Асинхронность в С++20. Доклад в Яндексе
Привет, это Григорий Демченко из WhatsApp. Мой доклад посвящён использованию сопрограмм в C++20. Я не стал говорить про низкоуровневые примитивы и то, как компилятор поддерживает сопрограммы и преобразовывает соответствующий код. Вместо этого акцент сделан на практическом применении сопрограмм для решения конкретных задач высокопроизводительных масштабируемых систем. Это именно то, ради чего создавались сопрограммы в новом стандарте, и то, с чем разработчик будет иметь дело в процессе проектирования и программирования. Я постарался рассмотреть конкретные примеры и проблемы, с которыми можно столкнуться при использовании полностью асинхронного подхода.— О чём я сегодня расскажу? Первое — введение в асинхронность. Далее мы рассмотрим примитивы, которые можно использовать в новом стандарте, и интеграцию с планировщиками. Также немаловажным аспектом будет являться работа со старым кодом, если мы пишем новый код с использованием нового подхода. Затем я покажу бонус, достаточно интересный и необычный. И подведём итоги того, что у нас получилось.
Я хотел бы заранее подчеркнуть, что будет в этой презентации. Прежде всего, я хочу рассмотреть stackless-сопрограммы из нового стандарта C++20. Я буду основываться на некоторых практических аспектах использования, то есть мы будем рассматривать высокоуровневые примитивы на примере библиотеки Folly. Дело в том, что в стандартной библиотеке у нас нет нормальных примитивов для работы с сопрограммами. Именно поэтому я буду использовать библиотеку Folly, но также можно использовать любую другую библиотеку.
Здесь не будет рассмотрены низкоуровневые вещи и взаимодействия — то, как именно реализовывать co_await, как реализовывать примитивы работы с сопрограммами, например асинхронный mutex, и так далее. Потому что их надо реализовать один раз, а потом использовать во многих местах. То есть с точки зрения практического использования эти знания о том, как всё выглядит внутри, не нужны, а я буду фокусироваться именно на практическом использовании.
Введение в асинхронность и сопрограммы

Что сейчас есть в стандарте? Потоки, mutex, можно использовать callbacks и лямбды, Futures. Некоторые используют std: async, но я бы этого не рекомендовал, так как это очень странная вещь в стандарте. Как правило, большинство из примитивов, о которых я только что сказал, содержат блокирующие операции — мы блокируем текущий поток исполнения, таким образом конкурентность серьёзно снижается, что ограничивает нашу параллельность и эффективность наших программ.
Поэтому необходимо использовать сторонние библиотеки либо писать всё с нуля для использования сопрограмм. Писать всё с нуля — конечно, очень благородная цель, но лучше использовать сторонние библиотеки, например Folly. Все аспекты, о которых я расскажу, применимы и для всех остальных библиотек, поэтому, один раз познакомившись с одной библиотекой, можно переносить этот опыт на все остальные.

Как же мы будем превращать наши программы в сопрограммы? Везде и всюду, если я буду использовать namespace fc, для краткости будет подразумеваться folly: core. Здесь есть обычная функция getString, которая возвращает нам строку. Давайте превратим её в асинхронную функцию на сопрограммах. Для этого мы обернём возвращаемый тип в fc: Task, а вместо return будем использовать ключевое слово co_return.
Всё, теперь у нас есть сопрограммы и асинхронный код, на этом можно презентацию можно было бы закончить, но с этого всё только начинается, дальше будут интересные моменты, примитивы и сюрпризы.

Рассмотрим более сложный пример. Есть строка getString из предыдущего примера, мы хотим воспользоваться результатом этой строки. Тогда нам необходимо иметь не fc: Task
Дальше предположим, что у нас есть функция main, она синхронная и не может быть асинхронной, поэтому в контексте функции main мы не можем звать co_return, co_await и прочее. Поэтому нам необходимо превратить асинхронный код в синхронный. Для этого есть функция blockingWait, о которой я поговорю позже. Мы запускаем нашу сопрограмму getFullString, планируем её на каком-то планировщике, в данном случае на глобальном CPUExecutor. Так мы можем получить наш результат и использовать его дальше. Происходит взаимодействие асинхронного мира с синхронным, если это потребуется.
Чем хороши сопрограммы? Например, если сравнивать с Future, то у нас получается более простой и линейный код, который гораздо проще писать, использовать и поддерживать. Также у нас лучше производительность, потому что Future, когда мы их запускаем, стартуют сразу же. Если мы делаем цепочку из Future, то нам каждый раз необходимо планировать эти маленькие продолжения. В случае с сопрограммой мы можем это делать гораздо более эффективно.
Кроме того, мы можем использовать эффективные примитивы, которые использовали раньше в обычных многопоточных приложениях: например, mutex или что-то другое. То есть сопрограммы — гораздо более удобный и быстрый способ написания программ. Также это даёт неоспоримые преимущества во время исполнения.

Рассмотрим некоторые детали и аспекты взаимодействия с сопрограммами. У нас есть класс Value, у него два метода — set и get. Метод set, в котором мы задаем значение, — синхронный, а get возвращает текущее значение. Изначально значение равно нулю.
Функция doSetGet создает экземпляр value с этим значением. Мы хотим присвоить значение 2, а дальше вызываем .get () и ожидаем некоторый результат. Казалось бы, результат должен быть равен двум, но это не так.

Дело в том, что сама сопрограмма, когда мы получаем задачу после вызова метода val.set (), не запускается, отложена. Она запускается, только когда мы начнём с этой сопрограммой что-то делать, когда позовём что-либо, например co_await. Только после этого у нас будет результат исполнения. Я заметил ошибку на слайде: в самой последней строчке, где мы сравниваем результат с двойкой, надо снова позвать val.get (), потому что результат переменной result не изменится, а .get () вернёт уже новое значение.
Как создать Task и запустить асинхронно на выполнение? Это мы рассмотрим чуть позднее.
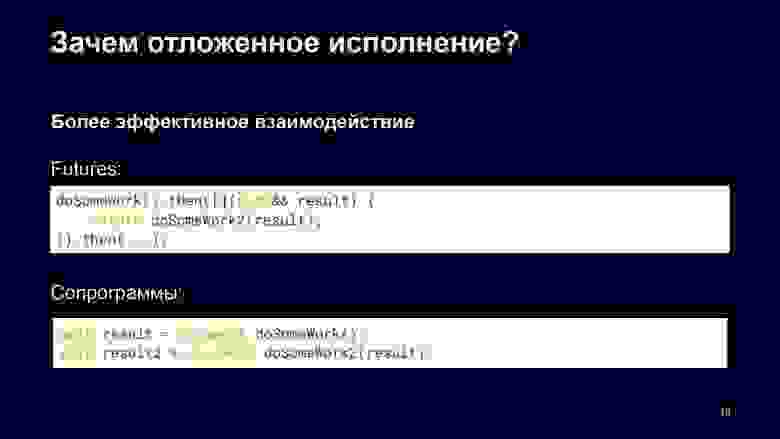
Как я говорил, это более эффективное взаимодействие, чем Future. Потому что если у нас есть задача, дальше мы хотим сделать продолжение, делаем другую задачу, дальше есть ещё одно продолжение, и эти маленькие кусочки необходимо каждый раз планировать заново.
В случае сопрограмм компилятор может оптимизировать это поведение, и нет необходимости каждый раз перепланировать эту операцию: мы можем запустить продолжение в том же контексте. Это связано с тем, что функция в сопрограмме — отложенная. Таким образом doSomeWork может запускаться в контексте текущей сопрограммы.

Рассмотрим типичные проблемы, которые могут возникнуть при работе с сопрограммами. Например, у нас есть функция, которая возвращает fc: Task, и функция bar, внутри которой мы создаём временную строку и возвращаем её, вызывая return foo (s).
Казалось бы, всё хорошо: foo возвращает fc: Task, мы возвращаем её и всё нормально. Проблема в том, что fc: Task мы вернули, но эта fc: Task не запущена. Мы запустили с параметром, который взяли по ссылке, временный объект уничтожился, и всё, а fc: Task ещё не запущена, поэтому нас ждёт весёлый сюрприз в runtime.

Чтобы этого не произошло, нам нужно использовать корутинный (сопрограммный) синтаксис везде, где только можно. Код следует переписать следующим образом. Тогда всё будет хорошо.
Примитивы для работы с асинхронностью
Сначала я хотел бы рассмотреть интеграцию: как лямбды уживаются с сопрограммами. В данном случае мы хотим сделать задачу. Для этого захватываем request, внутри вызываем processRequest, получаем reply и его возвращаем. В чём тут проблема?

Дело в том, что наша лямбда и наш компилятор не знают, какой тип вывести, когда мы вызываем co_await и co_return. Чтобы это произошло без ошибки компиляции, нам необходимо явно указать, какой возвращаемый тип у нас будет. В данном случае у нас будет тип reply. Нам необходимо явно сказать, что у нас будет задача с типом Reply: fc: Task. Тогда приведённый выше код скомпилируется.
Казалось бы, всё хорошо. Но разработчики стандартов не зря едят свой хлеб. Помимо ошибок компиляции у нас будут ошибки времени исполнения. Когда создаётся лямбда, она создаётся как временный объект. И когда мы её запускаем, этот временный объект запускается, возвращает нам fc: Task. fc: Task является отложенным исполнением, таким образом лямбда будет разрушена, потому что она временная, а с разрушением лямбды разрушается и контекст лямбды, то есть захваченная в лямбде переменная request. Таким образом этот код благополучно упадёт.

Конечно, разработчикам C++ не привыкать: придётся ещё сделать дополнительное приседание. У нас есть метод co_invoke,. Вместо того чтобы явно запросить лямбду, мы используем co_invoke, который позволяет решить эту проблему: запустить и сохранить этот контекст внутри лямбды. Такой код уже будет нормально и корректно работать.
То есть интеграция сопрограмм и лямбд в новом стандарте прошла у нас на ура!

Давайте рассмотрим mutex. Тут никаких сюрпризов нет: есть mutex, мы можем асинхронно его захватить, для этого внезапно можно использовать unique_lock (!): захватываем mutex асинхронно и делаем свою работу. Как видно, возвращаемый результат из mutex.co_scoped_lock () — это fc: Task.
Можно просто попытаться взять lock. Если мы попытались и нам удалось, то всё хорошо: блокировка получена. В этом случае метод может быть синхронный, потому что мы пытаемся и если у нас не получается, то мы ничего не ожидаем и наша сопрограмма не вытесняется.

Рассмотрим Baton, не путать с булками. В следующим примере у нас есть producer, consumer и значение — глобальное или некоторое другое, которое требует синхронизации из разных потоков. Мы задаём это значение в producer и в Baton делаем post. Для безопасного использования значения в consumer мы делаем co_await на baton, то есть ожидаем, когда значение будет передано.
Как только это произошло, мы можем это значение использовать. На основе такого простого паттерна можно реализовать Future/Promise в сопрограммах.

Рассмотрим блокирующий вызов, раньше я уже о нём говорил. Если нам необходимо задачу превратить из асинхронной в синхронную, можно позвать блокирующую операцию blockingWait. Но тогда мы теряем в эффективности, потому что в этот момент блокируем текущий поток. Однако это удобно в некоторых тестах, так как большинство тестов у нас синхронные, и нам необходимо дожидаться окончания работы задач. Поэтому для тестов это вполне подходит.

Рассмотрим подробно, как нам запускать параллельные операции. У нас есть две операции, которые мы бы хотели запустить параллельно. Что мы делаем? Казалось бы, запускаем первую задачу, запускаем вторую, ожидаем результат первой, ожидаем результат второй и возвращаемся из функции.
Если бы у нас были Future, такой подход бы работал. Но у нас fc: Task, а fc: Task — как мы помним, ленивые, они не запустятся, пока их не пнёшь. Поэтому они начинают запускаться, когда мы вызываем co_await, и видно: результатом этой функции будет являться последовательное выполнение действий.
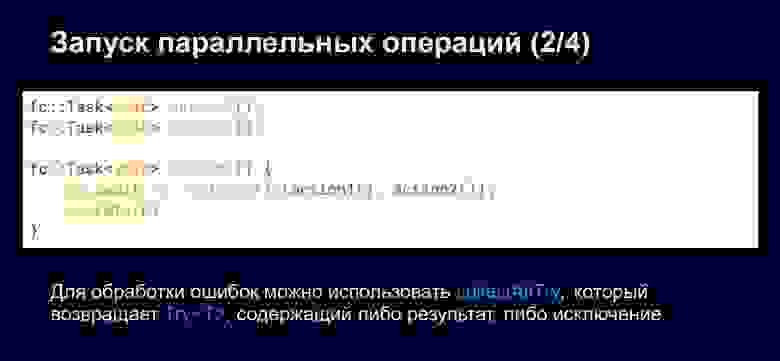
Нам надо пофиксить такое решение. Для этого мы будем использовать функцию collect All, в которую передадим действия для выполнения. Она выполнит их параллельно и дождётся результата. Если fc: Task возвращают void, то мы дождёмся завершения исполнения, а если функция возвращает, например, int, string, то она вернёт все эти результаты.
Если нам необходимо обработать ошибки, можно использовать collectAllTry. При этом будет возвращаться try, который содержит либо результат, либо ошибку. И мы можем тестировать наличие результата или конкретной ошибки.
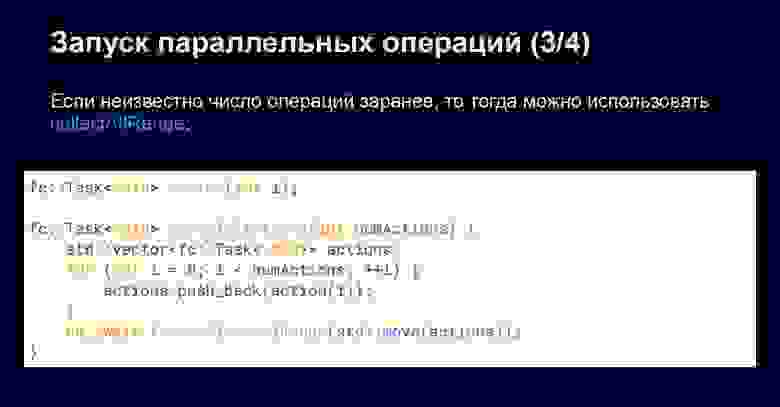
Предположим, нам неизвестно заранее, какое количество действий у нас есть — оно, например, известно во время исполнения, но не во время компиляции. Тогда надо использовать collectAllRange. Например, в приведённом примере у нас есть массив задач, и мы запускаем некоторые наши действия, заполняя этот массив.
Опять же: во время заполнения этого массива задачи у нас не запускаются. Они запускаются, только когда зовётся collectAllRange. В этот момент у нас все задачи разом запускаются, и мы ожидаем выполнения всех операций.
Также есть функция, которая позволяет запускать не все функции сразу, а только в рамках определённого окна. Всё это можно увидеть в документации.
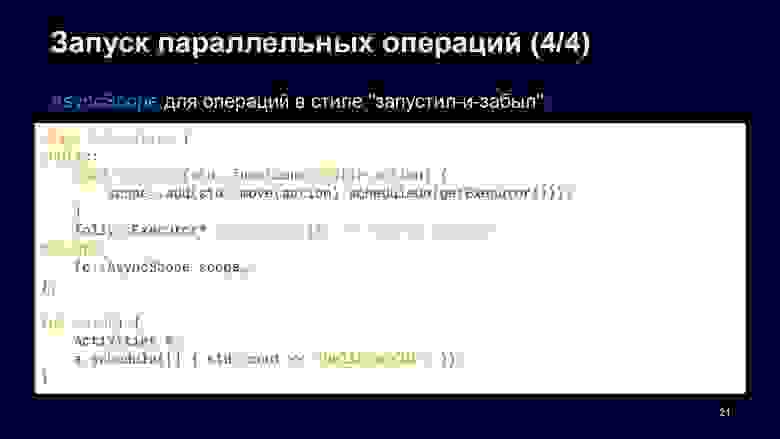
Но бывает, что нам необходимо запустить задачи в стиле «запустил и забыл», полностью асинхронно. Для этого можно использовать AsyncScope, в котором мы можем добавлять наши задачи. Но они должны быть запущены с использованием планировщика, как в приведённом примере. Таким образом можно в любой момент добавлять большое количество задач, если мы заранее не знаем, сколько их. Вот какие способы запуска параллельных операций можно использовать.
Интеграция с планировщиками
Мы уже видели интеграцию с планировщиками, теперь давайте рассмотрим более детально. Здесь у нас типичный метод getString, который является асинхронным. Если мы позовём этот метод, нам вернётся задача fc: Task
Если мы его запустим на планировщике, например globalCPUExecutor, то вернётся объект с типом TaskWithExecutor. То есть это уже будет не просто задача, а задача с планировщиком. Теперь, если мы действительно хотим сделать так, чтобы она запустилась асинхронно, нам надо вызвать метод start. Тогда вернётся semiFuture, которая как раз и запустит нашу задачу. Теперь этот результат действительно будет асинхронным. После этого момента наша задача запустится, и co_await для этого не обязателен.

Рассмотрим важный аспект интеграции сопрограмм с планировщиками. Дело в том, что сопрограммы внутри себя могут запускать какие-то другие сопрограммы. Они могут быть запущены на других планировщиках. Поэтому нам необходимо понять, где запускается наша текущая сопрограмма.
В первую очередь, чтобы извлечь планировщик из нашей текущей сопрограммы, есть специальная функция co_current_executor, которая возвращает текущий планировщик folly: Executor. Можно убедиться: даже если между вызовами co_current_executor существуют другие действия с сопрограммами, которые могут запускаться на других планировщиках, всё равно текущая сопрограмма всегда вернётся в тот же планировщик.
Это позволяет быть уверенным, что с сопрограммой ничего плохого не случится. Если мы запустили сопрограмму на одном планировщике, она будет оставаться на нём, пока не умрёт. Приведённый выше пример наглядно демонстрирует этот инвариант.

Рассмотрим подробнее типы fc: Task и fc: TaskWithExecutor. На них можно звать co_await, причём как на первом, так и на втором. При этом, если я позову co_await на задаче fc: Task, будет использоваться текущий планировщик из текущей сопрограммы. Понятно, что, если я сделаю taskWithExecutor, task запустится с привязанным к этой задаче планировщиком.
При этом есть специальные типы traits: fc: Task будет semi_awaitable, а для TaskWithExecutor будет awaitable. То есть во время компиляции можно обобщённо (на шаблонах) протестировать, привязан ли планировщик к задаче. Тут наблюдается аналогия с Future, потому что TaskWithExecutor — это полноценная Future, которая обладает пониманием, где она запущена. Если у нас нет связанного планировщика, то это SemiFuture.
Вот как работает аналогия:
Работа со старым кодом
Поговорим о том, как мигрировать код на новый и как интегрироваться со старым кодом. Потому что невозможно взять и просто переписать наши программы на сопрограммы.

Предположим, мы хотим превратить функцию foo, которая возвращает SemiFuture, в функцию, которая возвращает fc: Task. Нет проблем: есть функция toTask, которая превращает SemiFuture в fc: Task. Таким образом после того, как мы превратили типы, можно использовать все имеющиеся у нас примитивы сопрограмм.
Не забываем ключевые слова co_return и co_await: если мы сделаем return, то наступим на грабли, о которых я в говорил выше (про висячие ссылки). В данном случае у нас, конечно, нет аргументов, но если бы они были, возникли бы проблемы.

Если мы хотим обратно из сопрограмм перейти в старый код, то для этого есть специальные функции. toSemiFuture может превратить fc: Task обратно в SemiFuture. Или, предположим, нам действительно необходимо Future — что не рекомендуется, но тем не менее. Для этого есть метод toFuture. Но тогда нам необходимо указать планировщик, потому что без планировщика у нас будет SemiAwaitable, что эквивалентно SemiFuture. Чтобы получить полноценный Awaitable, необходимо иметь привязанный планировщик.

Таким образом, если у нас старая реализация Future или SemiFuture, их можно превратить в наши задачи с помощью указанных методов. Можно туда-сюда их превращать, пока весь код не перепишется в задачи fc: Task. Или наоборот, мы поймём, что нам что-то не нравится, и обратно перепишем на Future. Но не стоит забывать: когда возвращается Future или SemiFuture, функция сразу запускается на исполнение. Когда мы создаем fc: Task — задача не запускается. Это серьёзное отличие, которое надо иметь в виду.
Бонус: новая модель конкурентного взаимодействия
Давайте теперь рассмотрим бонус. Когда-то я уже описывал в статье на Хабре эту новую модель (см. CoAlone). Субъектарная модель включает эту модель, но на мой взгляд, о ней имеет смысл поговорить отдельно.

Модель достаточно простая, но, как оказалось, никто не знает, что так можно делать. Дело в том, что в библиотеке Boost и Folly есть strandExecutor. Его практически никто не использует? можно даже сказать, вообще никто не использует, но он обладает очень интересными свойствами.
У нас есть действия, и мы эти действия запускаем на сопрограммах, используя в качестве планировщика strandExecutor. Что у нас происходит? Внутри есть сопрограмма, которая делает первое действие синхронное, второе действие асинхронное и третье действие опять синхронное. Что в результате?

В результате — следующая интересная картина. Код выглядит так, как будто бы ниже приведён эквивалентный код, который является не реальной реализацией, а именно эквивалентом: семантика этих двух функций полностью идентична.
Для всех синхронных вызовов у нас берётся mutex на время этих синхронных вызовов. При этом, как только выполняется асинхронный вызов, блокировки снимаются на время исполнения этого асинхронного вызова. Затем мы снова берём блокировку и продолжаем наши синхронные вызовы.
То есть strandExecutor гарантирует, что физически наша сопрограмма, когда она исполняется на CPU, не допускает параллельного исполнения наших сопрограмм на этом планировщике. То есть у нас как будто эффективно берутся блокировки, когда мы делаем нечто осмысленное на CPU.

К чему это приводит? В первую очередь это позволяет синхронизировать доступ к данным, которые ассоциированы с этим планировщиком или с нашей моделью. То есть отсутствует data race: мы можем делать с данными что захотим и когда захотим.
При этом такой метод разрывает зависимость между пропускной способностью и задержками. Дело в том, что основной вклад задержки в асинхронном коде происходит, например, когда мы идём в базу данных или к другому сервису. Именно они дают нам миллисекундные или стомиллисекундные задержки.
Если мы делаем что-то на CPU, то, как правило, речь идет о микросекундах — мы делаем это быстро и доступ к данным синхронизирован автоматически. Как только мы идем куда-то удаленно и делаем асинхронную операцию, мы отпускаем все блокировки. Таким образом, какая-то другая сопрограмма может продолжать работать, происходит параллельное исполнение.
Как нетрудно догадаться, на выходе у нас получается линейный код. В этом смысле такая модель выгодно отличается от своих аналогов, например от акторной модели, в которой, чтобы достичь таких же свойств, необходимо весь код полностью переписать на асинхронный. Мы должны посылать сообщения и ожидать другие сообщения в ответ, всё это должно быть предусмотрено в акторе, у нас должна быть использована событийная модель. Код при этом не будет простым и линейным, так как мы должны быть готовы к любым событиям, которые могут к нам прийти, причём в разной последовательности. Всё это сильно усложняет логику и сложность программ.
Итоги
Что у нас получилось в результате? Начну со сравнения со stackful-сопрограммами, потому что, на мой взгляд, есть два конкурентных способа использовать простую асинхронность в C++: stackful- и stackless-сопрограммы.
Stackful-сопрограммы можно было использовать до C++20, потому что они не требовали поддержки компилятора, изменения кода, преобразования кода компилятором. Они требовали только операций на ассемблере, которые были реализованы, например, в библиотеке Boost. Давайте пройдёмся по плюсам и минусам stackless.
⊕ Конечно, это более тесная интеграция с компилятором, больше возможностей для оптимизации, потому что компилятор может видеть, что происходит с каждой функцией, может выполнить текущую задачу на текущем стеке вместо того, чтобы выделять дополнительную память. Stackless, в отличие от stackful-сопрограмм, не требуют выделения дополнительного стека для своего исполнения. При этом используется текущий стек.
⊖ Тем не менее, у такого подхода есть огромные минусы. В первую очередь, это несколько не ортогонально, на 180 градусов переворачивает наше представление о том, что мы можем использовать в C++. Например, асинхронность нельзя использовать в конструкторах и деструкторах. Получается, что у нас взяли и отобрали RAII. На мой взгляд, это очень существенный минус.
⊖ Другой немаловажный аспект — суперинвазивность. Что я под этим подразумеваю? Предположим, у нас есть синхронный метод и потом оказалось, что внутри этого метода нам необходимо использовать асинхронный код. Чтобы это сделать, необходимо вставить везде co_await, изменить возвращаемые типы c T на fc: Task, причем сделать это по всей цепочке вызовов.
Если что-то или кто-то использует этот метод, мы должны превратить в асинхронный и его тоже, и так далее. Это разрастается снежным комом. Как только где-то зарождается асинхронность, она начинает распространяться. В этом нет ничего плохого, но иногда это может доставлять неудобства: как минимум, менять стабильные интерфейсы сервисов и библиотек.
Что можно было бы ожидать от следующего стандарта? Например, создаём connection и хотим, чтобы конструктор был асинхронный — то есть чтобы, когда объект создаётся, можно было позвать co_await на этом конструкторе.
Также мы хотели бы, например, зачитывать в цикле значения из этого соединения. В данном случае пока невозможно написать for co_await. Также я бы хотел, чтобы деструктор тоже был асинхронным. Такая конструкция, например, явно бы вызывала co_await на деструкторе, но сейчас это не сделано.
Я бы хотел видеть в стандарте:
- Полноценную поддержку RAII, о которой уже рассказал.
- Поддержку алгоритмов и примитивов по аналогии с std: mutex и прочее.
- Реальные высокоуровневые примитивы для работы с сопрограммами, потому что сейчас для сопрограмм сделан не просто полуфабрикат, а какие-то затычки, всё надо реализовывать самому либо использовать сторонние библиотеки. Существует поддержка только со стороны компилятора, и всё. Примитивы обязательно должны быть в стандарте, если мы хотим, чтобы сопрограммы действительно стали использоваться.
Также немаловажно, чтобы была работа с планировщиками и тесная интеграция примитивов. Дело в том, что без планировщиков немыслимо делать что-то эффективно с Future, с сопрограммами. Планировщики — важный аспект эффективной и параллельной работы наших алгоритмов.
Тем не менее, техника async/await — это действительно серьезный шаг вперёд в C++ и в C++ 20. Я могу только поздравить программистов C++. Технику уже можно использовать, она готова для продакшена, код получается очень хороший, производительный и эффективный, никаких нареканий у меня нет. Мне нравится работать с сопрограммами гораздо больше, чем с Futures, потому что Futures более тяжеловесные и дают меньшую производительность.
Конечно, главный плюс — это простота. Код у нас линейный, простой, всё понятно и достаточно легко читается. Но нужно не забывать про то, о чём я сказал ранее, — про минусы и подводные грабли, которые очень классно расставлены.
