Мультимодальный трансформер для content-based рекомендаций
На первый взгляд может показаться, что ничего интересного в области RecSys не происходит и там всё давно решено: собираем взаимодействия пользователей и товаров, закидываем в какую-нибудь библиотеку, которая реализует коллаборативную фильтрацию, и рекомендации готовы. В то же время практически все остальные разделы машинного обучения перешли (NLP, CV, Speech) или экспериментируют (TimeSeries, Tabular ML) c нейросетевыми моделями на базе трансформеров. На самом деле, рекомендательные системы — не исключение, и исследования по применению трансформеров ведутся уже достаточно давно.
Мы в команде ранжирования и рекомендаций, стараемся не отставать от последних достижений в области RecSys. Меня зовут Дима, я Data Scientist в Циан, и сегодня хочу поделиться нашим опытом использования мультимодальных трансформеров для content-based рекомендаций.
Большинство подходов для рекомендаций основаны на использовании информации о взаимодействиях пользователей и товаров. Несмотря на то, что данные подходы хорошо себя показывают в различных доменах, большинство из них имеют несколько достаточно серьёзных недостатков, основным из которых является необходимость использования уникальных идентификаторов пользователей/товаров и вытекающая из этого необходимость повторного обучения моделей на новых товарах/интеракциях товаров и пользователей.
В эпоху победивших трансформеров, кажется странным, что всё ещё используются коллаборативные методы, например факторизации матриц, вместо трансформер-энкодеров, которые принимали бы на вход описания товаров, с которыми провзаимодействовал пользователь, и выдавали эмбеддинг товара, который должен быть следующим.
Теоретически, такая модель была бы лишена недостатков методов, основанных на идентификаторах, и могла бы работать так же хорошо на товарах и пользователях, которых не было в обучающем датасете.
Немного поискав, мы нашли статью Text Is All You Need: Learning Language Representations for Sequential Recommendation. Авторы предлагают представлять товар как совокупность его атрибутов, а пользователя описывать как атрибуты товаров, с которыми он взаимодействовал. Для получения эмбеддингов товаров и пользователей используется один и тот же энкодер.
С помощью Contrastive Learning, модель учится генерировать такой эмбеддинг пользователя, при котором эмбеддинг следующего товара, с которым он взаимодействовал, будет ближе по косинусному расстоянию, чем другие товары. Рекомендации в данном случае — это k ближайших товаров к эмбеддингу пользователя.
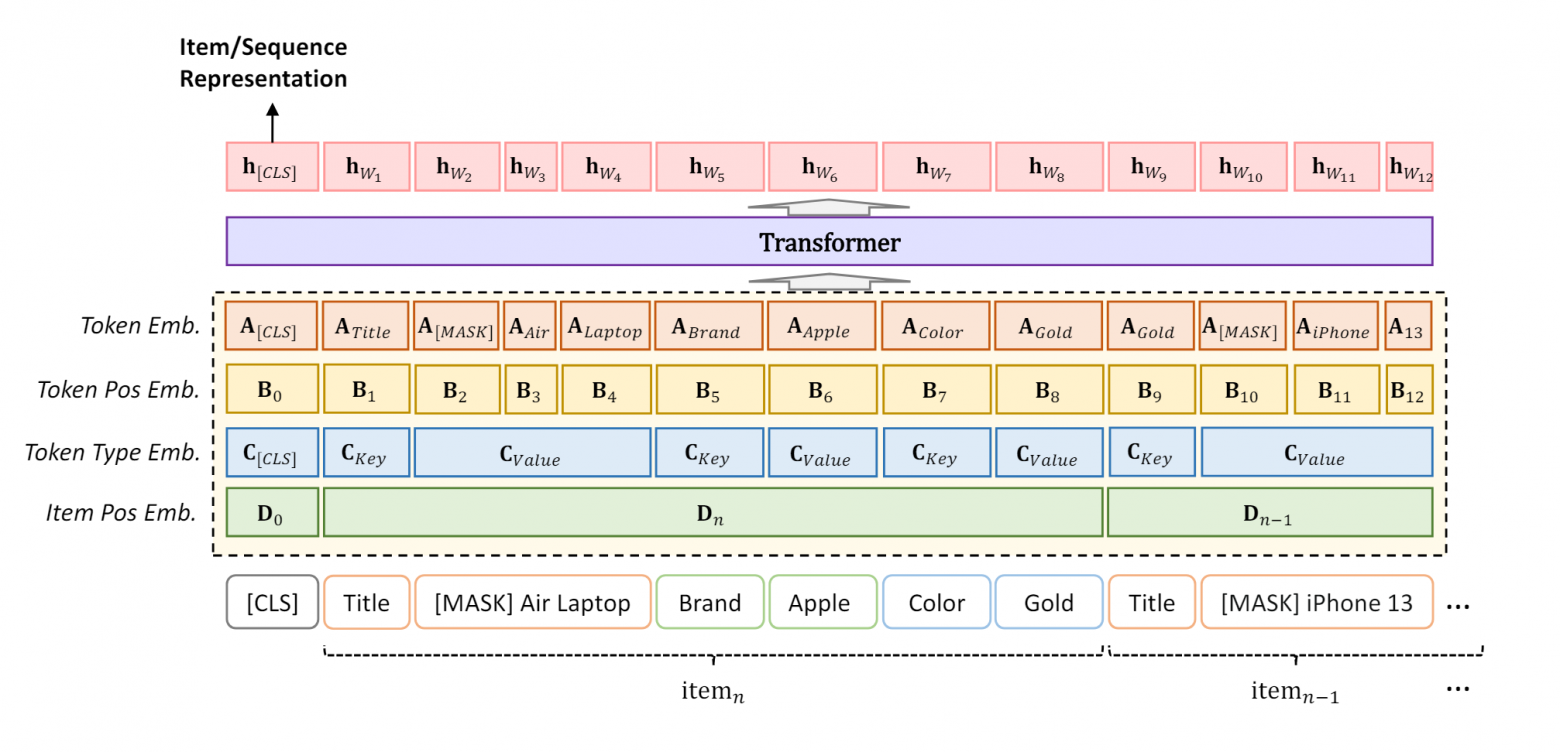
Опишем подробнее, что предлагается в статье:
Обучение происходит в 2 этапа:
Pre-training
Two-stage finetunning
Pre-training
Задача pre-training — получить хорошую инициализацию весов для fine-tunning.
Модели даётся две задачи: MLM, Masked Language Modelling, где часть входных токенов заменяется на токен [MASK] и цель модели — из контекста понять, какие токены были маскированы.
Целью второй задачи, item-item contrastive (IIC), является минимизация расстояния между эмбеддингом пользователя и эмбеддингом следующего товара в его истории взаимодействий и максимизация расстояния с эмбеддингами следующих товаров от других пользователей в батче.

Two-stage fine-tunning
Fine-Tunning происходит в 2 этапа.
На первом этапе раз в эпоху пересчитываются эмбеддинги товаров, и снова используется InfoNCE лосс, но только в этот раз негативами являются не остальные ground-truth элементы батча, а вообще все элементы, которые встречаются в истории всех пользователей.
На втором этапе эмбеддинги товаров замораживаются, и процесс файнтюннинга продолжается.
Далее авторы сравнивают свой подход с другими (ID-Only, ID-Text, Text only) на датасете Amazon Product Reviews и у всех (или почти у всех) выигрывают. Также авторы оценили zero-shot возможности модели, где модель пре-тренируется на одних датасетах, а тестируется на других. Сравнивались с Text-only методами, снова всех победили и сделали вывод, что pre-training позволяет получать знания, которые переносятся на downstream датасеты.
Наши модификации и опыт применения
Изменения в процессе тренировки
В результате экспериментов мы не увидели значительно эффекта от pre-training, и в дальнейшем от него отказались. Также второй этап в двухэтапном процессе fine-tunning’а снижает метрики при тестировании на новых товарах и новых пользователях, что не удивительно, ведь мы замораживаем эмбеддинги товаров, и изменения в процессе тренировок больше на них не отражаются.
Мы используем только первый этап fine-tunning’а, причём реэнкодим товары раз в N степов.
Измененный лосс
Вместо того чтобы предсказывать только следующий элемент, давайте попробуем считать позитивными несколько элементов. Это можно реализовать двумя способами:
Log in: мы вносим внутрь логарифма сумму позитивных элементов

Log out: суммируем по позитивным элементам снаружи логарифма

Мы реализовали Log in вариант. В результате наших тестов recall начал расти быстрее, чем со старым лоссом. Но в будущем необходимо провести ablation study и более точно оценить влияние различных лосс функций на метрики.
Изменения в данных
Наши данные значительно отличаются от данных, которые используют авторы статьи. В оригинальной статье сделан упор на текст/слова, например, названия товаров или текстовое описание их атрибутов, а также ключи на человекопонятном языке.
Наши данные очень похожи на табличные: числа, булевы значения, текстовые дискретные значения. Пример данных о товаре:
{
1:"dailyFlatRent",
2:"11",
3:"45.4",
5: "True",
6: "False"
}Изображения
Как известно, изображение — это примерно 256 слов, поэтому было бы интересно посмотреть, чему научится модель, если описывать товары только изображениями. Для этого мы извлекли эмбеддинги изображений с помощью EVA-02 ViT B/16 и подали их в LongFormer, дополнительно пропустив их через 1 обучаемый линейный слой, который инициализируется как единичная матрица, чтобы не вносить изменений в начале обучения.
В результате обучения модель научилась примерно определять цену, площадь, количество комнат и «вайб» ремонта. Это мы обнаружили, проанализировав ближайшие эмбеддинги к разным товарам.
Пример товаров с одинаковым «вайбом» фотографий


В дальнейшем мы подали изображения вместе с остальными признаками и тоже получили заметный прирост.
Метаинформация
Далее мы попробовали обогатить наш контекст дополнительной информацией о взаимодействии пользователя и товаров. Мы добавили тип действия и квантизованную длительность клика как отдельные атрибуты, которые подаются одновременно с атрибутами товаров. Это добавляет некое разногласие между товарами и пользователями, потому что метаданные не добавляются, когда мы энкодим товары. Тем не менее, мы также получили прирост метрик.
Результаты
Мы сравнили результаты для Offline метрики recall@30:
Прод модель первого уровня (без ранжирования) | 0.28 |
LongFormer | 0.31 |
LongFormer+meta_data | 0.32 |
LongFormer+meta_data+images | 0.34 |
Получили прирост в метрике, а также приятные бонусы, такие как:
Модель не нужно переобучать, она показывает примерно одинаковый performance на разных отрезках времени, с новыми товарами и пользователями.
Мы можем порекомендовать товар, с которым ещё не было взаимодействий, любому пользователю, у которого есть хотя бы 1 товар в истории.
Сейчас мы работаем над внедрением модели в production.
Сначала проведём эксперименты на item-item рекомендациях (блок Похожие объявления), это потребует наименьших усилий, так как рекомендации можно посчитать офлайн, и они не требуют истории пользователя. Далее мы проведём эксперименты в пользовательских рекомендациях, которые доставляются с помощью push-уведомлений. Их тоже можно считать офлайн, здесь мы сможем протестировать user-item рекомендации.
В случае успеха будем пробовать встроить рекомендации в онлайн, начав с пересчёта новых рекомендаций раз в N минут.
На одной 2080Ti можно сгенерировать рекомендации для ~45к пользователей за 35 минут. Производительность можно повысить, путём использования квантизации и оптимизирующих фреймворков, таких как TensorRT, либо компиляции модели с помощью torch.compile.
Потенциал для дальнейшего развития
Гибкость архитектуры трансформер позволяет дальнейшее развитие данного метода:
Можно использовать не base Longformer, а Large, что значительно замедлит трейн/инференс, но возможно даст лучшие результаты.
Возможно, что можно добиться большего прироста от использования картинок, если извлекать эмбеддинги другими методами. Например, натренировать VAE/VQVAE/VQGAN на собственном датасете, либо добавить какую-нибудь небольшую сеть, например EfficientNet, и тренировать её end-to-end вместе с трансформером, чтобы извлекать из картинок, признаки, которые нужны для рекомендаций. Ну или просто использовать CLIP энкодеры с большим количеством слоёв и разрешением.
Добавить можно не только картинки, но и дополнительный пользовательский текст: текста много и вставить токены текста напрямую, скорее всего, не получится, но можно поступить следующим образом: использовать pre-trained модели, либо провести pre-training BERT/LongFormer на пользовательских описаниях товаров и вставлять эти эмбеддинги текста в контекст.
Заключение
Мы поэкспериментировали с перспективной технологией: с трансформером, которому не нужны ID для рекомендаций. Данный подход не только показывает хорошее качество рекомендаций, но и позволяет рекомендовать товары быстрее: не нужно ждать, пока мы получим информацию о товаре из взаимодействий пользователей: как только товар появился, мы уже знаем, кому он может понравиться.
Но самое главное, что теперь у нас нет ограничений по промежутку времени, за который мы собираем тренировочный датасет: мы можем использовать данные из прошлого, чтобы улучшать качество предсказаний в будущем: глубже понимать, что интересно пользователю, и что он хочет сделать дальше.
