[Перевод] Высокодоступный и масштабируемый Elasticsearch в Kubernetes

В предыдущем посте мы масштабировали набор реплик MongoDB и познакомились со StatefulSet. Сейчас мы займемся оркестрацией кластера высокой доступности Elasticsearch (с другими мастер-нодами, нодами данных и клиентскими нодами) и задействуем ES-HQ и Kibana.
Вам понадобятся:
- Базовое представление об Elasticsearch, его типах нод и их ролях.
- Работающий кластер Kubernetes как минимум с тремя нодами (не меньше четырех ядер, 4 ГБ).
- Умение работать с Kibana.
Архитектура развертывания
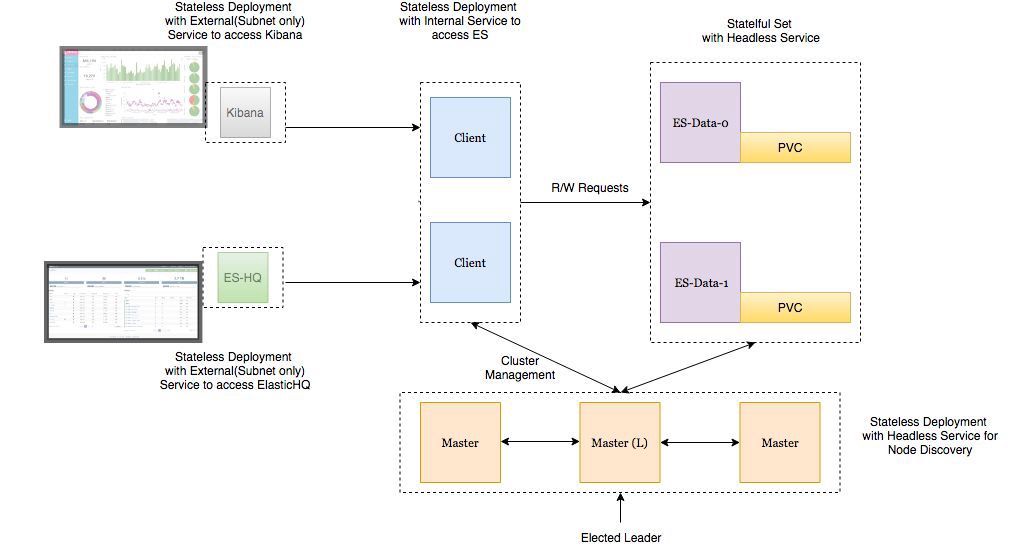
● Поды на нодах данных Elasticsearch развертываются как StatefulSet с headless сервисом, чтобы у нас были стабильные идентификаторы сети.
● Поды на мастернодах Elasticsearch развертываются как ReplicaSet с headless-сервисом. Это нужно для автообнаружения.
● Поды на клиентских нодах Elasticsearch развертываются как ReplicaSet с внутренним сервисом, чтобы можно было отправлять запросы на чтение/запись к нодам данных.
● Поды Kibana и ElasticHQ развертываются как ReplicaSet с сервисами, которые доступны за пределами кластера Kubernetes, но при этом находятся внутри подсети (не открываются наружу без необходимости).
● HPA (Horizonal Pod Autoscaler) развертывается для клиентских нод и отвечает за горизонтальное автомасштабирование при высокой нагрузке.
«Не забудьте настроить для среды:
- Переменную ES_JAVA_OPTS.
- Переменную CLUSTER_NAME.
- Переменную NUMBER_OF_MASTERS для деплоя мастеров, чтобы избежать ситуации split-brain. Если у нас 3 мастера, указываем 2.
- Правила anti-affinity для схожих подов, чтобы гарантировать высокую надежность, если отвалится рабочая нода.
»
Развернем-ка эти сервисы в кластере GKE.
kind: Namespace
metadata:
name: elasticsearch
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: es-master
namespace: elasticsearch
labels:
component: elasticsearch
role: master
spec:
replicas: 3
template:
metadata:
labels:
component: elasticsearch
role: master
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: role
operator: In
values:
- master
topologyKey: kubernetes.io/hostname
initContainers:
- name: init-sysctl
image: busybox:1.27.2
command:
- sysctl
- -w
- vm.max_map_count=262144
securityContext:
privileged: true
containers:
- name: es-master
image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4
env:
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: CLUSTER_NAME
value: my-es
- name: NUMBER_OF_MASTERS
value: "2"
- name: NODE_MASTER
value: "true"
- name: NODE_INGEST
value: "false"
- name: NODE_DATA
value: "false"
- name: HTTP_ENABLE
value: "false"
- name: ES_JAVA_OPTS
value: -Xms256m -Xmx256m
- name: PROCESSORS
valueFrom:
resourceFieldRef:
resource: limits.cpu
resources:
limits:
cpu: 2
ports:
- containerPort: 9300
name: transport
volumeMounts:
- name: storage
mountPath: /data
volumes:
- emptyDir:
medium: ""
name: "storage"
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-discovery
namespace: elasticsearch
labels:
component: elasticsearch
role: master
spec:
selector:
component: elasticsearch
role: master
ports:
- name: transport
port: 9300
protocol: TCP
clusterIP: None
view rawes-master.yml hosted with love by GitHub
(Деплой и headless-сервис для мастер-нод)
root$ kubectl -n elasticsearch get all
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/es-master 3 3 3 3 32s
NAME DESIRED CURRENT READY AGE
rs/es-master-594b58b86c 3 3 3 31s
NAME READY STATUS RESTARTS AGE
po/es-master-594b58b86c-9jkj2 1/1 Running 0 31s
po/es-master-594b58b86c-bj7g7 1/1 Running 0 31s
po/es-master-594b58b86c-lfpps 1/1 Running 0 31s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/elasticsearch-discovery ClusterIP None 9300/TCP 31s
Интересно изучить логи подов на мастер-нодах и посмотреть, как выбирается среди них мастер сейчас и как это будет потом, когда мы добавим новые ноды данных и клиентские ноды.
root$ kubectl -n elasticsearch logs -f po/es-master-594b58b86c-9jkj2 | grep ClusterApplierService
[2018-10-21T07:41:54,958][INFO ][o.e.c.s.ClusterApplierService] [es-master-594b58b86c-9jkj2] detected_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},{es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3]])
Здесь видно, что под es-master с именем es-master-594b58b86c-bj7g7 выбран мастером, а остальные два пода добавлены к нему и друг к другу.
headless сервис elasticsearch-discovery по умолчанию устанавливается в образе Docker как переменная среды и служит для обнаружения в нодах. Эту настройку при желании можно заменить.
Точно так же мы развертываем ноды данных и клиентские ноды. Конфигурации смотрите ниже.
Деплой нод данных:
kind: Namespace
metadata:
name: elasticsearch
---
apiVersion: storage.k8s.io/v1beta1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
fsType: xfs
allowVolumeExpansion: true
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: es-data
namespace: elasticsearch
labels:
component: elasticsearch
role: data
spec:
serviceName: elasticsearch-data
replicas: 3
template:
metadata:
labels:
component: elasticsearch
role: data
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: role
operator: In
values:
- data
topologyKey: kubernetes.io/hostname
initContainers:
- name: init-sysctl
image: busybox:1.27.2
command:
- sysctl
- -w
- vm.max_map_count=262144
securityContext:
privileged: true
containers:
- name: es-data
image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4
env:
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: CLUSTER_NAME
value: my-es
- name: NODE_MASTER
value: "false"
- name: NODE_INGEST
value: "false"
- name: HTTP_ENABLE
value: "false"
- name: ES_JAVA_OPTS
value: -Xms256m -Xmx256m
- name: PROCESSORS
valueFrom:
resourceFieldRef:
resource: limits.cpu
resources:
limits:
cpu: 2
ports:
- containerPort: 9300
name: transport
volumeMounts:
- name: storage
mountPath: /data
volumeClaimTemplates:
- metadata:
name: storage
annotations:
volume.beta.kubernetes.io/storage-class: "fast"
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: fast
resources:
requests:
storage: 10Gi
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-data
namespace: elasticsearch
labels:
component: elasticsearch
role: data
spec:
ports:
- port: 9300
name: transport
clusterIP: None
selector:
component: elasticsearch
role: data
view rawes-data.yml hosted with love by GitHub
(StatefulSet и headless сервис для нод данных)
headless сервис на нодах данных выдает нодам стабильные идентификаторы сети и помогает передавать данные между нодами.
Важно отформатировать постоянный том, прежде чем привязывать его к поду. Просто укажите тип тома, когда создаете класс хранилища. Еще можно задать параметр, разрешающий автомтическое расширение тома. Подробности читайте здесь.
parameters:
type: pd-ssd
fsType: xfs
allowVolumeExpansion: true
...
Деплой клиентских нод:
kind: Namespace
metadata:
name: elasticsearch
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: es-client
namespace: elasticsearch
labels:
component: elasticsearch
role: client
spec:
replicas: 2
template:
metadata:
labels:
component: elasticsearch
role: client
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: role
operator: In
values:
- client
topologyKey: kubernetes.io/hostname
initContainers:
- name: init-sysctl
image: busybox:1.27.2
command:
- sysctl
- -w
- vm.max_map_count=262144
securityContext:
privileged: true
containers:
- name: es-client
image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4
env:
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: CLUSTER_NAME
value: my-es
- name: NODE_MASTER
value: "false"
- name: NODE_DATA
value: "false"
- name: HTTP_ENABLE
value: "true"
- name: ES_JAVA_OPTS
value: -Xms256m -Xmx256m
- name: NETWORK_HOST
value: _site_,_lo_
- name: PROCESSORS
valueFrom:
resourceFieldRef:
resource: limits.cpu
resources:
limits:
cpu: 1
ports:
- containerPort: 9200
name: http
- containerPort: 9300
name: transport
volumeMounts:
- name: storage
mountPath: /data
volumes:
- emptyDir:
medium: ""
name: storage
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: elasticsearch
annotations:
cloud.google.com/load-balancer-type: Internal
labels:
component: elasticsearch
role: client
spec:
selector:
component: elasticsearch
role: client
ports:
- name: http
port: 9200
type: LoadBalancer
view rawes-client.yml hosted with love by GitHub
(Деплой и внешний сервис для клиентских нод)
Развернутый здесь сервис открывает доступ к кластеру ES снаружи кластера Kubernetes, но все равно находится внутри подсети. За это отвечает аннотация cloud.google.com/load-balancer-type: Internal.
Но если приложение, которое обращается к кластеру ES для чтения и записи, развернуть внутри кластера, то доступ к сервису ElasticSearch можно получить по адресу http://elasticsearch.elasticsearch:9200.
Когда вы развернете ноды данных и клиентские ноды, они добавятся в кластер автоматически. (Ищите мастер-под в логах)
root$ kubectl -n elasticsearch get pods -l role=data
NAME READY STATUS RESTARTS AGE
es-data-0 1/1 Running 0 48s
es-data-1 1/1 Running 0 28s
--------------------------------------------------------------------
root$ kubectl apply -f es-client.yml
root$ kubectl -n elasticsearch get pods -l role=client
NAME READY STATUS RESTARTS AGE
es-client-69b84b46d8-kr7j4 1/1 Running 0 47s
es-client-69b84b46d8-v5pj2 1/1 Running 0 47s
--------------------------------------------------------------------
root$ kubectl -n elasticsearch get all
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/es-client 2 2 2 2 1m
deploy/es-master 3 3 3 3 9m
NAME DESIRED CURRENT READY AGE
rs/es-client-69b84b46d8 2 2 2 1m
rs/es-master-594b58b86c 3 3 3 9m
NAME DESIRED CURRENT AGE
statefulsets/es-data 2 2 3m
NAME READY STATUS RESTARTS AGE
po/es-client-69b84b46d8-kr7j4 1/1 Running 0 1m
po/es-client-69b84b46d8-v5pj2 1/1 Running 0 1m
po/es-data-0 1/1 Running 0 3m
po/es-data-1 1/1 Running 0 3m
po/es-master-594b58b86c-9jkj2 1/1 Running 0 9m
po/es-master-594b58b86c-bj7g7 1/1 Running 0 9m
po/es-master-594b58b86c-lfpps 1/1 Running 0 9m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/elasticsearch LoadBalancer 10.9.121.160 10.9.120.8 9200:32310/TCP 1m
svc/elasticsearch-data ClusterIP None 9300/TCP 3m
svc/elasticsearch-discovery ClusterIP None 9300/TCP 9m
--------------------------------------------------------------------
#Check logs of es-master leader pod
root$ kubectl -n elasticsearch logs po/es-master-594b58b86c-bj7g7 | grep ClusterApplierService
[2018-10-21T07:41:53,731][INFO ][o.e.c.s.ClusterApplierService] [es-master-594b58b86c-bj7g7] new_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300}]]])
[2018-10-21T07:41:55,162][INFO ][o.e.c.s.ClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3] source [zen-disco-node-join[{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300}]]])
[2018-10-21T07:48:02,485][INFO ][o.e.c.s.ClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [4] source [zen-disco-node-join[{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300}]]])
[2018-10-21T07:48:21,984][INFO ][o.e.c.s.ClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [5] source [zen-disco-node-join[{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300}]]])
[2018-10-21T07:50:51,245][INFO ][o.e.c.s.ClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [6] source [zen-disco-node-join[{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300}]]])
[2018-10-21T07:50:58,964][INFO ][o.e.c.s.ClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [7] source [zen-disco-node-join[{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300}]]])
В логах главного мастер-пода хорошо видно, когда каждая нода добавляется в кластер. Это полезно знать при отладке.
Мы развернули все компоненты, и теперь нужно проверить:
1) Деплой Elasticsearch из кластера Kubernetes с помощью контейнера Ubuntu.
root$ kubectl run my-shell --rm -i --tty --image ubuntu -- bash
root@my-shell-68974bb7f7-pj9x6:/# curl http://elasticsearch.elasticsearch:9200/_cluster/health?pretty
{
"cluster_name" : "my-es",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 7,
"number_of_data_nodes" : 2,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
2) Деплой Elasticsearch снаружи кластера по IP внутреннего балансировщика GCP (в нашем случае — 10.9.120.8).
root$ curl http://10.9.120.8:9200/_cluster/health?pretty
{
"cluster_name" : "my-es",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 7,
"number_of_data_nodes" : 2,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
3) Правила anti-affinity для подов ES.
root$ kubectl -n elasticsearch get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
es-client-69b84b46d8-kr7j4 1/1 Running 0 10m 10.8.14.52 gke-cluster1-pool1-d2ef2b34-t6h9
es-client-69b84b46d8-v5pj2 1/1 Running 0 10m 10.8.15.53 gke-cluster1-pool1-42b4fbc4-cncn
es-data-0 1/1 Running 0 12m 10.8.16.58 gke-cluster1-pool1-4cfd808c-kpx1
es-data-1 1/1 Running 0 12m 10.8.15.52 gke-cluster1-pool1-42b4fbc4-cncn
es-master-594b58b86c-9jkj2 1/1 Running 0 18m 10.8.15.51 gke-cluster1-pool1-42b4fbc4-cncn
es-master-594b58b86c-bj7g7 1/1 Running 0 18m 10.8.16.57 gke-cluster1-pool1-4cfd808c-kpx1
es-master-594b58b86c-lfpps 1/1 Running 0 18m 10.8.14.51 gke-cluster1-pool1-d2ef2b34-t6h9
Заметьте — у нас нет двух похожих подов на одной ноде, так что мы обеспечили высокую надежность при отказе ноды.
Масштабирование
Мы можем развернуть сервисы автомасштабирования для клиентских нод в зависимости от лимита ЦП. Пример HPA для клиентской ноды:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: es-client
namespace: elasticsearch
spec:
maxReplicas: 5
minReplicas: 2
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: es-client
targetCPUUtilizationPercentage: 80
Автомасштабирование добавляет поды на клиентской ноде в кластер, и это видно в логах любого пода на мастер-ноде.
Что касается подов на нодах данных, нужно просто увеличить число реплик на панели управления Kubernetes или в консоли GKE. Созданная нода данных сама добавится в кластер и начнет реплицировать данные с других нод.
Подам на мастер-нодах автомасштабирование не нужно — они хранят только данные о состоянии кластера. Но если вы собираетесь добавлять ноды данных, следите, чтобы число мастер-нод в кластере было нечетным, и не забывайте менять для среды переменную NUMBER_OF_MASTERS.
Деплой Kibana и ES-HQ
Kibana и ES-HQ
Kibana — это простой инструмент для визуализации данных ES, а ES-HQ помогает администрировать и мониторить кластер Elasticsearch. При деплое Kibana и ES-HQ помните, что:
● Мы передаем образу Docker имя кластера ES как переменную среды.
● Сервис для доступа к деплою Kibana/ES-HQ остается внутри компании, то есть общедоступный IP не создается. Мы используем внутренний балансировщик нагрузки GCP.
Деплой Kibana
kind: Namespace
metadata:
name: elasticsearch
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: es-kibana
namespace: elasticsearch
labels:
component: elasticsearch
role: kibana
spec:
replicas: 1
template:
metadata:
labels:
component: elasticsearch
role: kibana
spec:
containers:
- name: es-kibana
image: docker.elastic.co/kibana/kibana-oss:6.2.2
env:
- name: CLUSTER_NAME
value: my-es
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
resources:
limits:
cpu: 0.5
ports:
- containerPort: 5601
name: http
---
apiVersion: v1
kind: Service
metadata:
name: kibana
annotations:
cloud.google.com/load-balancer-type: "Internal"
namespace: elasticsearch
labels:
component: elasticsearch
role: kibana
spec:
selector:
component: elasticsearch
role: kibana
ports:
- name: http
port: 80
targetPort: 5601
protocol: TCP
type: LoadBalancer
view rawes-kibana.yml hosted with love by GitHub
(Деплой и сервис Kibana)
Деплой ES-HQ
kind: Namespace
metadata:
name: elasticsearch
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: es-hq
namespace: elasticsearch
labels:
component: elasticsearch
role: hq
spec:
replicas: 1
template:
metadata:
labels:
component: elasticsearch
role: hq
spec:
containers:
- name: es-hq
image: elastichq/elasticsearch-hq:release-v3.4.0
env:
- name: HQ_DEFAULT_URL
value: http://elasticsearch:9200
resources:
limits:
cpu: 0.5
ports:
- containerPort: 5000
name: http
---
apiVersion: v1
kind: Service
metadata:
name: hq
annotations:
cloud.google.com/load-balancer-type: "Internal"
namespace: elasticsearch
labels:
component: elasticsearch
role: hq
spec:
selector:
component: elasticsearch
role: hq
ports:
- name: http
port: 80
targetPort: 5000
protocol: TCP
type: LoadBalancer
view rawes-hq.yml hosted with love by GitHub
(Деплой и сервис ES-HQ)
К обоим сервисам мы обращаемся через созданный внутренний балансировщик.
root$ kubectl -n elasticsearch get svc -l role=kibana
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kibana LoadBalancer 10.9.121.246 10.9.120.10 80:31400/TCP 1m
root$ kubectl -n elasticsearch get svc -l role=hq
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hq LoadBalancer 10.9.121.150 10.9.120.9 80:31499/TCP 1m
http://
(Панель управления Kibana)
http://
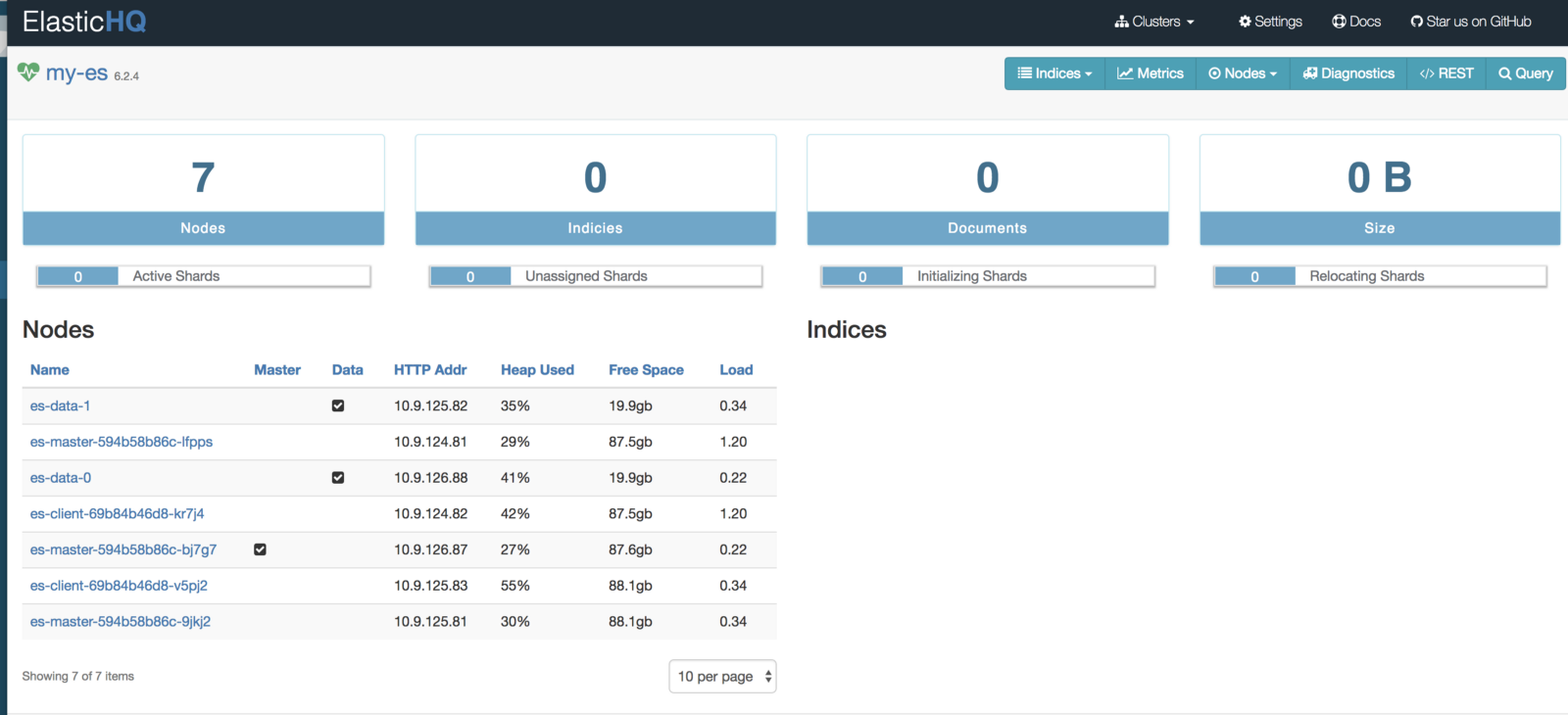
(Панель управления ElasticHQ для мониторинга и управления кластером)
ES — это одна из самых популярных распределенных систем поиска и анализа, а в Kubernetes она решает ключевые проблемы машстабирования и высокой доступности. К тому же новые кластеры ES в Kubernetes развертываются моментально.
