JSON-сериализатор на быстрых шаблонах

В чем проблема текстовых форматов обмена данными? Они медленные. И не просто медленные, а чудовищно медленные. Да, они избыточны, по сравнению с бинарными протоколами и, по идее, текстовый сериализатор должен быть медленнее примерно на столько же, на сколько он избыточен. Но на практике получается, что текстовые сериализаторы иной раз на порядки уступают бинарным аналогам.
Я не буду рассуждать о преимуществах JSON перед бинарными форматами — у каждого формата есть своя область применения, в которой он хорош. Но зачастую мы вынуждены отказываться от чего-то удобного в пользу не очень комфортного в силу катастрофической неэффективности первого. Разработчики отказываются от JSON, даже если он прекрасно подходит для решения задачи, только из-за того, что он оказывается узким местом в системе. Конечно же, виноват не JSON сам по себе, а реализации соответствующих библиотек.
В этой статье я расскажу не только о проблемах парсеров текстовых форматов вообще и JSON в частности, но и о нашей библиотеке, которую мы используем уже много лет в самых высоконагруженных проектах. Она настолько нас устраивает и в плане быстродействия, и в плане удобства использования, что порой отказываемся от бинарного формата там, где бы он больше подошел. Конечно же, я имею в виду некие пограничные условия, без претензий на все случаи жизни.
Для оценки масштаба трагедии я замерил время сериализации не сильно сложного объекта для пары известных JSON-библиотек, google: protobuf, «ручной» JSON-сериализации и для библиотеки wjson, разработчиком которой я являюсь и расскажу подробно в этой статье далее.
Результаты показаны на диаграмме: 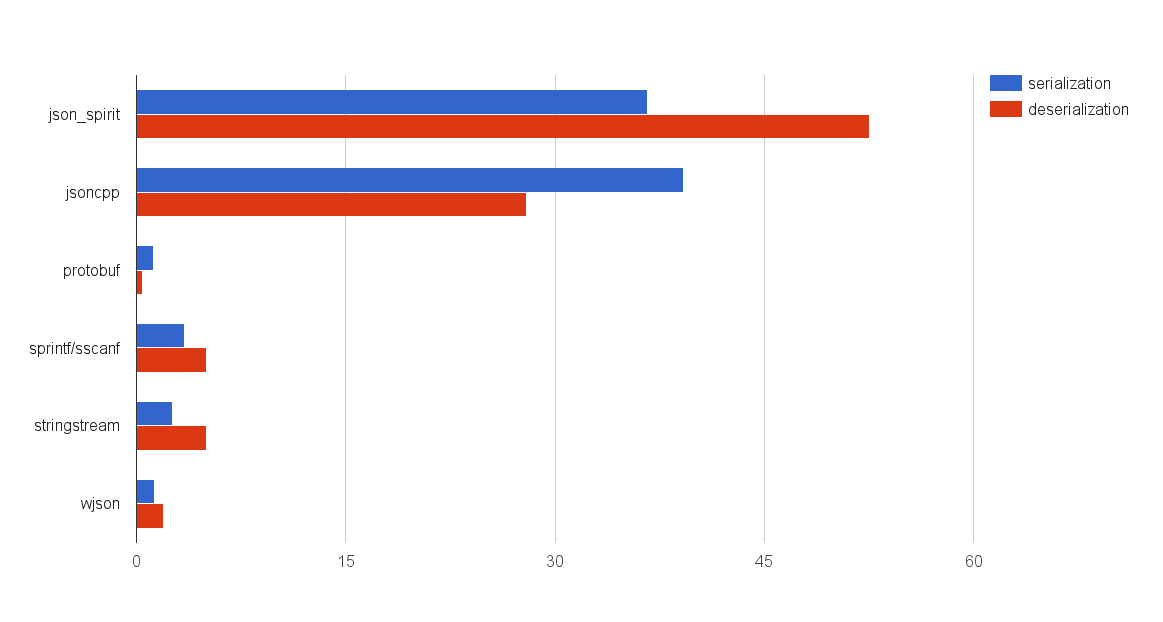
Признаюсь, меня эти результаты в свое время, скажем мягко, слегка удивили.
Производительность jsoncpp и json_spirit (на базе boost: spirit) катастрофически проигрывает google: protobuf. Ситуация с «ручной» сериализацией с использованием sprintf/sscanf или std: stringstream существенно лучше. Но если вы используете первые два инструмента, то не спешите все бросать, и с возгласом: «я же говорил, что надо делать самому!» — переделывать свои проекты. На графике замеры для одного единственного вызова sprintf/sscanf, в который мы запихали сериализуемый объект без всяких проверок и возможности переставлять или пропускать поля в JSON-объекте. Более подробные цифры я приведу в разделе про сериализации объектов.
В этой статье я рассматриваю JSON как формат обмена сообщениями с акцентом на производительность. Соответственно сравниваю те или иные технологии именно в этом контексте. Это означает также, что структура сообщений на этапе разработки (компиляции), нам известна. Предлагаемая библиотека wjson также разрабатывалась именно для этих задач. Исследовать неизвестные JSON-документы с помощью неё, конечно же, можно, и возможно, wjson будет эффективнее многих библиотек, уж во всяком случае, jsoncpp и json_spirit — это точно.
На самом деле wjson и концептуально ближе к protobuf, чем, например, к упомянутым выше библиотекам. Он точно так же по некоторому мета-описанию генерирует код сериализации/десериализации. Но в отличие от protobuf использует не внешнее приложение, а компилятор C++. Я в предыдущей статье показал, как компилятор можно научить играть в крестики-нолики, а уж научить его генерировать код сериализации — дело техники.
Но что мне больше самому нравится, так это то, что в сериализуемые структуры данных не нужно внедрять никакого дополнительного функционала — мухи отдельно, котлеты отдельно. А еще поддерживается наследование, в том числе и множественное, агрегация любой вложенности, и некоторые плюшки, например, сериализация enum-ов.
Изначально wjson задумывалась исключительно для декларативного описания JSON-конструкций на шаблонах c++, чтобы избавить программиста от написания run-time кода со множеством необходимых проверок. Но быстро выяснилось, что компилятор агрессивно inline-ит подобные конструкции. И потребовалось совсем немного усилий, чтобы заставить эти конструкции работать достаточно эффективно и выйти на приемлемый уровень производительности.
Если вы работали с XML, то вы в курсе, что есть два подхода к десериализации — это DOM (Document Object Model) и SAX (Simple API for XML). Напомню, что в случае DOM текст преобразуется в дерево узлов, которое можно исследовать, используя соответствующее API. А SAX парсер работает по-другому — он сканирует документ и генерирует те или иные события, которые обрабатывает код пользователя, реализованный, как правило, в виде функций обратного вызова. Так или иначе, большинство текстовых десериализаторов используют один из этих подходов, либо комбинируют их.
Основной недостаток DOM в необходимости строить дерево, а это всегда накладно. Процесс построения такого дерева на этапе десериализации может происходить существенно дольше, чем исполнение прикладных алгоритмов. Но кроме этого, необходимо произвести поиск необходимых полей и преобразовать их во внутренние структуры данных. А эта задача ложится уже на плечи программиста, которую он может реализовать чрезвычайно неэффективно. На самом деле это уже не столь важно, потому что именно построение деревьев DOM съедает основные ресурсы.
Парсеры типа SAX гораздо быстрее. По большому счету они проходят текст один раз, вызывая соответствующие хандлеры. Реализовать подобный парсер для JSON тривиальная задача, потому как сам JSON прост до безобразия, и в этом его прелесть. Но требует от программиста, его использующего, гораздо больше усилий по извлечению данных. А это — больше работы программисту, больше ошибок и неэффективного кода, что может свести на нет эффективность SAX.
Вообще, тема эффективной сериализации очень интересна с точки зрения разработки некоего универсального решения. Но с позиции прикладного программирования — это чрезвычайно нудно и скучно, а как следствие, огромные объемы неэффективного говнокода. Программисту гораздо интереснее оптимизировать прикладной код, а то, что десериализация происходит на порядок медленнее и его оптимизация в этом контексте не имеет особого смысла, его мало беспокоит.
Но если большинство существующих решений по каким-либо причинам нас не устраивает, давайте сделаем это вручную, благо JSON очень простой формат. А здесь очень интересную историю я наблюдал несколько раз. Если программист работает с бинарными протоколами, он скрупулезно сдвигает биты, оптимизирует код и получает от этого удовольствие. А вот если ему предложить поработать с текстовым форматом в этом же контексте, у него в мозгу как будто что-то отключается. Точнее, наоборот, у него включается защита против велосипедостроительства высшего порядка, от которой при работе с бинарным форматом он не особо страдал. Он подключает кучи библиотек для работы с текстом ради пары красивых (но, как правило, не очень эффективных) функций, чтобы как-то облагородить свой код, работающий с JSON. А результат все равно плачевный.
Мало кому в голову придет писать свою реализацию atoi, но мы все же попробуем:
template
P my_atoi( T& v, P beg, P end)
{
if( beg==end) return end;
bool neg = ( *beg=='-' );
if ( neg ) ++beg;
if ( beg == end || *beg < '0' || *beg > '9') return 0;
if (*beg=='0') return ++beg;
v = 0;
for ( ;beg!=end; ++beg )
{
if (*beg < '0' || *beg > '9') break;
v = v*10 + (*beg - '0');
}
if (neg)
v = static_cast(-v);
return beg;
}
На самом деле все просто, но универсальнее и удобнее (на мой взгляд), чем классическое atoi. Но самое интересное — это работает в два раза быстрее. Да, конечно, по большей части за счет inline подстановки, но это не суть важно. Кстати, sscanf/sprintf отрабатывают %s параметры быстрее, чем %d, при сопоставимой длине строки.
Я не буду сейчас рассказывать об опасности sscanf/sprintf, про это уже писали много раз и, кроме того, есть безопасные альтернативы, например, std: stringstream или boost: lexical_cast<>. К сожалению, многие программисты, в том числе и C++, руководствуются мифом, что тру Си быстрее, и с завидным упорством начинают использовать sscanf/sprintf. Но проблема-то, в данном контексте, не в языке, а в реализации того или иного функционала. Например, std: stringstream, при правильном использовании, может быть и не хуже Си альтернатив, а вот, допустим, boost: lexical_cast<> может существенно уступать в этом плане.
Поэтому нужно тщательно тестировать на производительность не только сторонние библиотеки, но и знакомые инструменты. Но зачастую будет быстрее свелосипедничать, подсмотрев необходимые реализации в Интернете.
Код для my_atoi практически без изменений взят из wjson, может, кому пригодится. Код для сериализации чуть более заморочен:
// Вычисляет размер временного буфера в зависимости от типа
template
struct integer_buffer_size
{
enum { value = sizeof(T)*2 + sizeof(T)/2 + sizeof(T)%2 + is_signed_integer::value };
};
// Проверка на отрицательные значения для знаковых
template
struct is_signed_integer_base
{
enum { value = 1 };
static bool is_less_zero(T v) { return v < 0; }
};
// Для беззнаковых проверки нет, всегда false
template
struct is_signed_integer_base
{
enum { value = 0 };
static bool is_less_zero(T ) { return false; }
};
template
struct is_signed_integer:
is_signed_integer_base< T, ( T(-1) < T(1) ) >
{
};
template
P my_itoa(T v, P itr)
{
char buf[integer_buffer_size::value];
char *beg = buf;
char *end = buf;
if (v==0)
*(end++) = '0';
else
{
// для беззнаковых типов условие вырождается if (false)
// и ненужный код оптимизатор убирает. Также это убирает
// предупреждения компилятора для беззнаковых типов
if ( is_signed_integer::is_less_zero(v) )
{
for( ; v!=0 ; ++end, v/=10)
*end = '0' - v%10;
*(end++)='-';
}
else
{
for( ; v!=0 ; ++end, v/=10)
*end = '0' + v%10;
}
}
do { *(itr++)=*(--end); } while( end != beg );
return itr;
}
За счет такого вот побайтного перебора для остальных конструкций JSON и inline подстановки можно добиться более быстрой десериализации. Если собрать их каким-либо образом в единую конструкцию, то получим своего рода SAX-парсер, который к тому же очень быстр.
Простые типы
Давайте сразу пример сериализации:
int value = 12345;
char bufjson[100];
char* ptr = wjson::value::serializer()(value, bufjson);
*ptr = '\0';
std::cout << bufjson << std::endl;
Здесь wjson: value
Сразу отвечу на вопрос, почему serializer не static-функция. Во-первых, static-элементы компилятор не очень любит в плане времени компиляции, а во-вторых, это просто удобнее, во всяком случае, для меня. По факту здесь произойдет полная подстановка кода, который я показал под спойлером выше, на примере my_itoa.
Конструкция value<> используется не только для целочисленных, но и для вещественных, строк и булевых. Определение:
template
struct value
{
typedef T target;
typedef implementation_defined serializer;
};
Для булевого и целочисленных типов аргумент R не используется. Для строчек типа std: string или std: vector
Класс serializer, помимо сериализации, предоставляет функционал десериализации, т.е. два перегруженных operator ():
template
class implementation_defined
{
public:
template
P operator()( const T& v, P itr);
template
P operator() ( T& v, P beg, P end, json_error* e );
};
Функция сериализации принимает на вход, помимо ссылки на сериализуемый тип, output-итератор, например:
int value = 12345;
std::string strjson;
wjson::value::serializer()(value, std::back_inserter(strjson));
std::cout << strjson << std::endl;
std::stringstream ssjson;
wjson::value::serializer()(value, std::ostreambuf_iterator(ssjson));
std::cout << ssjson.str() << std::endl;
wjson::value::serializer()(value, std::ostreambuf_iterator(std::cout));
std::cout << std::endl;
Десериализатор принимает на вход итераторы произвольного доступа, указывающие на начало и конец буфера, а также на указатель объект ошибки, который может быть нулевым:
value = 0;
char bufjson[100]=”12345”;
wjson::value::serializer()(value, bufjson, bufjson + strlen(bufjson), 0 );
std::cout << value << std::endl;
value = 0;
std::string strjson=”12345”;
wjson::value::serializer()(value, strjson.begin(), strjson.end(), 0 );
std::cout << value << std::endl;
И сериализатор, и десериализатор возвращают итераторы. В первом случае он указывает на место, где закончилась сериализация, а во втором — место во входном буфере, где закончилась десериализация, если не было ошибок. В случае ошибки возвращает указатель на конец буфера, и код ошибки, если был передан не нулевой указатель. Про обработку ошибок чуть позже, а сейчас добьем простые типы.
Поддерживаемые целочисленные: char, unsigned char, short, unsigned short, int, unsigned int, long int, unsigned long, long long, unsigned long long. C булевым (bool), все то же самое, сериализует в «true» или «false» и обратно. Автоматическое преобразование из других типов при десериализации не поддерживается.
Единственный тип, с которыми я не особо заморачивался в плане производительности — это вещественный (float, double, long double), там обычный std: stringstream. В первую очередь это связано с тем, что в реальных проектах, с которыми я работал, его всегда можно было заменить либо на целочисленные типы (например, передавать метры в миллиметрах), либо нагрузка в пределах 10К на ядро CPU, что не существенно. Если у вас основной объем трафика — это вещественные и никак от этого не уйти, то имеет смысл заморочиться с оптимизацией. По умолчанию вещественные сериализуются с мантиссой. При R>=0, как с фиксированной запятой:
double value = 12345.12345;
std::string json;
wjson::value::serializer()(value, std::back_inserter(json));
std::cout << json << std::endl;
json.clear();
wjson::value::serializer()(value, std::back_inserter(json));
std::cout << json << std::endl;
Результат:
1.234512e+04
12345.1234
Со строками, на первый взгляд, должно быть все просто, если вы используете utf-8, но на следующие моменты нужно обратить внимание:
- сериализация
- все utf-8 символы с кодом от 32 (пробел) копируются как есть
- символы »«,»\»,»/»,»\t»,»\b»,»\r»,»\n»,»\f» экранируются »\» в соответствии со спецификацией JSON
- остальные символы, с кодом меньшим 32, сериализуются в шестнадцатеричном формате (\uXXXX)
- не utf-8 сериализуется побайтно в формате \xXX, что не соответствует спецификации JSON, который работает исключительно с utf-8, но десериализатор wjson этот формат понимает
- десериализация
- экранированные символы деэкранируются
- комбинации вида \uXXXX преобразуются в utf-8, за исключением некоторых значений меньших 32 (если XXXX не кодирует »\t»,»\b»,»\r»,»\n»,»\f», то без преобразования)
- комбинации вида \хXX деэкранируются без проверок
- все остальные utf-8 символы копируются как есть
Некоторые сторонние библиотеки, особо не напрягаясь, сериализуют все, что не входит в диапазон ASCII (коды > 127) в формате \uXXXX. Но при десериализации подобной строки с помощью wjson это декодируется в utf-8. При повторной сериализации wjson этого экранирования уже не будет.
Иногда, как правило из-за программной ошибки, в середине строки оказывается »\0», который большинством сериализаторов, в том числе и wjson, преобразуется в \u0000, но при десериализации он не преобразуется в \0, а остается как есть.
Поддержка формата \xXX продиктована исключительно ограничением концепции wjson-сериализации, которая не предполагает невалидных данных (либо сериализуется, либо не компилируется). Для сериализации бинарных данных используйте, например, Base64.
#include
#include
#include
int main()
{
const char* english = "\"hello world!\"";
const char* russian = "\"\\u041F\\u0440\\u0438\\u0432\\u0435\\u0442\\u0020\\u043C\\u0438\\u0440\\u0021\"";
const char* chinese = "\"\\u4E16\\u754C\\u4F60\\u597D!\"";
typedef char str_t[128];
typedef wjson::value< std::string, 128 >::serializer sser_t;
typedef wjson::value< std::vector >::serializer vser_t;
typedef wjson::value< str_t >::serializer aser_t;
std::string sstr;
std::vector vstr;
str_t astr={'\0'};
// Десериализация
sser_t()( sstr, english, english + std::strlen(english), 0);
vser_t()( vstr, russian, russian + std::strlen(russian), 0);
aser_t()( astr, chinese, chinese + std::strlen(chinese), 0);
// Результат
std::cout << "English: " << sstr << "\tfrom JSON: " << english << std::endl;
std::cout << "Russian: " << std::string(vstr.begin(), vstr.end() ) << "\tfrom JSON: " << russian << std::endl;
std::cout << "Chinese: " << astr << "\tfrom JSON: " << chinese << std::endl;
// Сериализация english в stdout
std::cout << std::endl << "English JSON: ";
sser_t()( sstr, std::ostream_iterator( std::cout) );
std::cout << "\tfrom: " << sstr;
// Сериализация russian в stdout
std::cout << std::endl << "Russian JSON: ";
vser_t()( vstr, std::ostream_iterator( std::cout) );
std::cout << "\tfrom: " << std::string(vstr.begin(), vstr.end() );
// Сериализация chinese в stdout
std::cout << std::endl << "Chinese JSON: ";
aser_t()( astr, std::ostream_iterator( std::cout) );
std::cout << "\tfrom: " << astr;
std::cout << std::endl;
} Результат:
English: hello world! from JSON: "hello world!"
Russian: Привет мир! from JSON: "\u041F\u0440\u0438\u0432\u0435\u0442\u0020\u043C\u0438\u0440\u0021"
Chinese: 世界你好! from JSON: "\u4E16\u754C\u4F60\u597D!" English JSON: "hello world!" from: hello world!
Russian JSON: "Привет мир!" from: Привет мир!
Chinese JSON: "世界你好!" from: 世界你好!
Массивы
Для описания JSON массивов используется похожая с wjson: value конструкция:
template
struct array
{
typedef T target;
typedef implementation_defined serializer;
};
Здесь T — сериализуемый контейнер, а R — размер резерва для stl-контейнеров, которые поддерживают этот метод. Вроде все просто, но запись вида: wjson: array
typedef wjson::array< std::vector< wjson::value > > vint_json; В качестве параметра T передаем нужный нам контейнер, но вместо типа элемента контейнера передаем его JSON-описание. Поддерживаются:
- V[N]
- std: vector
- std: deque
- std: array
- std: list
- std: set
- std: multiset
- std: unordered_set
- std: unordered_multiset
Разумеется, максимальную производительность обеспечивают первые четыре варианта. Заполнение списков и ассоциативных контейнеров слишком накладно само по себе.
Пример, для классических си-массивов:
typedef wjson::value int_json;
typedef int vint_t[3];
typedef wjson::array< int_json[3] > vint_json;
Ну и, конечно же, поддерживаются многомерные массивы (например, векторы векторов и т.п.), как показано в примере:
#include
#include
#include
int main()
{
// Одномерный массив
typedef wjson::value int_json;
typedef std::vector vint_t;
typedef wjson::array< std::vector > vint_json;
std::string json="[ 1,\t2,\r3,\n4, /*пять*/ 5 ]";
vint_t vint;
vint_json::serializer()(vint, json.begin(), json.end(), NULL);
json.clear();
vint_json::serializer()(vint, std::back_inserter(json));
std::cout << json << std::endl;
// Двумерный массив (вектор векторов )
typedef std::vector< vint_t > vvint_t;
typedef wjson::array< std::vector > vvint_json;
json="[ [], [1], [2, 3], [4, 5, 6] ]";
vvint_t vvint;
vvint_json::serializer()(vvint, json.begin(), json.end(), NULL);
json.clear();
vvint_json::serializer()(vvint, std::back_inserter(json));
std::cout << json << std::endl;
// Трехмерный массив (вектор векторов из векторов)
typedef std::vector< vvint_t > vvvint_t;
typedef wjson::array< std::vector > vvvint_json;
json="[ [[]], [[1]], [[2], [3]], [[4], [5, 6] ] ]";
vvvint_t vvvint;
vvvint_json::serializer()(vvvint, json.begin(), json.end(), NULL);
json.clear();
vvvint_json::serializer()(vvvint, std::back_inserter(json));
std::cout << json << std::endl;
}
Здесь мы берем JSON-строку, десереализуем ее в контейнер, очищаем, сериализуем в эту же строку и выводим:
[1,2,3,4,5]
[[],[1],[2,3],[4,5,6]]
[[[]],[[1]],[[2],[3]],[[4],[5,6]]]
В строке «json» показано, что между элементами массива могут быть любые пробельные символы, в том числе перевод строки, а также комментарии в си-стиле, что очень удобно при реализации json-конфигурации.
Максимальный размер для динамических контейнеров не ограничен, а для си-массивов и std: array ограничением является собственно размер массива. Если во входящем JSON-элементов меньше, то оставшиеся заполняются значением по умолчанию, а если больше, то лишние просто отбрасываются.
Если JSON-массивы содержат элементы различных типов, то они сериализуются и десериализуются в два этапа. Сначала нужно описать контейнер строк, которые будут содержать произвольные не десериализованные JSON-конструкции, например:
typedef std::vector vstr; Для описания «сырого» JSON:
template
struct raw_value;
Который копирует строку JSON, как она есть, в контейнер T. А дальше, с помощью парсера, нужно определить тип JSON элемента и соответствующим образом десериализовать его. В примере ниже мы пытаемся прочитать массив чисел [1,»2»,[3]] инкрементировать все элементы и сериализовать его, сохраняя формат:
#include
#include
#include
int main()
{
typedef std::vector< std::string > vect_t;
typedef ::wjson::array< std::vector< ::wjson::raw_value > > vect_json;
vect_t inv;
vect_t outv;
std::string json = "[1,\"2\",[3]]";
std::cout << json << std::endl;
vect_json::serializer()( inv, json.begin(), json.end(), 0 );
for ( auto& v : inv )
{
outv.push_back("");
if ( wjson::parser::is_number(v.begin(), v.end()) )
{
int num = 0;
wjson::value::serializer()( num, v.begin(), v.end(), 0);
++num;
wjson::value::serializer()( num, std::back_inserter(outv.back()) );
}
else if ( wjson::parser::is_string(v.begin(), v.end()) )
{
std::string snum;
wjson::value::serializer()( snum, v.begin(), v.end(), 0);
int num = 0;
wjson::value::serializer()( num, snum.begin(), snum.end(), 0);
++num;
snum.clear();
wjson::value::serializer()( num, std::back_inserter(snum) );
wjson::value::serializer()( snum, std::back_inserter(outv.back()) );
}
else if ( wjson::parser::is_array(v.begin(), v.end()) )
{
std::vector vnum;
wjson::array< std::vector< wjson::value > >::serializer()( vnum, v.begin(), v.end(), 0);
++vnum[0];
wjson::array< std::vector< wjson::value > >::serializer()( vnum, std::back_inserter(outv.back()) );
}
else
{
outv.back()="null";
}
}
json.clear();
vect_json::serializer()( outv, std::back_inserter(json) );
std::cout << json << std::endl;
}
Результат:
[1,"2",[3]]
[2,"3",[4]]
Это работает также и с объектами, и со словарями, о которых речь пойдет дальше. Если числа у вас могут быть представлены только двумя вариантами, строкой или, собственно числом, то можно использовать обертку:
template
struct quoted;
- J — исходное JSON описание
- SerQ — предварительно сериализовывать в строку
- ReqQ — входной JSON должен быть «строкой»
- R резерв для промежуточного буфера (строки)
На самом деле эта конструкция работает для любого JSON-описания. Параметр SerQ включает двойную сериализацию. Например, для чисел это означает просто обрамление в кавычки. Параметр ReqQ включает двойную десериализацию, т.е. он требует, чтобы на входе была JSON-строка. Если он выключен, то правила немного сложнее. Если на входе не JSON-строка, то он просто запускает десериализатор J без предварительной десериализации. Если на входе JSON-строка, то он десериализует в промежуточный std: string. Если J описывает не строковую сущность, то повторная десериализация из промежуточного std: string. Для строковых сущностей определяем необходимость повторной десериализации. Это означает, что если после первой десериализации промежуточная строка начинается с кавычки, то это дважды сериализованная строка и десериализируем еще раз, в противном случае просто копируем.
Понятно, что wjson: quoted<> дает дополнительный оверхед и ее стоит рассматривать как временный костыль, на случай, если по каким-либо причинам клиент начал «чудить» и сериализовать числа сроками или делать двойную сериализацию вложенных объектов.
Парсер
В wjson есть класс parser, содержащий исключительно static-методы, которые можно разделить на два типа. Это проверка на соответствие тому или иному JSON-типу и, соответственно, методы — парсеры. Для каждого JSON-типа есть свой метод:
class parser
{
/*...*/
public:
template
static P parse_space( P beg, P end, json_error* e);
template
static P parse_null( P beg, P end, json_error* e );
template
static P parse_bool( P beg, P end, json_error* e );
template
static P parse_number( P beg, P end, json_error* e );
template
static P parse_string( P beg, P end, json_error* e );
template
static P parse_object( P beg, P end, json_error* e );
template
static P parse_array( P beg, P end, json_error* e );
template
static P parse_value( P beg, P end, json_error* e );
/*...*/
};
Так же, как и для десериализатора, здесь beg — начало буфера, end-конец буфера, а в «e», если не равно nullptr, будет записан код ошибки. В случае успеха, будет возвращен указатель на символ, следующий за последним символом текущей сущности. А в случае ошибки, будет возвращен end, и инициализирован e.
Допустим, у вас есть строка с несколькими JSON-объектами определенной структуры, которые разделены переводом строки или другими пробельными сущностями, тогда ее можно отработать так (без обработки ошибок):
for (;beg!=end;)
{
beg = wjson::parser::parse_space(beg, end, 0);
beg=my_json::serializer()(dict, beg, end, 0);
/* …. */
}
Все сериализаторы предполагают, что первым символом должен быть символ десериализуемого объекта, в противном случае будет ошибка. Но, как я уже и говорил, внутри объектов и массивов могут быть пробельные символы, в том числе и комментарии, которые десериализатор парсит тем же parse_space. Пример парсинга строки с несколькими JSON сущностями:
wjson::json_error e;
for (;beg!=end;)
{
beg = wjson::parser::parse_space(beg, end, &e);
beg = wjson::parser::parse_value(beg, end, &e);
if ( e ) abort();
}
Здесь parse_value проверяет любую JSON-сущность на валидность. Если на входе parse_space не пробельный символ, то он просто вернет beg. Он может вернуть ошибку, если, например, обнаружен незакрытый комментарий в си-стиле, но дополнительная проверка здесь избыточна. Если на вход парсеру (так же, как и десериализатору) приходит инициализированный объект ошибки, то он просто возвращает end.
Для определения конкретной JSON-сущности есть следующий набор методов:
class parser
{
/*...*/
public:
template
static bool is_space( P beg, P end );
template
static bool is_null( P beg, P end );
template
static bool is_bool( P beg, P end );
template
static bool is_number( P beg, P end );
template
static bool is_string( P beg, P end );
template
static bool is_object( P beg, P end );
template
static bool is_array( P beg, P end );
};
Несмотря на то, что они получают указатели на начало и конец буфера, эти методы определяют сущность по первому символу: { — это объект, [ — массив,» — строка, любая цифра — это число, а t, f или n — это true, false или null соответственно. Поэтому, если, например, is_object, нам возвращает истину, то чтобы убедиться, что это валидный объект, нужно вызвать parse_object и проверить, что нет ошибок.
Обработка ошибок
Проверять ошибки при десериализации нужно практически всегда. В примерах я это не делаю исключительно для наглядности. Рассмотрим на примере, где в исходный массив внедрили посторонний символ:
#include
#include
#include
int main()
{
typedef wjson::array< std::vector< wjson::value > >::serializer serializer_t;
std::vector< int > value;
std::string json = "[1,2,3}5,6]";
wjson::json_error e;
serializer_t()(value, json.begin(), json.end(), &e );
if ( e )
{
std::cout << "Error code: " << e.code() << std::endl;
std::cout << "Error tail of: " << e.tail_of() << std::endl;
if ( e.type() == wjson::error_code::ExpectedOf )
std::cout << "Error expected_of: " << e.expected_of() << std::endl;
std::cout << "Error position: "
<< wjson::strerror::where(e, json.begin(), json.end() ) << std::endl;
std::cout << "Error message: " << wjson::strerror::message(e) << std::endl;
std::cout << "Error trace: "
<< wjson::strerror::trace(e, json.begin(), json.end()) << std::endl;
std::cout << "Error message & trace: "
<< wjson::strerror::message_trace(e, json.begin(), json.end())
<< std::endl;
}
}
Собственно, сам объект ошибки wjson: json_error содержит информацию о коде ошибки и позицию относительно конца буфера, где парсер обнаружил какое-либо несоответствие. Для ошибок специального типа «Expected of», символ, который он ожидал.
Для получения читабельных сообщений используйте класс wjson: strerror. В примере выше в JSON-массиве встречается символ }, а парсер ожидает запятую (ну или квадратную скобку), о чем он и сообщает. В примере приведены все доступные методы для анализа ошибки. Результат следующий:
Error code: 3
Error tail of: 5
Error expected_of: ,
Error position: 6
Error message: Expected Of ','
Error trace: [1,2,3>>>}5,6]
Error message & trace: Expected Of ',': [1,2,3>>>}5,6]
Таким образом, можно получить не только код ошибки, читабельное сообщение, но и место, где оно произошло. При трассировке используется комбинация »>>>».
JSON Объекты
Десериализация JSON-объектов непосредственно в структуры данных — это то, ради чего и разрабатывался wjson. Рассмотрим простую структуру:
struct foo
{
bool flag = false;
int value = 0;
std::string string;
};
Которую нужно сериализовать в JSON типа:
{ "flag":true, "value":42, "string":"Привет Мир!"}
JSON-объект — это просто перечисление списка полей, которые состоят из имени и значения (любой JSON), разделенных двоеточием. Для сериализации отдельного поля нужно скопировать имя, которое известно на этапе компиляции, добавить двоеточие, и сериализовать значение. Эту концепцию реализует конструкция:
template >
struct member;
- N — имя поля
- T — тип структуры
- М — тип поля
- m — указатель на поле структуры
- J — JSON-описание поля
Но явно передавать строки параметрами шаблона проблематично. Поэтому воспользуемся следующим трюком. Для каждого имени поля структуры создадим конструкцию вида:
struct n_flag
{
const char* operator()() const
{
return "flag”;
}
};
Которую мы сможем передавать параметром шаблона. Конечно же, плодить такие структуры для каждого имени не очень удобно, поэтому тот редкий случай, когда я позволил себе макроподстановку. Для этого можно воспользоваться макросом:
JSON_NAME(flag)который создаст примерно такую же структуру. Префикс n_ используются по историческим причинам. Но если он вам не нравится, можно использовать второй вариант:
JSON_NAME2(n_flag, "flag”)который позволяет создать структуру с произвольным именем и строкой. Пример для описания отдельного поля:
wjson::member< n_flag, foo, bool, &foo::flag>Для простых типов JSON-описание (wjson: value<>) можно не передавать, но для всех остальных он требуется. Сама по себе сериализация поля структуры не имеет особого смысла, поэтому нужно объединить описания всех полей в список следующим образом:
wjson::member_list<
wjson::member,
wjson::member,
wjson::member
>
Для C++11 количество полей не ограничено, для c++03 ограничение 26 элементов, которое легко обойти, используя вложенные member_list. Правила сериализации JSON-объекта в структуры дает конструкция:
template
struct object
{
typedef T target;
typedef implementation_defined serializer;
typedef implementation_defined member_list;
};
Здесь T — тип структуры данных, а L — список сериализуемых полей (member_list).
#include
#include
#include
struct foo
{
bool flag = false;
int value = 0;
std::string string;
};
JSON_NAME(flag)
JSON_NAME(value)
JSON_NAME(string)
typedef wjson::object<
foo,
wjson::member_list<
wjson::member,
wjson::member,
wjson::member
>
> foo_json;
int main()
{
std::string json="{\"flag\":false,\"value\":0,\"string\":\"Привет Мир\"}";
foo f;
foo_json::serializer()( f, json.begin(), json.end(), nullptr );
f.flag = true;
f.string = "Пока Мир";
std::cout << json << std::endl;
foo_json::serializer()( f, std::ostream_iterator(std::cout) );
}
Результат:
{"flag":false,"value":0,"string":"Привет Мир"}
{"flag":true,"value":0,"string":"Пока Мир"}
На что хотелось бы обратить ваше внимание:
- в исходной структуре (foo) нет никакого упоминания о том, что она является персистентной.
- сериализуются поля ровно в том порядке, как они описаны в member_list.
- во входном JSON порядок полей не обязательно должен совпадать с порядком полей, описанном в member_list
- описывать все поля структуры не обязательно. Сериализуются только описанные поля
- все прочие поля из входного JSON игнорируются
- в member_list можно описать поля и базовых классов в произвольном порядке
- наследование поддерживается, в том числе и множественное (имеется в виду не виртуальное наследование структур данных)
Если во входном JSON порядок полей совпадает с порядком в JSON-описании, то десериализация происходит максимально быстро, по сути, за один проход. Пропуски полей или лишние элементы на производительность не сильно влияют (они просто игнорируются).
Но что будет, если поля в JSON пришли в произвольном порядке? Разумеется, это сказывается на производительности, потому что парсер сбивается и начинает перебор полей сначала. Но я рекомендую вообще не заморачиваться темой порядка полей.
Еще до того момента, когда это начнет реально ощущаться, вы столкнетесь с проблемой не времени десериализации, а избыточности JSON, и нужно будет думать о смене формата обмена данными. Это не обязательно означает переход на бинарные протоколы. Можно, например, передавать объекты в виде JSON-массивов, в котором позиция жестко соответствует некоторому полю структуры. В частных случаях, когда передается много нулей, такой формат может быть и компактнее, и быстрее protobuf.
Чтобы не быть голословным, я прогнал на производительность десериализацию следующей структуры:
struct foo
{
int field1 = 0;
int field2 = 0;
int field3 = 0;
std::vector field5;
};
JSON_NAME(field1)
JSON_NAME(field2)
JSON_NAME(field3)
JSON_NAME(field5)
typedef wjson::object<
foo,
wjson::member_list<
wjson::member,
wjson::member,
wjson::member,
wjson::member, &foo::field5, ::wjson::array< std::vector< ::wjson::value > > >
>
> foo_json;
С прямой и обратной (самой неудачной) последовательностями полей во входном JSON. Но потом заметил, что имена полей подобраны не совсем честно, т.к. совпадают за исключением последнего символа, поэтому также сделал замер для варианта:
JSON_NAME2(n_field1, "1field")
JSON_NAME2(n_field2, "2field")
JSON_NAME2(n_field3, "3field")
JSON_NAME2(n_field5, "5field")
когда все поля различаются первым символом. В итоге для JSON:
{"field1":12345,"field2":23456,"field3":34567,"field5":[45678,56789,67890,78901,89012]}
{"5field":[45678,56789,67890,78901,89012],"1field":12345,"2field":23456,"3field":34567}
{"field5":[45678,56789,67890,78901,89012],"field1":12345,"field2":23456,"field3":34567}
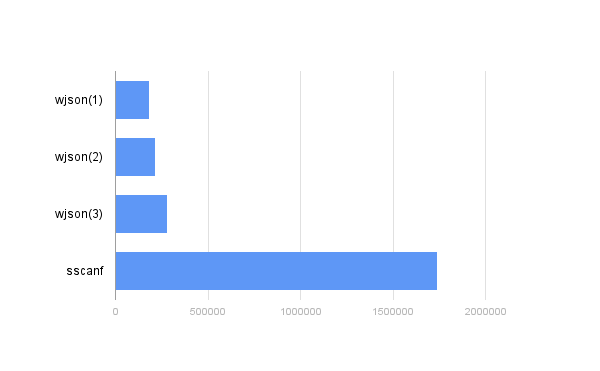
Получил следующие результаты:
- Время сериализации: 151321 ns (6608468 persec), сейчас не важно
- Десериализация для «оптимального» JSON: 204113 ns (4899246 persec)
- «Худший» порядок полей с оптимальными именами: 221140 ns (4522022 persec)
- «Худший» порядок полей с «плохими» именами: 237616 ns (4208470 persec)
Для наглядности и чтобы закрыть тему sprintf/sscanf, поднятой в начале статьи, я также замерил время выполнения такой конструкции:
sscanf( str, "{\"field1\":%d,\"field2\":%d,\"field3\":%d,\"field5\":[%d,%d,%d,%d,%d]}",
&(f.field1), &(f.field2), &(f.field3), &(f.field5[0]), &(f.field5[1]), &(f.field5[2]),&(f.field5[3]), &(f.field5[4]) );
Понятно, что здесь и речи не может быть о полноценной десериализации — любое несоответствие паттерну может привести к плачевным результатам. Тем не менее, результат 2477942 ns (403560 persec), что в десять раз хуже, чем у wjson со всеми проверками, с «плохим» порядком и «не удачными» именами полей:
Для тех, кто не поверил своим глазам, и хочет проверить эти цифры (что похвально), не дочитав статьи (а это мне сложно приветствовать), сразу предупрежу, что это работает толь
