Akka Streams для простых смертных
Как можно несколькими строками кода распечатать непрерывный поток сообщений из Твиттера, добавив в него данные о погоде в местах проживания их авторов? И как при этом ограничить скорость запросов к провайдеру метеоусловий, чтобы они не внесли нас в черный список?
Расскажем вам сегодня, как это сделать, но сначала познакомимся с технологией Akka Streams, позволяющей работать с потоками данных в реальном времени так же просто, как программисты работают с LINQ-выражениями, не требуя при этом ручной реализации ни отдельных акторов, ни интерфейсов Reactive Streams.
В основе статьи — расшифровка доклада Вагифа Абилова с нашей декабрьской конференции DotNext 2017 Moscow.
Меня зовут Вагиф, я работаю в норвежской компании Miles. Сегодня поговорим о библиотеке Akka Streams.
Akka и Reactive Streams — это пересечение довольно узких множеств, и может создаться впечатление, что это такая ниша, для входа в которую нужно обладать каким-то большим знанием, но всё как раз наоборот. И эта статья призвана показать, что, используя Akka Streams, вы можете избежать программирования низкого уровня, которое требуется при работе Reactive Streams и Akka.NET. Забегая вперед, могу сразу сказать: если бы в самом начале нашего проекта, на котором мы используем Akka, мы знали о существовании Akka Streams, мы бы многое писали по-другому, сэкономили бы и время, и код.
«Едва ли не худшее, что вы можете сделать, это заставить людей, не испытывающих боли, принимать ваш аспирин»
Макс Кремински
«Закрытые двери, головная боль и интеллектуальные нужды»
Прежде чем мы зайдем в технические детали, немного о том, каким может оказаться ваш путь к Akka Streams, что вас туда может привести. Как-то мне на глаза попался блог Макса Кремински, где он задавался таким философским вопросом для программистов: как или почему программисту невозможно объяснить, что такое монады. Он объяснял это так: очень часто люди сразу переходят к техническим деталям, объясняя, как вообще красиво функциональное программирование и как много смысла в монаде, не удосужившись задаться вопросом, а зачем вообще программисту это может понадобиться. Проводя аналогию, это все равно, как пытаться продать аспирин, не удосужившись узнать, испытывает ли ваш пациент боль.
Пользуясь этой аналогией, хочется задать следующий вопрос: если Akka Streams — это аспирин, то что же должно быть болью, которая вас к нему приведет?
Для начала поговорим о потоках данных. Поток может быть достаточно простым, линейным.
Your browser does not support HTML5 video.
Вот у нас есть некий потребитель данных (кролик на видео). Он потребляет данные со скоростью, которая его устраивает. Это идеальное взаимодействие потребителя с потоком: он устанавливает пропускную способность, и данные к нему тихонечко поступают. Этот простой поток данных может быть бесконечным, а может и закончиться.
Но поток может быть и более сложным. Если вы рядышком посадите несколько кроликов, у нас уже будет параллелизация потоков. То, что пытается решить Reactive Streams — это как раз то, как можно общаться с потоками на более концептуальном уровне, т. е. вне зависимости от того, идет ли речь просто о каком-нибудь измерении датчика температуры, где у нас вступают линейные измерения, или же у нас непрерывные измерения тысяч датчиков температуры, поступающие в систему через очереди RabbitMQ и сохраняемые в системных логах. Всё вышеперечисленное может рассматриваться как один композитный поток. Если заходить еще дальше, то автоматизированное управление производством (например, каким-нибудь интернет-магазином) тоже можно свести к потоку данных, и было бы здорово, если бы можно было говорить о планировании такого потока вне зависимости от того, насколько он сложен.

У современных проектов не очень хорошо обстоит дело с поддержкой потоков. Если я правильно помню, Aaron Stannard, чей твит вы видите на картинке, хотел получить поток многогигабайтного файла, содержащего CSV, т.е. текст, и выяснилось, что нет ничего такого, что можно просто взять и сразу использовать, без кучи дополнительных действий. А просто получить стрим CSV-значений он не мог, что его и опечалило. Решений существует мало (за исключением каких-то специальных областей), очень многое реализуется старыми методами, когда мы всё это открываем, начинаем читать, буферизовать, в худшем случае вообще получаем что-то типа notepad, который говорит, что файл слишком большой.
На высоком концептуальном уровне мы все занимаемся обработкой потоков данных, и Akka Streams вам поможет, если:
- вы знакомы с Akka, но хотите избавить себя от деталей, связанных с написанием кода акторов и их координацией;
- вы знакомы с Reactive Streams и хотели бы воспользоваться готовой реализацией их спецификации;
- для моделирования вашего процесса подходят блочные элементы стадий Akka Streams;
- вы хотите использовать преимущества обратного давления Akka Streams (backpressure) для управления и динамического уточнения пропускной способности стадий вашего рабочего процесса.

Первый путь — это от акторов к Akka Streams, мой путь.
Картинка показывает, зачем мы стали пользоваться моделью акторов. Мы были измучены ручным управлением потоками, разделенным состоянием (shared state), вот этим всем. Каждый, кто работал с большими системами, с многопоточными, понимает, как много это отнимает времени и как легко в этом сделать ошибку, которая может оказаться фатальной для всего процесса. Это и привело нас к модели акторов. Мы не жалеем о сделанном выборе, но, разумеется, когда начинаешь работать, больше программировать, то не то что первоначальный энтузиазм уступает место чему-то другому, но начинаешь осознавать, что что-то можно было сделать еще более эффективно.
«По умолчанию в код акторов вписаны получатели их сообщений. Если я создаю актор A, который посылает сообщение актору B, а вы хотите заменить получателя на актор C, в общем случае у вас это не выйдет»
Ноэль Уэлш (underscore.io)
Акторы критикуют за то, что они не компонуются. Одним из первых, кто написал об этом в своем блоге, был один из разработчиков Underscore Ноэль Уэлш. Он обратил внимание, что система акторов выглядит примерно так:

Если не пользоваться какими-то дополнительными вещами, типа dependency injection, в актор вшит адрес его получателя.

Когда они начинают слать друг другу сообщения, все это вы задаете заранее, программируя акторы. И без дополнительных ухищрений получается такая вот жесткая система.
Один из разработчиков Akka, Роланд Кун, объяснил, что вообще понимать под плохой компоновкой. В основе посылки сообщений акторов лежит метод tell, т. е. однонаправленные сообщения: он имеет тип void, т. е. не возвращает ничего (или unit, в зависимости от языка). Поэтому нельзя из цепочки акторов построить описание процесса. Вот вы послали tell, дальше что? Стоп. У нас получился void. Можно сравнить его, например, с LINQ-выражениями, где каждый элемент выражения возвращает IQueryable, IEnumerable, и все это легко можно компоновать. Акторы такой возможности не дают. При этом Роланд Кун возразил против того, что они, мол, не компонуются в принципе, сказав, что на самом деле они компонуются другими способами, в таком же смысле, в каком поддается компоновке человеческое общество. Звучит как философский аргумент, но если задуматься, аналогия имеет смысл — да, акторы шлют друг другу однонаправленные сообщение, но мы тоже общаемся друг с другом, произнося однонаправленные сообщения, но при этом взаимодействуем достаточно эффективно, т. е. создаем сложные системы. Тем не менее такая критика акторов существует.
public class SampleActor : ReceiveActor
{
public SampleActor()
{
Idle();
}
protected override void PreStart() { /* ... */ }
private void Idle()
{
Receive(job => /* ... */);
}
private void Working()
{
Receive(job => /* ... */);
}
}
Помимо этого реализация актора требует как минимум написания класса, если работать на C#, или функции, если работать на F#. На примере выше — boilerplate code, который вам придется писать в любом случае. Хотя он не очень большой, но это определенное количество линий, которое вы на этом низком уровне всегда должны будете написать. Практически весь код, который здесь присутствует — это некая церемония. То, что происходит, когда актор непосредственно получает сообщение, здесь вообще не показано. И все это нужно писать. Это, конечно, не очень много, но это свидетельство того, что мы работаем с акторами на низком уровне, создавая такие void-методы.
Что, если бы мы могли выйти на другой, более высокий уровень, задаться вопросами моделирования нашего процесса, который включает в себя обработку данных, поступающих из разных источников, которые смешиваются, преобразовываются и передаются дальше?
var results = db.Companies
.Join(db.People,
c => c.CompanyID,
p => p.PersonID,
(c, p) => new { c, p })
.Where(z => z.c.Created >= fromDate)
.OrderByDescending(z => z.c.Created)
.Select(z => z.p)
.ToList();
Аналогом подобного подхода может стать то, к чему мы все уже десять лет как привыкли, работая с LINQ. Мы не задаемся вопросами, как работает join. Мы знаем, что есть такой LINQ-провайдер, который все это сделает для нас, и мы заинтересованы на более высоком уровне выполнением запроса. Причем мы в общем-то можем здесь смешивать базы данных, можем посылать дистрибутивные запросы. Что, если бы можно было описывать процесс таким образом?
HttpGet pageUrl
|> fun s -> Regex.Replace(s, "[^A-Za-z']", " ")
|> fun s -> Regex.Split(s, " +")
|> Set.ofArray
|> Set.filter (fun word -> not (Spellcheck word))
|> Set.iter (fun word -> printfn " %s" word)
(Источник)
Или, например, функциональные трансформации. Чем многим нравится функциональное программирование — это тем, что можно пропустить данные через серию трансформаций, и получится достаточно наглядный компактный код, вне зависимости от того, на каком языке вы это пишете. Его достаточно легко читать. Код на картинке специально написан на F#, но в общем-то, наверное, всем понятно, что тут происходит.
val in = Source(1 to 10)
val out = Sink.ignore
val bcast = builder.add(Broadcast[Int](2))
val merge = builder.add(Merge[Int](2))
val f1,f2,f3,f4 = Flow[Int].map(_ + 10)
source ~> f1 ~> bcast ~> f2 ~> merge ~> f3 ~> sink
bcast ~> f4 ~> merge ~>
(Источник)
Как тогда насчет такого? На примере выше у нас есть источник данных Source, который состоит из целых чисел от 1 до 10. Это так называемый графический DSL (domain-specific language). Элементами языка домена в примере выше являются символы однонаправленных стрелок — это дополнительные операторы, определенные средствами языка, графически показывающие направление потока. Мы пропускаем Source через серию трансформаций — для простоты демонстрации они все просто добавляют десятку к числу. Дальше идет Broadcast: мы умножаем каналы, т. е. каждое число поступает в два канала. Дальше опять прибавляем 10, смешиваем наши потоки данных, получаем новый поток, в нем тоже добавляем 10, и все это уходит у нас на сток данных, в котором ничего не происходит. Это реальный код, который написан на Scala, часть Akka Streams, реализованная на этом языке. Т. е. вы задаете фазы преобразований ваших данных, указываете, что с ними делать, задаете источник, сток, какие-то пропускные пункты, после чего формируете такой граф с помощью графического DSL. Это всё — код единой программы. Несколько строчек кода показывают, что у вас происходит в процессе.
Давайте разучимся писать код определения отдельных акторов и выучим вместо этого примитивы компоновки высокого уровня, которые внутри себя создадут и соединят требуемые акторы. Когда мы запустим такой граф, система, которая обеспечивает Akka Streams, сама создаст требуемого актора, пошлет туда все эти данные, обработает так, как надо, и в итоге выдаст их конечному получателю.
var runnable =
Source
.From(Enumerable.Range(1, 1000))
.Via(Flow.Create().Select(x => x * 2)
.To(Sink.ForEach(x => Console.Write(x.ToString));
На примере выше показано, как это может выглядеть на C#. Простейший способ: у нас есть один источник данных — это числа от 1 до 1000 (как видите, в Akka Streams любой IEnumerable может стать источником потока данных, что очень удобно). Мы делаем какое-нибудь простое вычисление, скажем, умножаем на два, а потом на стоке данных все это выдается на экран.
var graph = GraphDsl.Create(builder =>
{
var bcast = builder.Add(new Broadcast(2));
var merge = builder.Add(new Merge(2));
var count = Flow.FromFunction(new Func(x => 1));
var sum = Flow.Create().Sum((x, y) => x + y);
builder.From(bcast.Out(0)).To(merge.In(0));
builder.From(bcast.Out(1)).Via(count).Via(sum).To(merge.In(1));
return new FlowShape(bcast.In, merge.Out);
});
То, что показано на примере выше, называется «графический DSL на C#». На самом деле никакой графики здесь нет, это порт со Scala, но в C# нет возможности так определять операторы, поэтому это выглядит чуть более громоздко, но все равно достаточно компактно для того, чтобы понять, что здесь происходит. Итак, мы создаем некий граф (есть разные типы графа, здесь он называется FlowShape) из разных компонент, где присутствует источник данных и есть какие-то трансформации. Мы пускаем данные на один канал, в котором генерируем count, т. е. число элемента данных, которое будет передано, а в другом генерируем сумму и потом все это смешиваем. Далее мы увидим более интересные примеры, чем просто обработка целых чисел.
Это первый путь, который может привести вас к Akka Streams, если у вас есть опыт работы с моделью акторов, и вы задумались о том, нужно ли писать вручную каждый, даже самый простой актор. Второй путь, по которому приходят к Akka Streams — через Reactive Streams.
Что такое Reactive Streams? Это совместная инициатива выработки стандарта асинхронной обработки потоков данных. Она определяет минимальный набор интерфейсов, методов и протоколов, описывающих необходимые операции и сущности для достижения цели — асинхронной обработки данных в реальном времени с неблокирующим обратным давлением (back pressure). Допускает различные реализации, использующие разные языки программирования.
Reactive Streams позволяет обрабатывать потенциально неограниченное количество элементов в последовательности и асинхронно передавать элементы между компонентами с неблокирующим обратным давлением.
Список инициаторов создания Reactive Streams достаточно внушителен: здесь и Netflix, и Oracle, и Twitter.
Спецификация очень проста, чтобы сделать реализацию на разных языках и платформах как можно более доступной. Основные компоненты Reactive Streams API:
- Publisher
- Subscriber
- Subscription
- Processor
Существенно, что эта спецификация не предполагает, что вы вручную начнете реализовывать эти интерфейсы. Подразумевается, что есть какие-то разработчики библиотек, которые сделают это для вас. И Akka Streams — одна из реализаций этой спецификации.
public interface IPublisher
{
void Subscribe(ISubscriber subscriber);
}
public interface ISubscriber
{
void OnSubscribe(ISubscription subscription);
void OnNext(T element);
void OnError(Exception cause);
void OnComplete();
}
Интерфейсы, как видно на примере, действительно очень простые: например, Publisher содержит всего лишь один метод — «подписаться». Подписчик, Subscriber, содержит всего лишь несколько реакций на событие.
public interface ISubscription
{
void Request(long n);
void Cancel();
}
public interface IProcessor
: ISubscriber, IPublisher
{
}
Наконец, подписка содержит два метода — это «начать» и «отказаться». Процессор вообще не определяет никакие новые методы, он объединяет в себе публикатора и подписчика.
Что выделяет Reactive Streams среди прочих реализаций потоков? Reactive Streams комбинирует модели push и pull. Для поддержки это наиболее эффективный сценарий быстродействия. Положим, у вас медленный подписчик на данные. В этом случае push для него может оказаться фатальным: если ему слать огромное количество данных, он не сможет их обрабатывать. Лучше пользоваться pull, чтобы подписчик сам вытягивал данные из публикатора. Но если публикатор медленный, то получается, что подписчик все время блокирован, все время ждет. Промежуточным решением может стать конфигурация: у нас есть config-файл, в котором мы определяем, кто из них быстрее. А если их скорости изменятся?
Так вот, наиболее элегантной реализацией является та, при которой мы динамически можем менять push- и pull-модели.
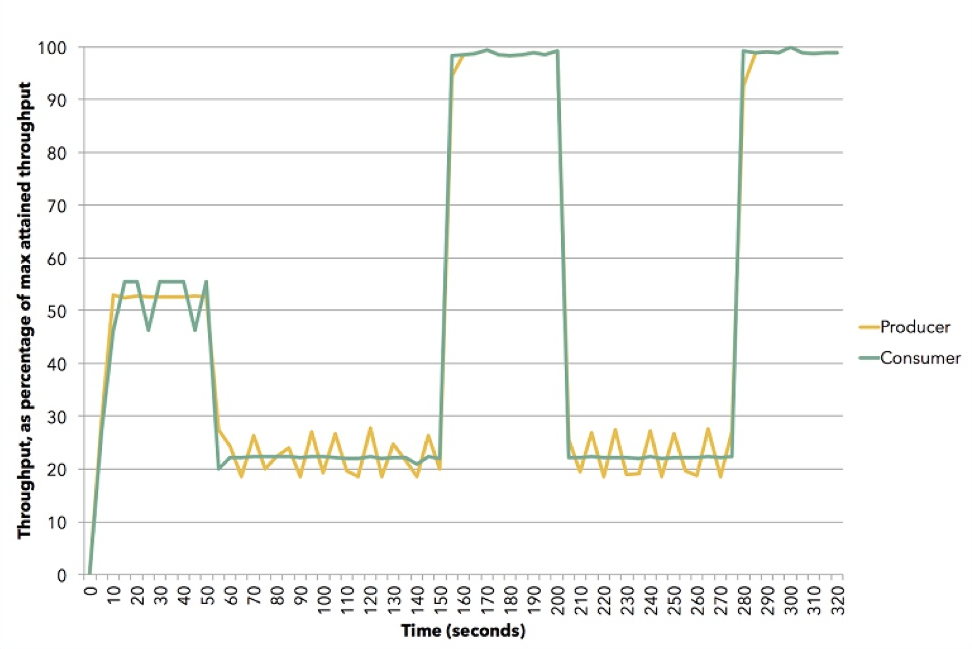
(Источник (Apache Flink))
На диаграмме показано, как это может произойти. Эта демонстрация использует Apache Flink. Желтый — это публикатор, продюсер данных, он был установлен примерно на 50% своей способности. Подписчик пытается выбрать наилучшую стратегию — это оказывается push. Потом мы сбрасываем подписчика на скорость порядка 20%, и он переходит на pull. Дальше мы выходим на 100%, снова возвращаем на 20%, к модели pull, и т. д. Все это происходит в динамике, не нужно останавливать сервис, вводить что-то в конфигурацию. Это иллюстрация того, как работает обратное давление в Akka Streams.
Конечно, Akka Streams не стала бы набирать популярность, если бы там не было встроенных блоков, которыми очень легко пользоваться. Их достаточно много. Они делятся на три основные группы:
- Источник данных (Source) — стадия обработки с одним выходом.
- Сток (Sink) — стадия обработки с одним входом.
- Пропускной пункт (Flow) — стадия обработки с одним входом и одним выходом. Здесь происходят функциональные трансформации, причем необязательно в памяти: это может быть, например, обращение к веб-сервису, к каким-то элементам параллелизма, многопоточное.
Из этих трех типов можно формировать графы (Graph). Это уже более сложные стадии обработки, которые построены из источников, стоков и пропускных пунктов. Но не каждый граф можно исполнить: если в нем есть дыры, т. е. открытые входы и выходы, то этот граф незапускаем.
Граф является запускаемым (Runnable Graph), если он закрыт, т. е. на каждый вход есть выход: если данные вошли, они обязательно куда-то вышли.

В Akka Streams есть встроенные источники: на картинке вы видите, как их много. Их названия примерно один в один отражают то, что есть в Scala или JVM, за исключением некоторых специфических для .NET полезных источников. Первые два (FromEnumerator и From) — одни из самых важных: любой нумератор, любой ienumerable можно превратить в источник потока.

Есть встроенные стоки: некоторые из них напоминают методы LINQ, например, First, Last, FirstOrDefault. Разумеется, все, что вы получаете, вы можете сбрасывать в файлы, в стримы, уже не в Akka Streams, а в .NET streams. И опять же, если у вас есть какие-то акторы в вашей системе, вы их можете использовать как на входе, так и на выходе системы, т. е. при желании встраиваете это в вашу готовую систему.

И есть огромное количество встроенных пропускных пунктов, которые, может быть, еще больше напоминают LINQ, потому что здесь есть и Select, и SelectMany, и GroupBy, т. е. все то, с чем мы привыкли работать в LINQ.
Например, Select в Scala называется SelectAsync: он достаточно мощный, потому что одним из аргументов берет уровень параллелизма. Т. е. вы можете указать, что, например, Select отправляет данные на какой-то веб-сервис параллельно в десяти потоках, потом они все собираются и передаются дальше. Фактически вы определяете степень масштабирования пропускного пункта одной строчкой кода.
Декларация потока является его исполнительным планом, т. е. граф, даже запускаемый, нельзя исполнить просто так — его нужно материализовать. Должна быть инстанциированная система, actor system, вы должны передать ей поток, этот план к исполнению, и тогда он будет исполнен. Более того, во время исполнения он сильно оптимизирован, примерно так же, как когда вы посылаете LINQ-выражение в базу данных: провайдер может оптимизировать ваш SQL для более эффективной выдачи данных, по сути заменив команду запроса на другую. То же самое с Akka Streams: начиная с версии 2.0 вы можете задать какое-то количество пропускных пунктов, а система поймет, что некоторые из их можно объединить, чтобы они исполнялись одним актором (operator fusion). Пропускные пункты, как правило, сохраняют очередность обработки элементов.
var results = db.Companies
.Join(db.People,
c => c.CompanyID,
p => p.PersonID,
(c, p) => new { c, p })
.Where(z => z.c.Created >= fromDate)
.OrderByDescending(z => z.c.Created)
.Select(z => z.p)
.ToList();
Материализацию потока можно сравнить с последним элементом ToList в LINQ-выражении в примере выше. Если мы не напишем ToList, то у нас получится нематериализованное LINQ-выражение, которое не приведет к тому, что данные будут переданы на SQL-сервер или Oracle, поскольку большинство LINQ-провайдеров поддерживают так называемое deferred query execution (отложенное исполнение запроса), т. е. запрос выполняется, лишь когда дана команда выдать какой-то результат. В зависимости от того, что запрошено — список или первый результат — будет сформирована наиболее эффективная команда. Когда мы говорим ToList, мы тем самым запрашиваем LINQ-провайдер выдать нам готовый результат.
var runnable =
Source
.From(Enumerable.Range(1, 1000))
.Via(Flow.Create().Select(x => x * 2)
.To(Sink.ForEach(x => Console.Write(x.ToString));
Схожим образом работает и Akka Streams. На картинке — наш запускаемый граф, который состоит из источника пропускных пунктов и стока, и нам хочется теперь его запустить.
var runnable =
Source
.From(Enumerable.Range(1, 1000))
.Via(Flow.Create().Select(x => x * 2)
.To(Sink.ForEach(x => Console.Write(x.ToString));
var system = ActorSystem.Create("MyActorSystem");
using (var materializer = ActorMaterializer.Create(system))
{
await runnable.Run(materializer);
}
Для того чтобы это произошло, нам нужно создать систему акторов, в ней — материализатор, передать ему наш граф, и он его выполнит. Если мы заново создадим его, он выполнит его снова, при этом могут получиться другие результаты.
Помимо материализации потока, говоря о материальной части Akka Streams, стоит еще упомянуть материализованные значения.
var output = new List();
var source1 = Source.From(Enumerable.Range(1, 1000));
var sink1 = Sink.ForEach(output.Add);
IRunnableGraph runnable1 = source1.To(sink1);
var source2 = Source.From(Enumerable.Range(1, 1000));
var sink2 = Sink.Sum((x,y) => x + y);
IRunnableGraph> runnable2 =
source2.ToMaterialized(sink2, Keep.Right);
Когда у нас есть поток, который идет от источника через пропускные пункты до стока, то если мы не запрашиваем какие-то промежуточные значения, они нам недоступны, поскольку он будет исполняться наиболее эффективным образом. Это как черная коробка. Но нам может быть интересно вытащить какие-то промежуточные значения, потому что на каждой точке слева поступают какие-то значения, справа выходят другие значения, и можно, задавая граф, указать, в чем вы заинтересованы. На примере выше — запускаемый граф, в котором указан NotUsed, т. е. никакие материализованные значения нас не интересуют. Ниже мы создаем его с указанием, что в правой части стока, т. е. после выполнения всех трансформаций, нам нужно выдать материализованные значения. Мы получаем граф Task — задачу, при выполнении которой мы получим int, т. е. то, что получится на конце этого графа. Можно в каждом пункте указывать, что вам нужны какие-то материализованные значения, все это постепенно будет собираться.
Чтобы передавать данные внутрь потоков Akka Streams или вытаскивать их оттуда, нужны, конечно же, какие-то взаимодействия с внешним миром. Встроенные стадии источников содержат широкий спектр реактивных потоков данных:
- Source.FromEnumerator и Source.From позволяют передавать данные из любого источника, реализующегоIEnumerable;
- Unfold и UnfoldAsync формируют результаты вычислений функции при условии возврата ею ненулевых значений;
- FromInputStream преобразовывает Stream;
- FromFile обращает в реактивный поток содержимое файла;
- ActorPublisher преобразовывает сообщения актора.
Как я уже говорил, для .NET-разработчиков весьма продуктивным является использование Enumerator или IEnumerable, но иногда это слишком примитивно, слишком неэффективный способ обращения к данным. Более сложные и содержащие большое количество данных источники требуют специальных коннекторов. Такие коннекторы пишутся. Есть опенсорсный проект Alpakka, который изначально появился в Scala и сейчас есть в .NET. Помимо этого, в Akka есть так называемые персистентные акторы, а у них есть свои собственные потоки, которыми можно пользоваться (например, Akka Persistence Query формирует поток содержимого Akka Event Journal).

Если вы работаете со Scala, то вам проще всего: там огромное количество коннекторов, и вы наверняка найдете что-то на свой вкус. Для сведения, Kafka — это так называемый Reactive Kafka, а не Kafka Streams. Kafka Streams, насколько я знаю, не поддерживает back pressure. Reactive Kafka — это реализация потока из Kafka, которая поддерживает Reactive Streams.
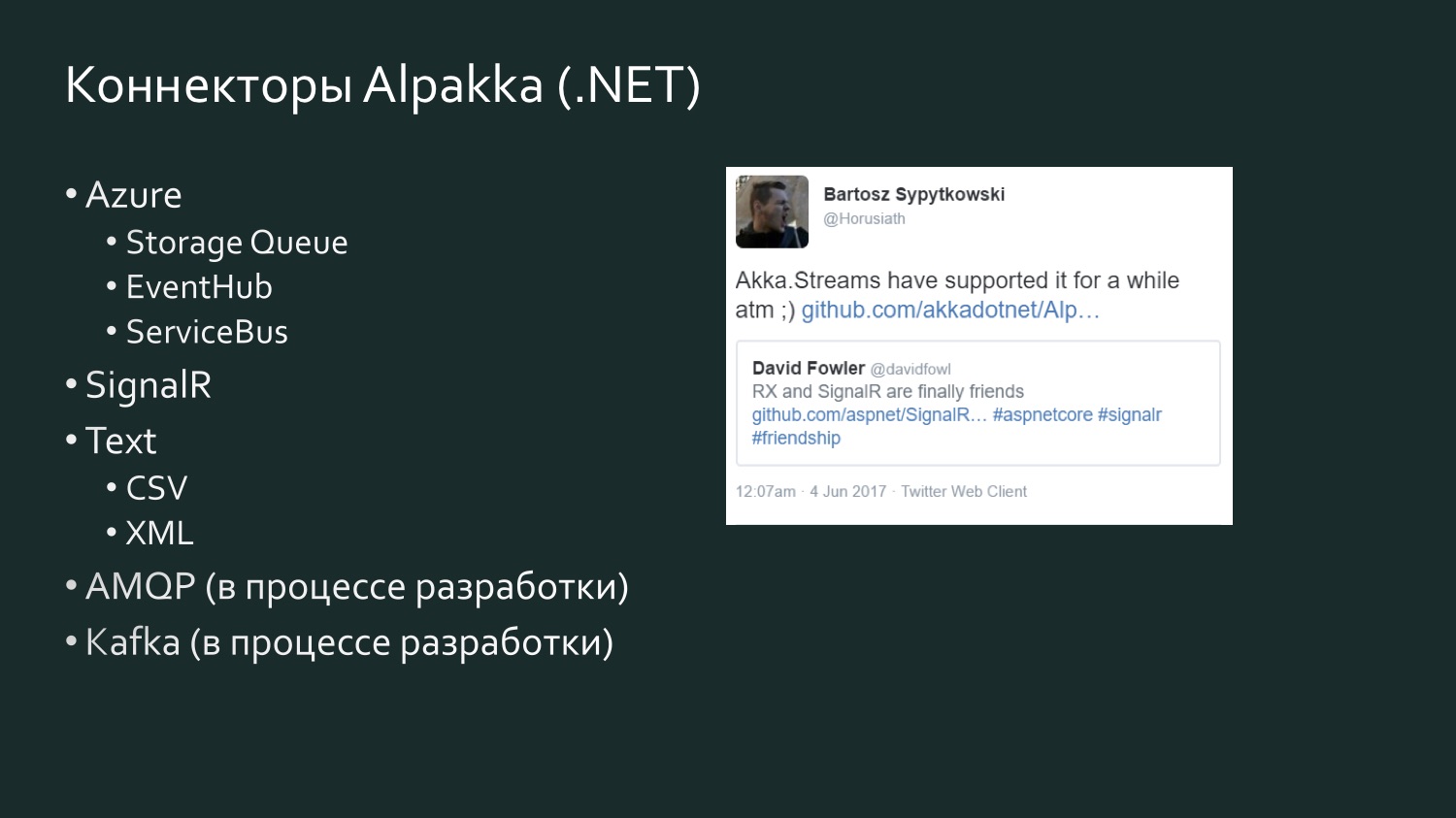
Список коннекторов Alpakka .NET более скромный, но он пополняется, и там есть элемент конкуренции. Есть твит полугодовой давности David Fowler из Microsoft, который сообщил, что SignalR теперь может обмениваться данными с Reactive Extensions, и один из разработчиков Akka ответил, что на самом деле в Akka Streams это уже какое-то время было. Akka поддерживает различные сервисы из Microsoft Azure. CSV является результатом расстройства Aaron Stannard, когда он обнаружил, что нет хорошего потока для CSV: теперь у Akka есть свой поток для CSV XML. Есть AMQP (в реальности RabbitMQ), он в процессе разработки, но доступен для использования, он работает. Kafka тоже находится в процессе разработки. Этот список будет и дальше расширяться.
Пара слов об альтернативах, поскольку если вы работаете с потоками данных, Akka Streams — это, разумеется, далеко не единственный способ эти потоки обработать. Скорее всего в вашем проекте выбор того, как реализовать потоки, будет зависеть от многих других факторов, которые могут стать ключевыми. Например, если вы много работаете с Microsoft Azure и в потребности вашего проекта органично встраивается Orleans с их поддержкой виртуальных акторов, или, как они их называют, grains, то у них есть своя собственная реализация, не соответствующая спецификации Reactive Streams — Orleans Streams, которая для вас будет ближе всего, и вам имеет смысл обратить внимание на нее. Если вы много работаете с TPL, есть TPL DataFlow — это, может быть, наиболее близкая аналогия Akka Streams: там тоже есть примитивы для компоновки потоков данных, а также средства буферизации и средства ограничения пропускной способности (BoundedCapacity, MaxMessagePerTask). Если же вам близки идеи модели акторов, то Akka Streams — это способ обратиться к этому и сэкономить значительное количество времени без необходимости писать каждый актор вручную.
Давайте посмотрим на пару примеров реализации. Первый пример — это не реализация непосредственно потока, это как использовать поток. Это был наш первый опыт работы с Akka Streams, когда мы обнаружили, что на самом деле можем подписаться на какой-то поток, который многое для нас упростит.
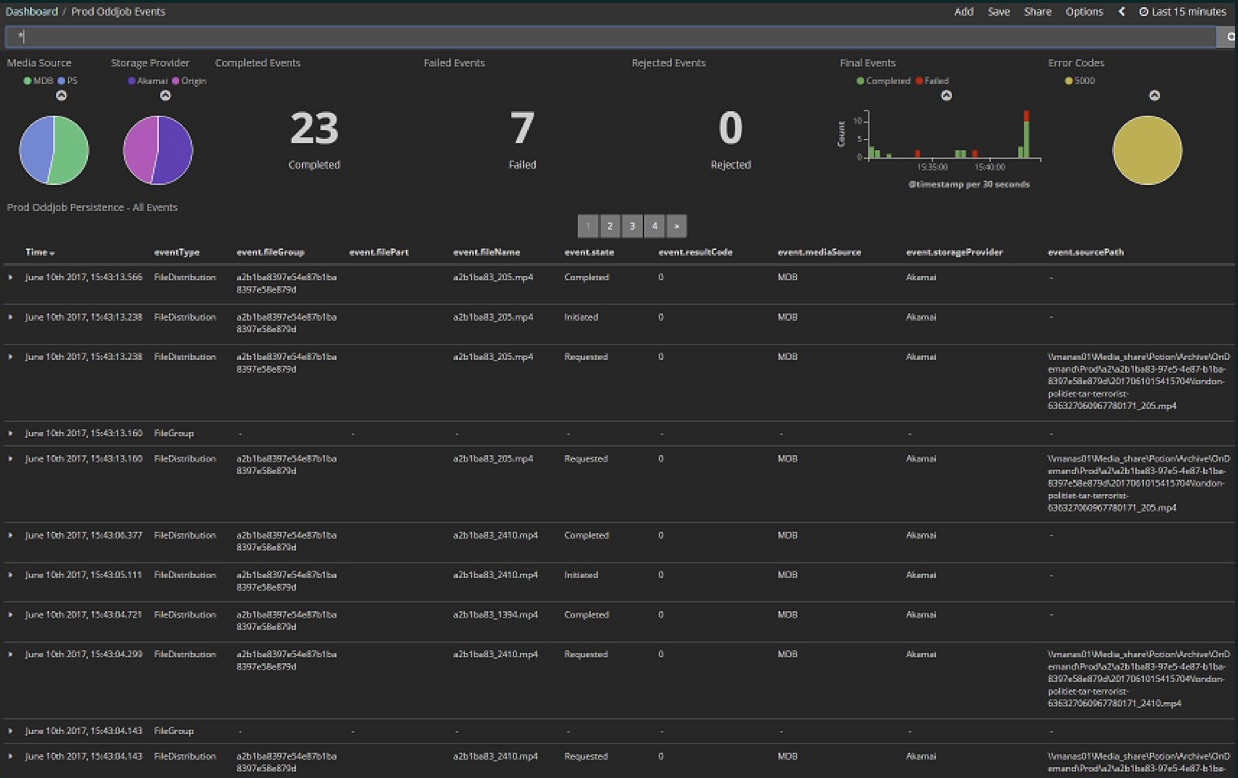
Мы загружаем в облако разные медиафайлы. Это была ранняя стадия проекта: здесь за последние 15 минут 23 файла, из них 7 ошибок. Сейчас ошибок уже практически нет и число файлов гораздо больше — сотнями проходят за каждые несколько минут. Все это содержится в Kibana Dashboard.
Kibana читает данные из Elasticsearch и, поскольку в Elasticsearch хранятся вторичные, а не первичные данные, то для реализации этого индексера требовалось, чтобы его можно было удалить и дать команду, чтоб он снова заполнился. Поскольку проект в стадии разработки, это позволяет нам менять форматы данных, расширять их новыми значениями, т. е. индекс нужно постоянно обновлять. Он пополняется содержимым журнала событий (event journal) Akka, который хранится в базе данных Microsoft SQL Server. И ранее сохраненные события, и события реального времени должны отображаться на панели текущих операций.
CREATE TABLE EventJournal (
Ordering BIGINT IDENTITY(1,1) PRIMARY KEY NOT NULL,
PersistenceID NVARCHAR(255) NOT NULL,
SequenceNr BIGINT NOT NULL,
Timestamp BIGINT NOT NULL,
IsDeleted BIT NOT NULL,
Manifest NVARCHAR(500) NOT NULL,
Payload VARBINARY(MAX) NOT NULL,
Tags NVARCHAR(100) NULL
CONSTRAINT QU_EventJournal UNIQUE (PersistenceID, SequenceNr)
)
Чтобы этого достичь, нам нужно, с одной стороны, переписать данные, взятые из SQL Server, в котором содержатся некий eventstore персистентных акторов Akka, eventJournal. На картинке показан типичный eventstore.
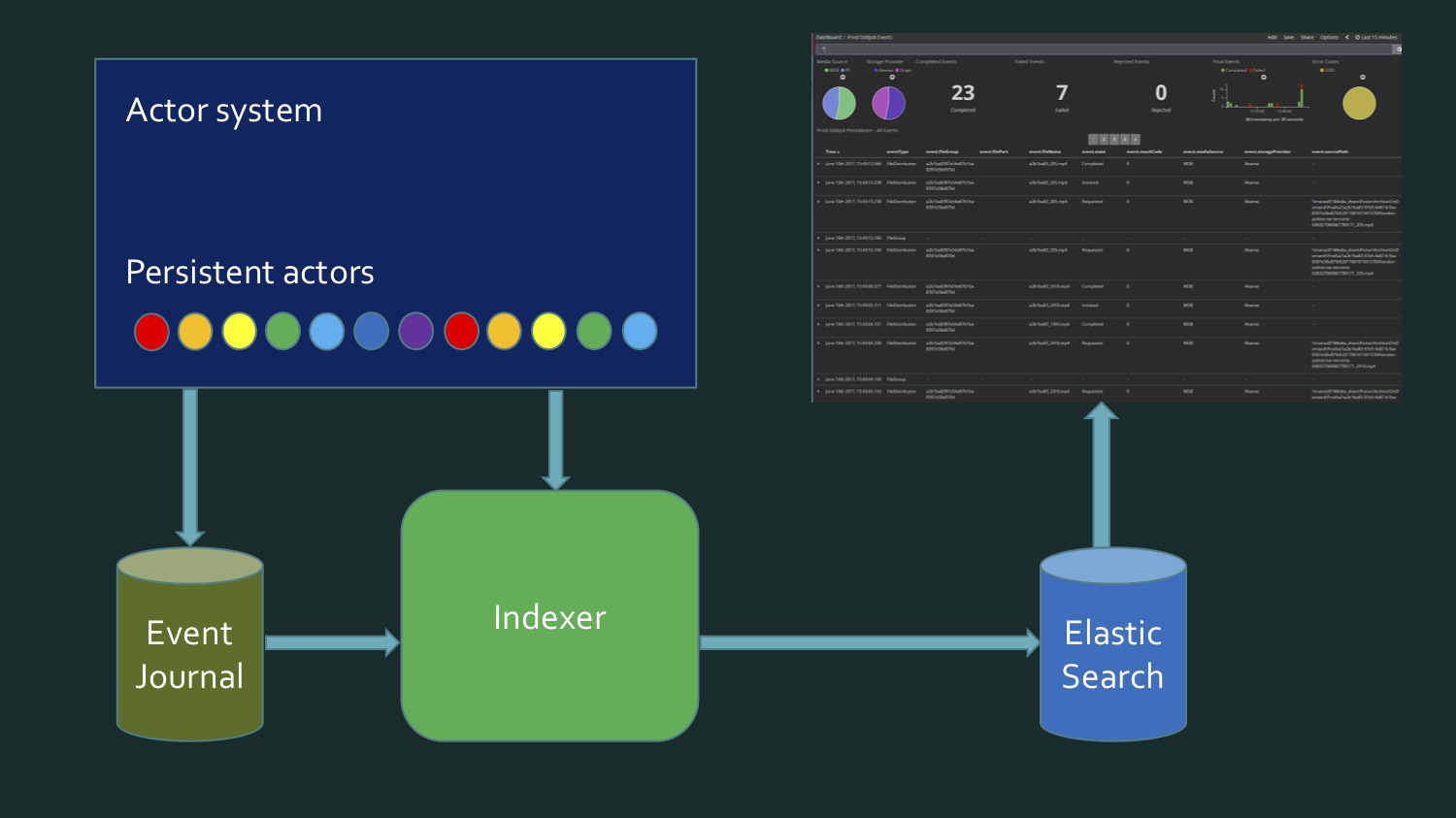
А с другой стороны, данные поступают в реальном времени. И получается, что чтобы написать индекс, нам нужно считывать данные из базы данных, плюс поступают данные в реальном времени, и в какой-то момент нам нужно понять: вот здесь кончились данные отсюда, это новые. Этот пограничный момент требует дополнительной проверки, чтобы ничего не потерять и ничего не записать дважды. Т. е. получалось как-то довольно сложно. Мы с коллегой не были довольны тем, что у нас выходит. Это не то что очень сложный код, просто довольно муторный. Пока мы не вспомнили, что персистентные акторы в Akka поддерживают persistence query.
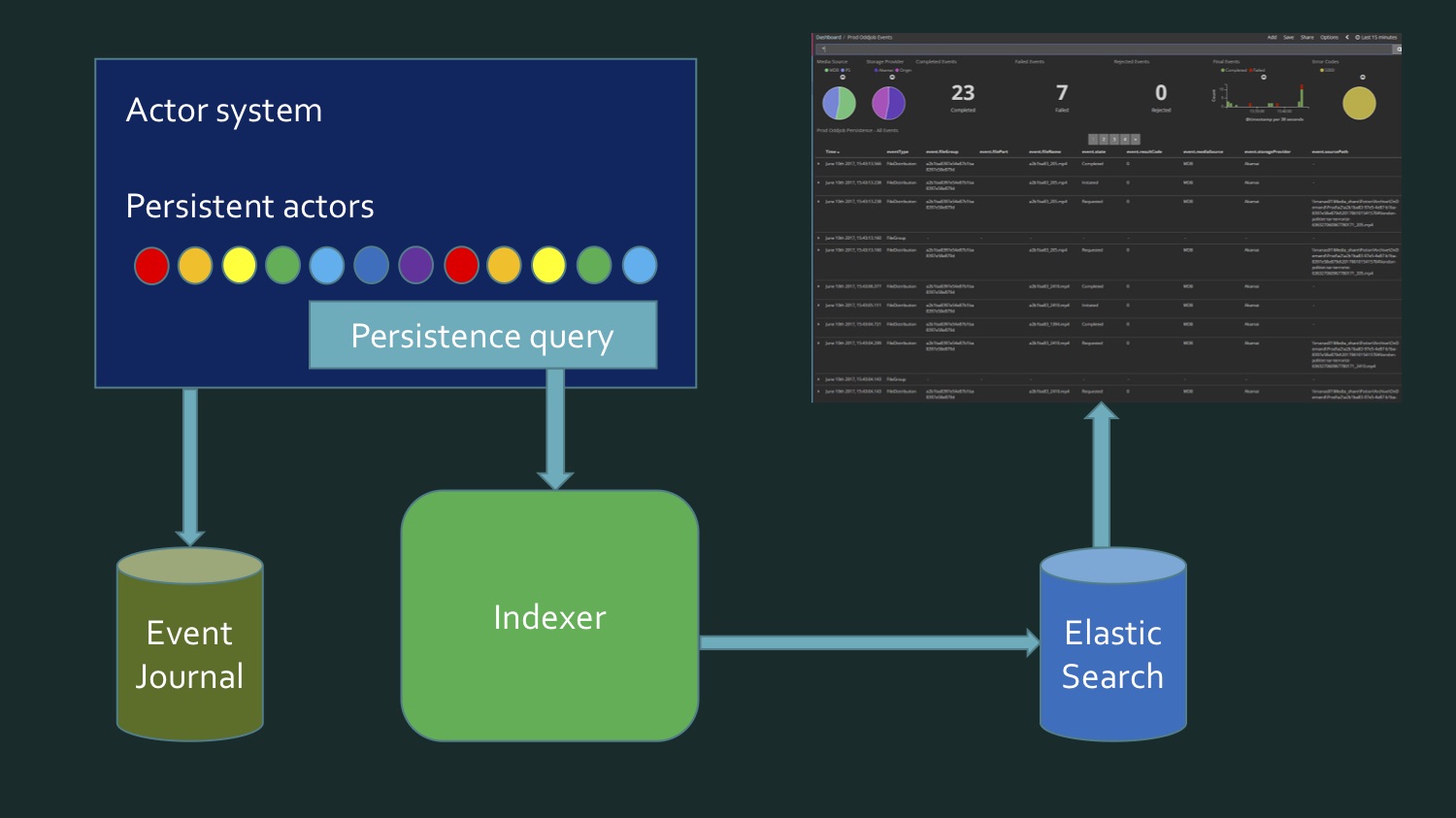
Это как раз возможность получить их в виде потока данных, абстрагированного над источником, идут они из базы данных или получаются в реальном времени.
Встроенные запросы (persistence queries):
- AllPersistencelds
- CurrentPersistencelds
- EventsByPersistenceld
- CurrentEventsByPersistenceld
- EventsByTag
- CurrentEventsByTag
И там есть целый ряд методов, которые мы можем использовать, например, есть метод Current — это снапшот, данные исторически до данного момента времени. А без этого префикса — сначала и включая реальные. Нам понадобился EventsByTag.
let system = mailbox.Context.System
let queries = PersistenceQuery.Get(system)
.ReadJournalFor(SqlReadJournal.Identifier)
let mat = ActorMaterializer.Create(system)
let offset = getCurrentOffset client config
let ks = KillSwitches.Shared "persistence-elastic"
let task =
queries.EventsByTag(PersistenceUtils.anyEventTag, offset)
.Select(fun e -> ElasticTypes.EventEnvelope.FromAkka e)
.GroupedWithin(config.BatchSize, config.BatchTimeout)
.Via(ks.Flow())
.RunForeach((fun batch -> processItems client batch), mat)
.ContinueWith(handleStreamError mailbox,
TaskContinuationOptions.OnlyOnFaulted)
|> Async.AwaitTaskVoid
И оказалось, что нам хватило кода. Он был написан на F#, но на C# он был примерно таким же компактным. Мы получаем EventsByTag, применяем встроенные блоки Akka Streams, и из всего этого получаются данные, которые мы шлем в Elasticsearch. Т. е. мы воспользовались чьей-то реализацией потока данных, и это позволило нам забыть о том, где наши данные, откуда они берутся — из базы данных или же это происходит в реальном времени. Эта реализация дала нам все это одним запросом.
Но здесь мы выступали потребителями этих данных. В том случае, когда мы хотим сами производить такие данные, пример становится более интересным, и мы его рассмотрим на реальных данных, поскольку Twitter был одним из инициаторов этой спецификации, и твиты — это то, что доступно всем, то, что понимаем мы все. Это стандартный пример демонстрации того, как работает Akka Streams.
Есть пример для Akka для Scala, для Akka.NET, но я счел эти примеры недостаточными, поскольку они показывают один конкретный пример, как данные вытаскиваются и что с ними делается, а хотелось посмотреть на постепенное усложнение, т. е. начать с простого потока и дальше добавить к нему какие-то новые конструкции. Для этого воспользуемся библиотекой Tweetinvi — это опенсорсная библиотека, которая выдает данные из Twitter, она как раз поддерживает выдачу данных в виде потока. Этот поток не удовлетворяет спецификации Reactive Streams, т. е. мы не можем сразу его взять, но это даже хорошо, поскольку это позволит нам показать, как можно, используя в общем-то примитивные Akka, написать на базе этого свой поток, который бы удовлетворял этой спецификации.

Сейчас у нас будет некий источник твитов, который мы распараллелим на два канала, т. е. это Broadcast-примитив. В первом канале мы просто будем форматировать твиты, будем выбирать имя автора твита, и потом смешаем с данными второго канала. А во втором канале мы сделаем нечто более сложное: ограничим пропускную способность этого потока, потом расширим данные твитов данными погоды в тех местах, где эти твиты писались, отформатируем все это температурой, смешаем с первым каналом и все это распечатаем на экране.
Всё это находится в моем GitHub-аккаунте, в AkkaStreamsDemo. Открывайте и смотрите (или можете начать смотреть запись доклада вот с этого момента).
Начнем с простого. Вначале я хочу напрямую считывать данные из Twitter: в файле Program.cs
var useCachedTweets = false
На случай, если меня забанят в Twitter, у меня есть кэшированные твиты, они быстрее. Для начала мы создаем некий RunnableGraph.
public static IRunnableGraph CreateRunnableGraph()
{
var tweetSource = Source.ActorRef(100, OverflowStrategy.DropHead);
var formatFlow = Flow.Create().Select(Utils.FormatTweet);
var writeSink = Sink.ForEach(Console.WriteLine);
return tweetSource.Via(formatFlow).To(writeSink);
}
(Источник)
У нас здесь есть источник твитов, который получается из некоего актора. Я сейчас покажу, как мы туда затаскиваем эти твиты, форматируем (формат твита просто выдает автора твита) и потом пишем это на экран.
StartTweetStream — здесь мы будем пользоваться библиотекой Tweetinvi.
public static void StartTweetStream(IActorRef actor)
{
var stream = Stream.CreateSampleStream();
stream.TweetReceived += (_, arg) =>
{
arg.Tweet.Text = arg.Tweet.Text.Replace("\r", " ").Replace("\n", " ");
var json = JsonConvert.SerializeObject(arg.Tweet);
File.AppendAllText("tweets.txt", $"{json}\r\n");
actor.Tell(arg.Tweet);
};
stream.StartStream();
}
(Источник)
Через CreateSampleStream мы получаем самплы твитов, они выдаются с не очень большой скоростью. Из всего этого мы выбираем то, что нам нужно, и создаем некий актор, которому говорим: «Прими этот твит». Дальше нам нужно получить IEnumerable, чтобы в итоге у нас получился источник.
А TweetEnumerator выглядит очень просто: у нас есть коллекция твитов, и нам нужно реализовать Current, MoveNext, Reset, ну и Dispose, чтобы быть хорошими гражданами. Если мы запустим это, то увидим пример в реальном времени. Здесь многое непечатаемое, поскольку это из разных нелатинских стран. Это самый простой вариант нашей прог
