Быстрое обнаружение поддерживаемых SNMP-устройством MIB-модулей
При внедрении систем мониторинга и управления IT-инфраструктурой часто приходится сталкиваться с «нестандартными» устройствами. Нередко про такое устройство наверняка известно только то, что оно поддерживает SNMP. Подключение его к проекту придется начать с ответа на вопрос о том, какую информацию о себе оно предоставляет. Обычно для этого проводится полный опрос устройства, и полученные данные анализируются на предмет выявления полезной информации… Но тут, как говорится, есть нюансы. В этой заметке я расскажу об одном таком — о разработанном нами алгоритме быстрого определения «поддерживаемых» устройством MIB-модулей.Данных на устройстве может быть довольно много. Например, маршрутизатор Cisco 2600, с которым я немного поэкспериментировал в процессе написания этой статьи, выдает более 12-ти тысяч значений. И, надо сказать, это далеко не предел.В связи с этим возникает пара проблем: как в этой куче информационного богатства отыскать именно полезные/нужные данные, и как это сделать за разумное время?
И, надо сказать, это далеко не предел.В связи с этим возникает пара проблем: как в этой куче информационного богатства отыскать именно полезные/нужные данные, и как это сделать за разумное время?
Решение первой лежит на поверхности: в соответствии с древней стратегией «разделяй и властвуй» надо разбить все собранные значения на относительно небольшое количество категорий, каждую из которых оценить на предмет полезности. Ответ на вопрос «как и на какие категории разбивать данные?» в данном случае тоже достаточно очевиден — все (ну, или практически все) данные до нас рассортировали по MIB-модулям, куда обычно складывают описания логически связанных между собой элементов данных (переменных).
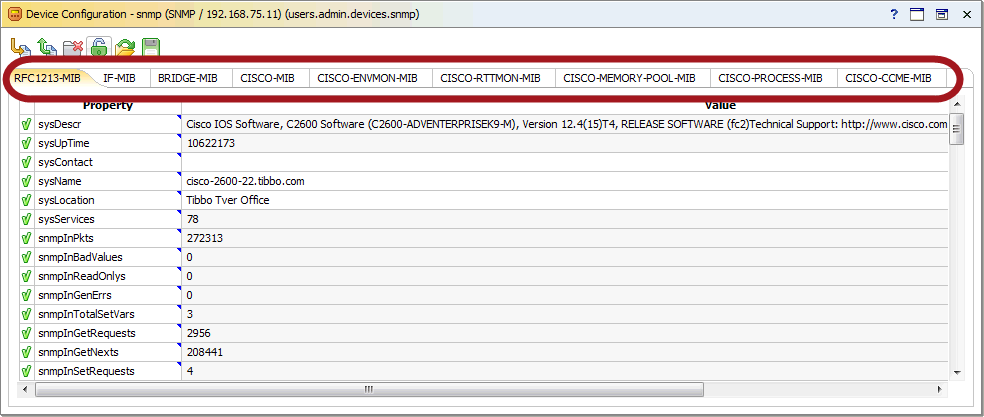 Стандартный способ разбиения SNMP-данных в AggreGate Network Manager — по MIB-модулям.
Стандартный способ разбиения SNMP-данных в AggreGate Network Manager — по MIB-модулям.
Таким образом, подзадача выделения нужной информации сводится к отображению полученных данных на MIB-модули (связь осуществляется по идентификатору переменной — OID-у).
Существует много инструментов, делающих что-то подобное. И все они (по крайней мере, все известные нам) выполняют полный опрос устройства.
Так, к примеру, работает утилита MIB Walk в составе Engineer’s Toolset от SolarWinds, которая ту же «киску» с моего компьютера опрашивает 3,5 — 4 минуты. Вроде бы, это и не так много. Но надо учесть, что это не самое «большое» устройство, и что доступно мне оно по слабо загруженной локальной сети. В условиях настоящего «боевого» проекта, где присутствует серьезный трафик, а устройство находится в другой сети, время полного опроса может вырасти на порядки. И пока идет такой опрос, специалист, в чьи обязанности входит подключение устройства, так или иначе отвлечется, что называется «потеряет контекст», и сюда придется добавить время на «возвращение к задаче» (что нередко оказывается значительным довеском). Надо также учесть, что таких устройств в серьезном проекте часто бывает много — в некоторых случаях нам приходилось изучать по 2 — 3 десятка устройств. В конечном итоге набегает значительная величина.
Так или иначе, но и наши собственные специалисты по внедрению систем мониторинга, и самостоятельно настраивающие систему пользователи в какой-то момент стали часто упоминать ожидание завершения полного опроса SNMP-устройств в качестве одного из факторов, существенно «тормозящих» работу. И пришлось изобретать способ, позволяющий сократить время бесполезного ожидания. В итоге, мы придумали и реализовали в своей системе следующий алгоритм.
Хорошая формулировка проблемы — половина решения. Мы можем описать задачу следующим образом. Даны список MIB-модулей и SNMP-устройствоТребуется определить, «поддерживается» ли этим устройством каждый из данных MIB-модулей.
Такая формулировка сразу ставит вопрос: Что значит «MIB-модуль поддерживается устройством»? MIB-модуль представляет собой описание некоторого набора SNMP-переменных. В свете этого логично звучит следующий ответ на вопрос: будем считать, что MIB-модуль поддерживается, если хотя бы одна описанная в нем переменная присутствует на устройстве.Замечание: Есть небольшая сложность: одно и то же значение может быть описано в разных MIB-ах. Ниже мы это учтем.Из данного определения напрямую вытекает идея оптимизации: если мы нашли на устройстве одну переменную из некоторого MIB-модуля, остальные переменные данного модуля можно исключить из опроса. Поскольку переменные MIB-модуля чаще всего идут довольно большими блоками, мы можем не просто заметно, а, как показывает практика, радикально сократить количество данных, которые нам нужно будет получить от устройства. За счет этого снизится и время опроса.
Получаем такой алгоритм:
Сначала сформируем списки OID-ов, описанных в каждом MIB-е нашей библиотеки. Для каждого OID-а запомним, к каким MIB-ам он принадлежит (их может быть несколько, помните?), и сольем эти списки в единое множество, отсортировав OID-ы в лексикографическом порядке Теперь, получив от устройства с помощью GET_NEXT очередную переменную и определив MIB-модули, которым она принадлежит, мы не только «включаем» эти модули в список поддерживаемых, но можем с чистой совестью убрать из списка все принадлежащие (только) этим MIB-модулям OID-ы. Следующий GET_NEXT мы делаем уже для первой оставшейся в списке опроса переменной. Таким образом, мы не «гуляем» (WALK) по устройству, а буквально несемся по нему большими скачками.
Помня о высокой «кучности» OID-ов в MIB-модуле, можно слегка улучшить алгоритм за счет предварительного «прореживания» исходного списка OID-ов: если некоторая последовательность OID-ов относится к одному MIB-модулю (или, в более общем случае, к одному множеству MIB-модулей), то нет смысла проверять их все — запрос GET_NEXT к первом из них в любом случае выдаст либо один из этой группы, либо покажет, что данный блок данных на устройстве отсутствует.
На рисунках представлен результат обнаружения MIB-модулей на упомянутом выше маршрутизаторе Cisco.Начало списка обнаруженных модулей: 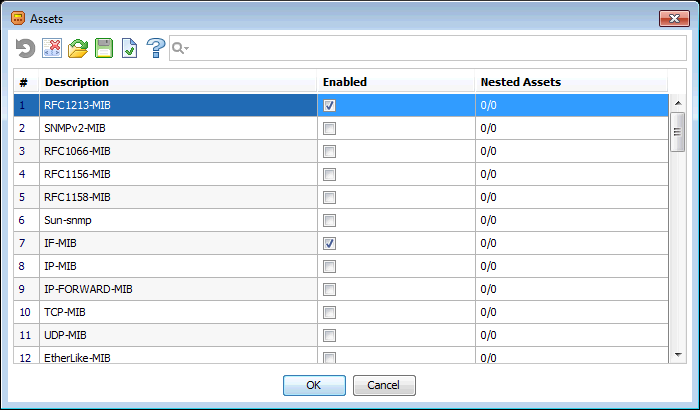 А это — его последняя страница:
А это — его последняя страница: 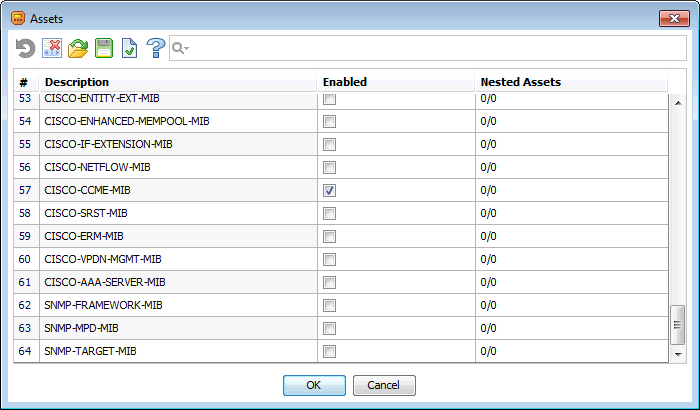
Как видим, обнаружено 64 MIB-модуля. Кстати, время работы алгоритма: 1–2 секунды.
На следующем скриншоте — результат обнаружения на «нестандартном» устройстве Hirschmann Railswitch RSB20.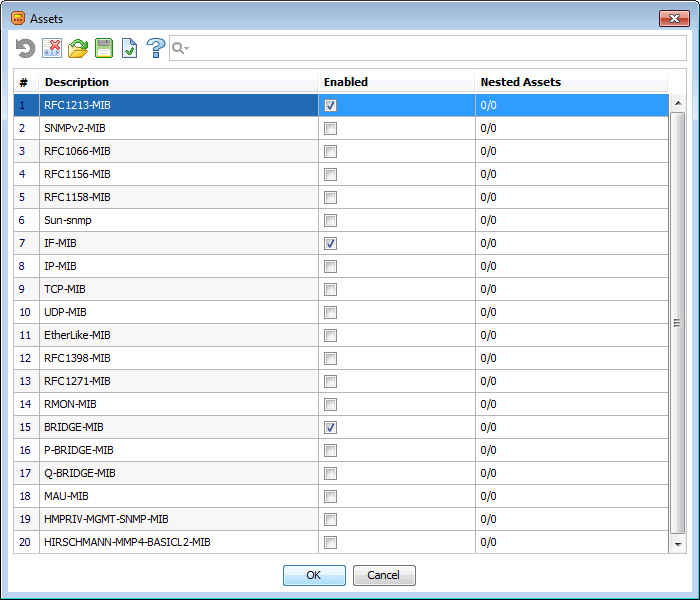 Две последних записи представляют «кастомные» MIB-модули, поставляющиеся с этим устройством.
Две последних записи представляют «кастомные» MIB-модули, поставляющиеся с этим устройством.
«Вживую» процесс обнаржения MIB-модулей на Hirschmann-е можно увидеть в нашем ролике про подключение нестандартных устройств (гурманов может заинтересовать англоязычная версия). Правда вся магия с MIB-ами остается за кадром и укладывается в двух–трех секундный отрезок, но зато станет понятен наш подход к работе с SNMP-устройствами.
Алгоритм быстрого обнаружения поддерживаемых устройством MIB-модулей был реализован в драйвере SNMP системы AggreGate. На данный момент он отлажен и стабильно работает в разных проектах по мониторингу IT-инфраструктуры разного уровня на протяжении уже нескольких лет. За последний год ошибок в нем выявлено не было, что говорит о том, по крайней мере, что идея правильная. До этого время от времени встречались неточности, но 99% из них были связаны с разнообразно-неправильными с точки зрения спецификаций SNMP реализациями агента на устройствах. Но клиент всегда прав, пришлось вносить в драйвер поправки, учитывающие такие «особенности»; касалось это и реализации данного алгоритма.
