Безопасность алгоритмов машинного обучения. Защита и тестирование моделей с использованием Python

В рамках предыдущей статьи мы рассказали про такую проблему машинного обучения, как Adversarial примеры и некоторые виды атак, которые позволяют их генерировать. В данной статье речь пойдет об алгоритмах защиты от такого рода эффекта и рекомендациях по тестированию моделей.
Защита
Прежде всего давайте сразу поясним один момент — полностью защититься от такого эффекта невозможно, и это вполне естественно. Ведь если бы мы решили проблему Adversarial примеров полностью, то мы бы параллельно решили проблему построения идеальной гиперплоскости, что, естественно, невозможно сделать, не имея генеральной совокупности данных.
Защищать модель машинного можно на двух этапах:
Обучения — мы обучаем наш алгоритм правильно реагировать на Adversarial примеры.
Эксплуатации — мы пытаемся детектировать Adversarial пример на этапе эксплуатации модели.
Сразу стоит сказать, что работать с методами защиты, представленными в данной статье можно с помощью библиотеки Adversarial Robustness Toolbox от компании IBM.
Adversarial Training

Если задать человеку, только что познакомившемуся с проблемой Adversarial примеров, вопрос: «Как же защититься от данного эффекта?», то непременно 9 из 10 человек скажут: «Давайте добавим сгенерированные объекты в обучающую выборку». Такой подход сразу же был предложен в статье Intriguing properties of neural networks еще в 2013 году. Именно в этой статье и была впервые описана данная проблема и L-BFGS атака, позволяющая получить Adversarial примеры.
Этот метод очень прост. Мы генерируем Adversarial примеры с помощью разного рода атак и добавляем их в обучающую выборку на каждой итерации, тем самым повышая «сопротивляемость» модели Adversarial примерам.
Недостаток же данного метода достаточно очевиден: на каждой итерации обучения, на каждый пример мы можем сгенерировать очень большое количество примеров, соответственно, и время на обучение модели возрастает многократно.
Применить данный метод с использованием библиотеки ART-IBM можно следующим образом.
from art.defences.adversarial_trainer import AdversarialTrainer
trainer = AdversarialTrainer(model, attacks)
trainer.fit(x_train, y_train)
Gaussian Data Augmentation
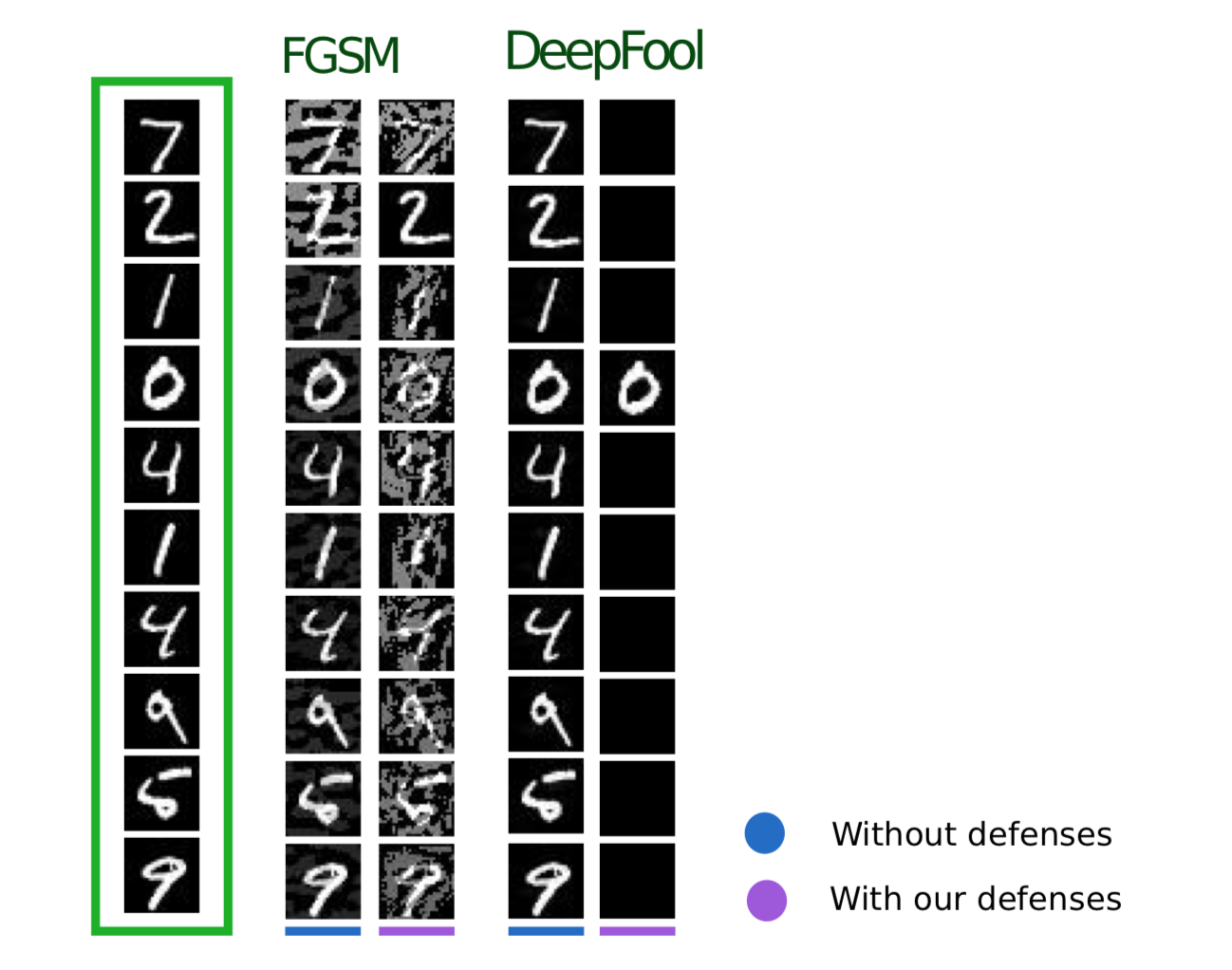
Следующий метод, описанный в статье Efficient Defenses Against Adversarial Attacks, использует похожую логику: он тоже предлагает добавлять в обучающую выборку дополнительные объекты, но в отличие от Adversarial Training эти объекты не Adversarial примеры, а немного зашумленные объекты обучающей выборки (в качестве шума используется Гауссовский шум, отсюда и название метода). И, действительно, это кажется очень логичным, ведь основная проблема моделей — это именно плохая устойчивость к шумам.
Данный метод показывает схожие с Adversarial Training результаты, затрачивая при этом гораздо меньше времени на генерирование объектов для обучения.
Применить данный метод можно с помощью класса GaussianAugmentation в ART-IBM
from art.defences.gaussian_augmentation import GaussianAugmentation
GDA = GaussianAugmentation()
new_x = GDA(x_train)
Label Smoothing
Метод Label Smoothing очень прост в реализации, но тем не менее несет в себе достаточно много вероятностного смысла. Мы не будем вдаваться в подробности вероятностной интерпретации данного метода, его вы сможете найти в исходной статье Rethinking the Inception Architecture for Computer Vision. Но, если сказать об этом кратко, то Label Smoothing является дополнительным видом регуляризации модели в задаче классификации, что делает ее более устойчивой к шумам.
По факту же данный метод сглаживает метки классов. Делая их, скажем, не 1, а 0.9. Тем самым модели при обучении штрафуются за сильно большую «уверенность» в метке для конкретного объекта.
Применение данного метода на Python можно увидеть ниже
from art.defences.label_smoothing import LabelSmoothing
LS = LabelSmoothing()
new_x, new_y = LS(train_x, train_y)
Bounded ReLU
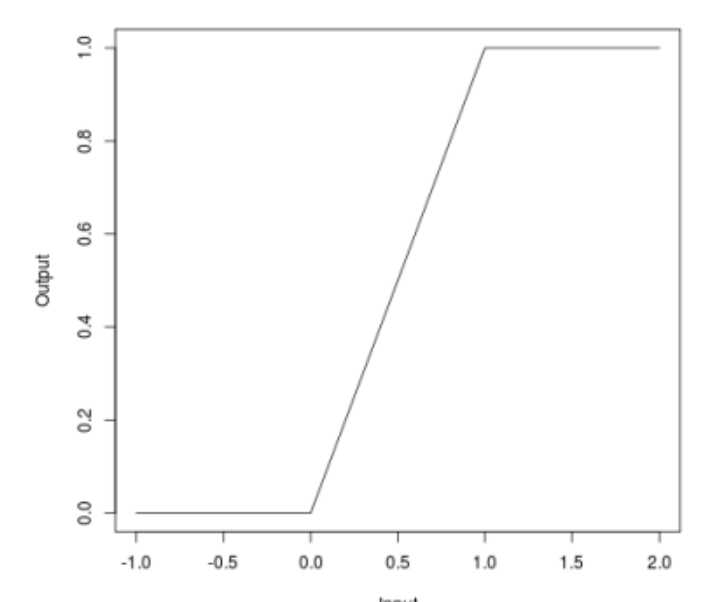
Когда мы говорили об атаках, многие могли заметить, что некоторые атаки (JSMA, OnePixel) зависят от того, насколько сильный градиент в той или иной точке входного изображения. C этой задачей пытается бороться простой и «дешевый» (в плане вычислительных и временных затрат) метод Bounded ReLU.
Суть метода в следующем. Давайте заменим функцию активации ReLU в нейронной сети на такую же, но ограниченную не только снизу, но и сверху, тем самым мы сгладим карты градиентов, и в конкретных точках нельзя будет получить всплеск, что не позволит, изменив один пиксель изображения, обмануть алгоритм.

\begin{equation*}f (x)=
\begin{cases}
0, x
\\
x, 0 \leq x \leq t
\\
t, x>t
\end{cases}
\end{equation*}
Данный метод был также описан в статье Efficient Defenses Against Adversarial Attacks
Построение Ансамблей Моделей
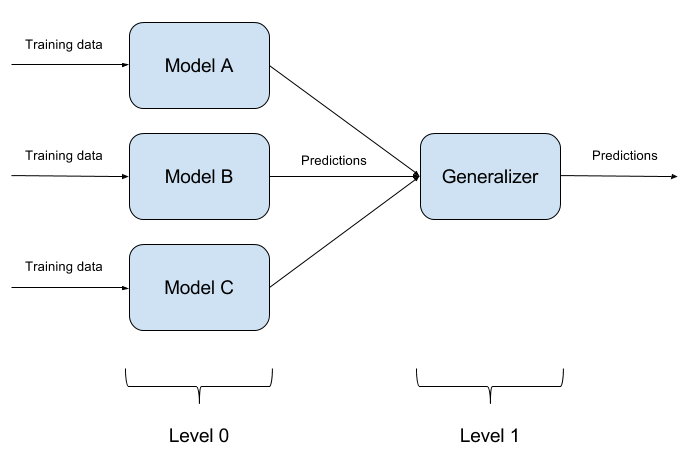
Не составляет труда обмануть одну обученную модель. Обмануть две модели одновременно одним объектом еще труднее. А если таких моделей N? Именно на этом основан метод ансамблирования моделей. Мы просто строим N разных моделей и агрегируем их выход в единый ответ. Если модели представлены еще и разными алгоритмами, то обмануть такую систему хоть и возможно, но крайне трудно!
Совершенно естественно, что реализация ансамблей моделей это чисто архитектурный подход, задающий множество вопросов (Какие базовые модели брать? Как агрегировать выходы базовых моделей? Есть ли зависимость между моделями? и тд.). Именно по этой причине данный подход не реализован в ART-IBM
Feature squeezing
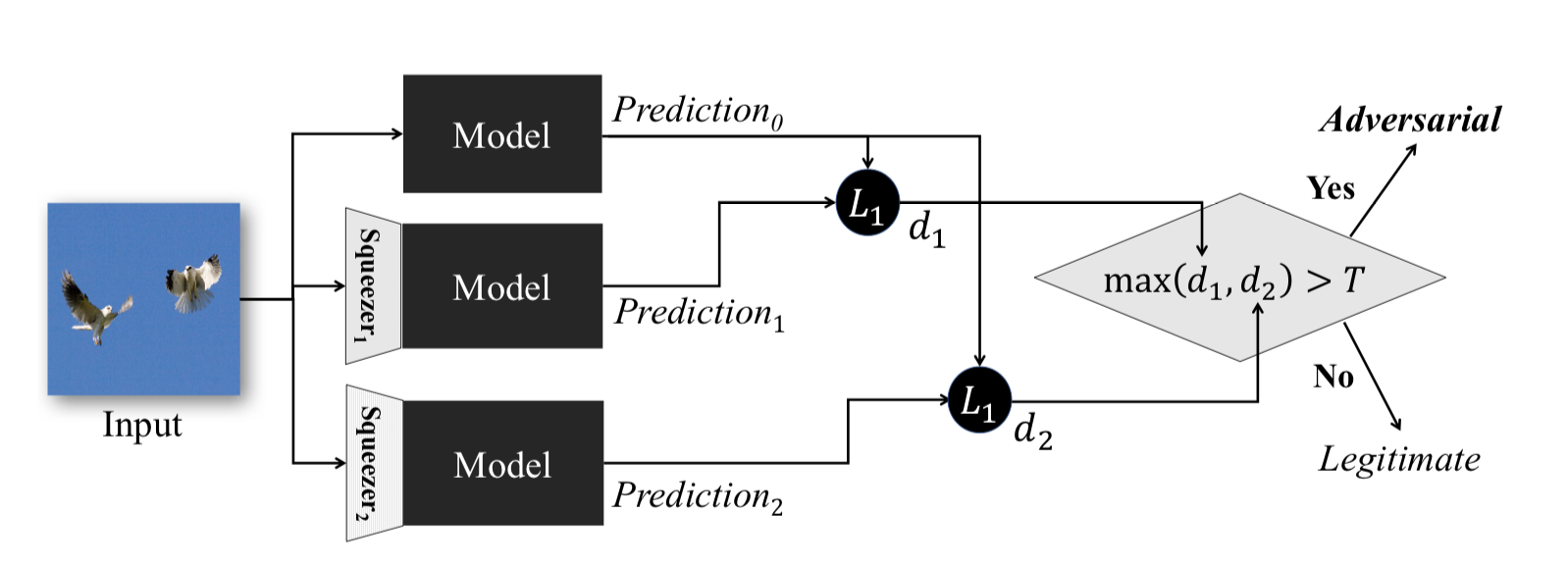
Данный метод, описанный в статье Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks, работает на этапе эксплуатации модели. Он позволяет детектировать Adversarial примеры.
Идея, стоящая за этим методом, следующая: если обучить n моделей на одних и тех же данных, но разной степени сжатия, то результаты их работы будут все равно схожи. При этом Adversarial пример, который сработает на исходной сети, с высокой долей вероятности провалится на дополнительных сетях. Тем самым, посчитав попарную разницу выходов исходной нейронной сети и дополнительных, выбрав из них максимум и сравнив его с заранее подобранным порогом, мы сможем утверждать, что объект, подающийся на вход, либо Adversarial, либо абсолютно валидный.
Ниже представлен метод, позволяющий получить сжатые объекты с помощью ART-IBM
from art.defences.feature_squeezing import FeatureSqueezing
FS = FeatureSqueezing()
new_x = FS(train_x)
На этом мы закончим с методами защиты. Но было бы неправильно не уяснить один важный момент. Если у злоумышленника не будет доступа к входу и выходу модели, он не будет понимать, как «сырые» данные обрабатываются внутри вашей системы перед входом в модель. Тогда и только тогда все его атаки будут сводиться к случайному перебору входных значений, что естественно маловероятно приведет к желаемому результату.
Тестирование
Теперь давайте поговорим о тестировании алгоритмов на предмет противодействия Adversarial примерам. Здесь прежде всего необходимо понять, как мы будем тестировать нашу модель. Если мы предполагаем, что каким-либо путем злоумышленник может получить полный доступ ко всей модели, тогда тестировать нашу модель необходимо методами WhiteBox атак.
В другом случае мы предполагаем, что злоумышленник никогда не получит доступ к «внутренностям» нашей модели, однако при этом сможет, хоть и косвенно, но влиять на входные данные и видеть результат работы модели. Тогда следует применять методы BlackBox атак.
Общий алгоритм тестирования можно описать следующим примером:
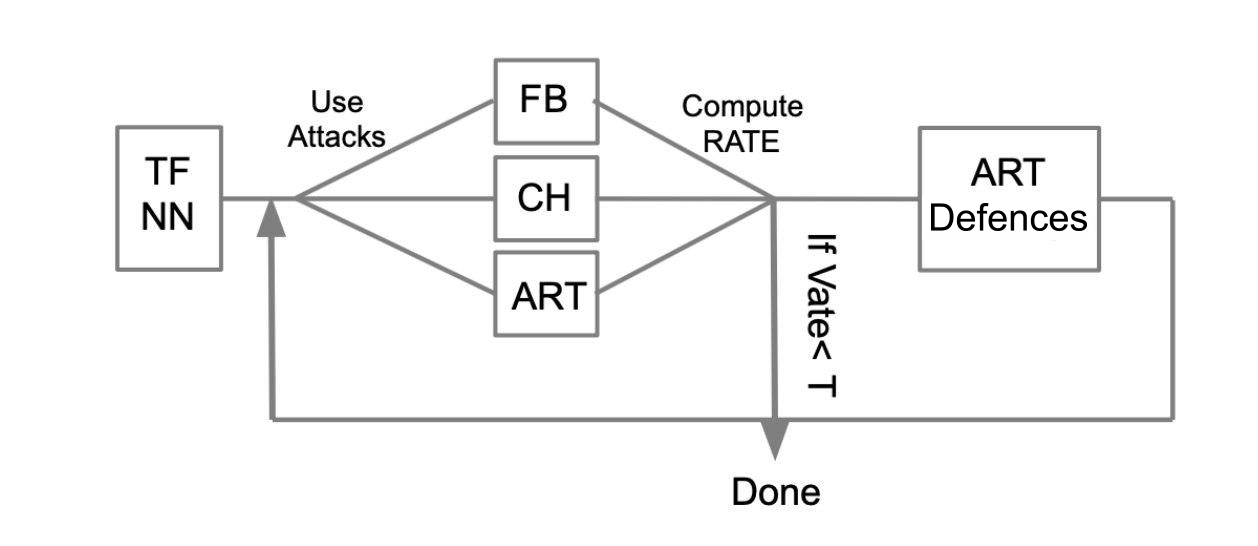
Пускай имеется обученная нейронная сеть, написанная на TensorFlow (TF NN). Мы экспертно утверждаем, что наша сеть может попасть в руки злоумышленника, путем проникновения в систему, где находится модель. В таком случае нам необходимо проводить WhiteBox атаки. Для этого мы определяем пул атак и фреймворки (FoolBox — FB, CleverHans — CH, Adversarial robustness toolbox — ART), позволяющие эти атаки реализовать. После чего, посчитав то, сколько атак были успешными, подсчитываем Succes Rate (SR). Если SR нас устраивает, заканчиваем тестирование, иначе применяем один из способов защиты, например реализованные в ART-IBM. После чего опять проводим атаки и считаем SR. Делаем данную операцию циклично, до тех пор, пока SR не будет нас устраивать.
Выводы
На этом хотелось бы закончить с общей информацией про атаки, защиты и тестирование моделей машинного обучения. Подводя итог двух статей, можно заключить следующее:
- Не стоит верить в машинное обучение как в некое чудо, способное решить все ваши проблемы.
- Применяя алгоритмы машинного обучения в своих задачах, подумайте о том, насколько данный алгоритм стойкий к такой угрозе как Adversarial примеры.
- Защищать алгоритм можно как со стороны машинного обучения, так и со стороны системы, в которой данная модель эксплуатируется.
- Тестируйте свои модели, особенно в случаях, когда результат работы модели напрямую влияет на принимаемое решение
- Такие библиотеки, как FoolBox, CleverHans, ART-IBM предоставляют удобный интерфейс для применения способов нападения и защиты моделей машинного обучения
Также в данной статье хотелось бы подвести итоги по работе с библиотеками FoolBox, CleverHans и ART-IBM:
FoolBox — простая и понятная библиотека для применения атак на нейронные сети, поддерживающая множество разных фреймворков.
CleverHans — библиотека, позволяющая проводить атаки изменяя множество параметров проводимой атаки, немного сложнее FoolBox, поддерживает меньше фреймворков.
ART-IBM — единственная библиотека из описанных выше, позволяющая работать с методами защиты, пока что поддерживает только TensorFlow и Keras, но развивающаяся быстрее остальных.
Здесь стоит сказать, что есть еще одна библиотека для работы с Adversarial примерами от компании Baidu, но, к сожалению, подойдет она только людям владеющим китайским языком.
В следующей статье на эту тему мы разберем часть задания, которое предлагалось решить в ходе ZeroNights HackQuest 2018 путем обмана типичной нейронной сети с использованием библиотеки FoolBox.
