[Перевод] Prometheus
Доброго всем.
Делимся тут очень интересной статьёй, на которую натыкались в рамках подготовки нашего курса. Перевод идёт, как есть целиком (за исключением некоторых комментариев).
Предыстория
В двух словах — вступление о мониторинге и аппеляционности убеждений
Как многим известно, я сопровождаю Riemann — инструмент обработки потоков событий для мониторинга распределенных систем. В моей книге, посвященной мониторингу, я использовал Riemann, как основной инструмент для изучения новых подходов и паттернов мониторинга, и описал архитектуру whitebox-мониторинга (с выборочным blackbox-мониторингом), используя push модель.
Чтобы понять, о чем я вообще веду речь, объясним некоторые концепции. Blackbox-мониторинг отвечает за проверку внешних характеристик сервисов или приложений: возможно ли подключиться к открытому порту сервиса, возвращаются ли корректные данные или код ответа. Примером blackbox-мониторинга может служить ICMP-запрос и подтверждение получения ответа.
В свою очередь, whitebox-мониторинг сфокусирован на том, что происходит внутри сервиса или приложения. Приложение, обладающее соответствующим инструментарием, возвращает состояние самого себя или внутренних компонентов, результат выполнения транзакций или событий. Эти данные отвечают на вопрос «как работает приложение», а не на вопрос «работает ли приложение». Whitebox-мониторинг передает события, логи или метрики в специальный инструмент для мониторинга или предоставляет информацию наружу для последующего сбора инструментом мониторинга.
Большинство людей, занимающихся современным мониторингом, понимают, что в whitebox-мониторинг нужно вкладывать большие инвестиции. Информация, полученная изнутри приложения представляет ощутимо бОльшую ценность для бизнеса и эксплуатации, чем та, что получена на поверхности. Это совсем не значит, что blackbox-мониторинг — пустая трата ресурсов. Внешний мониторинг сервисов и приложений полезен, особенно для служб, которые находятся за пределами вашего контроля, или когда взгляд извне дает контекст, недоступный изнутри, например, касательно маршрутизации или проблем DNS.
В книге я фокусируюсь на работе с push-моделью, а не pull. Также много внимания в книге уделено преимуществам мониторинга на основе push-модели над pull-моделью. Многие (если не большинство) системы мониторинга построены именно на основе pull/polling-модели. В такой модели система опрашивает сервис или приложение, которое мониторит. В свою очередь в push-модели приложения и сервисы сами отправляют данные в систему мониторинга.
По множеству причин (некоторые из них не очевидны на первый взгляд) я предпочитаю push-модель. Но особенности обоих подходов зачастую не мешают реализации по ряду причин (например, из-за масштаба). А вероятность успеха никак не зависит от споров о реализации или инструментах. Я придерживаюсь мнения, что инструменты, в первую очередь, должны подходить именно вам, и нет смысла бездумно следовать тенденциям или догматизму.
Именно стремление не быть категоричным и недостаточность понимания различий сообществом воодушевили меня написать вводный туториал для одного из ведущих инструментов мониторинга на базе pull-модели: Prometheus. Он очень популярен, особенно в мире контейнеров и Kubernetes.
Знакомство с Prometheus
Prometheus разработан инженерами Soundcloud, ранее работавшими в Google. Он написан на Go, обладает открытым исходным кодом и разрабатывается при поддержке Cloud Native Computing Foundation. Источником вдохновения для проекта послужил Borgmon от Google.
Prometheus сфокусирован на whitebox-мониторинге. Он собирает time series данные, полученные из приложений и сервисов. Приложение предоставляет эти данные самостоятельно или через плагины, которые называются экспортеры (exporters).
Платформа Prometheus основывается на сервере, который собирает и хранит time series данные. Она обладает многомерной моделью временных рядов, объединяющую метрические имена и пары ключ/значение, называемые метками для метаданных. Time series данные хранятся на сервере, отдельные серверы автономны и не зависят от распределенного хранилища.
Платформа также содержит клиентские библиотеки и ряд экспортеров для специфических функций и компонентов. Например, экспортер StatsD, который преобразует time series данные StatsD в формат Prometheus. Кроме того, есть push-gateway для приема небольших объемов входящих данных и alert manager, который умеет обрабатывать уведомления, созданные триггерами или при превышении пороговых значений данных, собранных Prometheus.
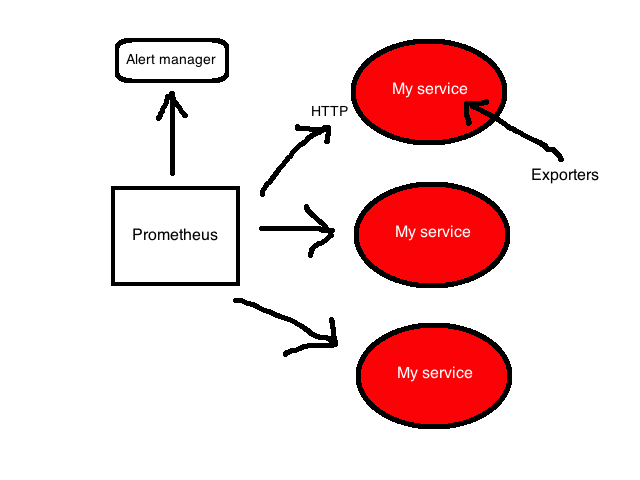
С более детальной архитектурой можно познакомиться в документации Prometheus.
Установка
Сервер Prometheus — бинарный файл с одноименным названием prometheus. Возьмем его последнюю версию и распакуем.
$ wget https://github.com/prometheus/prometheus/releases/download/v1.8.0/prometheus-1.8.0.darwin-amd64.tar.gz
$ tar -xzf prometheus-*.tar.gz
$ cd prometheus-1.8.0.darwin-amd64/На официальном сайте также размещены различные дополнительные компоненты: alert manager для отправки уведомлений и экспортеры для разнообразных сервисов.
Настройка
Бинарный файл prometheus, который мы только что распаковали, настраивается через YAML файл. Посмотрим, что он собой представляет:
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
monitor: 'codelab-monitor'
rule_files:
# - "first.rules"
# - "second.rules"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
В данном конфигурационном файле определены три YAML блока:
Глобальный
Первый блок global содержит глобальные настройки для управления поведением сервера.
scrape_interval задает интервалы между опросами приложения или сервиса, в нашем случае 15 секунд. Это разрешение шкалы данных, т. е. период времени, который покрывается каждой точкой данных.
evaluation_interval сообщает Prometheus, как часто обрабатывать данные согласно правилам. Правила бывают двух основных видов: правила записи и правила алерта. Правила записи позволяют заранее вычислить часто используемые и ресурсоемкие выражения и сохранить результат в виде новых time series данных. Правила алерта позволяют определять условия оповещений. Prometheus будет (пере-)проверять эти условия каждый 15 секунд.
В external_labels содержится список пар «ключ/значение» для меток, которые будут добавлены к любой метрике, существующей на сервере, например, при генерации предупреждения.
Файлы правил
Второй блок — rule_files, содержит в себе список файлов с правилами записи или алерта.
Конфигурация опросов
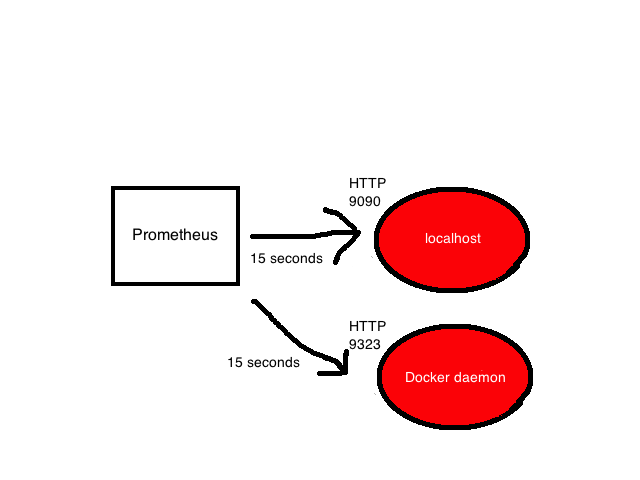
Последний блок scrape_configs показывает все цели, которые Prometheus будет опрашивать. Prometheus называет цели инстансами (instances), а группы инстансов — заданием (job). По умолчанию есть только одно задание — prometheus. Внутри него лежит static_config со списком инстансов (по умолчанию только один — сервер Prometheus). Он опрашивает порт 9090 localhost«а для получения метрик состояния самого сервера. Предполагается, что метрики находятся в /metrics, поэтому локально опрашивается адрес localhost:9090/metrics. Путь можно изменить с помощью опции metric_path.
Одинокий задание — довольно скучно, поэтому добавим еще одно для опроса локального демона Docker. Воспользуемся инструкцией в документации Docker и настроим демона, чтобы он отдавал метрики с адреса localhost:9323/metrics. А после, добавим еще одно задание с названием docker.
- job_name: 'docker'
static_configs:
- targets: ['localhost:9323']
У задания есть имя и инстанс, который ссылается на адрес для получения метрик демона Docker. Путь по умолчанию снова /metrics.
Полный конфигурационный файл можно найти по ссылке.
Запуск сервера
Запустим сервер и посмотрим, что происходит.
$ ./prometheus -config.file "prometheus.yml"Запускаем бинарный файл и указываем файл настройки во флаге командной строки -config.file. Сервер Prometheus теперь запущен, опрашивает инстансы в заданиях prometheus и docker и возвращает результаты.
Дашборд
У Prometheus есть встроенный интерфейс, где можно посмотреть результаты. Для этого нужно открыть в браузере http://localhost:9090/graph.
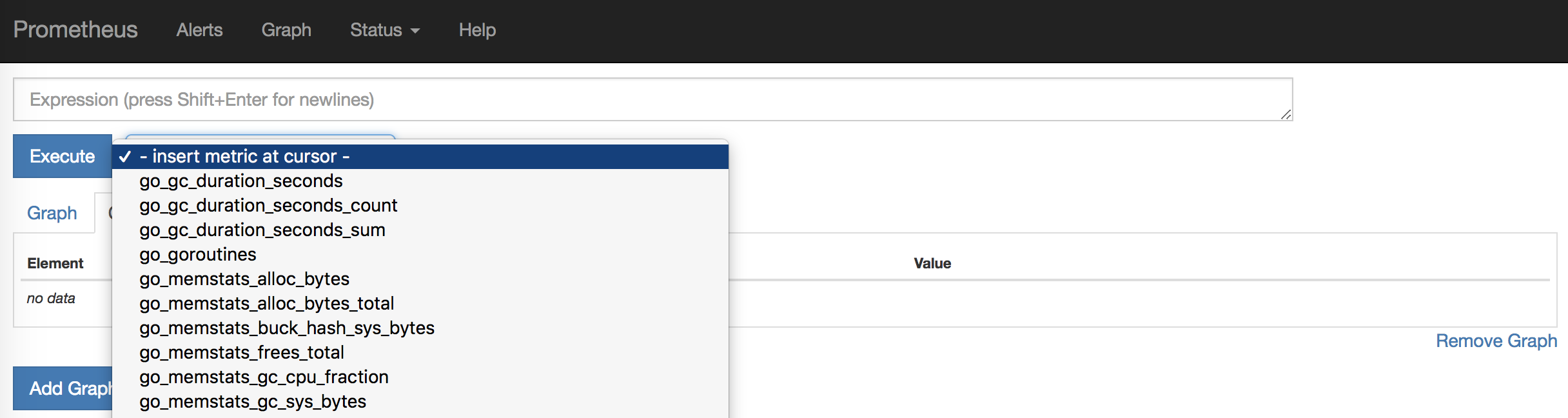
Если кликнуть по — insert metric at cursor -, можно выбрать одну из собираемых метрик. Посмотрим на HTTP запросы. Для этого нужно выбрать метрику http_requests_total и нажать Execute.
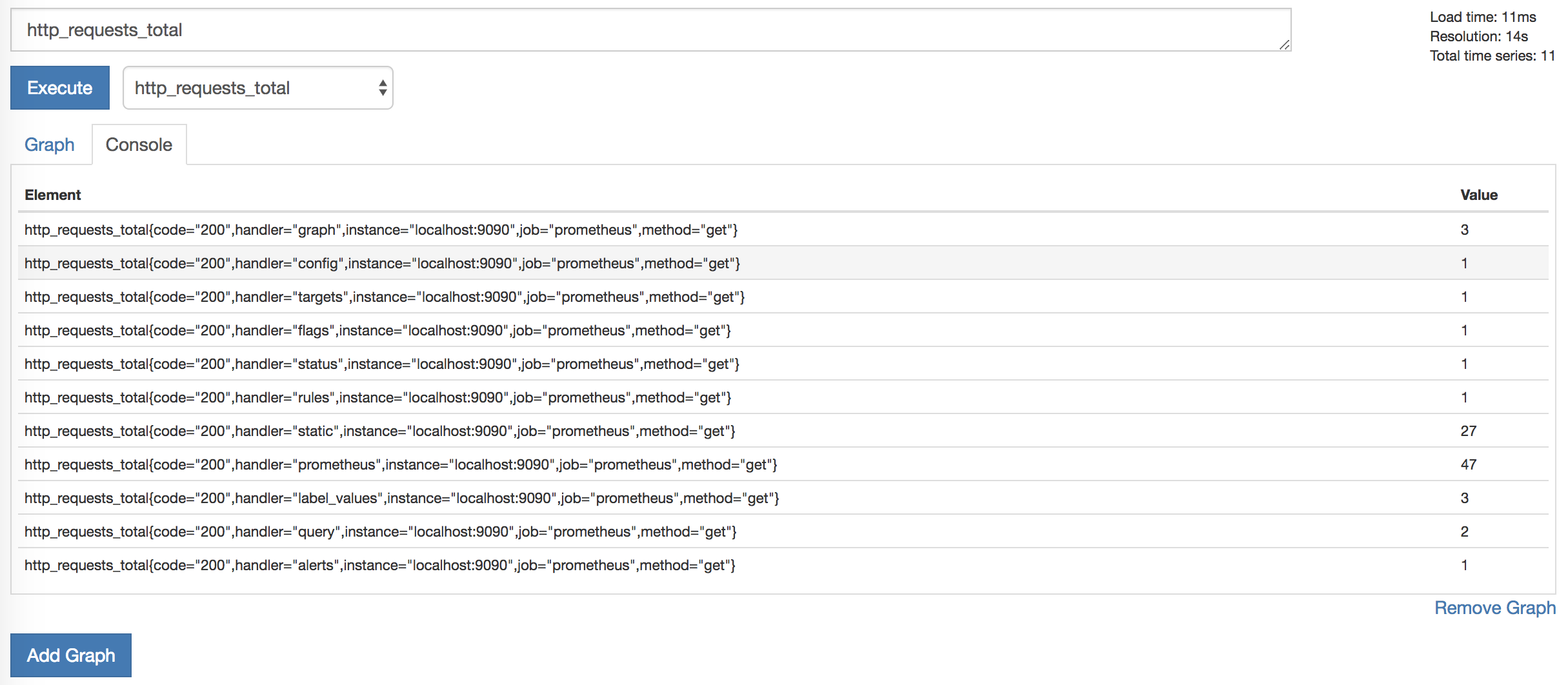
Появится список элементов и значений, например:
http_requests_total{code="200",handler="prometheus",instance="localhost:9090",job="prometheus",method="get"}Эти элементы являются метриками, которые разделены дополнительными измерениями (они предоставляются метками метрик). Например, у метрики http_requests_total есть метка handler, которая содержит информацию о порождающем запрос процессе. Список метрик можно уменьшить, выбрав конкретные метрики, содержащие одну из этих меток.
Гибкость языка выражений, встроенного на сервер Prometheus, упрощает поиск и агрегирование метрик.

Мы использовали метку handler, чтобы выбрать метрики только для хендлера prometheus.
Дополнительно агрегируем метрики HTTP запросов. Допустим, необходимо посмотреть количество HTTP запросов за пять минут, разбитых по заданиям. Для этого уточним запрос:
sum(rate(http_requests_total[5m])) by (job)Теперь выполним запрос, нажав Execute:

Дополнительно можно посмотреть график результатов, выбрав вкладку Graph:

На нем мы видим общее количество HTTP запросов за последние пять минут, сгруппированных по заданиям.
Мы можем сохранить эти запросы в качестве правил записи, обеспечивая их автоматическое выполнение и создание новой метрики из данного правила.
Для этого добавим файл в блок rule_files:
rule_files:
- "first.rules"
# - "second.rules"И пропишем следующее правило в файл first.rules:
job:http_requests_total:sum = sum(rate(http_requests_total[5m])) by (job)Это создаст новую метрику job: http_requests_total: sum для каждого задания.

Теперь можно сделать график из метрики и добавить его в дашборд.
Alerting
Предупреждения, как и агрегация, основываются на правилах. Чтобы добавить правило предупреждения, нужно прописать еще один файл в блок rule_files.
rule_files:
- "first.rules"
- "second.rules"Создадим в файле second.rule новое правило, которое будет уведомлять о падении инстансов. Для этого используем одну из стандартных метрик для сбора: up — это метрика состояния, ее значение равно 1, если опрос успешен, и 0, если опрос потерпел неудачу.
Добавим правило алерта в файл правил. Выглядеть оно должно следующим образом:
ALERT InstanceDown
IF up == 0
FOR 5m
LABELS { severity = "moderate" }
ANNOTATIONS {
summary = "Instance {{ $labels.instance }} down",
description = "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.",
}
Правило алерта немного похоже на условный запрос. Мы даем ему имя InstanceDown и набор правил. Алерт InstanceDown срабатывает, когда метрика up равна 0 (т. е. сбор метрик провалился) на протяжении пяти минут. Мы добавили метку к алерту: severity = moderate (т.е. уровень серьезности = умеренный) и аннотации. Аннотации позволяют добавить больше информации алерту, например, описание события. Аннотации содержат {{ }} — скобки для шаблонизации в Go, в которых прописаны переменные. Так мы можем кастомизировать алерт с помощью шаблонов. В нашем случае, переменная $labels содержит метку метрики, например, $labels.instance возвращает имя инстанса, $labels.job имя джоба, и т.д.
Теперь, спустя пять минут после остановки демона Docker, Prometheus запустит наш алерт и отправит сообщение в диспетчер Alertmanager (который предварительно нужно установить и запустить отдельно, либо воспользоваться каким-то другим инструментом, например, Alerta tool). Текущие уведомления можно увидеть на дашборде во вкладке Alerts.
Заключение
Prometheus — отличная платформа, которую легко установить и настроить. Конфигурация описывается в YAML, что упрощает использование подхода Infrastructure as Code (IaC). Мониторинг простых окружений становится безболезненным благодаря автономному серверу. К сожалению, не удалось найти много примеров для более сложных окружений, поэтому стоит потратить время на эксперименты и разные подходы, чтобы найти наиболее оптимальный способ.
Модель данных очень гибкая, особенно поражает легкость, с которой можно присваивать метки метрикам и производить по ним поиск. Я познакомился с большей частью клиентских библиотек и с несколькими экспортерами — ничего сверхсложного. Создание инструментов и генерация метрик не должна вызвать больших трудностей.
Встроенный интерфейс чистый и элегантный, а в совокупности с языком запросов, выглядит как подходящий инструмент для отладки или планирования ресурсов. Правила записи подходят для агрегации метрик.
Я немного изучил хранилище, безопасность, обнаружение серверов и прочие доступные интеграции — возможности выглядят всеобъемлющими. Быстрый поиск по GitHub показал внушительный набор инструментов, интеграций и примеров, которых для начала точно должно хватить.
У основной платформы есть достаточная документация, но для некоторых смежных проектов она довольно хаотичная и неполная. Хотя даже при ограниченном знании Prometheus, буквально за час мне удалось создать рабочую конфигурацию.
Распространение одного бинарного файла без скриптов инициализации или пакетирования нельзя назвать решением, готовым к использованию из коробки, но, тем не менее, это рабочее решение для многих проектов. Также существуют различные подготовительные скрипты среди систем управления конфигурации, которыми можно воспользоваться. Тем не менее, большинство исследующих инструменты вроде Prometheus’а скорее всего справятся с установкой самостоятельно. Поддержка контейнеров и Kubernetes привлекательна для людей, пользующихся этими инструментами. А исследователей (микро-)сервисов и динамических или облачных стеков заинтересует автономность и портативность сервера.
Если у вас есть проект, где нужно реализовать мониторинг, я рекомендую Prometheus. Он также стоит потраченного времени, если ваша деятельность связана с контейнерами и инструментами вроде Docker и Kubernetes. Благодаря своей гибкости он подходит для таких инструментов и архитектур гораздо лучше других существующих платформ.
P.S. Вдохновением для этого поста послужила статья Monitoring in the time of Cloud Native, написанная Синди Сридхаран (Cindy Sridharan). Спасибо, Синди!
THE END
Надеемся, что буде полезно.
