[recovery mode] Роботы вместо лучших сотрудников: машинное обучение по ответам экспертов
Один из текущих проектов Devim — разработка сервиса скоринга для микрофинансовой организации (МФО). Проект был выполнен нашей Data Science командой Андреем Давыденко и Дмитрием Гореловым datasanta. Мы рассказываем о том, какие решались задачи, какие факторы принимались во внимание, а также о полученных результатах. В основе предложенного на данный момент решения — подход, при котором автоматическая обработка заявок выполняется с учётом вероятности отказа/одобрения похожих существующих заявок андеррайтерами (экспертами). Такой подход позволил выполнить проект в сжатые сроки и принять во внимание некоторые особенности бизнес-целей. В числе интересных результатов: как оказалось, решения андеррайтеров при выдаче займов могут быть с высокой точностью спрогнозированы статистической моделью (AUC>0.93).
Надеемся, что публикация будет интересна не только специалистам по скорингу, но и всем, кто интересуется машинным обучением и его применением на практике.
Материал подготовлен Data Science командой Devim
Введение
Всё больше компаний хотят заменить сотрудников роботами. Цель — сократить расходы в условиях усиления конкуренции на рынках и роста зарплатных ожиданий сотрудников.
Но реализация алгоритма, лежащего в основе действий робота, — не всегда тривиальная задача. Например, обработка заявки клиента в системе массового обслуживания может включать анализ различных факторов, включая возраст, доход, историю отношений с клиентом, а также информацию о текущей ситуации в компании. При этом требуется учитывать краткосрочные и долгосрочные бизнес-цели. Зачастую, все эти факторы сложно формализовать и даже перечислить. Однако, эксперты, хорошо знающие особенности бизнеса, могут принимать решения достаточно эффективно для обеспечения нужных показателей работы фирмы. Стоимость работы экспертов довольно высока, найти или «вырастить» эксперта в компании — процесс длительный и трудоемкий. Вопрос сводится к тому, как научить робота делать работу эксперта.
Мы рассматриваем подход, основанный на «копировании» действий эксперта. Предполагается, что существует база данных наблюдений с параметрами возможных ситуаций и информацией о действиях экспертов в соответствующих ситуациях. За счет использования модели, обученной по имеющимся данным, становится возможным часть решений принимать в автоматическом режиме, тем самым разгружая или «тиражируя» сотрудников.

Мы разбираем преимущества и недостатки данного подхода и иллюстрируем его на примере нашего опыта реализации автоскоринга для МФО.
Проблемы обучения модели без ответов экспертов
Существует альтернативный подход, когда модель предсказывает не решение эксперта, а какой-либо целевой показатель целевой показатель (целевую переменную). Если речь идёт о выдаче займов, модель может быть обучена с целью предсказания просрочки выплаты по договору. Однако здесь возникает ряд вопросов, которые требуют существенных затрат на их решение. В итоге все равно решение будет носить отчасти субъективный характер.
Во-первых, выбор целевой переменной неочевиден. Для скоринга целевой переменной может быть выбрана просрочка в 15 дней или 30 дней или какое-то другое количество дней. То, как вероятность просрочки преобразовывается в конечное решение об одобрении/отклонении заявки также остаётся вопросом. Данные вопросы необходимо решать на основе соотношения потерь от невозврата и прибыли при возврате, что требует проведения специального исследования для конкретной МФО и сопряжено с существенными временными и денежными затратами. Кроме того, текущие цели компании могут войти в противоречие с целевой переменной: например, запуск рекламной акции с целью увеличения потока клиентов приведет к тому, что решения станут неоптимальными в краткосрочном периоде проведения такой акции.
Во-вторых, данные для обучения, включающие значения целевой переменной модели, могут отсутствовать. Например, при создании нового продукта/открытии филиала в новом городе или стране невозможно сразу получить данные о целевом показателе.
В-третьих, поскольку данные по невозврату кредитов для отклоненных заявок отсутствуют, автоскоринг скорее всего будет выдавать некорректные прогнозы невозврата. Данная проблема известна в литературе как анализ отклоненных заявок или reject inference. Характер зависимостей между целевой переменной и признаками может быть различным для выборок с одобренными и отклоненными заявками. Тогда свойства выборки одобренных заявок будут отличаться от свойств выборки всех заявок, т.н. TTD-выборки (TTD = through-the-door). По этой же причине невозможно оценить качество модели (например, по критерию AUC) применительно к TTD-выборке. Вместе с тем, в конечном счете именно TTD-показатель должен характеризовать работоспособность модели.
Проблема анализа отклоненных заявок описана в литературе (Anderson, 2007); разработаны соответствующие специальные инструменты в составе систем автоскоринга, таких как SAS и Deductor. Но имеющиеся решения всё равно основаны на задании параметров, определяемых субъективно.
Когда модель обучается по ответам экспертов, вышеуказанные вопросы не так критичны, поскольку: 1) целевая переменная определена, 2) данные могут быть получены в необходимом объеме путём опроса экспертов, 3) используется TTD-выборка.
Фазы проекта
Реализация систем интеллектуальной обработки данных включает большое количество взаимосвязанных задач, которые должны решаться в определенном порядке. Для того, чтобы регламентировать процесс выполнения проекта по аналитике данных, многими фирмами используется стандарт CRISP-DM (Cross-Industry Standard Process for Data Mining — межотраслевой стандартный процесс для исследования данных), (Shearer, 2000). Методология CRISP-DM позволяет формализовывать задачи и документировать ход выполнения проекта с целью эффективного использования ресурсов.
Согласно CRISP-DM, проект включает следующие фазы: 
В случае нашего подхода, CRISP-DM также применим. Дальше описываются (упрощённо) задачи, которые мы решали, и как они соотносятся с фазами стандарта.
В целях сокращения публикации и для сохранения коммерческой тайны некоторые детали мы не приводим, фокусируясь на основных результатах проекта.
Автоскоринг
Понимание бизнес-целей
Бэкграунд проекта
Автоматизируется задача отказа/одобрения заявки, поступающей в МФО, на получение кредита с одноразовым погашением. Решение должно быть принято на основе совокупности данных о потенциальном клиенте.
Входная информация:
- Данные анкеты (ФИО, доход, семейное положение и др. информация)
- Сумма кредита
- Информация из бюро кредитных историй (БКИ) «Эквифакс», включая скоринг-балл (продукт «Скоринг МФО 2.0») и информацию по каждому кредитному договору клиента
- Результаты запроса в банк данных исполнительных производств (БД ИП)
Важно, что информация БКИ является платной. Поэтому запрашивать её целесообразно только когда на основе другой информации нельзя вынести решение об одобрении/отказе.
Заявки обрабатываются вручную андеррайтерами на основе совокупности имеющейся информации, включая отчёты БКИ.
Цели и критерии успеха
Модель должна автоматизировать процесс принятия решений и принимать решение вместо андеррайтера.
Выходная информация модели — один из трех вариантов:
- Автоматически одобрить;
- Автоматически отказать;
- Передать на рассмотрение андеррайтеру.
Цель в конечном итоге — сократить расходы на рассмотрение заявок путём автоматической обработки части трафика, при этом не сильно снижая (желательно, не снижая вообще) качество решений по заявкам.
Задачи и критерии успеха:
Задача № 1: Автоотказ по БД ИП
Во многих случаях БД ИП содержит информацию, которой уже достаточно, чтобы отказать в выдаче займа.
Будет считаться успешной модель автоотказа, которая практически безошибочно сможет спрогнозировать отказ для клиента на основе информации БД ИП, данных анкеты и суммы кредита. Такая модель позволит сэкономить ресурсы на запросах в БКИ и ручную обработку трафика.
Задача № 2: Автоодобрение или автоотказ на основе всей информации (включая ответ из БКИ)
Если модель автоотказа по БД ИП не определила автоматический отказ, необходима модель, использующая информацию из БКИ для автоматического принятия решения по заявке.
В этом случае модель будет успешной, если удастся обеспечить достаточно низкий уровень несовпадений решений по модели и решений андррайтеров. Предельно допустимый процент несовпадений требуется установить на основе стресс-тестирования. Найденная модель позволит сэкономить ресурсы на ручную обработку трафика, а также создаст основу для масштабируемых решений (в т.ч. для автоматической выдачи кредитов онлайн).
Сроки проекта были довольно сжатыми (3 месяца), поэтому команда старалась найти наиболее простые решение, которые, тем не менее, приводили бы к приемлемому результату.
Подготовка и изучение данных
Данные по заявкам были собраны за период в полгода. Соответственно, по каждой заявке имелось решение андеррайтера. Процент одобренных заявок (accept rate) довольно низкий — менее 10%. А для заявок, по которым найдены записи в БД ИП, accept rate ещё ниже. При таком accept rate сложно получить надёжную модель для предсказания дефолта в силу описанной ранее проблемы анализа отклоненных заявок (a.k.a. reject inference).
Предсказание решений андеррайтеров — задача более простая, т.к. одобрения/отказы известны для всех заявок (кроме находящихся в рассмотрении).
По части заявок имелась кредитная история (КИ) в формате XML. Каждая КИ была преобразована в набор признаков для конкретной заявки. Мы следовали распространенным рекомендациям по выделению набора признаков для автоскоринга на основе КИ. Очень редко при описании информации по кредитным договорам содержались пропуски данных или ошибки/неточности (например, не было разделителей между рублями и копейками).
Была использована БД ИП: по каждой заявке, например, имеется количество ИП на данного клиента, а также суммарная задолженность в рублях.
По анкетным данным были сгенерированы дополнительные признаки. Например, пол клиента на основе последних букв в отчестве и фамилии.
Числовые характеристики были преобразованы с целью получения симметричных распределений и анализа выбросов. В частности, найдено что методом Бокса-Кокса можно получить близкие к нормальному распределения. Показатели в рублях (типа сумм задолженностей) имеют логнормальное распределение, что упрощает анализ. Выбросы определялись методом Тьюки.
В целом, существенных проблем с качеством данных, которые могли бы повлиять на качество модели, обнаружено не было — данные достаточно полные и корректные.
Моделирование и оценка
Задача № 1
Для реализации автоотказа на основе данных анкеты и БД ИП была применена логистическая регрессия. Решение андеррайтера использовалось в качестве целевой переменной. То есть регрессионная модель в этом случае оценивает вероятность того, что андеррайтер примет решение отказать в выдаче кредита. Если вероятность достаточно высокая, заявка может быть отклонена автоматически.
Преимущества логистической регрессии состоят в простой интерпретации результатов, возможности проверки допущений, прозрачности алгоритма для бизнеса и скорости реализации сервиса автоотказа.
В ходе построения алгоритма автоотказа необходимо решить два основных вопроса: 1) как выбрать признаки, 2) как выбрать пороговое значение вероятности.
Для отбора признаков использовался алгоритм stepwise regression. Этот алгоритм последовательно исключает переменные из модели для того, чтобы найти наилучшую модель путём оптимизации значения информационного критерия.
Характер зависимостей между вероятностью отказа и набором признаков для заявок, где доход указан, и для заявок с нулевым доходом существенно различался. Поэтому в итоге было получено 2 модели логистической регрессии.
Для оценки качества модели и выбора порогового значения вероятности использовались следующие характеристики. Построив последовательность возможных пороговых значений (от 0 до 1 с шагом 0.01), для каждого возможного значения мы определили:
- Какой процент трафика будет автоматически отклоняться моделью автоотказа;
- Сколько одобрений (заявок, которые могли бы одобрить андеррайтеры) будет ошибочно отклоняться моделью автоотказа (в процентах от общего текущего количества одобрений).
Зависимость между этими показателями отображена на графике:
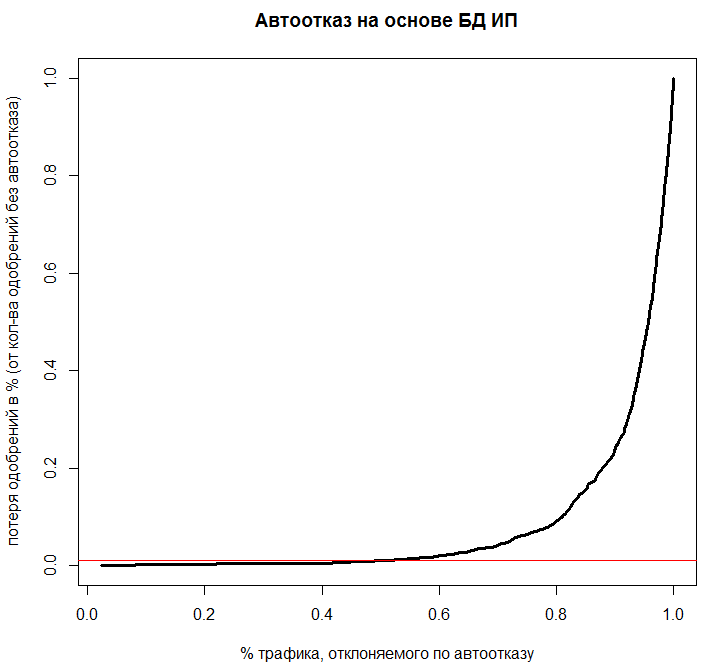
На графике видно, что при отклонении 40% трафика по модели автоотказа ошибочно будет отклоняться не более 1% «хороших» заявок (т.е. таких, которые бы одобрили андеррайтеры). Такой компромисс был оценен как выгодный на основе анализа соотношения цены закупки дополнительных данных для отклоняемых заявок и потерянной выгоды от «хороших» заявок.
Задача № 2
Применялись стандартные методы для задачи автоскоринга. Однако, важное отличие состоит в том, что в качестве целевой переменной использовался бинарный ответ андеррайтера. Признаки включают в себя информацию из БКИ и данные анкеты.
Для предсказания целевой переменной использовался алгоритм Random Forest. За счёт того, что значение целевой переменной известно для всей TTD-выборки, качество модели можно оценить по всем имеющимся наблюдениям. В ходе кросс-валидации получено значение AUC = 0.93, что характеризует высокую точность модели: 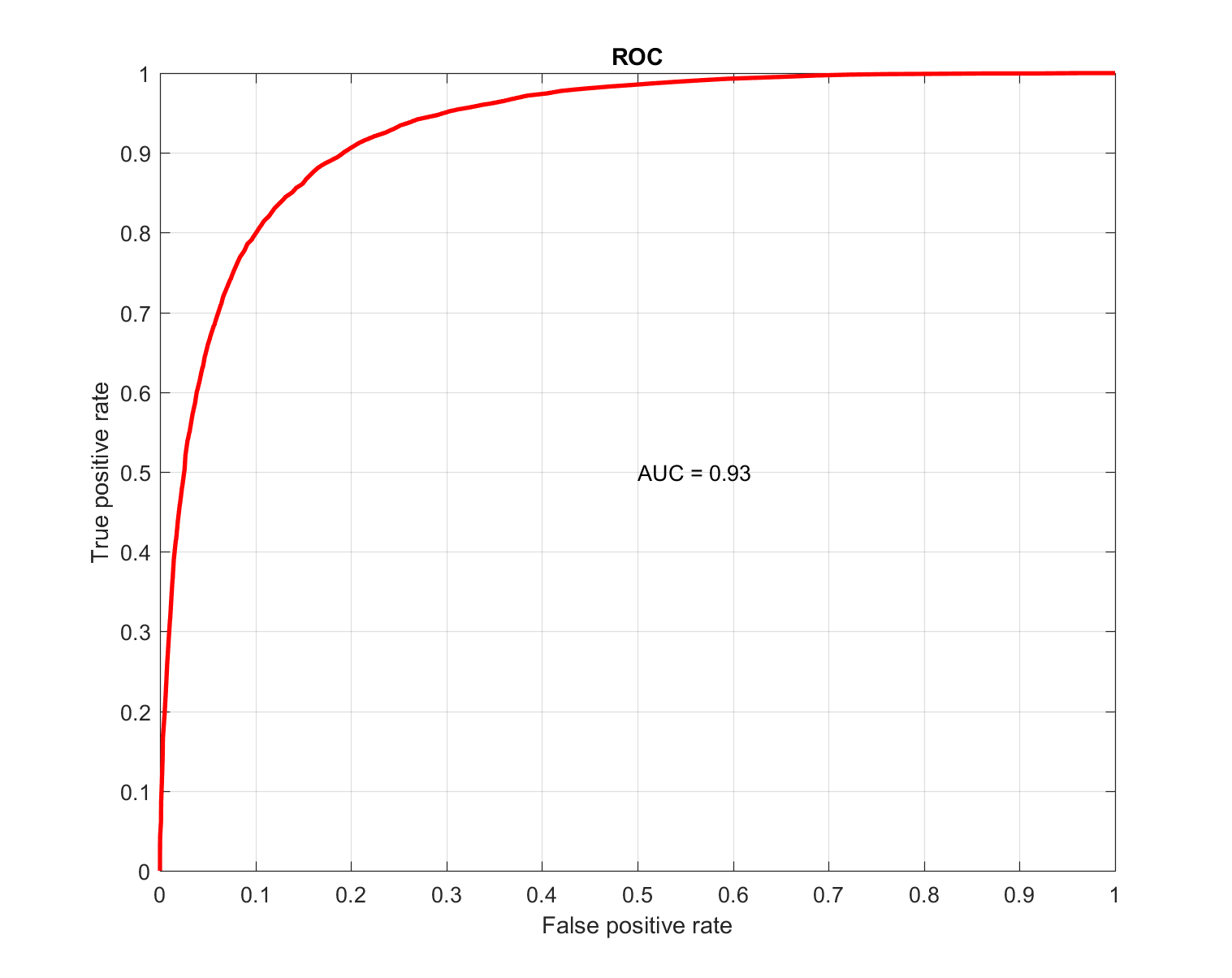
Также по аналогии с задачей была построена зависимость между процентом автоматически обрабатываемого трафика и процентом несоответствий решений модели и андеррайтеров. На тестовой выборке решения андеррайтеров и модели отличались в не более 7–8% случаев. В целом, в ходе стресс-тестов данные показатели оказались приемлемыми для работы модели в автоматическом режиме.
Внедрение и дальнейшие шаги
Чтобы следить за качеством в real-time режиме, используются следующие метрики:
- Specificity (a.k.a. true negative rate) — процент совпадений решений модели с решениями андеррайтера по отказам;
- Recall (a.k.a. true positive rate) — процент совпадений решений модели с решениями андеррайтера по одобрениям;
- Accept rate — процент одобряемых заявок (должен совпадать с accept rate андеррайтеров).
Дальнейшие направления — добавление новых признаков и использование комбинированных схем обучения модели, когда в качестве целевой переменной будет не только факт одобрения/отказа заявки, но и данные о реальной просрочке. Реализация такого решения требует изучения возможных эффектов, возникающих вследствие отсутствия данных по отклоненным заявкам.
Другие области применения
Кроме кредитного скоринга обучение по ответам экспертов может применяться к огромному многообразию задач: оценка стоимости автомобилей с пробегом, оценка объектов недвижимости, оценка эффективности рекламных кампаний и даже подбор цвета губной помады или подбор подарков.

Преимущества и недостатки подхода
Преимущества
- Основным преимуществом модели (по сравнению с классическим подходом) является скорость реализации, экономия ресурсов при разработке системы и возможность оценить качество решений с помощью простых метрик;
- Отсутствие необходимости «анализа отклоненных заявок»;
- При таком подходе мы не пытаемся умалить роль эксперта и полностью автоматизировать задачу (внедрение подхода с меньшим риском будет воспринято враждебно по сравнению с полной автоматизацией). Наоборот, ценность эксперта только возрастает. При этом эксперт может больше времени тратить на рассмотрение одного случая/заявки при принятии решений.
Недостатки
- Неоптимальность. Известно, что человеческие суждения в условиях неопределённости являются неоптимальными и содержат систематические ошибки (Tversky & Kahneman, 1974). Эксперты могут завышать/занижать вероятности тех или иных событий, что в итоге приводит к неоптимальным результатам работы обученной по ответам экспертов модели. Также эксперты не могут эффективно оценить влияние совокупности большого количества факторов на целевой показатель, поэтому применяют эвристики, т.е. оценивают реально существующие зависимости в упрощённом виде.
- Требуется необходимое количество актуальных данных для обучения. Например, ручной андеррайтинг должен всё равно сохраняться для получения обучающей выборки и непрерывного онлайн-тестирования и мониторинга качества.
Заключение
Результат применения подхода — возможность масштабирования бизнеса в десятки и более раз. Достигнуты приемлемые показатели соотношения процента автоматически обрабатываемого трафика и количества несовпадений с решениями андеррайтеров. Обучение модели по решениям андеррайтеров позволило ускорить и упростить процесс реализации автоскоринга и хорошо укладывается в методологию CRISP-DM.
В целом, «копировение» экспертов может положительно сказаться на показателе возврата инвестиций (ROI) для проектов по разработке и внедрению систем интеллеткуальной обработки данных.
Вместе с тем, следует учитывать ряд особенностей такого подхода.
Во-первых, подход не является оптимальным в части минимизации рисков или максимизации прибыли, но при этом позволяет сэкономить на оплате экспертов и/или получить масштабируемую систему.
Во-вторых, экспертные решения должны быть достаточно обоснованными и эффективными для этого, чтобы использоваться как эталон для обучения модели. То есть эксперты действительно должны давать хорошие ответы, которые в целом приводят к нужным результатам.
Обученная модель также может рассматриваться как временный, но работоспособный вариант решения задачи. В это время могут накапливаться данные и разрабатываться более качественное решение, основанное на добавление в модель целевого показателя, который сначала необходимо выбрать и обосновать.
Литература
Anderson, R. (2007). The credit scoring toolkit: theory and practice for retail credit risk management and decision automation. Oxford: Oxford University Press.
Shearer C. (2000). The CRISP-DM model: the new blueprint for data mining, Journal of Data Warehousing, Vol. 5, pp. 13–22.
Tversky, A., Kahneman D. (1974). Judgment under Uncertainty: Heuristics and Biases, Science, New Series, Vol. 185, No. 4157. (Sep. 27, 1974), pp. 1124–1131.
