[Перевод] PuppetConf 2016. Kubernetes для сисадминов. Часть 1
Я системный администратор, занимаюсь компьютерами, и сегодня мы поговорим о Kubernetes. Я постараюсь глубже окунуться в тему, рассмотрев, какие проблемы сисадмин может решить с помощью этого приложения, и также затрону некоторые моменты эксплуатации Puppet, которая вроде как вписалась в этот мир с помощью нового набора абстракций для работы приложения.
Пять или шесть лет назад Луис Андре Барросо и Урс Хёзл в статье «Дата-центр как компьютер» высказали мысль, что мы должны воспринимать центр обработки данных как один массивный компьютер. Нужно абстрагироваться от того, что дата-центр состоит из отдельных машин, и считать его одной логической сущностью. Как только вы попытаетесь использовать эту идею на практике, то сможете применять к дата-центрам принципы построения распределенных систем и распределенных вычислений.

Для того, чтобы относится к центру обработки данных как к компьютеру, вам нужна операционная система. Она выглядит очень похожей на ту, которую вы используете на отдельном компьютере, но должна иметь другой интерфейс, потому что вам не нужен доступ к отдельной машине и не нужен доступ к ядру. Итак, давайте думать о дата-центре как о большом компьютере. Сегодня я расскажу, как вам поступать, если вас будто бы лишат способности управлять любой машиной с помощью SSH. Вы не сможете залогиниться, и хотя некоторые люди считают, что без этого невозможно управлять системой, я расскажу, как много можно сделать при помощи Kubernetes. Во-первых, вы должны воспринимать Kubernetes как фреймворк для строительства распределенных платформ.

Это не означает, что скачав Kubernetes, вы получите пользовательский интерфейс, который предоставит вам все, что вы захотите проделать с системой. Нет, это всего лишь фундамент для создания инструментов, которые необходимы для запуска вашей инфраструктуры. Я покажу, как создать интеграцию с помощью центра сертификации Let's Encrypt для автоматизации процесса оформления сертификатов для моего приложения, использующего Kubernetes в качестве фреймворка.
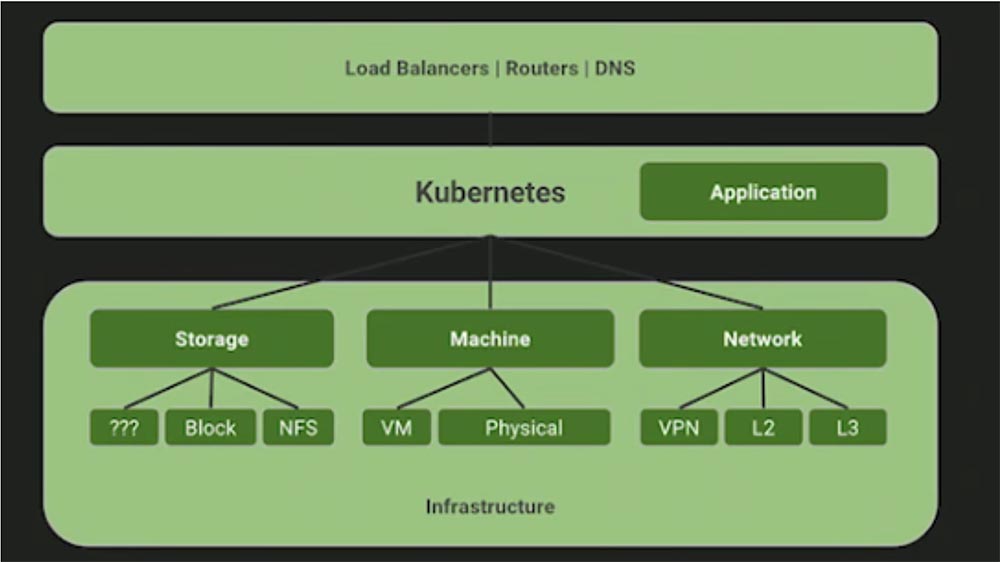
Многие спрашивают, для каких именно целей хорош Kubernetes. Я много лет работал с Puppet Labs и видел, что эту штуку устанавливали на компьютеры для того, чтобы предоставить системе API, которого до сих пор не было. Вместо Bash, скриптов YAML и подобных вещей, Puppet снабдила пользователя DSL, который позволил ему взаимодействовать с машинами программным путем, не используя shell-скрипты. Отличие Kubernetes в том, что он расположен над уровнем «железа». Давайте сфокусируемся не столько на автоматизации и абстракции этой системы, сколько на отношениях, или на контракте, между нашей инфраструктурой и приложениями, которые мы собираемся вытянуть из какого-либо узла. В Kubernetes мы не назначаем машинам никаких приложений, здесь не существует такого понятия, как «манифест узла», планировщик рассматривает отдельные узлы просто как ресурсы дата-центра, представляющего собой один большой компьютер.
Вопросы: «работает ли Kubernetes на базе OpenStack, на VMware, на Bare Metal, в облаке?» не имеют смысла. Правильный вопрос звучит так: «Могу ли я запустить агент Kubernetes для извлечения этих ресурсов?», и ответ на него будет «да». Потому что работа этого приложения совершенно не зависит от выбранной вами платформы.

Kubernetes не зависит от платформы. Kubernetes декларативен так же, как и Puppet. Поэтому вы сообщаете, для какого приложения собираетесь его использовать – в данном примере это nginx. Это контракт, заключаемый между вами, разработчиком, и Kubernetes как средства для создания образов контейнеров.
Я люблю использовать аналогию с курьерской компанией FedEx – вы не можете притащить им целый вагон вещей и ждать, пока они все это рассортируют и отправят куда следует. У них существует правило: упакуйте свои вещи в коробку. Как только вы это сделаете, они отправят вашу коробку и смогут сказать, когда она прибудет в место назначения. «Если у вас нет коробки, то вы не сможете работать с нашей системой».
Поэтому при работе с контейнерами бесполезно обсуждать, что у вас имеется – Python, Java и или что-то еще, это не имеет никакого значения – просто возьмите все ваши зависимости и поместите их в контейнер. Многие люди говорят о контейнерах, что они будто бы решают проблемы целой инфраструктуры. Однако проблема состоит в том, что люди не воспринимают контейнеры как две разные вещи, которыми они являются на самом деле. Первая вещь – это идея формата упаковки, вторая – это идея контейнерной среды выполнения. Это две разные вещи, для которых не обязательно нужны одни и те же инструменты.
Кто из присутствующих создавал контейнеры? А кто использует Puppet для строительства контейнеров? Правильно, я тоже с этим не согласен! Вы можете сказать: «как же так? Вы же на конференции Puppet, вы должны быть согласны!». Причина, по которой я не согласен с идеей строительства контейнеров в Puppet, следующая: я не знаю, нужно ли нам это вообще, потому что вещи, требующиеся нам для создания образа, отличаются от вещей, необходимых для запуска prod-процесса.
Давайте подумаем об этом как о строительстве программного конвейера и взглянем на этот Dockerfile. Закройте глаза те, кто никогда не видел этих файлов, потому что для вас они могут выглядеть пугающе. В этом файле показано, как создать приложение Ruby on Rails – приложение на языке Ruby с каркасом Rails.
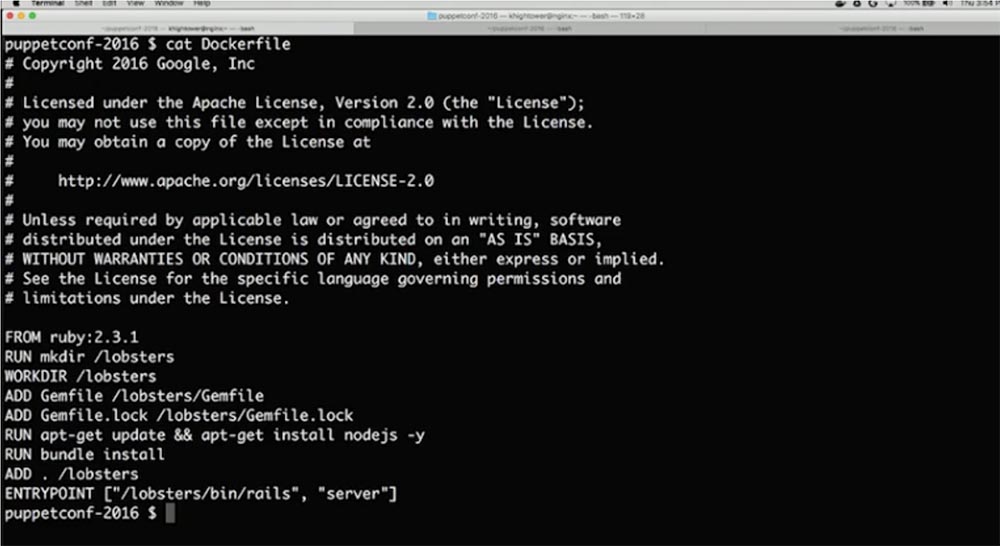
Здесь написано «FROM ruby 2.3.1», что, вероятно, вставит в контейнер всю операционную систему, в данном случае базовый образ alpine-linux Ruby. Кто-нибудь знает, почему мы вставляем в эти контейнеры образы ОС Ubuntu или Red Hat? Большинство людей не знают, что такое зависимости, и используют бессистемный подход, просто запихивая всю ОС в контейнер, чтобы гарантированно иметь свои зависимости где-то там внутри. Итак, после того, как вы построили эту штуку, ее нужно запустить всего один раз. Вот откуда возникает недоразумение: если эта штука не работает, изменяйте строчку кода, пока она не заработает. Просто проверяйте! Не нужно особо мудрить с этими файлами, ваша цель – построить автономную репрезентацию вашего приложения со всеми зависимостями. Это всего лишь костыль, который мы используем из Ubuntu как отправной точки.
Если бы вы просто создали приложение и запустили его в работу, то использовали бы что-то вроде статической ссылки. Никаких зависимостей на хосте, у вас в контейнере был бы просто бинарник однострочного Docker-файла и никаких базовых образов. На самом деле это просто перенос привычных нам вещей. Посмотрите, как будет выглядеть эта сборка.

Я предварительно уже создал этот файл, но обычно он выглядит как попытка построить весь интернет. Я немного побаиваюсь этой сборки, потому что не уверен, что здешний интернет справиться с Ruby. Смотрите, что получилось.

Как вам этот объем в 1 Гиг? Причем исходный файл, то есть само ваше приложение, может занимать, скажем, всего 100 кБ. Так как же мы смогли набрать целый гигабайт? Это происходит потому, что мы пользуемся неэффективными инструментами для сборки автономных приложений. Все они созданы для запуска на компьютерах и используют динамические библиотеки, подгружаемые из внешней среды.
Сейчас мы попробуем сделать то, что мы делаем в мобильном телефоне — portable-версии приложений, для использования которых имеется контракт между вами и инфраструктурой. Как только у нас появится такой контракт, мы сможем указать системе, что именно она должна делать, и ей будет все равно, что делать.
У вас нет никакого особенного, специально созданного приложения. Я сталкивался с компаниями, которые говорят: «у нас особенное приложение!». Я говорю: «Давайте, угадаю, что оно делает: запускается, привязывается к порту, принимает трафик, делает что-то с данными», и они такие: «Вау, откуда ты это знаешь?». Знаю, потому что тут нет ничего особенного!
Итак, мы берем образец, который поместили в контейнер, и отправляем его на сервер API. Далее нам нужно превратить это в нечто такое, что будет работать на нашей машине. Однако для того, чтобы собрать ресурсы с машины, мы должны установить несколько вещей: контейнерную среду выполнения для Docker-файла, агента, который понимает, как общаться с мастером, чтобы запустить все необходимое, какой должна быть ответная реакция системы, чтобы приложение начало работать. Этот агент просто наблюдает – здесь нет никаких 30-ти секундных интервалов, повторных проверок, ничего такого. Он просто наблюдает, говоря: «если для меня найдется работа, дайте об этом знать, и я запущусь и буду постоянно сообщать вам статус процесса», так что вы будете знать, что он работает.
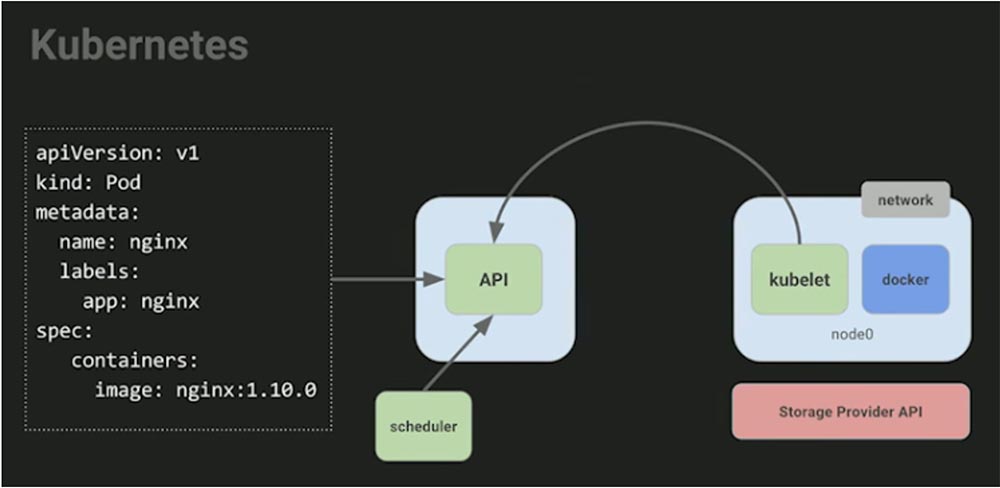
Как только мы это проделаем на машине, нам понадобится планировщик. Сколько людей используют планировщик? Вы все должны поднять руки! Это все равно, что ответ на вопрос: «кто из вас имеет ноутбук с более чем одноядерным процессором?». Действительно, когда я задаю вопрос о планировщике, большинство не поднимает рук.
Когда вы запускаете свой процесс на машине, что-то должно выбрать, какой процессор задействовать. Кто занимается этой работой? Правильно, ядро. Сейчас я объясню вам, ребята, что такое планировщик. Самый быстрый способ это сделать – это сыграть в «Тетрис». Первое, что мы обсудим – это автоматическое развертывание.

Кто из вас использовал полностью автоматическое развертывание? Понятно, думаю, именно поэтому мы все здесь находимся. Итак, я нажимаю кнопку, сверху начинают падать блоки, и теперь можно сходить за пивом. Но обратите внимание, что происходит слева и справа: ваш процессор и ваша память превращаются в мусорную корзину.

Это происходит, потому что большинство людей используют не более 5% компьютерных ресурсов. Вы автоматизируете процессы, но при этом теряете кучу денег. Я работаю облачным провайдером, у меня огромные запасы ресурсов, но просто ужасно, когда люди тратят деньги подобным способом.
Когда вы используете планировщик, то по аналогии с «Тетрис», контролируете игровое поле и управляете каждым блоком, направляя его в нужное место, то есть используете ресурсы машины самым оптимальным путем. Для этого в Kubernetes используют пару алгоритмов. Основной алгоритм носит название Bin Packing – понять его поможет тот же «Тетрис». В Kubernetes поступает рабочая нагрузка разных форм и размеров, и наша задача упаковать ее на машинах оптимальным образом.
Наша цель — повторно использовать все ресурсы, которые становятся доступными по ходу выполнения работы. Не все рабочие нагрузки одинаковы, поэтому их трудно поместить в одну и ту же коробку. Но в Kubernetes, когда появляется какой-то «кусок» рабочей нагрузки (или блок «Тетрис», если продолжить нашу аналогию), всегда находится правильный кластер, куда его можно поместить и запустить. И как при любой пакетной обработке, после того, как задание выполнено, мы получаем обратно все занятые до этого ресурсы, чтобы использовать их для выполнения будущих заданий.
Так как мы обитаем не в игровом, а в реальном мире, у вас имеются решения, наработанные много лет назад. Затем вы становитесь сисадмином, работодатели показывают вам свое производство, и вы замечаете, что их развертывание недостаточно хорошо.
Вы можете установить менеджеры кластеров на части своих машин и позволить им управлять некими ресурсами. В данном конкретном случае можно использовать Kubernetes, который начнет заполнять пустые места вашего «Тетриса» по мере того, как вы будете продвигаться вперед.
Пусть поднимут руки те, кто работает на производстве. Да, это классика, которая называется «зарплата». Предположим, что у вас на предприятии имеется несколько проблем. Первая заключается в том, что все написано на Java или даже на COBOL – вот к этому обычно никто не готов.
Вторая проблема, часто встречающаяся на предприятиях – это СУБД Oracle. Это такая штука, которая находится в тылу программного обеспечения и говорит: «Не вздумайте ничего автоматизировать!». Если вы автоматизируете ПО, у вас увеличится стоимость. Поэтому никакой автоматизации – раскручиваем свою консалтинговую экосистему!
Обычно в таких условиях люди спрашивают, можно ли просто привлечь для решения этих проблем Kubernetes. Отвечаю: «нет», потому что в ситуации, аналогичной проигрышу в «Тетрис», вам уже ничего не поможет. Вам нужно сделать что-то другое, а именно – использовать планировщик.
Теперь, когда у нас есть планировщик, который успешно разбирается с рабочими нагрузками, можно просто разложить все по коробкам, и планировщик начнет свою работу.

Поговорим о ключевых сущностях Kubernetes. Во-первых, это поды Pods, которые представляют собой коллекцию контейнеров. В большинстве случаев приложение состоит более чем из одного компонента. Можно приставить себе приложение, написанное без скриптов Java, но, возможно, вы захотите использовать nginx для завершения TLS и просто прокси в бэкграунде приложения, и тогда эти вещи должны быть соединены вместе, поскольку представляют собой жестко связанные зависимости. Слабо связанная зависимость – это база данных, которую вы независимо масштабируете.

Вторая важная вещь – это контроллер репликации Replication Controller, который представляет собой менеджер процессов, происходящих в кластере Kubernetes. Он позволяет создать несколько экземпляров подов и следить за их состоянием.
Когда вы говорите о том, что хотели бы запустить какой-то процесс, это значит, что он все время будет работать где-то в кластере.
Третий важный элемент – это служба Service, набор совместно работающих подов. Ваше развертывание базируется на основе динамического определения желаемого состояния – где должны работать приложения, с каким IP-адресом и т.д., поэтому вам нужна какая-то форма сервиса.
Четвертый элемент – это хранилища Volumes, которые можно рассматривать как каталоги, доступные для контейнеров в поде. В Kubernetes существуют разные типы Volumes, определяющие, как создается данное хранилище и что оно содержит. Концепция Volume присутствовала и в Docker, однако проблема заключалась в том, что там хранилище было ограничено конкретным подом. Как только под прекращал существование, Volume исчезал вместе с ним.
Хранилище, которые создаются с помощью Kubernetes, не ограничиваются каким-либо контейнером. Оно поддерживает любой или все контейнеры, развернутые внутри пода. Ключевым преимуществом Kubernetes Volume является поддержка различных типов хранилищ, которые Pod может использовать одновременно.
Давайте рассмотрим, что представляет собой контейнер. Это формат образа, в который запаковывается наше приложение со всеми зависимостями, и основная конфигурация среды выполнения, показывающая, каким образом это приложение должно работать. Это два разных элемента, хотя вы можете упаковать в эту штуку все, что угодно, в частности, Root Filesystem в виде сжатого tar-файла Tarball, который содержит множество конфигурационных файлов для конкретной системы.
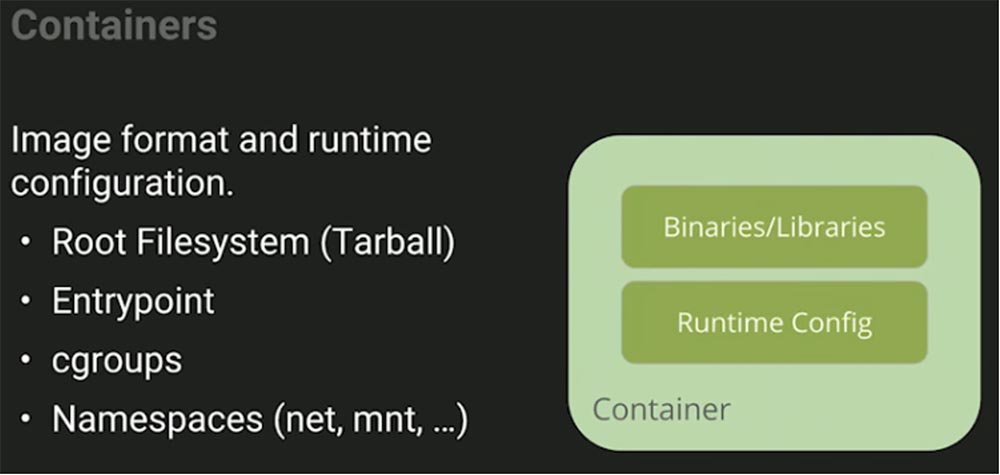
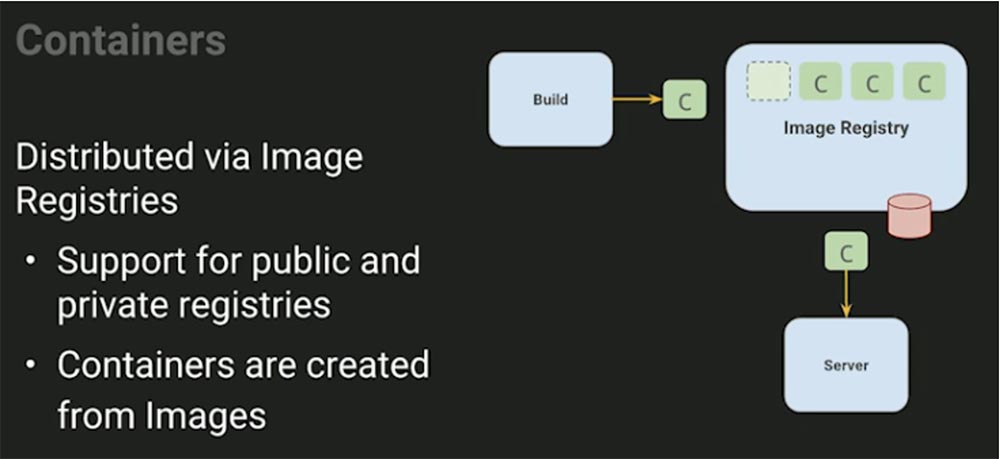
Затем мы можем выполнить дистрибуцию, всем вам хорошо знакомый процесс – здесь используется RPM или другая система репозитория. Вы берете все эти вещи и помещаете их в репозиторий. Этот процесс очень похож на то, что мы делаем с пакетами OS, только касается контейнеров, которые создаются из образов.
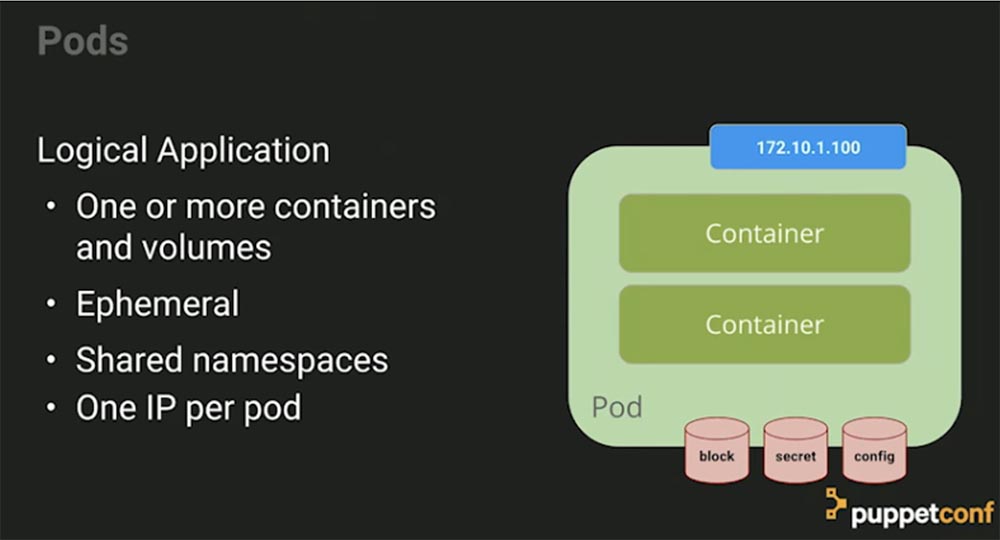
Pod позволяет составить композицию всего того, в чем нуждается наше логическое приложение. Логическое приложение — это средство управления несколькими приложениями в рамках одного системного профиля. Под — это пакет ресурсов, куда входят один или несколько контейнеров и хранилищ, общее пространство имен и один IP-адрес на каждый под. Хранилища могут распределяться между контейнерами.
В целом конструкция пода напоминает виртуальную машину. Она гарантирует, что приложение будет запускаться и останавливаться как атомарная единица. На следующем слайде показано, как выглядит контроллер репликации. Если я отправлю эту декларацию на сервер и скажу: «Эй, я хочу, чтобы заработала одна реплика приложения «Foo»!», то контроллер создаст ее из шаблона и отправит в работу планировщику, который разместит приложение на машине Node 1. Мы не указываем, на какой именно машине оно должно запускаться, хотя можем это сделать. Теперь увеличим количество реплик до 3.

Каких действий вы ожидаете от системы, если одна из машин выйдет из строя? В этом случае контроллер репликации приведет текущее состояние системы к желаемому состоянию, перенеся под с контейнером с третьей, нерабочей машины, на вторую.
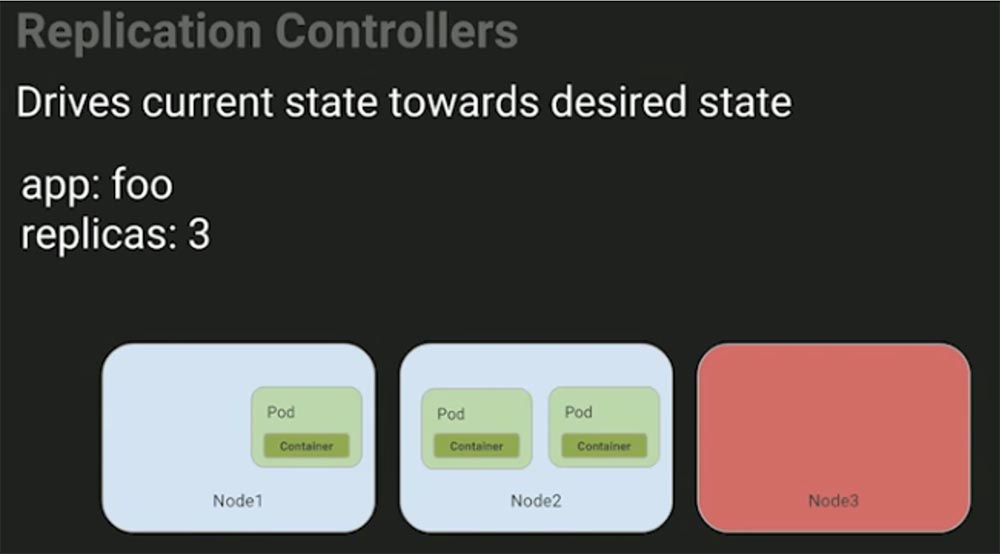
Вам не нужно вникать в этот процесс и руководить им – поручая работу контроллеру, вы можете быть уверенны, что работа приложений будет обеспечена должным образом за счет постоянного наблюдения за изменениями текущего состояния инфраструктуры и принятия решений, обеспечивающих работоспособность системы.
Эти вещи опережают свое время – вы просто говорите системе: «Я хочу, чтобы три эти машины работали!», и на этом ваше управление заканчивается. Такой подход сильно отличается от скриптинга и чистой автоматизации, когда вам действительно нужно управлять тем, что происходит прямо сейчас, чтобы повлиять на будущее решение. Вы не можете кодифицировать все это без возможности получать входящую информацию, чтобы реагировать на ситуацию должным образом. Описанный выше подход предоставляет вам такую возможность.
Как вы представляете себе конфигурацию – концепцию файлов настроек для сервисов? Очень много людей замалчивают этот вопрос, когда речь заходит о контейнерах, но мы все еще нуждаемся в конфигурации, она никуда не исчезает!
В Kubernetes используется также концепция Secrets, которая служит для хранения и передачи зашифрованных данных между менеджерами и узлами Nods.
Мы никогда не запускаем Puppet в контейнере, потому что не существует никаких причин это делать. Можно использовать Puppet для генерации config-файла, однако вы все равно захотите хранить его в Kubernetis, потому что это позволяет распространять его с помощью среды выполнения. Рассмотрим, как это выглядит.
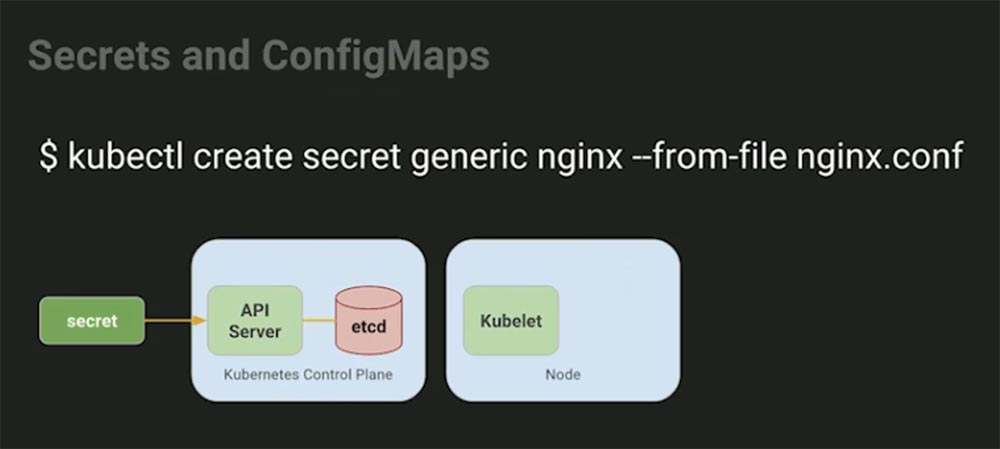
В этом примере мы создаем secret из файла и сохраняем его на API-сервере Kubernetes. Можете представить, что вы заменили эту часть на что-то вроде Puppet, которая использует шаблон eRB и скрытые данные для заполнения содержимого secret — не имеет значения, кто это делает, но вы в любом случае можете это проделать.
Как только secret оказывается на месте, он может послужить ссылкой для создания развертывания, которое говорит: «Я хочу использовать этот secret!». В этом случае Kubernetes совершает следующее.

Он создает pod, берет данные из secret, помещает их во временную файловую систему и представляет в виде контейнера, точно так же, как Puppet создает копию на машине. Это следует за жизненным циклом приложения, и когда приложение «умирает», конфигурация исчезает вместе с ним. Если вам нужно 10 000 экземпляров приложений, понадобится создать и инъектировать в под 10 000 временных файловых систем.
Services позволяет запустить все эти элементы в кластере и синхронизировать их с другой конечной точкой endpoint. Фактически сервис представляет собой группу подов, функционирующих как единый под. Он содержит постоянный IP-адрес и порт, обеспечивает интеграцию в DNS, использует балансировку нагрузки и обновляется при изменении программно-аппаратной части.

А теперь давайте рассмотрим совместную работу концептуальных составляющих Kubernetes. У нас имеются кирпичики Lego и конфигурации, которые должны взаимодействовать друг с другом. Если вы собираетесь запустить в кластере базу данных, то действительно можете это сделать в системе Kubernetes. Многие говорят, что вы не сможете запускать stateful- приложения в контейнерах, но это совершенно не так.
Если задуматься о том, как работают гипервизоры, можно понять, что они делают почти то же самое, что и вы: создают виртуальную машину, планировщик перемещает ее к гипервизору и присоединяет хранилище. Иногда вы работаете с локальным хранилищем, которое поступает от гипервизора, и не существует никаких причин, по которым контейнеры не могли бы сделать то же самое.
Однако проблема с контейнерами заключается в том, что большинство людей не приучены иметь явный список путей к файлам, который они должны предоставить приложению. Большинство людей не смогут точно назвать вам устройства и файлы, в которых нуждается хранилище данных. Они упаковывают в контейнеры все подряд, и в результате из этого не получается ничего хорошего. Поэтому не верьте, что контейнеры не способны запускать приложения, сохраняющие состояние – вы вполне можете это сделать.

На слайде вы видите пример Ruby-on-Rails, и прежде, чем мы сможем использовать наше приложение, необходимо выполнить миграцию базу данных. Давайте приступим к «живой» демонстрации программы. Для того, чтобы осуществить развертывание, я использую MY_SQL, и вы видите на экране массу данных.

Я показываю вам все это, потому что как системный администратор вы должны разбираться во многих вещах. В этом развертывании я уточняю некоторые метаданные своего приложения, но главное я выделю серым цветом: я хочу запустить 1 копию приложения mysql и использовать контейнер mysql версии 5.6.32.

Заметьте, что здесь я выбираю из Kubernetes некоторые secret в качестве ссылок, которые в данном случае собираюсь инъектировать как переменные среды. Позже я покажу вам еще один случай, когда мы вставляем их в файловую систему. Таким образом, мне не нужно «запекать» secrets в свою конфигурацию. Следующие важные строки – это блок ресурсов.
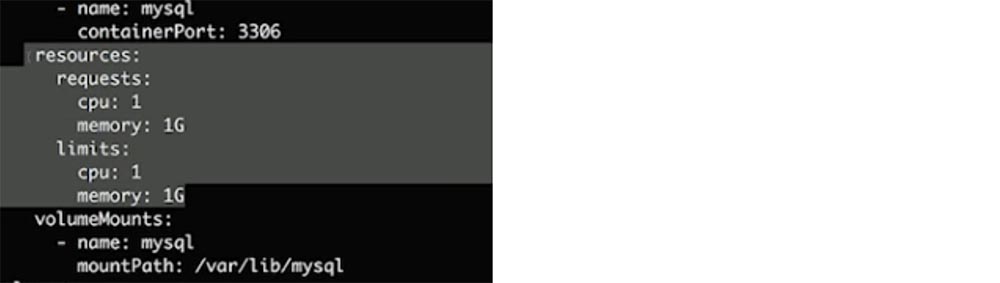
Вы не сможете играть в «Тетрис», пока не узнаете размер блоков. Множество людей начинают развертывание, не использовав ограничения ресурсов для этого процесса. В результате RAM полностью забивается, и вы «укладываете» весь сервер.
22:09 мин
Продолжение будет совсем скоро…
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас:Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
