Асинхронное программирование в однопоточных средах JavaScript
Моя прошлая обучающая статья Введение в Redux & React-redux набрала больше 100к просмотров. Что же это не может не радовать меня. И поэтому я решил порадовать и вас написав очередную статью по JavaScript. Хотя если честно я не хотел больше писать статьи поскольку это довольно сложно, занимает уйму времени и сил, а еще мне не платят за всю эту научную работу. Так что следующую статью я напишу только если эта наберет 150к просмотров.
Оглавление
1. Введение в асинхронное программирование
2. Цикл событий
3. Отложенное выполнение кода с помощью setTimeout setImmediate и process.nextTick
…3.1 setTimeout
…3.2 setImmediate
…3.3 process.nextTick
4. Устаревшие паттерны асинхронного программирования
5. Promise
…5.1 Основы Promise
…5.2 Методы экземпляра Promise
…5.2.1 Promise.prototype.then
…5.2.2 Promise.prototype.catch
…5.2.3 Promise.prototype.finally
…5.3 Композиция и цепочки промисов
…5.3.1 Графы промисов
…5.3.2 Параллельная композиция промисов с Promise.all и Promise.race
…5.3.3 Серийная композиция промисов
6. Асинхронные функции
…6.1 Остановка и возобновление выполнения
…6.2 Стратегии для асинхронных функций
…6.2.1 Реализация Sleep
…6.2.2 Максимизация распараллеливания
…6.2.3 Серийное выполнение промисов
…6.2.4 Трассировка стека и управление памятью
1. Введение в асинхронное программирование
Двойственность между синхронным и асинхронным поведением является фундаментальной концепцией в computer science, особенно в однопоточной модели цикла событий, такой как JavaScript. Асинхронное поведение обусловлено необходимостью оптимизации для более высокой вычислительной пропускной способности в условиях операций с высокой задержкой. Это прагматично, если возможно выполнение других инструкций во время завершения вычислений и при этом поддерживается стабильное состояние системы.
Асинхронная операция необязательно является вычислительной операцией или операцией с высокой задержкой. Ее можно использовать везде, где нет смысла блокировать поток выполнения, чтобы дождаться возникновения асинхронного поведения.
Синхронное поведение аналогично последовательным инструкциям процессора в памяти. Каждая инструкция выполняется строго в том порядке, в котором она появляется, и каждая из них также способна немедленно извлекать информацию, которая хранится локально в системе (например, в регистре процессора или в системной памяти). В результате можно легко определить состояние программы (например, значение переменной) в любой заданной точке кода.
let x = 3;
x = x + 4;
На каждом шаге этой программы можно рассуждать о ее состоянии, потому что выполнение не будет продолжено, пока не будет выполнена предыдущая инструкция. Когда последняя инструкция завершается, вычисленное значение сразу становится доступным для использования.
И наоборот, асинхронное поведение аналогично прерываниям, когда объект, внешний по отношению к текущему процессу, может инициировать выполнение кода. Часто требуется асинхронная операция, потому что невозможно заставить процесс долго ждать завершения операции (как в случае синхронной операции). Это длительное ожидание может возникнуть из-за того, что код обращается к ресурсу с высокой задержкой, например, отправляет запрос на удаленный сервер и ожидает ответа.
Пример выполнение арифметической операции за время ожидания:
let x = 3
setTimeout(() => x = x + 4, 1000)
Эта программа в конечном итоге выполняет ту же работу, что и синхронная — складывая два числа вместе, —, но этот поток выполнения не может точно знать, когда изменится значение x, потому что это зависит от того, когда обратный вызов будет исключен из очереди сообщений и выполнен.
В тот момент, когда прерывание будет запущено, это станет черным ящиком для среды выполнения JavaScript, поэтому невозможно точно знать, когда именно произойдет прерывание (хотя оно гарантированно произойдет после завершения текущего потока синхронного выполнения, поскольку обратный вызов еще не был снят с выполнения и утилизирован). Тем не менее обычно нельзя утверждать, когда именно состояние системы изменится после запланированного обратного вызова.
Чтобы значение x стало полезным, эта асинхронно выполняемая функция должна сообщить остальной части программы, что она обновила значение x. Однако если программе не нужно это значение, тогда она может продолжить и выполнять другую работу вместо ожидания результата.
Разработать систему, которая будет знать, когда можно прочитать значение x, на удивление сложно. Реализации такой системы в JavaScript прошли несколько итераций.
Представьте, например, сложный алгоритм преобразования изображения, который работает в браузере. Пока у стека вызовов есть функции для выполнения, браузер не может ничего сделать — он заблокирован. Это означает, что браузер не может рендерить, он не может запускать какой-либо другой код, он просто завис. И здесь возникает проблема — пользовательский интерфейс вашего приложения больше не эффективен, он больше не интерактивен, не приятен. Ваше приложение зависло.
В некоторых случаях это может быть не такой критической проблемой. Но как только ваш браузер начнет обрабатывать слишком много задач в стеке вызовов, он может перестать отвечать на запросы в течение длительного времени. В этот момент многие браузеры предпримут действия, выдав ошибку, спрашивая, должны ли они закрыть страницу:

2. Цикл событий
До ES6 сам JavaScript фактически никогда не имел прямого встроенного понятия асинхронности. Движок JavaScript никогда не делал ничего, кроме выполнения одного фрагмента вашей программы в любой момент времени.
Движок JavaScript (далее. JS Engine) — специализированная программа, обрабатывающая JavaScript. Самый популярный на сегодняшний день считается движок V8 он используется в браузерах Google Chrome и в Node Js.
На самом деле JS Engine не работает изолированно — он работает внутри среды хостинга, которая для большинства разработчиков является типичным веб-браузером или Node.js. На самом деле, в настоящее время JavaScript внедряется во все виды устройств, от роботов до лампочек и каждое отдельное устройство представляет отдельный тип среды выполнения для JS Engine.
Общим знаменателем во всех средах является встроенный механизм, называемый циклом событий, который обрабатывает выполнение нескольких фрагментов вашей программы с течением времени, каждый раз вызывая JS Engine.
Это означает, что JS Engine — это просто среда выполнения по требованию для любого произвольного кода JS. Это окружающая среда, которая планирует события (выполнение кода JS).
Более подробно о работе JS Engine вы можете узнать из серии книг Вы не знаете JS.
Цикл событий выполняет одну простую задачу — отслеживает стек вызовов и очередь обратного вызова. Если стек вызовов пуст, цикл событий возьмет первое событие из очереди и поместит его в стек вызовов, который эффективно его запустит.
Такая итерация называется тиком в цикле событий. Каждое событие — это просто обратный вызов функции.
Давайте пошагово рассмотрим работу цикла событий, на этом простом примере:
console.log('Hi')
setTimeout(function cb1() {
console.log('cb1')
}, 5000)
console.log('Bye')
1. Состояние чисто. Консоль браузера чиста, а стек вызовов пуст.
2. console.log ('Hi') добавляется в стек вызовов.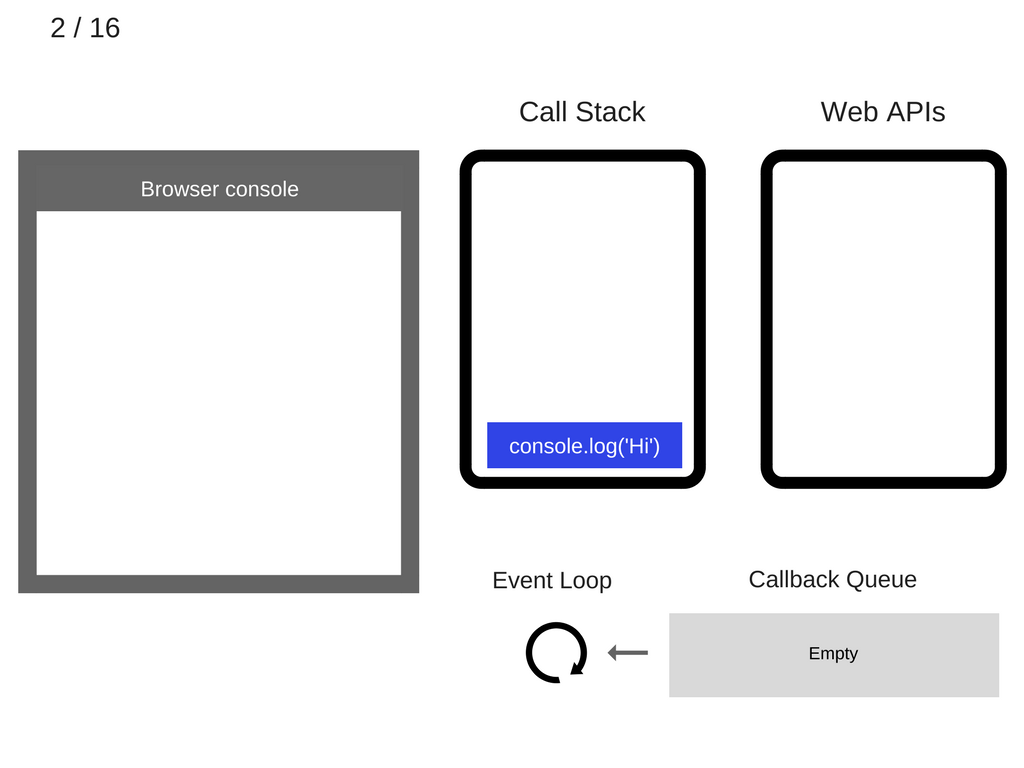
3. console.log ('Hi') выполняется.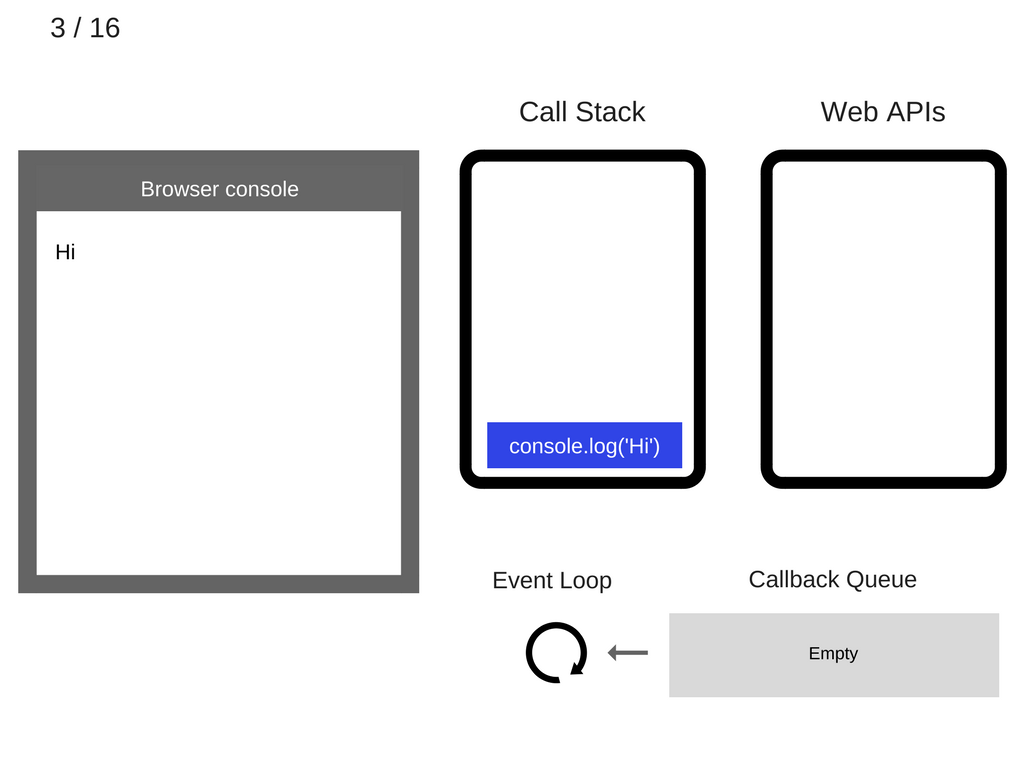
4. console.log ('Hi') удаляется из стека вызовов.
5. setTimeout (function cb1() {… }) добавляется в стек вызовов.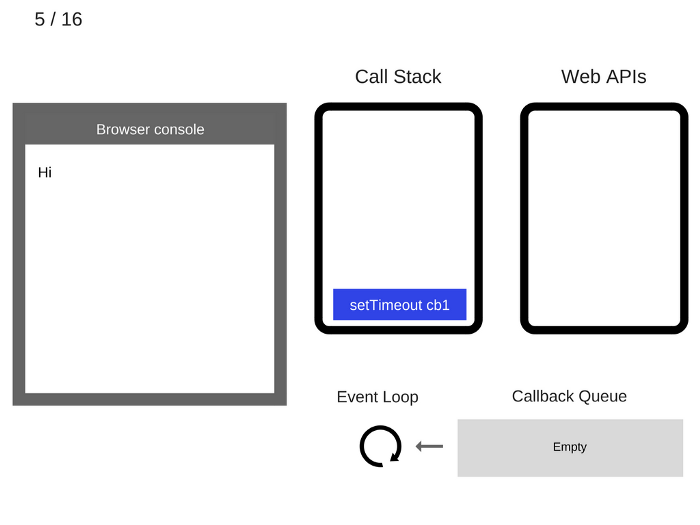
6. Выполняется setTimeout (function cb1() {… }). Браузер создает таймер как часть веб-API и обрабатывает обратный отсчет.
7. Сам setTimeout (function cb1() {… }) завершен и удаляется из стека вызовов.
8. console.log ('Bye') добавлен в стек вызовов.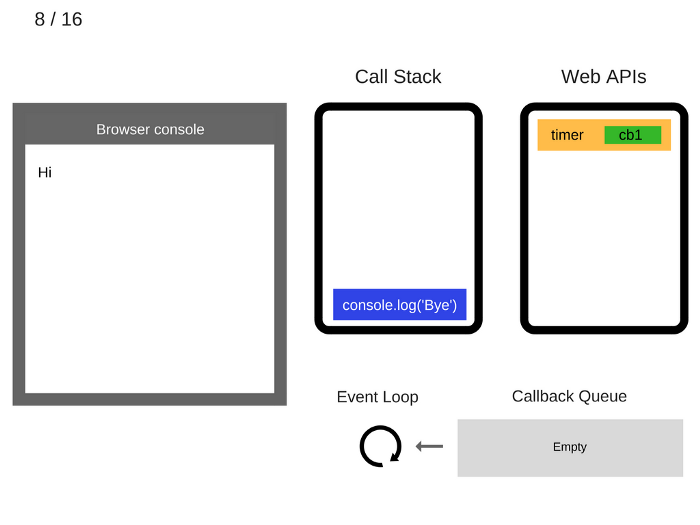
9. console.log ('Bye') выполняется.
10. console.log ('Bye') удаляется из стека вызовов.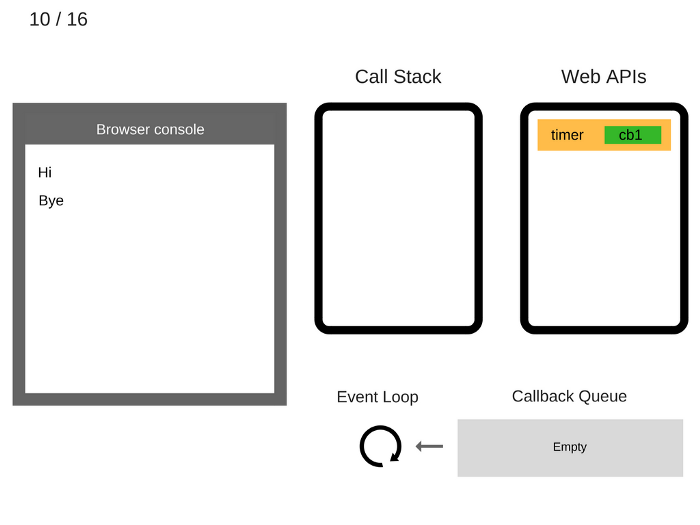
11. По прошествии не менее 5000 мс таймер завершает работу и отправляет обратный вызов cb1 в очередь обратных вызовов.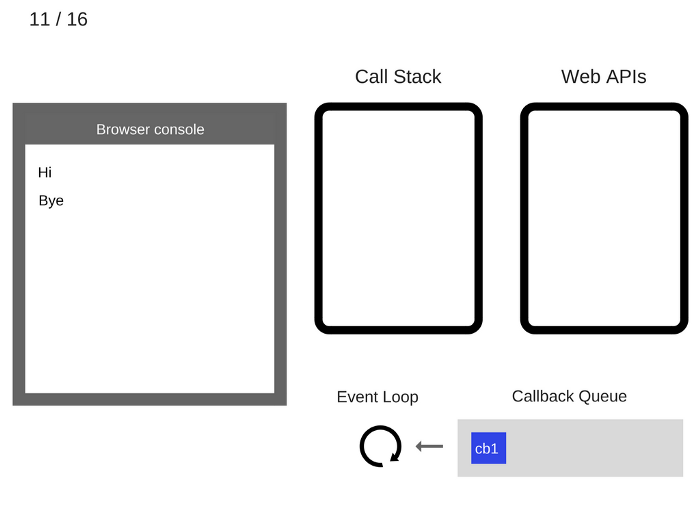
12. Цикл событий берет cb1 из очереди обратного вызова и помещает его в стек вызовов.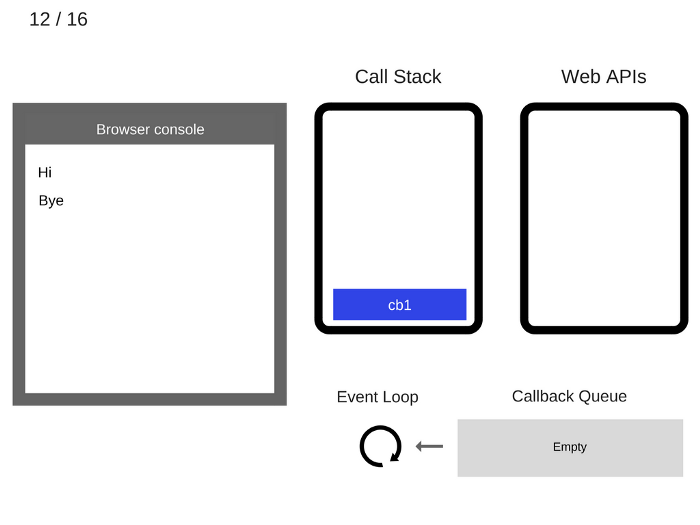
13. cb1 выполняется и добавляет console.log ('cb1') в стек вызовов.
14. console.log ('cb1') выполняется.
15. console.log ('cb1') удаляется из стека вызовов.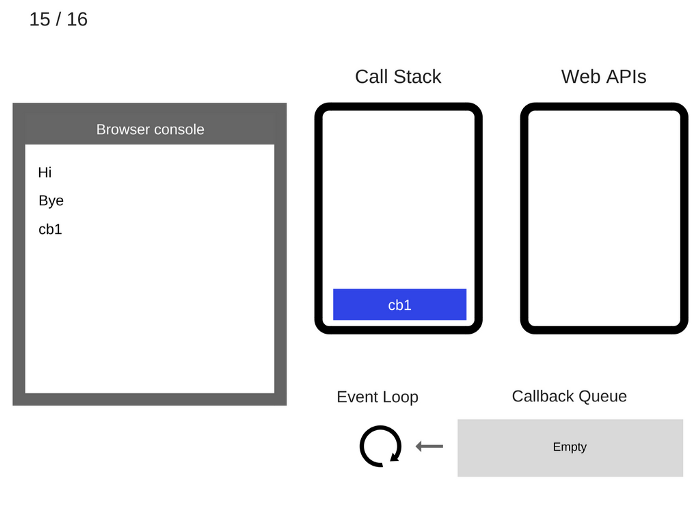
16. cb1 удаляется из стека вызовов.
Краткий обзор: 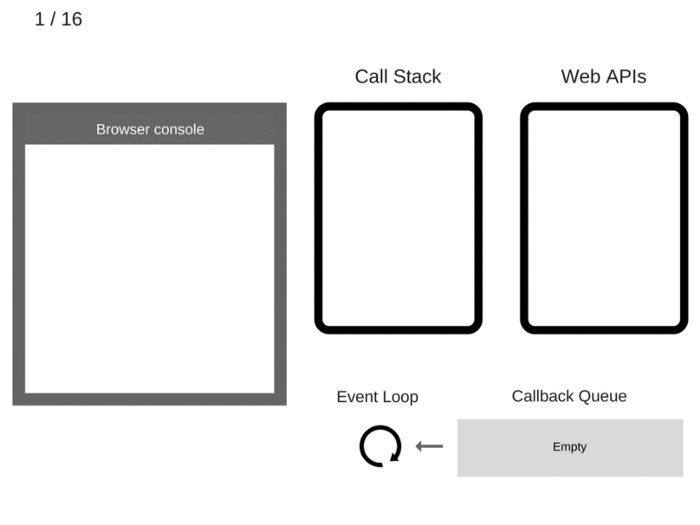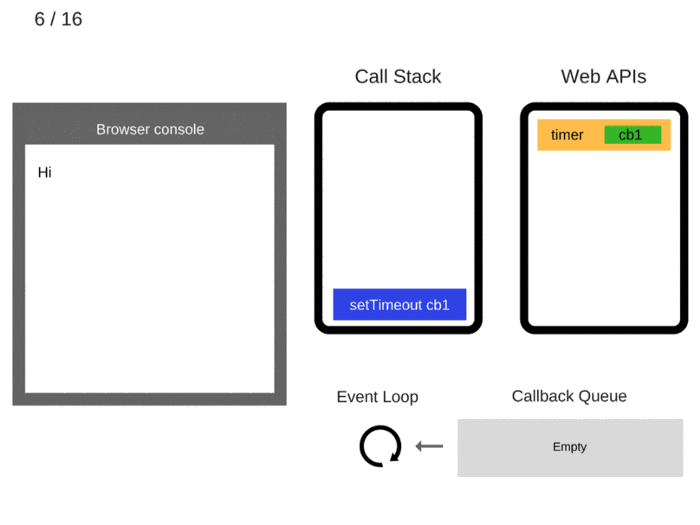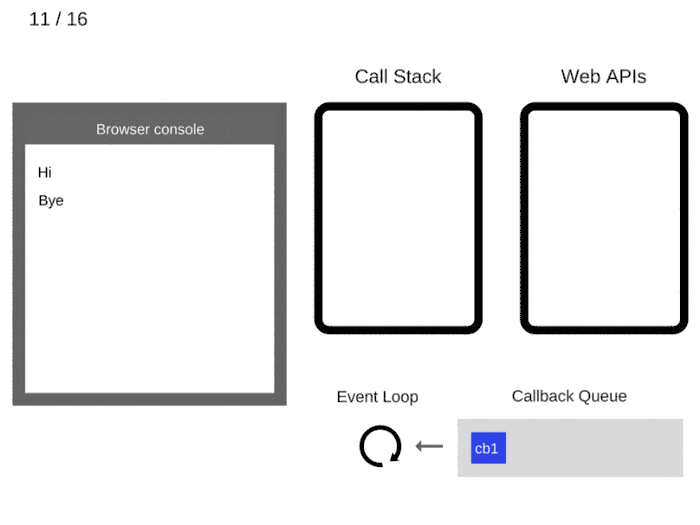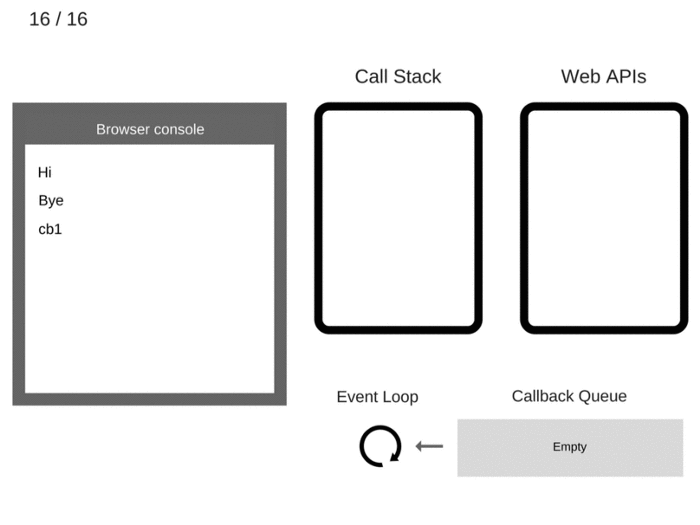
Интересно отметить, что ES6 определяет, как должен работать цикл событий, а это означает, что технически это входит в сферу ответственности JS Engine, который больше не играет роль только среды выполнения. И одной из основных причин этого изменения является введение Promise в ES6, потому что они требуют доступа к прямому, детализированному контролю над операциями планирования в очереди цикла событий.
3. Отложенное выполнение кода с помощью setTimeout setImmediate и process.nextTick
3.1 setTimeout
setTimeout не помещает автоматически ваш обратный вызов в очередь цикла обработки событий. Он устанавливает таймер. Когда таймер истекает, среда помещает ваш обратный вызов в цикл событий, чтобы какой-нибудь будущий тик подхватил его и выполнил.
Это не означает, что обратный вызов будет выполнен через указанное время, а скорее то, что через это время функция обратного вызова будет добавлена в очередь цикла событий. Однако в очереди могут быть и другие события, которые были добавлены ранее — тогда вашему обратному вызову придется подождать.
Передавая вторым аргументом в setTimeout в качестве задержки 0, вы можете подумать что в таком случае функция обратного вызова будет выполнена сразу, как будто setTimeout и вовсе не было. Но это не так. Взгляните на этот простой пример:
let x
setTimeout(() => x = 10, 0)
console.info(x) // undefined
На самом деле вызов setTimeout с 0 в качестве второго аргумента просто откладывает обратный вызов до тех пор, пока стек вызовов не будет очищен. В данном примере x = 10 не может выполнится до того, как вызов console.info (x) произойдет, потому что console.info (x) занимает стек вызовов, и setTimeout не может вызвать колбэк пока там есть что-то.
3.2 setImmediate
let x
setImmediate(() => x = 10)
console.info(x) // undefined
setImmediate и setTimeout похожи, но ведут себя по-разному в зависимости от того, когда они вызываются.
- setImmediate предназначен для выполнения скрипта после завершения текущей фазы опроса.
- setTimeout планирует запуск скрипта по истечении минимального порога в мс.
Порядок, в котором выполняются таймеры, зависит от контекста, в котором они вызываются. Если оба вызываются из основного модуля, то время будет зависеть от производительности процесса (на которую могут влиять другие приложения, работающие на машине).
Например, если мы запускаем следующий скрипт, который не находится в цикле ввода-вывода (т. е. в основном модуле), порядок, в котором выполняются два таймера, не детерминирован, поскольку он связан с производительностью процесса:
// timeout_vs_immediate.js
setTimeout(() => {
console.log('timeout')
}, 0)
setImmediate(() => {
console.log('immediate')
})$ node timeout_vs_immediate.js
timeout
immediate
$ node timeout_vs_immediate.js
immediate
timeoutОднако, если вы перемещаете два вызова в пределах цикла ввода-вывода, обратный вызов setImmediate всегда выполняется первым:
// timeout_vs_immediate.js
const fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout')
}, 0)
setImmediate(() => {
console.log('immediate')
})
})$ node timeout_vs_immediate.js
immediate
timeout
$ node timeout_vs_immediate.js
immediate
timeout
Основное преимущество использования setImmediate по сравнению с setTimeout заключается в том, что setImmediate всегда будет выполняться перед любыми таймерами, если они запланированы в цикле ввода-вывода, независимо от того, сколько таймеров присутствует.
setTimeout и setImmediate будут запущены в следующей итерации цикла обработки событий. Но setImmediate всегда будет выполняться перед любыми таймерами, если они запланированы в цикле ввода-вывода, независимо от того, сколько таймеров присутствует.
3.3 process.nextTick
process.nextTick является частью асинхронного API. Но технически он не является частью цикла обработки событий. Вместо этого nextTickQueue будет обработан после завершения текущей операции, независимо от текущей фазы цикла обработки событий. Здесь операция определяется как переход от базового обработчика C/C++ и обработка JavaScript, которой необходимо выполнить.
Каждый раз, когда вы вызываете process.nextTick на определенной фазе, все обратные вызовы, переданные в process.nextTick, будут разрешены до того, как цикл событий продолжится. Это может создать некоторые плохие ситуации, потому что позволяет «голодать» вашему процессу ввода-вывода, выполняя рекурсивные вызовы process.nextTick, которые не позволяют циклу обработки событий достичь фазы опроса.
Когда мы передаем функцию в process.nextTick, мы инструктируем движок вызывать эту функцию в конце текущей операции, прежде чем начнется следующий тик цикла событий.
Вызов setTimeout (() => {}, 0) или setImmediate выполнит функцию обратного вызова в конце следующего тика, намного позже, чем при использовании nextTick, который отдает приоритет вызову и выполняет его непосредственно перед началом следующего тика.
По сути, имена должны быть заменены местами. process.nextTick срабатывает быстрее, чем setImmediate, но это ошибки прошлого, которые вряд ли можно исправить. Выполнение этого переключения приведет к поломке большого процента пакетов в npm.
process.nextTick выполняется когда цикл событий завершит обработку текущего стека вызовов и операции завершатся, JS Engine запускает все функции, переданные в вызовы nextTick во время этой операции.
Таким образом мы можем указать движку JS обрабатывать функцию асинхронно (после текущей функции), но как можно скорее, а не ставить ее в очередь.
Главное отличие process.nextTick от setTimeout и setImmediate в том что nextTick, выполняет обратный вызов непосредственно перед началом следующего тика, а не в следующем тике.
Поэтому вам следует использовать nextTick, если вы хотите убедиться, что в следующей итерации цикла событий этот код будет уже выполнен.
Зачем нам вообще нужно что-то подобное? Частично это философия дизайна, согласно которой API всегда должен быть асинхронным, даже если это не обязательно. Возьмем, к примеру, этот фрагмент кода:
function apiCall(arg, callback) {
if (typeof arg !== 'string')
return process.nextTick(
callback,
new TypeError('argument should be string'),
)
}
Фрагмент проверяет аргумент и, если он неверен, передает ошибку обратному вызову. API обновлен совсем недавно, чтобы разрешить передачу аргументов в process.nextTick, что позволяет ему принимать любые аргументы, переданные после обратного вызова, для распространения в качестве аргументов обратного вызова, поэтому вам не нужно вкладывать функции.
Здесь мы возвращаем ошибку пользователю, но только после того, как разрешили выполнение остального кода пользователя. Используя process.nextTick, гарантируется, что apiCall всегда выполняет свой обратный вызов после остального кода пользователя и до того, как цикл обработки событий будет разрешен. Это позволяет выполнять рекурсивные вызовы process.nextTick без достижения RangeError: Maximum call stack size exceeded from v8.
Эта философия может привести к некоторым потенциально проблемным ситуациям. Возьмем, к примеру, этот фрагмент:
let bar
// someAsyncApiCall имеет асинхронную сигнатуру, но синхронно вызывает обратный вызов
function someAsyncApiCall(callback) {
callback()
}
// обратный вызов вызывается до завершения `someAsyncApiCall`
someAsyncApiCall(() => {
// так как someAsyncApiCall не завершился, bar не было присвоено никакого значения
console.log('bar', bar) // bar undefined
})
bar = 1
someAsyncApiCall имеет асинхронную сигнатуру, но на самом деле он работает синхронно. Когда он вызывается, обратный вызов, предоставленный someAsyncApiCall, вызывается в той же фазе цикла событий, потому что someAsyncApiCall на самом деле ничего не делает асинхронно. В результате обратный вызов пытается обратиться к полосе ссылок, даже если эта переменная еще не указана в области действия, поскольку сценарий не может быть выполнен до конца.
Поместив обратный вызов в process.nextTick, сценарий по-прежнему имеет возможность выполняться до завершения, позволяя инициализировать все переменные, функции и т. д. до вызова callback. Также это дает возможность, не продолжать цикл событий. Это может быть полезно, чтобы пользователь был предупрежден об ошибке до того, как цикл обработки событий будет разрешен. Вот предыдущий пример с использованием process.nextTick:
let bar
function someAsyncApiCall(callback) {
process.nextTick(callback)
}
someAsyncApiCall(() => {
console.log('bar', bar) // bar 1
})
bar = 1
Вот еще один пример из реальной жизни:
const server = net.createServer(() => {}).listen(8080)
server.on('listening', () => {})
Когда передается только порт, порт привязывается немедленно. Таким образом, обратный вызов «listening» может быть вызван немедленно. Проблема в том, что к этому времени обратный вызов. on ('listening') не будет установлен.
Чтобы обойти это, событие «listening» ставится в очередь в nextTick, чтобы сценарий мог выполняться до завершения. Это позволяет устанавливать любые обработчики событий.
Зачем использовать process.nextTick?
Есть две основные причины:
- Иметь возможножность обрабатывать ошибки, очищать все ненужные ресурсы или, возможно, повторить запрос, прежде чем цикл обработки событий продолжится.
- Иногда необходимо выполнить обратный вызов после запуска стека вызовов, но до продолжения цикла обработки событий.
Одним из примеров является соответствие ожиданиям пользователя. Простой пример:
const server = net.createServer()
server.on('connection', (conn) => {})
server.listen(8080)
server.on('listening', () => {})
Предположим, что listen запускается в начале цикла событий, но обратный вызов прослушивания помещается в setImmediate. Если имя хоста не передано, привязка к порту произойдет немедленно. Чтобы цикл событий продолжался, он должен попасть в фазу опроса, что означает, что существует ненулевая вероятность того, что connection могло быть получено, что позволяет запустить событие connection до события прослушивания.
Другой пример — запуск конструктора функции, который должен был, скажем, наследоваться от EventEmitter, и он хотел вызвать событие внутри конструктора:
const EventEmitter = require('events')
const util = require('util')
function MyEmitter() {
EventEmitter.call(this)
this.emit('event')
}
util.inherits(MyEmitter, EventEmitter)
const myEmitter = new MyEmitter()
myEmitter.on('event', () => {
console.log('an event occurred!')
})
Вы не можете немедленно сгенерировать событие из конструктора, потому что сценарий не будет обработан до точки, в которой пользователь назначает обратный вызов этому событию. Таким образом, внутри самого конструктора вы можете использовать process.nextTick для установки обратного вызова для отправки события после завершения конструктора, что обеспечивает ожидаемые результаты:
const EventEmitter = require('events')
const util = require('util')
function MyEmitter() {
EventEmitter.call(this)
// использование nextTick для генерации события после назначения обработчика
process.nextTick(() => {
this.emit('event')
})
}
util.inherits(MyEmitter, EventEmitter)
const myEmitter = new MyEmitter()
myEmitter.on('event', () => {
console.log('an event occurred!')
})
Больше примеров смотрите в статье «Цикл событий Node.js, таймеры и process.nextTick ()»
4. Устаревшие паттерны асинхронного программирования
Асинхронное поведение долгое время было важным, но ужасным краеугольным камнем JavaScript. В ранних версиях языка асинхронная операция поддерживала только определение функции обратного вызова для указания, что асинхронная операция завершена. Сериализация асинхронного поведения была распространенной проблемой, обычно решаемой с помощью кодовой базы, полной вложенных функций обратного вызова, в миру называемой «адом обратных вызовов».
Предположим, вы работали со следующей асинхронной функцией, которая использует setTimeout для выполнения некоторого поведения через одну секунду:
function double(value) {
setTimeout(() => setTimeout(() => console.log(value * 2), 0), 1000)
}
double(3)
// 6 (выводится примерно спустя 1000 мс)
setTimeout позволяет определить обратный вызов, который планируется выполнить по истечении заданного промежутка времени. Спустя 1000 мс во время выполнения JavaScript запланирует обратный вызов, поместив его в очередь цикла обработки событий. Этот обратный вызов снимается и выполняется способом, который полностью невидим для кода JavaScript. Более того, функция double завершается сразу после успешного выполнения операции планирования setTimeout.
Предположим, операция setTimeout вернула полезное значение. Как лучше всего вернуть значение туда, где оно необходимо? Широко используемая стратегия заключается в предоставлении обратного вызова для асинхронной операции, где обратный вызов содержит код, требующий доступ к вычисленному значению (предоставляется в качестве параметра).
function double(value, callback) {
setTimeout(() => callback(value * 2), 1000)
}
double(3, (x) => console.log(`I was given: ${x}`))
// I was given: 6 (выводится примерно спустя 1000 мс)
Здесь при вызове setTimeout команда помещает функцию в очередь сообщений по истечении 1000 мс. Эта функция будет удалена и асинхронно вычислена средой выполнения. Функция обратного вызова и ее параметры все еще доступны в асинхронном исполнении через замыкание функции.
Возможно, вы также хотели бы иметь возможность обработать ошибки в асинхронной функции, поэтому вероятность сбоя также должна быть включена в эту модель обратного вызова, так что обычно она принимает форму обратного вызова в случае успеха и неудачи.
function double(value, success, failure) {
setTimeout(() => {
try {
if (typeof value !== 'number')
throw new Error(`Unexpected argument. expected number but received: ${typeof value}`)
success(2 * value)
} catch (e) {
failure(e)
}
}, 1000)
}
const successCallback = (x) => console.log(`Success: ${x}`)
const failureCallback = (e) => console.log(`Failure: ${e}`)
double(3, successCallback, failureCallback) // Success: 6 (выводится примерно спустя 1000 мс)
double('b', successCallback, failureCallback) // Failure: Error: Unexpected argument. expected number but received: string
Этот формат уже нежелателен, так как обратные вызовы должны быть определены при инициализации асинхронной операции. Значение, возвращаемое из асинхронной функции, является временным, и поэтому только обратные вызовы, которые готовы принять это временное значение в качестве параметра, могут получить к нему доступ.
Ситуация с обратными вызовами еще более усложняется, когда доступ к асинхронным значениям зависит от других асинхронных значений. В мире обратных вызовов это требует вложения обратных вызовов.
function double(value, success, failure) {
setTimeout(() => {
try {
if (typeof value !== 'number')
throw new Error(`Unexpected argument. expected number but received: ${typeof value}`)
success(2 * value)
} catch (e) {
failure(e)
}
}, 1000)
}
const successCallback = (x) => double(x, (y) => console.log(`Success: ${y}`))
const failureCallback = (e) => console.log(`Failure: ${e}`)
double(3, successCallback, failureCallback)
// Success: 12 (выводится примерно спустя 1000 мс)
Неудивительно, что эта стратегия обратного вызова плохо масштабируется по мере роста сложности кода. Выражение «ад обратных вызовов» вполне заслужено, так как кодовые базы JavaScript, которые были поражены такой структурой, стали почти не поддерживаемыми.
5. Promise
Promise (далее промис) — это суррогатная сущность, которая выступает в качестве замены для результата, который еще не существует. Термин «промис» был впервые предложен Дэниелом Фридманом и Дэвидом Уайзом в их статье 1976 г. «Влияние прикладного программирования на многопроцессорность (The Impact of Applicative Programming on Multiprocessing)», но концептуальное поведение промиса было формализовано лишь десятилетие спустя Барбарой Лисков и Любой Шрира в их статье 1988 г. «Промисы: лингвистическая поддержка эффективных асинхронных процедурных вызовов в распределенных системах (Promises: Linguistic Support for Efficient Asynchronous Procedure Calls in Distributed Systems)». Современные компьютерные ученые описали похожие понятия, такие как «возможное», «будущее», «задержка» или «отсроченное»; все они описаны в той или иной форме программным инструментом для синхронизации выполнения программы.
Ранние формы промисов появились в jQuery и Dojo Deferred API, а в 2010 г. растущая популярность привела к появлению спецификации Promises/A внутри проекта CommonJS. Сторонние библиотеки промисов JavaScript, такие как Q и Bluebird, продолжали завоевывать популярность, но каждая реализация немного отличалась от предыдущей. Чтобы устранить разногласия в пространстве промисов, в 2012 г. организация Promises/A + разветвила предложение CommonJS Promises/A и создала одноименную спецификацию промисов Promises/A+. Эта спецификация в конечном итоге определила, то как промисы были реализованы в спецификации ECMAScript 6.
ECMAScript 6 представил первоклассную реализацию совместимого с Promise/A+ типа Promise. За время, прошедшее с момента его введения, промисы пользовались невероятно высоким уровнем поддержки. Все современные браузеры полностью поддерживают тип промисов ES6, и несколько API-интерфейсов браузера, таких как fetch () и Battery API, используют исключительно его.
5.1 Основы Promise
Интерфейс Promise (промис) представляет собой обёртку для значения, неизвестного на момент создания Promise. Он позволяет обрабатывать результаты асинхронных операций так, как если бы они были синхронными: вместо конечного результата асинхронного метода возвращается своего рода обещание (дословный перевод слова «промис») получить результат в некоторый момент в будущем.
Начиная с ECMAScript 6, Promise является поддерживаемым ссылочным типом и может быть создан с помощью оператора new.
let p = new Promise(() => {})
console.log(p) // Promise
При передаче экземпляра Promise в console.log выводы консоли (которые могут
различаться в разных браузерах) указывают, что этот экземпляр Promise находится
в состоянии ожидания (pending).
Промис — это объект с состоянием, который может существовать в одном из трех состояний:
- в ожидании (Pending) — начальное состояние;
- выполнен или решенным (Fulfilled) — операция завершена успешно;
- отклонен (Rejected) — операция завершена с ошибкой.
Состояние ожидания — это начальное состояние, с которого начинается промис. Из состояния ожидания промис может быть установлен путем перехода в выполненное состояние, указывающее на успех, или отклоненное, указывающее на отказ. Этот переход к установленному состоянию необратим; как только происходит переход к выполненному или отклоненному состоянию, состояние промиса уже не сможет измениться. Кроме того, не гарантируется, что промис когда-либо покинет состояние ожидания. Следовательно, хорошо структурированный код должен вести себя правильно, если промис успешно разрешается, если он отклоняется или никогда не выходит из состояния ожидания.
Состояние промиса является частным и не может быть напрямую проверено в JavaScript. Причина этого заключается прежде всего в том, чтобы предотвратить синхронную программную обработку объекта промиса на основе его состояния при чтении. Кроме того, состояние промиса не может быть изменено внешним JS-кодом по той же причине, по которой состояние не может быть прочитано: промис намеренно инкапсулирует блок асинхронного поведения, а внешний код, выполняющий синхронное определение его состояния, противоречит его цели.
Существуют две основные причины, по которым конструкция промисов полезна. Первая — это абстрактное представление блока асинхронного выполнения. Состояние промиса указывает на то, должен ли промис подождать с завершением выполнения. Состояние ожидания указывает, что выполнение еще не началось или все еще выполняется. Выполненное состояние является неспецифическим индикатором того, что выполнение успешно завершено. Отклоненное состояние является неспецифическим индикатором того, что выполнение не завершилось успешно.
В некоторых случаях внутренней машиной состояний является вся полезность, которую промис должен предоставить: одного лишь знания о том, что кусок асинхронного кода завершен, достаточно для информирования о ходе выполнения программы. Например, предположим, что промис отправляет HTTP-запрос на сервер. Запрос, возвращающийся со статусом не 200–299, может быть достаточным для перехода состояния обещания в выполненное. Точно так же запрос, возвращающийся со статусом, который не является 200–299, перевел бы состояние промиса в отклоненное.
В других случаях асинхронное выполнение, которое оборачивает промис, фактически генерирует значение, и поток программы будет ожидать, что это значение будет доступно, когда промис изменит состояние. С другой стороны, если промис отклоняется, поток программы ожидает причину отклонения после изменения состояния промиса. Например, предположим, что промис отправляет HTTP-запрос на сервер и ожидает его возврата в формате JSON. Запрос, возвращающийся со статусом 200–299, может быть достаточным для перевода промиса в выполненное состояние, и JSON-строка будет доступна внутри промиса. Точно так же запрос, возвращаемый со статусом, который не является 200–299, перевел бы состояние промиса в отклоненное, и причиной отклонения может быть объект Error, содержащий текст, сопровождающий HTTP-код статуса.
Для поддержки этих двух вариантов использования каждый промис, который переходит в выполненное состояние, имеет закрытое внутреннее значение. Точно так же каждый промис, который переходит в отклоненное состояние, имеет закрытую внутреннюю причину. И значение, и причина являются неизменной ссылкой на примитив или объект. Оба являются необязательными и по умолчанию будут иметь значение undefined. Асинхронный код, который планируется выполнить после того, как промис достигает определенного установленного состояния, всегда снабжается значением или причиной.
Поскольку состояние промиса является закрытым, им можно манипулировать только изнутри. Эта внутренняя манипуляция выполняется внутри функции-исполнителя промиса. Функция-исполнитель выполняет две основные обязанности: инициализирует асинхронное поведение промиса и контролирует любой возможный переход состояния. Управление переходом между состояниями осуществляется путем вызова одного из двух параметров функции, которые обычно называются resolve и reject. Вызов resolve изменит состояние на выполненное; вызов reject изменит состояние на отклоненное. Вызов rejected () также сгенерирует ошибку.
let p1 = new Promise((resolve, reject) => resolve())
setTimeout(() => console.log(p1), 0) // Promise {: undefined}
// [[PromiseState]]: "fulfilled"
// [[PromiseResult]]: undefined
let p2 = new Promise((resolve, reject) => reject())
setTimeout(() => console.log(p2), 0) // Promise {: undefined}
// [[PromiseState]]: "rejected"
// [[PromiseResult]]: undefined
// Uncaught error (in promise)
В этом примере асинхронное поведение на самом деле не происходит, потому что состояние каждого промиса уже изменяется к моменту выхода из функции-исполнителя. Сама функция-исполнитель будет выполняться синхронно, так как она действует как инициализатор для промиса.
let p = new Promise((resolve, reject) => {
resolve()
reject() // Безрезультатно
})
setTimeout(() => console.log(p), 0) // Promise {: undefined}
Вы можете избежать зависания промиса в состоянии ожидания, добавив запланированное поведение выхода. Например, можно установить тайм-аут, чтобы отклонить промис через 10 секунд:
let p = new Promise((resolve, reject) => {
setTimeout(reject, 100) // Вызов reject() спустя 1 секунду
// Код исполнителя
})
setTimeout(() => console.log(p), 0) // Promise
setTimeout(() => console.log(p), 200) // Проверка состояния спустя 2 секунды
// (Спустя 1 секунду) Uncaught error
// (Спустя 2 секунды) Promise
Поскольку промис может изменить состояние только один раз, такое поведение тайм-аута позволяет безопасно устанавливать максимальное количество времени, в течение которого промис может оставаться в состоянии ожидания. Если код внутри исполнителя должен был разрешить или отклонить промис до истечения времени ожидания, попытка обработчика времени ожидания отклонить промис будет игнорироваться.
Промис не обязательно должен начинаться с состояния ожидания и использовать функцию-исполнитель для достижения установленного состояния. Можно создать экземпляр промиса в состоянии «разрешено», вызвав статический метод Promise.resolve.
Следующие два экземпляра промисов фактически эквивалентны:
let p1 = new Promise((resolve, reject) => resolve())
let p2 = Promise.resolve()
Значение этого разрешенного промиса станет первым аргументом, переданным Promise.resolve. Таким образом можно эффективно «преобразовать» любое значение в промис:
const p1 = Promise.resolve()
console.info(p1) // Promise : undefined
const p2 = Promise.resolve(3)
console.info(p2) // Promise : 3
// Дополнительные аргументы игнорируются
const p3 = Promise.resolve(4, 5, 6)
console.info(p3) // Promise : 4
Возможно, наиболее важным аспектом этого статического метода является его способность действовать как переход, когда аргумент уже является промисом. В результате Promise.resolve является идемпотентным методом:
const p = Promise.resolve(7)
console.log(p === Promise.resolve(p)) // true
console.log(p === Promise.resolve(Promise.resolve(p))) // true
Эта идемпотентность будет учитывать состояние промиса, переданного ему.
let p = new Promise(() => {})
console.log(p) // Promise
console.log(Promise.resolve(p)) // Promise
console.log(p === Promise.resolve(p)) // true
Этот статический метод с радостью обернет любой не-промис, включая объект ошибки, как разрешенный промис, что может привести к непреднамеренному поведению.
let p = Promise.resolve(new Error('foo'))
console.log(p)
// Promise : Error: foo
В принципе, аналогично Promise.resolve, Promise.reject создает отклоненный промис и генерирует асинхронную ошибку (которая не будет перехвачена try/catch и может быть перехвачена только обработчиком отклонения).
Следующие два экземпляра промисов фактически эквивалентны.
let p1 = new Promise((resolve, reject) => reject())
let p2 = Promise.reject()
Поле «причины» этого разрешенного промиса будет первым аргументом, переданным Promise.reject. Оно также будет ошибкой, переданной обработчику отклонения:
let p = Promise.reject(3)
console.log(p) // Promise : 3
p.then(null, e => console.log(e)) // 3
Promise.reject не отражает поведение Promise.resolve в отношении идемпотентности. Если объект промиса передан, он с
