Без денег, репликации и кеша: ограничиваем нагрузку на сервисы, используя подходы из TCP
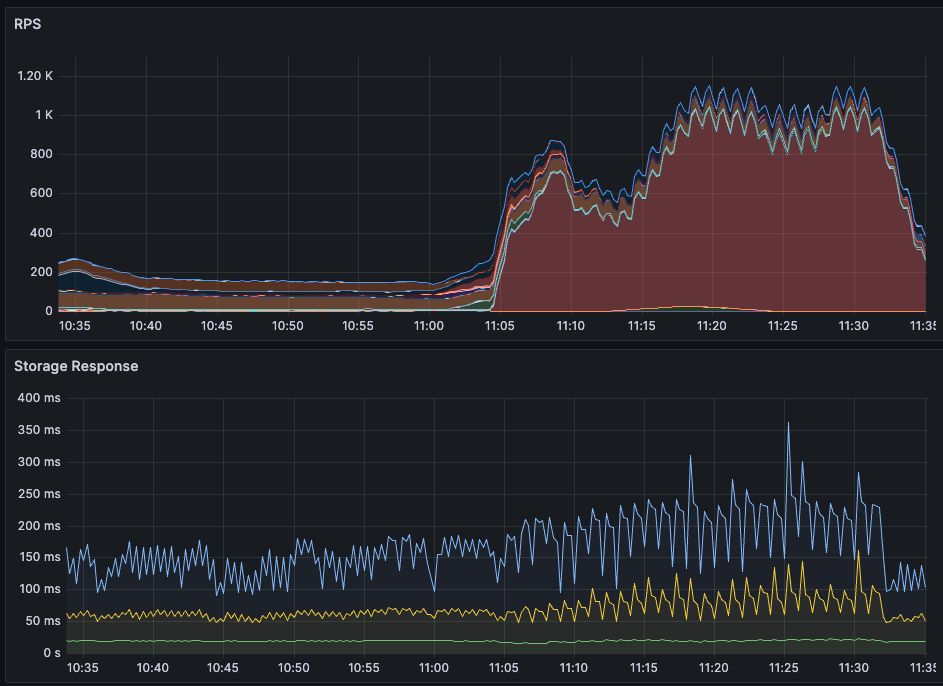
Ограничение в действии: RPS кратно растет, но время ответа базы не превышает установленного предела
При росте нагрузки одна из частей системы может подтормаживать. Часто уязвимым местом оказывается база данных. Так произошло и в нашем случае.
Я работаю в Mindbox в команде, которая отвечает за выдачу товарных рекомендаций. Наша база периодически деградировала, заливать ее деньгами (скейлить) не хотелось, а кешировать запросы не позволяла специфика данных.
В этой статье расскажу про комплексное решение, к которому мы пришли — динамически ограничивать конкурентные запросы и менять лимит в зависимости от времени ответа базы.
С чем работали
Mindbox — сервис для маркетологов. Одна из функций — подбор персональных рекомендаций: система анализирует активность пользователя и выбирает товары, которые могут его заинтересовать. Эти предложения лежат в базе данных.
В базу поступает два типа запросов: синхронные и асинхронные.
Синхронные. Например, пользователь зашел на сайт — должны подгрузиться рекомендованные товары. Такие запросы:
Создают невысокую и стабильную нагрузку — около 150 RPS.
Нужно обработать как можно скорее. Если ответ будет поступать за треть секунды — это уже плохо, ведь все это время пользователь ждет.
Отправляет пользователь — настроить логику их повторения нельзя.
Асинхронные. Например, интернет-магазин запускает рассылку на миллион клиентов, в письма подставляются рекомендованные товары. Они:
Создают большую нагрузку — до 8 тысяч RPS. И случается она периодически — 1–2 раза в день.
Можем обрабатывать долго. Даже если письма будут готовиться минуту, бизнес ничего не потеряет.
Отправляет внутренний сервис — можно настроить логику ретраев.

Как растет RPS к базе, когда большой клиент запускает рассылку с блоками рекомендации
Все запросы поступают в единую базу данных. С синхронными она справляется, но как только вместе с ними поступают и асинхронные, база «перегревается»: время ответа увеличивается втрое и синхронные запросы страдают.
Задача — добиться, чтобы асинхронные запросы не тормозили базу, а синхронные обрабатывались по-прежнему быстро. Для этого будем отбрасывать асинхронные запросы, которые выходят за лимит.
Почему не воспользовались стандартными методами
Мы сразу отмели простые способы решения проблемы:
Вертикально заскейлить (купить базу дороже и мощнее). Лишь на время скроем проблему: мы продолжим неоптимально использовать ресурсы и вскоре снова столкнемся с деградацией.
Сделать реплику базы и перекинуть на нее тяжелую нагрузку. Это дорого и усложняет работу — появляется еще одна база, которую нужно поддерживать, оплачивать, а за механизмом репликации нужно следить.
Кешировать данные. В нашем случае данные быстро обновляются: клиент зашел на страницу нового товара — рекомендации чуть изменились. На момент нового запроса кеш уже протухнет.
Есть еще два решения, которые происходят уже на уровне сервиса — ограничение по RPS (request per second) и статическое ограничение конкурентных запросов. От них также решили отказаться.
Ограничение по RPS
Суть метода: установить лимит — определенное число запросов, которые могут направляться в базу каждую секунду. Все запросы, не входящие в лимит, отклоняются или встают в очередь.
Это простой и распространенный способ, у большинства языков есть библиотеки для его реализации, а у некоторых он встроен в базовый фреймворк. Есть множество вариантов реализации, которые можно подбирать под задачу: token bucket, fixed window, sliding window etc.
У статического ограничения по RPS есть проблемы:
Отрезаем запросы, которые могли бы обработать. Например, если прилетает много «легких» запросов, база быстро их пережевывает и может взять еще, но лимит RPS израсходован и не пускает новые.
Отдаем много тяжелых запросов. Обратная ситуация: пришло много сложных запросов, мы пускаем их по лимиту, но база не справляется с таким количеством.
Сложности при скейлинге. Лимит задается разработчиком, поменять его можно только вручную. Настройки ограничения по RPS обычно лежат внутри сервиса, и их приходится подвязывать либо к количеству подов, либо к суммарной настройке RPS по всем инстансам. Оба варианта выглядят некрасиво и сложно, и обычно в них легко пропустить ошибку.
Статическое ограничение конкурентных запросов
Метод похож на ограничение по RPS, но учитывает не количество запросов в единицу времени, а количество одновременных запросов в базу. Ограничивать их просто — обычного семафора хватит.
Такой подход позволяет избежать ситуаций, когда мы отрезаем запросы, которые могли бы обработать, или отдаем много тяжелых запросов. Однако управлять количеством запросов по-прежнему нужно централизованно — писать сложный код, покрывающий непрозрачную логику, чтобы каждый инстанс приложения понимал, сколько ему положено держать запросов.
На практике это выражается в следующих сложностях:
Еще одна точка синхронизации. Что будет с сервисом, если эта точка не будет отвечать?
Запаздывание в системе. В идеальном случае ко времени ответа добавятся доли секунд, пока запрос летит от точки синхронизации до сервиса. Но чаще — период поллинга, измеряемый секундами.
Если нужно скейлить базу или сервисы приложения, настройку все равно придется подбирать на глаз.
Наш метод — динамическое ограничение конкурентных запросов
Для своей задачи мы решили менять количество конкурентных запросов, ноне отталкиваться от статичной цифры, а подстраиваться под время ответа базы. Ответы приходят быстро, мы увеличиваем лимит; база тормозит — уменьшаем. Такая система обратной связи позволяет выставить желаемое время отклика и поддерживать его.
Лимит в каждом инстансе независимо подстраивается под нагрузку. Благодаря этому нет необходимости в общей точке синхронизации при скейлинге сервиса или базы — система сама адаптируется под новые условия.
Для решения похожей проблемы уже есть специализированные алгоритмы. Они используются в TCP (Transmission Control Protocol) и называются congestion control algorithms. С их помощью предотвращают застой трафика в TCP-узле: разница здесь только в том, что вместо congestion window мы будем использовать количество одновременных запросов (concurrency). В разработку сервисов такие алгоритмы проникли не так давно, так как распределенные нагруженные системы — относительно новая вещь. Но у взрослых дядей уже можно увидеть подобное: например, стратегия ретраев s3 у Amazon, библиотека лимитера у Netflix, ограничение нагрузки на Active Directory у Microsoft.
Алгоритмов congestion control algorithms несколько. Самый распространенный — AIMD (Additive Increase Multiplicative Decrease). Он работает по следующему принципу: при каждом запросе проверяем, случилась ли перегрузка. Если нет, увеличиваем congestion window на a. Видим перегрузку — уменьшаем.
Формула ограничения конкурентных запросов:
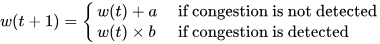
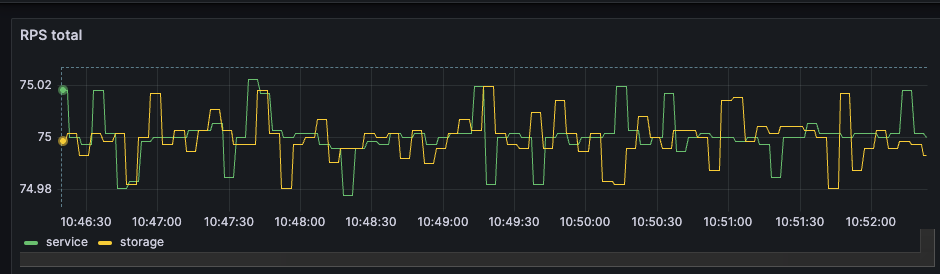
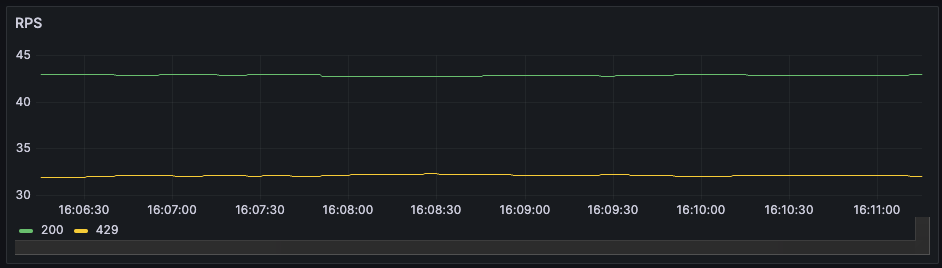
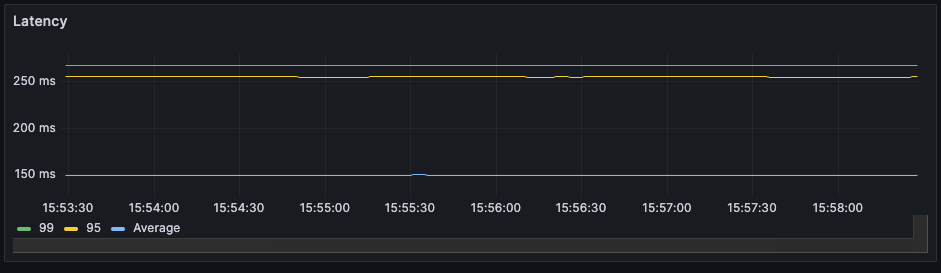
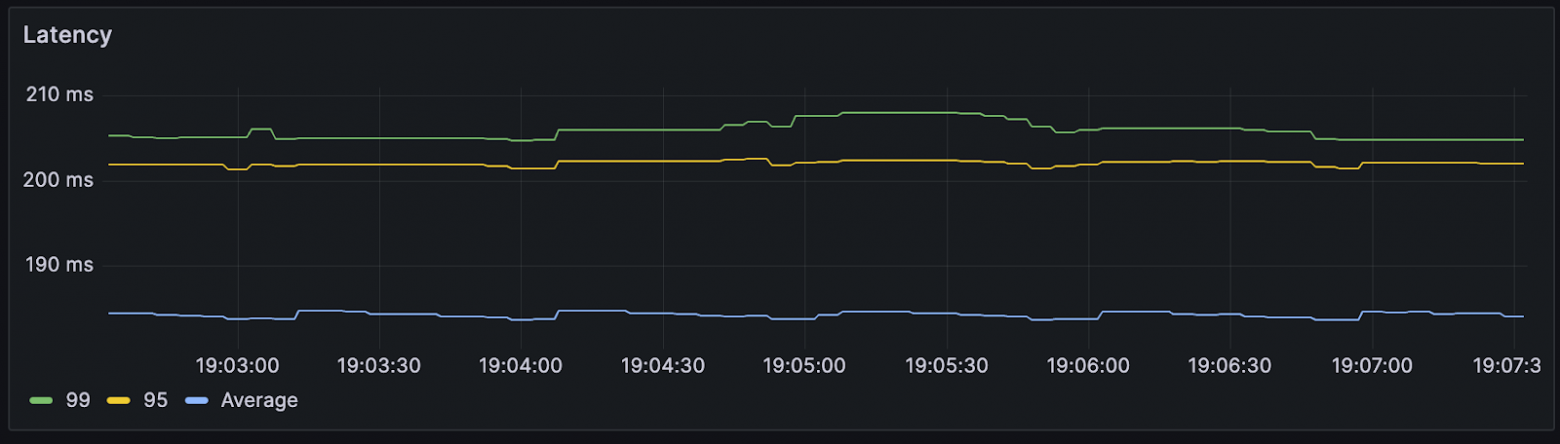
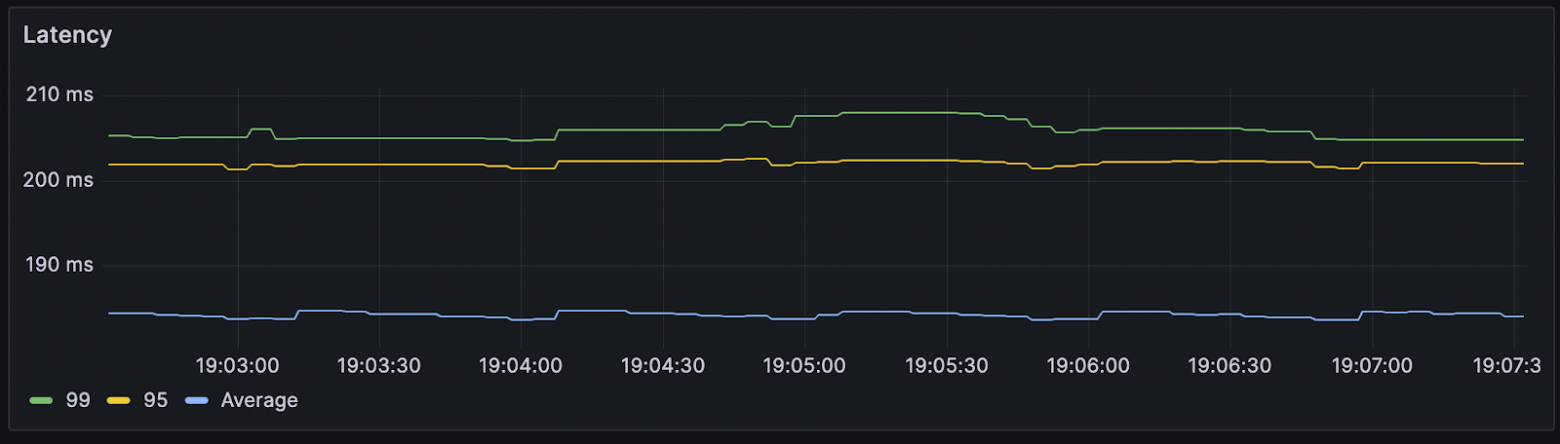
w (t) — размер пропускного окна в конкретный момент времени. Несмотря на элегантность решения, оно редко используется в разработке сервисов, а готовых библиотек, реализующих алгоритм, очень мало. У нас сервис на .NET и библиотек для него я не нашел, поэтому собрал решение сам. Для этого понадобилось: Написать логику, по которой меняется лимит подключений. Решение подсмотрел в библиотеке Netflix. Она написана понятно, с комментариями и описаниями, а кода относительно немного, потому реализовать то же самое не составит труда. Реализовать семафор с динамическим изменением емкости. С этим помог вклад некоего доброго человека в Polly.Contrib, который вкрутил динамический семафор прямо в BulkheadPolicy известной библиотеки Polly. Его код ещё можно причесывать, но он делает что нужно, и вполне исправно. Всё это получилось завести в проде и решить проблему деградации. В статье опишу запуск на тестовом полигоне и результаты, которые удалось воспроизвести. Результат, к которому пришли: при асинхронном запросе RPS растет, но при этом время ответа базы не превышает установленного предела Дано — хранилище, которое будет искусственно увеличивать время отклика от количества RPS. Допустим, будет базовый доступный RPS, и если текущий увеличится вдвое, время отклика тоже. Ситуация — в сервис летит 75 RPS. Сервис лезет в базу, после отдает данные клиенту. Задержка от базы при такой нагрузке — в районе 260 мс. Динамика RPS Время ответа Представим, что требование по времени отклика — 200 мс. То есть в текущей конфигурации мы выбиваемся. Добавим механизм ограничения. Для этого используем следующие настройки: MinConcurrency и MaxConcurrency — ограничение конкурентных запросов. Ставим ограничение снизу, потому что какое-то количество одновременных запросов сервис может прожевать (хотя бы 1). Ограничение сверху — сколько запросов мы согласны впускать в сервис. _maxLatency — максимальная задержка, допустимая при ответах. В нашем случае это 200 мс, о которых договорились выше. BackoffRatio — коэффициент, на который умножаем параллелизм при «пробитии» latency. В формуле ограничения конкурентных запросов это параметр b. Он определяет, во сколько раз сократится допустимое количество одновременных запросов. Значение все ставят по-разному: в TCP это 0,5 (т.е. уменьшение вдвое), в библиотеке Netflix — по умолчанию 0,9. Формула ограничения конкурентных запросов w (t) — размер пропускного окна в конкретный момент времени. В коде это выглядит следующим образом: В результате нагрузка на сервис по RPS та же, что и раньше, но до хранилища доходит от силы половина. Остальное возвращается клиенту в виде 429 ответа. Нагрузка на сервис и базу. Зеленым показана общая нагрузка на сервис, желтым — сколько запросов доходит до хранилища Разделение ответов. Зеленым — ответы на обработанные запросы, желтым — TooManyRequests (429) Задержка ответа от хранилища. Синим — средняя задержка, желтым и зеленым — 95 и 99 процентили соответственно Получившийся алгоритм работает, но в нем есть пара нюансов, которые хотелось бы поправить: Лимит — цифра «с потолка». Лимит в 200 мс, который мы поставили, — ни к чему не привязанная цифра. В нашем случае есть более весомое ограничение — SLA или обещания клиентам. По SLA, 95% запросов должны обрабатываться не дольше, чем n мс — от этого и нужно отталкиваться. Частая смена лимита. При каждом запросе мы проходим по алгоритму, чтобы понять, стоит ли менять лимит. При нагрузке в сотню RPS это становится неприятно. Станет лучше, если поправим логику и при расчете нового лимита будем отталкиваться от процентиля с последних n запросов. Например, мы хотим, чтобы 95% запросов выполнялись быстрее 200 мс. Добавив в расчет процентиль, мы получили мягкость изменений: это спасает от ситуаций, где, например, моргнувшая сеть привела к 10 подряд «просроченным» запросам, что опустит лимит до минимума. С учетом процентиля график ответа нашего сервиса будет выглядеть уже так: График с ограничением 200 мс на 95 процентиль Если долго нет нагрузки, база отвечает быстро, и изменяемый лимит улетает в потолок. Мы рискуем в какой-то момент впустить слишком много запросов, и база ляжет. Чтобы такого не было, при увеличении лимита стоит проверять, утилизируется ли количество запросов, разрешенное сейчас: Конечный алгоритм расчета нового лимита будет выглядеть примерно так: ➡️ Репозиторий, чтобы посмотреть, как все это собрано, и запустить лимитер в песочнице. Динамическое ограничение конкурентных запросов — не универсальное решение. Например, стоит учитывать следующие негативные эффекты, которые могут возникнуть. Подход с динамическим изменением лимита работает отлично при скейлинге, когда лимит запросов от конкретного инстанса зависит только от того, как быстро отвечает база. Вот, например, добавление +2 инстансов в целом не влияет на задержку в ответах и RPS на хранилище. Скелинг сервиса до трех инстансов Изменение задержки при скейлинге сервисов (в 11:10 заскейлил до трех) Однако при этом надо быть аккуратным с настройкой MinConcurrency — она должна быть достаточно низкой для максимального количества инстансов. То есть если в вашем сервисе minConcurrency=40, а инстансов 20, то общий минимальный concurrency на систему уже 800. База может этого не ожидать. Недостаток процентиля в том, что лимит уменьшается уже постфактум — когда граница уже «пробита». Потому лимит стоит всегда ставить чуть ниже критичного. Реальное значение процентиля превышает на пару мс то, что мы установили как цель (200 мс) Запись конференции StrangeLoop, где рассказывают про метод динамического ограничения конкурентных запросов. Библиотека Netflix. Из нее я частично позаимствовал реализацию. А еще в ней реализован не только AIMD, но и ряд других механизмов для ограничения concurrency, которых в этой статье нет. Статья о congestion control и почему он работает. Статья об AIMD в TCP протоколе.
a — на сколько увеличиваем этот размер в случае, если «не успели» с запросом.
b — множитель, уменьшающий общую нагрузку в случае слишком долгих запросов 0
Кейс: запуск на тестовом полигоне

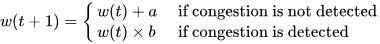
a — на сколько увеличиваем этот размер в случае, если «не успели» с запросом.
b — множитель, уменьшающий общую нагрузку в случае слишком долгих запросов 0public int Calculate(TimeSpan roundTimeTrip, int currentLimit, int inFlightRequests)
{
var newLimit = currentLimit;
if (roundTimeTrip > _maxLatency)
newLimit = (int)(1d * _settings.BackoffRatio * newLimit);
else
newLimit++;
var result = Math.Min(_settings.MaxConcurrency, Math.Max(newLimit, _settings.MinConcurrency));
return result;
}
Улучшим результат — добавим процентиль для плавности изменений
Проверка нагрузки, чтобы избыточно не повысить лимит
private static bool CorrectlyUtilized(int currentLimit, int inFlightRequests) =>
inFlightRequests * 2 + 1 >= currentLimit;Результат
public int Calculate(TimeSpan roundTimeTrip, int currentLimit, int inFlightRequests)
{
_lastRequests.Enqueue(roundTimeTrip);
var requests = GetRequestTimes();
if (requests.Length == 0)
return currentLimit;
var percentileLatency = CalculatePercentileLatency(requests, _settings.TargetPercentile);
var newLimit = currentLimit;
if (percentileLatency > _maxLatency)
newLimit = (int)(_settings.BackoffRatio * newLimit);
else if (CorrectlyUtilized(currentLimit, inFlightRequests))
newLimit++;
var result = Math.Min(_settings.MaxConcurrency, Math.Max(newLimit, _settings.MinConcurrency));
return result;
}Какие проблемы всплыли при запуске
Нюансы при автоскейлинге
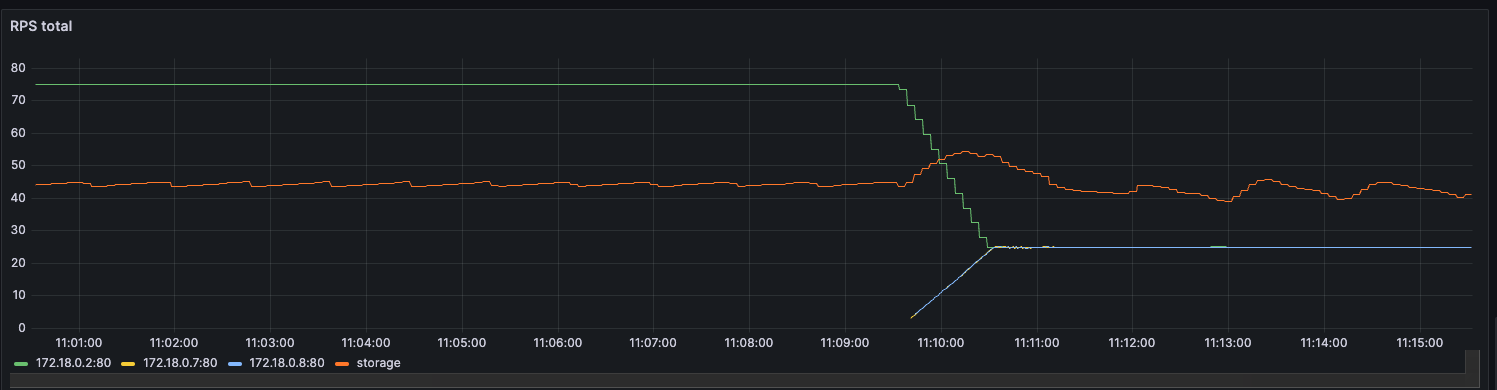

Время ответа периодически превышает лимит
Что помогло при внедрении
