Бюджетное SAN-хранилище на LSI Syncro, часть 2
 Продолжу, первая часть тут.
Продолжу, первая часть тут.
Итак, приступим к настройке софта, управляющего кластером.У нас это будет Pacemaker + Corosync в качестве транспортного бэкенда для общения между нодами.Corosync для большей надёжности поддерживает работу через несколько колец обмена данными.Причём, три и более уже не тянет, хотя в доках про это нигде особо не указано, только ругается при запуске если указать более двух в конфиге.Кольца названы так потому что общение между нодами идёт по кольцу — ноды передают данные друг другу последовательно, заодно проверяя живучесть друг друга. Работает оно по UDP, может как по мультикасту, так и по уникасту. У нас будет последний, почему — будет понятно ниже.
Кольца
Для связи между нодами я решил применить несколько параноидальную схему — внешнее кольцо через коммутаторы (тут стандартный Bonding/Etherchannel на два свича) + внутреннее кольцо, соединяющее ноды напрямую (напомню, что их три — два хранилища + свидетель).Схема следующая: 
Зелёные связи — внутреннее кольцо, чёрные — внешнее. В данной топологии ноды должны будут сохранить связность даже при полном отказе внешних устройств (шторм положил коммутаторы, админ (то бишь я) своими кривыми руками что-то напортачил… маловероятно, но всё может быть).Но тут случился затык — как организовать свободный обмен данными между нодами по внутреннему кольцу? А ведь это именно топология кольцо, не очень характерная для Ethernet. Связность между любыми двумя нодами должна сохраняться при разрыве любого из трёх линков, образующих кольцо.
Были рассмотрены следующие варианты:
Обычный Ethernet-мост + STP для обрыва петель. При тюнинге таймеров STP можно добиться сходимости в 5–6 секунд.Для нас это вечность, не пойдёт.
Относительно недавно добавленный в ядро протокол HSR. Если кратко, то он был задуман для отказоустойчивой связи в топологиях Ring и Mesh с мгновенной сходимостью. Два интерфейса объединяются в подобие моста и пакеты, с дополнительными заголовками, уходят в оба интерфейса одновременно. Приходящие пакеты, которые предназначены не нам — переправляем дальше по кольцу. Для отсекания петель используются идентификаторы из заголовка пакета (т.е. то, что уже пересылали — отбрасываем, в таком духе).Выглядит красиво и вкусно, но реализация хромает: даже в последнем стабильном ядре 3.18 при удалении HSR-устройства это самое ядро падает (в GIT уже поправили).Но, даже если не удалять — работает странно, я так и не смог прогнать iperf по кольцу для замера скорости (которая должна быть около 50% от номинальной) — траффик не шёл, хотя пинги бегали, глубже разбираться не стал.
В общем, тоже отметаем.
OSPF. Учитывая, что для Corosync не важна L2-связность, это оказался самый подхдящий вариант. Время сходимости около 100 мсек, что нас вполне устраивает. Quagga Для реализации OSPF используем Кваггу. Есть ещё проект BIRD от наших соседей из Чехии, но мне как-то привычнее Quagga. Хотя BIRD, по некоторым тестам, работает быстрее и занимает меньше памяти, но в наших реалиях это, в общем, по барабану.Каждый линк между хостами будет отдельной /24 сетью. Да, можно использовать /30 или даже /31, но эти сети не будут никуда маршрутизоваться, так что экономить смысла особого не было.
На каждом хосте создадим dummy-интерфейс c IP-адресом /32 для анонса соседям, Corosync будет общаться именно через них. Можно было этот адрес повесить на Loopback, но отдельный интерфейс для этих целей мне показался более подходящим.
Примерные куски /etc/network/interfaces:
Storage1 # To Storage-2 auto int1 iface int1 inet static address 192.168.160.74 netmask 255.255.255.0
# To Witness auto ext2 iface ext2 inet static address 192.168.161.74 netmask 255.255.255.0
# Dummy loopback auto dummy0 iface dummy0 inet static address 192.168.163.74 netmask 255.255.255.255 Storage2 # To Storage-1 auto int1 iface int1 inet static address 192.168.160.75 netmask 255.255.255.0
# To Witness auto ext2 iface ext2 inet static address 192.168.162.75 netmask 255.255.255.0
# Dummy loopback auto dummy0 iface dummy0 inet static address 192.168.163.75 netmask 255.255.255.255 Witness # To Storage-1 auto int2 iface int2 inet static address 192.168.161.76 netmask 255.255.255.0
# To Storage-2 auto ext2 iface ext2 inet static address 192.168.162.76 netmask 255.255.255.0
# Dummy loopback auto dummy0 iface dummy0 inet static address 192.168.163.76 netmask 255.255.255.255 Именование сетевых интерфейсов (intN, extN) тут по принципу встроенный это или внешний адаптер + порядковый номер порта на нём, мне так удобнее.Далее настраиваем OSPF./etc/quagga/ospfd.conf:
Storage1 hostname storage1
interface int1 ip ospf dead-interval minimal hello-multiplier 10 ip ospf retransmit-interval 3
interface ext2 ip ospf dead-interval minimal hello-multiplier 10 ip ospf retransmit-interval 3
router ospf log-adjacency-changes
network 192.168.160.0/24 area 0 network 192.168.161.0/24 area 0 network 192.168.163.74/32 area 0
passive-interface dummy0
timers throttle spf 10 10 100 Storage2 hostname storage2
interface int1 ip ospf dead-interval minimal hello-multiplier 10 ip ospf retransmit-interval 3
interface ext2 ip ospf dead-interval minimal hello-multiplier 10 ip ospf retransmit-interval 3
router ospf log-adjacency-changes
network 192.168.160.0/24 area 0 network 192.168.162.0/24 area 0 network 192.168.163.75/32 area 0
passive-interface dummy0
timers throttle spf 10 10 100 Witness hostname witness
interface int2 ip ospf dead-interval minimal hello-multiplier 10 ip ospf retransmit-interval 3
interface ext2 ip ospf dead-interval minimal hello-multiplier 10 ip ospf retransmit-interval 3
router ospf log-adjacency-changes
network 192.168.161.0/24 area 0 network 192.168.162.0/24 area 0 network 192.168.163.76/32 area 0
passive-interface dummy0
timers throttle spf 10 10 100 Включаем на хостах net.ipv4.ip_forward, запускаем кваггу, пинг с интервалом в 0.01с, и рвём кольцо: root@witness:/# ping -i 0.01 -f 192.168.163.74 … root@storage1:/# ip link set ext2 down
root@witness:/# --- 192.168.163.74 ping statistics --- 2212 packets transmitted, 2202 received, 0% packet loss, time 26531ms rtt min/avg/max/mdev = 0.067/0.126/0.246/0.045 ms, ipg/ewma 11.999/0.183 ms Итого, потеряно 10 пакетов, это около 100 мсек — OSPF сменил маршруты очень быстро.Corosync Теперь, когда сетевая подсистема готова, будем настраивать Corosync на её эксплуатацию.Конфиг на всех хостах должен быть почти идентичен, меняется только адрес dummy0 интерфейса во внутреннем кольце:
/etc/corosync/corosync.conf compatibility: none
totem { version: 2 # Произвольное имя cluster_name: storage # Аутентификация через файл authkey, который мы раскидали по всем нодам в прошлой части. Лишней не будет. secauth: on # Включаем дополнительный контроль живости нод heartbeat_failures_allowed: 3 threads: 6 # Режим отказоустойчивых колец активный — юзать сразу оба кольца. Об особенностях читать в доках. rrp_mode: active # Не использовать мультикаст — для нас это важно, так как городить мультикаст роутинг через OSPF нет никакого желания. transport: udpu # Внешнее кольцо, перечисляем адреса нод interface { member { memberaddr: 10.1.195.74 }
member { memberaddr: 10.1.195.75 }
member { memberaddr: 10.1.195.76 }
ringnumber: 0 # Сеть адаптера, к которому будем привязываться bindnetaddr: 10.1.195.0 # Порт для обмена сообщениями. Несмотря на название используется и в уникасте. Также резервируется (mcastport-1) для приёма. mcastport: 6405 } # Внутреннее кольцо interface { member { memberaddr: 192.168.163.74 }
member { memberaddr: 192.168.163.75 }
member { memberaddr: 192.168.163.76 }
ringnumber: 1 # Этот адрес выставить соответственно адресу dummy0 bindnetaddr: 192.168.163.76 mcastport: 5405 } }
# Дальше всё стандартно amf { mode: disabled }
service { ver: 1 name: pacemaker }
aisexec { user: root group: root }
logging { syslog_priority: warning fileline: off to_stderr: yes to_logfile: no to_syslog: yes syslog_facility: daemon debug: off timestamp: on logger_subsys { subsys: AMF debug: off tags: enter|leave|trace1|trace2|trace3|trace4|trace6 } } После этого запускаем Corosync и смотрим статус колец на серверах и список нод, которые объединяет Corosync: root@storage1:/# corosync-cfgtool -s Printing ring status. Local node ID 1254293770 RING ID 0 id = 10.1.195.74 status = ring 0 active with no faults RING ID 1 id = 192.168.163.74 status = ring 1 active with no faults
root@storage1:/# corosync-objctl | grep member totem.interface.member.memberaddr=10.1.195.74 totem.interface.member.memberaddr=10.1.195.75 totem.interface.member.memberaddr=10.1.195.76 totem.interface.member.memberaddr=192.168.163.74 totem.interface.member.memberaddr=192.168.163.75 totem.interface.member.memberaddr=192.168.163.76 runtime.totem.pg.mrp.srp.members.1254293770.ip=r (0) ip (10.1.195.74) r (1) ip (192.168.163.74) runtime.totem.pg.mrp.srp.members.1254293770.join_count=1 runtime.totem.pg.mrp.srp.members.1254293770.status=joined runtime.totem.pg.mrp.srp.members.1271070986.ip=r (0) ip (10.1.195.75) r (1) ip (192.168.163.75) runtime.totem.pg.mrp.srp.members.1271070986.join_count=2 runtime.totem.pg.mrp.srp.members.1271070986.status=joined runtime.totem.pg.mrp.srp.members.1287848202.ip=r (0) ip (10.1.195.76) r (1) ip (192.168.163.76) runtime.totem.pg.mrp.srp.members.1287848202.join_count=1 runtime.totem.pg.mrp.srp.members.1287848202.status=joined Ага, всё работает.Pacemaker Теперь, когда бэкенд кластера в рабочем состоянии — можно приступить к настройке.На каждой ноде запускаем Pacemaker, и с любой из них смотрим статус кластера: root@storage1:/# crm status ============ Last updated: Tue Mar 24 09:39:28 2015 Last change: Mon Mar 23 11:40:13 2015 via crmd on witness Stack: openais Current DC: witness — partition with quorum Version: 1.1.7-ee0730e13d124c3d58f00016c3376a1de5323cff 3 Nodes configured, 3 expected votes 0 Resources configured. ============
Online: [ storage1 storage2 witness ] Все ноды видны, можно приступать к настройке.Запускаем crm configure edit, откроется редактор по умолчанию (nano) и туда заносим такую вот ересь:
Конфиг кластера node storage1 node storage2 node witness
# Описываем STONITH (Shoot The Other Node In The Head) ресурсы. # В данном случае, если нода выпадет из кластера, остальные две посовещаются и убьют её через IPMI послав команду RESET primitive ipmi_storage1 stonith: external/ipmi \ params hostname=«storage1» ipaddr=»10.1.1.74» userid=«stonith» passwd=«xxx» interface=«lanplus» \ pcmk_host_check=«static-list» pcmk_host_list=«storage1» primitive ipmi_storage2 stonith: external/ipmi \ params hostname=«storage2» ipaddr=»10.1.1.75» userid=«stonith» passwd=«xxx» interface=«lanplus» \ pcmk_host_check=«static-list» pcmk_host_list=«storage2»
# Ресурс для управления состояниями ALUA, параметры выставить согласно своему /etc/scst.conf primitive p_scst ocf: esos: scst \ params alua=«true» device_group=«default» \ local_tgt_grp=«local» \ remote_tgt_grp=«remote» \ m_alua_state=«active» \ s_alua_state=«nonoptimized» \ op monitor interval=»10» role=«Master» \ op monitor interval=»20» role=«Slave» \ op start interval=»0» timeout=»120» \ op stop interval=»0» timeout=»60»
# Описываем режимы Master-Slave для вышеуказанного ресурса ms ms_scst p_scst \ meta master-max=»1» master-node-max=»1» clone-max=»2» clone-node-max=»1» notify=«true» interleave=«true» \ target-role=«Master»
# Предпочитаем ноду storage1 для Master-режима location prefer_ms_scst ms_scst inf: #uname eq storage1
# Не запускаем ресурс SCST на ноде witness location dont_run ms_scst -inf: #uname eq witness
# Запрещаем ресурсам STONITH висеть на тех же нодах, которые они призваны убивать. Cамоубийство — это не наш метод! location loc_ipmi_on_storage1 ipmi_storage1 -inf: #uname eq storage1 location loc_ipmi_on_storage2 ipmi_storage2 -inf: #uname eq storage2
property $id=«cib-bootstrap-options» \ dc-version=»1.1.7-ee0730e13d124c3d58f00016c3376a1de5323cff» \ cluster-infrastructure=«openais» \ expected-quorum-votes=»3» \ stonith-enabled=«true» \ last-lrm-refresh=»1427100013» Сохраняем, применяем (commit).Для STONITH в IPMI серверов нужно создать юзера с правами Administrator, иначе ресурс будет отказываться к нему подключаться. В принципе, хватило бы и Operator, но ковырять код ресурса желания не было.
Смотрим статус кластера:
root@storage1:/# crm status ============ Last updated: Wed Mar 25 15:48:29 2015 Last change: Mon Mar 23 11:40:13 2015 via crmd on witness Stack: openais Current DC: witness — partition with quorum Version: 1.1.7-ee0730e13d124c3d58f00016c3376a1de5323cff 3 Nodes configured, 3 expected votes 4 Resources configured. ============
Online: [ storage1 storage2 witness ]
Master/Slave Set: ms_scst [p_scst] Masters: [ storage1 ] Slaves: [ storage2 ] ipmi_storage1 (stonith: external/ipmi): Started witness ipmi_storage2 (stonith: external/ipmi): Started storage1 Ну, вроде бы всё красиво. В принципе, уже можно подключаться с инициаторов.Для верности мы проверим как работает STONITH:
Отключаемся от коммутаторов: root@storage2:/# ip link set bond_hb_ext down
… мы всё еще живы.
Рвём внутреннее кольцо в одом месте root@storage2:/# ip link set int1 down
… и всё равно кластер ещё держится.
Рвём последнюю ниточку: root@storage2:/# ip link set ext2 down
… и через пару секунд кластер коллегиальным решением нас грохнул :) Сервер ушёл в ребут. Небольшое замечание по работе с Master-Slave ресурсами: в Pacemaker нет команды, которая принудительно поменяет ноды, на которых в данный момент ресурс работает Master-ом и Slave-ом, местами. Можно только командой demote перевести ресурс в Slave на обеих нодах.Решения два:1) Редактируем конфигурацию кластера и меняем предпочитаемую ноду для Master-режима на другую, коммитим и через некоторое небольшое время кластер сам отработает по перемещению ресурса.2) В нашем случае, так как рабочий ресурс, по сути, только один, можно просто потушить Pacemaker на Master-ноде:) Это сигнализирует второй ноде перейти в Master режим. После этого перезагрузить бывшую мастер-ноду для того чтобы владение массивами ушло к другой ноде.
В случае плановой остановки Pacemaker и Corosync STONITH отрабатывать не будет.
Финальные штрихи Установить на все сервера Watchdog-демон, работающий с IPMI через /dev/watchdog на тот случай, если сервер зависнет, а STONITH его по каким-то причинам убить не сможет./etc/watchdog.conf: watchdog-device = /dev/watchdog admin = root interval = 1 realtime = yes priority = 1 Выставить в /etc/sysctl.conf параметры: kernel.panic = 1 kernel.panic_on_io_nmi = 1 kernel.panic_on_oops = 1 kernel.panic_on_unrecovered_nmi = 1 kernel.unknown_nmi_panic = 1 Это нужно для того, чтобы ядро в любой непонятной (а OOPS и всякие NMI это скверно) ситуации резетило сервер и давало второй ноде полноценно взяться за дело. Если ядро будет ещё более или менее живое, то этот функционал должен отработать быстрее чем Watchdog и STONITH. Настроить watchquagga в /etc/quagga/debian.conf на перезапуск в случае падения каких-либо демонов Quagga: watchquagga_enable=yes watchquagga_options=(--daemon --unresponsive-restart -i 5 -t 5 -T 5 --restart-all '/etc/init.d/quagga restart') Настроить NetConsole для прямого сбора логов ядра с серверов-хранилищ на Witness-ноде на случай каких-либо проблем.Добавить в /etc/fstab: none /sys/kernel/config configfs defaults 0 0 Плюс небольшой скрипт для настройки: netconsole.pl #!/usr/bin/perl -w
use strict; use warnings;
my $dir = '/sys/kernel/config/netconsole';
my %tgts = ( 'tgt1' => { 'dev_name' => 'ext2', 'local_ip' => '192.168.161.74', 'remote_ip' => '192.168.161.76', 'remote_mac' => '00:25:90:77: b8:8b', 'remote_port' => '6666' } );
foreach my $tgt (sort keys %tgts) { my $t = $tgts{$tgt}; my $tgtdir = $dir.»/».$tgt;
mkdir ($tgtdir); foreach my $k (sort keys $t) { system («echo '».$t→{$k}.»' > ».$tgtdir.»/».$k); }
system («echo 1 > ».$tgtdir.»/enabled»);
}
После активации кластера хранилищ на инициаторах уже должны появиться наши LUNы:  Здесь мы видим (один из портов FC):2 устройства, 4 путя до каждого (2 к основному хранилищу, 2 к резервному)
Hardware Acceleration = Supported означает что хранилищами поддерживаются VAAI примитивы (SCSI-команды ATS, XCOPY, WRITE SAME), которые позволяют оффлоадить часть операций с хоста на хранилище (блокировка, клонирование, забивание нулями)
SSD: позволит хосту использовать эти LUNы для Host Cache и прочих служб, которые хотят SSD
Для полноценного использования нескольких путей до хранилищ нам нужно две вещи: Установить режим Round Robin
Настроить его на смену путей каждый 1 IO. По-умолчанию он меняет путь каждую 1000 операций ввода-вывода, что не совсем оптимально, хотя и несколько меньше напрягает CPU хоста. Есть отличная статья от EMC, где очень подробно исследуется влияние этого параметра на производительность: тыц
И если первый пункт можно сделать из vSphere Client, то второй придётся делать из консоли. Для этого активируем SSH на хостах, логинимся на каждый, и вводим:
Выставляем режим Round Robin (сразу, чтобы не ковырять GUI):
# for i in `ls /vmfs/devices/disks/ | grep «eui» | grep -v »:»`; do esxcli storage nmp device set --psp=VMW_PSP_RR --device=$i; done
Меняем количество IOPS до смены пути:
# for i in `ls /vmfs/devices/disks/ | grep «eui» | grep -v »:»`; do esxcli storage nmp psp roundrobin deviceconfig set --type=iops --iops=1 --device=$i; done
Проверяем:
# for i in `ls /vmfs/devices/disks/ | grep «eui» | grep -v »:»`; do esxcli storage nmp psp roundrobin deviceconfig get --device=$i | grep IOOperation; done
IOOperation Limit: 1
IOOperation Limit: 1
Отлично. Теперь смотрим на результаты наших манипуляций:
Здесь мы видим (один из портов FC):2 устройства, 4 путя до каждого (2 к основному хранилищу, 2 к резервному)
Hardware Acceleration = Supported означает что хранилищами поддерживаются VAAI примитивы (SCSI-команды ATS, XCOPY, WRITE SAME), которые позволяют оффлоадить часть операций с хоста на хранилище (блокировка, клонирование, забивание нулями)
SSD: позволит хосту использовать эти LUNы для Host Cache и прочих служб, которые хотят SSD
Для полноценного использования нескольких путей до хранилищ нам нужно две вещи: Установить режим Round Robin
Настроить его на смену путей каждый 1 IO. По-умолчанию он меняет путь каждую 1000 операций ввода-вывода, что не совсем оптимально, хотя и несколько меньше напрягает CPU хоста. Есть отличная статья от EMC, где очень подробно исследуется влияние этого параметра на производительность: тыц
И если первый пункт можно сделать из vSphere Client, то второй придётся делать из консоли. Для этого активируем SSH на хостах, логинимся на каждый, и вводим:
Выставляем режим Round Robin (сразу, чтобы не ковырять GUI):
# for i in `ls /vmfs/devices/disks/ | grep «eui» | grep -v »:»`; do esxcli storage nmp device set --psp=VMW_PSP_RR --device=$i; done
Меняем количество IOPS до смены пути:
# for i in `ls /vmfs/devices/disks/ | grep «eui» | grep -v »:»`; do esxcli storage nmp psp roundrobin deviceconfig set --type=iops --iops=1 --device=$i; done
Проверяем:
# for i in `ls /vmfs/devices/disks/ | grep «eui» | grep -v »:»`; do esxcli storage nmp psp roundrobin deviceconfig get --device=$i | grep IOOperation; done
IOOperation Limit: 1
IOOperation Limit: 1
Отлично. Теперь смотрим на результаты наших манипуляций: 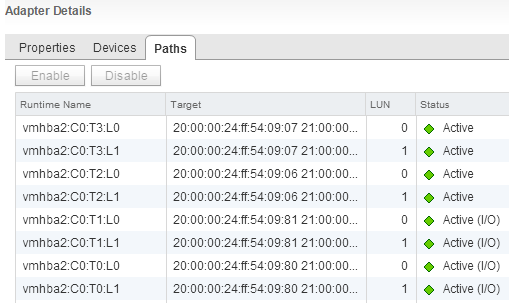
Это вид на хранилища через один из портов FC адаптера, через второй всё точно так же.Отлично, имеем 2 активных и 2 резервных пути до каждого из LUNов.
Теперь создадим на каждом LUNе VMFS, положим на них по 1 виртуальной машине с Debian (диски — Thick Provision Eager Zeroed, чтобы ESXi не мухлевал со скоростью чтения неиспользованных блоков) и проведём тестирование скорости работы и процесса переключения на резервное хранилище.
На каждой ВМ установим fio и создадим файлик read.fio с параметрами теста:
[test] blocksize=512 filename=/dev/sda size=128G rw=randread direct=1 buffered=0 ioengine=libaio iodepth=64 То есть будем делать случайное чтение блоками по 512 байт с глубиной очереди 64 пока не прочитаем 128Гбайт (такой диск у ВМ).Смотрим:


Результаты fio при тестировании с одной ВМ:
fio random test: (g=0): rw=randread, bs=512–512/512–512, ioengine=libaio, iodepth=64 2.0.8 Starting 1 process Jobs: 1 (f=1): [r] [100.0% done] [77563K/0K /s] [155K/0 iops] [eta 00m:00s] test: (groupid=0, jobs=1): err= 0: pid=3100 read: io=131072MB, bw=75026KB/s, iops=150052, runt=1788945msec slat (usec): min=0, max=554, avg= 2.92, stdev= 1.94 clat (usec): min=127, max=1354.3K, avg=420.90, stdev=1247.77 lat (usec): min=130, max=1354.3K, avg=424.51, stdev=1247.77 clat percentiles (usec): | 1.00th=[ 350], 5.00th=[ 378], 10.00th=[ 386], 20.00th=[ 398], | 30.00th=[ 406], 40.00th=[ 414], 50.00th=[ 418], 60.00th=[ 426], | 70.00th=[ 430], 80.00th=[ 438], 90.00th=[ 450], 95.00th=[ 462], | 99.00th=[ 494], 99.50th=[ 516], 99.90th=[ 636], 99.95th=[ 732], | 99.99th=[ 3696] bw (KB/s) : min= 606, max=77976, per=100.00%, avg=75175.70, stdev=3104.46 lat (usec) : 250=0.02%, 500=99.19%, 750=0.75%, 1000=0.03% lat (msec) : 2=0.01%, 4=0.01%, 10=0.01%, 20=0.01%, 250=0.01% lat (msec) : 500=0.01%, 750=0.01%, 1000=0.01%, 2000=0.01% cpu: usr=62.25%, sys=37.18%, ctx=58816, majf=0, minf=14 IO depths: 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0% submit: 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete: 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0% issued: total=r=268435456/w=0/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs): READ: io=131072MB, aggrb=75026KB/s, minb=75026KB/s, maxb=75026KB/s, mint=1788945msec, maxt=1788945msec
Disk stats (read/write): sda: ios=268419759/40, merge=0/2, ticks=62791530/0, in_queue=62785360, util=100.00% fio sequental test: (g=0): rw=read, bs=1M-1M/1M-1M, ioengine=libaio, iodepth=64 2.0.8 Starting 1 process Jobs: 1 (f=1): [R] [100.0% done] [1572M/0K /s] [1572 /0 iops] [eta 00m:00s] test: (groupid=0, jobs=1): err= 0: pid=3280 read: io=131072MB, bw=1378.6MB/s, iops=1378, runt= 95078msec slat (usec): min=36, max=2945, avg=80.13, stdev=16.73 clat (msec): min=11, max=1495, avg=46.33, stdev=29.87 lat (msec): min=11, max=1495, avg=46.42, stdev=29.87 clat percentiles (msec): | 1.00th=[ 35], 5.00th=[ 38], 10.00th=[ 39], 20.00th=[ 40], | 30.00th=[ 42], 40.00th=[ 43], 50.00th=[ 43], 60.00th=[ 44], | 70.00th=[ 52], 80.00th=[ 56], 90.00th=[ 57], 95.00th=[ 57], | 99.00th=[ 59], 99.50th=[ 62], 99.90th=[ 70], 99.95th=[ 529], | 99.99th=[ 1483] bw (MB/s) : min= 69, max= 1628, per=100.00%, avg=1420.43, stdev=219.51 lat (msec) : 20=0.04%, 50=68.57%, 100=31.33%, 750=0.02%, 2000=0.05% cpu: usr=0.57%, sys=13.40%, ctx=16171, majf=0, minf=550 IO depths: 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0% submit: 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete: 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0% issued: total=r=131072/w=0/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs): READ: io=131072MB, aggrb=1378.6MB/s, minb=1378.6MB/s, maxb=1378.6MB/s, mint=95078msec, maxt=95078msec
Disk stats (read/write): sda: ios=261725/14, merge=0/1, ticks=11798940/350, in_queue=11800870, util=99.95% Основные моменты:>300k IOPS суммарно. Довольно неплохо, учитывая что при тестировании бэкенд был зашифрован Линейная скорость плавает в пределах 1300–1580 Мбайт/с (что близко к пределу 2×8Gbit FC), тут уже упирается в скорость шифрования Random Latency у 99.9% запросов не превышает 0.7 мс Если тест на одной из ВМ остановить, то на оставшейся будут все те же 150к IOPS. Это, похоже, предел для двухпортовой FC-карты на ESXi. Хотя это несколько странно, нужно будет заняться тюнингом При тесте нагрузка на CPU хранилища около 60%, так что запас ещё есть А может бахнем? Обязательно бахнем Теперь мы проверим как система отреагирует на отключение Master-ноды.Плановое: останавливаем на Master-ноде Pacemaker. Практически мгновенно кластер переключает вторую ноду в Master-режим:
[285401.041046] scst: Changed ALUA state of default/local into active [285401.086053] scst: Changed ALUA state of default/remote into nonoptimized А на первой последовательно отключает SCST и выгружает все связанные с ним модули из ядра: dmesg [286491.713124] scst: Changed ALUA state of default/local into nonoptimized [286491.757573] scst: Changed ALUA state of default/remote into active [286491.794939] qla2×00t: Unloading QLogic Fibre Channel HBA Driver target mode addon driver [286491.795022] qla2×00t (0): session for loop_id 132 deleted [286491.795061] qla2×00t (0): session for loop_id 131 deleted [286491.795096] qla2×00t (0): session for loop_id 130 deleted [286491.795172] qla2xxx 0000:02:00.0: Performing ISP abort — ha= ffff880854e28550. [286492.428672] qla2xxx 0000:02:00.0: LIP reset occured (f7f7). [286492.488757] qla2xxx 0000:02:00.0: LOOP UP detected (8 Gbps). [286493.810720] scst: Waiting for 4 active commands to complete… This might take few minutes for disks or few hours for tapes, if you use long executed commands, like REWIND or FORMAT. In case, if you have a hung user space device (i.e. made using scst_user module) not responding to any commands, if might take virtually forever until the corresponding user space program recovers and starts responding or gets killed. [286493.810924] scst: All active commands completed [286493.810997] scst: Target 21:00:00:24: ff:54:09:80 for template qla2×00t unregistered successfully [286493.811072] qla2×00t (1): session for loop_id 0 deleted [286493.811111] qla2×00t (1): session for loop_id 1 deleted [286493.811146] qla2×00t (1): session for loop_id 2 deleted [286493.811182] qla2×00t (1): Unable to send command to SCST, sending BUSY status [286493.811226] qla2×00t (1): Unable to send command to SCST, sending BUSY status [286493.811266] qla2×00t (1): Unable to send command to SCST, sending BUSY status [286493.811305] qla2×00t (1): Unable to send command to SCST, sending BUSY status [286493.811345] qla2×00t (1): Unable to send command to SCST, sending BUSY status [286493.811384] qla2×00t (1): Unable to send command to SCST, sending BUSY status [286493.811424] qla2×00t (1): Unable to send command to SCST, sending BUSY status [286493.811463] qla2×00t (1): Unable to send command to SCST, sending BUSY status [286493.811502] qla2×00t (1): Unable to send command to SCST, sending BUSY status [286493.811541] qla2×00t (1): Unable to send command to SCST, sending BUSY status [286493.811672] qla2xxx 0000:02:00.1: Performing ISP abort — ha= ffff880854e08550. [286494.441653] qla2xxx 0000:02:00.1: LIP reset occured (f7f7). [286494.481727] qla2xxx 0000:02:00.1: LOOP UP detected (8 Gbps). [286495.833746] scst: Target 21:00:00:24: ff:54:09:81 for template qla2×00t unregistered successfully [286495.833828] qla2×00t (2): session for loop_id 132 deleted [286495.833866] qla2×00t (2): session for loop_id 131 deleted [286495.833902] qla2×00t (2): session for loop_id 130 deleted [286495.833991] qla2xxx 0000:03:00.0: Performing ISP abort — ha= ffff88084f310550. [286496.474662] qla2xxx 0000:03:00.0: LIP reset occured (f7f7). [286496.534750] qla2xxx 0000:03:00.0: LOOP UP detected (8 Gbps). [286497.856734] scst: Target 21:00:00:24: ff:54:09:32 for template qla2×00t unregistered successfully [286497.856815] qla2×00t (3): session for loop_id 0 deleted [286497.856852] qla2×00t (3): session for loop_id 1 deleted [286497.856888] qla2×00t (3): session for loop_id 130 deleted [286497.856926] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.856970] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.857009] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.857048] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.857087] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.857127] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.857166] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.857205] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.857244] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.857284] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.857323] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.857362] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.857401] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.857440] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.857480] qla2×00t (3): Unable to send command to SCST, sending BUSY status [286497.857594] qla2xxx 0000:03:00.1: Performing ISP abort — ha= ffff88084dfc0550. [286498.487642] qla2xxx 0000:03:00.1: LIP reset occured (f7f7). [286498.547731] qla2xxx 0000:03:00.1: LOOP UP detected (8 Gbps). [286499.889733] scst: Target 21:00:00:24: ff:54:09:33 for template qla2×00t unregistered successfully [286499.889799] scst: Target template qla2×00t unregistered successfully [286499.890642] dev_vdisk: Detached virtual device SSD-RAID6–1 (»/dev/disk/by-id/scsi-3600605b008b4be401c91ac4abce21c9b») [286499.890718] scst: Detached from virtual device SSD-RAID6–1 (id 1) [286499.890756] dev_vdisk: Virtual device SSD-RAID6–1 unregistered [286499.890798] dev_vdisk: Detached virtual device SSD-RAID6–2 (»/dev/disk/by-id/scsi-3600605b008b4be401c91ac53bd668eda») [286499.890869] scst: Detached from virtual device SSD-RAID6–2 (id 2) [286499.890906] dev_vdisk: Virtual device SSD-RAID6–2 unregistered [286499.890945] scst: Device handler «vdisk_nullio» unloaded [286499.890981] scst: Device handler «vdisk_blockio» unloaded [286499.891017] scst: Device handler «vdisk_fileio» unloaded [286499.891052] scst: Device handler «vcdrom» unloaded [286499.891754] scst: Task management thread PID 5162 finished [286499.891801] scst: Management thread PID 5163 finished [286499.891847] scst: Init thread PID 5161 finished [286499.899867] scst: Detached from scsi0, channel 0, id 20, lun 0, type 13 [286499.899911] scst: Detached from scsi0, channel 0, id 36, lun 0, type 13 [286499.899951] scst: Detached from scsi0, channel 0, id 37, lun 0, type 13 [286499.899992] scst: Detached from scsi0, channel 0, id 38, lun 0, type 13 [286499.900031] scst: Detached from scsi0, channel 0, id 39, lun 0, type 13 [286499.900071] scst: Detached from scsi0, channel 0, id 40, lun 0, type 13 [286499.900110] scst: Detached from scsi0, channel 0, id 41, lun 0, type 13 [286499.900150] scst: Detached from scsi0, channel 0, id 42, lun 0, type 13 [286499.900189] scst: Detached from scsi0, channel 0, id 59, lun 0, type 13 [286499.900228] scst: Detached from scsi0, channel 0, id 60, lun 0, type 13 [286499.900268] scst: Detached from scsi0, channel 2, id 0, lun 0, type 0 [286499.900307] scst: Detached from scsi0, channel 2, id 1, lun 0, type 0 [286499.900346] scst: Detached from scsi1, channel 0, id 0, lun 0, type 0 [286499.900385] scst: Detached from scsi2, channel 0, id 0, lun 0, type 0 [286499.900595] scst: Exiting SCST sysfs hierarchy… [286502.914203] scst: User interface thread PID 5153 finished [286502.914248] scst: Exiting SCST sysfs hierarchy done [286502.914458] scst: SCST unloaded На виртуальных машинах IO замирает примерно секунд на 10–15, похоже ESXi тыкается какое-то время по старым путям и только после некоего таймаута переключается на новые. IOPS на каждой ВМ падает со 120к до 22к — такова цена I/O Shipping.
Далее отключаем или перезагружаем первый сервер — Syncro на втором перехватывает ведущую роль и I/O возвращается к нормальным значениям.
Если запустить Pacemaker обратно, то кластер переключится на эту ноду обратно, ибо так писано в конфиге:)
Внеплановое: Тут мы можем, например, убить через kill -9 процесс corosync и кластер грохнет нас через STONITH. Либо просто выключить ноду по питанию. Результат один и, в общем, не отличается от планового, за исключением того, что не будет IO Shipping: второй контроллер сразу схватит массивы и скорость не упадёт до 22к IOPS.
За кадром остались ещё скрипты для self-monitoring ноды, тут большое поле для деятельности: проверка живости контроллера через всякие StorCLI, проверка отвечают ли массивы на I/O запросы (ioping) и тому подобное. В случае обнаружения неисправностей ноде следует совершить харакири.Таким вот незамысловатым способом можно сделать достаточно надёжное и быстрое хранилище из подручных материалов.Вопросы, предложения и критика приветствуются.
Всем бобра!
