«Битрикс24»: «Быстро поднятое не считается упавшим»
На сегодняшний день у сервиса «Битрикс24» нет сотен гигабит трафика, нет огромного парка серверов (хотя и существующих, конечно, немало). Но для многих клиентов он является основным инструментом работы в компании, это настоящее business-critical приложение. Поэтому падать — ну, никак нельзя. А что если падение все-таки случилось, но «восстал» сервис так быстро, что никто ничего и не заметил? И как удаётся реализовать при этом failover без потери качества работы и количества клиентов? Александр Демидов, директор направления облачных сервисов «Битрикс24», рассказал для нашего блога о том, как за 7 лет существования продукта эволюционировала система резервирования.

«В виде SaaS мы запустили «Битрикс24» 7 лет назад. Главная сложность, наверное, была в следующем: до запуска в паблик в виде SaaS этот продукт существовал просто в формате коробочного решения. Клиенты покупали его у нас, размещали у себя на серверах, заводили корпоративный портал — общее решение для общения сотрудников, хранения файлов, ведение задач, CRM, вот это всё. И мы к 2012 году решили, что хотим запустить это как SaaS, администрируя самостоятельно, обеспечивая отказоустойчивость и надёжность. Опыт мы набирали в процессе, потому что до тех самых пор у нас его просто не было — мы были лишь производителями ПО, не сервис-провайдерами.
Запуская сервис, мы понимали, что самое главное — это обеспечить отказоустойчивость, надежность и постоянную доступность сервиса, потому что если у вас простой обычный сайт, магазин, например, и он упал у вас и лежит час — страдаете только вы сами, вы теряете заказы, вы теряете клиентов, но для самого вашего клиента — для него это не очень критично. Он расстроился, конечно, но пошёл и купил на другом сайте. А если это приложение, на которое завязана вся работа внутри компании, коммуникации, решения, то самое ключевое — это завоевать доверие пользователей, то есть не подводить их и не падать. Потому что вся работа может встать, если что-то внутри работать не будет.
Битрикс. 24 как SaaS
Первый прототип мы собрали за год до публичного запуска, в 2011 году. Собрали примерно за неделю, посмотрели, покрутили — он даже был работающий. То есть можно было зайти в форму, ввести там название портала, разворачивался новый портал, заводилась база пользователей. Посмотрели на него, оценили в принципе продукт, свернули, и целый год дальше дорабатывали. Потому что у нас была большая задача: мы не хотели делать две разные кодовые базы, мы не хотели поддерживать отдельно коробочный продукт, отдельно облачные решения, — мы хотели делать все это в рамках одного кода.

Типичное веб-приложение на тот момент — это один сервер, на котором крутится какой-то код php, база mysql, файлы загружаются, документы, картинки кладутся в папочку upload — ну и всё это работает. Увы, запускать критически устойчивый веб-сервис на этом невозможно. Там распределенный кэш не поддерживается, репликация баз данных не поддерживается.
Мы сформулировали требования: это умение размещаться в разных локейшнах, поддерживать репликацию, в идеале размещаться в разных географически распределённых дата-центрах. Разделить логику продукта и, собственно, хранение данных. Динамически уметь масштабироваться по нагрузке, статику вообще вынести. Из этих соображений сложились, собственно, требования к продукту, который мы как раз в течение года и дорабатывали. За это время в платформе, которая получилась единой — для коробочных решений, для нашего собственного сервиса, — мы сделали поддержку тех вещей, которые нам были необходимы. Поддержку репликации mysql на уровне самого продукта: то есть разработчик, который пишет код — не задумывается, как его запросы будут распределяться, он использует наш api, а мы умеем правильно распределять запросы на запись и на чтение между мастерами и слейвами.
Мы сделали поддержку на уровне продукта различных облачных объектных хранилищ: google storage, amazon s3, — плюс, поддержка open stack swift. Поэтому это было удобно и для нас как для сервиса, и для разработчиков, которые работают с коробочным решением: если они используют просто наш api для работы, они не задумываются, где в итоге файл сохранится, локально на файловой системе или попадёт в объектное файловое хранилище.
В итоге мы сразу решили, что будем резервироваться на уровне целого дата-центра. В 2012 году мы запускались полностью в Amazon AWS, потому что у нас уже был опыт работы с этой платформой — наш собственный сайт там размещался. Нас привлекало то, что в каждом регионе в Amazon«e есть несколько зон доступности — по сути, (в их терминологии) несколько дата-центров, которые более-менее друг от друга независимы и позволяют нам резервироваться на уровне целого дата-центра: если он вдруг выходит из строя, базы реплицируются master-master, серверы веб-приложений зарезервированы, а статика вынесена в объектное хранилище s3. Нагрузка балансируется — на тот момент амазоновским elb, но чуть позже мы пришли к собственным балансировщикам, потому что нам нужна была более сложная логика.
Что хотели — то и получили…
Все базовые вещи, которые мы хотели обеспечить — отказоустойчивость самих серверов, веб-приложений, баз данных — все работало хорошо. Самый простой сценарий: если у нас выходит из строя какое-то из веб-приложений, то тут всё просто — они выключаются из балансировки.

Вышедшие из строя машины балансировщик (тогда это был амазоновский elb) сам помечал unhealthy, выключал распределение нагрузки на них. Работал амазоновский автоскейлинг: когда нагрузка вырастала, добавлялись новые машины в автоскейлинг-группу, нагрузка распределялась на новые машины — всё было хорошо. С нашими балансировщиками логика примерна та же самая: если что-то случается с сервером приложений, мы убираем с него запросы, выкидываем эти машины, стартуем новые и продолжаем работать. Схема за все эти годы немножко менялась, но продолжает работать: она простая, понятная, и никаких сложностей с этим нет.
Мы работаем по всему миру, пики нагрузки у клиентов абсолютно разные, и, по-хорошему, мы должны иметь возможность проводить те или иные сервисные работы с любыми компонентами нашей системы в любое время — незаметно для клиентов. Поэтому мы имеем возможность выключить из работы базу данных, перераспределив нагрузку на второй дата-центр.
Как это все работает? — Трафик мы переключаем на работающий дата-центр — если это авария на дата-центре, то полностью, если это наши плановые работы с какой-то одной базой, то мы часть трафика, обслуживающего этих клиентов, переключаем на второй дата-центр, приостанавливается репликация. Если нужны новые машины для веб-приложений, так как выросла нагрузка на втором дата-центре, они автоматом стартуют. Работы заканчиваем, репликация восстанавливается, и мы возвращаем всю нагрузку назад. Если нам надо зеркально провести какие-то работы во втором ДЦ, например, установить системные обновления или изменить настройки во второй базе данных, то, в общем, повторяем всё то же самое, просто в другую сторону. А если это авария, то мы делаем всё банально: в системе мониторинга используем механизм event-handlers. Если у нас срабатывает несколько проверок и статус переходит в critical, то у нас запускается этот handler, обработчик, который может выполнить ту или иную логику. У нас для каждой базы прописано, какой сервер является для нее failover«ом, и куда нужно переключить трафик в случае её недоступности. Мы — так исторически сложилось — используем в том или ином виде nagios или какие-либо его форки. В принципе, подобные механизмы есть практически в любой системе мониторинга, что-то более сложное мы пока не используем, но возможно когда-то будем. Сейчас мониторинг срабатывает на недоступность и имеет возможность что-то переключить.
Все ли мы зарезервировали?
У нас много клиентов из США, много клиентов из Европы, много клиентов, которые ближе к Востоку — Япония, Сингапур и так далее. Разумеется, огромная доля клиентов в России. То есть работа далеко не в одном регионе. Пользователям хочется быстрого отклика, есть требования по соблюдению различных локальных законов, и внутри каждого региона мы резервируемся на два дата-центра, плюс есть какие-то дополнительные сервисы, которые, опять же, удобно размещать внутри одного региона — для клиентов, которые в этом регионе работают. Обработчики REST, серверы авторизации, они менее критичны для работы клиента в целом, по ним можно переключаться с небольшой приемлемой задержкой, но не хочется изобретать велосипеды, как их мониторить и что с ними делать. Поэтому по максимуму мы пытаемся использовать уже существующие решения, а не развивать у себя какую-то компетенцию по дополнительным продуктам. И где-то мы банально используем переключение на уровне dns, причем живость сервиса определяем тем же самым dns. В Amazon есть сервис Route 53, но это не просто dns, в который можно записи внести и всё, — он гораздо более гибкий и удобный. Через него можно построить гео-распределённые сервисы с геолокациями, когда вы с его помощью определяете, откуда пришёл клиент, и даёте ему те или иные записи — с его помощью можно построить failover-архитектуры. Те же самые health-checks настраиваются в самом Route 53, вы задаёте endpoint, которые мониторятся, задаёте метрики, задаёте, по каким протоколам определять «живость» сервиса — tcp, http, https; задаёте периодичность проверок, определяющих, сервис живой или нет. И в самом dns прописываете, что будет primary, что будет secondary, куда переключаться, если срабатывает health-check внутри route 53. Всё это можно сделать какими-то другими инструментами, но чем это удобно — один раз настроили и потом вообще не думаем о том, как у нас делаются проверки, как у нас идёт переключение: всё работает само.
Первое «но»:, а как и чем резервировать сам route 53? Мало ли, вдруг с ним что-то случится? Мы, к счастью, ни разу на эти грабли не наступали, но опять же, впереди у меня будет рассказ, почему мы задумывались, что всё-таки резервировать надо. Здесь мы стелем себе соломку заранее. Несколько раз в сутки мы делаем полную выгрузку всех зон, которые у нас в route 53 заведены. API Amazon’a позволяет их спокойно отдавать в JSON, и у нас поднято несколько резервных серверов, куда мы это конвертируем, выгружаем в виде конфигов и имеем, грубо говоря, бэкапную конфигурацию. В случае чего мы можем быстро развернуть её вручную, не потеряем данные настроек dns.
Второе «но»: что в этой картине ещё не зарезервировано? Сам балансировщик! У нас распределение клиентов по регионам сделано очень просто. У нас есть домены bitrix24.ru, bitrix24.com, .de — сейчас их штук 13 разных, которые работают по самым разным зонам. Мы пришли к следующему: в каждом регионе — свои балансировщики. Так удобнее распределять по регионам, в зависимости от того, какая где пиковая нагрузка по сети. Если это сбой на уровне какого-то одного балансировщика, то он просто выводится из эксплуатации и убирается из dns. Если происходит какая-то проблема с группой балансировщиков, то они резервируются на других площадках, и переключение между ними делается с помощью той же самой route53, потому что за счет короткого ttl переключение происходит максимум в течение 2, 3, 5 минут.
Третье «но»: что еще не зарезервировано? S3, правильно. Мы, размещая файлы, которые храним у пользователей в s3, — искренне верили, что он бронебойный и ничего там резервировать не надо. Но история показывает, что происходит по-другому. Вообще, Amazon описывает S3 как фундаментальный сервис, потому что сам Amazon использует S3 для хранения образов машин, конфигов, образов AMI, снэпшотов… И если падает s3, как это однажды случилось за эти 7 лет, сколько мы bitrix24 эксплуатируем, он за собой веером тянет кучу всего — недоступность старта виртуалок, сбой в работе api и так далее.
И упасть S3 может — так случилось однажды. Поэтому мы пришли к следующей схеме: ещё несколько лет назад серьёзных объектных публичных хранилищ в России не было, и мы рассматривали вариант делать что-то своё… К счастью, мы этого делать не начали, потому что закопались бы в ту экспертизу, которой мы не обладаем, и наверняка накосячили бы. Сейчас s3-совместимые хранилища есть у Mail.ru, есть у Яндекса, есть еще у ряда провайдеров. Мы в итоге пришли к мысли, что хотим иметь, во-первых, резервирование, во-вторых, возможность работы с локальными копиями. Для конкретно российского региона мы используем сервис Mail.ru Hotbox, который по api совместим с s3. Нам не потребовалось каких-то серьёзных доработок по коду внутри приложения, и мы сделали следующий механизм: в s3 есть триггеры, которые срабатывают на создание/удаление объектов, у Amazon есть такой сервис, как Лямбда — это serverless запуска кода, который выполнится как раз при срабатывании тех или иных триггеров.
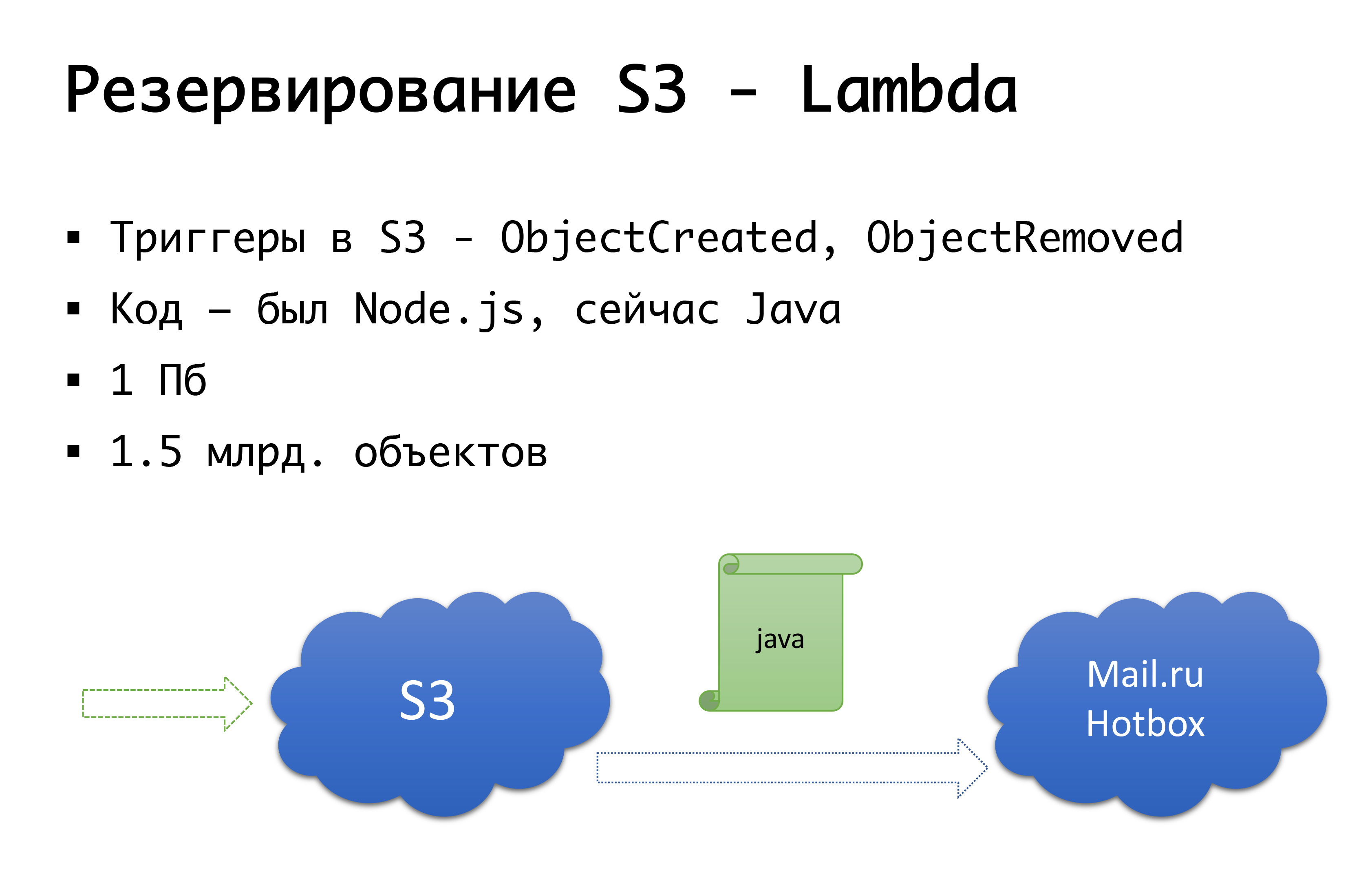
Мы сделали очень просто: если у нас срабатывает триггер, мы выполняем код, который скопирует объект в хранилище Mail.ru. Чтобы полноценно запустить работу с локальными копиями данных, нам нужна ещё обратная синхронизация, чтобы клиенты, которые находятся в российском сегменте, могли работать с хранилищем, которое к ним ближе. Mail вот-вот доделает триггеры у себя в хранилище — можно будет уже на уровне инфраструктуры исполнять обратную синхронизацию, пока же мы это делаем на уровне нашего собственного кода. Если мы видим, что клиент разместил какой-то файл, то мы у себя на уровне кода помещаем событие в очередь, обрабатываем его и делаем обратную репликацию. Чем она плоха: если у нас происходит какая-то работа с нашими объектами вне нашего продукта, то есть какими-то внешними средствами, мы это не учтём. Поэтому мы ждём до конца, когда появятся триггеры на уровне хранилища, чтобы независимо от того, откуда мы выполнили код, объект, который к нам попал, копировался в другую сторону.
На уровне кода у нас для каждого клиента прописываются оба хранилища: одно считается основным, другое бэкапным. Если всё хорошо, мы работаем с тем хранилищем, которое к нам ближе: то есть наши клиенты, которые в Amazon, они работают с S3, а те, кто работает в России, они работают с Hotbox. Если срабатывает флажок, то у нас должен подключиться failover, и мы клиентов переключаем на другое хранилище. Мы этот флажок можем ставить независимо по регионам и можем их туда-сюда переключать. На практике еще этим не пользовались, но механизм этот предусмотрели и думаем, что когда-то нам это самое переключение понадобится и пригодится. Один раз это уже случилось.
Ой, а у вас Amazon сбежал…
В этом апреле — годовщина начала блокировок Телеграмм в России. Самый пострадавший провайдер, который под это попал, — Amazon. И, к сожалению, больше пострадали российские компании, которые работали на весь мир.
Если компания глобальная и Россия для неё — совсем маленький сегмент, 3–5% — ну, так или иначе, можно ими пожертвовать.
Если это сугубо российская компания — я уверен, что нужно размещаться локально — ну просто самим пользователям будет удобно, комфортно, рисков будет меньше.
А если это компания, которая работает глобально, и у неё примерно поровну клиентов из России, и где-то по миру? Связность сегментов важна, и работать друг с другом они так или иначе должны.
Ещё в конце марта 2018-го Роскомнадзор направил самым большим операторам письмо, о том, что они планируют заблокировать несколько миллионов ip Amazon, для того чтобы заблокировать… мессенджер Zello. Спасибо этим самым провайдерам — они письмо успешно всем слили, и возникло понимание, что связность c Amazon может развалиться. Это была пятница, мы в панике прибежали к коллегам из servers.ru, со словами: «Друзья, нам нужно несколько серверов, которые будут стоять не в России, не в Amazon, а, например, где-нибудь в Амстердаме», для того чтобы иметь возможность хотя бы каким-нибудь образом поставить там собственные vpn и proxy для каких-то endpoint’ов, на которые мы никак не можем влиять, например endpont’ы того же s3 — нельзя попытаться поднять новый сервис и получить другой ip, нам все равно нужно туда достучаться. За несколько дней мы эти серверы настроили, подняли, и в общем, к моменту начала блокировок подготовились. Любопытно, что РКН, посмотрев на шумиху и поднятую панику, сказал: «Не, мы сейчас блокировать ничего не будем». (Но это ровно до того момента, когда начали блокировать телеграм.) Настроив возможности обхода и поняв, что блокировку не ввели, мы, тем не менее, не стали все это дело разбирать. Так, на всякий случай.

И вот в 2019 году мы таки живём в условиях блокировок. Я вот вчера ночью смотрел: около миллиона ip продолжают блокироваться. Правда, Amazon почти в полном составе разблокировали, в пике доходило до 20 миллионов адресов… В общем, реальность такова, что связности, хорошей связности — ее может не быть. Внезапно. Ее может не быть по техническим причинам — пожары, экскаваторы, всё такое. Или, как мы видели, не совсем техническим. Поэтому кто-то большой и крупный, с собственными AS-ками, наверное, может этим рулить другими путями, — direct connect и прочие вещи уже на уровне l2. Но в простом варианте, как мы или еще помельче, можно на всякий случай иметь резервирование на уровне серверов, поднятых где-то еще, настроенных заранее vpn, proxy, с возможностью быстро на них переключать конфигурацию в тех сегментах, которые у вас критичны по связности. Это нам пригодилось неоднократно, когда начались блокировки Amazon, мы через них пускали в самом худшем случае как раз трафик S3, но постепенно все это разрулилось.
А как резервировать… целого провайдера?
Сейчас сценария на случай выхода из строя всего Amazon у нас нет. У нас похожий сценарий есть для России. Мы в России размещались у одного провайдера, у которого мы выбирали, чтобы было несколько площадок. И год назад мы столкнулись с проблемой: даже несмотря на то, что это два дата-центра, уже на уровне конфигурации сети провайдера могут быть проблемы, которые затронут все равно оба дата-центра. И мы можем получить недоступность на обеих площадках. Конечно, так и случилось. Мы в итоге пересмотрели архитектуру внутри. Она не очень сильно изменилась, но для России у нас сейчас две площадки, которые не у одного провайдера, а у двух разных. Если у одного что-то выйдет из строя, мы можем переключиться на другого.
Гипотетически мы для Amazon рассматриваем возможность резервировать на уровне другого провайдера; может быть, Google, может быть, еще кто-то… Но пока мы наблюдали на практике, что если у Amazon аварии на уровне одной availability-зоны случаются, то аварии на уровне целого региона — достаточно редкое явление. Поэтому мы теоретически имеем представление о том, что мы, может быть, сделаем резервирование «Amazon — не Amazon», но на практике такого пока нет.
Пара слов про автоматизацию
Всегда ли нужна автоматика? Тут уместно вспомнить эффект Даннинга-Крюгера. По оси «х» наши знания и опыт, которого мы набираемся, а по оси «у» — уверенность в наших действиях. Мы сначала не знаем ничего и совсем не уверены. Затем мы знаем немножко и становимся мега-уверенными — это так называемый «пик глупости», хорошо иллюстрируется картинкой «слабоумие и отвага». Дальше мы уже немножко научились и готовы идти в бой. Потом мы наступаем на какие-то мега-серьёзные грабли, попадаем в долину отчаяния, когда вроде что-то знаем, а на самом деле мы многого не знаем. Затем, по мере набора опыта, становимся уже более уверенными.
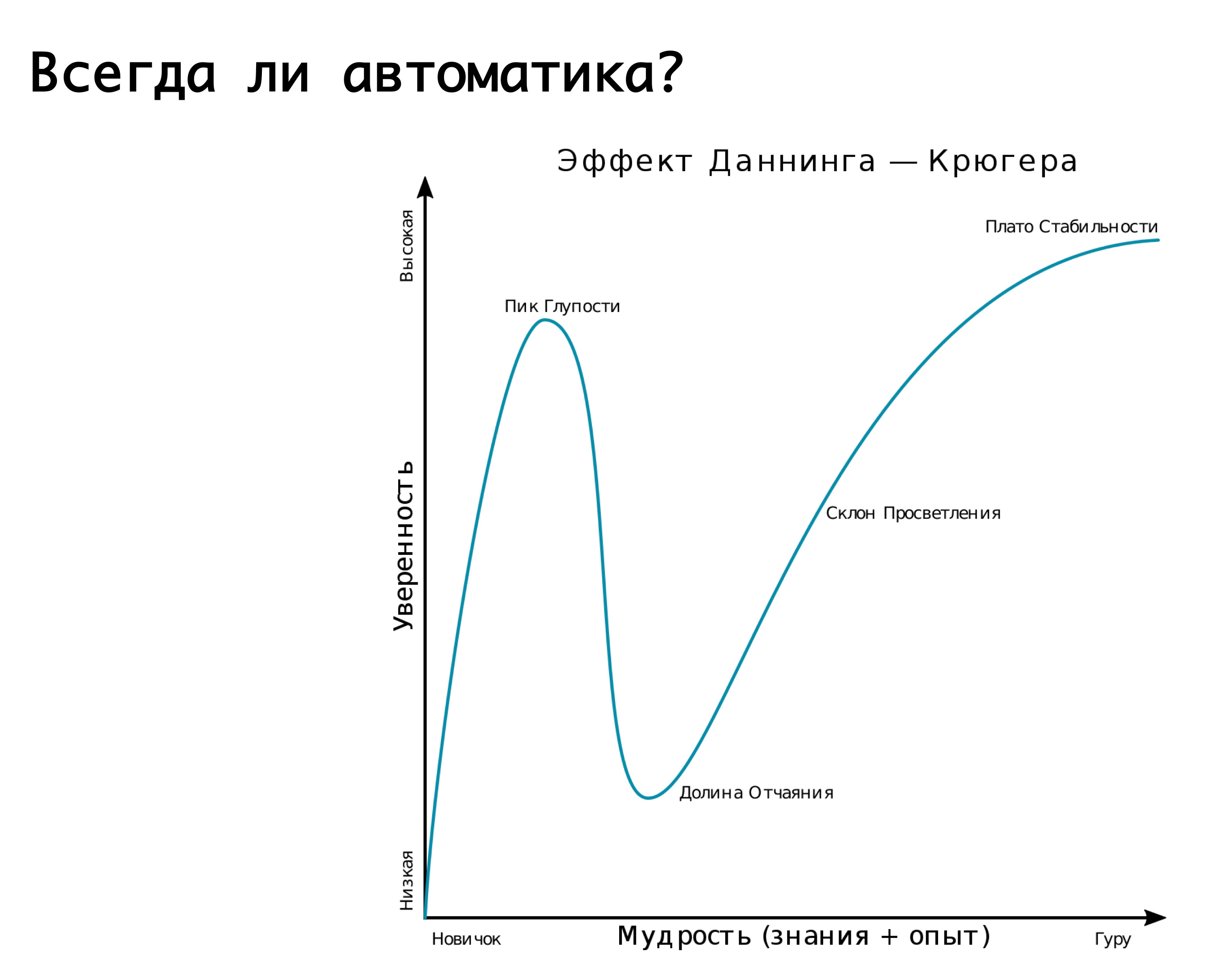
Наша логика про различные переключения автоматически на те или иные аварии — она очень хорошо описывается этим графиком. Мы стартовали — мы ничего не умели, практически все работы производились вручную. Потом мы поняли, что можно на всё навесить автоматику и, типа, спать спокойно. И вдруг мы наступаем на мега-грабли: у нас срабатывает false positive, и мы переключаем туда-сюда трафик, когда, по-хорошему, не стоило этого делать. Следовательно, ломается репликация или ещё что-нибудь — вот та самая долина отчаяния. А дальше приходим к пониманию, что ко всему надо относиться с умом. То есть имеет смысл положиться на автоматику, предусмотрев возможность ложного срабатывания. Но! если последствия могут быть разрушительными, то лучше отдать это на откуп дежурной смене, дежурным инженерам, которые убедятся, проследят, что действительно авария, и необходимые действия выполнят вручную…
Заключение
За 7 лет мы прошли путь от того, что, когда что-то падало, — была паника-паника, к пониманию, что проблем не существует, есть только задачи, их необходимо — и можно — решать. Когда вы строите какой-то сервис, посмотрите на него взглядом сверху, оцените все риски, которые могут случиться. Если вы сразу видите их — то заранее предусматривайте резервирование и возможность построения отказоустойчивой инфраструктуры, потому что любая точка, которая может выйти из строя и привести к неработоспособности сервиса — она обязательно это сделает. И даже если вам кажется, что какие-то элементы инфраструктуры точно не выйдут из строя — типа того же s3, всё равно имейте в виду, что они могут. И хотя бы в теории имейте представление о том, что вы будете с ними делать, если что-то все-таки случится. Имейте план по отработке рисков. Когда вы задумываетесь о том, чтобы делать все автоматикой или вручную, — оцените риски: что будет, если автоматика начнёт все переключать — не приведёт ли это к ещё худшей картине по сравнению с аварией? Возможно, где-то нужно использовать разумный компромисс между использованием автоматики и реакцией дежурного инженера, который оценит реальную картину и поймёт, нужно ли с ходу что-то переключить или «да, но не сейчас».
Разумный компромисс между перфекционизмом и реальными силами, временем, деньгами, которые вы можете потратить на ту схему, которая у вас в итоге будет.
Данный текст является дополненной и расширенной версией доклада Александра Демидова на конференции Uptime day 4.
