Altera + OpenCL: вскрываем ядро

Всем привет!
В прошлой статье я запустил простой OpenCL пример на FPGA фирмы Altera:
// ACL kernel for adding two input vectors
__kernel void vector_add( __global const uint *restrict x,
__global const uint *restrict y,
__global uint *restrict z )
{
// get index of the work item
int index = get_global_id(0);
// add the vector elements
z[index] = x[index] + y[index];
}
Я намеренно не углублялся в детали и показал верхушку айсберга: процесс разработки, сборку проекта, запуск на системе.
При подготовке первой статьи мне стало дико интересно, во что превращаются (со стороны FPGA) эти строчки. Понимание архитектуры даст возможность что-то соптимизировать и понять на что уходят ресурсы, а так же что хорошо и плохо для этой системы.
В этой статье мы попробуем вскрыть ядро и найти ответы на следующие вопросы:
- Какая у него архитектура?
- Как происходит его настройка? Как попадают данные на обработку?
- На какой частоте он работает? Чем это определяется?
- Можно ли просимулировать только ядро в RTL-симуляторах?
- Какие блоки занимают больше всего ресурсов? Можно ли как-то это соптимизировать?
Давайте взглянём на его внутренности! Добро пожаловать под кат!
Как это видит Альтера
Перед тем, как пристально изучать проект для FPGA, обратимся к различным презентациям от вендора: что они рассказывают про реализацию на высокоуровневом (маркетинговом) языке.
Рекомендую глянуть большую презентацию-введение в OpenCL от Альтеры
Harnessing the Power of FPGAs using Altera«s OpenCL Compiler (осторожно, больше ста слайдов, ~16 МБ).
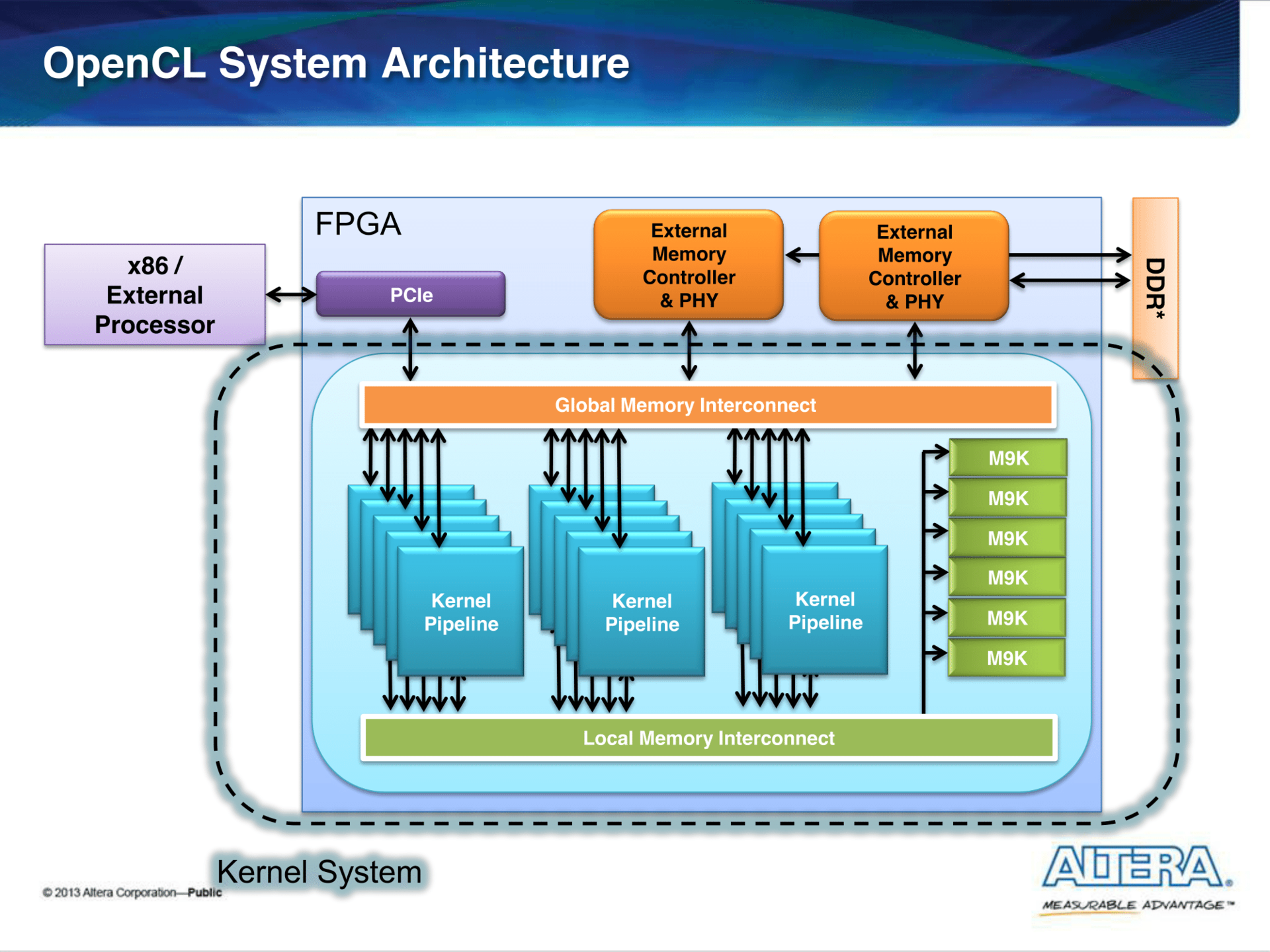
Прошивка состоит из:
- IP-ядер, которые обеспечивают доступ до периферии (PCIe, внешняя память (DDR, QDR)).
- Ядер, реализованые по принципу конвейера. В них происходят вычисления, описанные в OpenCL ядрах.
- Инфраструктура: Global и Local Memory Interconnect.
Интерконнект — это деление общей шины между модулями, которые являются мастерами и слейвами (ведущими и ведомыми).
В нашем случае мастера — это ядра, которые читают/пишут данные как в глобальную память (это может быть как память хоста, так и внешняя память), так и в локальную (внутреннюю), которую можно назвать кэшом. В результате процесса арбитража и мультиплексирования данных появляются модули, которые, как мы увидим ниже, могут отъедать значительное количество ресурсов.
Для удобства протокол общения между модулями стандартизируют. Altera в своих проектах использует интерфейсы типа Avalon: Avalon-MM (Memory Mapped) и Avalon-ST (Streaming). Я на этом подробно останавливаться не буду: читатель может самостоятельно про это почитать тут. В этой статье большинство интерконнекта будет именно интерфейса Avalon-MM.
Еще раз сделаю акцент на том, что всё это получается автоматически из описания ядра на OpenCL.
Результаты после обновления
В прошлой статье я описывал результаты сборки исходя из работы на версии Quartus 14.1.
Не так давно вышла версия 15.1, и я решил посмотреть, есть ли там большие различия. Для этого я перегенерировал исходники и пересобрал их новой версией.
Увы, в визуализаторе и профилировщике OpenCL никаких изменений не произошло (с виду): их вид всё еще оставляет желать лучшего.
Отчет о сборке с --profile (с профилирующими счетчиками):
+-----------------------------------------------------------------------------------+
; Fitter Summary ;
+---------------------------------+-------------------------------------------------+
; Fitter Status ; Successful - Sun Nov 22 13:18:14 2015 ;
; Quartus Prime Version ; 15.1.0 Build 185 10/21/2015 SJ Standard Edition ;
; Family ; Cyclone V ;
; Device ; 5CSEMA5F31C6 ;
; Timing Models ; Final ;
; Logic utilization (in ALMs) ; 5,472 / 32,070 ( 17 % ) ;
; Total registers ; 10409 ;
; Total pins ; 103 / 457 ( 23 % ) ;
; Total block memory bits ; 127,344 / 4,065,280 ( 3 % ) ;
; Total RAM Blocks ; 44 / 397 ( 11 % ) ;
; Total PLLs ; 2 / 6 ( 33 % ) ;
; Total DLLs ; 1 / 4 ( 25 % ) ;
+---------------------------------+-------------------------------------------------+
По сравнению с предыдущей версией компилятора проект похудел примерно на 100 ALM.
А вот отчет сборки без профилирующих счетчиков:
+-----------------------------------------------------------------------------------+
; Fitter Summary ;
+---------------------------------+-------------------------------------------------+
; Fitter Status ; Successful - Sun Nov 22 13:51:21 2015 ;
; Quartus Prime Version ; 15.1.0 Build 185 10/21/2015 SJ Standard Edition ;
; Family ; Cyclone V ;
; Device ; 5CSEMA5F31C6 ;
; Timing Models ; Final ;
; Logic utilization (in ALMs) ; 4,552 / 32,070 ( 14 % ) ;
; Total registers ; 7991 ;
; Total pins ; 103 / 457 ( 23 % ) ;
; Total block memory bits ; 127,344 / 4,065,280 ( 3 % ) ;
; Total RAM Blocks ; 44 / 397 ( 11 % ) ;
; Total PLLs ; 2 / 6 ( 33 % ) ;
; Total DLLs ; 1 / 4 ( 25 % ) ;
+---------------------------------+-------------------------------------------------+
Как видим, около 1000 ALM занимают профилирующие счетчики и логика, которые их «вычитывает».
В дальнейшем именно этот отчет мы будем использовать для анализа, что сколько занимает.
Первый взгляд на проект
Напомню, что проект выложен на на гитхабе.
Файл проекта называется незамысловато: top.qpf (QPF — Quartus Project File), самый главный модуль top.v, который по факту содержит экземпляр модуля system и простой счетчик, который отображается на светодиодах.
system (4535 ALM)
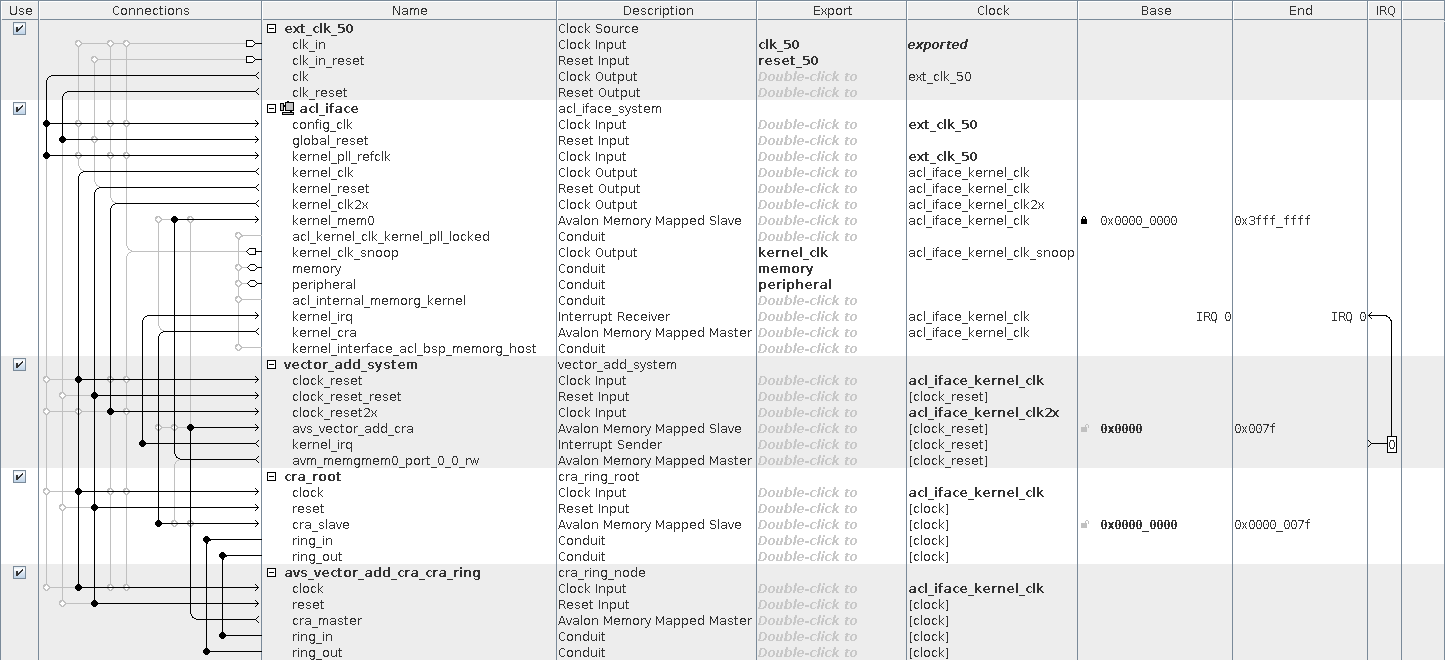
system — это автосгенеренный модуль с помощью Qsys. Qsys — это GUI-ишная тулза, которая позволяет соединять различные IP-блоки, автоматически генерируя код модулей, которые необходимы для интерконнекта, перехода с одной частоту на другую и пр.
Модули:
- vector_add_system (2141 ALM) — это модуль, который реализует то, что мы написали в ядре vector_add.
- acl_iface (2343 ALM) — инфраструктура, которая обеспечивает более удобный доступ и взаимодейстие с ядром.
Интерфейсы:
- avs_vector_add_cra — Avalon-MM для управления ядром.
- avm_memgmem0_port_0_0_rw — Avalon-MM для доступа к DDR памяти. Ширина данных — 256 бит.
acl_iface (2343 ALM)
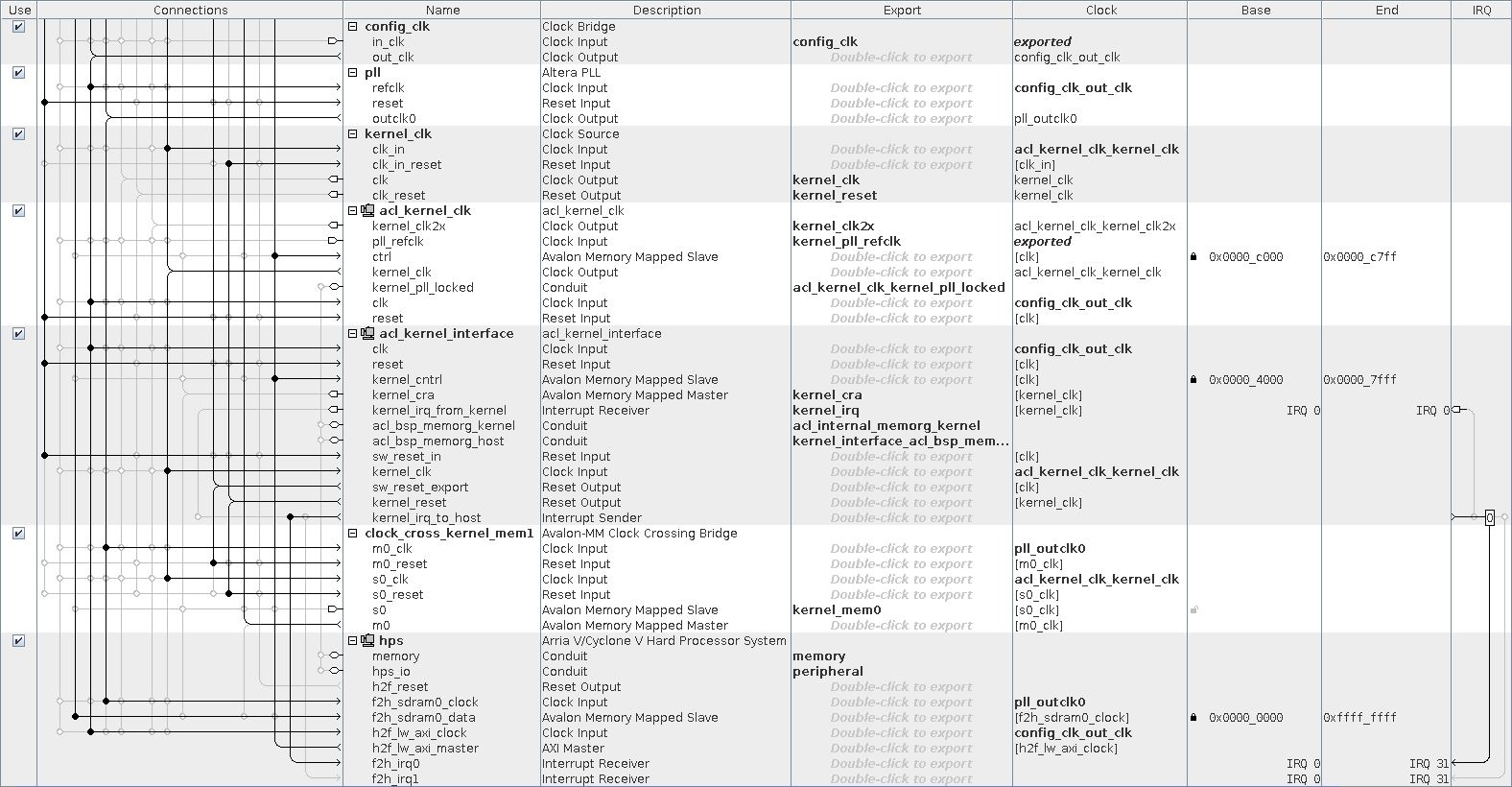
Модули:
- pll (0 ALM): PLL, которая получает клок pll_outclk0 (100 МГц) из config_clk (50 МГц, поступает с внешнего генератора).
- acl_kernel_clk (1057 ALM): еще одна PLL: она генерирует клок, который подается на ядро. Она имеет интересный нюанс: о ней более подробно поговорим позже.
- acl_kernel_interface (439 ALM): обеспечивает «взаимодействие» ядра и процессора (через интерфейс управления и прерывание).
- clock_cross_kernel_mem1 (82 ALM): он занимается «согласованием» интерфейсов, которые работают на разных частотах (CDC).
- hps (0 ALM): это инстанс HPS (Hard Processor System). Никакой логики в FPGA он не занимает, т.к. это аппаратное ядро.
Интерфейсы:
- f2h_sdram0 — Avalon-MM интерфейс для доступа к DDR памяти. Ширина данных — 256 бит, а частота работы — pll_outclk0 (100 МГц).
- h2f_lw — AXI интерфейс. Через него CPU (ARM) имеет возможность управлять и настраивать систему используя контрольные/статусные регистры кернела и т.д.
Если сложим суммарную ёмкость этих модулей, то сумма не сойдется. Дело в том, что Qsys по умолчанию не показывает модули типа interconnect. Для отображения их необходимо нажать Show System With Qsys Interconnect в меню System. После этого можно увидеть, что есть модули вида mm_interconnect_*, которые занимают 568 и 195 ALM.
vector_add_system (2141 ALM)
Архитектуру этого модуля нельзя посмотреть в GUI: для понимания как он работает погружаемся в Verilog.
Примерная схема выглядит так: 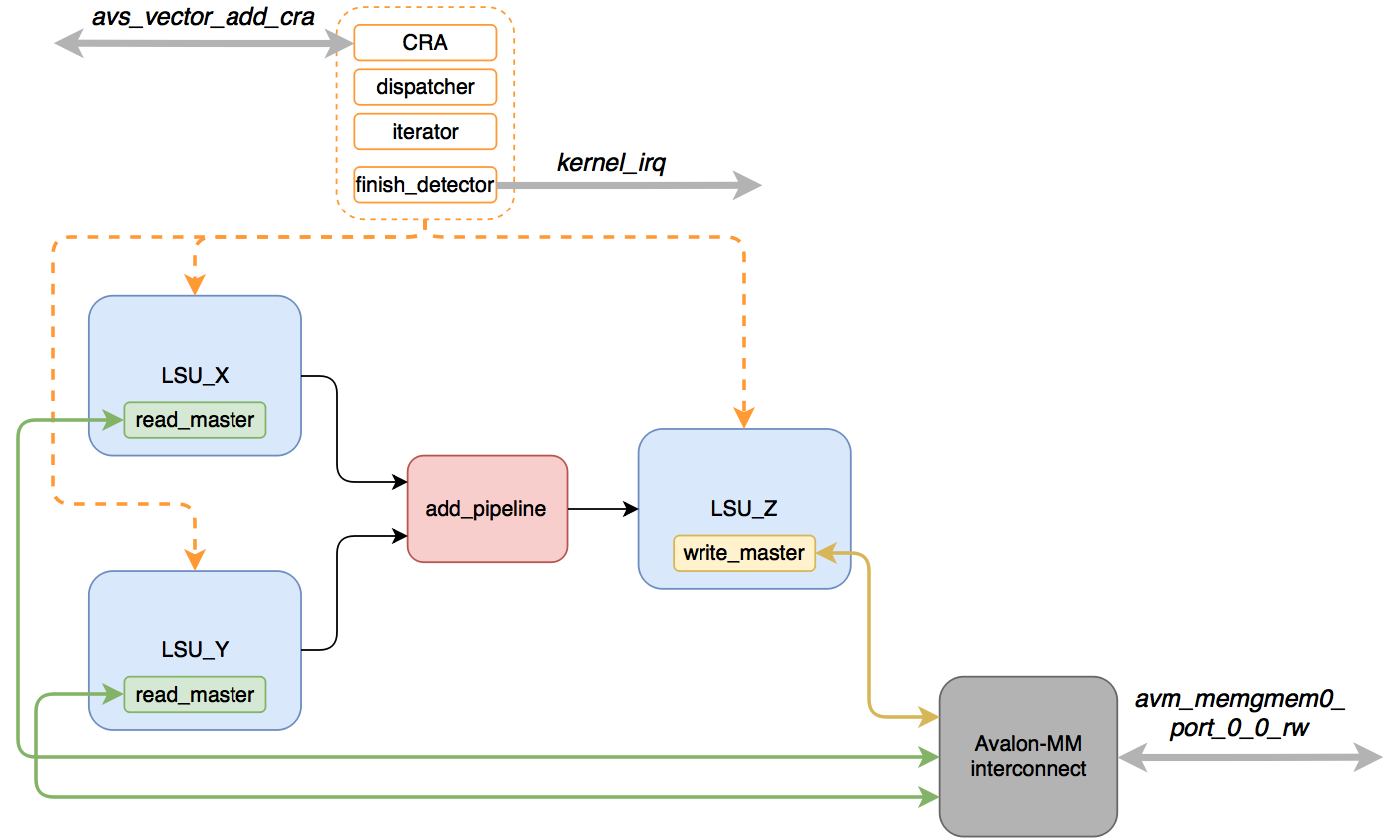
- vector_add_system_interconnect_* (443 ALM) — модули интерконнекта, которые проводят арбитраж и мультиплексирование интерфейса avm_memgmem0_port_0_0_rw
- LSU_X (235), LSU_Y (239) — вычитывают данные из глобальной памяти для векторов (аргументы ядра x и y соответственно).
- LSU_Z (424 ALM) — записывает результат вычислений в глобальную память (аргумент z).
- acl_id_iterator (228 ALM), acl_work_group_dispatcher (149 ALM) — они выдают задание для выполнения ядру (показывают, какой элемент надо обработать).
- acl_kernel_finish_detector (144 ALM) — определяет, когда ядро закончило работу.
Примечание:
LSU-модули являются инстансами одного модуля (lsu_top) и имеют названия lsu_local_bb0_ld_, lsu_local_bb0_ld__u0 и lsu_local_bb0_st_add. Для удобства я придал им более «человечные» названия. Более подробно про LSU мы поговорим ниже.
Как работает ядро:
- Происходит настройка через CRA, запускается обработка.
- LSU_X и LSU_Y получают «команды» на чтение данных и делают запросы к глобальной памяти.
- Прочитанные данные буферизируются в памяти (FIFO), до тех пор, пока не будут готовы данные с обоих LSU.
- Как только данные есть в обоих FIFO, они отправляются на конвеер, который производит сложение.
- Результат попадает в LSU_Z, где они дожидаются возможности быть записанными в глобальную память.
- Как только обработано желаемое количество элементов, и все результаты записаны в память (нет отложенных записей) срабатывает kernel_finish_detector — выставляется прерывание kernel_irq.
Важно отметить, что три LSU будут между собой бороться за один интерфейс доступа к глобальной памяти — они являются мастерами интерфейса Avalon-MM.
Конвеер, который я обозначил в схеме как add_pipeline на самом деле в отдельный модуль не помещается: он просто расположен в файле vector_add.v в модуле vector_add_basic_block_0.
Сама строчка, которая осуществляет сложение двух 32-битных чисел, выглядит вот так:
assign local_bb0_add = (rstag_3to3_bb0_ld__u0 + rstag_3to3_bb0_ld_);
Логические элементы, которые будут созданы из этой строчки и делают всю полезную работу.
Всё остальное — инфраструктура, которая подгоняет данные к этой логике.
LSU (Load Store Unit)
Самым интересным модулем этого ядра является LSU. Давайте посмотрим, как он работает.
lsu_top — это по факту обертка над другими lsu_*-модулями, которые выбираются в зависимости от параметров READ и STYLE.
Из всех разновидностей у нас будет только две:
- LSU_READ_STREAMING — LSU_X, LSU_Y (READ = 1, STYLE = «STREAMING»)
- LSU_WRITE_STREAMING — LSU_Z (READ = 0, STYLE = «STREAMING»)
LSU_READ_STREAMING
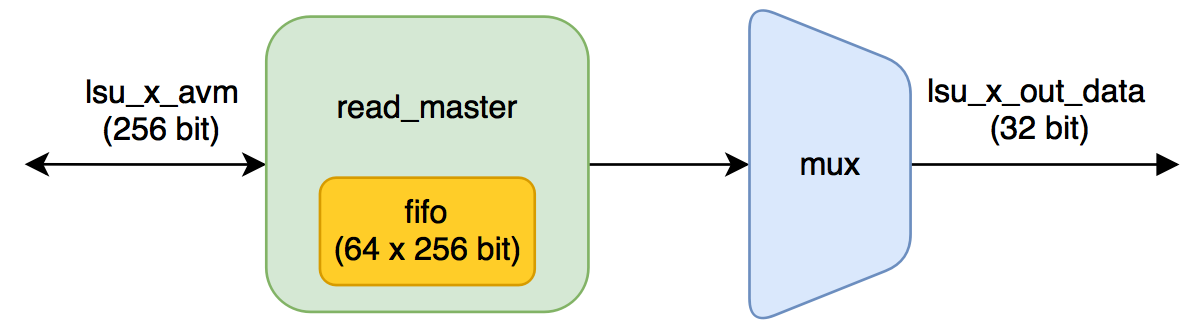
Обратим внимание на параметры модуля:
BURSTCOUNT_WIDTH = 5;
MEMORY_SIDE_MEM_LATENCY = 89;
BURSTCOUNT_WIDTH показывает ширину сигнала avm_burstcount — при запросе по интерфейсу Avalon-MM там располагается количество слов, которое необходимо прочитать при бёрстной транзакции.
Если ширина сигнала равна пяти, то максимальное значение бёрста равно 16. Это явно следует из спецификации:
The value of the maximum burstcount parameter must be a power of 2.
A burstcount interface of width n can encode a max burst of size 2^(n-1).
For example, a 4-bit burstcount signal can support a maximum burst count of 8.
The minimum burstcount is 1.
Это значит, что максимум за один запрос будет прочитано 16 256-битных слов — это 4096 Кбит или 128 32-битных чисел (мы складываем именно 32-битные целые числа).
MEMORY_SIDE_MEM_LATENCY влияет на количество слов FIFO в lsu_burst_read_master. Эта FIFO служит для буферизации читаемых данных с глобальной памяти.
Как определяется количество слов для неё:
localparam MAXBURSTCOUNT=2**(BURSTCOUNT_WIDTH-1);
// Parameterize the FIFO depth based on the "drain" rate of the return FIFO
// In the worst case you need memory latency + burstcount, but if the kernel
// is slow to pull data out we can overlap the next burst with that. Also
// since you can't backpressure responses, you need at least a full burst
// of space.
// Note the burst_read_master requires a fifo depth >= MAXBURSTCOUNT + 5. This
// hardcoded 5 latency could result in half the bandwidth when burst and
// latency is small, hence double it so we can double buffer.
localparam _FIFO_DEPTH = MAXBURSTCOUNT + 10 + ((MEMORY_SIDE_MEM_LATENCY * WIDTH_BYTES + MWIDTH_BYTES - 1) / MWIDTH_BYTES);
// This fifo doesn't affect the pipeline, round to power of 2
localparam FIFO_DEPTH = 2**$clog2(_FIFO_DEPTH);
_FIFO_DEPTH = 16 + 10 + ((89 * 4 + 32 - 1)/32) = 39
Округляем вверх до числа, кратного степени двойки:
FIFO_DEPTH = 64
Вывод:
будет выделен буфер (кэш) на 64 слова по 256 бит.
На самом для фиксирования этого факта не обязательно было ковырять исходники: достаточно глянуть секцию RAM Summary отчета от сборке. Наш расчет оказался верным, причем в отчете видно, что будет использовано 7 блоков M10K. Семь блоков это 10240 бит * 7 = 70 Кбит, вместо ожидаемых 256 бит * 64 = 16 Кбит.
Почему так произошло?
В FPGA внутренняя память — это много маленьких блоков, которые могут быть по разному настроены.
Посмотреть как можно сконфигурировать блок M10K (а именно он составляет основу в чипах семейства Cyclone V) можно тут.
Максимальная длина слова в блоке памяти — 40 бит, если необходимо создать слово в 256 бит, то надо 256/40 = 6.4 → 7 блоков, которые и получились. Из-за того, что количество слов в памяти выбрано 64, то каждый блок будет сконфигурирован как 64×40, и оставшиеся 75% памяти будут просто не использоваться.
На что влияет размер бёрста и размер кэша?
- Чем больше бёрст, тем больше мы можем прочитать за один запрос, но при этом будут блокироваться остальные запросы к памяти (у нас три мастера, которые хотят общаться с внешней памятью).
- Чем больше кэш, тем больше данных есть в «запасе» для обработки, пока читается новая порция данных. Минусов большего кэша я не знаю, кроме расхода ресурсов. В данном случае можно было сделать кэш с количеством слов равное 256 и было бы потрачено такое же количество блоков M10K.
LSU_WRITE_STREAMING
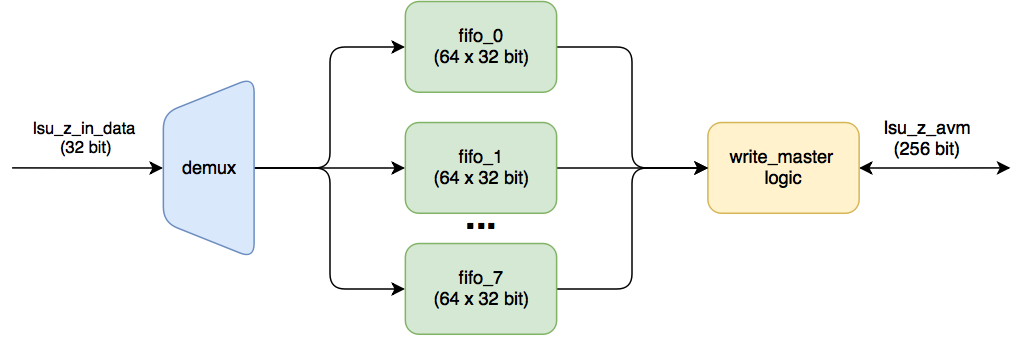
Поступающие 32 битные данные (результат сложения) кладутся по очереди в свои FIFO. Как только набирается в каждой из них по MAXBURSTCOUNT (для этого модуля этот параметр тоже равен 16), то происходит транзакция записи в память. Каждая из таких FIFO имеет ширину данных размером 32. Таких фифошек FIFO восемь штук (256/32).
На какое количество данных рассчитаны эти фифошки?
Расчет возьмем из кода lsu_streaming_write. Для этого модуля параметр. MEMORY_SIDE_MEM_LATENCY равен 32.
localparam MAXBURSTCOUNT=2**(BURSTCOUNT_WIDTH-1);
localparam __FIFO_DEPTH=2*MAXBURSTCOUNT + (MEMORY_SIDE_MEM_LATENCY * WIDTH + MWIDTH - 1) / MWIDTH;
localparam _FIFO_DEPTH= ( __FIFO_DEPTH > MAXBURSTCOUNT+4 ) ? __FIFO_DEPTH : MAXBURSTCOUNT+5;
// This fifo doesn't affect the pipeline, round to power of 2
localparam FIFO_DEPTH= 2**($clog2(_FIFO_DEPTH));
MAXBURSTCOUNT = 2^4 = 16
__FIFO_DEPTH = 2 * 16 + ( 32 * 32 + 256 - 1)/256 = 36 + 5 = 41
_FIFO_DEPTH = 41
Округляем вверх до кратного степени двойки:
FIFO_DEPTH = 64
Подтвержаем отчетом: 64×32 = 2048 бит (1 M10K).
Так как FIFO полностью отдельные, то на каждую FIFO выделятся по одному блоку M10K, что приводит к 8 блокам M10K, против 7 блоков M10K в lsu_read_streaming.
Почему сделали 8 FIFO, хотя можно было сделать одну, но широкую? Скорее всего так проще сделать (не надо отдельно хранить количество валидных слов).
Как вычисляются параметры LSU?
Попробуем разобраться, откуда такие числа возникли:
Есть подозрение, что эти настройки беруться из файла, который описывает плату (altera/15.1/hld/board/de1soc/de1soc_sharedonly/board_spec.xml).
Находим строчку, которая связана с глобальной памятью:
Для разъяснений этих параметров обратимся к Altera SDK for OpenCL: Custom Platform Toolkit User Guide глава XML Elements, Attributes, and Parameters in the board_spec.xml File.
max_bandwidth — The maximum bandwidth of all global memory interfaces combined in their current configuration. The Altera Offline Compiler uses max_bandwidth to choose an architecture suitable for the application and the board. Compute this bandwidth value from datasheets of your memories.
max_bandwidth — Максимальная пропускная способность всех интерфейсов для глобальной памяти. Altera Offline Compiler использует max_bandwidth для выбора архитектуры, которая лучше всего подходит для конкретной платы и приложения. Вычислите эти значения исходя из параметров используемой памяти.
К сожалению нет пояснений в каких единицах и как это считается: с одной стороны в профилировщике писалось 6400 MB/s, с другой стороны по расчетам 6400 MB/s никак не получаются: 400 (МГц, тактовая частота DDR) * 32 (бит, ширина сигнала данных на DDR-интерфейсе) * 2 (работа по двум фронтам) = 25600 Mb/s = 3200 MB/s. Либо надо считать в обе стороны?
max_burst — Maximum burst size for the slave interface.
max_burst — Максимальный размер берста для ведомого (слейв) интерфейса.
В нашем случае — 16, что дает BURSTCOUNT_WIDTH = 5. Но почему именно 16? Интерфейс fpga2hps_sdram поддерживает max_burstcount = 128. 16 — это какое-то магическое число, подходит всем? :)
latency — An integer specifying the time in nanoseconds (ns) for the memory interface to respond to a request. The latency is the round-trip time from the kernel issuing the board system a memory read request to the memory data returning to the kernel. For example, the Altera DDR3 memory controller running at 200 MHz with clock-crossing bridges has a latency of approximately 240 ns.
latency — Целое число, которые показывает время в наносекундах, необходимое
интерфейсу памяти для ответа. Задержка — это время от запроса на чтение, до получения данных в ядре. Например, Altera DDR3 контроллер, работающий на частоте 200 МГц в связке с модулем для перехода на другую частоту, имеет задержку около 240 нс.
Допустим, что в нашем случае тоже задержка 240 ns. Очевидно, что размерность MEMORY_SIDE_MEM_LATENCY это количество тактов (да и комментарий это подсказывает: Latency in cycles between LSU and memory).
Проведём несколько экспериментов, изменяя значения в board_spec.xml (maxburst, latency) и структуру ядра (количество аргументов, которые складываются (readers)). Следим за значением параметра MEMORY_SIDE_MEM_LATENCY у обоих модулей (LSU_X (lsu_read_streaming) и LSU_Z (lsu_write_streaming)).
|--------------------------------------------------------|
| maxburst | latency | readers | MEMORY_SIDE_MEM_LATENCY |
| | | |-------------------------|
| | | | LSU_X | LSU_Z |
|--------------------------------------------------------|
| 16 | 0 | 1 | 25 | 16 |
| 16 | 100 | 1 | 45 | 16 |
| 16 | 240 | 1 | 73 | 16 |
|--------------------------------------------------------|
| 16 | 0 | 2 | 41 | 32 |
| 16 | 100 | 2 | 61 | 32 |
| 16 | 240 | 2 | 89 | 32 |
|--------------------------------------------------------|
| 16 | 0 | 3 | 57 | 48 |
| 16 | 100 | 3 | 77 | 48 |
| 16 | 240 | 3 | 105 | 48 |
|--------------------------------------------------------|
| 32 | 0 | 1 | 41 | 32 |
| 32 | 100 | 1 | 61 | 32 |
| 32 | 240 | 1 | 89 | 32 |
|--------------------------------------------------------|
| 32 | 0 | 2 | 73 | 64 |
| 32 | 100 | 2 | 93 | 64 |
| 32 | 240 | 2 | 121 | 64 |
|--------------------------------------------------------|
| 32 | 0 | 3 | 105 | 96 |
| 32 | 100 | 3 | 125 | 96 |
| 32 | 240 | 3 | 153 | 96 |
|--------------------------------------------------------|
Какие прослеживаются зависимости:
- При увеличении latency и фиксировании maxburst и readers LSU_X_MEMORY_SIDE_MEM_LATENCY возрастает на значение равное latency/5. Скорее всего 5 — это 5 ns (нас отсылают к магической частоте 200 МГц?).
- При увеличении количества читателей LSU_X_MEMORY_SIDE_MEM_LATENCY возрастает на значение бёрста.
- LSU_Z_MEMORY_SIDE_MEM_LATENCY линейно зависит от количества элементов, которые хотят получать доступ к глобальной памяти и от значения максимально бёрста.
Виднеются формулы:
- LSU_X_MEMORY_SIDE_MEM_LATENCY = 9 + readers * maxburst + latency/5. (9 — это либо какое-то магическое число, либо еще одна характеристика ядра, до которой я не докопался. Возможно, это общая задержка ядра).
- LSU_Z_MEMORY_SIDE_MEM_LATENCY = maxburst * readers.
Примечание:
эти формулы только для конкретного ядра (реализации), для другого всё может быть иначе.
На какой частоте работает ядро
Генерацией тактового сигнала для ядра занимается модуль acl_kernel_clk.
В его основе лежит PLL, которая может динамически реконфигурироваться (менять выходную частоту).
Если откроем этот модуль в Qsys или system_acl_iface_acl_kernel_clk_kernel_pll.v, то увидим, что эта PLL генерирует два сигнала — 140 МГц (kernel_clk) и 280 МГц (kernel_clk2x). Сразу скажу, что kernel_clk2x нигде не используется.
Означает ли, что ядро всегда (и любое) будет работать только на частоте 140 МГц и его никак нельзя разогнать? Конечно же, нет.
140 МГц — это настройка для конкретно этой платы.
В завимости от того, какие логические элементы используются и как они соединены, то значение тактовой частоты, на которой схема будет гарантировано работать без сбоев может быть различным. Я затрагивал этот вопрос в статье про конвейеризацию.
Задача компилятора — расположить примитивы (логические элементы, блоки памяти и пр.) так, чтобы удовлетворить заданному требованию частоты. Это значит что:
- он не старается найти такое расположение, которое даст самую максимальную тактовую частоту.
- если в течении некоторого времени он, перебирая расположение элементов в чипе, понимает, что он развести не может, то он оставляет один из лучших вариантов (который был за время поиска).
Допустим вместо 140 МГц Quartus показывает максимальную тактовую частоту 135 МГц. Это значит, что:
- компилятор гарантирует, что если подать 135 МГц, то вычисления произойдут корректно, ничего не зависнет и пр. (если нет алгоритимических ошибок в самом коде, разумеется).
- если подать 140 МГц, то может так произойти, что всё будет хорошо. А может быть и нет. Это зависит от чипа — чипы с одной маркировкой могут немного отличаться, поэтому компилятор перестраховывается и расчитывает по худшему случаю.
Чаще всего после пересборки проекта FPGA разработчики смотрят отчет о сборке и интересуются: уложилось ли по частоте схема. Мы же в прошлой статье просто взяли бинарник и зашили его. Что будет, если компилятор не уложился в эти 140 МГц? Расчеты будут неверны?
Для того, чтобы скрыть от разработчиков эту проблему, Altera сделала очень интересную фишку (наверно, самую интересную из того, что я раскопал, когда игрался с Altera OpenCL SDK):
- После окончания сборки вызывается скрипт adjust_plls.tcl. Он получает максимальную допустимую частоту для ядра (Fmax), и генерирует файлы (pll_rom.mif и pll_rom.hex), которые используются для инициализации ROM в модуле pll_rom.
- Когда загружается FPGA, на логику подается заданная частота (140 МГц). Перед запуском ядра, вычитываются данные из ROM, и используя эти коэффициенты происходит перестройка PLL (через интерфейс реконфигурации). Как только реконфигурация закончилась на кернел уже подается нужная частота.
Итого:
- На ядро будет подана та, частота которую можно подавать. Если логика оказалась слишком ёмкой, и не удалось уложиться в заданное число, то вычисления не сломаются — просто они будут медленее идти.
- Если же допустимая частота выше, то PLL будет настроено на это значение (вычисления ускорятся). Поиска расположения, которое даст максимальную частоту, не будет. Если есть ощущение, что еще можно «разогнать», то лучше вручную поднимать планку у частоты PLL.
Немного упрощаем сборку
Перед тем как мы продолжии познавать как устроено и настраивается ядро я сделаю небольшое отступление, которое может помочь вам, если захотите внести какие-то изменения (в ядро) или отлаживаться на железе.
Напомню процесс разработки: файл vector_add.aocx, который содержит прошивку FPGA получается из vector_add.cl.
Проблема заключается в том, что если вы внесли какие-то изменения в проект Квартуса, то они не попадут в *.aocx, т.к. при перезапуске утилиты aoc происходит копирование «дефолтного проекта» и перегенерация Verilog IP. Тем самым ваши изменения пропадут.
Утилита aoc является бинарником, но можно проследить, что при вызове:
$ aoc device/vector_add.cl -o bin/vector_add.aocx --board de1soc_sharedonly --profile -v
Происходит запуск скрипта на перле aoc.pl, который уже и делает всю полезную работу.
Можно напрямую вызывать этот скрипт, без использования утилиты aoc.
$ /home/ish/altera/15.1/quartus/linux64/perl/bin/perl /home/ish/altera/15.1/hld/share/lib/perl/acl/aoc.pl device/vector_add.cl --board de1soc_sharedonly --profile -v
Хорошо, что скрипт написан на интерпретируемом языке, а значит мы сможем разобраться, что он делает и внести свои изменения.
В самом начале скрипта описаны различные переменные, которые настраиваются через ключи (в том числе скрытые от пользователя в хелпе).
Так, там обнаруживается ключик --quartus, который вызывает только сборку квартуса и упаковку необходимых частей в *.aocx файл. Никакой перегенерации проекта (исходников) при этом не будет.
Так же для дополнительного удобства можно вывести лог сборки на консоль. Для этого надо в качестве stdout и stderr указать пустые строчки в вызове функции mysystem_full:
$return_status = mysystem_full(
{'time' => 1, 'time-label' => 'Quartus compilation', 'stdout' => '', 'stderr' => ''},
$synthesize_cmd);
Теперь мы можем легко вносить любые изменения в проект (играться с оптимизациями, добавлять SignalTap) и просто вызывать пересборку только проекта для FPGA, а не всего ядра с вызовом clang’a и перегенерацией кода.
Для проверки этого я добавил SignalTap на интерфейсы (а так же добавил 15 секундый sleep после загрузки ядра и стартом вычислений, чтобы я успел подключиться с помощью дебаггера).

Как управляется ядро
Интерфейс avs_vector_add_cra служит для настройки кернела: по адресам регистров записываются данные.
К сожалению, в открытом доступе я не нашел карты регистров и что как надо настраивать, поэтому придется сделаем небольшое исследование.
Все регистры описываются в vector_add.v и имеют адекватные названия.
Они являются 64-битными: [31:0] обозначают нижние 32 бита, а [63:32] — старшие.
0x0 - status
0x1 - 0x4 - profile
0x5 - [31:0] - work_dim
0x5 - [63:32] - workgroup_size
0x6 - [31:0] - global_size[0]
0x6 - [63:32] - global_size[1]
0x7 - [31:0] - global_size[2]
0x7 - [63:32] - num_groups[0]
0x8 - [31:0] - num_groups[1]
0x8 - [63:32] - num_groups[2]
0x9 - [31:0] - local_size[0]
0x9 - [63:32] - local_size[1]
0xA - [31:0] - local_size[2]
0xA - [63:32] - global_offset[0]
0xB - [31:0] - global_offset[1]
0xB - [63:32] - global_offset[2]
0xC - [31:0] - kernel_arguments[31:0] - input_x[31:0]
0xC - [63:32] - kernel_arguments[63:32] - input_x[63:32]
0xD - [31:0] - kernel_arguments[95:64] - input_y[31:0]
0xD - [63:32] - kernel_arguments[127:96] - input_y[63:32]
0xE - [31:0] - kernel_arguments[159:128] - input_z[31:0]
0xE - [63:32] - kernel_arguments[191:160] - input_z[63:32]
Исходя из названий, можно попытаться наугад что-то настроить и запустить, но давайте не рисковать, а просто узнаем что и в каком порядке туда пишется.
Запишем все транзакции по этому интерфейсу (с помощью SignalTap’a):
----------------------------------------------
| addr | write_data | byte_enable |
----------------------------------------------
| 0x5 | 0x00000000 0x00000001 | 0x0F |
| 0x5 | 0x000F4240 0x00000000 | 0xF0 |
----------------------------------------------
| 0x6 | 0x00000000 0x000F4240 | 0x0F |
| 0x6 | 0x00000001 0x00000000 | 0xF0 |
----------------------------------------------
| 0x7 | 0x00000000 0x00000001 | 0x0F |
| 0x7 | 0x00000001 0x00000000 | 0xF0 |
----------------------------------------------
| 0x8 | 0x00000000 0x00000001 | 0x0F |
| 0x8 | 0x00000001 0x00000000 | 0xF0 |
----------------------------------------------
| 0x9 | 0x00000000 0x000F4240 | 0x0F |
| 0x9 | 0x00000001 0x00000000 | 0xF0 |
----------------------------------------------
| 0xA | 0x00000000 0x00000001 | 0x0F |
| 0xA | 0x00000000 0x00000000 | 0xF0 |
----------------------------------------------
| 0xB | 0x00000000 0x00000000 | 0x0F |
| 0xB | 0x00000000 0x00000000 | 0xF0 |
----------------------------------------------
| 0xC | 0x00000000 0x20100000 | 0x0F |
| 0xC | 0x00000000 0x00000000 | 0xF0 |
----------------------------------------------
| 0xD | 0x00000000 0x20500000 | 0x0F |
| 0xD | 0x00000000 0x00000000 | 0xF0 |
----------------------------------------------
| 0xE | 0x00000000 0x20900000 | 0x0F |
| 0xE | 0x00000000 0x00000000 | 0xF0 |
----------------------------------------------
| 0x0 | 0x00000000 0x00000001 | 0x0F |
----------------------------------------------
Примечание:
byte_enable «выбирает» в какие байты регистра писать: так, в рамках самой первой транзакции записали 0×00000001 в нижние 32 бита регистра 0×5 (старшие 32 бита при этом не изменились).
Смотреть транзакции в SignalTap не всегда может быть удобно: на хосте есть возможность включить дополнительный дебаг через переменные окружения. Их можно подсмотреть в главе Troubleshooting Altera Stratix V Network Reference Platform Porting Guide.
Нам необходима переменная ACL_HAL_DEBUG. Выставляем её значение в 2 и запускаем хостовое приложение vector_add:
root@socfpga:~/myvectoradduint# export ACL_HAL_DEBUG=2
root@socfpga:~/myvectoradduint# ./vector_add
// <пропущен различный дебаг>
:: Launching kernel 0 on accelerator 0.
:: Writing inv image [ 0] @ 0x28 := 1
:: Writing inv image [ 4] @ 0x2c := f4240
:: Writing inv image [ 8] @ 0x30 := f4240
:: Writing inv image [12] @ 0x34 := 1
:: Writing inv image [16] @ 0x38 := 1
:: Writing inv image [20] @ 0x3c := 1
:: Writing inv image [24] @ 0x40 := 1
:: Writing inv image [28] @ 0x44 := 1
:: Writing inv image [32] @ 0x48 := f4240
:: Writing inv image [36] @ 0x4c := 1
:: Writing inv image [40] @ 0x50 := 1
:: Writing inv image [44] @ 0x54 := 0
:: Writing inv image [48] @ 0x58 := 0
:: Writing inv image [52] @ 0x5c := 0
:: Writing inv image [56] @ 0x60 := 20100000
:: Writing inv image [60] @ 0x64 := 0
:: Writing inv image [64] @ 0x68 := 20500000
:: Writing inv image [68] @ 0x6c := 0
:: Writing inv image [72] @ 0x70 := 20900000
:: Writing inv image [76] @ 0x74 := 0
:: Accelerator 0 reporting status 2.
:: Accelerator 0 is done.
Можно заметить, что 0×28 — это байтовый оффсет 5-го 64-битного регистра.
Видно, что адреса и данные совпадают, правда, в этом дебаге нет информации о транзакции в нулевой регистр (даже если ACL_HAL_DEBUG поставить равным пяти).
Результат настройки:
- work_dim — 0×1 — т.к. у нас одномерный вектор.
- workgroup_size — 0xF4240 или 1000000.
- global_size — 0xF4240 для первого измерения и 0×1 для всех остальных.
- num_groups — 0×1 для всех измерений.
- local_size — 0xF4240 для первого измерения и 0×1 для всех остальных.
- global_offset — 0×0 для всех измерений.
- input_x, input_y, input_z — 0×20100000, 0×20500000, 0×20900000 соответственно.
После настройки ядра дергается младший бит нулевого регистра, который производит старт вычислений.
Пока крутится барабан, хочу передать привет разработчикам из Альтеры.
Зачем вы включаете обработку через регистр с названием status?
Может стоило его назвать иначе?
Симуляция ядра
Теперь мы понимаем, как настраивается ядро — давайте же его просимулируем!
Очень удобно, что у ядра всего два интерфейса — один для настройки, другой для чтения данных (еще есть интерфейс (размером в один сигнал) для выставления прерывания —, но нам это не так интересно).
Для симуляции ядра нам надо сделать всё как в реальной жизни:
- настроить его (теперь мы знаем что в какой последовательности надо писать, а интерфейс относительно простой).
- предоставить доступ до глобальной памяти, где выделены буфера и лежат данные.
Конечно же, никакой линукс и хостовое приложение симулировать мы не очень хотим, поэтому в качестве первого приближения можно ограничиться следующей схемой: 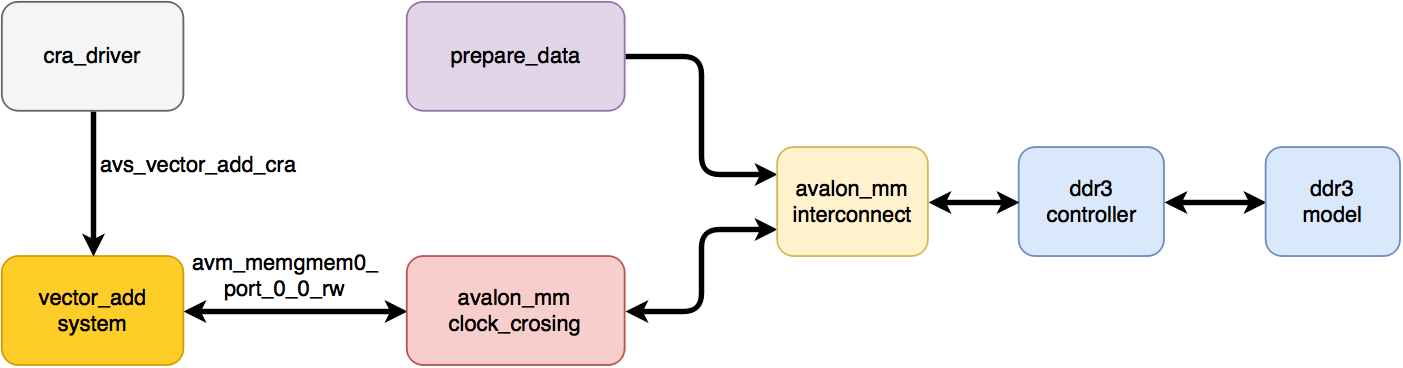
- cra_driver — драйвер для настройки ядра.
- vector_add_system — ядро, которое симулируем (DUT).
- avalon_mm_clock_crossing — переброс данных с частоты кернела (140 МГц) на частоту чтения из контроллера (100 МГц) и обратно.
- prepare_data — простые таски, которые записывают данные в буферы X и Y перед началом симуляции.
- avalon_mm_interconnect — мультиплексирование и арбитраж двух Avalon-MM интерфейсов.
- ddr3_contoller, ddr3_model — симуляционные модели Altera Hard Memory Controller и DDR3 памяти. Настройки модели и контроллера совпадают с теми, которые используются в модуле hps.
Драйвер для настройки ядра это просто последовательный вызов следующего таска с теми настройками ядра, что мы раскопали благодаря SignalTap’у:
task cra_write( input bit [3:0] _addr, bit [63:0] _data, bit [7:0] _byteenable );
$display("%m: _addr = 0x%x, _data = 0x%x, _byteenable = 0x%x",
_addr, _data, _byteenable );
@( posedge clk );
cra_addr <= _addr;
cra_wr_data <= _data;
cra_byteenable <= _byteenable;
cra_wr_en <= 1'b0;
@( posedge clk );
cra_wr_en <= 1'b1;
@( posedge clk );
cra_wr_en <= 1'b0;
// dummy waiting
repeat (10) @( posedge clk );
endtask
initial
begin
wait( ram_init_done );
wait( test_data_init_done );
cra_write( 4'h5, 64'h000F424000000000, 8'hF0 );
cra_write( 4'h5, 64'h0000000100000000, 8'hF0 );
cra_write( 4'h6, 64'h00000000000F4240, 8'h0F );
cra_write( 4'h6, 64'h0000000100000000, 8'hF0 );
cra_write( 4'h7, 64'h0000000000000001, 8'h0F );
cra_write( 4'h7, 64'h0000000100000000, 8'hF0 );
cra_write( 4'h8, 64'h0000000000000001, 8'h0F );
cra_write( 4'h8, 64'h0000000100000000, 8'hF0 );
cra_write( 4'h9, 64'h00000000000F4240, 8'h0F );
cra_write( 4'h9, 64'h0000000100000000, 8'hF0 );
cra_write( 4'hA, 64'h0000000000000001, 8'h0F );
cra_write( 4'hA, 64'h0000000000000000, 8'hF0 );
cra_write( 4'hB, 64'h0000000000000000, 8'h0F );
cra_write( 4'hB, 64'h0000000000000000, 8'hF0 );
cra_write( 4'hC, 64'h0000000020100000, 8'h0F );
cra_write( 4'hC, 64'h0000000000000000, 8'hF0 );
cra_write( 4'hD, 64'h0000000020500000, 8'h0F );
cra_write( 4'hD, 64'h0000000000000000, 8'hF0 );
cra_write( 4'hE, 64'h0000000020900000, 8'h0F );
cra_write( 4'hE, 64'h0000000000000000, 8'hF0 );
cra_write( 4'h0, 64'h0000000000000001, 8'h0F );
end
Для подготовки данных для которых необходимо сделать расчет пишем аналогичный таск, который будет писать в память по заранее забитым адресам. (Для выделения адресов нам никого (систему) спрашивать не надо). Для демонстрации не обязательно записывать 2×1000000 чисел как надо по условиям задачи — достаточно пару тысяч, для того, чтобы посмотреть как это работает. Если мы данные не запишем, то из памяти будут считываться x (unknown value), т.к. в эти ячейки ничего не было записано.
Смотрим результат симуляции (все числа на времянках в 16-ричной форме) (скриншоты лучше открыть в отдельном окне): 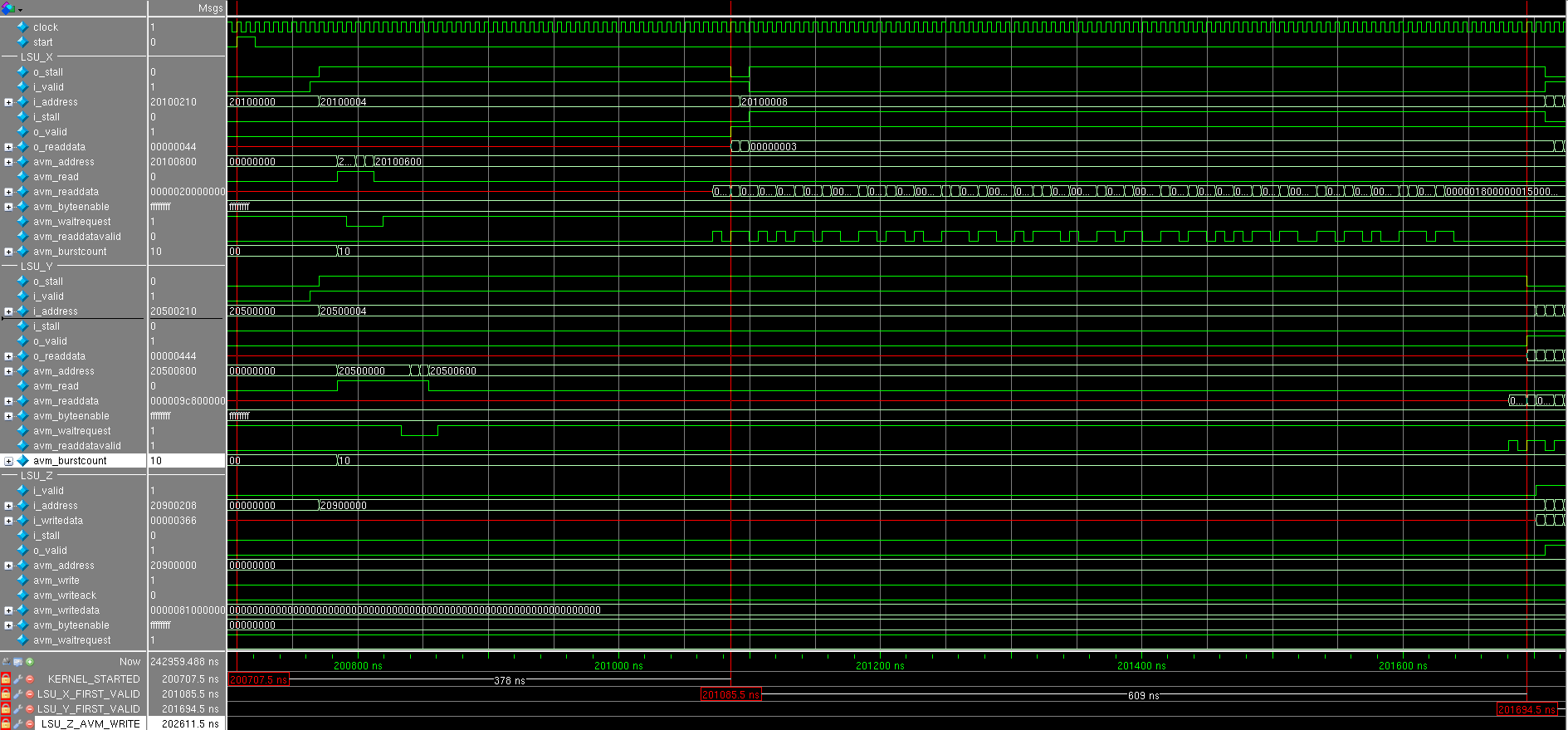
Приходит сигнал start и через несколько тактов оба LSU одновременно выставляют запрос на чтение данных с размером берста равным 0×10 = 16. Интересно, что сначала принимаются три запроса только от LSU_X, а потом от LSU_Y© Habrahabr.ru
