Архитектура ELK-RabbitMQ — управление логами для большой IT-инфраструктуры
Как с помощью брокера AMQP RabbitMQ создать отказоустойчивую архитектуру с минимальными потерями лог-данных при сбоях.

Потеря логов при управлении большой инфраструктурой компании-хостера может обернуться имиджевыми и финансовыми потерями. Вместе с тем большое количество управляемого оборудования не вызывает желания создавать системы, в которых логи будут дублироваться и превращаться в огромный и трудноуправляемый массив информации.
Мы в компании Hostkey не стали изобретать велосипед и построили нашу систему на базе Open Distro. В этой статье мы расскажем о варианте архитектуры этого решения, которое благодаря использованию брокера AMQP RabbitMQ обеспечивает отказоустойчивость и минимальные потери лог-данных при сбоях.
Чаще всего система обработки и хранения логов организуется примерно по такой схеме:

Приложение для сбора логов передает их напрямую посредством протокола Syslog в конвейер обработки данных Logstash. Оттуда данные попадают в базу Elasticsearch и далее используются панелью визуализации данных Kibana.
Все элементы ELK поддерживают отказоустойчивость, и схема прямого взаимодействия вполне устойчива. Однако с ростом системы необходимо закладывать линейный рост мощности системы обработки логов, поскольку Logstash — это точка приема логов и одновременно система их парсинга. При всплесках числа сообщений требуется линейный рост производительности системы, то есть приемник не должен «захлебываться» сообщениями — напротив, он должен стабильно поставлять информацию при сбое без потери сообщений. Соответственно, необходимо заранее закладывать ресурсы под предполагаемые всплески.
В одной из прошлых статей мы рассказывали, как устроено управление оборудованием в компании Hostkey и какую роль выполняет кластер брокера сообщений (RabbitMQ) в нашей инфраструктуре. Особенностью RabbitMQ является высокая надежность и способность обрабатывать значительные объемы сообщений при минимальном потреблении ресурсов. Это возможно потому, что Rabbit не занимается обработкой сообщений, а только их хранением и доставкой.
Мы решили доработать систему обработки и добавили RabbitMQ в качестве буфера очередей.

Это решение позволило повысить отказоустойчивость системы: если что-то пойдет не так на любом из этапов обработки и хранения логов, они останутся в Rabbit AMQP. Другим преимуществом нашего решения является дополнительная вариативность работы с логами — например, мы можем добавлять дополнительные анализаторы и выполнять аналогичные действия по управлению и обработке логов.
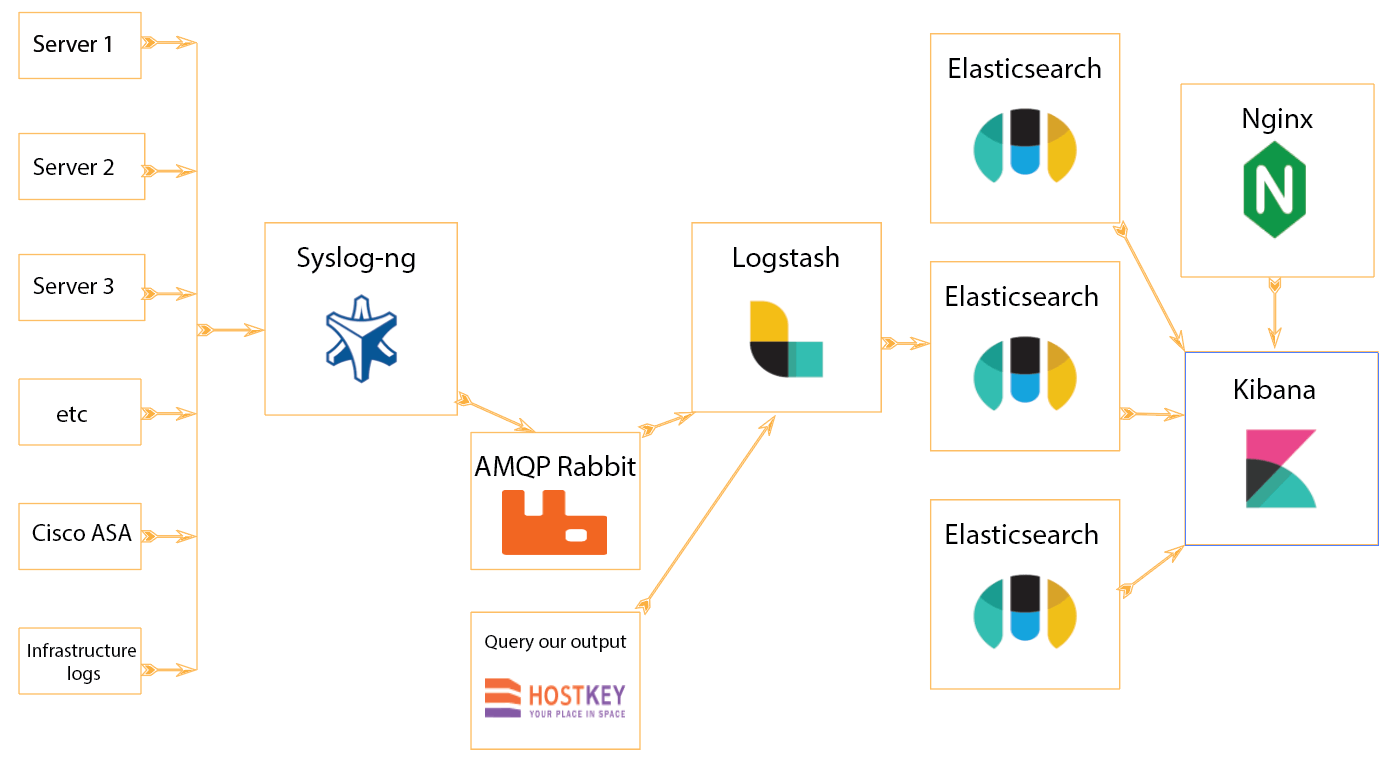
* Nginx мы используем для проксирования Kibana
В результате Logstash забирает информацию с выходных очередей по мере способности обработать сообщения. Rabbit здесь играет роль кеша, он способен принять заведомо многократно больший объем информации, чем Logstash.
В случае аварийной ситуации отдельные сообщения также можно просмотреть через Rabbit. Кроме того, очередь Rabbit является точкой мониторинга, накопление сообщений в очереди — прямое свидетельство существенных (всплеск числа логов) или частных (отказ системы ELK) проблем в инфраструктуре.
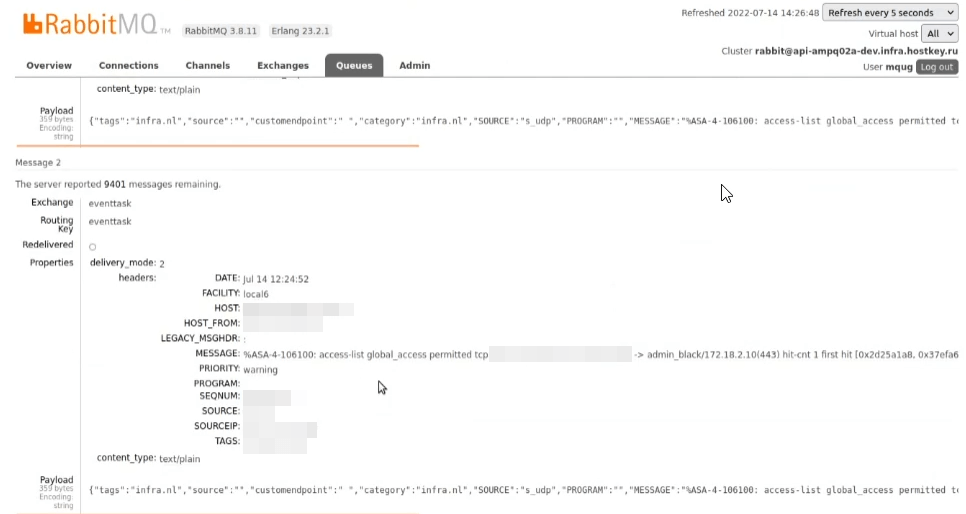
Конфигурация клиентского агента Logstash:
destination d_ampqp {
amqp(
vhost("/")
host("HOST_IP")
port(5672)
exchange("****")
exchange-type("direct")
routing-key("****")
body("$(format-json —-scope nv_pairs —-pair category=\"infra.ru\" —-pair
source=$source —-pair customendpoint=\" \" —-pair tags=\"infra.ru\")")
persistent(yes)
username("")
password("")
}
}Конфигурация агента индексатора Logstash:
input {
rabbitmq {
host => "HOST_IP"
queue => "syslog"
heartbeat => 30
durable => true
password => "****"
user => "****"
}
}
filter {
# your filters here
}
output {
elasticsearch { hosts => ["https://localhost:9200"]
hosts => "https://localhost:9200"
manage_template => false
user => "admin"
password => "****"
ssl => false
ssl_certificate_verification => false
index => "%{[@metadata][syslog]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}Клиенты системы
Рассмотрев общую идею, перейдем к реализации. Первым делом мы разделили клиентов системы сбора логов на доверенных и недоверенных. Доверенные приложения/хосты имеют возможность авторизоваться и писать в очередь сообщений (напрямую или через посредника, о котором расскажем чуть позже). Недоверенные — приложения, не имеющие прямого доступа к RabbitMQ.
Объясним на примере:
Доверенный клиент — стандартный инфраструктурный хост компании.
Недоверенный клиент — LiveCD, производящий инсталляцию ОС на хост клиента (клиент потенциально может вмешаться в процесс и получить доступ к инфраструктуре RabbitMQ).
Далее было необходимо решить вопрос прозрачного (для приложений) перехода от syslog protocol к AMQP. Для обеспечения конвертации трафика syslog в AMQP отлично подходит syslog-ng. Наши основные ОС, используемые в инфраструктуре, — CentOS7 и 8. Для седьмой версии ОС необходимо собрать пакет с новой версией сервера, поскольку версия из штатного репозитория не поддерживает AMQP. С восьмеркой таких проблем нет. Далее на инфраструктурных (доверенных) инсталляциях необходимо заменить стандартный rsyslog на syslog-ng и настроить взаимодействие с кластером Rabbit:
destination d_ampqp {
amqp(
vhost("/")
host("AMQP_HOST")
port(5672)
exchange("eventtask")
exchange-type("direct")
routing-key("eventtask")
body("$(format-json —-scope core)")
persistent(yes)
username("RABBIT_USERNAME")
password("RABBIT_PASSWORD")
);
};Для недоверенных хостов или хостов, на которые невозможно установить syslog-ng, необходим внешний syslog-ng-приемник.
Мы решили разместить такой приемник непосредственно на хостах RabbitMQ, чтобы минимизировать лишний служебный трафик, но это не правило — группа хостов syslog-ng вполне может работать отдельно от брокера. Число приемников мы сделали равным числу хостов кластера Rabbit, выбор хоста осуществляется через DNS-RoundRobin. Такая схема содержит недостаток в виде возможной потери сообщений при отказе одного из хостов. Эта проблема решается достаточно легко через перевод хостов-приемников на кластеризованный IP через связку pacemaker/corosync (это простой в использовании механизм, о котором мы можем рассказать в отдельной статье).
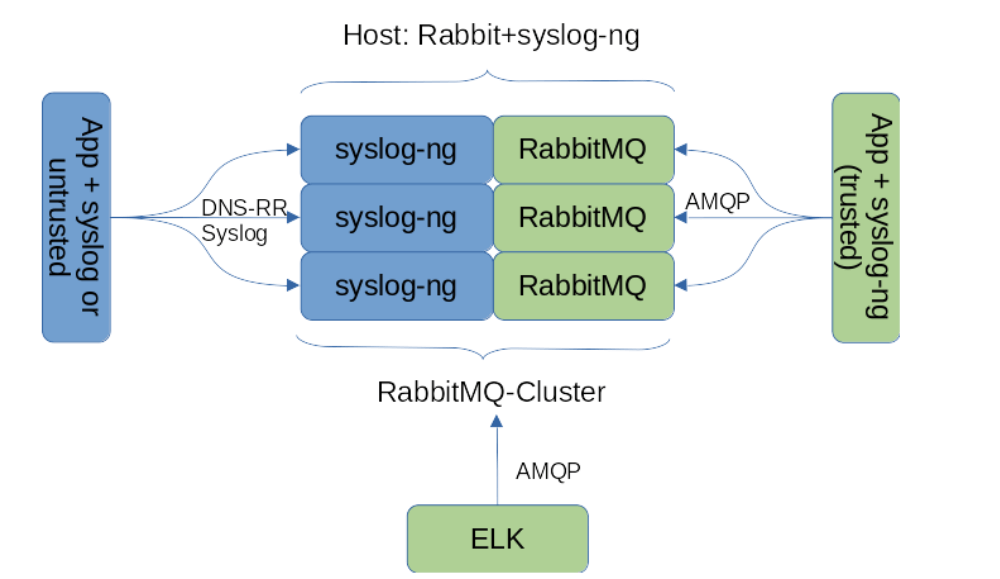
Преимущества итоговой системы:
Отказоустойчивость — система способна обрабатывать большие потоки сообщений без потерь, выдерживает выход из строя любого отдельного хоста, обеспечивающего сервис.
Гибкость — производительность системы легко наращивать, система способна принимать сообщения от любого syslog-клиента: от продвинутых (syslog-ng) до самых консервативных (Microsoft, etc).
Экономичность — система позволяет не закладывать избыточные ресурсы на обработку логов. «Шторм» сообщений не приводит к их потере.
В нашем блоге на сайте hostkey.ru вы сможете найти больше интересных публикаций.
