AggreGate Network Manager: платформа+коробка для зонтичного мониторинга IT-инфраструктуры
 Диагностика проблем надежности и производительности в сложных ИТ-инфраструктурах требует понимания целостной картины всех процессов и событий, а также возможности отслеживать важнейшие тренды. Необходимость внедрения единой («зонтичной») системы управления ИТ-инфраструктурой обоснована классическими для бизнеса причинами:
Диагностика проблем надежности и производительности в сложных ИТ-инфраструктурах требует понимания целостной картины всех процессов и событий, а также возможности отслеживать важнейшие тренды. Необходимость внедрения единой («зонтичной») системы управления ИТ-инфраструктурой обоснована классическими для бизнеса причинами:
Максимизация возврата инвестиций в бизнес-приложения и сервисы. Система управления позволяет оценивать и оптимизировать ресурсы, необходимые для работы ИТ сервисов компании. Это обеспечивает минимальные операционные расходы и ускорение окупаемости новых ИТ-сервисов. Повышение качества ИТ-сервисов. Поддержание и улучшение качества ИТ-услуг требует детального понимания их текущего состояния. Часто деградация производительности остается подолгу незамеченной собственными службами компании, нанося урон репутации и доверию клиентов. Автоматизированный мониторинг предоставляет необходимую отчетность по соответствию услуг определенным для них соглашениям об уровне обслуживания (SLA), сводя риски незамеченной деградации к минимуму. Уменьшение времени простоя сервисов и компонентов ИТ-инфраструктуры. Проактивный мониторинг позволяет предотвращать многие отказы оборудования и приложений, а также минимизировать продолжительность и степень деградации сервисов. В случаях, когда отказы все-таки случаются, система непрерывного мониторинга позволяет быстрее локализовать и исправить проблемные компоненты. Финансовые потери, вызванные несколькими часами недоступности бизнес-сервисов, не всегда бывают адекватно оценены и часто сопоставимы с расходами на внедрение системы управления ИТ. Повышение эффективности сотрудников департамента эксплуатации ИТ-инфраструктуры. Избавляя администраторов ИТ-систем от рутинных повседневных обязанностей, таких как анализ текущей ситуации и управление конфигурациями, а также от срочных задач по устранению инцидентов, система управления позволяет сотрудникам использовать освободившееся время для разовых задач по дальнейшей автоматизации процессов, что в конечном итоге приводит к повышению эффективности бизнеса в целом. Написанное выше понимают (интуитивно или осознанно) практически все ИТ-директора, руководители департаментов эксплуатации ИТ-инфраструктуры и системные администраторы. Тем не менее, степень «зрелости» ИТ-инфраструктуры очень сильно отличается от страны к стране, от отрасли к отрасли, от компании к компании. А подход к автоматизации управления и мониторинга ИТ очень сильно зависит от степени развития самой ИТ-инфраструктуры в целом.
Мы условно выделяем несколько уровней развития подхода к управлению ИТ-инфраструктурой:
Жизнь без мониторинга. Все компоненты инфраструктуры и сервисы работают сами по себе, без оперативного контроля. Устранение инцидентов производится путем подключения к индивидуальным компонентам инфраструктуры и сервисов, построение картины произошедшего происходит «в голове» админов, разбор полетов — обычно по логам. Реактивный мониторинг. Конечно же, от слова «реакция», а не «реактивность». На этом этапе внедряется классическая система мониторинга начального класса. Это может быть либо простейшая «пинговалка», либо система, занимающаяся периодическим опросом компонентов инфраструктуры по стандартным протоколам (SNMP, WMI, и т.д.) или при помощи агентов. Собранные данные сохраняются и визуализируются при помощи инструментальных панелей (дэшбордов). Также производится простейшая консолидация событий (SNMP traps, Syslog) и рассылка оповещений по критическим событиям и нарушению порогов. Проактивный мониторинг. Отличается от реактивного возможностью предсказывать инциденты и избегать их в случаях, когда развитие инцидента происходит не быстро и система мониторинга имеет возможность предупредить операторов о негативном тренде. Системы с возможностью проактивного мониторинга обычно также предоставляют дополнительные возможности, такие как, например, динамические пороги тревог, анализ трафика, мониторинг VoIP путем вызовов по SIP и сбора данных IP SLA, и т.п. Комплексное управление ИТ. Пока на этом этапе в России находится небольшое количество крупных компаний. В рамках комплексного, или, иначе говоря, «зонтичного» управления ИТ одна система объединяет все функции по мониторингу инфраструктуры и сервисов с функциями по автоматизированному управлению конфигурациями, обеспечивая при этом единую точку интеграции с корпоративной системой класса ITSM/Service Desk. Системы такого класса реализуют сценарии сложной корреляции цепочек событий и их обогащения данными из системы инвентаризации активов. Как результат, появляется возможность обучать систему методикам поиска первопричины отказа (root cause analysis). Набор готовых алгоритмов поиска первопричины обычно является частью коробочного продукта. Количество систем мониторинга ИТ и сетей на мировом рынке достаточно велико. Тем не менее, большую часть составляют узкоспециализированные продукты, например решения по мониторингу и декомпозиции трафика или решения по мониторингу Java-приложений.
Если же говорить об универсальных комплексных системах, круг резко сужается. Все более-менее известные решения, как бесплатные так и коммерческие, упоминаются в статье «Сравнение систем мониторинга сети» на Википедии (русская версия, английская версия).
Все универсальные решения по мониторингу ИТ можно также условно поделить на несколько категорий, имеющих свои плюсы и минусы:
Бесплатные системы с открытым исходным кодом. К этому классу относятся, например, Nagios, Cacti, Zenoss, Zabbix, Pandora FMS и OpenNMS. Бесплатность самой системы не всегда меньшую совокупную стоимость владения — настройка через конфигурационные файлы и необходимость написания скриптов для многих сценариев мониторинга в конечном итоге обходится недешево. Затраты на оплату рабочего времени администраторов являются косвенными и распределяются на большом промежутке времени, поэтому часто остаются для компании незаметными. В то же время, системы этого класса имеют некоторое преимущество в гибкости над недорогими коммерческими системами, поскольку открытый исходный код позволяет опытным сетевым инженерам решить большинство задач классического мониторинга дописывая систему и не заключая при этом контракта на платную техническую поддержку. Коммерческие продукты с фиксированным функционалом. К этому сегменту относится большинство коммерческих решений для мониторинга сетей, включая WhatsUp Gold, OpManager, Solarwinds, PRTG, AccelOps, AdRem NetCrunch, op5 Monitor и SevOne. Такие коммерческие системы обычно очень быстро развертываются и хорошо решают типовые задачи «из коробки». Большинство продуктов обладает неплохой юзабилити, опять же в рамках реализации стандартных сценариев мониторинга. Главный недостаток всех подобных систем — низкая гибкость и слабая способность к адаптации под нестандартные задачи. Зачастую даже если куплена максимально полная версия продукта ответом на вопрос «как настроить мониторинг X по Y и чтобы видеть Z?» может быть твердое «никак» с перспективой долгого общения с вендором в надежде реализации нужной фичи в будущих версиях продукта. Коммерческие линейки продуктов платформенного типа. Игроками в этом сегменте являются крупнейшие западные компании — IBM, CA, HP, EMC. В данном случае под решением понимается не один конкретный продукт, а набор продуктов, покрывающих различные группы задач мониторинга и управления. К сожалению, продукты эти часто были разработаны сторонними компаниями, поглощенными впоследствии, поэтому интегрированные на уровне единой консоли управления продукты внутри устроены, настраиваются и работают совершенно по-разному. Стоимость внедрения такого набора продуктов достаточно высока. Тем не менее, системы этого типа покрывают максимальное количество задач мониторинга «из коробки» и позволяют решать широкий спектр нестандартных задач. В целом рынок систем управления ИТ является одним из наиболее высоко-конкурентных среди всех рынков ПО. Так зачем же мы решили инвестировать в разработку AggreGate Network Manager — еще одной системы этого класса?
Ответ на этот вопрос не совсем тривиален. У нас есть платформа AggreGate — наш конструктор для создания систем мониторинга и управления. Многие наши решения для вертикальных рынков, такие как AggreGate SCADA/HMI и AggreGate Fleet Manager, построены путем доработки нескольких новых драйверов для сбора данных и упаковки нового решения в красивый маркетинговый фантик. В отличие от SCADA, система мониторинга сетей требует как множества новых механизмов сбора данных (WMI, IMPI, SSH, JMX, SIP, NetFlow, Syslog и т.д.), так и огромного количества преднастроенных шаблонов опроса, тревог и инструментальных панелей. Соответственно, инвестиции изначально обещали быть немалыми.
 Мы построили этот продукт, потому что мы видим возможность изменить мир систем мониторинга и управления ИТ. Гибкость базовой платформы позволяет моделировать поведение и визуально разрабатывать интерфейс системы мониторинга под свою ИТ-инфраструктуру. Эти возможности выходят далеко за рамки добавления новых графиков на инструментальные панели и настройки порога срабатывания тревоги — речь и о моделировании бизнес-процессов и автоматизированном вычислении их KPI, и о создании динамических планов корпоративных ЦОДов, и о визуальном проектировании «с нуля» собственного операторского интерфейса первой линии для видео-стены в ЦУС«е, и о многом другом.
Мы построили этот продукт, потому что мы видим возможность изменить мир систем мониторинга и управления ИТ. Гибкость базовой платформы позволяет моделировать поведение и визуально разрабатывать интерфейс системы мониторинга под свою ИТ-инфраструктуру. Эти возможности выходят далеко за рамки добавления новых графиков на инструментальные панели и настройки порога срабатывания тревоги — речь и о моделировании бизнес-процессов и автоматизированном вычислении их KPI, и о создании динамических планов корпоративных ЦОДов, и о визуальном проектировании «с нуля» собственного операторского интерфейса первой линии для видео-стены в ЦУС«е, и о многом другом.
Специалисты, работающие в области автоматизации производственных процессов, привыкли, что каждое производство априори считается уникальным и инжиниринговая компания начинает внедрение АСУ ТП с проектирования и разработки специфичных алгоритмов управления и мнемосхем.
Все крупные инфраструктуры являются не менее уникальными, чем производственные процессы. Так почему же все ИТ-инфраструктуры управляются «под одну гребенку», а большинство систем управления предоставляют весьма ограниченные возможности по их кастомизации? Система AggreGate Network Manager, основанная на платформе AggreGate, дает ИТ-специалистам возможности по построению уникального процесса управления инфраструктурой, сравнимые с возможностями инженера по автоматизации, использующего хорошую АСУ ТП.
При этом мы прекрасно понимаем, что широкий рынок воспринимает продукт только если он хорошо работает «из коробки». Система должна разворачиваться в течение 10 минут, еще столько же уходит на сканирование сети, после этого сразу же должны быть доступны стандартные инструментальные панели.
Как и большинство универсальных систем на этом рынке, Network Manager покрывает управление двумя основными видами ИТ-инфраструктур:
1. Инфраструктуры телекоммуникационных компаний. Процессы управления включают обнаружение и визуализацию сетевой топологии (L2/L3, MPLS, SDH), мониторинг трафика и состояния интерфейсов, мониторинг каналов связи через WAN, управление конфигурациями оборудования, и т.д. 2. Инфраструктуры малых/средних компаний и корпораций. В данном случае наиболее актуален мониторинг серверов, операционных систем и приложений. Также важно наблюдение за СУБД, виртуализованной средой и бизнес-сервисами. Наличие в составе продуктов на основе платформы AggreGate системы SCADA позволила нам объединить возможности продуктов Network Manager и SCADA/HMI, которые технически являются наборами модулей, подсоединяемых к ядру платформы. Комбинированный продукт, названный AggreGate Data Center Supervisor, покрывает мониторинг третьего и последнего вида современных типовых ИТ-инфраструктур:
3. Инфраструктуры ЦОДов. Управление ЦОД предполагает комплексный мониторинг ИТ, инженерной инфраструктуры и инфраструктуры системы физической безопасности. Необходимо обеспечивать глубокий мониторинг микроклимата, контроль систем отопления, кондиционирования и вентиляции, мониторинг ИБП и ДГУ, тесную интеграцию со СКУД и системой видеонаблюдения/видеоаналитики, а также инвентаризацию ИТ-активов.
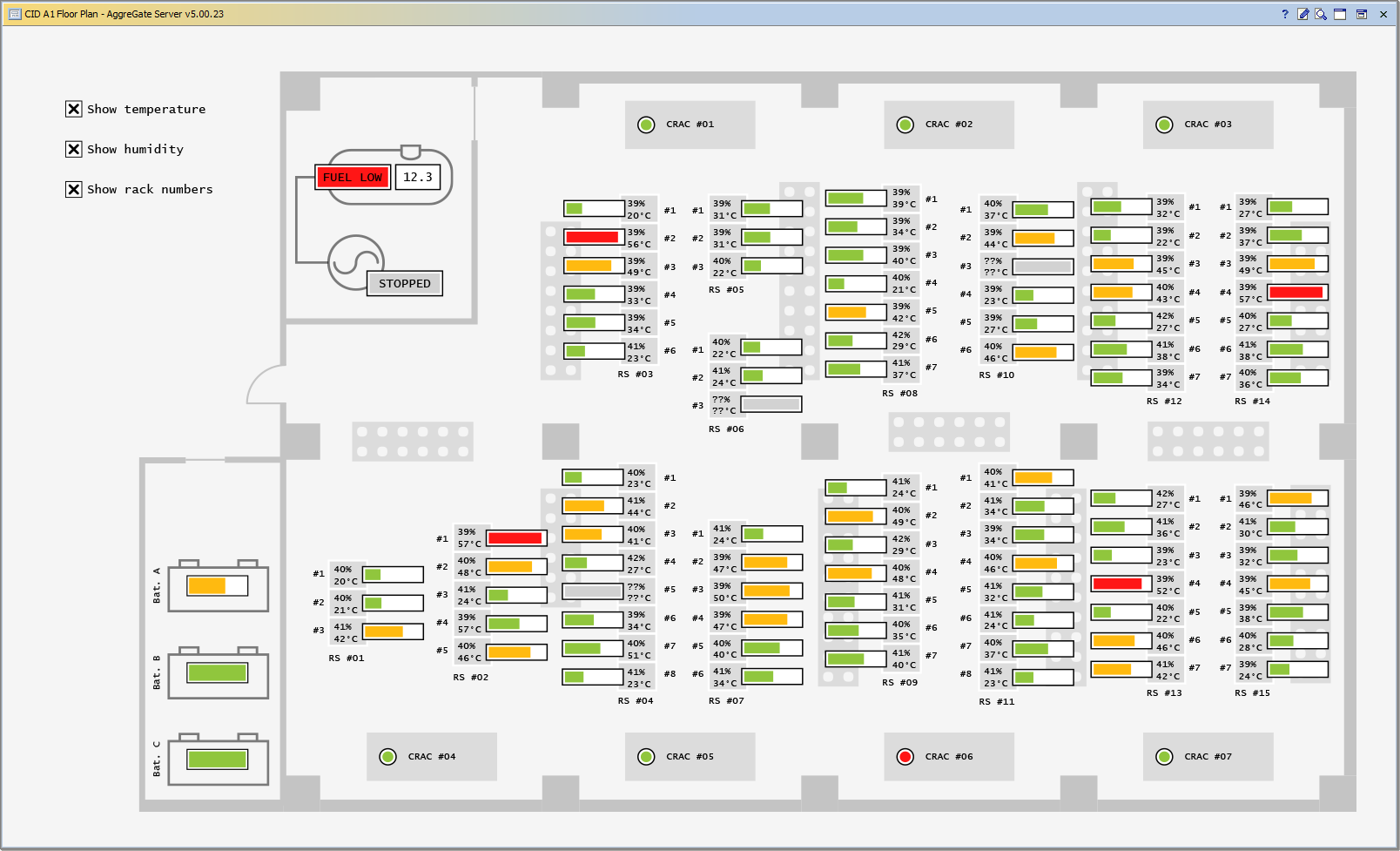 С точки зрения стандартного функционала систем мониторинга, AggreGate Network Manager предоставляет в рамках единого продукта все классические функции:
С точки зрения стандартного функционала систем мониторинга, AggreGate Network Manager предоставляет в рамках единого продукта все классические функции:
Обнаружение сетевых устройств и сервисов, в том числе по расписанию Сбор данных и событий по десяткам протоколов (SNMP, WMI, DHCP, DNS, FTP, SSH, Telnet, ICMP, IMAP, JMS, JMX, LDAP, NetFlow/xFlow, SQL/JDBC/ODBC, POP3, Radius, SIP, SMB/CIFS, SMTP, SOAP, Syslog, CORBA и другим) Построение топологических, географических и статических карт сети Доступность сотен «коробочных» инструментальных панелей, отчетов и тревог для анализа производительности сети и приложений, поиска и локализации сбоев Мониторинг виртуальной инфраструктуры, VoIP и беспроводных сетей Декомпозиция трафика на основе NetFlow/xFlow Многопользовательский ролевой доступ к серверу, возможность аутентификации через LDAP Распределенный мониторинг с возможностью хранения исторических данных на удаленных вторичных серверах мониторинга Инвентаризация сетевых активов — ПО, компонентов ПК, периферии, модулей коммутаторов и маршрутизаторов, и т.п. Консолидация, фильтрация, дедупликация, корреляция, и другая обработка сетевых сообщений Создание тревог с функциями гистерезиса, динамических порогов, обнаружения биения, эскалации, ручного закрытия, отправки оповещений по e-mail и СМС, а также выполнения автоматических и интерактивных корректирующих действий Создание по тревогам тикетов в системе ITSM/Service Desk Архивация и восстановление конфигураций оборудования, проверка их соответствия корпоративным политикам Впрочем, вышеприведенный список покрывается всеми серьезными решениями для управления ИТ. Вопрос лишь в качестве его реализации, возможностями по настройке и адаптации, удобстве использования продукта, стоимости владения, доступности и качестве технической поддержки.
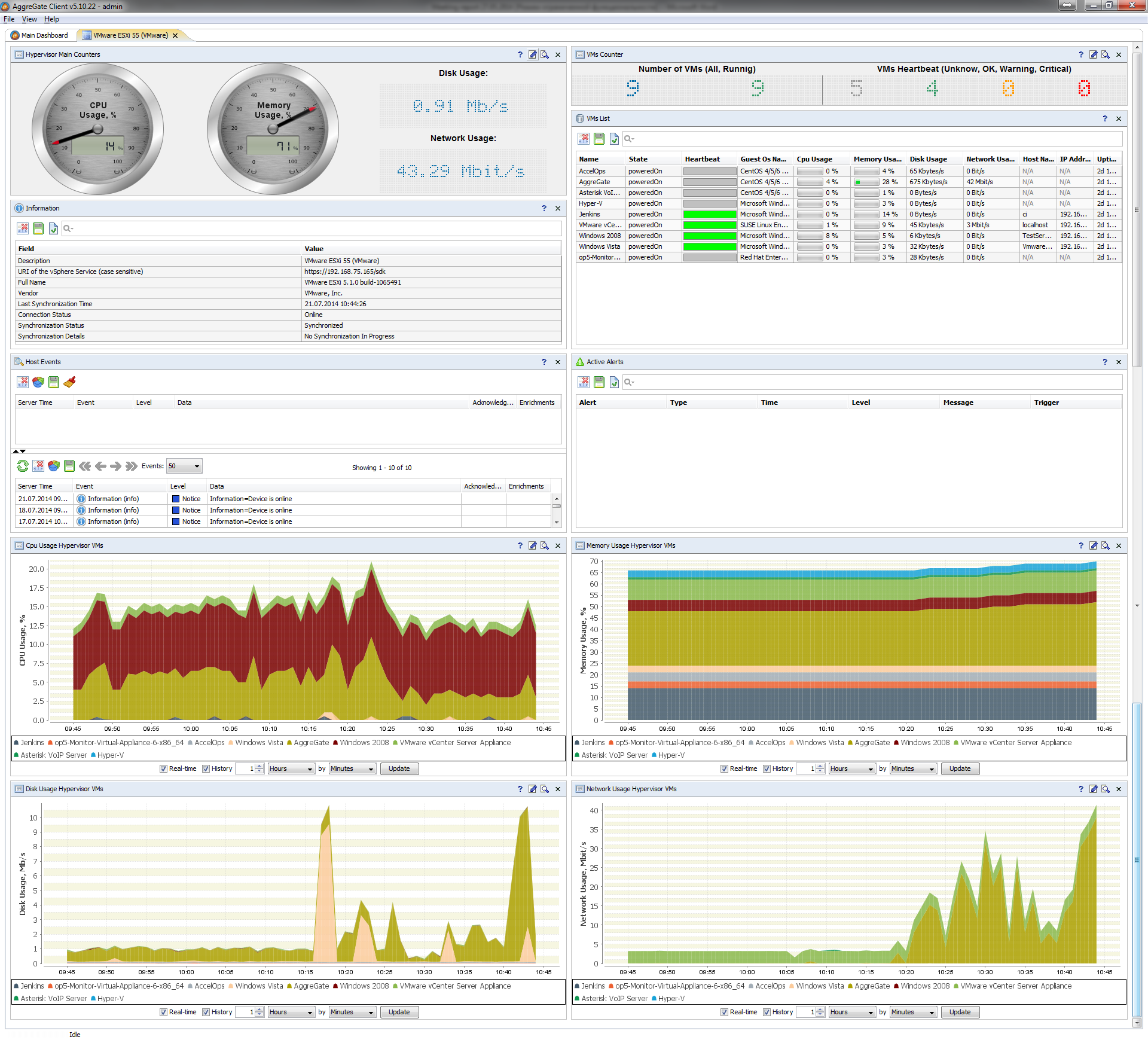
В части возможностей по настройке Network Manager очень сильно отличается от всех остальных продуктов. Продукт полностью разработан при помощи стандартных инструментов платформы AggreGate по обработке и визуализации данных. Проще говоря, всю систему управления ИТ, не считая модулей сбора данных, разрабатывали наши системные и бизнес аналитики, а также сотрудники отдела внедрения. Результат их труда — сотни шаблонов отчетов, виджетов, тревог, каждый из которых можно открыть в системных редакторах и изменить «под себя».
Эта возможность касается не только простейшей настройки, вроде смены порога срабатывания тревоги, но и практически любых изменений поведения продукта. Посмотрим один пример: мониторинг статистики загрузки процессора.
На инструментальной панели Top 10 имеется таблица, показывающая 10 устройств с максимальной загрузкой процессора. Настройки элемента инструментальной панели ссылаются на запрос, доступный администратору в виде отдельного объекта в дереве объектов. Текст запроса такой:
SELECT info.info$description AS device, info.cpuLoad$cpuLoad AS processor_utilization_percentage FROM users.*.devices.*: cpuLoad: info: genericProperties AS info WHERE (info.cpuLoad$cpuLoad IS NOT NULL) AND (info.genericProperties$suspend = 0) ORDER BY processor_utilization_percentage DESC LIMIT 10 Этот запрос извлекает из единой модели данных платформы AggreGate значения переменной cpuLoad сразу же для всех устройств (соответствующих маске users.*.devices.*), и таким образом строит сводную таблицу по загрузке CPU, отсортированную по убыванию и ограниченную первыми 10-ю строками. Можно легко поменять текст запроса, например, чтобы он показывал только устройства определенного типа или из определенной группы.
Откуда же берется переменная cpuLoad? Может быть ее вычисляет ядро системы мониторинга на основе данных SNMP? А вот и нет. Еще одним ресурсом, полностью созданным в визуальных редакторах, является модель CPU Load. Она настроена таким образом, что к каждому сетевому устройству прикрепляется индивидуальный экземпляр модели. Этот экземпляр добавляет в устройства ту самую переменную cpuLoad, на которую ссылается отчет. Кроме того, в модели определен набор бизнес правил, позволяющих вычислить загрузку CPU в зависимости от доступных в снимке устройства данных:
Если устройство поддерживает HOST-RESOURCES-MIB (Windows, Linux, и т.д.), берется среднее текущее значение загрузки по всем ядрам CPU
Если на устройстве включен WMI, используются данные WMI класса Win32_PerfFormattedData_PerfOS_Processor
Для Cisco используется посчитанное устройством среднее значение за последние 5 минут
Для Solaris складываются значения пользовательской и системной загрузки CPU
Немного сложнее, системы HP/UX предоставляют вместо посчитанного значения загрузки CPU счетчик миллисекунд, в которые процессор был занят с момента включения. Для промежуточного анализа используется еще один объект платформы AggreGate, называемый статистический канал. Он преобразует данные счетчика миллисекунд в скорость изменения и сохраняет статистику в кольцевой базе данных (RRD). Правило вычисления загрузки CPU для HP/UX в свою очередь ссылается на вычисленную каналом среднюю загрузку CPU за последнюю минуту.
И так далее, в поставку продукта входят правила вычисления загрузки для многих распространенных устройств.
 Если добавить при помощи редактора правил новое правило, например для Huawei, то все входящие в стандартный продукт тревоги, отчеты и инструментальные панели по загрузке процессора станут автоматически совместимы с оборудованием Huawei, так как они также ссылаются на модель CPU Load.
Если добавить при помощи редактора правил новое правило, например для Huawei, то все входящие в стандартный продукт тревоги, отчеты и инструментальные панели по загрузке процессора станут автоматически совместимы с оборудованием Huawei, так как они также ссылаются на модель CPU Load.
Все остальные модули системы мониторинга также созданы по принципу использования стандартных компонентов платформы вместо «хардкодинга» логики в ядро продукта. Например, для запуска сканирования сети по расписанию используется настраиваемая (и даже удаляемая) задача системного планировщика.
Инструментальные панели, реализующие настроечные экраны и главный операторский экран продукта Network Manager, спроектированы так, чтобы скрыть от обычных пользователей все сложности связанные с настройкой системы и позволить им эффективно решать повседневные задачи.
Цель этой статьи — описании идеологии нашей системы, «за бортом» осталось даже очень поверхностное перечисление возможностей продукта. Мы и не думаем, что хабр подходящая для этого площадка. Поэтому в последующих статьях мы будем уделять внимание интересным проектам, в которых нам довелось поучаствовать, а также детальным описаниям способа решения различных нестандартных задачек.
Мы сделаем бесплатную лицензию Network Manager Premium на 25 устройств любому человеку, обратившемуся со ссылкой на хабр. Она позволит поставить под мониторинг пару десятков корпоративных серверов, баз данных, гипервизоров, или, например, источников NetFlow. Никаких условий для получения лицензии нет, мы надеемся на фидбэк — как положительный, так и критический.
