Беспростойная миграция RabbitMQ в Kubernetes

RabbitMQ — написанный на языке Erlang брокер сообщений, позволяющий организовать отказоустойчивый кластер с полной репликацией данных на несколько узлов, где каждый узел может обслуживать запросы на чтение и запись. Имея в production-эксплуатации множество кластеров Kubernetes, мы поддерживаем большое количество инсталляций RabbitMQ и столкнулись с необходимостью миграции данных из одного кластера в другой без простоя.
Данная операция была необходима нам как минимум в двух случаях:
- Перенос данных из кластера RabbitMQ, находящегося не в Kubernetes, в новый — уже «кубернетезированный» (т.е. функционирующий в pod«ах K8s) — кластер.
- Миграция RabbitMQ в рамках Kubernetes из одного namespace в другой (например, если контуры разграничены пространствами имён, то для переноса инфраструктуры из одного контура в другой).
Предлагаемый в статье рецепт ориентирован на ситуации (но вовсе не ограничен ими), в которых есть старый кластер RabbitMQ (например, из 3 узлов), находящийся либо уже в K8s, либо на каких-то старых серверах. С ним работает приложение, размещённое в Kubernetes (уже там или в перспективе):

… и перед нами стоит задача его миграции в новый production в Kubernetes.
Сначала будет описан общий подход к самой миграции, а уже после этого — технические детали по её реализации.
Алгоритм миграции
Первый, предварительный, этап перед какими-либо действиями — проверка, что в старой инсталляции RabbitMQ включён режим высокой доступности (HA). Причина очевидна — мы ведь не хотим потерять каких-либо данных. Чтобы осуществить эту проверку, можно зайти в админку RabbitMQ и во вкладке Admin → Policies убедиться, что установлено значение ha-mode: all:

Следующий шаг — поднимаем новый кластер RabbitMQ в pod«ах Kubernetes (в нашем случае, например, состоящий из 3 узлов, но их число может быть и другим).
После этого мы объединяем старый и новый кластеры RabbitMQ, получая единственный кластер (из 6 узлов):
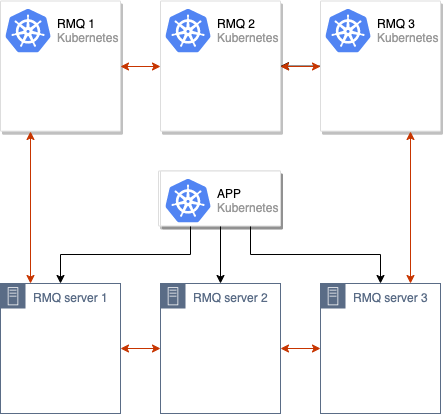
Инициируется процесс синхронизации данных между старым и новым кластерами RabbitMQ. После того, как все данные синхронизируются между всеми узлами в кластере, мы можем переключить приложение на использование нового кластера:
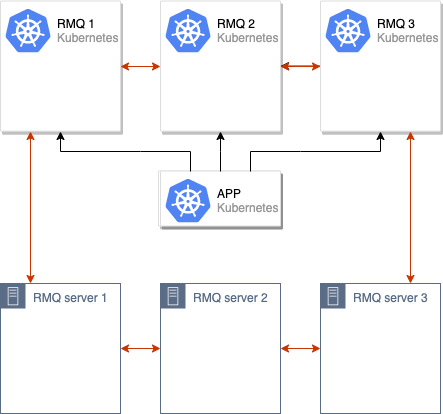
После этих операций достаточно вывести из кластера RabbitMQ старые узлы, и переезд можно считать завершённым:

Эту схему мы неоднократно применяли у нас в production. Однако для собственного удобства реализовали её в рамках специализированной системы, распространяющей типовые конфигурации RMQ на множествах кластеров Kubernetes (для тех, кому любопытно: речь идёт про addon-operator, о котором мы совсем недавно рассказывали). Ниже будут представлены отдельно взятые инструкции, которые каждый может применить на своих инсталляциях, чтобы попробовать предлагаемое решение в действии.
Пробуем на практике
Требования
Реквизиты очень просты:
- Кластер Kubernetes (подойдет и minikube);
- Кластер RabbitMQ (может быть и развернут на bare metal, и сделан как обычный кластер в Kubernetes из официального Helm-чарта).
Для описанного ниже примера я развернул RMQ в Kubernetes и назвал его rmq-old.
Подготовка стенда
1. Скачаем Helm-чарт и немного отредактируем его:
helm fetch --untar stable/rabbitmq-ha
Для удобства задаём пароль, ErlangCookie и делаем политику ha-all, чтобы по умолчанию очереди синхронизировались между всеми узлами кластера RMQ:
rabbitmqPassword: guest
rabbitmqErlangCookie: mae9joopaol7aiVu3eechei2waiGa2we
definitions:
policies: |-
{
"name": "ha-all",
"pattern": ".*",
"vhost": "/",
"definition": {
"ha-mode": "all",
"ha-sync-mode": "automatic",
"ha-sync-batch-size": 81920
}
}
2. Устанавливаем чарт:
helm install . --name rmq-old --namespace rmq-old
3. Заходим в админку RabbitMQ, создаём новую очередь и добавляем несколько сообщений. Они понадобятся для того, чтобы после миграции мы могли удостовериться, что все данные сохранились и мы ничего не потеряли:

Тестовый стенд готов: у нас есть «старый» RabbitMQ с данными, которые нужно перенести.
Миграция кластера RabbitMQ
1. Для начала развернём новый RabbitMQ в другом пространстве имён с такими жеErlangCookie и паролем для пользователя. Для этого проделаем описанные выше операции, изменив конечную команду по установке RMQ на следующую:
helm install . --name rmq-new --namespace rmq-new
2. Теперь требуется объединить новый кластер со старым. Для этого заходим в каждый из pod«ов нового RabbitMQ и выполняем команды:
export OLD_RMQ=rabbit@rmq-old-rabbitmq-ha-0.rmq-old-rabbitmq-ha-discovery.rmq-old.svc.cluster.local && \
rabbitmqctl stop_app && \
rabbitmqctl join_cluster $OLD_RMQ && \
rabbitmqctl start_app
В переменной OLD_RMQ находится адрес одного из узлов старого кластера RMQ.
Эти команды остановят текущий узел нового кластера RMQ, присоединят его к старому кластеру и снова запустят.
3. Кластер RMQ из 6 узлов готов:

Необходимо подождать, пока сообщения синхронизируются между всеми узлами. Нетрудно догадаться, что время синхронизации сообщений зависит от мощностей железа, на котором развёрнут кластер, и от количества сообщений. В описываемом сценарии их всего 10, поэтому данные синхронизировались моментально, но при достаточно больших количестве сообщений синхронизация может длиться часами.
Итак, статус синхронизации:

Здесь +5 означает, что сообщения уже находятся ещё на 5 узлах (кроме того, что указан в поле Node). Таким образом, синхронизация прошла успешно.
4. Остается лишь переключить в приложении адрес RMQ на новый кластер (конкретные действия здесь зависят от используемого вами технологического стека и другой специфики приложения), после чего можно попрощаться со старым.
Для последней операции (т.е. уже после переключения приложения на новый кластер) заходим на каждый узел старого кластера и выполняем команды:
rabbitmqctl stop_app
rabbitmqctl reset
Кластер «забыл» о старых узлах: можно удалять старый RMQ, на чём переезд будет закончен.
Примечание: Если вы используете RMQ с сертификатами, то принципиально ничего не меняется — процесс переезда будет осуществляться точно так же.
Выводы
Описанная схема подходит практически для всех случаев, когда нам нужно перенести RabbitMQ или просто переехать в новый кластер.
В нашем случае сложности возникали только один раз, когда к RMQ обращались из множества мест, а у нас не было возможности везде поменять адрес RMQ на новый. Тогда мы запускали новый RMQ в том же пространстве имён с одинаковыми лейблами, чтобы он попадал под уже существующие сервисы и Ingress«ы, а при запуске pod«а руками манипулировали лейблами, удаляя их в начале, чтобы на пустой RMQ не попадали запросы, и добавляя их обратно после синхронизации сообщений.
Такую же стратегию мы применяли при обновлении RabbitMQ на новую версию с изменённой конфигурацией — всё работало как часы.
P.S.
В качестве логического продолжения этого материала мы готовим статьи про MongoDB (миграция с железного сервера в Kubernetes) и MySQL (как мы готовим эту СУБД внутри Kubernetes). Они будут опубликованы в ближайшие месяцы.
P.P. S.
Читайте также в нашем блоге:
