5 полезных библиотек Python (с примерами)
Python остается топ 1 среди языков программирования по версии многих журналов и сайтов. Популярность языка и его большое сообщество привело к тому, что сейчас для Python существует огромное число библиотек. К сожалению, большая часть этих библиотек была создана энтузиастами и больше не поддерживается. Давайте посмотрим на 5 хороших развивающихся библиотек, которые могут помочь при решении практических задач.
Funcy ⭐3000
Funcy содержит более 100 полезных методов и декораторов, собранных в одной библиотеке. Если вам важна чистота кода, и читать строки вида: a, b, dummy, _ = map(lambda x: x[1], sorted((query(*[x for x in candidates if x != candidates[j]]), candidates[j]) for j in range(4)))не радует глаз, то эта библиотека поможет вам сделать свой код проще и читабельнее без потери функциональности и без потери скорости.
Для строк есть пару функций, однако мне понравилась одна, где не надо писать лишний код приведения типов, одна функция делает всё за нас:
# funcy
result = str_join(sep=":", seq=data)
# Python
result = ",".join(map(str, data))Для работы со словарями тоже нашлось несколько полезных функций:
# слияние словарей по определенному правилу
merge_with(list, {"key1": "val"}, {"key1": 1, "key2": "val2"})
# -> {'key1': ['val', 1], 'key2': ['val2']}
f_test = lambda data: str_join(sep="", seq=data)
merge_with(f_test, {"key1": "val"}, {"key1": 1, "key2": "val2"})
# -> {'key1': 'val1', 'key2': 'val2'}
merge_with(sum, {1: 1}, {1: 10, 2: 2})
# -> {1: 11, 2: 2}
merge_with(sum, {1: 1, 3: 2, 2:10}, {1: 10, 2: 2})
# -> {1: 11, 3: 2, 2: 12}
# оставить только те ключи в словаре, которых нет в переданном итерируем объекте
omit({'a': 1, 'b': 2, 'c': 3}, 'ac')
# -> {'b': 2}
# возвращает значение в конце пути, которое указывается для поиска
# (может очень сильно помочь при парсинге json)
get_in({"a": {"b": 42}}, ["a", "b"], "не нашлось ключа")
# -> 42
get_in({"a": {"b": 42}}, ["a", "c"], "не нашлось ключа")
# -> не нашлось ключа
# применяет функцию только к ключам
walk_keys(str.upper, {'a': 1, 'b': 2, 'C': 0})
# -> {'A': 1, 'B': 2, 'C': 0}
# аналогично можно применять и для списков
walk(inc, {1, 2, 3})
# -> {2, 3, 4}Так же есть еще много интересных функций и декораторов, например:
@cache (timeout, key_func=None) — кеширует значение функции на определенное время;
@cached_readonly — кеширует значение функции, которая доступна только для чтения;
group_by (f, seq) — разбивает последовательность по определенному правилу;
where (mappings, **cond) — ищет в списке те словари, которые попадают под заданные правила и еще много других полезных функций.
Да, можно заметить, что какие-функции уже есть в питоне во встроенных либах, а какие-то функции пишутся в 3–4 строки кода. Но преимущество этой библиотеки как раз таки в том, что все эти функции уже реализованы в одном месте и их вызов прост и понятен.
JsonObject ⭐224
JsonObject — удобная библиотека для быстрого преобразования json в объекты Python. Крайне удобно, когда необходимо принимать данные по API и парсить их в определенные структуры. Вот парочка примеров работы с библиотекой:
from jsonobject import *
from datetime import datetime as dt
import json
# собственный класс User
class User(JsonObject):
username = StringProperty()
name = StringProperty()
# default - задает значение по умолчанию, если в json не было такого поля
active = BooleanProperty(default=False)
date_joined = DateTimeProperty()
tags = ListProperty()
user = User(username='Daniil123',
name='Daniil',
date_joined=dt.now(),
tags=['new', 'user', 'python'],
active=True)
# преобразовать класс в json
data = user.to_json()
print(data)
# -> {'username': 'Daniil123', 'name': 'Daniil',
# 'date_joined': '2023-03-12T14:07:02Z',
# 'tags': ['new', 'user', 'python'], 'active': True}
# загрузка обратно из json
user2 = User(data)
# или более наглядно
user3 = User({
'name': 'Daniil',
'username': 'Daniil123',
'active': False,
'date_joined': '2023-03-05T02:46:58Z',
'tags': ['new', 'user', 'python']
})
# читаем из файла
open('data.json', 'r', encoding='utf-8') as f:
dict_data = json.loads(f.read())
user4 = User(dict_data)Можно делать вложенные объекты друг в друга:
class NameUser(JsonObject):
username = StringProperty()
name = StringProperty()
class User(JsonObject):
name_info = ObjectProperty(NameUser)
active = BooleanProperty(default=False)
date_joined = DateTimeProperty()
tags = ListProperty()
user = User({
'name': 'Daniil',
'username': 'Daniil123',
'active': False,
'date_joined': '2023-03-05T02:46:58Z',
'tags': ['new', 'user', 'python']
})
print(user.name_info.name)
# -> DaniilЭта библиотека способна сэкономить кучу времени при работе со сторонними API, либо просто при работе с JSON данными, если требуется парсить JSON и обрабатывать его поля.
Pdir2 ⭐1300
Pdir2 — отличная библиотека для замены работы со стандартным dir (). Основные преимущества этой библиотеки:
Атрибуты сгруппированы по типам/функциям с выделением цветом;
Поддержка настройки цветовой схемы;
Поддержка всех платформ, включая Windows;
Поддержка ipython, ptpython, bpython и Jupyter Notebook;
Возможность искать определенные имена с помощью .s () или .search ();
И много других полезных функций.
Посмотрим, что умеет эта библиотека:
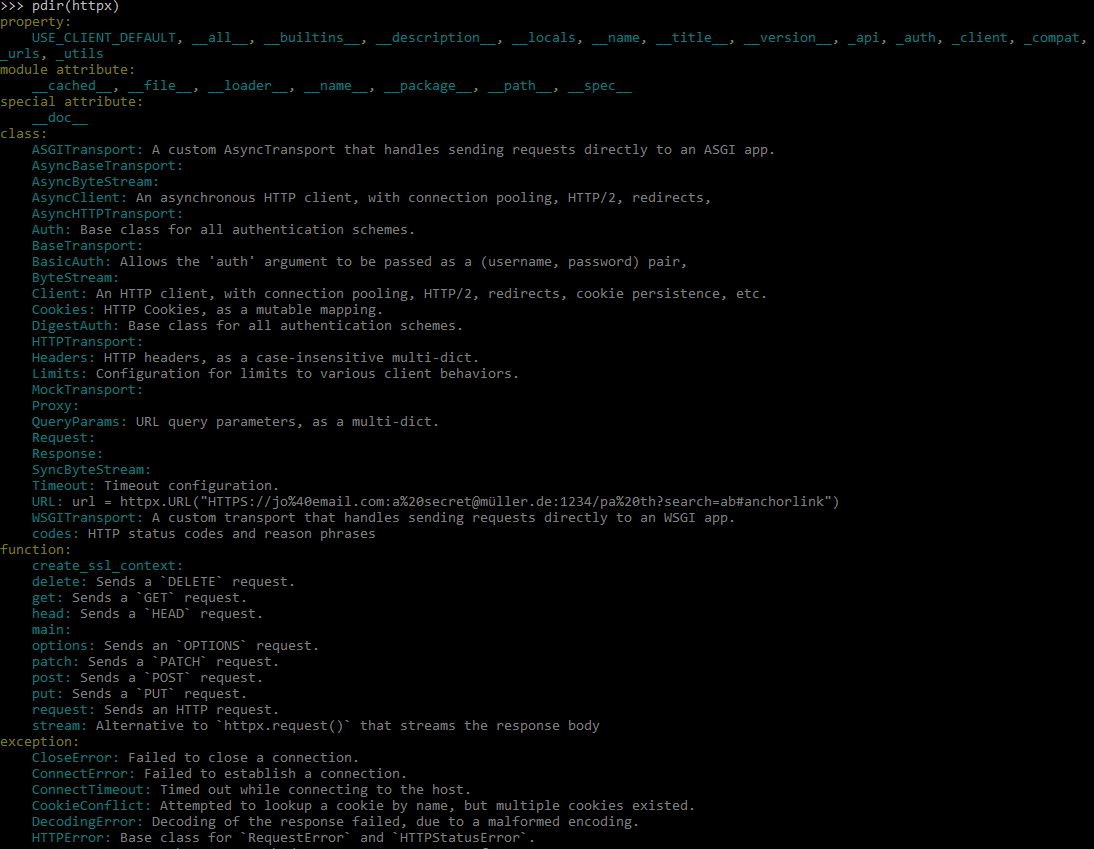
Pdir2 — пример 1
В каждом модуле вы можете спокойно искать интересующие вас методы или свойства по частичному названию:
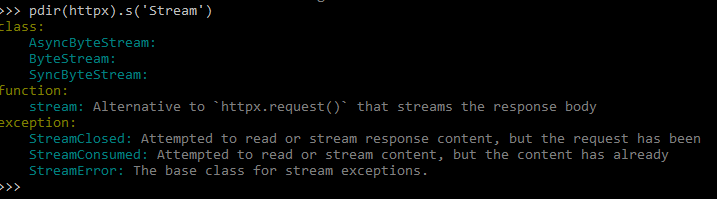
Pdir2 — пример 2
Так же посмотрим, как эта библиотека работает с класса (иногда хочется посмотреть, какие есть поля у сторонних классов, а в код напрямую не всегда удобно лезть):
# создаем собственный класс
class User:
def __init__(self):
self.name = ""
def get_name(self):
return self.name
user = User()
pdir(user)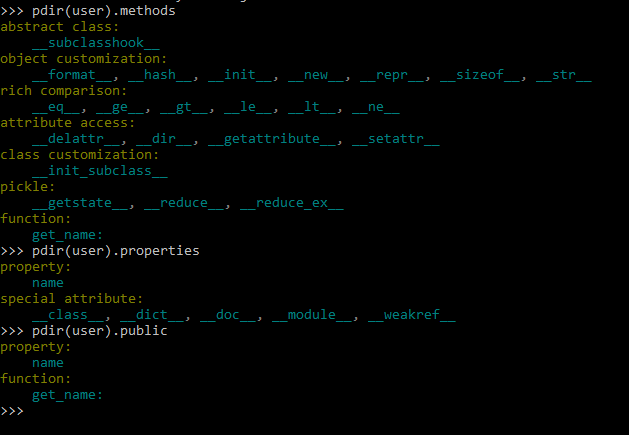
Pdir2 — пример 3
В целом библиотека очень удобна, если вам необходимо заглянуть внутрь какого-либо модуля или класса и при этом нет желания или возможность копаться в тоннах чужого кода.
Networkx ⭐12000
NetworkX — это очень большая и удобная библиотека для Python с множеством встроенных функций для работы с графами и их выводом.
Так всего в несколько строк кода можно создать полноценный граф и решить в нем задачу поиска оптимального пути:
import networkx as nx
# создаем граф
G = nx.Graph()
# заполняем ребра графа
G.add_edge("A", "B", weight=4)
G.add_edge("B", "D", weight=2)
G.add_edge("A", "C", weight=3)
G.add_edge("C", "D", weight=4)
# ищем кратчайший путь A->D
p = nx.shortest_path(G, "A", "D", weight="weight")
# -> ["A", "B", "D"]А вот, например, самая стандартная задача, когда вам нужно найти оптимальные пути между двумя точками, но с учетом того, что каждое ребро графа может иметь несколько свойств:
import networkx as nx
# создаем граф
G = nx.Graph()
# доабвляем пути
G.add_edge("Moscow", "Krasnodar", length=1000, price=150)
G.add_edge("Krasnodar", "Sochi", length=300, price=50)
G.add_edge("Moscow", "Rostov-na-Dony", length=900, price=120)
G.add_edge("Rostov-na-Dony", "Sochi", length=500, price=70)
# ищем кратчайший путь по свойству length (длина пути)
p = nx.shortest_path(G, "Moscow", "Sochi", weight="length")
# -> ['Moscow', 'Krasnodar', 'Sochi']
# ищем кратчайший путь по свойству price (стоимость поездки)
p = nx.shortest_path(G, "Moscow", "Sochi", weight="price")
# -> ['Moscow', 'Rostov-na-Dony', 'Sochi']Как создать граф, так и отрисовать его не составит особого труда:
import matplotlib.pyplot as plt
# G - граф из примера выше с городами
nx.draw_networkx(G, pos=nx.spiral_layout(G), node_color='r', edge_color='b')
plt.show()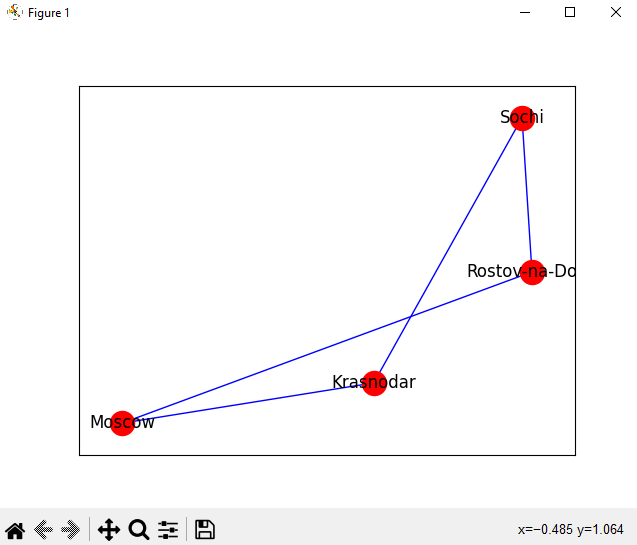
Вывод графа
Графы можно загружать и экспортировать в форматах:
Доступно более 60 алгоритмов работы с графом. Среди них: определение двудольности графа, поиск расстояния редактирования графа, определение является ли граф деревом или нет, поиск мостов в графе и тд.
Библиотека отлично подойдет как для упрощения работы с небольшими данными, так и для серьезных проектов, так как библиотеку постоянно расширяют и занимаются поддержкой уже больше 12 лет.
You-get ⭐46000
You-get — удобный инструмент для скачивания видео, фото и аудио- файлов с большинства популярных платформ. Среди крупнейших платформ есть:
YouTube;
VK;
Vimeo;
SoundCloud;
TED;
Pinterest;
Twitter
и еще 60.
Достаточно просто установить библиотеку: pip install you-get. Далее в командной строке выполнить код:
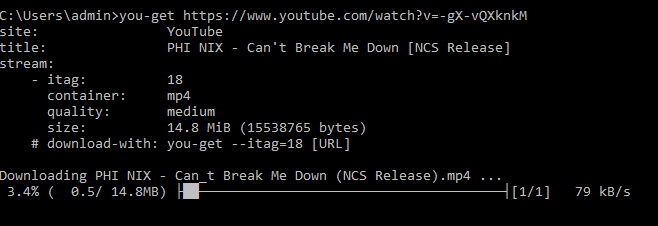
Скачивание you-get
Так же для скачивания с некоторых сайтов есть возможность использовать proxy. А узнать подробную информацию о файле для скачивания можно командой:
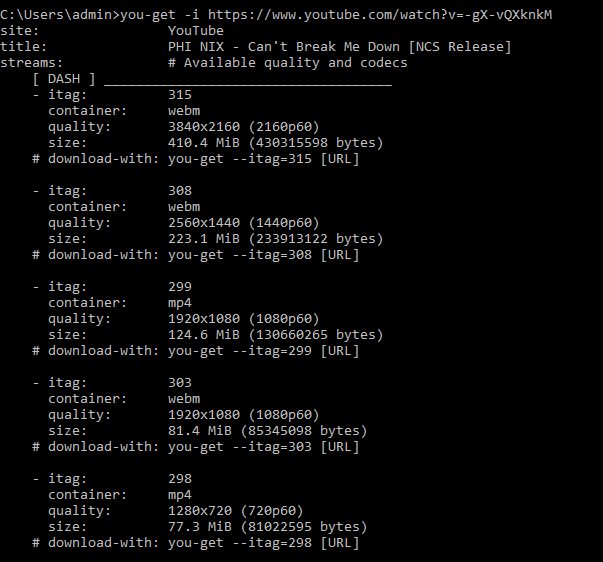
Информация о файле you-get
С полным описанием всех типов файлов и сайтов можно ознакомиться на сайте. Данные библиотека будет большим плюсом для тех, кто пишет свои проекты (сайты, телеграм/вк ботов, десктопные приложения), работающие поверх этих самых популярных платформ.
Заключение
Сообщество Python растёт и появляется всё больше и больше крутых библиотек. Делитесь друг с другом полезными материалами и ссылками, чтобы все эти библиотеки не замораживались, а постоянно развивались и улучшались.
