[Перевод - recovery mode ] Алгоритм поиска самой длинной подстроки палиндрома
Один из самых прекрасных алгоритмов в информатике, который показывает, как можно получить большое ускорение от «вялого» O (n3) до молниеносного1 O (n), просто посмотрев на проблему с другой точки зрения.
Задача состоит в том, чтобы найти самую длинную подстроку, которая является палиндромом (читается одинаково слева направо и справа налево, например, «racecar»). Так, самый длинный палиндром в строке «Fractions are never odd or even» это «never odd or even» (регистр букв и пробелы игнорируются). Это также имеет практическое применение в биохимии (ГААТТЦ или ЦТТААГ являются палиндромными последовательностями2). К тому же, эту задачу3 часто дают на собеседовании.
Самый простой и прямой подход (при этом самый медленный) — перебирать с начала все подстроки всех длин и проверять, является ли текущая палиндромом:
 Давайте пока сконцентрируемся на палиндромах с нечетным количеством букв, мы обобщим их с палиндромами четного размера позже.
Давайте пока сконцентрируемся на палиндромах с нечетным количеством букв, мы обобщим их с палиндромами четного размера позже.
Псевдокод такого решения
ЦИКЛ по символам всей строки:
ЦИКЛ по всем длинам, начиная с текущего символа:
ЦИКЛ по символам в этой подстроке:явно указывает, что метод со сложностью O (n3) (где n — это длина начальной строки) является быстровозрастающей функцией.
Если бы вместо перебора с самых начал подстрок, мы начинали перебор с середины, это позволило бы нам использовать результаты, которые мы получили на предыдущих шагах.

Например, если мы знаем, что «eve» — это палиндром, то нам потребуется всего одно сравнение, чтобы выяснить, что «level» тоже палиндром. В первом решении нам бы пришлось проверять все полностью с самого начала.
ЦИКЛ по символам строки до середины:
ЦИКЛ по всем длинам, начиная с текущего символа:В таком случае сложность составляет O (n2). Но существуют методы4, позволяющие сделать это еще быстрее.
Один из самых изящных — это алгоритм Манакера5. Он основан на методе, описанном выше, но его временная сложность сокращена до O (n).
Когда палиндромы в строке находятся далеко, оптимизировать нечего. Сложность и так O (n). Проблема появляется, когда они пересекаются, а худшим случаем является строка, состоящая из одной буквы.
Рассмотрим следующую ситуацию. Алгоритм нашел самый короткий зеленый палиндром, самый длинный голубой палиндром и остановился на букве «i»:
 Числа внизу — это половина от максимального размера палиндрома с серединой в этом символе
Числа внизу — это половина от максимального размера палиндрома с серединой в этом символе
Внимательно посмотрев на картинку, можно заметить, что у нас нет необходимости обрабатывать правую часть голубого палиндрома. По определению, это зеркальное отражение левой части, так что полученную левую часть мы можем отразить на правую и получить ее, так сказать, «за бесплатно».
 Случай A
Случай A
Однако, это не единственный случай перекрытия. На следующей картинке зеленый палиндром пересекает границу голубого, поэтому его длина должна быть уменьшена.
 Случай B
Случай B
Опять-таки нет нужды дважды проверять длину отраженного палиндрома: буквы b и x обязаны быть различными, иначе голубой палиндром был бы длиннее.
Наконец, один палиндром может «касаться» другого изнутри. В этом случае нет гарантий, что отраженный палиндром не имеет бОльшую длину, так как мы получаем нижнюю границу его длины:
 Случай C
Случай C
В идеале мы должны пропускать как нулевые, так и строго ненулевые значения (= все случаи, кроме последнего) в дальнейшей обработке (код 1 ниже). Но в практике (если вообще можно говорить о практике в такой абстрактной задаче) разница между ≥ и = довольно мала (всего одно дополнительное сравнение), поэтому имеет смысл рассматривать все ненулевые значения с помощью ≥ для краткости и читаемости кода (код 2 ниже).
Одна из возможных реализаций алгоритма на питоне:
#код 1
def odd(s):
n = len(s)
h = [0] * n
C = R = 0 # центр и радиус или крайний правый палиндром
besti, bestj = 0, 0 # центр и радиус самого длинного палиндрома
for i in range(n):
if i < C + R: # если есть пересечение
j = h[C-(i-C)] # отражение
if j < C + R - i: # случай A
h[i] = j
continue
elif j > C + R - i: # случай B
h[i] = C + R - i
continue
else: # case C
pass
else: # если нет пересечения
j = 0
while i-j > 0 and i+j bestj:
besti, bestj = i, j
if i + j > C + R:
C, R = i, j
return s[besti-bestj : besti+bestj+1] Сперва алгоритм пытается найти соответствующее отражение, как описано выше. Затем, если необходимо, последовательно ищет: как в алгоритме со сложностью O (n2), но принимая отраженное значения за начальную точку. В конце если новый палиндром перекрывает больше текста справа, чем предыдущий, то он становится новым крайним правым палиндромом.
Эта функция ищет палиндромы только нечетного размера. Общий подход для работы с палиндромами четного размера таков:
вставлять произвольный символ между символами в оригинальной строке, к примеру
‘noon’ -> ‘|n|o|o|n|’,находить палиндром нечетного размера,
удалять произвольные символы из результата.
Символ »|» необязательно должен отсутствовать в строке. Можно использовать любой символ.
def odd_or_even(s):
return odd('|'+'|'.join(s)+'|').replace('|', '')
>>> odd_or_even('afternoon')
'noon'Немного запутанная версия (труднее для понимания, немного медленнее, но короче) выглядит так:
#код 2
import re
def odd(s):
n = len(s)
h = [0] * n
C = R = 0 # центр и радиус или крайний правый палиндром
besti, bestj = 0, 0 # центр и радиус самого длинного палиндрома
for i in range(n):
j = 0 if i > C+R else min(h[C-(i-C)], C+R-i)
while i-j > 0 and i+j bestj:
besti, bestj = i, j
if i + j > C + R:
C, R = i, j
return s[besti-bestj : besti+bestj+1]
def manacher(s):
clean = re.sub('\W', '', s.lower())
return odd('|'+'|'.join(clean)+'|')[1::2]
>>> manacher('He said: "Madam, I\'m Adam!"')
'madamimadam' Как видно, в коде есть два вложенных цикла. Тем не менее, интуитивно понятно, почему сложность O (n). На диаграмме показан массив h.
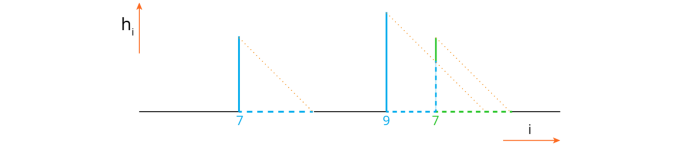
Внешний цикл соответствует горизонтальному перемещению, внутренний — вертикальному. Каждый шаг — это одно сравнение. Сплошные линии — расчет шагов, пунктирные — пропуск шагов.
Очевидно из диаграммы, что, когда палиндромы не пересекаются, число шагов «вверх» равно количеству горизонтальных «пропускающих» шагов. Для пересекающихся палиндромов чуть более заморочено, но если посчитать число шагов «вверх» и число горизонтальных «пропускающих шагов, то эти числа вновь совпадут. Так что общее число шагов ограничено 2n сравнениями. Не просто n, потому что, в отличие от вертикальных шагов, чтобы понять, пропускать ли горизонтальный шаг или нет, необходимо проделать некую работу (хотя можно изменить реализацию, чтобы пропускать их за постоянное время). Итого временная сложность — O (n).
Алгоритм Манакера позволяет найти самый длинный палиндром в строке (если быть точнее, не просто самый длинный палиндром, а самый длинный палиндром для всех возможных центров) за линейное время, используя очень интуитивный подход, лучше всего описываемый визуально.
Ссылки:
Сайт Big-O Cheat Sheet.
Статья на Википедии про палиндромные последовательности.
Задача на Leetcode про самый длинный палиндром в строке.
Статья на Википедии про самый длинный палиндром в строке.
Гленн Манакер (1975), «Новый линейный алгоритм для поиска самого длинного палиндрома строки», журнал ACM.
