[Перевод] Реверс-инжиниринг рендеринга «Ведьмака 3»
Первая часть перевода находится здесь. В этой части мы поговорим об эффекте резкости, средней яркости, фазах Луны и атмосферных явлениях во время дождя.
Часть 6. Sharpen
В этой части мы подробнее рассмотрим ещё один эффект постобработки из The Witcher 3 — Sharpen.
Sharpening делает изображение на выходе немного чётче. Этот эффект известен нам по Photoshop и другим графическим редакторам.
В The Witcher 3 у sharpening есть две опции: low и high. О разнице между ними я расскажу ниже, а пока давайте взглянем на скриншоты:

Опция «Low» — до

Опция «Low» — после

Опция «High» — до

Опция «High» — после
Если вы хотите взглянуть на более подробные (интерактивные) сравнения, то посмотрите раздел в руководстве о производительности The Witcher 3 компании Nvidia. Как видите, эффект особенно заметен на траве и листве.
В этой части поста мы изучим кадр из самого начала игры: я выбрал его намеренно, потому что здесь мы видим рельеф (длинная дистанция отрисовки) и купол неба.

С точки зрения входных данных для sharpening требуется цветовой буфер t0 (LDR после тональной коррекции и lens flares) и буфер глубин t1.
Давайте изучим ассемблерный код пиксельного шейдера:
ps_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb3[3], immediateIndexed
dcl_constantbuffer cb12[23], immediateIndexed
dcl_sampler s0, mode_default
dcl_resource_texture2d (float,float,float,float) t0
dcl_resource_texture2d (float,float,float,float) t1
dcl_input_ps_siv v0.xy, position
dcl_output o0.xyzw
dcl_temps 7
0: ftoi r0.xy, v0.xyxx
1: mov r0.zw, l(0, 0, 0, 0)
2: ld_indexable(texture2d)(float,float,float,float) r0.x, r0.xyzw, t1.xyzw
3: mad r0.x, r0.x, cb12[22].x, cb12[22].y
4: mad r0.y, r0.x, cb12[21].x, cb12[21].y
5: max r0.y, r0.y, l(0.000100)
6: div r0.y, l(1.000000, 1.000000, 1.000000, 1.000000), r0.y
7: mad_sat r0.y, r0.y, cb3[1].z, cb3[1].w
8: add r0.z, -cb3[1].x, cb3[1].y
9: mad r0.y, r0.y, r0.z, cb3[1].x
10: add r0.y, r0.y, l(1.000000)
11: ge r0.x, r0.x, l(1.000000)
12: movc r0.x, r0.x, l(0), l(1.000000)
13: mul r0.z, r0.x, r0.y
14: round_z r1.xy, v0.xyxx
15: add r1.xy, r1.xyxx, l(0.500000, 0.500000, 0.000000, 0.000000)
16: div r1.xy, r1.xyxx, cb3[0].zwzz
17: sample_l(texture2d)(float,float,float,float) r2.xyz, r1.xyxx, t0.xyzw, s0, l(0)
18: lt r0.z, l(0), r0.z
19: if_nz r0.z
20: div r3.xy, l(0.500000, 0.500000, 0.000000, 0.000000), cb3[0].zwzz
21: add r0.zw, r1.xxxy, -r3.xxxy
22: sample_l(texture2d)(float,float,float,float) r4.xyz, r0.zwzz, t0.xyzw, s0, l(0)
23: mov r3.zw, -r3.xxxy
24: add r5.xyzw, r1.xyxy, r3.zyxw
25: sample_l(texture2d)(float,float,float,float) r6.xyz, r5.xyxx, t0.xyzw, s0, l(0)
26: add r4.xyz, r4.xyzx, r6.xyzx
27: sample_l(texture2d)(float,float,float,float) r5.xyz, r5.zwzz, t0.xyzw, s0, l(0)
28: add r4.xyz, r4.xyzx, r5.xyzx
29: add r0.zw, r1.xxxy, r3.xxxy
30: sample_l(texture2d)(float,float,float,float) r1.xyz, r0.zwzz, t0.xyzw, s0, l(0)
31: add r1.xyz, r1.xyzx, r4.xyzx
32: mul r3.xyz, r1.xyzx, l(0.250000, 0.250000, 0.250000, 0.000000)
33: mad r1.xyz, -r1.xyzx, l(0.250000, 0.250000, 0.250000, 0.000000), r2.xyzx
34: max r0.z, abs(r1.z), abs(r1.y)
35: max r0.z, r0.z, abs(r1.x)
36: mad_sat r0.z, r0.z, cb3[2].x, cb3[2].y
37: mad r0.x, r0.y, r0.x, l(-1.000000)
38: mad r0.x, r0.z, r0.x, l(1.000000)
39: dp3 r0.y, l(0.212600, 0.715200, 0.072200, 0.000000), r2.xyzx
40: dp3 r0.z, l(0.212600, 0.715200, 0.072200, 0.000000), r3.xyzx
41: max r0.w, r0.y, l(0.000100)
42: div r1.xyz, r2.xyzx, r0.wwww
43: add r0.y, -r0.z, r0.y
44: mad r0.x, r0.x, r0.y, r0.z
45: max r0.x, r0.x, l(0)
46: mul r2.xyz, r0.xxxx, r1.xyzx
47: endif
48: mov o0.xyz, r2.xyzx
49: mov o0.w, l(1.000000)
50: ret
50 строк ассемблерного кода выглядят как вполне посильная задача. Давайте приступим к её решению.
Генерация величины Sharpen
Первый этап заключается в загрузке (Load) буфера глубин (строка 1). Стоит заметить, что в «Ведьмаке 3» используется перевёрнутая глубина (1.0 — близко, 0.0 — далеко). Как вы можете знать, аппаратная глубина привязывается нелинейным образом (подробности см. в этой статье).
Строки 3–6 выполняют очень интересный способ привязки этой аппаратной глубины [1.0 — 0.0] к значениям [близко-далеко] (мы задаём их на этапе MatrixPerspectiveFov). Рассмотрим значения из буфера констант:

Имея для «близко» значение 0.2, а для «далеко» значение 5000, мы можем вычислить значения cb12_v21.xy следующим образом:
cb12_v21.y = 1.0 / near
cb12_v21.x = - (1.0 / near) + (1.0 / near) * (near / far)
Этот фрагмент кода довольно часто встречается в шейдерах TW3, поэтому я считаю, что это просто функция.
После получения «глубины пирамиды видимости» строка 7 использует масштаб/искажение для создания коэффициента интерполяции (здесь мы используем saturate, чтобы ограничить значения интервалом [0–1]).

cb3_v1.xy и cb3_v2.xy — это, яркость эффекта sharpening на ближних и дальних расстояниях. Давайте назовём их «sharpenNear» и «sharpenFar». И это единственное отличие опций «Low» и «High» данного эффекта в The Witcher 3.
Теперь настало время использовать полученный коэффициент. Строки 8–9 просто выполняют lerp(sharpenNear, sharpenFar, interpolationCoeff). Для чего это нужно? Благодаря этому мы получаем разную яркость рядом с Геральтом и вдали от него. Посмотрите:

Возможно, это едва заметно, но здесь мы интерполировали на основании расстояния яркость sharpen рядом с игроком (2.177151) и яркость эффекта очень далеко (1.91303). После этого вычисления мы прибавляем к яркости 1.0 (строка 10). Зачем это нужно? Предположим, что показанная выше операция lerp дала нам 0.0. После прибавления 1.0 мы, естественно, получим 1.0, и это значение, которое не повлияет на пиксель при выполнении sharpening. Подробнее об этом рассказано ниже.
Во время добавления резкости мы не хотим влиять на небо. Этого можно достичь, добавив простую условную проверку:
// Не выполнять sharpen для неба
float fSkyboxTest = (fDepth >= 1.0) ? 0 : 1;
В The Witcher 3 значение глубины пикселей неба равно 1.0, поэтому мы используем его, чтобы получить своего рода «двоичный фильтр» (интересный факт: в данном случае step сработает неправильно).
Теперь мы можем умножить интерполированную яркость на «фильтр неба»:

Это умножение выполняется в строке 13.
Пример кода шейдера:
// Вычисление финального значения sharpen
float fSharpenAmount = fSharpenIntensity * fSkyboxTest;
Центр сэмплирования пикселя
В SV_Position есть аспект, который будет здесь важен: смещение в половину пикселя. Оказывается, что этот пиксель в верхнем левом углу (0, 0) имеет координаты не не (0, 0) с точки зрения of SV_Position.xy, а (0.5, 0.5). Ничего себе!
Здесь мы хотим взять сэмпл в центре пикселя, поэтому посмотрим на строки 14–16. Можно записать их на HLSL:
// Сэмплируем центр пикселя.
// Избавляемся от "половинопиксельного" смещения в SV_Position.xy.
float2 uvCenter = trunc( Input.Position.xy );
// Прибавляем половину пикселя, чтобы мы сэмплировали именно центр пикселя
uvCenter += float2(0.5, 0.5);
uvCenter /= g_Viewport.xy
А позже мы сэмплируем входную текстуру цвета из texcoords «uvCenter». Не волнуйтесь, результат сэмплирования будет тем же, что и при «обычном» способе (SV_Position.xy / ViewportSize.xy).
To sharpen or not to sharpen
Решение о том, нужно ли применять sharpen, зависит от fSharpenAmount.
// Получаем значение текущего пикселя
float3 colorCenter = TexColorBuffer.SampleLevel( samplerLinearClamp, uvCenter, 0 ).rgb;
// Финальный результат
float3 finalColor = colorCenter;
if (fSharpenAmount > 0)
{
// здесь выполняем sharpening…
}
return float4(finalColor, 1);
Sharpen
Настало время взглянуть на сами внутренности алгоритма.
По сути, он выполняет следующие действия:
— сэмплирует четыре раза входную текстуру цвета по углам пикселя,
— складывает сэмплы и вычисляет среднее значение,
— вычисляет разность между «center» и «cornerAverage»,
— находит максимальный абсолютный компонент разности,
— корректирует макс. абс. компонент, используя значения scale+bias,
— определяет величину эффекта, используя макс. абс. компонент,
— вычисляет значение яркости (luma) для «centerColor» и «averageColor»,
— делит colorCenter на его luma,
— вычисляет новое, интерполированное значение luma на основе величины эффекта,
— умножает colorCenter на новое значение luma.
Довольно много работы, и мне было сложно в этом разобраться, потому что я никогда не экспериментировал с фильтрами резкости.
Давайте начнём с паттерна сэмплирования. Как можно увидеть в ассемблерном коде, выполняется четыре считывания текстуры.
Лучше всего будет показать это на примере изображения пикселя (уровень мастерства художника — эксперт):
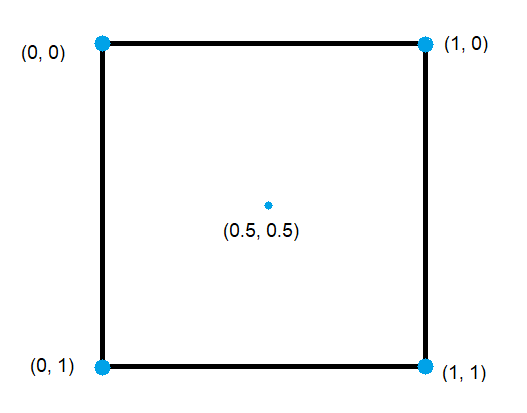
Все считывания в шейдере используют билинейное сэмплирование (D3D11_FILTER_MIN_MAG_LINEAR_MIP_POINT).
Смещение от центра до каждого из углов равен (±0.5, ±0.5), в зависимости от угла.
Видите, как это можно реализовать на HLSL? Давайте посмотрим:
float2 uvCorner;
float2 uvOffset = float2( 0.5, 0.5 ) / g_Viewport.xy; // remember about division!
float3 colorCorners = 0;
// Верхний левый угол
// -0,5, -0.5
uvCorner = uvCenter — uvOffset;
colorCorners += TexColorBuffer.SampleLevel (samplerLinearClamp, uvCorner, 0).rgb;
// Верхний правый угол
// +0.5, -0.5
uvCorner = uvCenter + float2(uvOffset.x, -uvOffset.y);
colorCorners += TexColorBuffer.SampleLevel (samplerLinearClamp, uvCorner, 0).rgb;
// Нижний левый угол
// -0.5, +0.5
uvCorner = uvCenter + float2(-uvOffset.x, uvOffset.y);
colorCorners += TexColorBuffer.SampleLevel (samplerLinearClamp, uvCorner, 0).rgb;
// Нижний правый угол
// +0.5, +0.5
uvCorner = uvCenter + uvOffset;
colorCorners += TexColorBuffer.SampleLevel (samplerLinearClamp, uvCorner, 0).rgb;
Итак, теперь все четыре сэмпла суммированы в переменной «colorCorners». Давайте выполним следующие шаги:
// Вычисляем среднее четырёх углов
float3 averageColorCorners = colorCorners / 4.0;
// Вычисляем разность цветов
float3 diffColor = colorCenter — averageColorCorners;
// Находим макс. абс. RGB-компонент разности
float fDiffColorMaxComponent = max (abs (diffColor.x), max (abs (diffColor.y), abs (diffColor.z)));
// Корректируем этот коэффициент
float fDiffColorMaxComponentScaled = saturate (fDiffColorMaxComponent * sharpenLumScale + sharpenLumBias);
// Вычисляем необходимую величину резкости пикселя.
// Заметьте здесь »1.0» — именно поэтому мы прибавили в fSharpenIntensity значение 1.0.
float fPixelSharpenAmount = lerp (1.0, fSharpenAmount, fDiffColorMaxComponentScaled);
// Вычисляем яркость «центра» пикселя и яркость среднего значения.
float lumaCenter = dot (LUMINANCE_RGB, finalColor);
float lumaCornersAverage = dot (LUMINANCE_RGB, averageColorCorners);
// делим «centerColor» на его яркость
float3 fColorBalanced = colorCenter / max (lumaCenter, 1e-4);
// Вычисляем новую яркость
float fPixelLuminance = lerp (lumaCornersAverage, lumaCenter, fPixelSharpenAmount);
// Вычисляем цвет на выходе
finalColor = fColorBalanced * max (fPixelLuminance, 0.0);
}
return float4(finalColor, 1.0);
Распознавание краёв выполняется вычислением макс. абс. компонента разности. Умный ход! Посмотрите его визуализацию:

Визуализация максимального абсолютного компонента разности.
Отлично. Готовый HLSL-шейдер выложен здесь. Простите за довольно плохое форматирование. Можете воспользоваться моей программой HLSLexplorer и поэкспериментировать с кодом.
Могу с радостью сказать, что представленный выше код создаёт тот же ассемблерный код, что и в игре!
Подведём итог: шейдер резкости «Ведьмака 3» очень хорошо написан (заметьте. что fPixelSharpenAmount больше 1.0! это интересно…). Кроме того, основной способ изменения яркости эффекта — это яркость ближних/дальних объектов. В этой игре они не являются константами; я собрал несколько примеров значений:
Скеллиге:
| sharpenNear | sharpenFar | sharpenDistanceScale | sharpenDistanceBias | sharpenLumScale | sharpenLumBias | |
|---|---|---|---|---|---|---|
| low | ||||||
| high | 2.0 | 1.8 | 0.025 |
-0.25 |
-13.33333 |
1.33333 |
Каэр Морхен:
| sharpenNear |
sharpenFar |
sharpenDistanceScale |
sharpenDistanceBias |
sharpenLumScale |
sharpenLumBias |
|
|---|---|---|---|---|---|---|
| low |
0.57751 |
0.31303 |
0.06665 |
-0.33256 |
-1.0 |
2.0 |
| high |
2.17751 |
1.91303 |
0.06665 |
-0.33256 |
-1.0 |
2.0 |
Часть 7. Средняя яркость
Операцию вычисления средней яркости текущего кадра можно найти практически в любой современной видеоигре. Это значение часто позже используется для эффекта адаптации глаза и тональной коррекции (см. в предыдущей части поста). В простых решениях используется вычисление яркости для, допустим текстуры размером 5122, затем вычисление её mip-уровней и применение последнего. Обычно это срабатывает, но сильно ограничивает возможности. В более сложных решениях используются вычислительные шейдеры, выполняющие, например параллельную редукцию.
Давайте узнаем, как эту задачу решила в «Ведьмаке 3» команда CD Projekt Red. В предыдущей части я уже исследовал тональную коррекцию и адаптацию глаза, поэтому единственным оставшимся куском головоломки осталась средняя яркость.
Начнём с того, что вычисление средней яркости The Witcher 3 состоит из двух проходов. Для понятности я решил разбить их на отдельные части, и сначала мы рассмотрим первый проход — «распределение яркости» (вычисление гистограммы яркости).
Распределение яркости
Эти два прохода довольно просто найти в любом анализаторе кадров. Они являются идущими по порядку вызовами Dispatch прямо перед выполнением адаптации глаза:
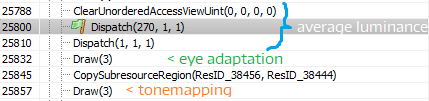
Давайте рассмотрим входные данные для этого прохода. Ему необходимы две текстуры:
1) HDR-буфер цветов, масштаб которого снижен до ¼ x ¼ (например, с 1920×1080 до 480×270),
2) Полноэкранный буфер глубин

HDR-буфер цветов с разрешением ¼ x ¼. Заметьте хитрый трюк — этот буфер является частью большего буфера. Многократное использование буферов — это хорошая практика.

Полноэкранный буфер глубин
Зачем уменьшать масштаб буфера цветов? Думаю, всё дело в производительности.
Что касается выходных данных этого прохода, то ими является структурированный буфер. 256 элемента по 4 байта каждый.
Здесь у шейдеров нет отладочной информации, поэтому предположим, что это просто буфер беззнаковых значений int.
Важно: первый этап вычисления средней яркости вызывает ClearUnorderedAccessViewUint для обнуления всех элементов структурированного буфера.
Давайте изучим ассемблерный код вычислительного шейдера (это первый вычислительный шейдер за весь наш анализ!)
cs_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb0[3], immediateIndexed
dcl_resource_texture2d (float,float,float,float) t0
dcl_resource_texture2d (float,float,float,float) t1
dcl_uav_structured u0, 4
dcl_input vThreadGroupID.x
dcl_input vThreadIDInGroup.x
dcl_temps 6
dcl_tgsm_structured g0, 4, 256
dcl_thread_group 64, 1, 1
0: store_structured g0.x, vThreadIDInGroup.x, l(0), l(0)
1: iadd r0.xyz, vThreadIDInGroup.xxxx, l(64, 128, 192, 0)
2: store_structured g0.x, r0.x, l(0), l(0)
3: store_structured g0.x, r0.y, l(0), l(0)
4: store_structured g0.x, r0.z, l(0), l(0)
5: sync_g_t
6: ftoi r1.x, cb0[2].z
7: mov r2.y, vThreadGroupID.x
8: mov r2.zw, l(0, 0, 0, 0)
9: mov r3.zw, l(0, 0, 0, 0)
10: mov r4.yw, l(0, 0, 0, 0)
11: mov r1.y, l(0)
12: loop
13: utof r1.z, r1.y
14: ge r1.z, r1.z, cb0[0].x
15: breakc_nz r1.z
16: iadd r2.x, r1.y, vThreadIDInGroup.x
17: utof r1.z, r2.x
18: lt r1.z, r1.z, cb0[0].x
19: if_nz r1.z
20: ld_indexable(texture2d)(float,float,float,float) r5.xyz, r2.xyzw, t0.xyzw
21: dp3 r1.z, r5.xyzx, l(0.212600, 0.715200, 0.072200, 0.000000)
22: imul null, r3.xy, r1.xxxx, r2.xyxx
23: ld_indexable(texture2d)(float,float,float,float) r1.w, r3.xyzw, t1.yzwx
24: eq r1.w, r1.w, cb0[2].w
25: and r1.w, r1.w, cb0[2].y
26: add r2.x, -r1.z, cb0[2].x
27: mad r1.z, r1.w, r2.x, r1.z
28: add r1.z, r1.z, l(1.000000)
29: log r1.z, r1.z
30: mul r1.z, r1.z, l(88.722839)
31: ftou r1.z, r1.z
32: umin r4.x, r1.z, l(255)
33: atomic_iadd g0, r4.xyxx, l(1)
34: endif
35: iadd r1.y, r1.y, l(64)
36: endloop
37: sync_g_t
38: ld_structured r1.x, vThreadIDInGroup.x, l(0), g0.xxxx
39: mov r4.z, vThreadIDInGroup.x
40: atomic_iadd u0, r4.zwzz, r1.x
41: ld_structured r1.x, r0.x, l(0), g0.xxxx
42: mov r0.w, l(0)
43: atomic_iadd u0, r0.xwxx, r1.x
44: ld_structured r0.x, r0.y, l(0), g0.xxxx
45: atomic_iadd u0, r0.ywyy, r0.x
46: ld_structured r0.x, r0.z, l(0), g0.xxxx
47: atomic_iadd u0, r0.zwzz, r0.x
48: ret
И буфер констант:

Мы уже знаем, что первыми входными данными является HDR-буфер цветов. При FullHD его разрешение равно 480×270. Посмотрим на вызов Dispatch.
Dispatch (270, 1, 1) — это означает, что мы запускаем 270 групп потоков. Проще говоря, мы запускаем по одной группе потоков на каждую строку буфера цветов.
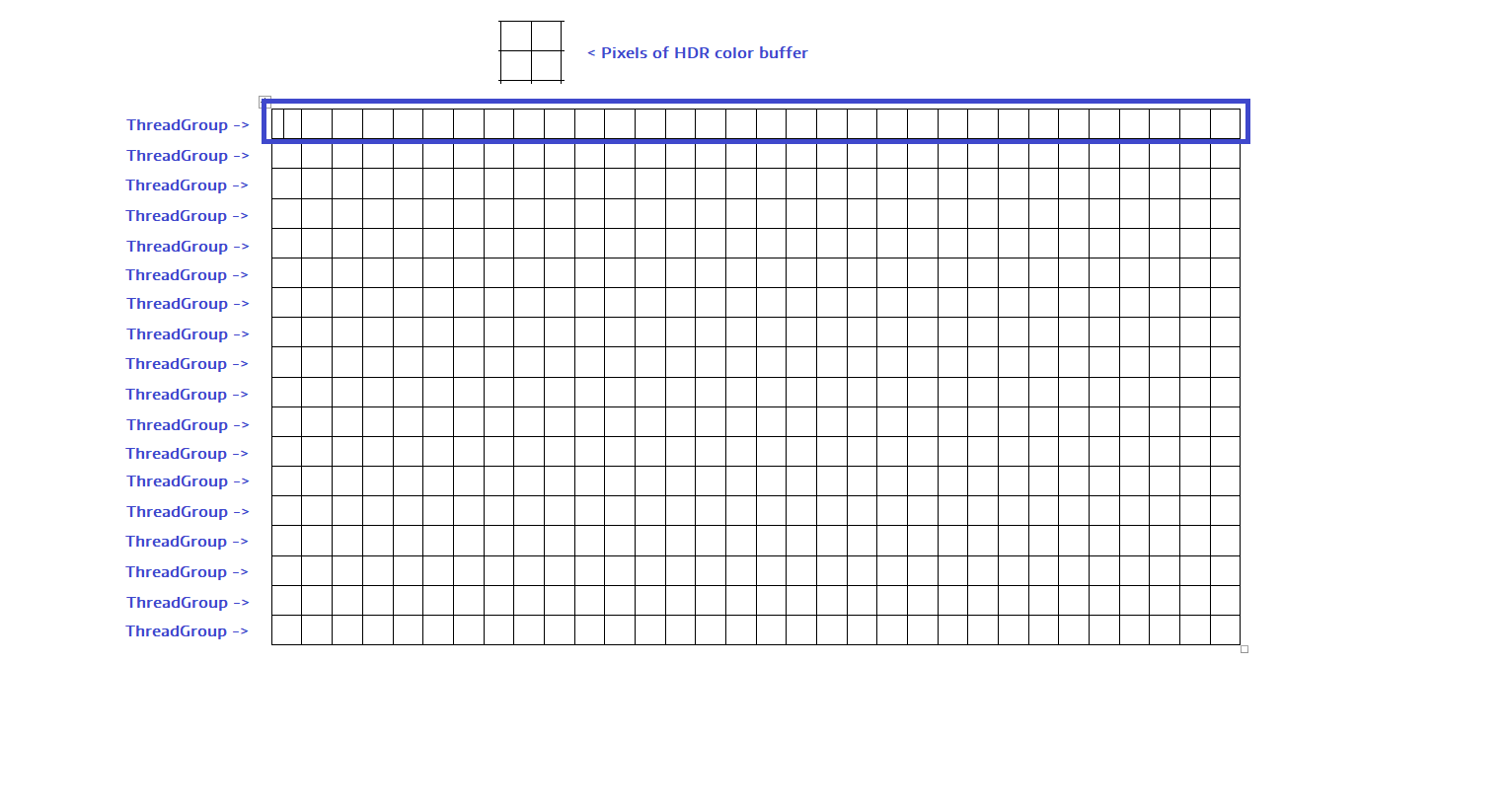
Каждая группа потоков выполняет одну строку HDR-буфера цветов
Теперь, когда у нас есть этот контекст, давайте попробуем выяснить, что же делает шейдер.
Каждая группа потоков имеет 64 потоков в направлении X (dcl_thread_group 64, 1, 1), а также общую память, 256 элементов по 4 байта в каждом (dcl_tgsm_structured g0, 4, 256).
Заметьте, что в шейдере мы используем SV_GroupThreadID (vThreadIDInGroup.x) [0–63] и SV_GroupID (vThreadGroupID.x) [0–269].
1) Мы начинаем с того, что присваиваем всем элементам общей памяти нулевые значения. Так как в общей памяти содержится 256 элемента и 64 потока на группу, это удобно можно сделать с помощью простого цикла:
// Первый шаг - присвоение всем общим данным нулевых значений.
// Так как в каждой группе потоков есть 64 потока, каждый из них может с помощью простого смещения обнулить 4 элемента.
[unroll] for (uint idx=0; idx < 4; idx++)
{
const uint offset = threadID + idx*64;
shared_data[ offset ] = 0;
}
2) После этого мы устанавливаем барьер с помощью GroupMemoryBarrierWithGroupSync (sync_g_t). Мы делаем это, чтобы гарантировать обнуление всеми потоками всех элементов в общей памяти групп перед переходом к следующему этапу.
3) Теперь мы выполняем цикл, который можно приблизительно записать так:
// cb0_v0.x - это ширина буфера цветов уменьшенного масштаба. Для 1920x1080 она равна 1920/4 = 480;
float ViewportSizeX = cb0_v0.x;
[loop] for ( uint PositionX = 0; PositionX < ViewportSizeX; PositionX += 64 )
{
...
Это простой цикл for с инкрементом на 64 (вы уже поняли, почему?).
Следующий этап — вычисление позиции загружаемого пикселя.
Давайте подумаем об этом.
Для координаты Y мы можем использовать SV_GroupID.x, потому что мы запустили 270 групп потоков.
Для координаты X мы… можем воспользоваться преимуществом текущего потока группы! Давайте попробуем это сделать.
Так как в каждой группе по 64 потока, такое решение обойдёт все пиксели.
Рассмотрим группу потоков (0, 0, 0).
— Поток (0, 0, 0) обработает пиксели (0, 0), (64, 0), (128, 0), (192, 0), (256, 0), (320, 0), (384, 0), (448, 0).
— Поток (1, 0, 0) обработает пиксели (1, 0), (65, 0), (129, 0), (193, 0), (257, 0), (321, 0), (385, 0), (449, 0)…
— Поток (63, 0, 0) обработает пиксели (63, 0), (127, 0), (191, 0), (255, 0), (319, 0), (383, 0), (447, 0)
Таким образом, будут обработаны все пиксели.
Также нам нужно гарантировать, что мы не загрузим пиксели из-за пределов буфера цветов:
// Мы попиксельно перемещаемся вдоль оси X. Значение Y равно GroupID.
uint CurrentPixelPositionX = PositionX + threadID;
uint CurrentPixelPositionY = groupID;
if ( CurrentPixelPositionX < ViewportSizeX )
{
// HDR-буфер цветов.
// Вычисляем позицию HDR-буфера цветов в экранном пространстве, загружаем его и вычисляем яркость.
uint2 colorPos = uint2(CurrentPixelPositionX, CurrentPixelPositionY);
float3 color = texture0.Load( int3(colorPos, 0) ).rgb;
float luma = dot(color, LUMA_RGB);
Видите? Всё довольно просто!
Также я вычислил яркость (строка 21 ассемблерного кода).
Отлично, мы уже вычислили яркость из цветного пикселя. Следующий шаг — загрузка (не сэмплирование!) соответствующего значения глубины.
Но здесь у нас есть проблема, потому что мы подключили буфер глубин полного разрешения. Что с этим делать?
Это на удивление просто — достаточно умножить colorPos на какую-нибудь константу (cb0_v2.z). Мы уменьшили масштаб HDR-буфера цветов в четыре раза. поэтому значением будет 4!
const int iDepthTextureScale = (int) cb0_v2.z;
uint2 depthPos = iDepthTextureScale * colorPos;
float depth = texture1.Load( int3(depthPos, 0) ).x;
Пока всё здорово! Но… мы дошли до строк 24–25…
24: eq r2.x, r2.x, cb0[2].w
25: and r2.x, r2.x, cb0[2].y
Так. Сначала у нас есть сравнение равенства с плавающей запятой, его результат записывается в r2.x, а сразу после этого идёт… что? Побитовое И? Серьёзно? Для значения с плавающей запятой? Какого чёрта???
Проблема 'eq+and'
Позвольте просто сказать, что это для меня была самая сложная часть шейдера. Я даже пробовал странные комбинации asint/asfloat…
А если использовать немного другой подход? Давайте просто выполним в HLSL обычное сравнение float-float.
float DummyPS() : SV_Target0
{
float test = (cb0_v0.x == cb0_v0.y);
return test;
}
А вот как выглядит вывод в ассемблерном коде:
0: eq r0.x, cb0[0].y, cb0[0].x
1: and o0.x, r0.x, l(0x3f800000)
2: ret
Интересно, правда? Не ожидал увидеть здесь «and».
0×3f800000 — это просто 1.0f… Логично, потому что мы получаем в случае успеха сравнения 1.0 и 0.0 в противном случае.
А что если мы «заменим» 1.0 каким-то другим значением? Например так:
float DummyPS() : SV_Target0
{
float test = (cb0_v0.x == cb0_v0.y) ? cb0_v0.z : 0.0;
return test;
}
Получим такой результат:
0: eq r0.x, cb0[0].y, cb0[0].x
1: and o0.x, r0.x, cb0[0].z
2: ret
Ха! Сработало. Это просто магия компилятора HLSL. Примечание: если заменить чем-то другим 0.0, то получится просто movc.
Вернёмся к вычислительному шейдеру. Следующим шагом будет проверка равенства глубины значению cb0_v2.w. Оно всегда равно 0.0 — проще говоря, мы проверяем, находится ли пиксель на дальней плоскости (в небе). Если да, то мы присваиваем этому коэффициенту какое-то значение, приблизительно 0.5 (я проверял на нескольких кадрах).
Такой вычисленный коэффициент используется для интерполяции между яркостью цвета и яркостью «неба» (значением cb0_v2.x, которое часто примерно равно 0.0). Предполагаю, что это нужно для управления важностью неба в вычислении средней яркости. Обычно важность уменьшается. Очень умная идея.
// Проверяем, лежит ли пиксель на дальней плоскости (в небе). Если да, то мы можем указать, как он будет
// смешиваться с нашими значениями.
float value = (depth == cb0_v2.w) ? cb0_v2.y : 0.0;
// Если 'value' равно 0.0, то эта lerp просто даёт нам 'luma'. Однако если 'value' отличается
// (часто около 0.50), то вычисленное luma имеет гораздо меньший вес. (cb0_v2.x обычно близко к 0.0).
float lumaOk = lerp (luma, cb0_v2.x, value);
Так как у нас есть lumaOk, следующим этапом будет вычисление его натурального логарифма для создания хорошего распределения. Но постойте, допустим, lumaOk равно 0.0. Мы знаем, что значение log (0) является неопределённым, поэтому прибавляем 1.0, потому что log (1) = 0.0.
После этого мы масштабируем вычисленный логарифм на 128, чтобы распределить его по 256 ячейкам. Очень умно!
И именно отсюда берётся это значение 88.722839. Это 128 * натуральный логарифм (2).
Это просто способ, которым HLSL вычисляет логарифмы.
В ассемблерном коде HLSL есть только одна функция, вычисляющая логарифмы: log, и она имеет основание 2.
// Предположим, что lumaOk равно 0.0.
// log(0) имеет значение undefined
// log(1) = 0.
// вычисляем натуральный логарифм яркости
lumaOk = log(lumaOk + 1.0);
// Масштабируем логарифм яркости на 128
lumaOk *= 128;
Наконец мы вычисляем из логарифмически распределённой яркости индекс ячейки и прибавляем 1 к соответствующей ячейке в общей памяти.
// Вычисляем правильный индекс. Значение имеет формат Uint, поэтому в массиве 256 элементов,
// нужно убедиться, что мы не вышли за границы.
uint uLuma = (uint) lumaOk;
uLuma = min(uLuma, 255);
// Прибавляем 1 к соответствующему значению яркости.
InterlockedAdd (shared_data[uLuma], 1);
Следующим шагом снова будет установка барьера, чтобы гарантировать, что были обработаны все пиксели в строке.
А последним шагом будет прибавление значений из общей памяти в структурированный буфер. Это делается тем же самым образом, через простой цикл:
// Ждём, пока обработаются все пиксели в строке
GroupMemoryBarrierWithGroupSync();
// Прибавление вычисленных значений в структурированный буфер.
[unroll] for (uint idx = 0; idx < 4; idx++)
{
const uint offset = threadID + idx*64;
uint data = shared_data[offset];
InterlockedAdd (g_buffer[offset], data);
}
После того, как все 64 потока в группе потоков заполнят общие данные, каждый поток добавляет 4 значения в буфер вывода.
Рассмотрим буфер вывода. Давайте подумаем об этом. Сумма всех значений в буфере равна общему количеству пикселей! (при 480×270 = 129 600). То есть мы знаем, сколько пикселей имеют конкретное значение яркости.
Если вы слабо разбираетесь в вычислительных шейдерах (как я), то поначалу это может быть непонятно, поэтому прочитайте пост ещё несколько раз, возьмите бумагу и карандаш, и попробуйте разобраться в концепциях, на которых построена эта техника.
Вот и всё! Именно так «Ведьмак 3» вычисляет гистограмму яркости. Лично я при написании этой части многому научился. Поздравляю ребят из CD Projekt Red с отличной работой!
Если вы интересуетесь полным HLSL-шейдером, то он выложен здесь. Я всегда стремлюсь получить как можно более близкий к игровому ассемблерный код и совершенно счастлив, что мне это снова удалось!
Вычисление средней яркости
Это вторая часть анализа вычислений средней яркости в «The Witcher 3: Wild Hunt».
Прежде чем мы вступим в бой с ещё одним вычислительным шейдером, давайте вкратце повторим, что произошло в прошлой части: мы работали с HDR-буфером цветов с уменьшенным до 1/4×1/4 масштабом. После первого прохода мы получили гистограмму яркости (структурированный буфер 256 беззнаковых целочисленных значений). Мы вычислили логарифм для яркости каждого пикселя, распределили его по 256 ячейкам и увеличили соответствующее значение структурированного буфера по 1 на пиксель. Благодаря этому общая сумма всех значений в этих 256 ячейках равна количеству пикселей.
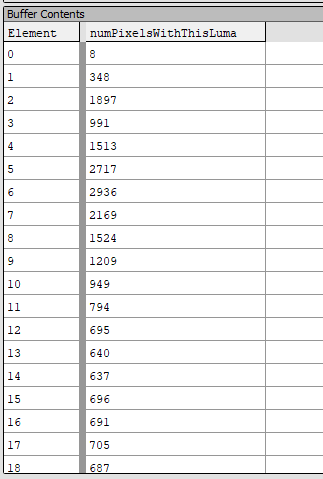
Пример вывода первого прохода. Здесь 256 элементов.
Например, наш полноэкранный буфер имеет размер 1920×1080. После уменьшения масштаба первый проход использовал буфер 480×270. Сумма всех 256 значений в буфере будет равна 480×270 = 129 600.
После этого краткого вступления мы готовы перейти к следующему этапу: к вычислениям.
На этот раз используется только одна группа потоков (Dispatch (1, 1, 1)).
Давайте посмотрим на ассемблерный код вычислительного шейдера:
cs_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb0[1], immediateIndexed
dcl_uav_structured u0, 4
dcl_uav_typed_texture2d (float,float,float,float) u1
dcl_input vThreadIDInGroup.x
dcl_temps 4
dcl_tgsm_structured g0, 4, 256
dcl_thread_group 64, 1, 1
0: ld_structured_indexable(structured_buffer, stride=4)(mixed,mixed,mixed,mixed) r0.x, vThreadIDInGroup.x, l(0), u0.xxxx
1: store_structured g0.x, vThreadIDInGroup.x, l(0), r0.x
2: iadd r0.xyz, vThreadIDInGroup.xxxx, l(64, 128, 192, 0)
3: ld_structured_indexable(structured_buffer, stride=4)(mixed,mixed,mixed,mixed) r0.w, r0.x, l(0), u0.xxxx
4: store_structured g0.x, r0.x, l(0), r0.w
5: ld_structured_indexable(structured_buffer, stride=4)(mixed,mixed,mixed,mixed) r0.x, r0.y, l(0), u0.xxxx
6: store_structured g0.x, r0.y, l(0), r0.x
7: ld_structured_indexable(structured_buffer, stride=4)(mixed,mixed,mixed,mixed) r0.x, r0.z, l(0), u0.xxxx
8: store_structured g0.x, r0.z, l(0), r0.x
9: sync_g_t
10: if_z vThreadIDInGroup.x
11: mul r0.x, cb0[0].y, cb0[0].x
12: ftou r0.x, r0.x
13: utof r0.y, r0.x
14: mul r0.yz, r0.yyyy, cb0[0].zzwz
15: ftoi r0.yz, r0.yyzy
16: iadd r0.x, r0.x, l(-1)
17: imax r0.y, r0.y, l(0)
18: imin r0.y, r0.x, r0.y
19: imax r0.z, r0.y, r0.z
20: imin r0.x, r0.x, r0.z
21: mov r1.z, l(-1)
22: mov r2.xyz, l(0, 0, 0, 0)
23: loop
24: breakc_nz r2.x
25: ld_structured r0.z, r2.z, l(0), g0.xxxx
26: iadd r3.x, r0.z, r2.y
27: ilt r0.z, r0.y, r3.x
28: iadd r3.y, r2.z, l(1)
29: mov r1.xy, r2.yzyy
30: mov r3.z, r2.x
31: movc r2.xyz, r0.zzzz, r1.zxyz, r3.zxyz
32: endloop
33: mov r0.w, l(-1)
34: mov r1.yz, r2.yyzy
35: mov r1.xw, l(0, 0, 0, 0)
36: loop
37: breakc_nz r1.x
38: ld_structured r2.x, r1.z, l(0), g0.xxxx
39: iadd r1.y, r1.y, r2.x
40: utof r2.x, r2.x
41: utof r2.w, r1.z
42: add r2.w, r2.w, l(0.500000)
43: mul r2.w, r2.w, l(0.011271)
44: exp r2.w, r2.w
45: add r2.w, r2.w, l(-1.000000)
46: mad r3.z, r2.x, r2.w, r1.w
47: ilt r2.x, r0.x, r1.y
48: iadd r2.w, -r2.y, r1.y
49: itof r2.w, r2.w
50: div r0.z, r3.z, r2.w
51: iadd r3.y, r1.z, l(1)
52: mov r0.y, r1.z
53: mov r3.w, r1.x
54: movc r1.xzw, r2.xxxx, r0.wwyz, r3.wwyz
55: endloop
56: store_uav_typed u1.xyzw, l(0, 0, 0, 0), r1.wwww
57: endif
58: ret
Здесь есть один буфер констант:

Вкратце взглянем на ассемблерный код: прикреплено два UAV (u0: входной буфер из первой части и u1: выходная текстура формата 1×1 R32_FLOAT). Также мы видим, что есть 64 потока на группу и 256 элементов 4-байтной общей групповой памяти.
Начнём с заполнения общей памяти данными из входного буфера. У нас 64 потока, поэтому делать придётся почти то же самое, что и раньше.
Чтобы быть абсолютно уверенными, что для дальнейшей обработки загружены все данные, после этого мы ставим барьер.
// Первый этап - заполнение всех общих данных данными из предыдущего этапа.
// Так как в каждой группе потоков по 64 потока, каждый может заполнить 4 элемента в одном потоке
// с помощью простого смещения.
[unroll] for (uint idx=0; idx < 4; idx++)
{
const uint offset = threadID + idx*64;
shared_data[ offset ] = g_buffer[offset];
}
// Здесь мы устанавливаем барьер, то есть блокируем выполнение всех потоков группы, пока не будет завершён
// весь общий доступ групп и все потоки в группе не достигнут этого вызова.
GroupMemoryBarrierWithGroupSync();
Все вычисления выполняются только в одном потоке, все другие используются просто для загрузки значений из буфера в общую память.
«Вычисляющий» поток имеет индекс 0. Почему? Теоретически, мы можем использовать любой поток из интервала [0–63], но благодаря сравнению с 0 мы можем избежать дополнительного сравнения integer-integer (инструкции ieq).
Алгоритм основан на указании интервала пикселей, которые будут учитываться в операции.
В строке 11 мы умножаем width*height, получая общее количество пикселей и умножаем их на два числа из интервала [0.0f-1.0f], обозначающие начало и конец интервала. Дальше используются ограничения, гарантирующие, что 0 <= Start <= End <= totalPixels - 1:
// Выполняем вычисления только для потока с индексом 0.
[branch] if (threadID == 0)
{
// Общее количество пикселей в буфере с уменьшенным масштабом
uint totalPixels = cb0_v0.x * cb0_v0.y;
// Интервал пикселей (или, если конкретнее, интервал яркости на экране),
// который мы хотим задействовать в вычислении средней яркости.
int pixelsToConsiderStart = totalPixels * cb0_v0.z;
int pixelsToConsiderEnd = totalPixels * cb0_v0.w;
int pixelsMinusOne = totalPixels — 1;
pixelsToConsiderStart = clamp (pixelsToConsiderStart, 0, pixelsMinusOne);
pixelsToConsiderEnd = clamp (pixelsToConsiderEnd, pixelsToConsiderStart, pixelsMinusOne);
Как видите, ниже есть два цикла. Проблема с ними (или с их ассемблерным кодом) в том, что в концах циклов есть странные условные переходы. Мне было очень сложно воссоздать их. Также взгляните на строку 21. Почему там »-1»? Я объясню это чуть ниже.
Задача первого цикла — отбросить pixelsToConsiderStart и дать нам индекс ячейки буфера, в которой присутствует пиксель pixelsToConsiderStart +1 (а также количество всех пикселей в предыдущих ячейках).
Допустим, что pixelsToConsiderStart примерно равна 30000, а в буфере 37000 пикселей в ячейке «ноль» (такое случается в игре ночью). Поэтому мы хотим начать анализ яркости примерно с пикселя 30001, который присутствует в ячейке «ноль». В данном случае мы сразу же выходим из цикла, получив начальный индекс '0' и ноль отброшенных пикселей.
Посмотрите на код HLSL:
// Количество уже обработанных пикселей
int numProcessedPixels = 0;
// Ячейка яркости [0–255]
int lumaValue = 0;
// Надо ли продолжать выполнение цикла
bool bExitLoop = false;
// Задача первого цикла — отбросить «pixelsToConsiderStart» пикселей.
// Мы сохраняем количество отброшенных пикселей из предыдущих ячеек и lumaValue, чтобы использовать их в следующем цикле.
[loop]
while (! bExitLoop)
{
// Получаем количество пикселей с заданным значением яркости.
uint numPixels = shared_data[lumaValue];
// Проверяем, сколько пикселей должно быть с lumaValue
int tempSum = numProcessedPixels + numPixels;
// Если больше, чем pixelsToConsiderStart, то выходим из цикла.
// Следовательно, мы начнём вычисление яркости из lumaValue.
// Проще говоря, pixelsToConsiderStart — это количество «затемнённых» пикселей, которые нужно отбросить, прежде чем начинать вычисления.
[flatten]
if (tempSum > pixelsToConsiderStart)
{
bExitLoop = true;
}
else
{
numProcessedPixels = tempSum;
lumaValue++;
}
}
Загадочное число »-1» из строки 21 ассемблерного кода связано с булевым условием выполнения цикла (я обнаружил это почти случайно).
Получив количество пикселей из ячеек lumaValue и само lumaValue, мы можем переходить ко второму циклу.
Задача второго цикла — вычисление влияния пикселей и средней яркости.
Мы начинаем с lumaValue, вычисленного в первом цикле.
float finalAvgLuminance = 0.0f;
// Количество отброшенных в первом цикле пикселей
uint numProcessedPixelStart = numProcessedPixels;
// Задача этого цикла — вычисление влияния пикселей и средней яркости.
// Мы начинаем с точки, вычисленной в предыдущем цикле, сохраняя количество отброшенных пикселей и начальную позицию lumaValue.
// Декодируем значение яркости из интервала [0–255], умножаем его на количество пикселей, имеющих это значение яркости, и суммируем их, пока не дойдём
// до обработки пикселей pixelsToConsiderEnd.
// После этого мы делим общее влияние на количество проанализированных пикселей.
bExitLoop = false;
[loop]
while (! bExitLoop)
{
// Получаем количество пикселей с заданным значением яркости.
uint numPixels = shared_data[lumaValue];
// Прибавляем ко всем обработанным пикселям
numProcessedPixels += numPixels;
// Текущее обрабатываемое значение яркости, распределённое в интервале [0–255] (uint)
uint encodedLumaUint = lumaValue;
// Количество пикселей с текущим обрабатываемым значением яркости
float numberOfPixelsWithCurrentLuma = numPixels;
// Текущее обрабатываемое значение яркости, закодированное в интервале [0–255] (float)
float encodedLumaFloat = encodedLumaUint;
На этом этапе мы получили закодированное в интервале [0.0f-255.f] значение яркости.
Процесс декодирования довольно прост — нужно обратить вычисления этапа кодирования.
Краткий повтор процесса кодирования:
float luma = dot( hdrPixelColor, float3(0.2126, 0.7152, 0.0722) );
...
float outLuma;
// так как log (0) равен undef, а log (1) = 0
outLuma = luma + 1.0;
// распределяем логарифмически
outLuma = log (outLuma);
// масштабируем на 128, что означает log (1) * 128 = 0, log (2,71828) * 128 = 128, log (7,38905) * 128 = 256
outLuma = outLuma * 128
// преобразуем в uint
uint outLumaUint = min ((uint) outLuma, 255);
Чтобы декодировать яркость, мы обращаем процесс кодирования, например вот так:
// начинаем с прибавления 0.5f (мы не хотим, чтобы получился нулевой результат)
float fDecodedLuma = encodedLumaFloat + 0.5;
// и декоридуем яркость:
// Делим на 128
fDecodedLuma /= 128.0;
// exp (x), что отменяет log (x)
fDecodedLuma = exp (fDecodedLuma);
// Вычитаем 1.0
fDecodedLuma -= 1.0;
Затем мы вычисляем распределение, умножая количество пикселей с заданной яркостью на декодированную яркость, и суммируя их, пока не дойдём до обработки pixelsToConsiderEndпикселей.
После этого мы делим общее влияние на число проанализированных пикселей.
Вот оставшаяся часть цикла (и шейдера):
// Вычисляем влияние этой яркости
float fCurrentLumaContribution = numberOfPixelsWithCurrentLuma * fDecodedLuma;
// (Временное) влияние от всех предыдущих проходов и текущего.
float tempTotalContribution = fCurrentLumaContribution + finalAvgLuminance;
[flatten]
if (numProcessedPixels > pixelsToConsiderEnd)
{
// чтобы выйти из цикла
bExitLoop = true;
// Мы уже обработали все нужные пиксели, поэтому выполняем здесь окончательное деление.
// Количество всех обработанных пикселей для выбранного пользователем начала
int diff = numProcessedPixels — numProcessedPixelStart;
// Вычисляем окончательную среднюю яркость
finalAvgLuminance = tempTotalContribution / float (diff);
}
else
{
// Передаём текущее влияние дальше и увеличиваем lumaValue
finalAvgLuminance = tempTotalContribution;
lumaValue++;
}
}
// Сохраняем среднюю яркость
g_avgLuminance[uint2(0,0)] = finalAvgLuminance;
Полный шейдер выложен здесь. Он полностью совместим с моей программой HLSLexplorer, без которой бы я не смог эффективно воссоздать вычисление средней яркости в «Ведьмаке 3» (да и все другие эффекты тоже!).
В заключение несколько мыслей. С точки зрения вычисления средней яркости этот шейдер было сложно воссоздать. Основные причины:
1) Странные «отложенные» проверки выполнения цикла, на это потребовалось гораздо больше времени, чем я предполагал ранее.
2) Проблемы с отладкой этого вычислительного шейдера в RenderDoc (v. 1.2).
Операции «ld_structured_indexable» поддерживаются не полностью,
