Десятиклассница из Сибири хочет стать проектировщицей процессоров. Почему бы ей не сделать нейроускоритель на ПЛИС?
Вчера мне пришло письмо от десятиклассницы из Сибири, которая хочет стать разработчицей микропроцессоров. Она уже получила некоторый результат в этой области — добавила инструкцию умножения в простейший процессор schoolMIPS, синтезировала его для ПЛИС Intel FPGA MAX10, определила максимальную частоту и повышение производительности простых программ. Все это она сначала делала в деревне Бурмистрово Новосибирской Области, а потом на конференции в Томске.
Теперь Даша Криворучко (так зовут десятиклассницу) переехала жить в московский интернат и спрашивает у меня, чего бы ей еще спроектировать. Я думаю, что на этом этапе карьеры ей стоит спроектировать аппаратный ускоритель нейросетей на основе систолического массива для умножения матриц. Использовать язык описания аппаратуры Verilog и ПЛИС Intel FPGA, но не дешевенький MAX10, а что-нибудь подороже, чтобы вместить большой систолический массив.
После этого сравнить производительность аппаратного решения с программой, работающей на процессоре schoolMIPS, а также с программой на Питоне, работающей на десктопном компьютере. В качестве тестового примера использовать распознавание цифр с небольшой матрицы.

Собственно все части этого упражнения уже разработаны разными людьми, но вся фишка в том, чтобы скомпоновать это в единое задокументированное упражнение, которое можно потом использовать как основу для онлайн курса и для практических олимпиад:
1) В онлайн-курсе такого рода (проектирование хардвера на уровне регистровых передач + нейросети) заинтересовано eNano, образовательное отделение РОСНАНО, которое в прошлом организовало семинары Чарльза Данчека по проектированию современной электроники (маршрут RTL-to-GDSII) для студентов и сейчас работает над облегченным курсом для продвинутых школьников. Вот мы с Чарльзом у их офиса:

2) В базе для олимпиад может быть заинтересованы Олимпиады НТИ, с которыми я затронул этот вопрос пару недель назад в Москве. К такому примеру участники олимпиад могли бы добавлять хардвер для разных функций активации. Вот коллеги из Олимпиад НТИ:

Так что если Даша это разработает, она теоретически может внедрить свой хорошо описанный акселератор и в РОСНАНО, и в Олимпиады НТИ. Я думаю, для администрации ее школы это было бы выгодно — можно было бы по телевизору показать или вообще на конкурс Intel FPGA отправить. Вот пара россиян из Санкт-Петербурга на финале конкурса Intel FPGA в Санта-Клара, Калифорния:

Теперь поговорим про техническую сторону проекта. Идея акселератора систолического массива описана в статье, которую перевел редактор Хабра Вячеслав Голованов SLY_G Почему TPU так хорошо подходят для глубинного обучения?
Так выглядит dataflow граф нейросети для простого распознавания:

Примитивный вычислительный элемент, который выполняет умножения и сложения:

Сильно конвейеризованная структура из таких элементов, это систолический массив для умножения матриц и есть:

В интернете есть куча кода на Verilog и VHDL с реализацией систолического массива, например код вот под этим блог-постом:

module top(clk,reset,a1,a2,a3,b1,b2,b3,c1,c2,c3,c4,c5,c6,c7,c8,c9);
parameter data_size=8;
input wire clk,reset;
input wire [data_size-1:0] a1,a2,a3,b1,b2,b3;
output wire [2*data_size:0] c1,c2,c3,c4,c5,c6,c7,c8,c9;
wire [data_size-1:0] a12,a23,a45,a56,a78,a89,b14,b25,b36,b47,b58,b69;
pe pe1 (.clk(clk), .reset(reset), .in_a(a1), .in_b(b1), .out_a(a12), .out_b(b14), .out_c(c1));
pe pe2 (.clk(clk), .reset(reset), .in_a(a12), .in_b(b2), .out_a(a23), .out_b(b25), .out_c(c2));
pe pe3 (.clk(clk), .reset(reset), .in_a(a23), .in_b(b3), .out_a(), .out_b(b36), .out_c(c3));
pe pe4 (.clk(clk), .reset(reset), .in_a(a2), .in_b(b14), .out_a(a45), .out_b(b47), .out_c(c4));
pe pe5 (.clk(clk), .reset(reset), .in_a(a45), .in_b(b25), .out_a(a56), .out_b(b58), .out_c(c5));
pe pe6 (.clk(clk), .reset(reset), .in_a(a56), .in_b(b36), .out_a(), .out_b(b69), .out_c(c6));
pe pe7 (.clk(clk), .reset(reset), .in_a(a3), .in_b(b47), .out_a(a78), .out_b(), .out_c(c7));
pe pe8 (.clk(clk), .reset(reset), .in_a(a78), .in_b(b58), .out_a(a89), .out_b(), .out_c(c8));
pe pe9 (.clk(clk), .reset(reset), .in_a(a89), .in_b(b69), .out_a(), .out_b(), .out_c(c9));
endmodule
module pe(clk,reset,in_a,in_b,out_a,out_b,out_c);
parameter data_size=8;
input wire reset,clk;
input wire [data_size-1:0] in_a,in_b;
output reg [2*data_size:0] out_c;
output reg [data_size-1:0] out_a,out_b;
always @(posedge clk)begin
if(reset) begin
out_a<=0;
out_b<=0;
out_c<=0;
end
else begin
out_c<=out_c+in_a*in_b;
out_a<=in_a;
out_b<=in_b;
end
end
endmodule
Замечу, что этот код не оптимизирован и вообще корявый (и даже непрофессионально написан — исходник в посте использует блокирующие присваивания в @ (posedge clk) — я это поправил). Даша могла бы например использовать конструкции Verilog generate для более элегантного кода.
Кроме двух экстремальных реализаций нейросети (на процессоре и на систолическом массиве) Даша могла бы рассмотреть и другие варианты, которые быстрее чем процессор, но не такие прожорливые на операции умножение как систолический массив. Правда это уже скорее не для школьников, а для студентов.
Один вариант — это выполняющее устройство с большим количеством параллельно работающих функциональных блоков, как в Out-of-Order процессоре:

Другой вариант — это так называемый Coarse Grained Reconfigurable Array — матрица из квази-процессорных элементов, у каждого из которых есть небольшая программа. Эти процессорные элементы идейно похожи на ячейки ПЛИС/FPGA, но оперируют не с отдельными сигналами, а с группами бит / числами на шинах и в регистрах — см. Прямой репортаж с рождения крупного игрока в аппаратном AI, который ускоряет TensorFlow и конкурирует с NVidia».
Теперь собственно исходное письмо от Даши:
Доброго времени суток, Юрий.
Я в 2017 году в ЛШЮПе училась в у вас в мастерской и в октябре 2017 года участвовала в конференции в Томске в октябре того же года с работой посвящённой встраиванию блока умножения в процессор SchooolMIPS.
Я бы сейчас хотела продолжить эту работу. В данный момент мне удалось получить разрешение в школе взять эту тему в качестве небольшой курсовой. У вас есть возможность помочь мне с продолжением данной работы?
P.S. Поскольку работа делается в определенном формате, требуется написание введения и литературного обзора темы. Посоветуйте, пожалуйста, источники, из которых можно взять информацию по истории развития данной темы, по философиям архитектур и прочее, если у вас есть такие ресурсы на примете.
Плюсом, в данный момент я проживаю в Москве в школе-интернате, возможно, будет проще осуществлять взаимодействие.
С уважением,
Дарья Криворучко.
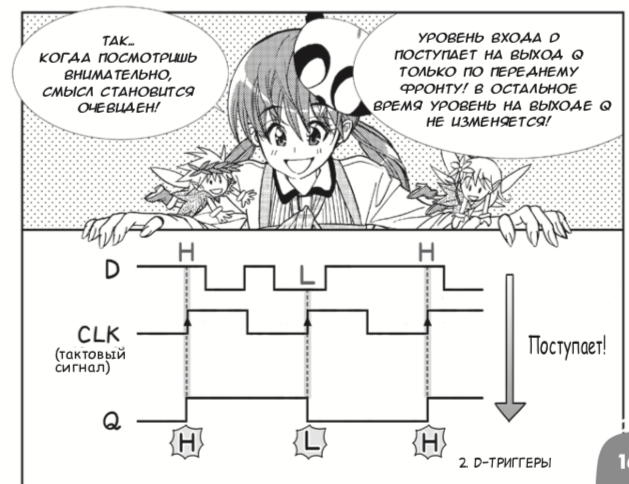
Даша учила Verilog и проектирование на уровне регистровых передач с помощью меня и книжки Дэвида Харриса и Сары Харрис «Цифровая схемотехника и архитектура компьютера». Однако если вы школьник/школьница и хотите понять основные концепции ну на совсем простом уровне, то для вас издательство ДМК-Пресс выпустило русский перевод японской манги 2013 года про цифровые схемы, созданной Амано Хидэхару и Мэгуро Кодзи. Несмотря на несерьезную форму изложения, книжка корректно вводит логические элементы и D-триггеры, после чего привязывает это к ПЛИС-ам:
Вот как выглядела Летняя Школа Юных Программистов в Новосибирской области, где Даша выучила Verilog, ПЛИС, методологию разработки на уровне регистровых передач (Register Transfer Level — RTL):


А вот выступление Даши на конференции в Томске вместе с другим десятиклассником, Арсением Чегодаевым:
После выступления Даша со мной и с Станиславом Жельнио sparf, главным создателем учебного процессорного ядра schoolMIPS для реализации на ПЛИС:

Проект schoolMIPS находится с документацией на https://github.com/MIPSfpga/schoolMIPS. В простейшей конфигурации этого учебного процессорного ядра всего 300 строк на Verilog, в то время как в промышленном встроенном ядре среднего класса примерно 300 тысяч строк. Тем не менее, Даша смогла почувствовать, как выглядит работа проектировшиков в индустрии, которые точно так же меняют декодер и выполняющее устройство, когда добавляют в процессор новую инструкцию:
В заключение приведем фотографии декана Самарского Университета Ильи Кудрявцева, который заинтересован в создании летней школы и олимпиад с процессорами на ПЛИС для будущих абитуриетов:

И фотографию сотрудников зеленоградского МИЭТ, которые уже планируют такую летнюю школу в следуюшем году:

И в одном, и в другом месте должны хорошо пойти как материалы от РОСНАНО, так и возможные материалы Олимпиады НТИ, а также наработки, которые сделаны в последние пару лет во внедрении ПЛИС и микроархитектуры в программу университетов ВШЭ МИЭМ, МГУ и казанского Иннополиса.
