будет отображать список разложенных и неразложенных чисел в виде json. У него будет две конечных точки:
http.HandleFunc("/solved", solvedHandler)
http.HandleFunc("/unsolved", unsolvedHandler)
Обработчик http-запроса с получением данных из Redis и отдачей их в виде json выглядит так:
func solvedHandler(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "application/json")
w.Header().Set("Access-Control-Allow-Origin", "*")
w.Header().Set("Access-Control-Allow-Methods", "GET")
w.Header().Set("Access-Control-Allow-Headers", "Accept, Content-Type, Content-Length, Accept-Encoding, X-CSRF-Token, Authorization")
// выбираем БД №0 - разложенные числа
cmd := redis.NewStringCmd("select", 0)
err := client.Process(cmd)
if err != nil {
w.WriteHeader(http.StatusInternalServerError)
return
}
// получаем все ключи из БД
keys := client.Keys("*")
var solved []data
var item data
// для каждого ключа получаем значение и добавляем в массив
for _, key := range keys.Val() {
item.Key = key
val, err := client.Get(key).Result()
if err != nil {
w.WriteHeader(http.StatusInternalServerError)
return
}
item.Val = val
solved = append(solved, item)
}
// десериализуем массив в JSON
err = json.NewEncoder(w).Encode(solved)
if err != nil {
w.WriteHeader(http.StatusInternalServerError)
return
}
}
Результат запроса по адресу: localhost/solved
[{
"Key": "1604388558816",
"Val": "[1,2,3,227]"
},
{
"Key": "545232916387",
"Val": "[1,545232916387]"
},
{
"Key": "1786301239076",
"Val": "[1,2]"
},
{
"Key": "698495534061",
"Val": "[1,3,13,641,165331]"
}]
Вот теперь можно углубиться в документацию и специализированную литературу. Надеюсь, что статья была полезна.
Прошу специалистов не полениться и указать на мои ошибки.
