[Перевод] Знакомство с рекомендательными системами
Привет, Хабр!
Давайте вернемся к периодически затрагиваемой у нас теме машинного обучения и нейронных сетей. Сегодня речь пойдет об основных типах рекомендательных систем, их достоинствах и недостатках. Под катом — интересная статья Тоби Дейгла с кодом на Python,
Над катом — ссылка на большую презентацию нашего замечательного автора Сергея Николенко, чью книгу «Глубокое обучение. Погружение в мир нейронных сетей», написанную в соавторстве с Артуром Кадуриным и Екатериной Архангельской, мы просто не успеваем допечатывать. В презентации описаны основные типы рекомендательных систем и принципы их работы.
Читаем и комментируем!
Многие получают советы, но лишь мудрые в состоянии ими воспользоваться. — Харпер Ли
Рекомендательные системы кажутся многим волшебными артефактами, словно читающими наши мысли. Вспомните хотя бы рекомендательный движок Netflix, подсказывающий нам новые фильмы, или сервис Amazon, предлагающий нам товары, которые могут понравиться. С самого зарождения такие инструменты совершенствовались и оттачивались, пользоваться ими становилось все удобнее. Но, пусть многие из рекомендательных движков — очень сложные системы, фундаментально их устройство весьма незамысловато.
Что такое рекомендательная система?
Рекомендательные движки — это подсемейство систем для фильтрации контента, предоставляющих пользователю те элементы, которые могли бы его заинтересовать. Рекомендации подбираются на основе преференций и поведения пользователя. Система должна спрогнозировать вашу реакцию на тот или иной элемент — и предложить другие, которые также могут вам понравиться.
Как создать рекомендательную систему?
Хотя, при программировании рекомендательных систем применяется множество методов, расскажу вам о трех самых простых, которые используются чаще всего. Речь пойдет о коллаборативной фильтрации (collaborative filtering), контентная фильтрация (content-based filtering) и, наконец, экспертные системы (knowledge-based systems). По каждой системе я опишу ее слабые места, потенциальные подводные камни и расскажу, как их обходить. Наконец, в финале статьи я приведу полноценную реализацию рекомендательного движка.
Коллаборативная фильтрация

Первый из рассматриваемых методов, коллаборативная фильтрация — один из простейших и наиболее эффективных. Этот трехэтапный процесс начинается со сбора пользовательской информации. Затем выстраивается матрица для расчета ассоциаций и, наконец, дается весьма достоверная рекомендация. Существует две основные разновидности этого метода: на основе пользователей, занимающихся поиском, и на основе элементов, образующих ту или иную категорию.
Пользовательская коллаборативная фильтрация
Идея, на которой основан этот метод — искать пользователей, чьи вкусы похожи на предпочтения нашего целевого пользователя. Если ранее Жан-Пьер и Джейсон проставили схожие оценки нескольким фильмам, то мы считаем, что вкусы у них подобны, и по рейтингам тех или иных фильмов, проставленным Жаном-Пьером, можем угадать неизвестные рейтинги Джейсона. Например, если Жану-Пьеру понравились фильмы »Возвращение джедая» и »Империя наносит ответный удар», а Джейсону понравился фильм »Возвращение джедая», то мы определенно должны подсказать Джейсону и фильм »Империя наносит ответный удар». В принципе, для прогнозирования интересов Джейсона нужно найти несколько пользователей, с которыми у него схожие вкусы.
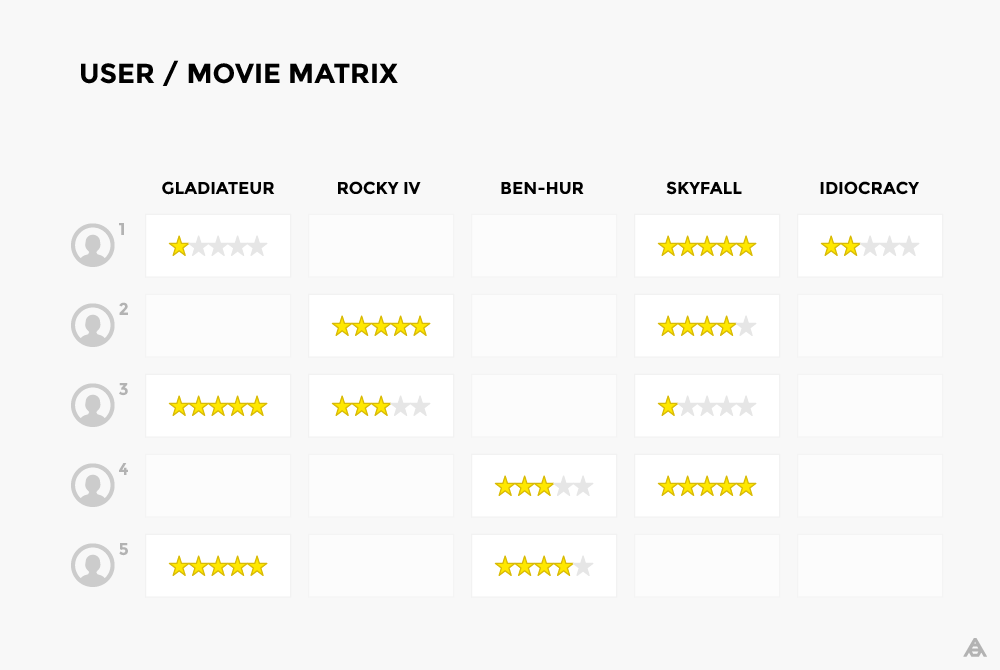
В таблице, где каждый ряд соответствует пользователю, а каждый столбец — фильму, просто найти сходство между рядами в матрице и, соответственно, подыскать пользователей с общими интересами.
Однако, такая реализация сопряжена с рядом проблем:
— Пользовательские предпочтения со временем меняются. В результате система может генерировать множество неактуальных рекомендаций;
— Чем больше количество пользователей, тем больше времени уходит на генерирование рекомендации
— Фильтрация пользователей уязвима для накрутки рейтингов, когда злоумышленник обманывает систему и необъективно повышает оценку одних продуктов по сравнению с другими.
Коллаборативная фильтрация по элементам
Процесс прост. Сходство двух элементов рассчитывается по рейтингам, выставленным пользователем. Вернемся к примеру с Жаном-Пьером и Джейсоном — как мы помним, обоим понравились фильмы »Возвращение джедая» и »Империя наносит ответный удар». Можно сделать вывод, что большинству пользователей, высоко оценивших первый фильм, должен понравиться и второй. Таким образом, было бы релевантно предложить фильм «Империя наносит ответный удар» Ларри, которому понравился фильм »Возвращение джедая».
Следовательно, сходство вычисляется по столбцам, а не по строкам (как понятно из матрицы с пользователями и фильмами, приведенной выше). Зачастую предпочитается именно коллаборативная фильтрация по элементам, так как она лишена всех недостатков, присущих пользовательской фильтрации. Во-первых, элементы в системе (здесь — фильмы) не изменяются со временем, поэтому рекомендации получатся более релевантными. Кроме того, элементов обычно гораздо меньше, чем пользователей, поэтому обработка данных при такой фильтрации происходит быстрее. В конечном итоге, такие системы гораздо сложнее обмануть.
Контентная рекомендательная система

В контентных рекомендательных системах рекомендации формулируются на основе атрибутов, присваиваемых каждому элементу. Термин «контент» относится именно к этим описаниям. Например, если изучить историю музыкальных интересов Софи, можно заметить, что ей нравится жанр кантри. Следовательно, система может рекомендовать ей композиции в стиле кантри, а также композиции схожих жанров. Более сложные системы в состоянии выявлять соотношения между множественными атрибутами и давать более качественные рекомендации. Так, на сайте Music Genome Project каждая композиция, имеющаяся в базе данных, категоризируется по 450 различным атрибутам. Именно на основе этого движка работает музыкальная рекомендательная система на сайте Pandora.
Экспертные рекомендательные системы
Экспертные рекомендательные системы особенно хороши для работы с такими элементами, которые приобретаются нечасто — например, дома, автомобили, финансовые активы или дорогие предметы роскоши. В таких случаях рекомендательный процесс осложняется из-за дефицита рейтингов по товарам. В экспертных системах рекомендации предлагаются не на основе рейтингов, а на базе сходства между пользовательскими требованиями и описанием продукта, либо в зависимости от ограничений, выставляемых пользователем при конкретизации желаемого продукта. Поэтому система такого типа получается уникальной, ведь она позволяет клиенту явно указать, чего он хочет. Что касается ограничений — в случаях, когда они вообще применяются — обычно такие ограничения известны с самого начала и реализуются экспертами в данной предметной области. Например, если пользователь явно указывает, что ищет недвижимость в данной ценовой категории, то система должна ориентироваться на данную спецификацию при подборе вариантов.
Проблема холодного старта в рекомендательных системах
Одна из важнейших проблем, связанных с рекомендательными системами, заключается в том, что исходное количество доступных рейтингов обычно невелико. Что делать, если новоиспеченный пользователь пока не рейтинговал фильмов, либо, если в систему добавился новый фильм? В таких случаях затруднительно применять традиционные модели коллаборативной фильтрации. Контентные методы и экспертные системы справляются с проблемой холодного старта увереннее коллаборативных моделей, но и они не всегда есть в распоряжении. Поэтому именно для таких случаев был разработан ряд альтернативных решений — например, гибридные системы.
Гибридные рекомендательные системы
Итак, у всех разнообразных рекомендательных систем, рассмотренных выше, есть свои достоинства и недостатки, и предлагаемые этими системами варианты базируются на разных исходных данных. Некоторые рекомендательные движки, в частности, экспертные системы, наиболее эффективны в контекстах, где количество доступных данных ограничено. Другие системы, например, коллаборативная фильтрация, лучше всего работают в средах, где имеются большие массивы данных. Зачастую, когда данные диверсифицированы, мы располагаем достаточной гибкостью, чтобы решать одну и ту же задачу разными методами. Следовательно, можно скомбинировать рекомендации, полученные несколькими способами, тем самым повысив качество системы в целом. Исследовано множество комбинаторных приемов, в том числе:
- Взвешенные: рекомендациям, полученным разными методами, присваивается различный вес — то есть, некоторые рекомендации считаются более предпочтительными, нежели другие.
- Смешанные: общий набор рекомендаций, без явного предпочтения тем или иным классам
- Дополненные: рекомендации от одной системы используются в качестве ввода для следующей, и так по цепочке.
- Переключение: выбор случайного метода
Один из наиболее известных гибридных движков — система, которая стала известна по результатам конкурса Netflix Prize и работала с 2006 по 2009 год. Цель проекта заключалась в совершенствовании рекомендательного движка Cinematch от Netflix, предлагавшего пользователям новые фильмы, а задача — увеличить точность попаданий не менее, чем на 10%. Команда Bellkor Pragmatix Chaos выиграла премию в 1 миллион долларов за решение, в котором комбинировалось 107 различных алгоритмов; их программа повысила точность Cinematch на 10.06%. Для справки: точность — это степень совпадения текущего рейтинга фильма с последующими выставляемыми ему оценками.
Что насчет ИИ?
Рекомендательные системы часто используются в контексте искусственного интеллекта. Возможность выдачи подсказок, прогнозирования событий и подчеркивание корреляций — все это результаты применения ИИ. С другой стороны, при воплощении рекомендательных систем часто используются приемы машинного обучения. Например, компания Arcbees написала эффективный рекомендательный движок, работающий на основе нейронных сетей и данных, которые берутся из IMdB. Нейронные сети позволяют быстро решать сложные задачи и с легкостью манипулировать большими данными. Взяв в качестве ввода список фильмов, и сопоставив вывод с пользовательскими оценками, сеть может усвоить правила и затем руководствоваться ими, прогнозируя дальнейшие рейтинги, которые может проставить конкретный пользователь.
Советы экспертов
Читая материалы по этой теме, я нашел два отличных совета от экспертов. Во-первых, базовым материалом для работы рекомендательного движка должны быть такие элементы, за которые пользователи готовы платить. В таком случае можно быть уверенным, что оценки выставляемые пользователями, будут довольно точными и релевантными. Во-вторых, всегда лучше опираться на совокупности алгоритмов, а не на единственный алгоритм. Хороший пример — Netflix Prize.
Реализация рекомендательной системы на основе подбора элементов
В следующем коде показано, как легко и быстро можно реализовать рекомендательный движок, в котором используется коллаборативная фильтрация. Код написан на Python, здесь использованы библиотеки Pandas и Numpy — одни из самых популярных в данном сегменте. В качестве массива данных использовались рейтинги фильмов, а само множество данных доступно на MovieLens.
Этап 1: Находим похожие фильмы
Считываем данные
import pandas as pd
ratings_cols = ['user_id', 'movie_id', 'rating']
ratings = pd.read_csv('u.data', sep='\t', names=ratings_cols, usecols=range(3))
movies_cols = ['movie_id', 'title']
movies = pd.read_csv('u.item', sep='|', names=movies_cols, usecols=range(2))
ratings = pd.merge(ratings, movies)
Строим матрицу фильмов для пользователя X
movieRatings = ratings.pivot_table(index=['user_id'],columns=['title'],values='rating')
Выбираем кино и генерируем индекс схожести (корреляции) между этим фильмом и всеми остальными
starWarsRatings = movieRatings['Star Wars (1977)']
similarMovies = movieRatings.corrwith(starWarsRatings)
similarMovies = similarMovies.dropna()
df = pd.DataFrame(similarMovies)Удаляем непопулярные фильмы, чтобы система не подкидывала нам неподходящих рекомендаций
ratingsCount = 100
movieStats = ratings.groupby('title').agg({'rating': [np.size, np.mean]})
popularMovies = movieStats['rating']['size'] >= ratingsCount
movieStats[popularMovies].sort_values([('rating', 'mean')], ascending=False)[:15]Извлекаем популярные фильмы, похожие на целевой
df = movieStats[popularMovies].join(pd.DataFrame(similarMovies, columns=['similarity']))
df.sort_values(['similarity'], ascending=False)[:15]
Этап 2: предлагаем пользователю рекомендации в зависимости от проставленных им оценок
Генерируем индекс схожести в каждой паре фильмов и оставляем только популярные
userRatings = ratings.pivot_table(index=['user_id'],columns=['title'],values='rating')
corrMatrix = userRatings.corr(method='pearson', min_periods=100)
Генерируем рекомендации для каждого фильма, просмотренного и оцененного нашим пользователем (здесь — данные для пользователя 0)
myRatings = userRatings.loc[0].dropna()
simCandidates = pd.Series()
for i in range(0, len(myRatings.index)):
# Извлекаем фильмы, похожие на оцененные мной
sims = corrMatrix[myRatings.index[i]].dropna()
# Далее оцениваем их сходство в зависимости от того, как я оценил тот или иной фильм
sims = sims.map(lambda x: x * myRatings[i])
# Добавляем индекс в список сравниваемых кандидатов
simCandidates = simCandidates.append(sims)
simCandidates.sort_values(inplace = True, ascending = False)
Суммируем показатели идентичных фильмов
simCandidates = simCandidates.groupby(simCandidates.index).sum()
simCandidates.sort_values(inplace = True, ascending = False)
Оставляем лишь те фильмы, которые пользователь еще не смотрел
filteredSims = simCandidates.drop(myRatings.index)Что дальше?
В вышеприведенном случае нам вполне удалось обработать множество данных MovieLens при помощи библиотеки Pandas на обычном процессоре. Однако, обработка более крупных наборов данных может занимать больше времени. В таких случаях могут помочь более мощные решения — например, Spark или MapReduce.
