Андрей Себрант (Яндекс): Бизнес в Эпоху Искусственного Интеллекта
Сейчас все говорят о новой революции, которую несет искусственный интеллект и машинное обучение. Умные алгоритмы проникают во все сферы жизни: от поисков бозона Хиггса, до выбора фильма на вечер. Самые передовые компании уже активно внедряют эти технологии в свои продукты и маркетинг. Персонализированные рекомендации, реклама, интерфейс сайта — все это не какая-то черная магия, а уже доступные технологии.
На отечественном рынке, без сомнения, самой передовой компанией, использующей мощь машин, является Яндекс. В своем докладе на #amoCONF директор по маркетингу сервисов Яндекс, Андрей Себрант, рассказал о наступившем будущем и возможностях, открывающихся каждой компании. Оптимизируйте ваш бизнес под тенденции будущего!
Disclaimer. Эта статья — расшифровка выступления Андрея Себранта. Есть люди, которые экономят время и любят текст, есть те, кто не может на работе или в дороге смотреть видео, но с радостью читает Хабр, есть слабослышащие, для которых звуковая дорожка недоступна или сложна для восприятия. Мы решили для всех них и вас расшифровать отличный контент. Кто всё же предпочитает видео — ссылка в конце.
Машинный интеллект и коммодитизация технологий
Добрый день! Здравствуйте, все собравшиеся в «Олимпийском». Спасибо за подводку. Я, правда, собираюсь рассказывать о будущем, используя при этом страшные слова. Я подозреваю, что термин «коммодитизация технологий» мало кому известен — не стесняйтесь, он вообще мало кому известен. Но он полезен, он простой на самом деле. Я про него расскажу дальше. И да, была правильная фраза: я собираюсь рассказывать про будущее, которые наступило, наступает, на некоторых наступило так, что только соскребать остаётся.
Беда в том, что за 20 лет моей работы в интернете мне казалось, что всё офигенно, быстро происходит — как классно! Это я теперь понимаю, что всё, что происходило эти 20 лет, было чудовищно тормозным процессом, невероятно медленным, а быстро начинается сейчас. Вообще, весь доклад, рассказ — построен по принципу странной мозаики, мозаики, которая… Даже нет, лучше так скажу: по принципу рассыпанного пазла. Если в результате разглядывания этих кусочков у вас потом в голове начнёт складываться картинка из этих кусочков пазла — цель достигнута, если нет — ну, не знаю, посмотрите запись, попробуйте — может, в итоге сложится. Потому что это не поваренная книга — я не буду рассказывать, как что сделать. Я буду рассказывать, в каком будущем, буквально через несколько лет, через 3–4–5 (не больше) вам предстоит организовывать свои продажи, привлекать клиентов, коммуницировать как-то с людьми, которые имеют к вам отношение.
Будущее, которое уже наступило. Два кейса не про интернет и не про маркетинг.
Но расскажу я немножко странные кейсы. Вот история мужика из Калифорнии. Я не случайно привёл его возраст на слайде — мужику 65 лет, он даже меня старше. У него проблема: у него жена, которая очень любит свою чистенькую лужайку (но это Калифорния, там нет двухметровых заборов вокруг лужаек); на лужайку ходят соседние коты и гадят. Как решается эта задача в 2016 году?
Соседские коты и любимый газон: как решить проблему с женой
В 2016 году этот человек, Роберт Бонд, докупает немножечко железа к своему домашнему компьютеру, подключает к нему уже стоящую камеру наружного наблюдения, которая смотрит за лужайкой и дальше проделывает несколько необычную вещь — он загружает доступный, бесплатный софт «опен-сорсный», который является нейронной сеточкой и начинает обучать эту нейронную сеточку распознавать котов на изображении с камеры.
И задача сначала кажется тривиальной, потому что, уж если чему-то учить легко — это котам, потому что котами завален интернет, десятки миллионов котов в интернете. Если бы всё было так просто — распознавать такого «дневного» кота можно обучить на «дата-сете», который загружается просто со скоростью пропускного канала. Но дела обстоят хуже: в реальной жизни коты ходят гадить в основном ночью. Картинок ночных котов, писающих на лужайке, в интернете практически нет. Человеку пришлось, как делаем мы, как делает любая компания, занятая нормальной data-science и обучением нейронных сеточек… Окей, мы докопим картинки дополнительно, сделаем их сами; сеточка научилась распознавать ночных котов тоже очень надёжно…

И после этого — последний шаг: на выход этого компьютера подключается электроуправление вентилем. Вентиль стоит на трубе, которая ведёт к опрыскивателю. Поэтому как только кот заходит на лужайку и хочет приспособиться, его начинают поливать — кот сваливает.
Задача, таким образом, решена, жена довольна, коты не ходят, а всё это странное чудо — нейронные сети, обучающиеся распознавать котов, выяснивших, что в интернете, чёрт, не хватает исходных изображений для тренировки. Окей, мы тебя доучим! Она доучилась. Это, наверное, единственная в мире нейронная сетка, которая умеет распознавать ночных котов.
Всё это делается человеком, который не является гиперпрограммистом, не работал в «Гугле» или «Яндексе» всю свою жизнь, и с помощью вот такого вот железа, в общем-то, достаточно дешёвого, компактного и простого.
Японские огурцы: как помочь маме
Другая история. Через океан от Калифорнии, на маленькой домашней ферме японцы выращивают огурцы. Огурцы на этой форме принято сортировать на 9 разных категорий.
Этой сортировкой вручную занимается старенькая мама. Ей тяжело — она 8 часов в день стоит возле конвейера, и она всю жизнь… Ну, не всю, но последние несколько лет жизни посвятила тому, что она понимает, глядя на огурец (его пупырышки, цвет, размер и форму), в какую из девяти категорий его надо отнести. У них беда — они не могут даже нанять временного рабочего, потому что рабочего надо несколько месяцев учить этому славному процессу — распознавать огурцы. Дальше вы, наверное, уже догадались.

Это был снова компьютер. На этот раз, правда, сеточка была в облаке, потому что компьютер Raspderry Pi достаточно маломощный. Сеточку обучили тому, что делает мама в качестве тренировочной выборки, использовали действие самой мамы: вот фотография огурца, куда его мама отнесла. После того, как мама проделала так 10 тысяч раз: «Сеточка, вот тебе новая огурец, ты понимаешь, какая у него категория?» «Понимаю», — говорит сеточка.

И всё это воплотилось вот в такую конструкцию: конвейер, по нему едут огурцы, перед тем как упасть на конвейер, их разглядывает камера, вдоль конвейера стоят толкатели и в ящик соответствующей категории сталкивают огурец. Опять же, это решение 2016 года. Оно иллюстрирует очень важный момент, который сейчас плохо осознают. Он написан на экране:

То, что мы привыкли называть информационными технологиями, в сущности, перестало быть информационными. Это операционные технологии: обученная машина сама совершает действия, а не сообщает нам; не раздаётся звонок — «Кот пришёл. Что делать будешь? Повяжешь его полотенцем или как»? И высвечивает номер категории над проплывающим огурцом. «Ну вот, а теперь ты можешь своей царской рукой столкнуть»… Да нет! Человека вообще нет в этом процессе после того, как закончилось обучение. Это очень универсальная картинка, которая характеризует, как работает будущее, в котором интеллектуальные задачи (опознать кота, понять, к какой категории относится огурец) решают машины.
Информационные технологии стали операционными
И собственно говоря, это не наша какая-то блажь. И вообще, это не свойство только интернета и виртуальных каких-то вещей, происходящих в компьютере. Специально привёл слайд: General Electric — довольно немаленькая компания, работающая с колоссальными офлайновыми бизнесами, которые считают, что именно 2015 год стал тем годом, когда произошла эта конверсия — информационные технологии стали операционными, и они определяют наше будущее. И по сути нам, чтобы успеть за всем этим, надо думать, как в наших бизнес-процессах настроить тот же переход, потому что трансформация — всегда болезненная и не мгновенная вещь.
Но если не готовиться к этой информации сейчас, можно оказаться среди тех, на кого наступили. Хороший пример: на «Кодак» наступили, он думал, что хорошо защищён (такая технология!). На «Блэкберри» наступили — они искренне думали, что людям ценно давить на кнопочки, и никто не будет возить пальцами по экрану, пачкая его. Где «Блэкберри»?…
Наконец, ещё одна отсылка к авторитетам. В начале этого года в Давосе на Всемирном экономическом форуме собственно и были официально многократно произнесены вот эти самые слова: мы находится сейчас в самом центре четвёртой промышленной революции. Это промышленная революция происходит в основном за счёт бешеной скорости, с которой внедряется искусственный интеллект и машинное обучение.

Я ненавижу слова «искусственный интеллект» и сейчас объясню почему. Потому что на самом деле мы пытаемся в этом месте сравнить машину с собой и причём как-то испугать машину (она не боится): «Ты же никогда с нами не сравнишься! Мы же мыслители»! Понимаете, машина на протяжении всей истории человечества доказывала, что она может больше — больше потому, что мы так её придумываем.
Машина всегда может больше
Вот хороший пример, который я люблю приводить на куче лекций — это история про искусственную птицу. Мы вот это воспроизвести не можем. Мы и вправду понятия не имеем, как устроено каждое пёрышко в её крыле, какую функцию оно несёт в полёте. Да ещё и разнообразие этих пернатых крыльев в природе чудовищно!… А ещё есть летучие мыши.
Что такое «искусственная птица»?
Мы, правда, не только воспроизвести не можем и не сможем, судя по развитию технологий, в ближайшие несколько лет — мы и понять до конца не можем физику полёта с точностью, как каждый волосок в крыле работает. Но мы, поскольку мы всё-таки люди, человечество, были вдохновлены птицей как идеей полёта. И в этом смысле первой искусственной птицей был воздушный шар, за много веков до нас сегодняшних созданный. Потому что он позволил людям подняться в воздух.
Потом, через некоторое время, вернулись к идее крыла совершенно другого, с тем профилем, который птице неизвестен — он в статистике, без маховых движений может держать машину в воздухе. Зато у него есть реактивный двигатель, и эта машина стала возить нас через океан, чего птицы не могут.
Более того, в какой-то момент мы, человечество, улетели к звёздам… Окей, к Марсу! Пока не к звёздам, но по Марсу ползает этот «Куриосити» и селфи оттуда передаёт. Это же искусственная птица его туда принесла. Понимаете, то, что мы подумали про идею полёта и то, что должно быть искусственной птицей.

Слушайте, когда мне теперь говорят про искусственный интеллект… Ну мы ж не знаем, как устроено (показывает на голову)… Да! Точно так же, как мы не знаем ничего про птичье крыло. Это не помешало нам на той стадии, когда появились воздушные шары, придумать абаку и упростить некую операцию, на которую не способны животные, а вот мы устным счётом владеем — но, блин, так проще. Потом технологии помогли нам сделать ещё проще, а потом технологии дошли до тех самых нейронных сеток, которые обучаются сами — это важно! Они обучаются сами!
Что такое искусственный интеллект?
Если вспомнить пример с котом, никто не объяснял этой сетке формальные параметры отличия кота от младенца и от собаки. Сетка училась сама, разглядывая миллионы картинок котов и в итоге научилась. Мы не знаем как. Ну как мы сами обучаемся?
И собственно, то, о чём я сейчас говорю, то, что искусственный интеллект (машинный говорить всё-таки правильнее) будет иметь такое же отношение к нашему мозгу, как ракета к воробью — и делает жизнь такой интересной. Ракета не умеет чирикать и какать нам на голову. Воробей умеет.

При этом ракета, как вы догадываетесь, может: ядерный заряд на соседний континент, «Куриосити» — на Марс, спутник — на орбиту, чтобы спутниковый интернет работал, много чего, но это абсолютно не имеет отношения к воробьям. Точно то же самое произойдёт с машинным интеллектом: он будет делать вещи, которые мы сообразить не можем, что можно делать мозгом, а она сможет.

При этом в параллель произошла ещё одна интереснейшая история, которая касается не столько сервисов… Потому что я говорю сейчас про конкретные сервисы — распознавание изображения, по сути та функция, вокруг которой строились оба примера, вокруг которой строится поиск картинок, куча ещё каких-то вещей. Но это всё-таки конкретный сервис. Можно сказать, персонализация — у меня будут про это отдельные примеры. Это тоже отдельный сервис — понять что-то про пришедшего к вам покупателя. Но это сервис.
Не только сами сервисы, но и интерфейсы
Самообучающиеся системы, нейронные сеточки в первую очередь позволили решить другую интересную задачу которая абсолютно вот так вот — поперёк всех сервисов. Эта задача — интерфейсная.
Ещё некоторое время назад существовала такая проблема (правда, существовала): надо привести информацию в машиночитаемый вид, чтобы машина могла начать с ней работать. Нет больше такой проблемы! Потому что… Что такое машиночитаемый вид? Она текст может прочитать может хоть с рукописи, хоть с экрана, хоть с наскального рисунка, если там текст есть. Она может, более того, понять, что на этой картинке произошло, если это картинка. Она может услышать, что было произнесено вслух и превратить это в печатный текст, если это вам зачем-то необходимо; хуже того — смысл всего этого понять…
Распознавание речи, изображений, синтез речи
И вот это — самая интересная история, которая сейчас происходит. То, что происходит ровно сейчас офигенно сильно изменит жизнь, скажем, через какие-нибудь пару лет. Для того чтобы машина научилась не тупо слушать и просто в буквы переводить звуки, необходимо было научить её какому-то смыслу. Вот здесь началась интересная задача, практическая совершенно задача, которую снаружи не видно, а это — огромный прорыв, который был решён, например, поисковыми системами, которым приходилось решать задачу…

Вот знаете, при некоторых психических заболеваниях (если в зале есть психологи — они знают такой тест) дают четыре объекта или больше и говорят: «Какой здесь лишний? Найди». Во многих случаях при некоторых заболеваниях совершенно удивительные, странные ответы, которые нам кажутся бредовыми. Так вот, такая же задача для машины: четыре объекта — найди лишний.

И оказывается, что в старой, традиционной модели лингвистического анализа это большая засада. Потому что, если мы поглядим на объект № 2 и объект № 4, то выяснится, что пока это написанный текст и ударение не слышно — зАмок и замОк не отличаются. Более того, даже углублённый анализ прилагательного показывает что это что-то, описывающее материал, из которого, видимо, изготовлено это существительное. И казалось бы, эти два объекта являются очень близкими (указывает на «Каменный замок» и «Железный замок»), а этот («Старая крепость») — вообще никуда, тут ничего похожего нет. Но мы-то с вами понимаем, что история совсем другая: вообще говоря, вот этот объект лишний («Железный замок»), а вот эти — три одинаковых. Машине как это объяснить? Особенно, когда речь заходит о том, что здесь вообще изображение и, будем для простоты, точнее для реалистичности предполагать, что это изображение не содержит прикартиночного текста — например, на странице, где оно найдено. Просто изображение. В фотоальбоме. Как его классифицировать? Выводить ли его по запросу «старая крепость»?
И оказалось, что существует такая вещь, которая казалось некоторое время ещё ненаучной фантастикой, как очень многомерное пространство смыслов, в котором можно научить машину строить некоторые вектора. Куски этих векторов приведены под картинками, и даже беглый взгляд показывает, что эти (первые три картинки) в общем похожи — ну, ребят, здесь что-то 8, 7, 1, 3…, а тут — бррр, это явно что-то совсем не то. То есть вот эти три торчат куда-то в одно место, в одну область, примерно в одну область этого чудовищного многомерного пространства смыслов, а четвёртый — куда-то вот туда.
И это решает задачу понимания смысла хотя бы с точки зрения того, какие объекты по смыслу близки друг к другу. Прикольно, что эта задачка уже сейчас, например, решать примерно похоже задачи, позволит тому же «Майкрософту» обеспечить великолепный синхронный перевод в «Скайпе». Потому что именно в тот момент, когда вместо классических лингвистических моделей, которые спотыкаются на этой проблеме (зАмок — замОк), подключили нейронные сетки — переводиться стал смысл. А дальше, ребят, дальше они уже подключают язык за языком. В тот момент, когда у тебя пространство этих векторов смысла заполнено, его проекция на любой язык — чисто техническая операция. В этот момент языковые проблемы на нашей планете исчезают как класс.
Это очень нетривиальная история! Я не про то, что гениальный «Яндекс», гениальный «Майкрософт», гениальный «Гугл» это сейчас делают. Я про то, что это меняет жизнь так, как мы представить себе не могли, как-то вот так — с полпинка. Мы не увидим даже, что вдруг в интерфейсе всё само запереводилось. Оно же вот так будет выглядеть — не как какой-то отдельный суперсервис.
Покушение на традиционную науку? Нет, симбиоз с ней!
Хочу показать, что происходит с традиционными областями специально на примере науки, а не какого-то коммерческого продукта. Вот смотрите, наука, которая касается всех нас — метеорология. Все хотим понимать: зонтик-то брать надо, дождик-то сегодня будет? Может, на самом деле не зонтик надо, а просто одеться потеплее, и дождя не будет, а колотун страшный.
И вот тут я скажу сейчас про яндексовое решение, потому что оно, опять же… Я не хочу здесь продавать «Яндекс», он достаточно велик и без моих продаж. Эти вещи с метеорологией сейчас проделывают все крупные компании, занятые прогнозированием метеоявлений в мире: и Weather Channel, и другие, IBM подключился с точки зрения машинного обучения. У нас, к счастью, и прогноз есть внутри (один из сервисов «Яндекса»), и, чего-чего, а машинного обучения у нас хватает.
О прогнозе погоды и «Метеуме»
Итак, появляется «Метеум». Краткая экскурсия о том, что такое метеопрогноз. Это офигенный совершенно массив разнородных данных, льющий в реальном времени в суперкомпьютеры. Данные берутся из того, что сейчас на экране. Это десятки метеорологических спутников, из которых льётся информация о том участке земли, который под ними расположен, в самых разных частях спектра. Это порядка десяти тысяч метеостанций, которые дают (но, к сожалению, только на поверхности земли) информацию о состоянии атмосферы: её температуру, направление ветра, скорость ветра, влажность, химический состав, если надо, степень освещённости солнцем — дофига всего.

Ну и поскольку, вообще говоря, атмосфера трёхмерна, и для того, чтобы смоделировать всякие такие процессы в ней, которые требуют ещё изменения чего-то по высоте (облака же на определённой высоте, а не просто столбом стоят) — есть ещё несколько, к сожалению, достаточно малых для размеров нашей Земли станций, откуда регулярно, несколько часов в сутки запускаются метеозонды — здоровенный воздушный шар, наполненный гелием (поэтому он взлетает), который несёт набор датчиков, которые умеют мерить всё то же самое (температуру, скорость, влажность и так далее).

И весь набор этих данных льётся в несколько гипер-, суперкомпьютерных центров, которые расположены по миру, и эти данные обрабатывают несколько построенных физиками-теоретиками, специалистами по динамике сжимаемой жидкости (именно так на нормальном «физическом» языке называется окружающая нас атмосфера)… Этих моделей счётное количество, их реально мало, и тяжелейше они создавались, десятилетиями, трудом кучи гениальных мозгов, очень сильных физиков, а потом превращались в исполняемый код не менее гениальными программистами и математиками.
Эти модели дают, в общем, дают какой-то примерно осмысленный прогноз. Специальный пример: ни одна из этих моделей в такой ситуации не предскажет +30 (солнышко). Но видно, что они врут (примерно такая погода, как сейчас у нас во дворе) — то ли чуть больше нуля, то ли чуть меньше нуля, то ли посыплет снежок, то ли дождичек, то ли что?
Окей, давайте мы подключим сюда системку машинного обучения — ту, которая у нас называется «Матрикснетом» (со всякими обвесками ещё). И скажи мне, система машинного обучения, у тебя задачка стоит: вот есть куча-куча-куча прогнозов (скажем, на завтра на 9 утра в районе «Олимпийского»). Ты их сейчас, эти прогнозы, записываешь — завтра ты их сравнишь с результатами фактических наблюдений, потому что завтра мы будем знать в 9 утра, что здесь произошло. И так непрерывно, и так для всей Земли. Дата-центры у нас большие.
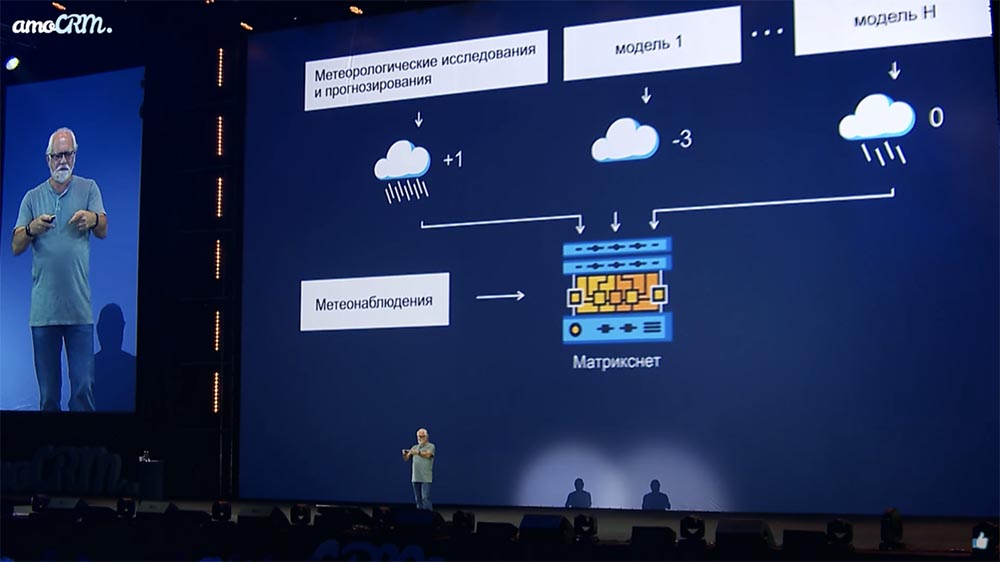
Твоя задача — обучаться всё время, сравнивая, как разошлась каждая из этих моделей с фактическим наблюдением в данной точке; научиться минимизировать эту дельту, научиться генерить свой собственный прогноз, который имел бы дельту (расхождение с действительностью, по температуре или по количеству осадков или ещё по какой-то метрике) меньшую, чем расхождение любой из этих моделей по отдельности.
При этом заметьте, важная вещь: мы не учим эту машину физике, у нас нет штата профессоров, как в Институте физики атмосферы Академии наук. Это машинка учится сама минимизировать некоторый параметр, то есть делать более точный прогноз. Почему? Да мы понятия не имеем! Мы ещё в неё дополнительные данные загружаем, которые не удаётся загрузить в модель. Например, из общих соображений мы понимаем, что, вообще говоря, по разному устроена жизнь в атмосфере над разными типами подстилающей поверхности, то есть над озером, над еловым лесом или лиственном лесом или городской застройкой атмосфера себя ведёт сильно по-разному.
Но мы на «Яндекс.Картах» довольно актуальную информацию видим, в отличие от этих моделей, в которые эту информацию когда-то, сто лет назад заложили, а потом этот лес вырубили, а там город построили… Но у нас-то более-менее свежая информация есть со спутниковых карт наших. Мы можем её загнать и в итоге заставить сгенерить прогнозы, которые уже сейчас в среднем оказываются точнее, чем любой из прогнозов этих гигантских моделей. А поскольку мы запустили «Метеум» всего лишь меньше года назад, у него сейчас повысится точность, потому что для того, чтобы машинке обучиться хорошо предсказывать… Ну, погода так устроена — это штука с погодной цикличностью. То есть пока ты хотя бы одну осень не пережил, как-то предсказывать осеннюю погоду надёжно сложно.
И вот сейчас она доходит до того момента, когда она переживёт каждый сезон хотя бы по одному разу. Мы её запускали как раз поздней осенью. Теперь для неё зима не будет новинкой — зиму она однажды уже изучала. И это повысит прогнозирование погоды без улучшения нашего понимания сути протекающих в атмосфере процессов. Ну, вы понимаете, я специально акцентирую на этих словах, потому что это то, что будет происходить с вашей работой. Машина рядом с вами будет решать важные, умные, интеллектуальные задачи, при этом абсолютно не понимая, что на самом деле происходит. Ей никто и не объяснял, как мы этой ничего не объясняли про физику.
Персонализация: неизбежное будущее коммуникации с клиентами
И поэтому сейчас я всё-таки чуть-чуть расскажу о том, что важно для конкретного бизнеса. Наука наукой, но мы же про бизнес. Вот смотрите, история про персонализацию здесь уже звучала: Михаил в прекрасном совершенно докладе по поводу обновления amoCRM как раз говорил, что, ребят, теперь вы можете персонально этого человека догнать объявлениями про то, что он у вас ещё не докупил.
Это правильно, это идеально, что это становится нормой в самых разных системах, но не всё на свете управляется только из amoCRM. Вот, amoCRM, например, позволяет догнать человека на других сайтах (у вас, возможно, есть свой собственный сайт).
Технологии таргетинга
Здесь возникает смешной парадокс 2016 года: реклама оказывается технологически гораздо более продвинутой, чем всё остальное на сайте. Ну вы же понимаете: для простоты беру сейчас не приложение, а просто сайт — у вас на сайте может висеть статический контент, который там висит последние три года, вот просто тупо, без какой-либо интерактивности, как во времена зарождения «веба», 20 лет назад. А рекламный код, кусочек кода, гугла и яндекса или ещё какой-нибудь хорошей сетки, — он страшно умный чёрный ящик, который в тот момент, пока эта страница отрисовывается, всё понимает про пришедшего пользователя, обращается к базе данных с сотней объявлений и делает умные, интуитивные предположения, какой из них имеет большую вероятность клика. Потому что на самом деле оптимизированный параметр, когда вам показывают объявление, — это вероятность клика. То есть куча всякой математики, «машин-лёрнинга» и всего на свете. А страница — как есть, так и есть.

Машинный интеллект учится у людей
Вы же понимаете, что так долго не будет? Вы же понимаете, что достаточно скоро иметь сайт, который не настолько же умён, как реклама вокруг… ну, ква… ну, противно на таком сайте находиться?! Противно заходить на сайт, морда которого одинакова для всех, на карточку товара, которая одинакова для всех и так далее, и так далее, и так далее.

То есть история о том, что персонализация настигнет вас везде. И чем дальше, тем больше она будет работать всё лучше, потому что, ещё раз: машины учатся у людей. Это очень важно, что не мы её обучаем, мы чего-то нового не поняли и поэтому нам нечему обучить машину. Да она сама всё время самообучается, потому что всё время происходят эти миллионы, миллиарды кликов, которые она берёт себе.
Crypta
И да, вот — оказывается… Немножко пугающая такая немножко блок-схема, сделанная из более технической презентации. Например, технология, которая у нас называется Криптой, позволяет определить интересы человека, много всего крутится и в итоге «чёрный ящик» решает, что ему нарисовать на «морде» какого-то «маркета».
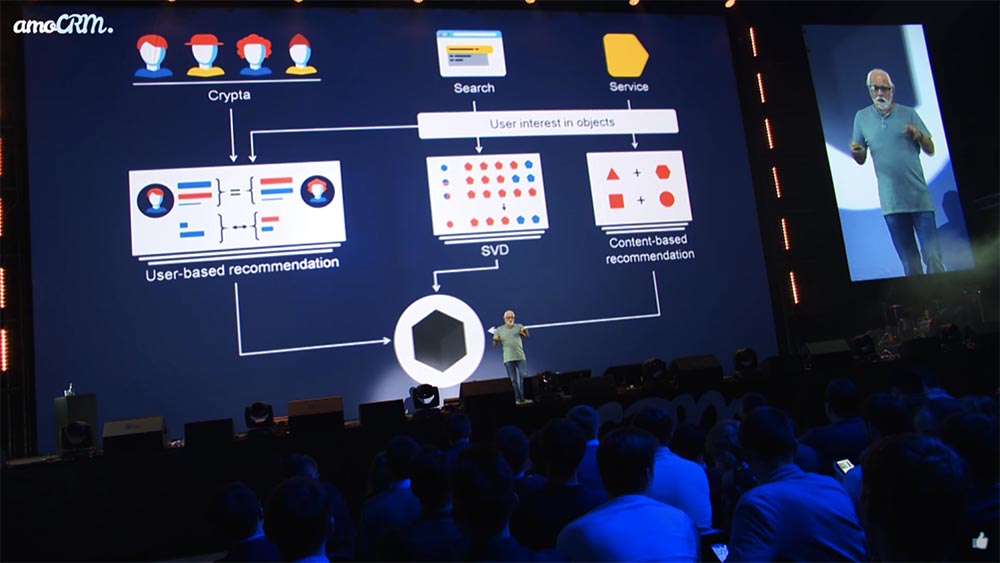
Хватит усреднять и сегментировать!
В переводе на привычные маркетинговые термины это означает: хватит усреднять, хватит сегментировать, можно работать на уровне персонализации. Этот привычный коктейль из нескольких компонентов способен удержать наш слабенький мозг. Машине не нужен. Ей не нужно разбивать на десять категорий или пойти в какое-нибудь RFM-сегментирование, где, опять же… Мало кто из продвинутых маркетологов, просто мало кто из людей может больше двадцати сегментов удержать в голове. А машине пофигу, ей не нужны сегменты — она работает прямо с сотней миллионов, как, например, в нашем случае, различных пользователей.
При этом умный алгоритм показывает не только похожее (человеку будет уныло), он может открывать что-то, он может показать человеку — «Вау! Как я мог об этом не знать?». Зашёл на страницу — и текст; залипает…
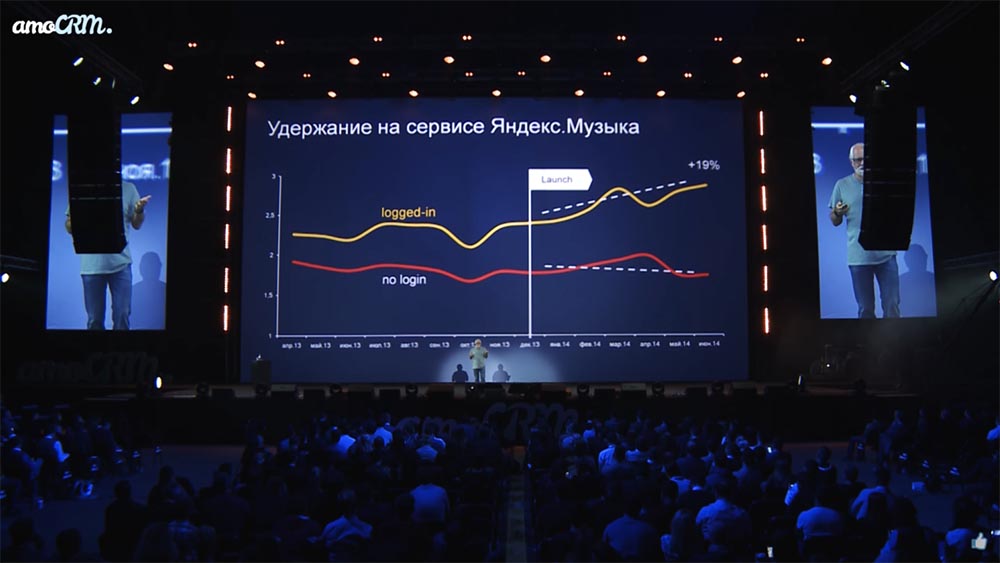
Можно ли уйти от «похожести»?
И так работают, например, все современные стриминговые сервисы, так работает «Ютуб». Рекомендации начинают подстраиваться под каждого конкретного человека. В качестве иллюстрации — график, как увеличивается время пребывания на сервисе в тот момент, когда включаешь «чёрный ящик»… и-и-и… человек начинает залипать, потому что ему рекомендуют песенки, которые он всё время хочет послушать.

«Яндекс.Дзен»
Или как это происходит в нашем более продвинутом, совсем недавно запущенном, причём в куче разных стран, убийце времени под названием «Дзен». Такой сервис. Он либо в «ланчере» на мобильном, либо в браузере на мобильном. Существует оптимизированная под каждого персонально человека лента контента, самого разного: новости, картинки, котики, рецепты — что человек хочет почитать.

Но она персонализирована под него абсолютно автоматически. Там мы впервые убедились, что нам всё равно, где сервис запускать — в Бразилии, Индонезии или России. Нам не надо заниматься долго познанием культурных особенностей, особенностей потребления контента в этой стране — это всё делает алгоритм.
Социальный эксперимент «Яндекса»
Мы проделали вот такой эксперимент на нашей маркетинговой конференции в «Яндексе» в конце июня этого года. Проделывали на конференции, потому что есть некоторые юридические тонкости и технические тонкости, почему мы не могли это вынести на улицу. Ну, на улице это будет через год.

Вот человек проходит мимо монитора. Камера не просто показывает его изображение, а у него над головой какая-то фигня крутится. Человек наводит с установленным приложением камеру своего смартфона на людей других в холле, а над ними другие картинки крутятся. Эти картинки — это интересы этих людей. Мы их об этом не спрашивали. И я не буду рассказывать, какая магия, затем что…
Подводя итоги…
Я вот представляю, что бы, если бы я сейчас… В каком кармане у меня смартфон?
Ну, вот здесь это не сработает. Но представляете, я провёл — и знаю, о чём с каждым из вас поговорить.
Подводя итоги, я говорил. Вот смотрите, этот слайд — просто для иллюстрации. Когда я говорил о коммодитизации технологий — это означает, что всё стало доступным из розетки, что это стало «коммодити», как электричество. Никто из нас не электрик и никто из нас не знает, как запустить дизель-генератор. Ну, большинство. Но мы прекрасно знаем, что у нас есть розетка в квартире и в неё можно воткнуть: хочешь — стиральную машину, хочешь — утюг. Так вот точно так же сейчас можно работать с машинными обучениями, с машинным разумом, потому что есть «опен-сорсный» код, есть API — здесь просто список того, что доступно зачастую бесплатно (чтобы не быть голословным).
И, как главный результат, собственно, главный финальный, итоговый слайд.
2020+: важнейшие умения менеджера
Ребят, меня когда просили это сделать этот слайд: «Ну, про двадцать-двадцать что-нибудь расскажешь?» Я говорю: «Да, легко». Потому что сводится к трём основным тезисам.

Вам предстоит работать вместе с творческими умными машинами (хотите, не хотите — предстоит). Это чертовски тяжело. Вот по собственному опыту в «Яндексе» знаю. Вот здесь (мне плохо видно вас из-за слепящих прожекторов) прошу вслух ответить на вопрос: здесь есть люди, у которых в подчинении есть другие сотрудники (из зала отвечают «да»)? Окей, вам легко было делегировать им (из зала — «нет»)? Ожидаемо. Нам тоже! Представьте себе: вам предстоит делегировать машинам, а с машиной не пойдёшь вечером пивка или чего-нибудь попить и сказать: «Вася, ну что же ты… Давай ты так больше не будешь». Эта машина реально не сможет вам объяснить, почему она приняла это решение. Но если не научиться с ней работать (да, она иногда будет «факапить», как любой из нас и любой из наших сотрудников), то тогда — просто «крышка».
Закон Кларка
Это самый последний слайд. Это один из законов Кларка. Я выхожу с седым хвостом и рассказываю какие-то странные вещи. Вот есть закон, который гласит: если человек моего возраста выходит, начинает что-то нести про то, что — «Этого никогда не будет! Человек есть мера всех вещей, поэтому машина никогда не будет… (глубоко вздыхает) Это возрастной консерватизм, ребят, простите».

А когда человек говорит, — «Слушайте, несмотря на весь мой консерватизм, это будет!», — он, скорее всего, прав, если он в этом деле эксперт. А я всё-таки в интернете последние двадцать лет варюсь.
Поэтому спасибо! Так или иначе, но это случится!
