[Перевод] ООП мертво, да здравствует ООП
Этот пост возник благодаря недавней публикации Араса Пранцкевичуса о докладе, предназначенном для программистов-джуниоров. В нём рассказывается о том, как адаптироваться к новым ECS-архитектурам. Арас следует привычной схеме (объяснения ниже): показывает примеры ужасного ООП-кода, а затем демонстрирует, что отличным альтернативным решением является реляционная модель (но называет её «ECS», а не реляционной). Я ни в коем случае не критикую Араса — я большой фанат его работ и хвалю его за отличную презентацию! Я выбрал именно его презентацию вместо сотен других постов про ECS из Интернета потому, что он приложил дополнительные усилия и опубликовал git-репозиторий для изучения параллельно с презентацией. В нём содержится небольшая простая «игра», используемая в качестве примера выбора разных архитектурных решений. Этот небольшой проект позволил мне на конкретном материале продемонстрировать свои замечания, так что спасибо, Арас!
Слайды Араса выложены здесь: http://aras-p.info/texts/files/2018Academy — ECS-DoD.pdf, а код находится на github: https://github.com/aras-p/dod-playground.
Я не буду (пока?) анализировать получившуюся ECS-архитектуру из этого доклада, но сосредоточусь на коде «плохого ООП» (похожего на уловку «чучело») из его начала. Я покажу, как бы он выглядел на самом деле, если бы правильно исправили все нарушения принципов OOD (object-oriented design, объектно-ориентированного проектирования).
Спойлер: устранение всех нарушений OOD приводит к улучшениям производительности, аналогичным преобразованиям Араса в ECS, к тому же использует меньше ОЗУ и требует меньше строк кода, чем ECS-версия!
TL; DR: Прежде чем прийти к выводу, что ООП отстой, а ECS рулит, сделайте паузу и изучите OOD (чтобы знать, как правильно использовать ООП), а также разберитесь в реляционной модели (чтобы знать, как правильно применять ECS).
Я уже долгое время принимаю участие во множестве дискуссий про ECS на форуме, частично потому, что не думаю, что эта модель заслуживает существовать в качестве отдельного термина (спойлер: это просто ad-hoc-версия реляционной модели), но ещё и потому, что почти каждый пост, презентация или статья, рекламирующие паттерн ECS, повторяют следующую структуру:
- Показать пример ужасного ООП-кода, реализация которого имеет ужасные изъяны из-за излишнего использования наследования (а значит, эта реализация нарушает многие принципы OOD).
- Показать, что композиция — это лучшее решение, чем наследование (и не упоминать о том, что OOD на самом деле даёт нам тот же урок).
- Показать, что реляционная модель отлично подходит для игр (но назвать её «ECS»).
Такая структура бесит меня, потому что: (A) это уловка «чучело»… сравнивается мягкое с тёплым (плохой код и хороший код)… и это нечестно, даже если сделано ненамеренно и не требуется для демонстрации того, что новая архитектура хороша; и, что более важно: (B) это имеет побочный эффект — такой подход подавляет знания и непреднамеренно демотивирует читателей от знакомства с исследованиями, проводившимися в течение полувека. О реляционной модели впервые начали писать в 1960-х. На протяжении 70-х и 80-х эта модель значительно улучшалась. У новичков часто возникают вопросы типа »в какой класс нужно поместить эти данные? », и в ответ им часто говорят нечто расплывчатое, наподобие »вам просто нужно набраться опыта и тогда вы просто научитесь понимать нутром»…, но в 70-х этот вопрос активно изучался и на него в общем случае был выведен формальный ответ; это называется нормализацией баз данных. Отбрасывая уже имеющиеся исследования и называя ECS совершенно новым и современным решением, вы скрываете это знание от новичков.
Основы объектно-ориентированного программирования были заложены столь же давно, если не раньше (этот стиль начал исследоваться в работе 1950-х годов)! Однако именно в 1990-х годах объектно-ориентированность стала модной, виральной и очень быстро превратилась в доминирующую парадигму программирования. Произошёл взрыв популярности многих новых ОО-языков, в том числе Java и (стандартизированной версии) C++. Однако так как это было связано с ажиотажем, то всем нужно было знать это громкое понятие, чтобы записать в своё резюме, но лишь немногие по-настоящему в него углублялись. Эти новые языки создали из многих особенностей ОО ключевые слова — class, virtual, extends, implements — и я считаю, что именно поэтому в тот момент ОО разделилась на две отдельные сущности, живущие собственными жизнями.
Я буду называть применение этих вдохновлённых ОО языковых особенностей »ООП», а применение вдохновлённых ОО техник создания дизайна/архитектур »OOD». Все очень быстро подхватили ООП. В учебных заведениях есть курсы ОО, выпекающие новых ООП-программистов… однако знание OOD плетётся позади.
Я считаю, что код, использующий языковые особенности ООП, но не следующий принципам проектирования OOD, не является ОО-кодом. В большинстве критических отзывов, направленных против ООП, используется для примера выпотрошенный код, на самом деле не являющийся ОО-кодом.
ООП-код имеет очень плохую репутацию, и в частности потому, что бОльшая часть ООП-кода не следует принципам OOD, а потому не является «истинным» ОО-кодом.
Как сказано выше, 1990-е стали пиком «моды на ОО», и именно в то время «плохой ООП», вероятно, был хуже всего. Если вы изучали ООП в то время, то, скорее всего, узнали о «четырёх столпах ООП»:
- Абстрагирование
- Инкапсуляция
- Полиморфизм
- Наследование
Я предпочитаю называть их не четырьмя столпами, а «четырьмя инструментами ООП». Это инструменты, которые можно использовать для решения задач. Однако недостаточно просто узнать, как работает инструмент, необходимо знать, когда нужно его использовать… Со стороны преподавателей безответственно обучать людей новому инструменту, не говоря им, когда каждый из них стоит применять. В начале 2000-х оказывалось сопротивление активному неверному использованию этих инструментов, своего рода «вторая волна» OOD-мышления. Результатом этого стало появление мнемоники SOLID, предоставлявшей быстрый способ оценки сильных сторон архитектуры. Надо заметить, что эта мудрость на самом деле была широко распространена в 90-х, но не получила ещё крутого акронима, позволившего закрепить их в качестве пяти базовых принципов…
- Принцип единственной ответственности (Single responsibility principle). Каждый класс должен иметь только одну причину изменения. Если у класса «A» есть две обязанности, то нужно создать класс «B» и «C» для обработки каждой из них по отдельности, а затем создать «A» из «B» и «C».
- Принцип открытости/закрытости (Open/closed principle). ПО со временем изменяется (т.е. важна его поддержка). Стремитесь помещать части, которые скорее всего будут изменяться, в реализации (implementations) (т.е. в конкретные классы) и создавайте интерфейсы (interfaces) на основе тех частей, которые скорее всего не изменятся (например, абстрактные базовые классы).
- Принцип подстановки Барбары Лисков (Liskov substitution principle). Каждая реализация интерфейса должна на 100% соответствовать требованиям этого интерфейса, т.е. любой алгоритм, работающий с интерфейсом, должен работать с любой реализацией.
- Принцип разделения интерфейса (Interface segregation principle). Делайте интерфейсы как можно более малыми, чтобы каждая часть кода «знала» о наименьшем объёме кодовой базы, например, избегала ненужных зависимостей. Этот совет хорош и для C++, где время компиляции становится огромным, если ему не следовать.
- Принцип инверсии зависимостей (Dependency inversion principle). Вместо двух конкретных реализаций, обменивающихся данными напрямую (и зависящих друг от друга), их обычно можно разделить, формализовав их интерфейс связи в качестве третьего класса, используемого как интерфейс между ними. Это может быть абстрактный базовый класс, определяющий вызовы методов, используемых между ними, или даже просто структура ПСД (POD), определяющая передаваемые между ними данные.
- Ещё один принцип не включён в акроним SOLID, но я уверен, что он очень важен: «Предпочитать композицию наследованию» (Composite reuse principle). Композиция это правильный выбор по умолчанию. Наследование стоит оставить для случаев, когда она абсолютно необходима.
Так мы получаем SOLID-C (++) 
Ниже я буду ссылаться на эти принципы, называя их по акронимам — SRP, OCP, LSP, ISP, DIP, CRP…
Ещё несколько замечаний:
- В OOD понятия интерфейсов и реализаций не возможно привязать к каким-то конкретным ключевым словам ООП. В C++ мы часто создаём интерфейсы с абстрактными базовыми классами и виртуальными функциями, а затем реализации наследуют от этих базовых классов…, но это только один конкретный способ воплощения принципа интерфейса. В C++ мы также можем использовать PIMPL, непрозрачные указатели, утиную типизацию, typedef и т.д… Можно создать OOD-структуру, а затем реализовать её на C, в котором вообще нет ключевых слов ООП-языка! Поэтому когда я говорю об интерфейсах, я необязательно имею в виду виртуальные функции — я говорю о принципе сокрытия реализации. Интерфейсы могут быть полиморфными, но чаще всего такими не являются! Полиморфизм правильно используется очень редко, но интерфейсы — фундаментальное понятие для всего ПО.
- Как я дал понять выше, если вы создаёте POD-структуру, которая просто хранит какие-то данные для передачи от одного класса другому, тогда эта структура используется как интерфейс — это формальное описание данных.
- Даже если вы просто создаёте один отдельный класс с общей и частной частями, то всё что находится в общей части, является интерфейсом, а всё в частной части — реализацией.
- Как я дал понять выше, если вы создаёте POD-структуру, которая просто хранит какие-то данные для передачи от одного класса другому, тогда эта структура используется как интерфейс — это формальное описание данных.
- Наследование на самом деле имеет (по крайней мере) два типа — наследование интерфейсов и наследование реализаций.
- В C++ наследование интерфейсов включает в себя абстрактные базовые классы с чисто виртуальными функциями, PIMPL, условными typedef. В Java наследование интерфейсов выражается через ключевое слово implements.
- В C++ наследование реализаций происходит каждый раз, когда базовые классы содержат что-то, кроме чисто виртуальных функций. В Java наследование реализаций выражается с помощью ключевого слова extends.
- В OOD есть много правил наследования интерфейсов, но наследование реализаций обычно стоит рассматривать как «код с душком»!
И, наконец, мне стоит показать несколько примеров ужасного обучения ООП и того, как оно приводит к плохому коду в реальной жизни (и плохой репутации OOP).
- Когда вас учили иерархиям/наследованию, то, возможно, давали подобную задачу: Допустим, у вас есть приложение университета, в которой содержится каталог студентов и персонала. Можно создать базовый класс Person, а затем класс Student и класс Staff, наследуемые от Person.
Нет-нет-нет. Здесь я вас остановлю. Негласный подтекст принципа LSP гласит, что иерархии классов и алгоритмы, которые их обрабатывают, являются симбиотическими. Это две половины целой программы. ООП — это расширение процедурного программирования, и оно по-прежнему в основном связано с этими процедурами. Если мы не знаем, какие типы алгоритмов будут работать с Students и Staff (и какие алгоритмы будут упрощены благодаря полиморфизму), то будет полностью безответственно приступать к созданию структуры иерархий классов. Сначала вам нужно узнать алгоритмы и данные.
- Когда вас обучали иерархиям/наследованию, то, вероятно, давали подобную задачу: Допустим, у вас есть класс фигур. Также у нас есть в качестве подклассов квадраты и прямоугольники. Квадрат должен быть прямоугольником, или прямоугольник квадратом?
На самом деле, это хороший пример для демонстрациии разницы между наследованием реализаций и наследованием интерфейсов.
TL; DR — ваш ООП-класс говорил вам, каким было наследование. Ваш отсутствующий OOD-класс должен был сказать вам не использовать его 99% времени!
Разобравшись с предпосылками, давайте перейдём к тому, с чего начинал Арас — к так называемой начальной точке «типичного ООП».
Но для начала ещё одно дополнение — Арас называет этот код «традиционным ООП», и на это я хочу возразить. Этот код может быть типичным для ООП в реальном мире, но, как и приведённых выше примерах, он нарушает всевозможные базовые принципы ОО, поэтому его вообще не стоит рассматривать, как традиционный.
Я начну с первого коммита, прежде чем он начал переделывать структуру в сторону ECS: «Make it work on Windows again» 3529f232510c95f53112bbfff87df6bbc6aa1fae
// -------------------------------------------------------------------------------------------------
// super simple "component system"
class GameObject;
class Component;
typedef std::vector ComponentVector;
typedef std::vector GameObjectVector;
// Component base class. Knows about the parent game object, and has some virtual methods.
class Component
{
public:
Component() : m_GameObject(nullptr) {}
virtual ~Component() {}
virtual void Start() {}
virtual void Update(double time, float deltaTime) {}
const GameObject& GetGameObject() const { return *m_GameObject; }
GameObject& GetGameObject() { return *m_GameObject; }
void SetGameObject(GameObject& go) { m_GameObject = &go; }
bool HasGameObject() const { return m_GameObject != nullptr; }
private:
GameObject* m_GameObject;
};
// Game object class. Has an array of components.
class GameObject
{
public:
GameObject(const std::string&& name) : m_Name(name) { }
~GameObject()
{
// game object owns the components; destroy them when deleting the game object
for (auto c : m_Components) delete c;
}
// get a component of type T, or null if it does not exist on this game object
template
T* GetComponent()
{
for (auto i : m_Components)
{
T* c = dynamic_cast(i);
if (c != nullptr)
return c;
}
return nullptr;
}
// add a new component to this game object
void AddComponent(Component* c)
{
assert(!c->HasGameObject());
c->SetGameObject(*this);
m_Components.emplace_back(c);
}
void Start() { for (auto c : m_Components) c->Start(); }
void Update(double time, float deltaTime) { for (auto c : m_Components) c->Update(time, deltaTime); }
private:
std::string m_Name;
ComponentVector m_Components;
};
// The "scene": array of game objects.
static GameObjectVector s_Objects;
// Finds all components of given type in the whole scene
template
static ComponentVector FindAllComponentsOfType()
{
ComponentVector res;
for (auto go : s_Objects)
{
T* c = go->GetComponent();
if (c != nullptr)
res.emplace_back(c);
}
return res;
}
// Find one component of given type in the scene (returns first found one)
template
static T* FindOfType()
{
for (auto go : s_Objects)
{
T* c = go->GetComponent();
if (c != nullptr)
return c;
}
return nullptr;
}
Да, в ста строках кода сложно разобраться сразу, поэтому давайте начнём постепенно… Нам нужен ещё один аспект предпосылок — в играх 90-х популярно было использовать наследование для решения всех проблем многократного использования кода. У вас была Entity, расширяемая Character, расширяемая Player и Monster, и так далее… Это наследование реализаций, как мы описывали его ранее («код с душком»), и кажется, что правильно начинать с него, но в результате это приводит к очень негибкой кодовой базе. Потому что в OOD есть описанный выше принцип «composition over inheritance». Итак, в 2000-х стал популярным принцип «composition over inheritance», и разработчики игр начали писать подобный код.
Что делает этот код? Ну, ничего хорошего 
Если говорить вкратце, то этот код заново реализует уже существующую особенность языка — композицию как библиотеку времени выполнения, а не как особенность языка. Можно представить это так, как будто код на самом деле создаёт новый метаязык поверх C++ и виртуальную машину (VM) для выполнения этого метаязыка. В демо-игре Араса этот код не требуется (скоро мы его полностью удалим! ) и служит только для того, чтобы примерно в 10 раз снизить производительность игры.
Однако что же он на самом деле выполняет? Это концепция »Entity/Component» («сущность/компонент») (иногда по непонятной причине называемая »Entity/Component system» («система сущность/компонент»)), но она полностью отличается от концепции »Entity Component System» («сущность-компонент-система») (который по очевидным причинам никогда не называется »Entity Component System systems). Он формализует несколько принципов «EC»:
- игра будет строиться из не имеющих особенностей «сущностей» («Entity») (в этом примере называемых GameObjects), которые состоят из «компонентов» («Component»).
- GameObjects реализуют шаблон «локатор служб» — их дочерние компоненты будут запрашиваться по типу.
- Компоненты знают, каким GameObject они принадлежат — они могут находить компоненты, находящиеся с ними на одном уровне, с помощью запросов к родительскому GameObject.
- Композиция может быть глубиной только в один уровень (компоненты не могут иметь собственных дочерних компонентов, GameObjects не могут иметь дочерних GameObjects).
- GameObject может иметь только один компонент каждого типа (в некоторых фреймворках это обязательное требование, в других нет).
- Каждый компонент (вероятно) со временем изменяется неким неуказанным образом, поэтому интерфейс содержит «virtual void Update».
- GameObjects принадлежат сцене, которая может выполнять запросы ко всем GameObjects (а значит и ко всем компонентам).
Подобная концепция была очень популярна в 2000-х годах, и несмотря на свою ограничительность, оказалась достаточно гибкой для создания бесчисленного количества игр и тогда, и сегодня.
Однако это не требуется. В вашем языке программирования уже есть поддержка композиции как особенность языка — для доступа к ней нет необходимости в раздутой концепции… Зачем же тогда существуют эти концепции? Ну, если быть честным, то они позволяют выполнять динамическую композицию во время выполнения. Вместо жёсткого задания типов GameObject в коде их можно загружать из файлов данных. И это очень удобно, потому что позволяет дизайнерам игр/уровней создавать свои типы объектов… Однако в большинстве игровых проектов бывает очень мало дизайнеров и в буквальном смысле целая армия программистов, поэтому я бы поспорил, что это важная возможность. Хуже того — это ведь не единственный способ, которым можно реализовать композицию во время выполнения! Например, Unity использует в качестве «языка скриптов» C#, и во многих других играх используются его альтернативы, например Lua — удобный для дизайнеров инструмент может генерировать код C#/Lua для задания новых игровых объектов без необходимости использования подобного раздутой концепции! Мы заново добавить эту «функцию» в следующем посте, и сделаем это так, чтобы он не стоил нам десятикратного снижения производительности…
Давайте оценим этот код в соответствии с OOD:
Итак, весь показанный выше код на самом деле можно удалить. Всю эту структуру. Удалить GameObject (в других фреймворках называемые также Entity), удалить Component, удалить FindOfType. Это часть бесполезной VM, нарушающая принципы OOD и ужасно замедляющая нашу игру.
Если мы удалим фреймворк композиции, и у нас не будет базового класса Component, то как нашим GameObjects удастся использовать композицию и состоять из компонентов? Как сказано в заголовке, вместо написания этой раздутой VM и создания поверх неё GameObjects на странном метаязыке, давайте просто напишем их на C++, потому что мы программисты игр и это в буквальном смысле наша работа.
Вот коммит, в котором удалён фреймворк Entity/Component: https://github.com/hodgman/dod-playground/commit/f42290d0217d700dea2ed002f2f3b1dc45e8c27c
Вот первоначальная версия исходного кода: https://github.com/hodgman/dod-playground/blob/3529f232510c95f53112bbfff87df6bbc6aa1fae/source/game.cpp
Вот изменённая версия исходного кода: https://github.com/hodgman/dod-playground/blob/f42290d0217d700dea2ed002f2f3b1dc45e8c27c/source/game.cpp
Вкратце об изменениях:
- Удалили »: public Component» из каждого типа компонента.
- Добавили конструктор к каждому типу компонента.
- OOD — это в первую очередь про инкапсуляцию состояния класса, но поскольку эти классы так малы/просты, скрывать особо нечего: интерфейс — это описание данных. Однако одна из главных причин того, что инкапсуляция является основным столпом, заключается в том, что она позволяет нам гарантировать постоянную истинность инвариантов класса… или в случае, если инвариант нарушен, то вам достаточно исследовать инкапсулированный код реализации, чтобы найти ошибку. В этом примере кода стоит добавить конструкторы, чтобы воплотить простой инвариант — все значения должны быть инициализированы.
- Я переименовал слишком общие методы «Update», чтобы их названия отражали то, что делают на самом деле — UpdatePosition для MoveComponent и ResolveCollisions для AvoidComponent.
- Я удалил три жёстко заданных блока кода, напоминающие шаблон/префаб — код, который создаёт GameObject, содержащий конкретные типы Component, и заменил его тремя классами C++.
- Устранил антипаттерн «virtual void Update».
- Вместо того, чтобы компоненты искали друг друга через шаблон «локатор служб», игра явным образом связывает их вместе при конструировании.
Объекты
Поэтому вместо этого кода «виртуальной машины»:
// create regular objects that move
for (auto i = 0; i < kObjectCount; ++i)
{
GameObject* go = new GameObject("object");
// position it within world bounds
PositionComponent* pos = new PositionComponent();
pos->x = RandomFloat(bounds->xMin, bounds->xMax);
pos->y = RandomFloat(bounds->yMin, bounds->yMax);
go->AddComponent(pos);
// setup a sprite for it (random sprite index from first 5), and initial white color
SpriteComponent* sprite = new SpriteComponent();
sprite->colorR = 1.0f;
sprite->colorG = 1.0f;
sprite->colorB = 1.0f;
sprite->spriteIndex = rand() % 5;
sprite->scale = 1.0f;
go->AddComponent(sprite);
// make it move
MoveComponent* move = new MoveComponent(0.5f, 0.7f);
go->AddComponent(move);
// make it avoid the bubble things
AvoidComponent* avoid = new AvoidComponent();
go->AddComponent(avoid);
s_Objects.emplace_back(go);
}
У нас теперь есть обычный код C++:
struct RegularObject
{
PositionComponent pos;
SpriteComponent sprite;
MoveComponent move;
AvoidComponent avoid;
RegularObject(const WorldBoundsComponent& bounds)
: move(0.5f, 0.7f)
// position it within world bounds
, pos(RandomFloat(bounds.xMin, bounds.xMax),
RandomFloat(bounds.yMin, bounds.yMax))
// setup a sprite for it (random sprite index from first 5), and initial white color
, sprite(1.0f,
1.0f,
1.0f,
rand() % 5,
1.0f)
{
}
};
...
// create regular objects that move
regularObject.reserve(kObjectCount);
for (auto i = 0; i < kObjectCount; ++i)
regularObject.emplace_back(bounds);
Алгоритмы
Ещё одно серьёзное изменение внесено в алгоритмы. Помните, в начале я сказал, что интерфейсы и алгоритмы работают в симбиозе, и должны влиять на структуру друг друга? Так вот, антипаттерн »virtual void Update» стал врагом и здесь. Первоначальный код содержит алгоритм основного цикла, состоящий всего лишь из этого:
// go through all objects
for (auto go : s_Objects)
{
// Update all their components
go->Update(time, deltaTime);
Вы можете возразить, что это красиво и просто, но ИМХО это очень, очень плохо. Это полностью обфусцирует и поток управления, и поток данных внутри игры. Если мы хотим иметь возможность понимать своё ПО, если мы хотим поддерживать его, если мы хотим добавлять в него новые вещи, оптимизировать его, выполнять его эффективно на нескольких процессорных ядрах, то нам нужно понимать и поток управления, и поток данных. Поэтому «virtual void Update» нужно предать огню.
Вместо него мы создали более явный основной цикл, который сильно упрощает понимание потока управления (поток данных в нём по-прежнему обфусцирован, но мы исправим это в следующих коммитах).
// Update all positions
for (auto& go : s_game->regularObject)
{
UpdatePosition(deltaTime, go, s_game->bounds.wb);
}
for (auto& go : s_game->avoidThis)
{
UpdatePosition(deltaTime, go, s_game->bounds.wb);
}
// Resolve all collisions
for (auto& go : s_game->regularObject)
{
ResolveCollisions(deltaTime, go, s_game->avoidThis);
}
Недостаток такого стиля в том, что для каждого нового типа объекта, добавляемого в игру, нам придётся добавлять в основной цикл несколько строк. Я вернусь к этому в последующем посте из этой серии.
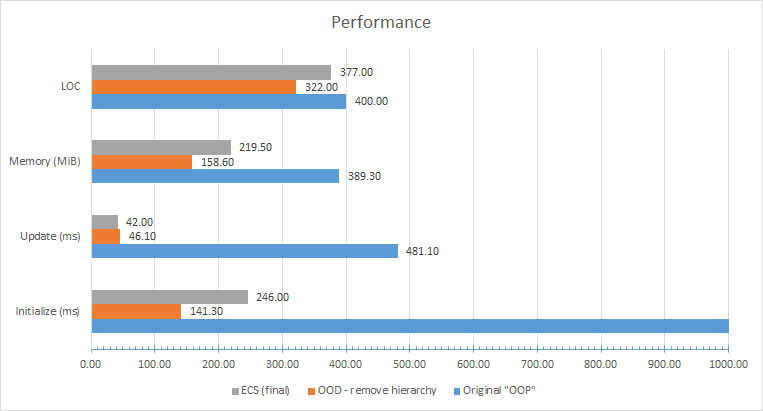
Здесь множество огромных нарушений OOD, сделано несколько плохих решений при выборе структуры и остаётся много возможностей для оптимизации, но я доберусь до них в следующем посте серии. Однако на уже на этом этапе понятно, что версия с «исправленным OOD» почти полностью соответствует или побеждает финальный «ECS»-код из конца презентации… И всё, что мы сделали — просто взяли плохой код псевдо-ООП, и заставили его соблюдать принципы ООП (а также удалил сто строк кода)!
Здесь я хочу рассмотреть гораздо больший спектр вопросов, в том числе решение оставшихся проблем OOD, неизменяемые объекты (программирование в функциональном стиле) и преимущества, которые они могут привнести в рассуждениях о потоках данных, передачу сообщений, применение логики DOD к нашему OOD-коду, применение относящейся к делу мудрости в OOD-коде, удаление этих классов «сущностей», которые в результате у нас получились, и использование только чистых компонентов, использование разных стилей соединения компонентов (сравнение указателей и обработчиков), контейнеры компонентов из реального мира, доработку ECS-версии для улучшения оптимизации, а также дальнейшую оптимизацию, не упомянутую в докладе Араса (например многопоточность/SIMD). Порядок не обязательно будет таким, и, возможно, я рассмотрю не всё перечисленное…
Ссылки на статью распространились за пределы кругов разработчиков игр, поэтому добавлю: «ECS» (эта статья Википедии плоха, кстати, она объединяет концепции EC и ECS, а это не одно и то же…) — это фальшивый шаблон, циркулирующий внутри сообществ разработчиков игр. По сути, он является версией реляционной модели, в которой «сущности» — это просто ID, обозначающие бесформенный объект, «компоненты» — это строки в конкретных таблицах, ссылающиеся на ID, а «системы» — это процедурный код, который может модифицировать компоненты. Этот «шаблон» всегда позиционировался как решение проблемы избыточного применения наследования, но при этом не упоминается, что избыточное применение наследования на самом деле нарушает рекомендации ООП. Отсюда моё возмущение. Это не «единственно верный способ» написания ПО. Пост предназначен для того, чтобы люди на самом деле изучали существующие принципы проектирования.
