Анализ данных на Scala — суровая необходимость или приятная возможность?

Традиционными инструментами в сфере Data Science являются такие языки, как R и Python — расслабленный синтаксис и большое количество библиотек для машинного обучения и обработки данных позволяет достаточно быстро получить некоторые работающие решения. Однако бывают ситуации, когда ограничения этих инструментов становятся существенной помехой — в первую очередь, если необходимо добиться высоких показателей по скорости обработки и/или работать с действительно крупными массивами данных. В этом случае специалисту приходится, скрепя сердце, обращаться к помощи «темной стороны» и подключать инструменты на «промышленных» языках программирования: Scala, Java и C++.
Но так ли уж темна эта сторона? За годы развития инструменты «промышленного» Data Science прошли большой путь и сегодня достаточно сильно отличаются от своих же версий 2–3 летней давности. Давайте попробуем на примере задачи SNA Hackathon 2019 разобраться, насколько экосистема Scala+Spark может соответствовать Python Data Science.
В рамках SNA Hackathon 2019 участники решают задачу сортировки новостной ленты пользователя социальной сети в одной из трех «дисциплин»: используя данные текстов, изображений или логов признаков. В этой публикации мы разберемся, как в Spark можно решать задачу на основе лога признаков средствами классического машинного обучения.
При решении задачи мы мы пройдём стандартный путь, который любой специалист по анализу данных проходит при разработке модели:
- Проведем исследовательский анализ данных, построим графики.
- Проанализируем статистические свойства признаков в данных, посмотрим на их различия между обучающим и тестовым множеством.
- Проведем начальный отбор признаков на базе статистических свойств.
- Посчитаем корреляции между признаками и целевой переменной, а также кросс-корреляцию между признаками.
- Сформируем окончательный набор признаков, обучим модель и проверим её качество.
- Проанализируем внутреннее устройство модели для идентификации точек роста.
В процессе нашего «путешествия» мы познакомимся с такими инструментами, как интерактивный блокнот Zeppelin, библиотека машинного обучения Spark ML и её расширение PravdaML, пакет для работы с графами GraphX, библиотека визуализации Vegas, ну и, конечно, Apache Spark во всей его красе:). Весь код и результаты эксперимента доступны на платформе коллаборативных блокнотов Zepl.
Особенностью данных, выложенных на SNA Hackathon 2019, является то, что обработать их напрямую с помощью Python можно, но затруднительно: исходные данные достаточно эффективно упакованы благодаря возможностям колоночного формата Apache Parquet и при чтении в память «в лоб» распаковываются на несколько десятков гигабайтов. При работе же с Apache Spark целиком загружать данные в память нет необходимости, архитектура Spark рассчитана на обработку данных кусками, подгружая с диска по необходимости.
Поэтому первый шаг — проверку распределения данных по дням — легко выполняется коробочными инструментам:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain")
z.show(train.groupBy($"date").agg(
functions.count($"instanceId_userId").as("count"),
functions.countDistinct($"instanceId_userId").as("users"),
functions.countDistinct($"instanceId_objectId").as("objects"),
functions.countDistinct($"metadata_ownerId").as("owners"))
.orderBy("date"))
Что отобразит в Zeppelin соответствующий график:
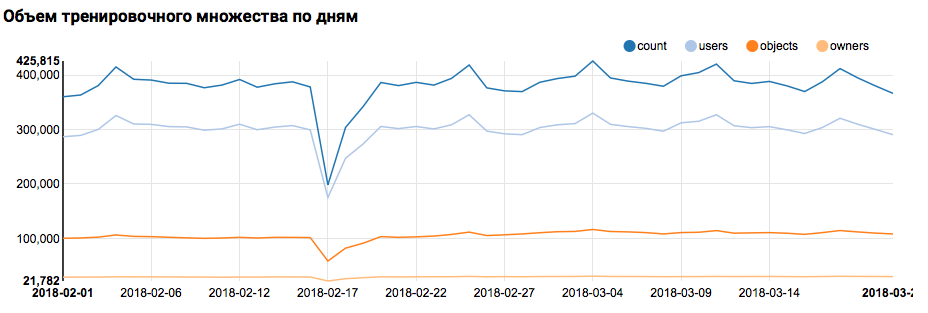
Надо сказать, что синтаксис Scala достаточно гибок, и тот же код может выглядеть, например, так:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain")
z.show(
train groupBy $"date" agg(
count($"instanceId_userId") as "count",
countDistinct($"instanceId_userId") as "users",
countDistinct($"instanceId_objectId") as "objects",
countDistinct($"metadata_ownerId") as "owners")
orderBy "date"
)
Здесь нужно сделать важное предостережение: при работе в большой команде, где каждый подходит к написанию Scala-кода исключительно с точки зрения собственного вкуса, коммуникация существенно затрудняется. Так что лучше выработать единую концепцию стилистики кода.
Но вернемся к нашей задаче. Простой анализ по дням показал наличие аномальных точек 17 и 18 февраля; вероятно, в этих днях собраны неполные данные, и распределения признаков могут быть смещены. Это стоит учитывать при дальнейшем анализе. Кроме того, бросается в глаза тот факт, что количество уникальных пользователей очень близко к количеству объектов, поэтому имеет смысл изучить распределение пользователей с разным количеством объектов:
z.show(filteredTrain
.groupBy($"instanceId_userId").count
.groupBy("count").agg(functions.log(functions.count("count")).as("withCount"))
.orderBy($"withCount".desc)
.limit(100)
.orderBy($"count"))
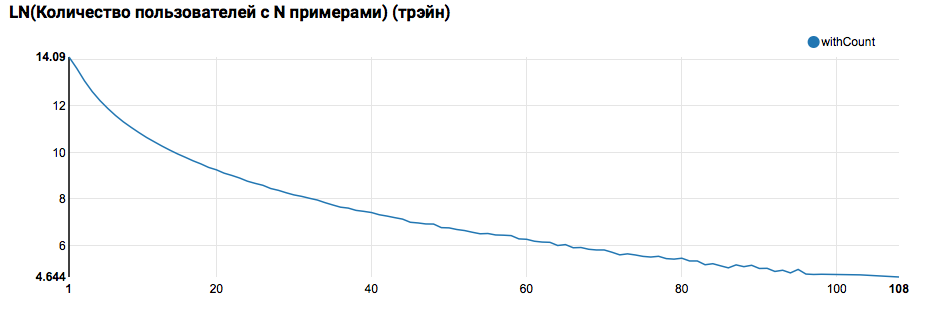
Ожидаемо видим распределение, близкое к степенному, с очень длинным хвостом. В таких задачах, как правило, добиться улучшения качества работы можно сегментируя модели для пользователей с разным уровнем активности. Для того, чтобы проверить, стоит ли этим заниматься, сравним распределение количества объектов по пользователю в тестовом множестве:
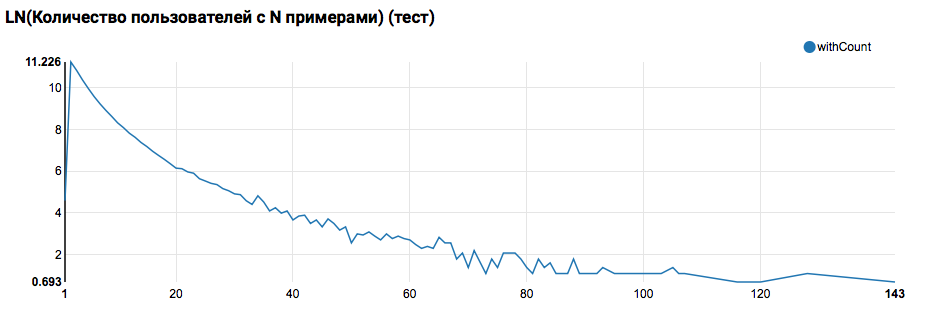
Сравнение с тестом показывает, что тестовые пользователи имеют не менее двух объектов в логах (поскольку на хакатоне решается задача ранжирования, это необходимое условие для оценки качества). В дальнейшем рекомендую посмотреть более пристально на пользователей в обучающем множестве, для чего объявим User Defined Function с фильтром:
// Всех пользователей, у которых есть и "Классы", и пропущенные объекты,
// соберем в отсортированный массив
val testSimilar = sc.broadcast(filteredTrain.groupBy($"instanceId_userId")
.agg(
functions.count("feedback").as("count"),
functions.sum(functions.expr("IF(array_contains(feedback, 'Liked'), 1.0, 0.0)")).as("sum")
)
.where("count > sum AND sum > 0")
.select("instanceId_userId").rdd.map(_.getInt(0)).collect.sorted)
// Используем двоичный поиск по массиву и на его основе делаем
// User Defined Function
val isTestSimilar = sqlContext.udf.register("isTestSimilar",
(x: Int) => java.util.Arrays.binarySearch(testSimilar.value, x) >= 0)
Здесь также надо сделать важную ремарку: именно с точки зрения определения UDF разительно отличается использование Spark из под Scala/Java и из под Python. Пока код на PySpark использует базовую функциональность, всё работает почти так же быстро, но при появлении переопределенных функций производительность PySpark деградирует на порядок.
На следующем шаге мы попробуем посчитать основную статистику по действиям и признакам. Но для этого нам понадобятся возможности SparkML, поэтому сначала рассмотрим её общую архитектуру:

SparkML построен на базе следующих концепций:
- Transformer — принимает на вход набор данных и возвращает видоизмененный набор (transform). Как правило, используется для реализации алгоритмов пре- и постпроцессинга, извлечения признаков, а также могут представлять итоговые ML-модели.
- Estimator — принимает на вход набор данных, а возвращает Transformer (fit). Естественным образом Estimator может представлять ML-алгоритм.
- Pipeline — частный случай Estimator, состоящий из цепочки трансформеров и эстиматоров. При вызове метода fit проходит по цепочке, и если видит трансформер, то применяет его к данным, а если видит эстиматор — обучает с помощью него трансформер, применяет к данным и идет дальше.
- PipelineModel — результат работы Pipeline также содержит внутри цепочку, но состоящую уже исключительно из трансформеров. Соответственно, сам PipelineModel также является трансформером.
Подобный подход к формированию ML-алгоритмов помогает добиться четкой модульной структуры и хорошей воспроизводимости — и модели, и конвейеры можно сохранить.
Для начала построим простой конвейер, с помощью которого посчитаем статистику распределения действий (поле feedback) пользователей в обучающем множестве:
val feedbackAggregator = new Pipeline().setStages(Array(
// На первом этапе перекодируем поле с массивом строк (feedback) в one-hot вектор
new MultinominalExtractor().setInputCol("feedback").setOutputCol("feedback"),
// Дальше посчитаем по этому вектору статистику
new VectorStatCollector()
.setGroupByColumns("date").setInputCol("feedback")
.setPercentiles(Array(0.1,0.5,0.9)),
// И развернем в удобную для анализа форму
new VectorExplode().setValueCol("feedback")
)).fit(train)
z.show(feedbackAggregator
.transform(filteredTrain)
.orderBy($"date", $"feedback"))
В этом конвейере активно используется функциональность PravdaML — библиотеки с расширенными полезными блоками для SparkML, а именно:
- MultinominalExtractor используется для кодирования признака типа «массив строк» в вектор по принципу one-hot. Это единственный эстиматор в конвейере (чтобы построить кодировку, надо собрать уникальные строки из датасета).
- VectorStatCollector используется для подсчета статистики вектора.
- VectorExplode применяется для преобразования результата в удобный для визуализации формат.
Результатом работы будет график, показывающий, что классы в датасете не сбалансированы, однако дисбаланс для целевого класса Liked не является экстремальным:

Анализ аналогичного распределения по пользователям, похожим на тестовых (имеющих и «позитив» и «негатив» в логах), показывает, что оно смещено в сторону положительного класса:
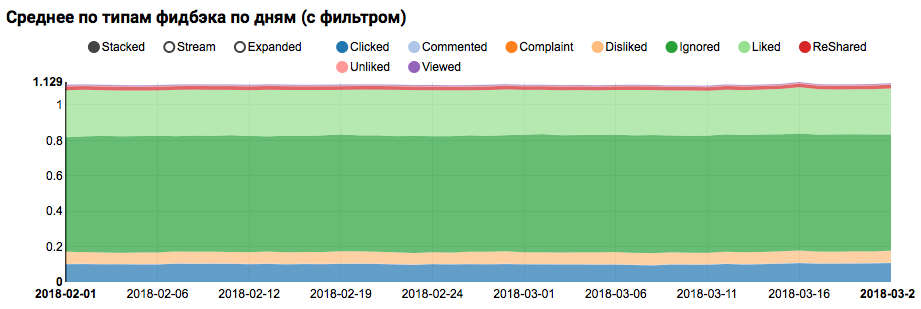
На следующем этапе проведем детальный анализ статистических свойств признаков. В этот раз нам понадобится конвейер побольше:
val statsAggregator = new Pipeline().setStages(Array(
new NullToDefaultReplacer(),
// Указываем какие колонки взять в оборот для построения статистики
new AutoAssembler()
.setColumnsToExclude(
(Seq("date", "feedback") ++ train.schema.fieldNames.filter(_.endsWith("Id")) : _*))
.setOutputCol("features"),
new VectorStatCollector()
.setGroupByColumns("date").setInputCol("features")
.setPercentiles(Array(0.1,0.5,0.9)),
new VectorExplode().setValueCol("features")
))
Поскольку сейчас нам нужно работать не с отдельным полем, а со всеми признаками сразу, воспользуемся еще двумя полезными утилитами PravdaML:
- NullToDefaultReplacer позволяет заменить отсутствующие элементы в данных на их значения по умолчанию (0 для чисел, false для логических переменных и т.д.). Если не делать этого преобразования, то в итоговых векторах появятся значения NaN, что для многих алгоритмов фатально (хотя, например, XGBoost это может пережить). Альтернативой замены на нули может быть замена на средние значения, это реализовано в NaNToMeanReplacerEstimator.
- AutoAssembler — очень мощная утилита, которая анализирует схему таблицы и для каждой колонки выбирает схему векторизации, соответствующую типу колонки.
Используя полученный конвейер посчитаем статистику по трем множествам (обучающему, обучающему с фильтром пользователей и тестовому) и сохраним в отдельные файлы:
// Обучаем конвейер (на этом этапе AutoAssembler проанализирует схему)
val trained = statsAggregator.fit(filteredTrain)
// А теперь считаем для трех случаев - обучающее, тестовое и фильтрованное обучающее множество.
trained
.transform(filteredTrain
.withColumn("date",
// Для того, чтобы статистика посчиталась и по дням, и в целом по датасету,
// добавим для каждой записи её копию с All вместо даты
functions.explode(functions.array(functions.lit("All"), $"date"))))
.coalesce(7).write.mode("overwrite").parquet("sna2019/featuresStat")
trained
.transform(filteredTrain
.where(isTestSimilar($"instanceId_userId"))
.withColumn("date", functions.explode(functions.array(functions.lit("All"), $"date"))))
.coalesce(7).write.mode("overwrite").parquet("sna2019/filteredFeaturesStat")
trained
.transform(filteredTest.withColumn("date", functions.explode(functions.array(functions.lit("All"), $"date"))))
.coalesce(3).write.mode("overwrite").parquet("sna2019/testFeaturesStat")
Получив три датасета со статистикой признаков, проанализируем следующие вещи:
- Есть ли у нас признаки, для которых наблюдаются большие выбросы.
— Такие признаки надо ограничить, или отфильтровать записи-выбросы. - Есть ли у нас признаки с большим смещением среднего относительно медианы.
— Такое смещение часто возникает при наличии степенного распределения, эти признаки имеет смысл логарифмировать. - Наблюдается ли смещение средних распределений между обучающим и тестовым множеством.
- Насколько плотно заполнена наша матрица признаков.
Прояснить эти аспекты нам поможет такой запрос:
def compareWithTest(data: DataFrame) : DataFrame = {
data.where("date = 'All'")
.select(
$"features",
// Отклонение среднего от медианы показатель не нормального распределения
// (часто степенного)
functions.log($"features_mean" / $"features_p50").as("skewenes"),
// Отклонение интервала между 90-й перцентилью и максимума от интервала
// между медианой и 90-й перцентилью — показатель наличия выбросов
functions.log(
($"features_max" - $"features_p90") /
($"features_p90" - $"features_p50")).as("outlieres"),
// Часто существенная часто признаков заполнена исключительно нулями, это
// тоже надо проконтролировать
($"features_nonZeros" / $"features_count").as("train_fill"),
$"features_mean".as("train_mean"))
.join(testStat.where("date = 'All'")
.select($"features", $"features_mean".as("test_mean"), ($"features_nonZeros" / $"features_count").as("test_fill")),
Seq("features"))
// Проверяем насколько сместилось среднее распределений между тестом и трейном
.withColumn("meanDrift", (($"train_mean" - $"test_mean" ) / ($"train_mean" + $"test_mean")))
// Проверяем насколько изменился процент заполнения
.withColumn("fillDrift", ($"train_fill" - $"test_fill") / ($"train_fill" + $"test_fill"))
}
// Отдельно смотрим на фильтрованное и нефильтрованное обучающее множество
val comparison = compareWithTest(trainStat).withColumn("mode", functions.lit("raw"))
.unionByName(compareWithTest(filteredStat).withColumn("mode", functions.lit("filtered")))
На этом этапе остро встает вопрос визуализации: штатными средствами Zeppelin-а сразу отобразить все аспекты сложно, да и блокноты с большим количеством графиков начинают заметно тормозить из-за раздутости DOM. Решить эту проблему может библиотека Vegas — DSL на Scala для построения спецификаций vega-lite. Vegas не только предоставляет более богатые возможности визуализации (сопоставимые с matplotlib), но и рисует их на Canvas, не раздувая DOM:).
Спецификация интересующего нас графика будет выглядеть так:
vegas.Vegas(width = 1024, height = 648)
// Задаем данные
.withDataFrame(comparison.na.fill(0.0))
// По оси Х отложим отклонение среднего между трейном и тестом
.encodeX("meanDrift", Quant, scale = Scale(domainValues = List(-1.0, 1.0), clamp = true))
// По У - насколько плотно заполнен признак в трейне
.encodeY("train_fill", Quant)
// Цветом подсветим признаки с симптомами выбросов
.encodeColor("outlieres", Quant, scale=Scale(
rangeNominals=List("#00FF00", "#FF0000"),
domainValues = List(0.0, 5), clamp = true))
// Размером покажем смещенность среднего относительно медианы
.encodeSize("skewenes", Quant)
// А формой - режим сравнения (с фильтром или без)
.encodeShape("mode", Nom)
.mark(vegas.Point)
.show
Нижеприведенную диаграмму следует читать так:
- По оси Х отложено смещение центров распределений между тестовым и обучающим множеством (чем ближе к 0, тем стабильнее признак).
- По оси У отложен процент ненулевых элементов (чем выше, тем для большего числа точек есть данные по признаку).
- Размер показывает смещение среднего относительно медианы (чем точка больше, тем более вероятен степенной закон распределения для нее).
- Цвет показывает наличие выбросов (чем краснее, тем выбросов больше).
- Ну и форма отличает режим сравнения: с фильтром пользователей в обучающем множестве или без фильтра.
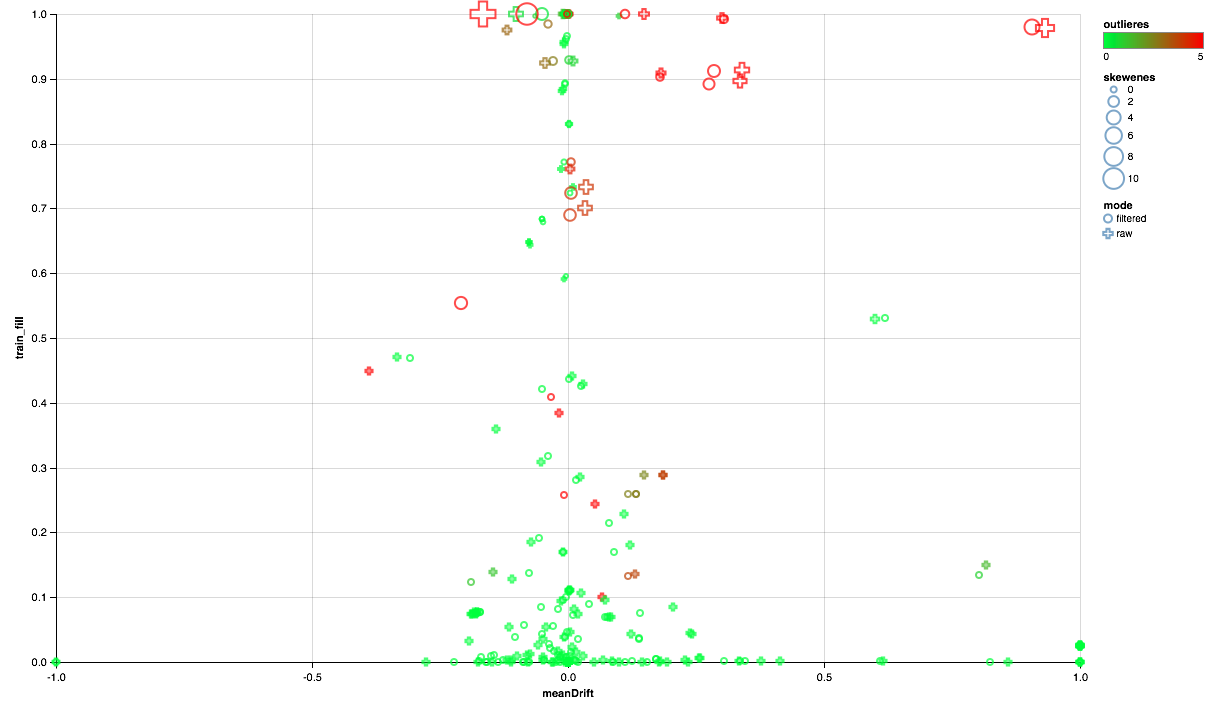
Итак, можно сделать следующие выводы:
- Часть признаков нуждается в фильтре выбросов — ограничим максимальные значения по 90-й перцентили.
- Часть признаков показывает распределение, близкое к экспоненциальному — будем брать логарифм.
- Часть признаков в тесте не представлена — исключим их из обучения.
После получения общего представления о том, как распределены признаки и как они соотносятся между обучающим и тестовым множеством, попробуем проанализировать корреляции. Для этого настроим экстрактор признаков на базе предыдущих наблюдений:
// На базе наблюдений с предыдущих шагов построим экстрактор признаков с учетом преобразований
val expressions = filteredTrain.schema.fieldNames
// Исключим идентификаторы и признаки со значительными сдвигами в тесте
.filterNot(x => x == "date" || x == "audit_experiment" || idsColumns(x) || x.contains("vd_"))
.map(x => if(skewedFeautres(x)) {
// Логарифмируем признаки со смещенным средним
s"log($x) AS $x"
} else {
// Обрежем признаки с выбросами
cappedFeatures.get(x).map(capping => s"IF($x < $capping, $x, $capping) AS $x").getOrElse(x)
})
val rawFeaturesExtractor = new Pipeline().setStages(Array(
new SQLTransformer().setStatement(s"SELECT ${expressions.mkString(", ")} FROM __THIS__"),
new NullToDefaultReplacer(),
new AutoAssembler().setOutputCol("features")
))
// Применим экстрактор к отфильтрованному обучающему множеству
val raw = rawFeaturesExtractor.fit(filteredTrain).transform(
filteredTrain.where(isTestSimilar($"instanceId_userId")))
Из новой машинерии в этом конвейере обращает на себя внимание утилита SQLTransformer, позволяющая проводить произвольные SQL-преобразования входной таблицы.
При анализе корреляций важно отфильтровать шум, создаваемый естественной корреляцией one-hot признаков. Для этого хотелось бы понимать, какие элементы вектора каким исходным колонкам соответствуют. Эта задача в Spark решается с помощью метаданных колонок (сохраняемых вместе с данными) и групп атрибутов. Следующий блок кода используется для фильтрации пар имен атрибутов, происходящих из одной и той же колонки типа String:
val attributes = AttributeGroup.fromStructField(raw.schema("features")).attributes.get
val originMap = filteredTrain
.schema.filter(_.dataType == StringType)
.flatMap(x => attributes.map(_.name.get).filter(_.startsWith(x.name + "_")).map(_ -> x.name))
.toMap
// Корреляция считается тривиальной, если оба признака построены на базе одной строковой колонки
val isNonTrivialCorrelation = sqlContext.udf.register("isNonTrivialCorrelation",
(x: String, y : String) =>
// Ну и немного Scala-quiz на базе Option
originMap.get(x).map(_ != originMap.getOrElse(y, "")).getOrElse(true))
Имея на руках датасет с колонкой-вектором рассчитать кросс-корреляции средствами Spark достаточно просто, но результатом будет матрица, для развертывания которой в набор пар придется немного подшаманить:
val pearsonCorrelation =
// Поддерживается коэффициент корреляции Pearson и Spearman
Correlation.corr(raw, "features", "pearson").rdd.flatMap(
// Возьмем итератор по рядам матрицы и для каждого вернем коллекцию
_.getAs[Matrix](0).rowIter.zipWithIndex.flatMap(x => {
// Восстановим имя признака, соответствующее ряду (на базе атрибутов,
// извлеченных ранее)
val name = attributes(x._2).name.get
// Пробежимся по значениям ряда, восстанавливая имена для колонок
x._1.toArray.zip(attributes).map(y => (name, y._2.name.get, y._1))
}
// Строим из всего этого DataFrame
)).toDF("feature1", "feature2", "corr")
.na.drop
// Фильтруем тривиальное
.where(isNonTrivialCorrelation($"feature1", $"feature2"))
// Сохраняем для дальнейшего анализа.
pearsonCorrelation.coalesce(1).write.mode("overwrite")
.parquet("sna2019/pearsonCorrelation")
Ну и, конечно, визуализация: нам опять понадобится помощь Vegas, чтобы нарисовать тепловую карту:
vegas.Vegas("Pearson correlation heatmap")
.withDataFrame(pearsonCorrelation
.withColumn("isPositive", $"corr" > 0)
.withColumn("abs_corr", functions.abs($"corr"))
.where("feature1 < feature2 AND abs_corr > 0.05")
.orderBy("feature1", "feature2"))
.encodeX("feature1", Nom)
.encodeY("feature2", Nom)
.encodeColor("abs_corr", Quant, scale=Scale(rangeNominals=List("#FFFFFF", "#FF0000")))
.encodeShape("isPositive", Nom)
.mark(vegas.Point)
.show
Результат лучше смотреть в Zepl-e. Для общего понимания:
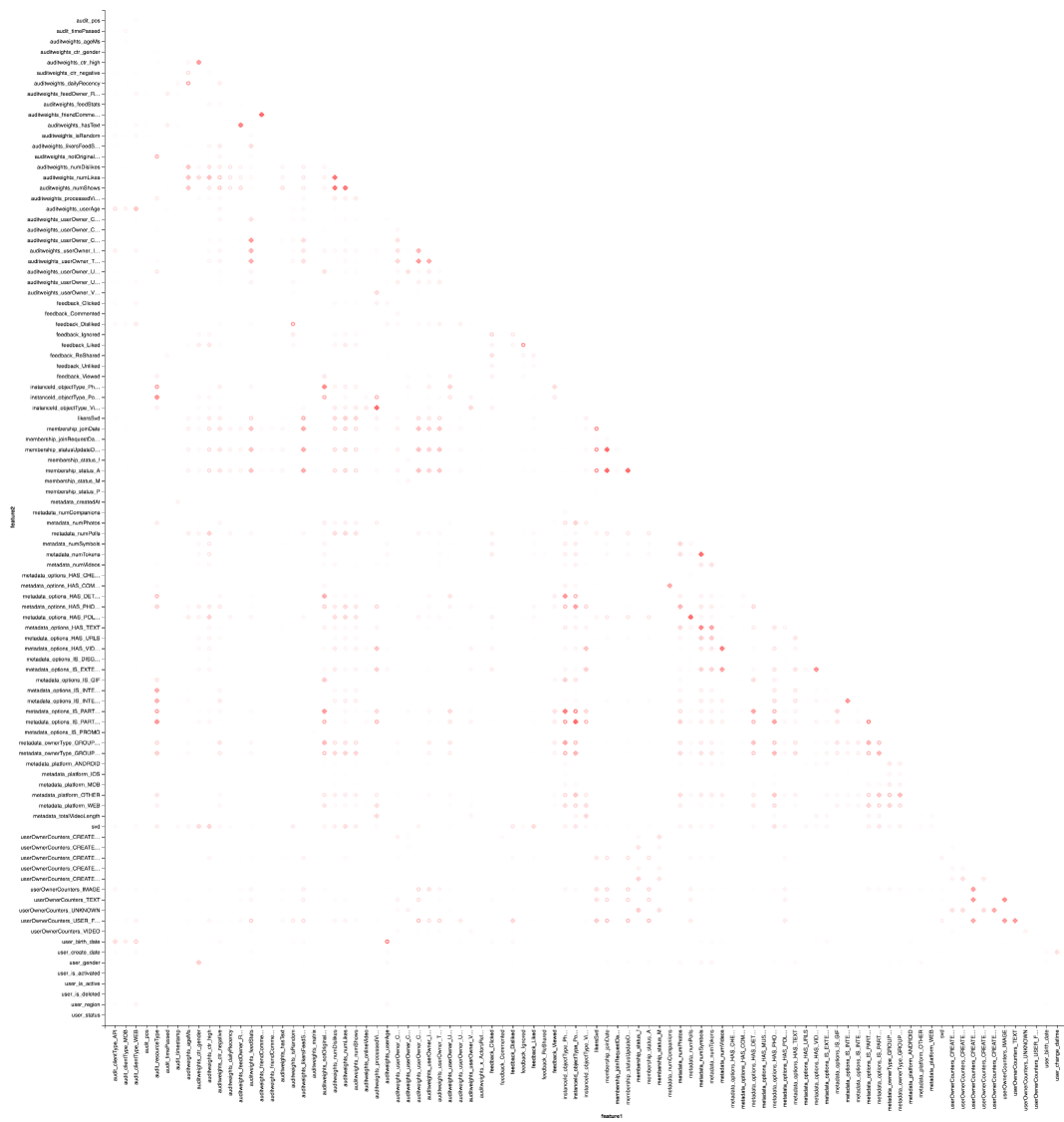
По тепловой карте видно, что некоторые корреляции явно имеются. Попробуем выделить блоки наиболее сильно скоррелированных признаков, для этого используем библиотеку GraphX: матрицу корреляции превратим в граф, отфильтруем рёбра по весу, после чего найдем компоненты связанности и оставим только невырожденные (из более чем одного элемента). Такая процедура по своей сути аналогична применению алгоритма DBSCAN и выглядит следующим образом:
// Проиндексируем вершины (GrpahX требует численные ID)
val featureIndexMap = spearmanCorrelation.select("feature1").distinct.rdd.map(
_.getString(0)).collect.zipWithIndex.toMap
val featureIndex = sqlContext.udf.register("featureIndex", (x: String) => featureIndexMap(x))
// Построим коллекцию вершин
val vertices = sc.parallelize(featureIndexMap.map(x => x._2.toLong -> x._1).toSeq, 1)
// Построим коллекцию рёбер
val edges = spearmanCorrelation.select(featureIndex($"feature1"), featureIndex($"feature2"), $"corr")
// Применим фильтр по весу
.where("ABS(corr) > 0.7")
.rdd.map(r => Edge(r.getInt(0), r.getInt(1), r.getDouble(2)))
// Создадим граф и найдем компоненты связности
val components = Graph(vertices, edges).connectedComponents()
val reversedMap = featureIndexMap.map(_.swap)
// Сгруппируем вершины по компонентам, в которые они попали, и выведем
// читаемые имена
val clusters = components
.vertices.map(x => reversedMap(x._2.toInt) -> reversedMap(x._1.toInt))
.groupByKey().map(x => x._2.toSeq)
.filter(_.size > 1)
.sortBy(-_.size)
.collect
Результат представим в виде таблицы:
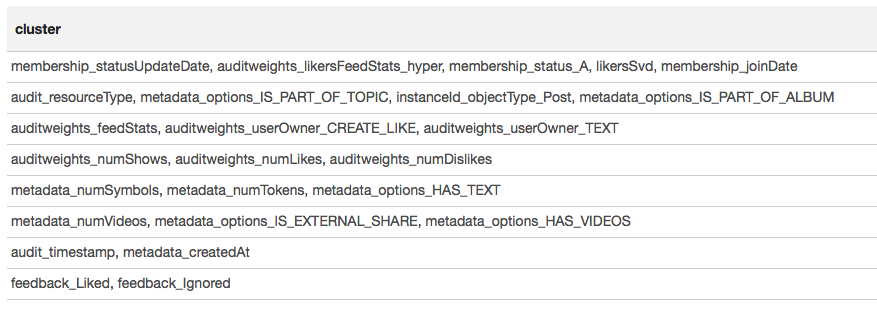
Исходя из результатов кластеризации можно сделать вывод о том, что наиболее коррелированные группы образовались вокруг признаков, связанных с членством пользователя в группе (membership_status_A), а также вокруг типа объекта (instanceId_objectType). Для лучшего моделирования взаимодействия признаков имеет смысл применить сегментацию моделей — обучать разные модели для разных типов объектов, отдельно для групп, в которых пользователь состоит и не состоит.
Подходим к самому интересному — машинному обучению. Конвейер для обучения простейшей модели (логистической регрессии) с помощью SparkML и расширений PravdaML выглядит следующим образом:
new Pipeline().setStages(Array(
new SQLTransformer().setStatement(
"""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""),
new NullToDefaultReplacer(),
new AutoAssembler()
.setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label")
.setOutputCol("features"),
Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition(
new LogisticRegressionLBFSG(),
numPartitions = 127)))
Здесь мы видим не только много знакомых элементов, но и несколько новых:
- LogisticRegressionLBFSG представляет собой эстиматор с распределенным обучением логистической регрессии.
- Для того, чтобы добиться максимальной производительности от распределенных ML-алгоритмов. данные надо оптимально распределить по партициям. В этом поможет утилита UnwrappedStage.repartition, добавляющая в конвейер операцию репартиционирования таким образом, что она применяется только на этапе обучения (ведь при построении прогнозов в ней уже нет необходимости).
- Для того, чтобы линейная модель могла дать хороший результат. данные надо масштабировать, за что отвечает утилита Scaler.scale. Однако наличие двух последовательных линейных преобразований (масштабирование и умножение на веса регрессии) приводит к лишним расходам, и эти операции желательно схлопнуть. При использовании PravdaML на выходе будет чистая модель с одним преобразованием :).
- Ну и, конечно, для подобных моделей нужен свободный член, который мы добавляем с помощью операции Interceptor.intercept.
Полученный конвейер, примененный ко всем данным, дает per-user AUC 0.6889 (код валидации доступен на Zepl). Теперь остается применить все наши изыскания: отфильтровать данные, преобразовать признаки и сегментировать модели. Итоговый конвейер будет выглядеть следующим образом:
new Pipeline().setStages(Array(
new SQLTransformer().setStatement(s"SELECT instanceId_userId, instanceId_objectId, ${expressions.mkString(", ")} FROM __THIS__"),
new SQLTransformer().setStatement("""SELECT *,
IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label,
concat(IF(membership_status = 'A', 'OwnGroup_', 'NonUser_'), instanceId_objectType) AS type
FROM __THIS__"""),
new NullToDefaultReplacer(),
new AutoAssembler()
.setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label", "type","instanceId_objectType")
.setOutputCol("features"),
CombinedModel.perType(
Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition(
new LogisticRegressionLBFSG(),
numPartitions = 127))),
numThreads = 6)
))
Появляется еще одно новшество PravdaML — операция сегментации моделей CombinedModel.perType. Обучать модели для разных типов можно параллельно, это мы задаём параметром numThreads = 6. Такой подход позволяет добиться очень высокой степени использования кластера и значительно ускоряет обучение.
Модель, обученная оптимизированным конвейером, показывает per-user AUC 0.7004. Стоит ли игра свеч? Давайте проверим, попробовав обучить «в лоб» модель на базе XGBoost:
new Pipeline().setStages(Array(
new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""),
new NullToDefaultReplacer(),
new AutoAssembler()
.setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label")
.setOutputCol("features"),
new XGBoostRegressor()
.setNumRounds(100)
.setMaxDepth(15)
.setObjective("reg:logistic")
.setNumWorkers(17)
.setNthread(4)
.setTrackerConf(600000L, "scala")
))
Первое, что бросается в глаза — XGBoost для Spark есть! Причем есть он и в стандартном исполнении от DLMC, и в модификации PravdaML, в которой закрываются некоторые проблемы стыковки (подробнее в этом рассказе). Использование XGboost «в лоб» работает в 10 раз дольше и даёт per-user AUC 0.6981.
Хорошо, у нас обучено несколько моделей, интересно понять, какие же признаки для себя они выявили. В дефолтной реализации SparkML информация часто зашита внутрь конвейера, поэтому вытаскивать и анализировать её неудобно. С PravdaML всё проще: важная информация сохраняется в формате Parquet рядом с самой моделью и может быть легко проанлизирована средствами самого Spark:
// Читаем веса сегментированной модели
val perTypeWeights = sqlContext.read.parquet("sna2019/perType/stages/*/weights")
// Для каждого типа вытаскиваем 20 наиболее весомых признаков (с
// учетом масштабирования)
val topFeatures = new TopKTransformer[Double]()
.setGroupByColumns("type")
.setColumnToOrderGroupsBy("abs_weight")
.setTopK(20)
.transform(perTypeWeights.withColumn("abs_weight", functions.abs($"unscaled_weight")))
.orderBy("type", "unscaled_weight")
Помимо возможности прочитать формат Parquet, в этом коде используется еще одна утилита PravdaML — TopKTransformer, позволяющий в удобной форме получить К топовых записей по каждому ключу.
Полученные веса визуализируем с помощью Vegas (лучше смотреть в Zepl):
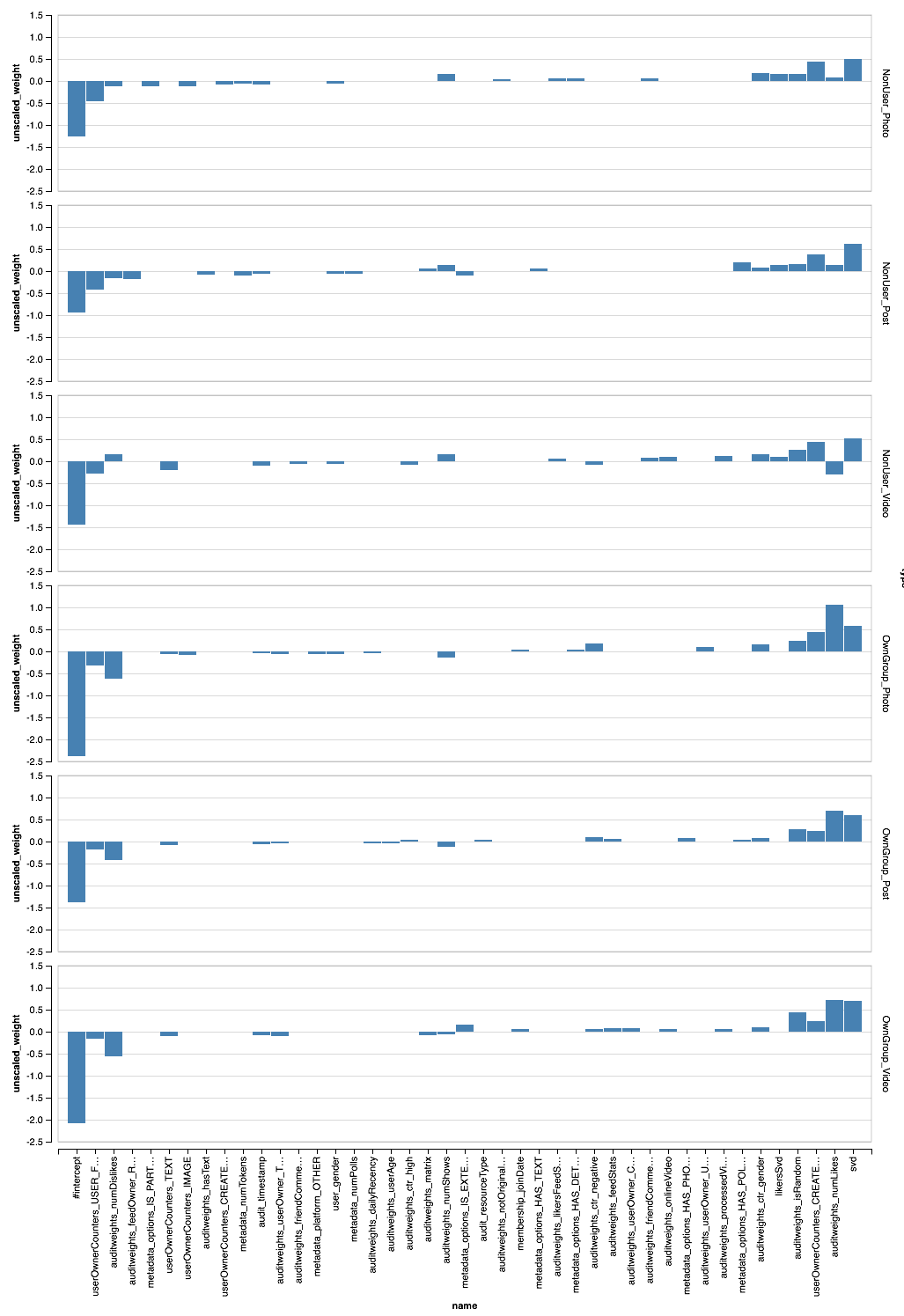
Видно, что сегментация позволила по-разному развесовать разные признаки. А что если заглянуть внутрь XGBoost?
val significance = sqlContext.read.parquet(
"sna2019/xgBoost15_100_raw/stages/*/featuresSignificance"
vegas.Vegas()
.withDataFrame(significance.na.drop.orderBy($"significance".desc).limit(40))
.encodeX("name", Nom, sortField = Sort("significance", AggOps.Mean))
.encodeY("significance", Quant)
.mark(vegas.Bar)
.show
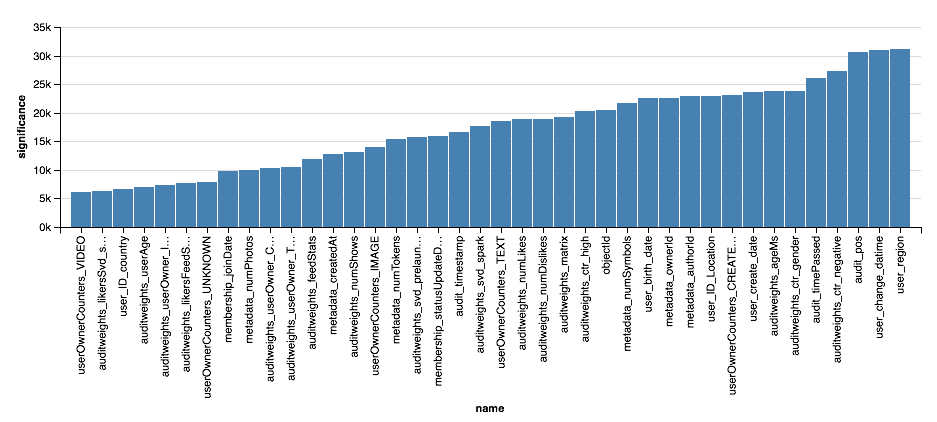
Можно заметить, что значимость признаков, по мнению XGBoost, это просто количество узлов со сплитом по этому атрибуту, что не всегда разумно. Хороший разбор анализа значимости признаков при использовании деревьев можно найти здесь. Но тот факт, что XGBoost часто выбирает для ветвлений признаки, связанные с демографией пользователя, наводит на мысли.
Спасибо всем, кто осилил эту статью до конца :). В заключение несколько небольших ремарок:
- Главный вывод в том, что анализировать данные на Scala в Spark можно более чем комфортно, для этого есть и интерактивные блокноты, и библиотеки с алгоритмами, и инструменты визуализации, и даже коллаборативные платформы.
- При этом связка Scala и Spark обладает рядом существенных преимуществ по сравнению с Python: прозрачные переход между ETL и ML, использование ресурсов распределенного кластера, промышленный инструментарий для разработки и отладки, существенно спрямленный путь в эксплуатацию.
- Третье наблюдение, часто подтверждающееся практикой, заключается в том, что простые модели (например, логистическая регрессия) могут работать не хуже, а иногда лучше сложных моделей, если правильно подойти к подготовке признаков.
- Конечно, это не говорит о том, что использовать сложные модели не имеет смысла. Иногда только с их помощью можно продвинуться дальше определённого предела, но важно не забывать о том, что в машинном обучении первичен, всё-таки, человек.
Конечно, переход на использование нового стека требует больше, чем прочтение одной статьи, и если вы собрались серьезно погрузиться в это, стоит пройти специализированный онлайн-курс. А может и в режиме вечернего обучения посетить, например, программу «Анализ данных на Scala» от Newprolab.
Ну, и практика, практика и еще раз практика — включайтейсь в SNA Hackathon 2019.
