[Перевод] Самые востребованные навыки в сфере data science
В плане знаний от специалистов по data science ждут многого: машинное обучение, программирование, статистика, математика, визуализация данных, коммуникация и глубокое обучение. Каждая из этих областей охватывает десятки языков, фреймворков, технологий, доступных для изучения. Так как же специалистам по работе с данными лучше распорядиться своим бюджетом времени на обучение, чтобы быть в цене у работодателей?
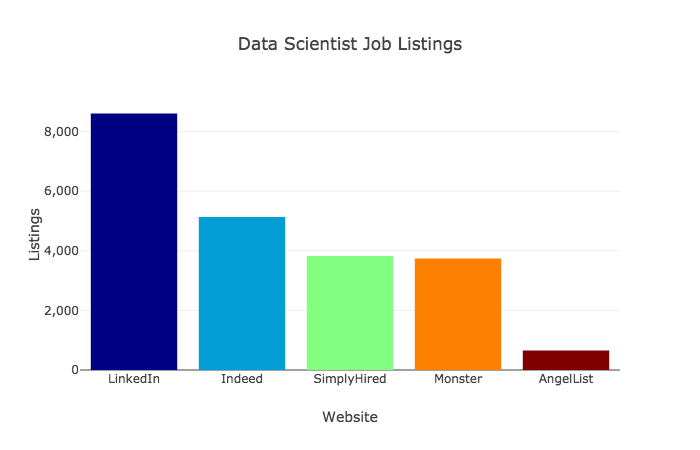
Я тщательно изучил сайты с вакансиями, чтобы выяснить, какие же навыки сейчас пользуются наибольшей популярностью у работодателей. Я рассматривал как более широкие дисциплины, связанные с работой с данными, так и конкретные языки и инструменты, в рамках отдельного исследования. За материалами я обратился к сайтам LinkedIn, Indeed, SimplyHired, Monster и AngelList, по состоянию на 10 октября 2018 года. На графике ниже показано, сколько вакансий по data science представлено на каждом из этих ресурсов.
Я изучил множество описаний вакансий и опросов, чтобы понять, какие навыки упоминаются чаще всего. Термины вроде «управление» в анализ не включались, так как на сайтах вакансий они употребляются в очень широком круге разнообразных контекстов.
Поиск производился по США на базе терминов «data science» «ключевое слово». Чтобы сократить выдачу, я отобрал только точные вхождения. Так или иначе, подобный метод гарантировал, что все результаты будут релевантны data science и ко всем запросам будут применяться одни и те же критерии.
AngelList выдает не общее число вакансий, имеющих отношение к работе с данными, а общее число компаний, предлагающих такие вакансии. Я исключил этот сайт из обоих исследований, так как его поисковый алгоритм, судя по всему, работает по принципу «ИЛИ» и не дает возможности как-нибудь переключиться на модель «И». С AngelList можно работать, когда вводишь что-то в духе «data scientist» «TensorFlow»- в этом случае соответствие второму запросу предполагает соответствие первому. Однако если использовать ключевые слова в духе «data scientist» «react.js», то в выдаче будет очень много вакансий, не связанных с data science.
Материалы с Glassdoor также пришлось исключить. На сайте утверждалось, что они располагают информацией о 26 263 вакансиях по работе с данными, но на деле отображалось максимум 900. К тому же, мне представляется крайне сомнительным, что они собрали в три с лишним раза больше вакансий, чем любой другой крупный сайт.
Для финального этапа исследования я отобрал ключевые слова, по которым на LinkedIn была большая выдача: более 400 результатов для навыков широкого профиля, более 200 — для частных технологий. Конечно, не обошлось без дублирующихся предложений. Итоги этого этапа я зафиксировал в Google-документе.
Затем я скачал файлы в формате .csv, загрузил их в JupyterLab, рассчитал степень распространенности каждого в процентном соотношении и усреднил полученные значения по разным ресурсам. Результаты по языкам я впоследствии сопоставил с теми, что приводились в исследовании по вакансиям из сферы data science от Glassdoor в первой половине 2017 года. Если прибавить к этому информацию из опроса об использовании KDNuggets, складывается впечатление, что некоторые навыки набирают популярность, в то время как другие постепенно теряют значение. Но об этом позже.
В моем Kaggle Kernel вы найдете интерактивные графики и дополнительный анализ. Для визуализации я использовал Plotly. Чтобы работать с Plotly и JupyterLab в связке придется кое-что подшаманить, по крайней мере, так было на момент написания этой статьи — инструкции можно прочитать в конце моего Kaggle Kernel, а также в документации Plotly.
Навыки широкого профиля
Вот график, который представляет самые популярные навыки общего профиля, которые работодатели хотят видеть у кандидатов.
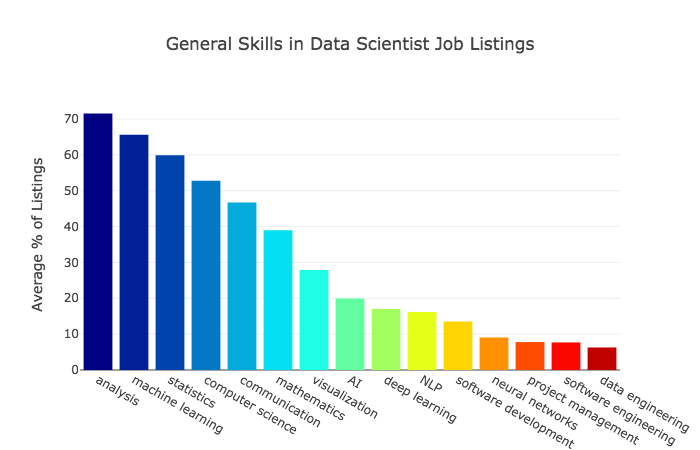
Результаты показывают, что аналитика и машинное обучение по-прежнему составляют основу работы специалистов по data science. Основное назначение этой специальности — делать полезные заключения на базе массивов данных. Машинное обучение ставит своей целью создание систем, способных предсказывать ход событий, соответственно, оно пользуется большим спросом.
Для обработки данных требуется знание статистики и умение писать код — тут удивляться нечему. Кроме того, статистика, математика и программная инженерия — это специальности, по которым ведется подготовка в вузах, что тоже может сказываться на частотности запросов.
Интересно, что в описаниях почти половины вакансий упоминается коммуникация: специалистам по работе с данными нужно уметь доносить до людей свои выводы и работать в команде.
Упоминания ИИ и глубокого обучения встречаются не так регулярно, как некоторые другие запросы. Тем не менее, эти области являются ответвления машинного обучения. Глубокое обучение все чаще и чаще применяется в задачах, для которых раньше использовались алгоритмы машинного обучения. Например, лучшие алгоритмы машинного обучения для проблем, возникающих при обработке естественного языка, сейчас относятся именно к области глубокого обучения. Полагаю, что в будущем оно будет становиться все более востребованным, а машинное обучение постепенно начнет восприниматься как синоним глубокого.
Какие же конкретные программные решения должны освоить специалисты по data science, по мнению работодателей? Перейдем к этому вопросу в следующем разделе.
Технологические навыки
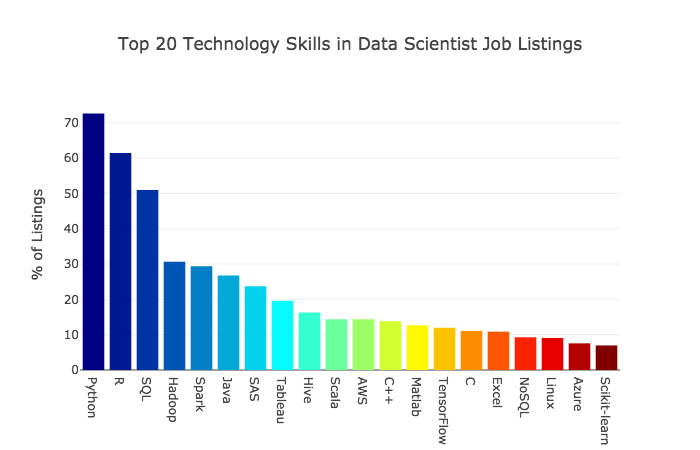
Внизу представлены 20 конкретных языков, библиотек и технологических инструментов, с которыми, на взгляд работодателей, специалисты по обработке данных должны иметь опыт работы.
Давайте быстро пройдемся по лидерам.

Python — самый востребованный вариант. То, что этот open source язык крайне популярен среди программистов, отмечали многие. Для новичков это очень удобный вариант: существует множество обучающих ресурсов. Подавляющее большинство новых инструментов для работы с данными с ним совместимо. Исходя из всего этого, Python можно называть основным языком для специалистов по data science.

R следует за Python с небольшим отрывом. Когда-то основным языком для специалистов по data science был именно он. Для меня стало сюрпризом то, что активный интерес к нему сохраняется до сих пор. Этот язык берет начало в статистике, и соответственно, пользуется большой популярностью у тех, кто ей занимается.
Практически все вакансии ставят обязательным условием знание одного из этих двух языков — Python или R.

SQL также очень востребован. Аббревиатура расшифровывается как Structured Query Language (язык структурированных запросов), и именно этот язык является главным инструментом для взаимодействия с реляционными базами данных. SQL в сообществе специалистов по data science нередко пренебрегают, однако он относится к навыкам, свободное владение которыми стоит показать, если вы планируете выходить на рынок труда.


Следом идут Hadoop and Spark — оба они являются open source инструментами от Apache, рассчитанными на работу с большими данными. Про них написано куда меньше туториалов и статей на Medium. Я предполагаю, что число соискателей, которые ими владеют, значительно меньше, чем тех, кто знаком с Python или R. Если вы умеете работать с Hadoop and Spark или имеете возможность их освоить, это может стать для вас хорошим преимуществом перед конкурентами.


Далее — Java и SAS. Я был удивлен, что эти два языка смогли забраться так высоко. Оба являются детищами крупных компаний и для обоих представлено какое-то количество бесплатных материалов. Тем не менее, среди специалистов по data science ни Java, ни SAS не возбуждают особого интереса.

Следующий в рейтинге востребованных технологий — Tableau. Это аналитическая платформа и инструмент для визуализации, отличающийся большой мощностью и простой в использовании. Его популярность неуклонно растет. У Tableau есть бесплатная публичная версия, но если хотите работать с данными в приватном режиме, придется раскошелиться. Если вы совсем не знакомы с Tableau, имеет смысл пройти краткий курс — скажем, Tableau 10 A-Z на Udemy. За рекламу они мне не платят, я просто сам занимался по этому курсу и нашел его очень полезным.
На графике внизу вы можете ознакомиться с расширенным списком востребованных языков, фреймворков и других инструментов для работы с данными.

Историческое сравнение
Команда GlassDoor публиковала исследование десяти самых популярных навыков для специалистов по data science на отрезке с января по июль 2017 года. На графике ниже их данные по частотности терминов сопоставляются с рассчитанными мной средними значениями для сайтов LinkedIn, Indeed, SimplyHired и Monster.
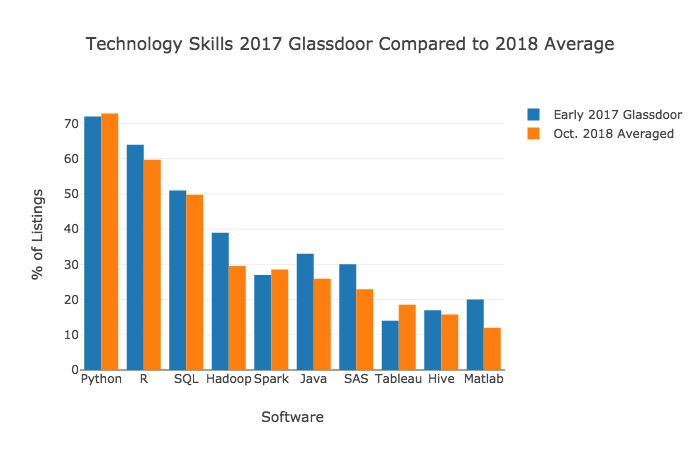
В целом, результаты схожи. И мое исследование, и исследование от Glassdoor сходятся на том, что на Python, R и SQL спрос наиболее высокий. Топы навыков также совпадают по составу в пределах первых девяти позиций, хотя точный порядок отличается.
Судя по результатам, по сравнению с первой половиной 2017 года степень востребованности R, Hadoop, Java, SAS и MatLab снизилась, а Tableau, напротив, стал более популярным. Этого следовало ожидать, если посмотреть хотя бы на результаты опроса разработчиков от KDnuggets. В них ясно видно, что R, Hadoop, Java и SAS на спаде уже несколько лет, в то время как Tableau стабильно на подъеме.
Рекомендации
С учетом этих выкладок я хотел бы предложить ряд рекомендаций для специалистов по работе с данными, которые уже вышли на рынок или только готовятся начать карьеру и хотя повысить свою конкурентоспособность.
- Покажите, что вы умеете проводить анализ данных, и не жалейте сил на то, чтобы как следует освоить машинное обучение
- Уделите внимание коммуникативным навыкам. Я бы посоветовал прочитать книгу «Made to Stick», где рассказывается, как придать своим идеям больше веса. Также попрактикуйтесь с приложением Hemmingway Editor, чтобы научиться яснее излагать свои мысли.
- Освойте фреймворк для глубокого обучения. Это постепенно становится неотъемлемой частью процесса освоения машинного обучения. В другой своей статье я сопоставляю различные фреймворки по тому, насколько они полезны, интересны и популярны — с ней можно ознакомиться здесь.
- Если вы колеблетесь между Python и R — выбирайте Python. Если Python вы уже знаете как свои пять пальцев, подумайте о том, чтобы изучить и R. Это однозначно сделает вас более привлекательной кандидатурой на рынке.
Когда работодатель ищет сотрудника, который работает с Python, он скорее всего будет ожидать от кандидатов знакомства с основными библиотеками для обработки данных: numpy, pandas, scikit-learn и matplotlib. Если вы хотите освоить этот набор, рекомендую следующие ресурсы:
- DataCamp и DataQuest — и там, и там можно за небольшие деньги пройти обучающий курс по SaaS data science в онлайн-режиме; учиться вы будете прямо в процессе написания кода. Оба курса охватывают широкий круг инструментов.
- Data School предлагает целый диапазон разных ресурсов, включая неплохую серию роликов на Youtube, где объясняются базовые понятия data science.
- «Python и анализ данных» МакКинни. Это труд автора библиотеки pandas; в основном речь там идет именно о ней, но также затрагиваются основы Python, numpy, and scikit-learn применительно к data science.
- «Введение в машинное обучение с помощью Python. Руководство для специалистов по работе с данными» от Мюллера и Гвидо. Мюллер отвечает за поддержку scikit-learn. Отличная книга для тех, кто изучает машинное обучение в целом и данную библиотеку в частности.
Если хотите сделать рывок в глубокое обучение, советую начать с Keras или FastAI, а потом перейти к TensorFlow или PyTorch. «Глубокое обучение на Python» Шолле — отличное подспорье для тех, кто учится работать с Keras.
Помимо этих рекомендаций, думаю, стоит сосредоточиться на изучении того, что вам самим интересно, хотя, разумеется, распределять свой запас времени на обучении можно с опорой на самые разные соображения.
Если вы ищете вакансии специалиста по работе с данными на онлайн-порталах, советую начать с LinkedIn — выдача у него стабильно самая обширная. Также при поиске вакансий или размещении резюме на сайтах очень большую роль играют ключевые слова. Например, на всех рассмотренных ресурсах по запросу «data science» выпадает в три раза больше результатов, чем по запросу «data scientist». С другой стороны, если вас интересуют только и исключительно предложения с должностью data scientist, лучше отдать предпочтение этому запросу.
Но какой бы ресурс вы ни выбрали, рекомендую создать онлайн-портфолио, которое демонстрировало бы ваши умения в разных востребованных областях — чем больше их будет, тем лучше. Профиль на LinkedIn в идеале должен содержать какие-то доказательства владения навыками, о которых вы говорите.
Возможно, я изложу остальные результаты исследования в других статьях. Если вы хотите подробнее изучить код или интерактивные графики — приглашаю в Kaggle Kernel.
