3D Говорящие Головы. Третий проект центра разработки Intel в России

Согласно известной шутке все мемуары в книжных магазинах должны располагаться в разделе «Фантастика». Но в моём случае это и правда так! Давным-давно в далёкой-далёкой галактике в российском центре разработки Intel мне довелось участвовать в реально фантастическом проекте. Проекте настолько удивительном, что я хочу воспользоваться своим служебным положением редактора блога Intel в личных целях, и в рамках цикла »20 лет — 20 проектов» рассказать про эту работу.
3D Talking Heads (Трехмерные Говорящие Головы) — это показывающий язык и подмигивающий бронзовый бюст Макса Планка; обезьянка, в реальном времени копирующая вашу мимику; это 3D модель вполне узнаваемой головы вице-президента Intel, созданная полностью автоматически по видео с его участием, и еще много всего… Но обо всём по порядку.
Синтетическое видео: MPEG-4 совместимые 3D Говорящие Головы — полное название проекта, осуществленного в Нижегородском Центре Исследований и Разработки Intel в 2000–2003 годах. Разработка представляла собой набор трёх основных технологий, которые можно использовать как совместно, так и по отдельности во многих приложениях, связанных с созданием и анимацией синтетических трехмерных говорящих персонажей.
- Автоматическое распознавание и слежение за мимикой и движениями головы человека на видео последовательности. При этом оцениваются не только углы поворота и наклона головы во всех плоскостях, но и внешние и внутренние контуры губ и зубов при разговоре, положение бровей, степень прикрытия глаз и даже направление взгляда.
- Автоматическая анимация в реальном времени практически произвольных трехмерных моделей голов в соответствии c параметрами анимации, полученными как при помощи алгоритмов распознавания и трекинга из первого пункта так из любых других источников.
- Автоматическое создание фотореалистичной 3D модели головы конкретного человека с использованием либо двух фотографий прототипа (вид спереди и сбоку), либо видео последовательности, на которой человек поворачивает голову от одного плеча к другому.
И еще бонусом — технологии, а, точнее, некоторые хитрости реалистичного рендеринга «говорящих голов» в реальном времени с учетом существовавших в начале 2000-х ограничений производительности железа и возможностей софта.
А связующим звеном между этими тремя с половиной пунктами, а также привязкой к Intel служат четыре буквы и одна цифра: MPEG-4.
MPEG-4
Немногие знают, что появившийся в 1998 году стандарт MPEG-4 помимо кодирования обычных, реальных видео и аудио потоков предусматривает кодирование информации о синтетических объектах и их анимации — так называемое синтетическое видео. Одним из таких объектов и является человеческое лицо, точнее — голова, заданная в виде триангулированной поверхности — сетки в 3D пространстве. MPEG-4 определяет на лице человека 84 особые точки — Feature Points (FP): уголки и середины губ, глаз, бровей, кончик носа и т.д.
К этим особым точкам (или ко всей модели в целом в случае поворотов и наклонов) и применяются анимационные параметры — Facial Animation Parameters (FAP), описывающие изменение положения и выражения лица по сравнению с нейтральным состоянием.
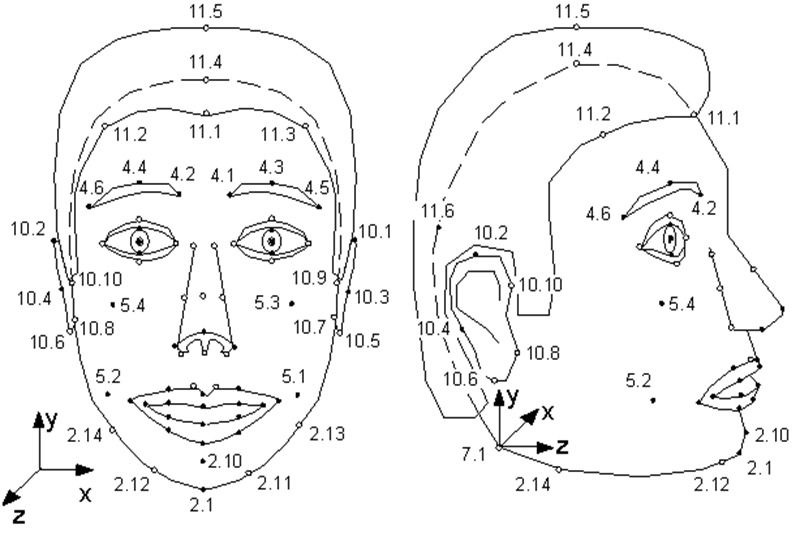
Иллюстрация из спецификации MPEG-4. Особые точки модели. Как видите, модель может шмыгать носом и шевелить ушами.
То есть, описание каждого кадра синтетического видео, показывающего говорящего персонажа, выглядит как небольшой набор параметров, по которым MPEG-4 декодер должен анимировать модель.
Какую модель? В MPEG-4 есть два варианта. Либо модель создается энкодером и передается декодеру один раз в начале последовательности, либо у декодера есть своя, проприетарная модель, которая и используется в анимации.
При этом, единственные требования MPEG-4 к модели: хранение в VRML-формате и наличие особых точек. То есть, моделью может служить как фотореалистичная копия человека, чьи FAP используются для анимации, так и модель любого другого человека, и даже говорящий чайник — главное, чтобы у него, помимо носика, были рот и глаза.

Одна из наших MPEG-4 совместимых моделей — самая улыбчивая
Помимо основного объекта «лицо», MPEG-4 описывает независимые объекты «верхняя челюсть», «нижняя челюсть», «язык», «глаза», на которых также задаются особые точки. Но если у какой-то модели этих объектов нет, то соответствующие им FAP просто не используются декодером.

— Модель, модель, а почему у тебя такие большие глаза и зубы? — Чтобы лучше себя анимировать!
Откуда берутся персонализированные модели для анимации? Как получить FAP? И, наконец, как осуществить реалистичную анимацию и визуализацию на основе этих FAP? На все эти вопросы MPEG-4 не даёт никаких ответов — так же, как и любой стандарт сжатия видео ничего не говорит о процессе съёмки и содержании кодируемых им фильмов.
До чего дошел прогресс? До невиданных чудес!
Конечно же, и модель и анимацию могут создать вручную профессиональные художники, потратив на это десятки часов и получив десятки сотен долларов. Но это значительно сужает область использования технологии, делает её неприменимой в промышленных масштабах. А потенциальных применений у технологии, фактически сжимающей кадры видео высокого разрешения до нескольких байт (ох, жаль, что не любого видео) существует масса. Прежде всего, сетевых — игры, образование и общение (видеоконференции) при помощи синтетических персонажей.
Особенно актуальны подобные применения были 20 лет тому назад, когда в интернет еще выходили с помощью модемов, а гигабитный безлимитный интернет казался чем-то вроде телепортации. Но, как показывает жизнь, и в 2020 году пропускная способность интернет-каналов во многих случаях всё еще остается проблемой. И даже если такой проблемы нет, скажем, речь идет о локальном использовании, синтетические персонажи способны на многое. Скажем, «воскресить» в фильме знаменитого актёра прошлого века, или дать возможность посмотреть в глаза популярным сейчас и до сих пор бесплотным голосовым помощникам. Но сначала процесс перехода от реального видео говорящего человека к синтетическому должен стать автоматическим, или хотя бы, обходиться минимальным участием человека.
Именно это и было реализовано в нижегородском Intel. Идея возникла сперва как часть реализации библиотеки MPEG Processing Library, разрабатываемой в свое время в Intel, а потом выросла не просто в полноценный spin-off, а в настоящий фантастический блокбастер.
Это был наш инициативный проект, у которого, кажется, единственного за все время существования российского Intel не было куратора в Intel США. Джастину Ратнеру (главе исследовательского подразделения Intel Labs) во время его визита в Нижний Новгород идея проекта понравилась, и он дал добро на все работы.

Синтетический Валерий Федорович Курякин, продюсер, режиссер-постановщик, автор сценария, а местами и каскадёр проекта — в то время руководитель группы разработчиков Intel.
Во-первых, фантастической была комбинация столь разных технологий в рамках одного небольшого проекта, над которым одновременно работало всего лишь от трёх до семи человек. В те годы в мире уже существовал как минимум, десяток компаний, занимавшихся как распознаванием и слежением за лицом, так и созданием и анимацией «говорящих голов». У всех них, безусловно, были достижения в некоторых областях: у кого-то отличного качества модели, кто-то показывал очень реалистичную анимацию, кто-то достиг успехов в распознавании и слежении. Но ни одна компания не смогла предложить весь набор технологий, позволяющий полностью автоматически создать синтетическое видео, на котором модель, очень похожая на свой прототип, хорошо копирует его мимику и движения.

Конвейер проекта по производству синтетических клонов образца 2003 года
Во-вторых, фантастическим было сочетание существовавшего в то время железа и реализованных в проекте технологических решений, а также планов по их использованию. Так, на момент начала проекта в моем кармане лежала Нокия 3310, на рабочем столе стоял Pentium III-500MHz, а особо критичные к производительности алгоритмы для работы в реальном времени тестировались на сервере Pentium 4–1.7GHz со 128 Mb оперативной памяти.
При этом мы рассчитывали на то, что в скором времени наши модели будут работать в мобильных устройствах, а качество будет не хуже, чем у героев вышедшего на экраны в то время (2001 год) фотореалистичного компьютерного анимационного фильма «Последняя Фантазия»

$137 миллионов составили затраты на фильм, созданный на рендер-ферме из ~1000 компьютеров Pentium III. Постер с сайта www.thefinalfantasy.com
Но давайте посмотрим, что же получилось у нас.
Распознавание и отслеживание лица, получение FAP.
Эта технология была представлена в двух вариантах:
- режим реального времени (25 кадров в секунду на уже упомянутом процессоре Pentium 4–1.7GHz), когда отслеживается человек, непосредственно стоящий перед видеокамерой, соединенной с компьютером;
- оффлайн режим (со скоростью 1 кадр в секунду на том же компьютере), когда распознавание и трекинг происходят по предварительно записанному видеофрагменту.
При этом, в реальном времени отслеживалась динамика изменения положения/состояния человеческого лица — мы могли приблизительно оценить углы поворота и наклона головы во всех плоскостях, примерную степень открывания и растяжения рта и поднятия бровей, распознать моргание. Для некоторых приложений такой приблизительной оценки достаточно, но, если нужно точно отследить мимику человека, то необходимы более сложные алгоритмы, а значит, более медленные.
В режиме оффлайн наша технология позволяла оценить не только положение головы в целом, но абсолютно точно распознать и отследить внешние и внутренние контуры губ и зубов при разговоре, положение бровей, степень прикрытия глаз, и даже смещение зрачков — направление взгляда.
Для распознавания и слежения была использована комбинация общеизвестных алгоритмов компьютерного зрения, часть из которых к тому моменту была уже реализована в только что выпущенной библиотеке OpenCV –- например, Optical Flow, а также собственных оригинальных методов, основанных на априорных знаниях о форме соответствующих объектов. В частности — на нашей усовершенствованной версии метода деформируемых темплейтов, на которую участники проекта получили патент.
Технология была реализована в виде библиотеки функций, принимавших на вход видеокадры с лицом человека, и выдающих соответствующие этим кадрам FAP.
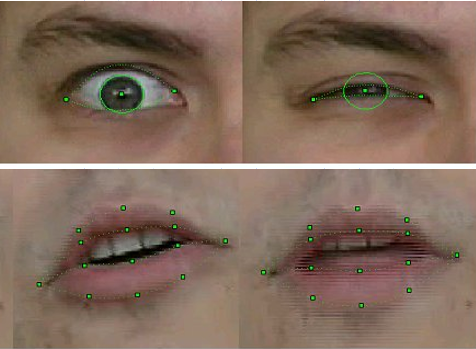
Качество распознавания и отслеживания FP образца 2003 года
Конечно, технология была несовершенна. Распознавание и отслеживание сбоили, если у человека в кадре были усы, очки или глубокие морщины. Но за три года работы качество значительно повысилось. Если в первых версиях для распознавания движения моделям при съемках видео приходилось наклеивать на соответствующие FP точки лица особые метки — белые бумажные кружки, полученные при помощи офисного дырокола, то в финале проекта ничего подобного, конечно же не требовалось. Более того, нам удалось достаточно устойчиво отслеживать положение зубов и направление взгляда — и это на разрешении видео с вебкамер того времени, где такие детали были едва различимы!

Это не ветрянка, а кадры из «детства» технологии распознавания. Intel Principle Engineer, а в то время — начинающий сотрудник Intel Александр Бовырин учит синтетическую модель читать стихи
Анимация
Как уже было неоднократно сказано, анимация модели в MPEG-4 полностью определяется FAP. И всё было бы просто, если бы не пара проблем.
Во-первых, тот факт, что FAP из видео последовательности извлекаются в 2D, а модель — трёхмерная, и требуется как-то достраивать третью координату. То есть, радушная улыбка в профиль (а у пользователей должна быть возможность этот профиль увидеть, иначе смысла в 3D немного) не должна превращаться в зловещую ухмылку.
Во-вторых, как тоже было сказано, FAP описывают движение особых точек, которых в модели около восьмидесяти, в то время как хоть сколько-нибудь реалистичная модель в целом состоит из нескольких тысяч вершин (в нашем случае — от четырех до восьми тысяч), и нужны алгоритмы, вычисляющие смещение всех остальных точек модели на основе смещений FP.
То есть, понятно, что при повороте головы на равный угол повернутся все точки, но при улыбке, даже если она до ушей, «возмущение» от сдвига уголка рта должно, постепенно затухая, двигать щеку, но не уши. Более того, это должно происходить автоматически и реалистично для любых моделей с любой шириной рта и геометрией сетки вокруг него. Для решения этих задач в проекте были созданы алгоритмы анимации. Они основывались на псевдомускульной модели, упрощенно описывающей мышцы, управляющие мимикой лица.
А далее для каждой модели и каждого FAP предварительно автоматически определялась «зона влияния» — вовлеченные в соответствующее действие вершины, движения которых и рассчитывались с учётом анатомии и геометрии — сохранения гладкости и связности поверхности. То есть, анимация состояла из двух частей — предварительной, выполняемой оффлайн, где создавались и заносились в таблицу определённые коэффициенты для вершин сетки, и онлайн, где с учетом данных из таблицы анимация в реальном времени применялась к модели.

Улыбка — непростое дело для 3D модели и её создателей
Создание 3D модели конкретного человека.
В общем случае задача реконструкции трёхмерного объекта по его двумерным изображениям — очень сложна. То есть, алгоритмы её решения человечеству давно известны, но на практике из за многих факторов получаемый результат далек от желаемого. И особенно это заметно в случае реконструкции формы лица человека — здесь можно вспомнить наши первые модели с глазами в форме восьмёрки (неудачно легла тень от ресниц на исходных фото) или лёгким раздвоением носа (причину за давностью лет уже не восстановить).
Но в случае MPEG-4 говорящих голов задача сильно упрощается, ведь набор черт человеческого лица (нос, рот, глаза, и т.д.) одинаков для всех людей, а внешние различия, по которым мы все (и программы компьютерного зрения) отличаем людей друг от друга «геометрические» — размеры\пропорции и расположение этих черт и «фактурные» — цвета и рельеф. Поэтому один из профилей синтетического видео MPEG-4, калибровочный (calibration), который и был реализован в проекте, предполагает, что у декодера имеется обобщенная модель «абстрактного человека», которая персонализируется под конкретного человека по фото или видео-последовательности.
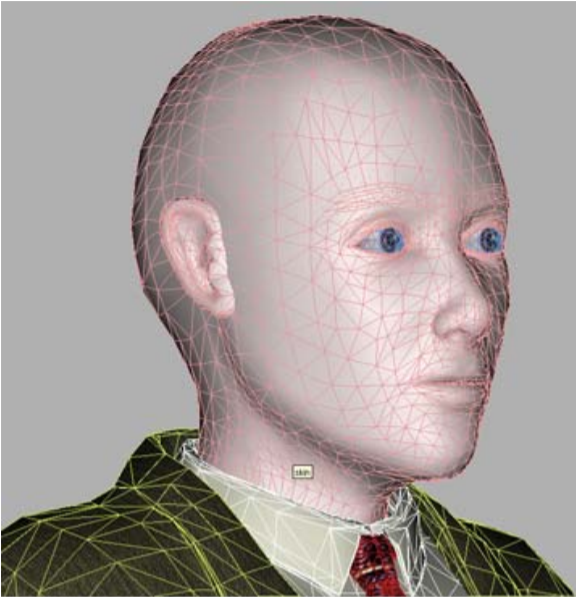
Наш «сферический человек в вакууме» — модель для персонализации
То есть, происходят глобальная и локальная деформации 3D сетки для соответствия пропорциям черт лица прототипа, выделенным на его фото\видео, после чего на модель накладывается «фактура» прототипа — то есть, текстура, созданная из тех же входных изображений. В результате и получается синтетическая модель. Делается это один раз для каждой модели, конечно же, оффлайн, и конечно же, не так просто.
Прежде всего, требуется регистрация или ректификация входных изображений — приведение их к одной системе координат, совпадающей с системой координат 3D модели. Далее на входных изображениях необходимо детектировать особые точки, и на основе их расположения деформировать 3D модель, например, при помощи метода радиальных базисных функций, после чего, используя алгоритмы сшивки панорам, сгенерировать текстуру из двух или нескольких входных изображений, то есть, «смешать» их в правильной пропорции для получения максимальной визуальной информации, а также компенсировать разницу в освещении и тоне, всегда присутствующую даже в фото, сделанных с одинаковыми настройками камеры (что далеко не всегда так), и очень заметную при совмещении этих фото.

Это — не кадр из фильмов ужасов, а текстура 3D-модели Pat Gelsinger, созданной с его разрешения при демонстрации проекта на Intel Developer Forum в 2003 году
Первоначальная версия технологий персонализации модели по двум фото была реализована самими участниками проекта в Intel. Но по достижении определённого уровня качества и осознании ограниченности своих возможностей, было решено передать эту часть работы исследовательской группе Московского Государственного Университета, имевшей опыт в данной области. Результатом работы исследователей из МГУ под руководством Дениса Иванова стало приложение «Head Calibration Environment», выполнявшее все вышеописанные операции по созданию персонализированной модели человека по его фото в анфас и профиль.
Единственный тонкий момент — приложение не было интегрировано с описанным выше разработанным в нашем проекте блоком распознавания лица, так что необходимые для работы алгоритмов особые точки на фото требовалось отмечать вручную. Конечно, не все 84, а только основные, а с учётом того, что у приложения имелся соответствующий пользовательский интерфейс, на эту операцию требовалось всего несколько секунд.
Также была реализована полностью автоматическая версия реконструкции модели по видео последовательности, на которой человек поворачивает голову от одного плеча к другому. Но, как нетрудно догадаться, качество текстуры, извлеченной из видео было значительно хуже, чем у текстуры, созданной с фотографий цифровых камер того времени с разрешением ~4K (3–5 мегапикселей), а значит, менее привлекательно выглядела и полученная модель. Поэтому существовал и промежуточный вариант с использованием нескольких фото разного угла поворота головы.

Верхний ряд — виртуальные люди, нижний — реальные.
Насколько хорошим был достигнутый результат? Качество полученной модели надо оценивать не в статике, а непосредственно на синтетическом видео по сходству с соответствующим видео оригинала. Но термины «похоже и не похоже» — не математические, они зависят от восприятия конкретного человека, и понять, насколько наша синтетическая модель и ее анимация отличаются от прототипа — сложно. Кому-то нравится, кому-то нет. Но итогом трёхлетней работы стало то, что при демонстрации результатов на различных выставках зрителям приходилось пояснять, в каком окне перед ними реальное видео, а в каком — синтетическое.
Визуализация.
Для демонстрации результатов работы всех вышеописанных технологий был создан специальный плеер MPEG-4 синтетического видео. На вход плеер принимал VRML файл с моделью, поток (или файл) с FAP, а также потоки (файлы) с реальным видео и аудио для синхронизированного показа с синтетическим видео с поддержкой режима «картинка в картинке». При демонстрации синтетического видео пользователю давалась возможность приблизить модель, а также посмотреть на неё со всех сторон, просто повернув мышью под произвольным углом.

Хотя плеер и был написан для Windows, но с учетом возможного портирования в будущем на другие OS, в том числе — мобильные. Поэтому в качестве 3D библиотеки была выбрана «классическая» OpenGL 1.1 безо всяких расширений.
При этом плеер не просто показывал модель, но и пытался её улучшить, но только не ретушировать, как это принято сейчас у фотомоделей, а наоборот, сделать как можно реалистичнее. А именно, оставаясь в рамках простейшего освещения Фонга и не имея никаких шейдеров, зато имея строгие требования к производительности, блок визуализации плеера автоматически создавал синтетическим моделям: мимические морщины, ресницы, способные реалистично сужаться и расширяться зрачки; надевал на модели очки подходящего размера;, а также при помощи простейшей трассировки лучей рассчитывал освещение (затенение) языка и зубов при разговоре.
Конечно, сейчас такие методы уже неактуальны, но вспомнить их достаточно интересно. Так, для синтеза мимических морщин, то есть, небольших изгибов рельефа кожи на лице, видимых во время сокращения лицевых мышц, относительно крупные размеры треугольников сетки модели не позволяли создать настоящие складки. Поэтому была применена разновидность технологии наложения рельефа (bump mapping) — normal mapping. Вместо изменений геометрии модели происходило изменение направления нормалей к поверхности в нужных местах, а зависимость диффузной компоненты освещенности в каждой точке от нормали создавала нужный эффект.

Такой он, синтетический реализм.
Но плеером дело не ограничилось. Для удобства использования технологий и передачи их во внешний мир была создана объектная библиотека Intel Facial Animation Library, содержащая функции для анимации (3D трансформации) и визуализации модели, так что любой желающий (и имеющий источник FAP) вызовами нескольких функций — «СоздатьСцену», «СоздатьАктера», «Анимировать» мог оживить и показать свою модель в своем приложении.
Итоги
Что дало участие в этом проекте лично мне? Конечно же, возможность совместной работы с замечательными людьми над интересными технологиями. В проект меня взяли за знание методов и библиотек рендеринга 3D моделей и оптимизации производительности под х86. Но, естественно, ограничиться 3D не удалось, пришлось пойти в другие измерения. Для написания плеера понадобилось разобраться с парсингом VRML (готовых библиотек для этой цели не имелось), освоить нативную работу с потоками в Windows, обеспечив совместную работу нескольких тредов с синхронизацией 25 раз в секунду, не забыв про взаимодействие с пользователем, и даже продумать и реализовать интерфейс. Позже к этому списку добавилось участие в улучшении алгоритмов отслеживания лица. А необходимость постоянно интегрировать и просто сочетать с плеером написанные другими членами команды компоненты, а также представлять проект во внешнем мире значительно прокачала мои навыки коммуникации и координации.
Что дало участие в этом проекте Intel? В результате нашей командой был создан продукт, способный служить хорошим тестом и демонстрацией возможностей платформ и продуктов Intel. Причем, как «железа» — CPU и GPU, так и программного обеспечения — наши головы (и реальные и синтетические) внесли свой вклад в улучшение библиотеки OpenCV.
Кроме этого, можно смело утверждать, что проект оставил видимый след в истории — по итогам работы его участниками были написаны статьи и представлены доклады на профильные конференции по компьютерному зрению и компьютерной графике, российские (GraphiCon), и международные.
А демонстрационные приложения 3D Talking Heads показаны Intel на десятках выставок, форумов и конгрессов по всему мирy.
За прошедшее время технологии, конечно, сильно продвинулись, соответственно, упростив автоматическое создание и анимацию синтетических персонажей. Появились Intel Real Sense камеры с определением глубины, а нейронные сети на основе больших данных научились генерировать реалистичные изображения даже несуществующих людей.
Но, всё же, размещенные в публичном доступе наработки проекта 3D Talking Heads продолжают просматривать до сих пор.
Посмотрите на нашего юного, почти двадцатилетнего, синтетического говорящего MPEG-4 героя и вы:
