[Перевод] Создание расширения для браузера Google Chrome. Часть 1
Введение
Расширения браузера это web-приложения, которые устанавливаются в web-браузер, чтобы расширить его возможности. Обычно, для того чтобы воспользоваться расширением, пользователю нужно найти его в Chrome Web Store и установить.
В этой статье я покажу как создать расширение для браузера Google Chrome с нуля. Это расширение будет использовать API браузера, для того чтобы получить доступ к содержимому web-страницы любой открытой вкладки. С помощью этих API можно не только читать информацию с открытых web-сайтов, но и взаимодействовать с этими страницами, например, переходить по ссылкам или нажимать на кнопки. Таким образом расширения браузера могут использоваться для широкого круга задач автоматизации на стороне клиента, таких как web-scrape или даже автоматизированное тестирование frontend.
Мы создадим расширение, которое называется Image Grabber. Оно будет содержать интерфейс для подключения к web-странице и для извлечения из нее информации о всех изображениях. Далее, при нажатии на кнопку »GRAB NOW» список абсолютных URL этих изображений будет скопирован в буфер обмена. В этом процессе вы познакомитесь с фундаментальными строительными блоками, которые в дальнейшем можно будет использовать для создания других расширений.
Расширения, создаваемые таким образом для браузера Chrome совместимы с другими браузерами, основанными на движке Chromium и могут быть установлены, например, в Yandex-браузер или Opera.
В результате при правильном выполнении всех шагов, вы получите расширение, которое будет выглядеть и работать так, как показано на следующем видео:
Это только первая часть истории. Во второй части, я покажу как расширить интерфейс, чтобы выгрузить все или выбранные изображения в виде ZIP-архива, а также, как опубликовать свое расширение в Chrome Web Store.
Базовая структура расширения
Расширение Google Chrome это web-приложение, содержащее любое количество HTML-страниц, файлов CSS и изображений, а также, файл manifest.json, который определяет как расширение выглядит и работает. Все эти файлы должны быть в одной папке.
Минимальное расширение состоит только из одного файла manifest.json. Вот пример этого файла, который вы можете использовать как шаблон при начале создания любого расширения:
{
"name": "Image Grabber",
"description": "Extract all images from current web page",
"version": "1.0",
"manifest_version": 3,
"icons": {},
"action": {},
"permissions": [],
"background":{}
}Здесь только manifest_version должен быть равен 3. Остальные поля заполняются произвольно в зависимости от назначения расширения: name — название расширения, description — краткое описание, version — версия. Остальные параметры мы будем заполнять по ходу разработки интерфейса. Полный список параметров manifest.json можно найти в официальной документации.
Папка с одним файлом manifest.json это минимальное расширение, которое может быть установлено в Google Chrome и запущено. Оно ничего не будет делать, однако именно с установки нужно начинать. Поэтому создайте папку image_grabber, затем добавьте в нее текстовый файл manifest.json с содержимым приведенным выше.
Установка расширения
В процессе разработки расширения, оно представляет собой папку с файлами. В терминологии Google Chrome это называется «unpacked extension». После завершения разработки, его нужно упаковать в ZIP-архив и загрузить в Chrome Web Store, откуда оно потом может быть установлено в браузер.
Однако на этапе разработки, «unpacked extension» тоже можно установить, просто как папку с файлами. Для этого нужно ввести chrome://extensions в браузере, чтобы открыть Chrome Extensions Manager:
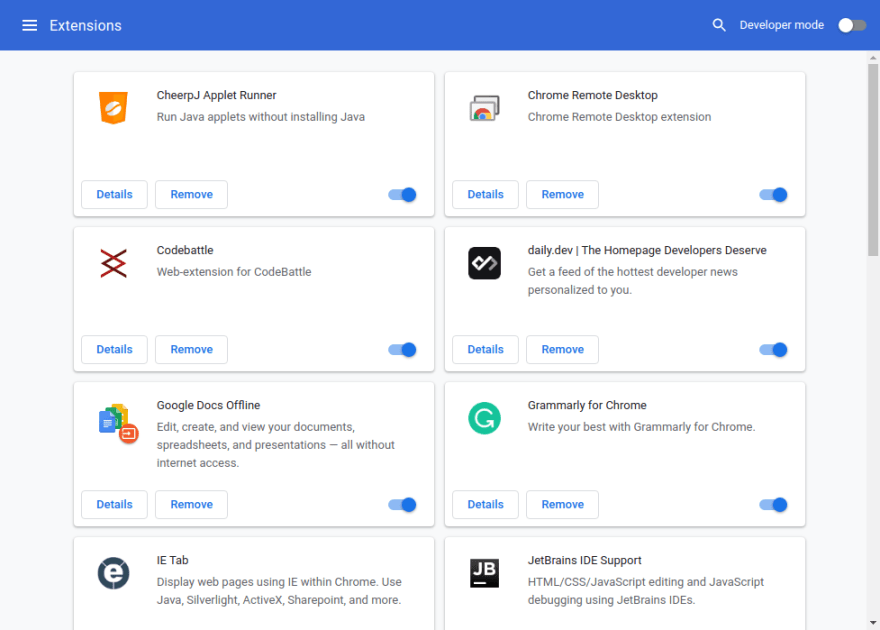
Это покажет список уже установленных расширений. Чтобы устанавливать в него «unpacked extensions», включите флажок «Developer mode» в правом верхнем углу. После этого должна отобразиться панель управления расширениями.
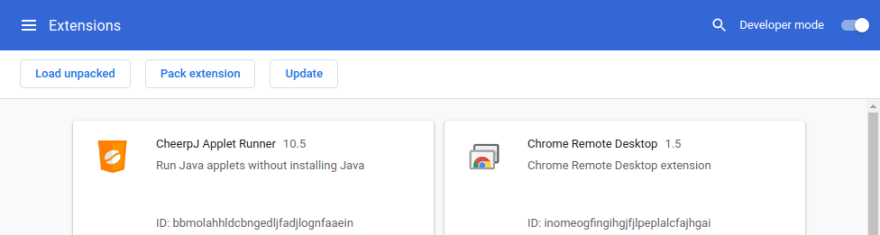
Затем нажмите первую кнопку Load unpacked и укажите папку, в которой находится расширение с файлом manifest.json. В нашем случае это папка image_grabber. Расширение должно отобразиться в списке:
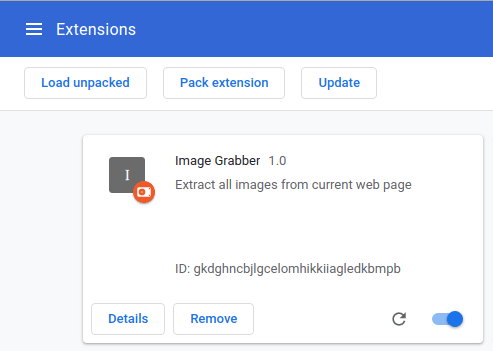
Эта панель должна показывать данные расширения такие как имя, описание и версию, ранее указанные в manifest.json, а также уникальный идентификатор, присвоенный этому расширению. Каждый раз после изменения manifest.json нужно обновлять расширение в браузере, нажимая на кнопку »Reload»:
Чтобы запустить и использовать установленное расширение в браузере, нажмите кнопку Extensions на панели инструментов Google Chrome рядом с URL и найдите »Image Grabber» в списке установленных расширений:
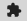
Также можно нажать иконку Pin в списке рядом с расширением, чтобы добавить кнопку данного расширения на панель Chrome, рядом с другими расширениями:


Вот как выглядит установленное минимальное расширение — кнопка с серым прямоугольником и буквой внутри (буква это первый символ в названии расширения Image Grabber). Естественно это не та картинка, которая нужна. Более того, когда мы нажимаем на эту кнопку ничего не происходит. Давайте заполним остальные поля файла manifest.json чтобы это исправить.
Добавление иконок
Параметр icons файла manifest.json принимает объект Javascript, ключами которого являются размеры иконок, а значениями пути к файлам, которые эти иконки содержат. Иконка это картинка с расширением PNG (для прозрачности). Расширение должно иметь иконки разных размеров: 16×16, 32×32, 48×48 и 128×128. Я создал иконки для всех этих размеров и поместил их в подпапку »icons» внутри папки с расширением. Сделайте то же самое. Имена файлов могут быть любыми:
{
"name": "Image Grabber",
"description": "Extract all images from current web page",
"version": "1.0",
"manifest_version": 3,
"icons": {
"16":"icons/16.png",
"32":"icons/32.png",
"48":"icons/48.png",
"128":"icons/128.png"
},
"action": {},
"permissions": [],
"background":{}
}Как видно, здесь указаны относительные пути к файлам в папке icons.
После изменения manifest.json нажмите кнопку »Reload» на панели расширения Image Grabber в Chrome Extensions Manager чтобы обновить установленное расширение. Если все сделано как описано выше, то картинка на кнопке расширения должна измениться:

Так значительно лучше, однако когда мы нажимаем на эту кнопку все еще ничего не происходит. Пришло время добавить «действия» (actions) к расширению.
Создание интерфейса расширения
Расширение должно что-то делать, то есть запускать определенные действия. Расширение может выполнять действия двумя способами:
В фоне, при запуске расширения и при дальнейшей его работе
Из интерфейса, когда пользователь нажимает кнопку расширения и затем взаимодействует с различными интерфейсными элементами.
Расширение может использовать обе эти возможности одновременно.
Чтобы запускать действия в фоне, нужно создать Javascript-файл и указать путь к нему в параметре »background» файла manifest.json. Этот скрипт должен содержать функции-обработчики различных событий браузера или жизненного цикла самого расширения, например когда пользователь открывает или закрывает вкладку браузера, когда пользователь добавляет/удаляет закладку и другие. Background-скрипт слушает эти события и запускает написанные для них функции обработчики.
Однако в этом расширении мы этим пользоваться не будем и параметр «background» останется пустым. Он присутствует только для того чтобы показать что это возможно и что данный файл manifest.json может использоваться для создания расширений любого типа. Однако расширение Image Grabber выполняет действия только когда пользователь нажимает кнопку »GRAB NOW» из интерфейса.
Соответственно мы создадим интерфейс для расширения. Интерфейс расширения это фактически Web-сайт, состоящий из HTML-страниц с элементами управления, CSS-таблиц стилей и скриптов, которые реагируют на события элементов управления из этих HTML-страниц и выполняют определенные действия, используя в частности API расширений Google Chrome.
Интерфейс должен содержать главную страницу, которая появляется когда пользователь нажимает на кнопку расширения. Эта страница может появляться либо в новой вкладке браузера, либо внутри всплывающего окна, как было показано на видео. Именно так и будет реализован интерфейс Image Grabber. Чтобы создать интерфейс всплывающего окна, внесите следующие изменения в manifest.json:
{
"name": "Image Grabber",
"description": "Extract all images from current web page",
"version": "1.0",
"manifest_version": 3,
"icons": {
"16":"icons/16.png",
"32":"icons/32.png",
"48":"icons/48.png",
"128":"icons/128.png"
},
"action": {
"default_popup":"popup.html"
},
"permissions": [],
"background":{}
}Здесь определено что основное действие (action) расширения это всплывающее окно (popup), которое содержит страницу popup.html.
Теперь создать файл popup.html с заголовком Image Grabber и кнопкой «GRAB NOW» и поместите его в папку с расширением:
Image Grabber
Image Grabber
Кнопка имеет идентификатор grabBtn который в дальнейшем будет использоваться из скрипта чтобы реагировать на нажатия этой кнопки.
Чтобы увидеть что изменилось, снова обновите расширение в Chrome Extensions Manager. Если все было сделано как написано выше, то при нажатии на иконку расширения будет появляться содержимое файла popup.html во всплывающем окне:
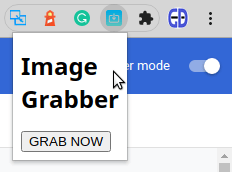
Работает! Но выглядит не очень. Теперь нужно стилизовать этот интерфейс с помощью CSS.
Создайте файл popup.css со следующим содержимым и поместите его в папку с расширением:
body {
text-align:center;
width:200px;
}
button {
width:100%;
color:white;
background:linear-gradient(#01a9e1, #5bc4bc);
border-width:0px;
border-radius:20px;
padding:5px;
font-weight: bold;
cursor:pointer;
}Этот файл определяет стили для кнопки и для body всей страницы: все содержимое должно быть выровнено по центру, а также, ширина содержимого должна быть 200 пикселей.
Добавьте ссылку на файл с этими стилями в popup.html:
Image Grabber
Image Grabber
Теперь при нажатии на кнопку расширения появится стилизованный интерфейс:

Обратите внимание, что в данном случае не требовалось нажимать кнопку Reload для того чтобы обновить расширение. При изменении любых файлов кроме manifest.json изменения применяются автоматически.
Чтобы придать интерфейсу завершенность, добавим JavaScript-код, который будет реагировать на нажатия кнопки »GRAB NOW». Создайте файл popup.js в папке с расширением со следующим содержимым:
const grabBtn = document.getElementById("grabBtn");
grabBtn.addEventListener("click",() => {
alert("CLICKED");
})и добавьте ссылку на этот файл в popup.html:
Image Grabber
Image Grabber
Таким образом мы добавили событие onClick для кнопки с идентификатором »grabBtn». Теперь, при нажатии на кнопку »GRAB NOW» в интерфейсе, должен появляться алерт «CLICKED».
В результате мы имеем такую файловую систему расширения:
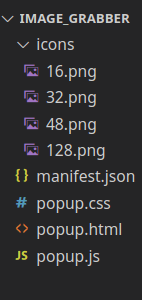
Это все файлы, других больше добавлять не будем. Такую структуру можно использовать как базу для создания расширений Google Chrome с интерфейсом основанном на всплывающих окнах.
Теперь реализуем бизнес-логику расширения: при нажатии на кнопку »GRAB NOW» расширение должно извлечь список путей ко всем картинкам текущей страницы в браузере и скопировать этот список в буфер обмена.
Функция «GRAB NOW»
Используя Javascript в расширении можно делать все то же самое, что и при использовании JavaScript на web-сайте, например открывать различные web-страницы из текущей или делать AJAX HTTP-запросы к различным серверам. Но в дополнении к этому, Javascript-код в расширении браузера может использовать различные API Chrome для взаимодействия с компонентами самого браузера. Большинство этих API доступно через пространство имен chrome. В частности, расширение Image Grabber будет использовать следующие API:
chrome.tabs— Chrome Tabs API. Будет использоваться для доступа к активной вкладке браузера.chrome.scripting— Chrome Scripting API. Будет использоваться для внедрения кода JavaScript на web-страницу активной вкладки и для исполнения этого кода в контексте этой страницы.
Получение необходимых разрешений
По умолчанию из соображений безопасности расширение Chrome не имеет доступа ко всем API браузера. Необходимо запросить этот доступ через механизм разрешений. Для этого нужно указать список требуемых разрешений в параметре permissions в файле manifest.json. Существует множество различных разрешений, которые описаны здесь: https://developer.chrome.com/docs/extensions/mv3/declare_permissions/. Для Image Grabber нужно указать следующие из них:
activeTab— разрешение для получения доступа к текущей вкладке браузера.scripting— разрешение для получения доступа к Chrome Scripting API для исполнения скриптов в контексте Web-страницы, открытой в браузере.
Добавьте эти разрешения в параметр permissions в файле manifest.json:
{
"name": "Image Grabber",
"description": "Extract all images from current web page",
"version": "1.0",
"manifest_version": 3,
"icons": {
"16":"icons/16.png",
"32":"icons/32.png",
"48":"icons/48.png",
"128":"icons/128.png"
},
"action": {
"default_popup":"popup.html",
},
"permissions": ["scripting", "activeTab"],
"background":{}
}и обновите расширение в Chrome Extensions Manager.
Между тем, листинг выше это окончательный вариант файла manifest.json для расширения. Теперь здесь есть все: название, описание, версия, иконки, ссылка на главную страницу интерфейса и разрешения на доступ к браузеру, которые этому интерфейсу необходимы.
Получение информации об активной вкладке браузера
Для получения информации о вкладках браузера используется функция chrome.tabs.query, которая определена следующим образом:
chrome.tabs.query(queryObject,callback)queryObjectэто объект запроса в котором указываются параметры поиска нужных вкладок.callback— функция обратного вызова, которая выполняется после выполнения этого запроса. В нее передается массивtabs, содержащий все найденные вкладки, соответствующие критерию запроса. Каждый элемент этого массива это объект типаTab, содержащий информацию о вкладке, включая ее уникальный идентификатор. Этот идентификатор будет использоваться для исполнения Javascript-кода на этой вкладке.
Здесь я не буду полностью описывать синтаксис queryObject, а также все поля возвращаемых объектов Tabs. Эту информацию можно найти в официальной документации по chrome.tabs: https://developer.chrome.com/docs/extensions/reference/tabs/.
Для расширения Image Grabber нужно получить только активную вкладку. Для этой цели queryObject должен быть определен как: {active: true} .
Теперь давайте изменим код обработчика нажатия кнопки grabBtn в popup.js чтобы он получал активную вкладку и ее идентификатор, когда пользователь нажимает на кнопку »GRAB NOW» в интерфейсе расширения:
const grabBtn = document.getElementById("grabBtn");
grabBtn.addEventListener("click",() => {
chrome.tabs.query({active: true}, (tabs) => {
const tab = tabs[0];
if (tab) {
alert(tab.id)
} else {
alert("There are no active tabs")
}
})
})Этот код выполняет запрос ко всем вкладкам, которые активны. Может быть только одна такая вкладка, поэтому к ней можно обратиться как tabs[0]. Если такая вкладка существует, то функция отображает ее id, а если не существует, то показывает сообщение об ошибке.
Если все сделано как описано выше, то при нажатии кнопки GRAB NOW должен появляться идентификатор текущей вкладки браузера. Далее мы изменим этот код таким образом, чтобы этот идентификатор использовался для доступа к web-странице, открытой на этой вкладке.
Извлечение изображений из текущей страницы
Расширение может взаимодействовать с открытыми страницами с помощью Chrome Scripting API, доступное через chrome.scripting. В частности, мы будем использовать функцию для внедрения своего кода в текущую web-страницу и для исполнения этого кода в ее контексте. То есть при запуске, этот код будет иметь доступ к DOM-дереву этой страницы и сможет делать нужные нам действия с любыми HTML-тэгами.
Для внедрение скрипта в страницу Web-браузера используется функция executeScript, определенная следующим образом:
chrome.scripting.executeScript(injectSpec,callback)Рассмотрим ее параметры.
injectSpec
Это объект типа ScriptInjection. В нем определяется какой Javascript-код, в какую web-страницу и каким образом его внедрить. В частности, в параметре target указывается идентификатор вкладки браузера со страницей, которая нам нужна. Мы получили его ранее. Остальные параметры указывают каким образом передать скрипт на эту страницу. Возможно использовать следующие параметры для передачи скрипта:
files— указывается список путей к JS-файлам, которые нужно внедрить, относительно корневой папки расширенияfunc— указывается Javascript-функция, которую нужно внедрить. Функция должна быть предварительно написана.
Скрипт, который планируется внедрить будет извлекать список изображений с web-страницы и возвращать список URL этих изображений. Это небольшой скрипт, поэтому достаточно создать функцию для него. Она будет называться grabImages. Эта функция должна извлекать список URL изображений web-страницы и возвращать его. Возвращаемое значение этой функции будет передано расширению.
В итоге injectSpec будет определен следующим образом:
{
target:{ tabId: tab.id, allFrames: true },
func: grabImages,
}, Здесь функция, указанная в параметре func будет внедрена на страницу, определенную параметром target. В параметре target указывается полученный на предыдущем этапе идентификатор вкладки, а также, устанавливается параметр allFrames. Этот дополнительный параметр говорит что скрипт должен выполняться во всех фреймах web-страницы, в случае если они на этой странице есть.
Саму функцию grabImages мы напишем чуть позже.
callback
Это функция обратного вызова, которая будет вызвана после того, как внедренный скрипт исполнится на странице и во всех ее фреймах, и в качестве параметра в ней будет массив результатов, которые вернула функция grabImages для каждого фрейма (возможно это будет всего один элемент, если фреймов нет). Каждый элемент этого массива это объект типа InjectionResult. Он в частности содержит свойство result. Именно оно содержит то, что возвращает функция grabImages, т.е. список URL-ов.
Теперь соберем все вместе в следующем коде:
const grabBtn = document.getElementById("grabBtn");
grabBtn.addEventListener("click",() => {
chrome.tabs.query({active: true}, function(tabs) {
var tab = tabs[0];
if (tab) {
chrome.scripting.executeScript(
{
target:{tabId: tab.id, allFrames: true},
func:grabImages
},
onResult
)
} else {
alert("There are no active tabs")
}
})
})
function grabImages() {
// TODO - Запросить список изображений
// и вернуть список их URL-ов
}
function onResult(frames) {
// TODO - Объединить списки URL-ов, полученных из каждого фрейма в один,
// затем объединить их в строку, разделенную символом перевода строки
// и скопировать в буфер обмена
}Функция grabImages может быть определена следующим образом:
/**
* Функция исполняется на удаленной странице браузера,
* получает список изображений и возвращает массив
* путей к ним
*
* @return Array массив строк
*/
function grabImages() {
const images = document.querySelectorAll("img");
return Array.from(images).map(image=>image.src);
}Здесь все просто: получаем список DOM-элементов и извлекаем свойство
src каждого из них в итоговый массив. Считаю нужным напомнить, что объект document, указанный в этой функции указывает на содержимое не той HTML-страницы, в которой находится функция grabImages, а удаленной web-страницы, в которую эта функция будет внедрена.
После того как данная функция выполнится в каждом фрейме, результаты будут объединены в единый массив и переданы в функцию onResult. Эта функция может быть определена следующим образом:
/**
* Выполняется после того как вызовы grabImages
* выполнены во всех фреймах удаленной web-страницы.
* Функция объединяет результаты в строку и копирует
* список путей к изображениям в буфер обмена
*
* @param {[]InjectionResult} frames Массив результатов
* функции grabImages
*/
function onResult(frames) {
// Если результатов нет
if (!frames || !frames.length) {
alert("Could not retrieve images from specified page");
return;
}
// Объединить списки URL из каждого фрейма в один массив
const imageUrls = frames.map(frame=>frame.result)
.reduce((r1,r2)=>r1.concat(r2));
// Скопировать в буфер обмена полученный массив
// объединив его в строку, используя символ перевода строки
// как разделитель
window.navigator.clipboard
.writeText(imageUrls.join("\n"))
.then(()=>{
// закрыть окно расширения после
// завершения
window.close();
});
}Следует упомянуть что не все вкладки браузера это вкладки с web-страницами. Например, может быть вкладка свойств браузера. Страницы на таких вкладках не имеют свойства document. В этом случае, функция grabImages не выполнится и не вернет результатов. Этот случай обрабатывается в самом начале функции. Затем массив массивов результатов объединяется в единый плоский массив используя концепцию map/reduce, затем функция window.navigator.clipboard используется чтобы скопировать его в буфер обмена. Предварительно массив результатов преобразовывается в строку, разделенную символом возврата каретки.
Завершающие штрихи
Здесь я описал только незначительную часть Chrome Scripting API и описал только в контексте данного расширения. Полная документация по Chrome Scripting API доступна здесь: https://developer.chrome.com/docs/extensions/reference/scripting/.
Теперь немного почистим код. Здесь я считаю нужным часть функции-обработчика grabBtn, которая выполняет chrome.scripting.executeScript вынести в отдельную функцию execScript. В результате файл popup.js выглядит так:
const grabBtn = document.getElementById("grabBtn");
grabBtn.addEventListener("click",() => {
// Получить активную вкладку браузера
chrome.tabs.query({active: true}, function(tabs) {
var tab = tabs[0];
// и если она есть, то выполнить на ней скрипт
if (tab) {
execScript(tab);
} else {
alert("There are no active tabs")
}
})
})
/**
* Выполняет функцию grabImages() на веб-странице указанной
* вкладки и во всех ее фреймах,
* @param tab {Tab} Объект вкладки браузера
*/
function execScript(tab) {
// Выполнить функцию на странице указанной вкладки
// и передать результат ее выполнения в функцию onResult
chrome.scripting.executeScript(
{
target:{tabId: tab.id, allFrames: true},
func:grabImages
},
onResult
)
}
/**
* Получает список абсолютных путей всех картинок
* на удаленной странице
*
* @return Array Массив URL
*/
function grabImages() {
const images = document.querySelectorAll("img");
return Array.from(images).map(image=>image.src);
}
/**
* Выполняется после того как вызовы grabImages
* выполнены во всех фреймах удаленной web-страницы.
* Функция объединяет результаты в строку и копирует
* список путей к изображениям в буфер обмена
*
* @param {[]InjectionResult} frames Массив результатов
* функции grabImages
*/
function onResult(frames) {
// Если результатов нет
if (!frames || !frames.length) {
alert("Could not retrieve images from specified page");
return;
}
// Объединить списки URL из каждого фрейма в один массив
const imageUrls = frames.map(frame=>frame.result)
.reduce((r1,r2)=>r1.concat(r2));
// Скопировать в буфер обмена полученный массив
// объединив его в строку, используя возврат каретки
// как разделитель
window.navigator.clipboard
.writeText(imageUrls.join("\n"))
.then(()=>{
// закрыть окно расширения после
// завершения
window.close();
});
}Заключение
Теперь, если нажать по иконке расширения Image Grabber и затем кликнуть кнопку GRAB NOW, то в буфере обмена будет список URL-ов всех изображений текущей web-страницы. Можно вставить его в любой текстовый редактор.
Для начала возможно неплохо, но практическая ценность такого расширения не велика. Поэтому в следующей части я покажу как выгрузить все эти изображения в виде zip-архива, а также, создать дополнительный интерфейс для того чтобы выбрать какие картинки добавлять в этот ZIP-архив, а какие нет. Также опишу процесс публикации готового расширения в Chrome Store.
Поэтому подписывайтесь, думаю к концу следующей недели вторая часть будет доступна вместе с полным исходным кодом.
