Яндекс открывает ClickHouse
Сегодня внутренняя разработка компании Яндекс — аналитическая СУБД ClickHouse, стала доступна каждому. Исходники опубликованы на GitHub под лицензией Apache 2.0.

ClickHouse позволяет выполнять аналитические запросы в интерактивном режиме по данным, обновляемым в реальном времени. Система способна масштабироваться до десятков триллионов записей и петабайт хранимых данных. Использование ClickHouse открывает возможности, которые раньше было даже трудно представить: вы можете сохранять весь поток данных без предварительной агрегации и быстро получать отчёты в любых разрезах. ClickHouse разработан в Яндексе для задач Яндекс.Метрики — второй по величине системы веб-аналитики в мире.
В этой статье мы расскажем, как и для чего ClickHouse появился в Яндексе и что он умеет; сравним его с другими системами и покажем, как его поднять у себя с минимальными усилиями.
Зачем кому-то может понадобиться использовать ClickHouse, когда есть много других технологий для работы с большими данными?
Если вам нужно просто хранить логи, у вас есть много вариантов. Вы можете загружать логи в Hadoop, анализировать их с помощью Hive, Spark или Impala. В этом случае вовсе не обязательно использовать ClickHouse. Всё становится сложнее, если вам нужно выполнять запросы в интерактивном режиме по неагрегированным данным, поступающим в систему в реальном времени. Для решения этой задачи, открытых технологий подходящего качества до сих пор не существовало.
Есть отдельные области, в которых могут быть использованы другие системы. Их можно классифицировать следующим образом:
- Коммерческие OLAP СУБД для использования в собственной инфраструктуре.
Примеры: HP Vertica, Actian Vector, Actian Matrix, EXASol, Sybase IQ и другие.
Наши отличия: мы сделали технологию открытой и бесплатной. - Облачные решения.
Примеры: Amazon Redshift и Google BigQuery.
Наши отличия: клиент может использовать ClickHouse в своей инфраструктуре и не платить за облака. - Надстройки над Hadoop.
Примеры: Cloudera Impala, Spark SQL, Facebook Presto, Apache Drill.
Наши отличия:- в отличие от Hadoop, ClickHouse позволяет обслуживать аналитические запросы даже в рамках массового сервиса, доступного публично, такого как Яндекс.Метрика;
- для функционирования ClickHouse не требуется разворачивать Hadoop инфраструктуру, он прост в использовании, и подходит даже для небольших проектов;
- ClickHouse позволяет загружать данные в реальном времени и самостоятельно занимается их хранением и индексацией;
- в отличие от Hadoop, ClickHouse работает в географически распределённых датацентрах.
- Open-source OLAP СУБД.
Примеры: InfiniDB, MonetDB, LucidDB.
Разработка всех этих проектов заброшена, они никогда не были достаточно зрелыми и, по сути, так и не вышли из альфа-версии. Эти системы не были распределёнными, что является критически необходимым для обработки больших данных. Активная разработка ClickHouse, зрелость технологии и ориентация на практические потребности, возникающие при обработке больших данных, обеспечивается задачами Яндекса. Без использования «в бою» на реальных задачах, выходящих за рамки возможностей существующих систем, создать качественный продукт было бы невозможно. - Open-source системы для аналитики, не являющиеся Relational OLAP СУБД.
Примеры: Metamarkets Druid, Apache Kylin.
Наши отличия: ClickHouse не требует предагрегации данных. ClickHouse поддерживает диалект языка SQL и предоставляет удобство реляционных СУБД.
В рамках той достаточно узкой ниши, в которой находится ClickHouse, у него до сих пор нет альтернатив. В рамках более широкой области применения, ClickHouse может оказаться выгоднее других систем с точки зрения скорости обработки запросов, эффективности использования ресурсов и простоты эксплуатации.

Карта кликов в Яндекс.Метрике и соответствующий запрос в ClickHouse
Изначально мы разрабатывали ClickHouse исключительно для задач Яндекс.Метрики — чтобы строить отчёты в интерактивном режиме по неагрегированным логам пользовательских действий. В связи с тем, что система является полноценной СУБД и обладает весьма широкой функциональностью, уже в начале использования в 2012 году, была написана подробная документация. Это отличает ClickHouse от многих типичных внутренних разработок — специализированных и встраиваемых структур данных для решения конкретных задач, таких как, например, Metrage и OLAPServer, о которых я рассказывал в предыдущей статье.
Развитая функциональность и наличие детальной документации привели к тому, что ClickHouse постепенно распространился по многим отделам Яндекса. Неожиданно оказалось, что система может быть установлена по инструкции и работает «из коробки», то есть не требует привлечения разработчиков. ClickHouse стал использоваться в Директе, Маркете, Почте, AdFox, Вебмастере, в мониторингах и в бизнес-аналитике. ClickHouse позволял либо решать задачи, для которых раньше не было подходящих инструментов, либо решать задачи на порядки эффективнее, чем другие системы.
Постепенно возник спрос на использование ClickHouse не только во внутренних продуктах Яндекса. Например, в 2013 году, ClickHouse применялся для анализа метаданных о событиях эксперимента LHCb в CERN. Система могла бы использоваться более широко, но в то время этому мешал закрытый статус. Другой пример: open-source технология Яндекс.Танк внутри Яндекса использует ClickHouse для хранения данных телеметрии, тогда как для внешних пользователей в качестве базы данных был доступен только MySQL, который плохо подходит для данной задачи.
По мере расширения пользовательской базы, возникла необходимость тратить на разработку чуть больше усилий, хоть и не очень много по сравнению с трудозатратами на решение задач Метрики. Зато в награду мы получаем повышение качества продукта, особенно в плане юзабилити.
Расширение пользовательской базы позволяет рассматривать примеры использования, которые без этого едва ли пришли бы в голову. Также это позволяет быстрее находить баги и неудобства, которые имеют значение в том числе и для основного применения ClickHouse — в Метрике. Без сомнения, всё это повышает качество продукта. Поэтому нам выгодно сделать ClickHouse открытым сегодня.
Давайте попробуем работать с ClickHouse на примере «игрушечных» открытых данных — информации об авиаперелётах в США с 1987 по 2015 год. Это нельзя назвать большими данными (всего 166 млн. строк, 63 GB несжатых данных), зато вы можете быстро скачать их и начать экспериментировать. Скачать данные можно отсюда.
Данные можно также скачать из первоисточника. Как это сделать, написано здесь.
Для начала, установим ClickHouse на один сервер. Ниже также будет показано, как установить ClickHouse на кластер с шардированием и репликацией.
На Ubuntu и Debian Linux вы можете установить ClickHouse из готовых пакетов. На других Linux-системах, можно собрать ClickHouse из исходников и установить его самостоятельно.
Пакет clickhouse-client содержит программу clickhouse-client — клиент ClickHouse для работы в интерактивном режиме. Пакет clickhouse-server-base содержит бинарник clickhouse-server, а clickhouse-server-common — конфигурационные файлы к серверу.
Конфигурационные файлы сервера находятся в /etc/clickhouse-server/. Главное, на что следует обратить внимание перед началом работы — элемент path — место хранения данных. Необязательно модифицировать непосредственно файл config.xml — это не очень удобно при обновлении пакетов. Вместо этого можно переопределить нужные элементы в файлах в config.d директории.
Также имеет смысл обратить внимание на настройки прав доступа.
Сервер не запускается самостоятельно при установке пакета и не перезапускается сам при обновлении.
Для запуска сервера, выполните:
sudo service clickhouse-server start
Логи сервера расположены по-умолчанию в директории /var/log/clickhouse-server/.
После появления сообщения Ready for connections в логе, сервер будет принимать соединения.
Для подключения к серверу, используйте программу clickhouse-client.
clickhouse-client
clickhouse-client --host=... --port=... --user=... --password=...
Включить многострочные запросы:
clickhouse-client -m
clickhouse-client --multiline
Выполнение запросов в batch режиме:
clickhouse-client --query='SELECT 1'
echo 'SELECT 1' | clickhouse-client
Вставка данных в заданном формате:
clickhouse-client --query='INSERT INTO table VALUES' < data.txt
clickhouse-client --query='INSERT INTO table FORMAT TabSeparated' < data.tsv
Создаём таблицу для тестовых данных
$ clickhouse-client --multiline
ClickHouse client version 0.0.53720.
Connecting to localhost:9000.
Connected to ClickHouse server version 0.0.53720.
:) CREATE TABLE ontime
(
Year UInt16,
Quarter UInt8,
Month UInt8,
DayofMonth UInt8,
DayOfWeek UInt8,
FlightDate Date,
UniqueCarrier FixedString(7),
AirlineID Int32,
Carrier FixedString(2),
TailNum String,
FlightNum String,
OriginAirportID Int32,
OriginAirportSeqID Int32,
OriginCityMarketID Int32,
Origin FixedString(5),
OriginCityName String,
OriginState FixedString(2),
OriginStateFips String,
OriginStateName String,
OriginWac Int32,
DestAirportID Int32,
DestAirportSeqID Int32,
DestCityMarketID Int32,
Dest FixedString(5),
DestCityName String,
DestState FixedString(2),
DestStateFips String,
DestStateName String,
DestWac Int32,
CRSDepTime Int32,
DepTime Int32,
DepDelay Int32,
DepDelayMinutes Int32,
DepDel15 Int32,
DepartureDelayGroups String,
DepTimeBlk String,
TaxiOut Int32,
WheelsOff Int32,
WheelsOn Int32,
TaxiIn Int32,
CRSArrTime Int32,
ArrTime Int32,
ArrDelay Int32,
ArrDelayMinutes Int32,
ArrDel15 Int32,
ArrivalDelayGroups Int32,
ArrTimeBlk String,
Cancelled UInt8,
CancellationCode FixedString(1),
Diverted UInt8,
CRSElapsedTime Int32,
ActualElapsedTime Int32,
AirTime Int32,
Flights Int32,
Distance Int32,
DistanceGroup UInt8,
CarrierDelay Int32,
WeatherDelay Int32,
NASDelay Int32,
SecurityDelay Int32,
LateAircraftDelay Int32,
FirstDepTime String,
TotalAddGTime String,
LongestAddGTime String,
DivAirportLandings String,
DivReachedDest String,
DivActualElapsedTime String,
DivArrDelay String,
DivDistance String,
Div1Airport String,
Div1AirportID Int32,
Div1AirportSeqID Int32,
Div1WheelsOn String,
Div1TotalGTime String,
Div1LongestGTime String,
Div1WheelsOff String,
Div1TailNum String,
Div2Airport String,
Div2AirportID Int32,
Div2AirportSeqID Int32,
Div2WheelsOn String,
Div2TotalGTime String,
Div2LongestGTime String,
Div2WheelsOff String,
Div2TailNum String,
Div3Airport String,
Div3AirportID Int32,
Div3AirportSeqID Int32,
Div3WheelsOn String,
Div3TotalGTime String,
Div3LongestGTime String,
Div3WheelsOff String,
Div3TailNum String,
Div4Airport String,
Div4AirportID Int32,
Div4AirportSeqID Int32,
Div4WheelsOn String,
Div4TotalGTime String,
Div4LongestGTime String,
Div4WheelsOff String,
Div4TailNum String,
Div5Airport String,
Div5AirportID Int32,
Div5AirportSeqID Int32,
Div5WheelsOn String,
Div5TotalGTime String,
Div5LongestGTime String,
Div5WheelsOff String,
Div5TailNum String
)
ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);
Мы создали таблицу типа MergeTree. Таблицы семейства MergeTree рекомендуется использовать для любых серьёзных применений. Такие таблицы содержат первичный ключ, по которому данные инкрементально сортируются, что позволяет быстро выполнять запросы по диапазону первичного ключа.
Например, если у нас есть логи рекламной сети и нам нужно показывать отчёты для конкретных клиентов-рекламодателей, то первичный ключ в таблице должен начинаться на идентификатор клиента, чтобы для получения данных для одного клиента, достаточно было прочитать лишь небольшой диапазон данных.
Загружаем данные в таблицу
xz -v -c -d < ontime.csv.xz | clickhouse-client --query="INSERT INTO ontime FORMAT CSV"
Запрос INSERT в ClickHouse позволяет загружать данные в любом поддерживаемом формате. При этом на загрузку данных расходуется O (1) памяти. На вход запроса INSERT можно передать любой объём данных. Вставлять данные всегда следует пачками не слишком маленького размера. При этом вставка блоков данных размера до max_insert_block_size (= 1 048 576 строк по умолчанию), является атомарной: блок данных либо целиком вставится, либо целиком не вставится. В случае разрыва соединения в процессе вставки, вы можете не знать, вставился ли блок данных. Для достижения exactly-once семантики, для реплицированных таблиц, поддерживается идемпотентность: вы можете вставить один и тот же блок данных повторно, возможно на другую реплику, и он будет вставлен только один раз. В данном примере мы вставляем данные из localhost, поэтому мы не беспокоимся о формировании пачек и exactly-once семантике.
Запрос INSERT в таблицы типа MergeTree является неблокирующим, равно как и SELECT. После загрузки данных или даже во время процесса загрузки мы уже можем выполнять SELECT-ы.
В данном примере некоторая неоптимальность состоит в том, что в таблице используется тип данных String тогда, когда подошёл бы Enum или числовой тип. Если множество разных значений строк заведомо небольшое (пример: название операционной системы, производитель мобильного телефона), то для максимальной производительности, мы рекомендуем использовать Enum-ы или числа. Если множество строк потенциально неограничено (пример: поисковый запрос, URL), то используйте тип данных String.
Во-вторых, отметим, что в рассматриваемом примере структура таблицы содержит избыточные столбцы Year, Quarter, Month, DayOfMonth, DayOfWeek, тогда как достаточно одного FlightDate. Скорее всего, это сделано для эффективной работы других СУБД, в которых функции для манипуляций с датой и временем, могут работать недостаточно быстро. В случае ClickHouse в этом нет необходимости, так как соответствующие функции хорошо оптимизированы. Впрочем, лишние столбцы не проблема: так как ClickHouse — это столбцовая СУБД, вы можете позволить себе иметь в таблице достаточно много столбцов. Сотни столбцов — это нормально для ClickHouse.
Примеры работы с загруженными данными
-
какие направления были самыми популярными в 2015 году;
SELECT OriginCityName, DestCityName, count(*) AS flights, bar(flights, 0, 20000, 40) FROM ontime WHERE Year = 2015 GROUP BY OriginCityName, DestCityName ORDER BY flights DESC LIMIT 20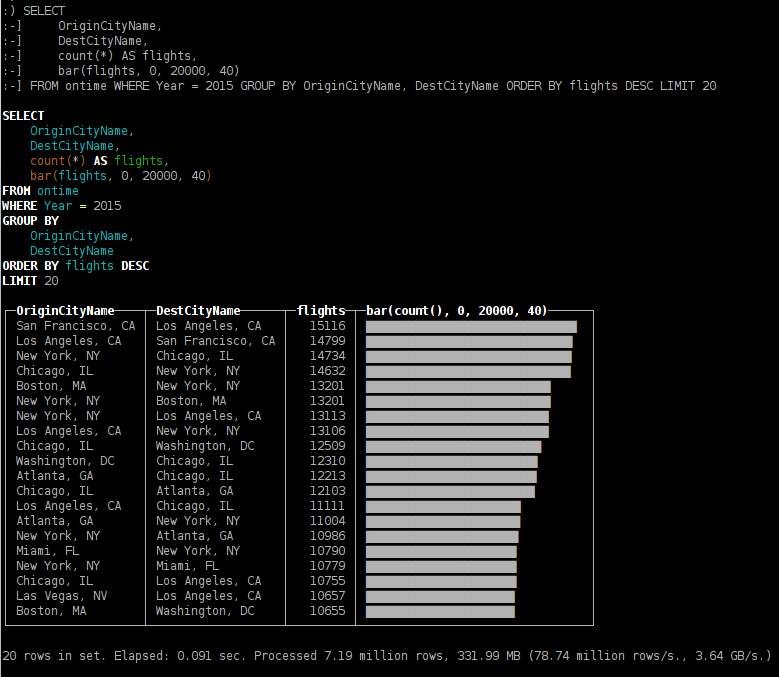
SELECT OriginCityName < DestCityName ? OriginCityName : DestCityName AS a, OriginCityName < DestCityName ? DestCityName : OriginCityName AS b, count(*) AS flights, bar(flights, 0, 40000, 40) FROM ontime WHERE Year = 2015 GROUP BY a, b ORDER BY flights DESC LIMIT 20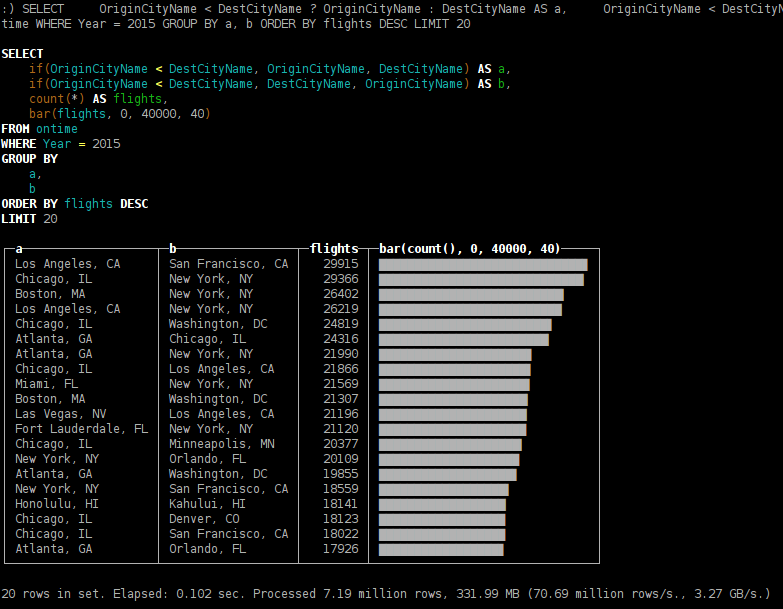
-
из каких городов отправляется больше рейсов;
SELECT OriginCityName, count(*) AS flights FROM ontime GROUP BY OriginCityName ORDER BY flights DESC LIMIT 20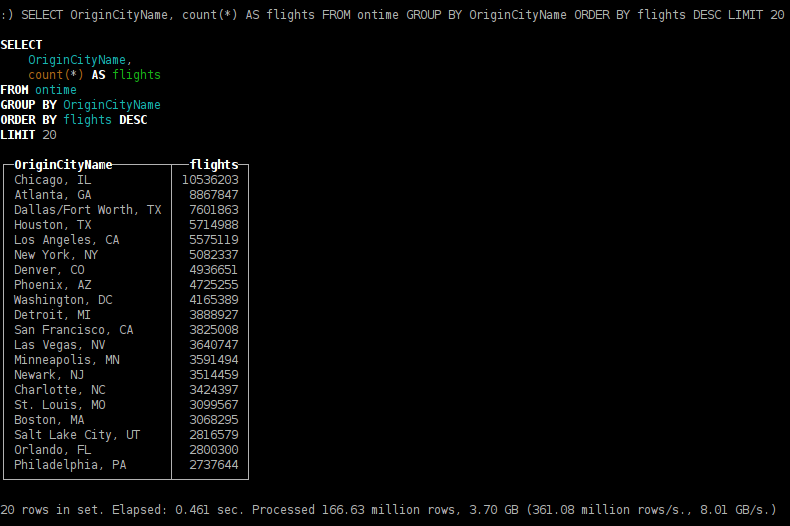
-
из каких городов можно улететь по максимальному количеству направлений;
SELECT OriginCityName, uniq(Dest) AS u FROM ontime GROUP BY OriginCityName ORDER BY u DESC LIMIT 20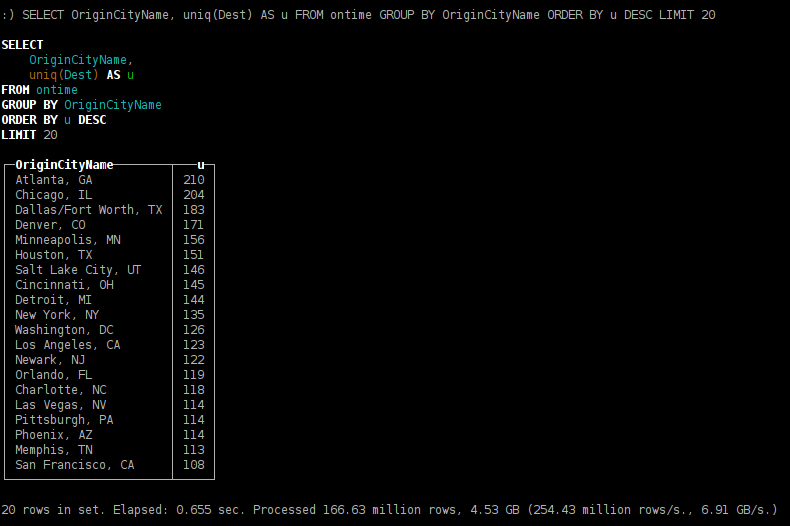
-
как зависит задержка вылета рейсов от дня недели;
SELECT DayOfWeek, count() AS c, avg(DepDelay > 60) AS delays FROM ontime GROUP BY DayOfWeek ORDER BY DayOfWeek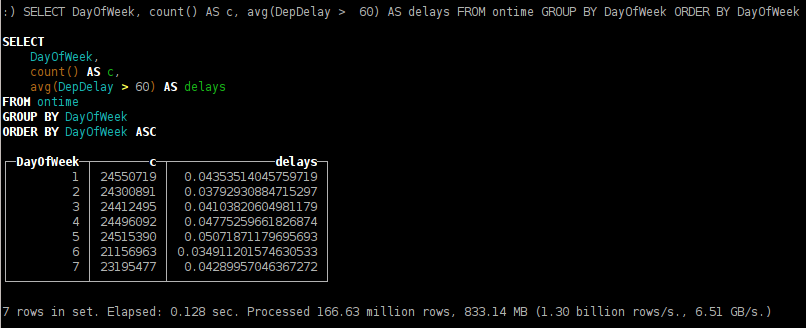
-
из каких городов, самолёты чаще задерживаются с вылетом более чем на час;
SELECT OriginCityName, count() AS c, avg(DepDelay > 60) AS delays FROM ontime GROUP BY OriginCityName HAVING c > 100000 ORDER BY delays DESC LIMIT 20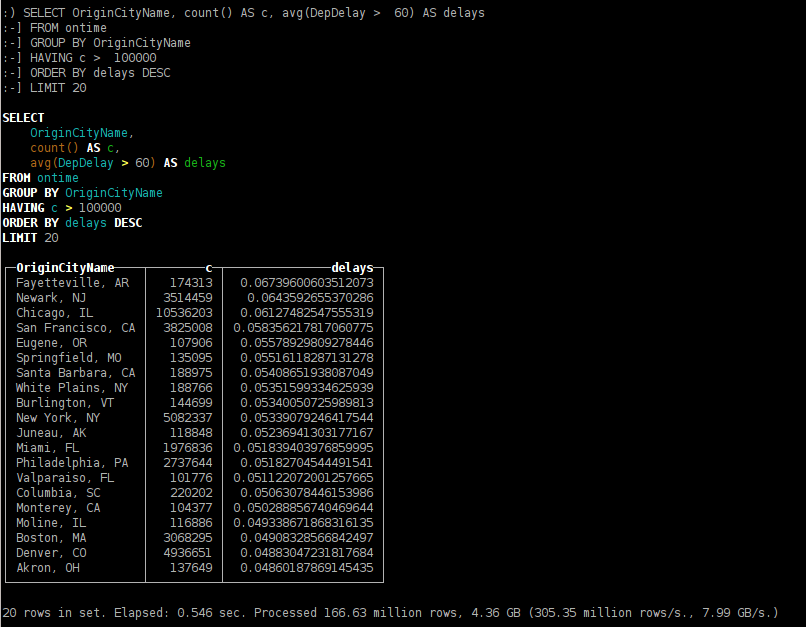
-
какие наиболее длинные рейсы;
SELECT OriginCityName, DestCityName, count(*) AS flights, avg(AirTime) AS duration FROM ontime GROUP BY OriginCityName, DestCityName ORDER BY duration DESC LIMIT 20
-
распределение времени задержки прилёта, по авиакомпаниям;
SELECT Carrier, count() AS c, round(quantileTDigest(0.99)(DepDelay), 2) AS q FROM ontime GROUP BY Carrier ORDER BY q DESC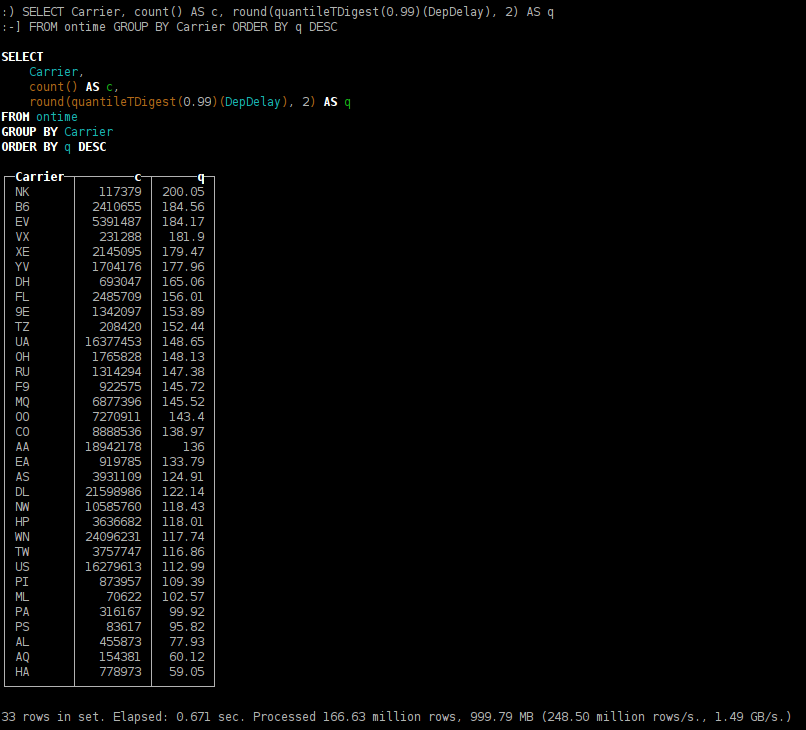
-
какие авиакомпании прекратили перелёты;
SELECT Carrier, min(Year), max(Year), count() FROM ontime GROUP BY Carrier HAVING max(Year) < 2015 ORDER BY count() DESC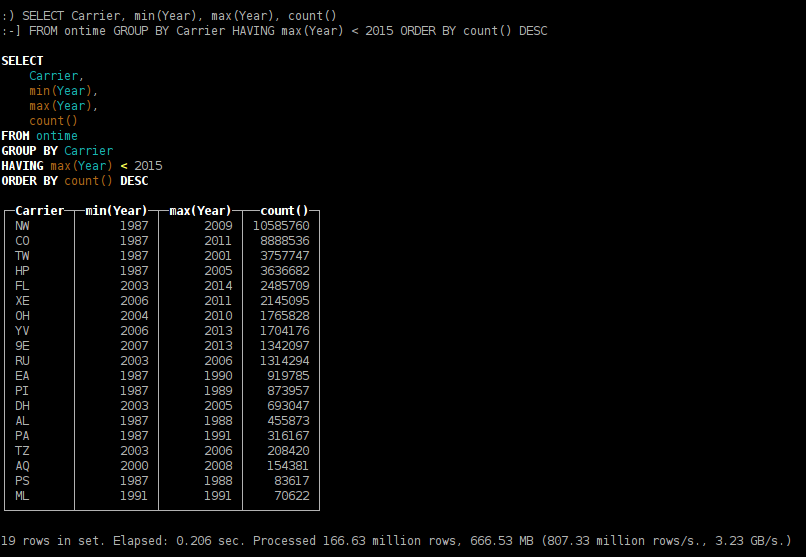
-
в какие города стали больше летать в 2015 году;
SELECT DestCityName, sum(Year = 2014) AS c2014, sum(Year = 2015) AS c2015, c2015 / c2014 AS diff FROM ontime WHERE Year IN (2014, 2015) GROUP BY DestCityName HAVING c2014 > 10000 AND c2015 > 1000 AND diff > 1 ORDER BY diff DESC
-
перелёты в какие города больше зависят от сезонности.
SELECT DestCityName, any(total), avg(abs(monthly * 12 - total) / total) AS avg_month_diff FROM ( SELECT DestCityName, count() AS total FROM ontime GROUP BY DestCityName HAVING total > 100000 ) ALL INNER JOIN ( SELECT DestCityName, Month, count() AS monthly FROM ontime GROUP BY DestCityName, Month HAVING monthly > 10000 ) USING DestCityName GROUP BY DestCityName ORDER BY avg_month_diff DESC LIMIT 20
Как установить ClickHouse на кластер из нескольких серверов
С точки зрения установленного ПО кластер ClickHouse является однородным, без выделенных узлов. Вам надо установить ClickHouse на все серверы кластера, затем прописать конфигурацию кластера в конфигурационном файле, создать на каждом сервере локальную таблицу и затем создать Distributed-таблицу.
Distributed-таблица представляет собой «вид» на локальные таблицы на кластере ClickHouse. При SELECT-е из распределённой таблицы запрос будет обработан распределённо, с использованием ресурсов всех шардов кластера. Вы можете объявить конфигурации нескольких разных кластеров и создать несколько Distributed-таблиц, которые смотрят на разные кластеры.
example-perftest01j.yandex.ru
9000
example-perftest02j.yandex.ru
9000
example-perftest03j.yandex.ru
9000
Создание локальной таблицы:
CREATE TABLE ontime_local (...) ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);
Создание распределённой таблицы, которая смотрит на локальные таблицы на кластере:
CREATE TABLE ontime_all AS ontime_local ENGINE = Distributed(perftest_3shards_1replicas, default, ontime_local, rand());
Вы можете создать Distributed-таблицу на всех серверах кластера — тогда для выполнения распределённых запросов, можно будет обратиться на любой сервер кластера. Кроме Distributed-таблицы вы также можете воспользоваться табличной функцией remote.
Для того, чтобы распределить таблицу по нескольким серверам, сделаем INSERT SELECT в Distributed-таблицу.
INSERT INTO ontime_all SELECT * FROM ontime;
Отметим, что для перешардирования больших таблиц, такой способ не подходит, вместо этого следует воспользоваться встроенной функциональностью перешардирования.
Как и ожидалось, более-менее долгие запросы работают в несколько раз быстрее, если их выполнять на трёх серверах, а не на одном.
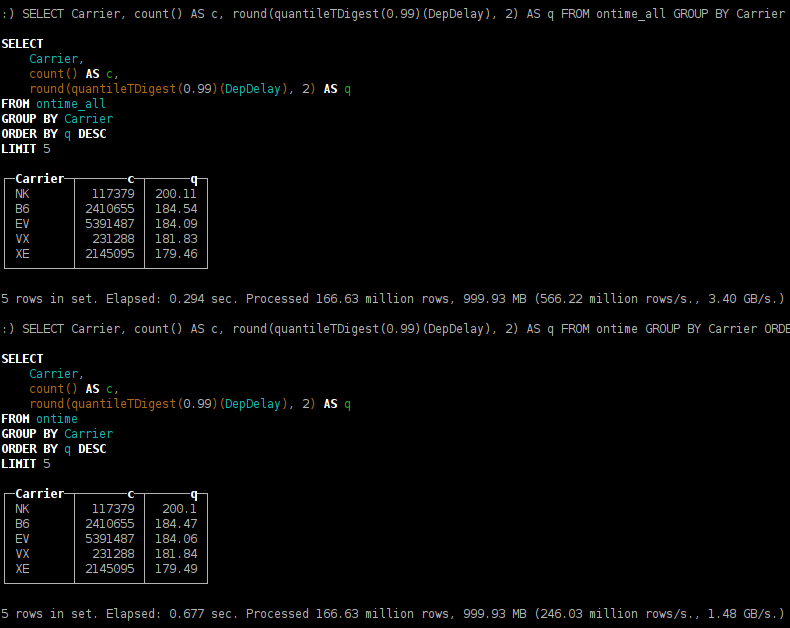
Можно заметить, что результат расчёта квантилей слегка отличается. Это происходит потому, что реализация алгоритма t-digest является недетерминированной — зависит от порядка обработки данных.
В данном примере мы использовали кластер из трёх шардов, каждый шард которого состоит из одной реплики. Для реальных задач в целях отказоустойчивости каждый шард должен состоять из двух или трёх реплик, расположенных в разных дата-центрах. (Поддерживается произвольное количество реплик.)
...
example-perftest01j.yandex.ru
9000
example-perftest02j.yandex.ru
9000
example-perftest03j.yandex.ru
9000
Для работы репликации (хранение метаданных и координация действий) требуется ZooKeeper. ClickHouse будет самостоятельно обеспечивать консистентность данных на репликах и производить восстановление после сбоев. Рекомендуется расположить кластер ZooKeeper на отдельных серверах.
На самом деле использование ZooKeeper не обязательно: в самых простых случаях вы можете дублировать данные, записывая их на все реплики вручную, и не использовать встроенный механизм репликации. Но такой способ не рекомендуется — ведь в этом случае ClickHouse не сможет обеспечивать консистентность данных на репликах.
zoo01.yandex.ru
2181
zoo02.yandex.ru
2181
zoo03.yandex.ru
2181
Также пропишем подстановки, идентифицирующие шард и реплику — они будут использоваться при создании таблицы.
01
01
Если при создании реплицированной таблицы других реплик ещё нет, то создаётся первая реплика, а если есть — создаётся новая реплика, которая клонирует данные существующих реплик. Вы можете либо сразу создать все таблицы-реплики и затем загрузить в них данные, либо сначала создать часть реплик, а затем добавить другие — уже после загрузки или во время загрузки данных.
CREATE TABLE ontime_replica (...)
ENGINE = ReplicatedMergeTree(
'/clickhouse_perftest/tables/{shard}/ontime',
'{replica}',
FlightDate,
(Year, FlightDate),
8192);
Здесь видно, что мы используем тип таблицы ReplicatedMergeTree, указывая в качестве параметров путь в ZooKeeper, содержащий идентификатор шарда, а также идентификатор реплики.
INSERT INTO ontime_replica SELECT * FROM ontime;
Репликация работает в режиме multi-master. Вы можете вставлять данные на любую реплику, и данные автоматически разъезжаются по всем репликам. При этом репликация асинхронная, и в заданный момент времени, реплики могут содержать не все недавно записанные данные. Для записи данных, достаточно доступности хотя бы одной реплики. Остальные реплики будут скачивать новые данные и восстанавливать консистентность как только станут активными. Такая схема допускает возможность потери только что вставленных данных.
Если у вас возникли вопросы, можно задать их в комментариях к этой статье либо на StackOverflow с тегом «clickhouse». Также вы можете создать тему для обсуждения в группе или написать своё предложение на рассылку clickhouse-feedback@yandex-team.ru. А если вам хочется попробовать поработать над ClickHouse изнутри, приглашаем присоединиться к нашей команде в Яндексе. У нас открыты вакансии и стажировки.
