8 мифов о дедупликации

Несмотря на то, что технология дедупликации известна уже достаточно давно, но только сейчас технологии, применяемые в современных массивах данных, позволили ей пережить второе рождение. Во всех современных массивах данных на текущий момент используется дедупликация, но наличие этой функции в массиве еще не значит, что это даст весомые преимущества именно под ваши данные.
К сожалению, большое количество администраторов принимают «на веру» и считают, что дедупликация обладает безграничными возможностями.
Не важно, являетесь ли вы администратором системы хранения уровня tier-1, архивного хранилища или all-flash гибридных систем хранения, вам будет интересно пройтись по мифам и легендам дедупликации, чтобы избежать досадных ошибок при проектировании или работе с вашими системами хранения.
Коэффициент сокращения данных: чудес не бывает
В то время как дедупликация стала доступна как для массивов, хранящих ваши продуктивные данные, так и для массивов, хранящих резервные копии данных, коэффициент дедупликации на этих массивах может быть совершенно разным. Архитекторы очень часто полагают, что коэффициент, достигнутый на архивном массиве, можно применить и к продуктивному хранилищу.
Дедупликация — это автоматический процесс, существующий на многих массивах известных производителей, но потенциальный коэффициент, который вы можете получить, отличается у массивов разного типа. В результате, например, если вам будет нужен массив на 100ТБ, а вы будете считать коэффициент 10:1, то и приобретете хранилище под 10ТБ, или, скажем, если вы будете оценивать коэффициент как 2:1, следовательно, приобретете хранилище на 50ТБ — в итоге, эти совершенно разные подходы, приводят к совершенно разной стоимости покупки! Вы должны на практике понять какой коэффициент вы можете получить на ваших продуктивных данных, прежде чем сделать выбор в пользу определенной модели с определенным объемом.
Строя конфигурации массивов данных под различные задачи оперативного хранения и резервного хранения, часто приходится сталкиваться со сложностями в правильном определении коэффициента дедупликации. Если вам интересны тонкости архитектурного дизайна массивов под дедупликацию, эта дискуссия для вас.
Как минимум, понимание на базовом уровне 8 мифов, приведенных далее, позволит вам осознанно понять дедупликацию и оценить ее коэффициент для ваших данных.
Миф1. Больший коэффициент дедупликации дает больше преимуществ для хранения данных
Верно ли утверждение, что если один вендор предлагает коэффициент дедупликации 50:1 это в пять раз лучше альтернативного предложения 10:1? Нужно проверять и сравнивать совокупную стоимость влдения! Дедупликация позволяет сократить требования к ресурсам, но какова потенциальная экономия объема? 10:1 позволяет уменьшить размер хранимых данных (reduction ratio) на 90%, в то время как коэффициент в 50:1 увеличивает этот показатель на 8% и дает 98% reduction ratio (см. график ниже). Но это только 8% разницы…
В целом, чем выше коэффициент дедупликации, тем меньше преимуществ по уменьшению объема данных, согласно закону убывающей доходности (https://en.wikipedia.org/wiki/Diminishing_returns).
Объяснение смысла закона убывающей доходности может быть таким: дополнительно применяемые затраты одного фактора (например, коэффициента дедупликации) сочетаются с неизменным количеством другого фактора (например, объема данных). Следовательно, новые дополнительные затраты на текущем объеме дают всё меньшую экономию ресурсов.
К примеру, у вас есть офис, в котором работают клерки. Со временем, если увеличивать количество клерков, не увеличивая размер помещения, они будут мешаться под ногами друг у друга и возможно затраты будут превышать доходы.

Рис. 1 Рост коэффициента дедупликации и сокращение объемов хранения
Миф2. Есть четкое определение термина «дедупликация»
Дедупликация позволяет сократить объем хранимых данных, удаляя повторяющиеся последовательности данных из пула. Дедупликация может быть на файловом уровне, блочном уровне или на уровне приложения или контента. Большая часть продуктов сочетают дедупликацию с компрессией, чтобы еще сильнее сократить объем хранимых данных. В то время, как некоторые производители не разделяют эти термины, некоторые разделяют их и вводят такие термины, как «уплотнение» (compaction), что, по сути, является просто другим названием «дедупликации плюс сжатие». К сожалению, не существует единственного определения дедупликации. В обывательском уровне вам будет важно, как вы сможете сэкономить на дисковых ресурсах вашей системы хранения и резервного копирования, применяя дедупликацию. Ниже мы раскроем эту тему.
Говоря про линейку систем хранения и резервного копирования HPE важно отметить, что и системы хранения, и системы резервного копирования обладают интересным функционалом, позволяющим заказчикам экономить на дисковых ресурсах.
Для систем хранения оперативных данных в массиве 3PAR разработан целый комплекс утилит и механизмов, позволяющий сократить объем данных на продуктивном массиве.
Этот комплекс носит название HPE 3PAR Thin Technologies и состоит из нескольких механизмов:
- Thin Provisioning — наиболее эффективно реализованная в системах хранения 3PAR, т.к. применяется виртуализация дискового пространства и массив используют свою внутреннюю карту хранимых блоков, при высвоюождении ресурсов массиву не нужно проводить ревизию (garbage collection), высвободившиеся блоки сразу готовы к дальнейшему использованию… Позволяет выделять логическому тому ровно столько объема, сколько он требует, но на массиве занять всего лишь столько, сколько на этот том физически записано.
- Thin Conversion — технология, позволяющая переводить в реальном времени тома со старых массивов данных HPE (3PAR, EVA), EMC, Hitachi и других производителей в «тонкие тома» (которые используют Thin Provisioning) на массиве 3PAR с сокращением объема тома на целевом устройстве.
- Thin Persistence и Thin Copy Reclamation — технология, позволяющая массиву 3PAR на очень низком гранулярном уровне понимать работу всех популярных файловых систем и гипервизоров и в случае удаления файлов (освобождения физического объема) переводить соответствующие блоки в пул свободных ресурсов.
- Thin Deduplication — технология позволяющая использовать дедупликацию на продуктивном массиве в реальном времени, без существенной просадки производительности.
Все три технологии доступны бесплатно и без ограничений по времени или объему для любой системы хранения 3PAR, в том числе, установленных у наших заказчиков, подробнее об этих технологиях: www.hpe.com/h20195/v2/GetPDF.aspx/4AA3–8987ENW.pdf
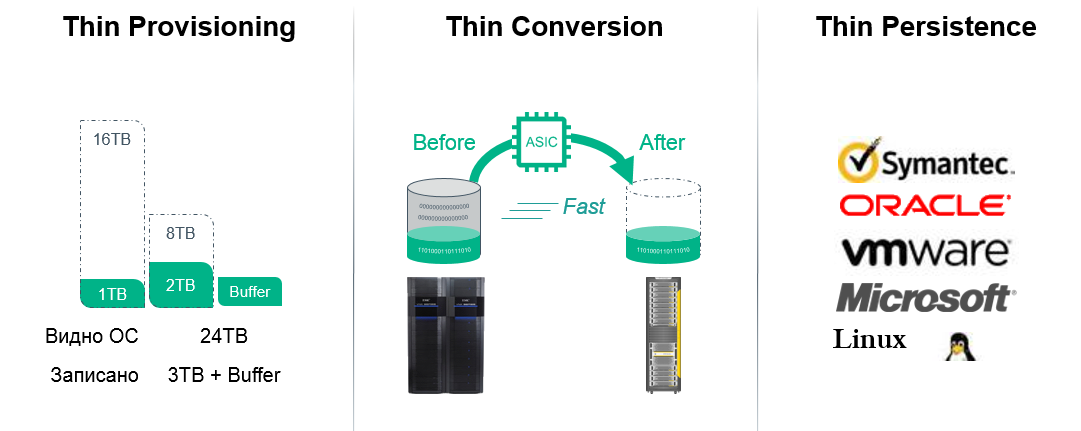
Рис. 2 Технологии Thin в массивах 3PAR
Миф3. Коэффициенты дедупликации на основном массиве такие же, как и на массиве с резервными копиями.
Разработчики систем хранения данных используют различные алгоритмы дедупликации. Некоторые из них требуют больших ресурсов CPU и сложнее, чем остальные, следовательно, не должен удивлять тот факт, что коэффициент дедупликации варьируется достаточно сильно.
Однако, самый большой фактор, влияющий на то, какой коэффициент дедупликации вы получите — как много у вас повторяющихся данных. По этой причине системы резервного копирования, содержащие несколько копий одних и тех же данных (дневные, недельные, месячные, квартальные, годичные) имеют такой высокий коэффициент дедупликации. В то время как оперативные системы хранения имеют практически уникальный набор данных, что практически всегда дает невысокий коэффициент дедупликации. В случае, если вы храните несколько копий оперативных данных на продуктивном массиве (например, в виде клонов) — это увеличивает коэффициент дедупликации, т.к. применяются механизмы сокращения места хранения.
Поэтому для оперативных массивов хранения данных иметь коэффициент 5:1 также замечательно, как иметь коэффициент 30:1 или 40:1 для систем резервного копирования, поскольку коэффициент этот зависит от того, сколько копий продуктивных данных хранится на таких массивах.
Если рассматривать продукты компании HPE, то в массивах для оперативного хранения HPE 3PAR поиск повторяющихся последовательностей (например, при инициализации виртуальных машин или создании снэпшотов) проходит «на лету» на специальной микросхеме ASIC, установленной в каждом контроллере массива. Этот подход позволяет разгрузить центральные процессоры массива для других, более важных, задач и дает возможность включить дедупликацию для всех типов данных, не боясь, что массив «просядет» под нагрузкой. Подробнее про дедупликацию на массиве 3PAR можно прочитать: www.hpe.com/h20195/v2/getpdf.aspx/4AA4–9573ENW.pdf
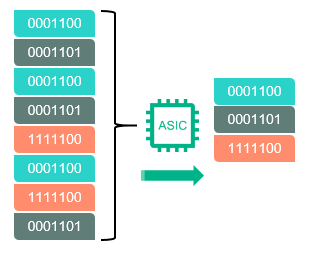
Рис. 3 Дедупликация в массивах 3PAR выполняется на выделенной микросхеме ASIC
В портфеле HPE также есть аппаратные комплексы для резервного копирования данных с онлайн дедупликацией на уровне блоков переменной длины — HPE StoreOnce. Варианты систем охватывают полный спектр заказчиков от начального до корпоративного уровня:

Рис. 4 Портфель систем резервного копирования HPE StoreOnce
Про преимущества систем резервного копирования StoreOnce можно почитать в других статьях.
Для заказчиков может быть интересно, что связка HPE 3PAR и StoreOnce позволяет упростить и ускорить процесс переноса данных с продуктивного массива на систему резервного копирования без использования ПО резервного копирования или выделенного сервера бэкапа. Такая связка получила название HPE StoreOnce RMC и подробнее о ней также можно почитать в нашей статье.
Миф4. Все данные одинаковы
Здесь не должно быть никаких сомнений- все данные разные. Даже данные одного и того же приложения в различных условиях будут иметь разные коэффициенты дедупликации на одном и том же массиве. Коэффициент дедупликации для конкретных данных зависит от разных факторов:
- Тип данных — данные, прошедшие программное сжатие, метаданные, медиа-потоки и зашифрованные данные всегда имеют очень невысокий коэффициент дедупликации или не сжимаются вовсе.
- Степень изменяемости данных — чем выше объем дневных изменений данных на блочном или файловом уровне, тем ниже коэффициент дедупликации. Это особенно актуально для систем резервного копирования.
- Срок хранения — чем больше копий данных вы имеете, тем выше коэффициент дедупликации.
- Политика резервного копирования — политика создания дневных полных копий, в противовес политике с инкрементными или дифференциальными бэкапами, даст больший коэффициент дедупликации (см. исследование ниже).
Таблица ниже дает поверхностную оценку коэффициента дедупликации, в зависимости от типа данных. Необходимо помнить, что коэффициент дедупликации на основном массиве данных будет всегда ниже коэффициента дедупликации на резервном массиве.

Рис. 5 Оценка коэффициента дедупликации в зависимости от типов данных и политики резервного копирования
Миф5. Группировка несвязных типов данных повышает уровень дедупликации
В теории, вы можете смешивать совершенно разные типы данных в общем пуле хранения для дедупликации есть ощущение, что вы имеете очень большой набор уникальных данных и, следовательно, вероятность нахождения в этом пуле уже записанных ранее блоков или объектов будет велика. На практике же этот подход не работает между несвязанными типами данных, например, между БД и Exchange, поскольку форматы данных разные, даже если хранится один и тот же набор данных. Такой, все время растущий пул, становится более сложным и требует больше времени для поиска повторяющихся последовательностей. Лучшей практикой является разделение пулов по типу данных.
Например, если выполнить дедупликацию одной виртуальной машины, вы получите некоторый коэффициент, если создать несколько копий этой виртуальной машины и выполнить дедупликацию на этом пуле, ваш коэффициент дедупликации вырастет, а если сгруппировать несколько виртуальных машин по типу приложения и создать несколько копий этих виртуальных машин — коэффициент увеличится еще больше.

Рис. 6 Зависимость коэффициента дедупликации от количества виртуальных машин в пуле и размеров блока данных.
Миф6. Ваше первое резервное копирование покажет вам ожидаемый коэффициент дедупликации.
Это ошибочное мнение появляется при сравнении коэффициентов на основном массиве и системе резервного копирования. Если вы храните только одну копию данных — возможно, вы увидите некоторый коэффициент дедупликации, больший единицы. Этот коэффициент сможет вырасти в том случае, если вы увеличите количество копий очень похожих данных, таких как резервные копии текущей БД.
График ниже показывает очень типичную кривую коэффициента дедупликации. Приложение, в этом графике — БД SAP HANA, но большинство приложений показывает схожую кривую. Ваше первое резервное копирование показывает определенную дедупликацию, но большая экономия достигается благодаря сжатию данных. Как только вы начинаете держать в пуле больше копий данных — коэффициент дедупликации пула начинает расти (голубая линия). Коэффициент индивидуального бэкапа взмывает вверх уже после создания второй копии (орнжевая линия), т.к. на блочном уровне первый и второй бэкап очень похожи.
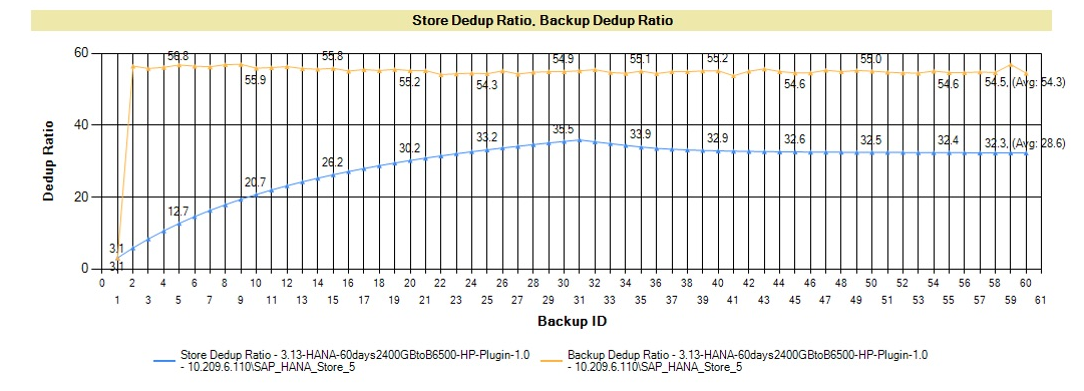
Рис. 7 График роста коэффициента дедупликации при увеличении количества резервных копий (подробнее в документе www.hpe.com/h20195/v2/GetPDF.aspx/4AA6–4641ENW.pdf).
Миф7. Вы не можете увеличить уровень дедупликации
Наивно рассуждать, что нет возможности искусственно увеличить уровень дедупликации. Другой вопрос — зачем? Если показать маркетинговые цифры — это одно, если необходимо создать эффективную схему резервного копирования — это другое. Если цель — иметь синтетический наивысший коэффициент дедупликации, то необходимо просто хранить больше как можно больше копий одних и тех же данных. Конечно, это увеличит объем хранимых данных, но ваш коэффициент дедупликации взмоет до небес.
Изменение политики резервного копирования, определенно также влияет на коэффициент дедупликации, как можно увидеть в примере ниже для реального типа данных, где сравниваются политики создания полных копий и комбинации полных копий с инкрементальными и дифферентальными бэкапами. В примере ниже лучший коэффициент получается при использовании только дневных полных бэкапов. Тем не менее, на одних и тех же данных объем хранения является довольно разным для всех трех подходов. Поэтому необходимо понимать, что изменение в вашем подходе к резервному копированию может довольно сильно повлиять на коэффициент дедупликации и на физический объем хранимых данных.
Миф8. Нет возможности заранее спрогнозировать коэффициент дедупликации
Всякая окружающая среда уникальна и очень сложно аккуратно спрогнозировать реальный коэффициент дедупликации. Но тем не менее, производители систем резервного копирования выпускают наборы небольших утилит для основных систем хранения и систем резервного копирования, позволяющие получить представление о типе данных, политике резервного копирования, сроке хранения. Эти утилиты позволяют в какой-то мере получить представление об ожидаемом коэффициенте дедупликации.
Также производители имеют представление о коэффициентах, получаемых у других заказчиках на примерно похожей среде и отраслевом сегменте и могут использовать эту информацию для построения прогноза. В то время как это не дает гарантии, что на ваших данных вы получите схожий коэффициент, к этим цифрам, как минимум, стоит присмотреться.
Но наиболее точный прогноз по коэффициенту дедупликации получается в ходе проведения испытаний на реальных данных.

Рис. 8 Изменение коэффициента дедупликации и объема занимаемых данных в зависимости от политики резервного копирования на данных конкретного заказчика
У компании HPE есть набор утилит и сайзеров, позволяющий спрогнозировать (с неким допущением) тот объем систем хранения, который необходим заказчикам.
- Для оперативного хранилища данных есть бесплатная программа оценки текущей утилизации массива и оценки экономии места, в случае перехода на 3PAR: www.hpe.com/h20195/v2/GetDocument.aspx? docname=4AA3–4015ENW
- Для оценки утилизации ресурсов на оперативном массиве и построения прогноза по росту объема данных на уже установленных системах, при условии разрешения отправки массивом информации о его состоянии в службу технической поддержки HPE: www.storefrontremote.com
- Аналогичная программа по оценке утилизации систем резервного копирования: www.hpe.com/h20195/V2/GetDocument.aspx? docname=4AA4–0953ENW&cc=us&lc=en
Также есть возможность оценить предполагаемый объем, который мы получим после включения на системе 3PAR дедупликации в режиме симулятора, для этого необходимо на 3PAR запустить команду оценки, выполняемую в онлайн режиме, прозрачно для хоста:
checkvv -dedup_dryrun {Имена виртуальных томов}
И получить предварительную оценку:

Итак, нет никакой магии за понятием дедупликации, а развенчивание мифов, приведенное выше, позволит вам лучше понять, на что способны ваши данные и позволит вам спрогнозировать утилизацию ваших массивов.
Следует отметить, что современный рост объемов SSD и снижения стоимости хранения на 1ГБ на flash накопителях (а стоимость уже соответствует $1.5 за ГБ) отодвигают вопросы, связанные с эффективностью дедупликации на второй план для оперативного хранилища, но становятся все более актуальными для систем резервного копирования.
К слову, есть альтернативное видение будущего (без дедупликации):
Викибон считает, что устранение копий одних и тех же данных эффективнее, чем рост коэффициенотв дедупликации и компрессии (см. по ссылке в середине отчета — wikibon.org/wiki/v/Evolution_of_All-Flash_Array_Architectures), но такой подход требует кардинального внедрения целого комплекса технических мер, изменения всей инфраструктуры, правил одновременной работы приложений (процессинг, аналитика) с данными так, чтобы они не снижали производительность (при внедрении хороших средств работы с SLA) и надежность.
И, самое главное, если все это внедрить во всей экосистеме — и разработчикам ПО, и вендорам, и CIO, то через несколько лет экономия от этого будет больше, чем от дедупликации.
Какая школа мысли победит — покажет время.
Использованы материалы community.hpe.com/t5/Around-the-Storage-Block/Myth-Busting-8-Common-Data-Deduplication-Misconceptions/ba-p/6901652? dysig_tid=1360ea31461c41288850c325abab37cf#.V-zGavl974Y
