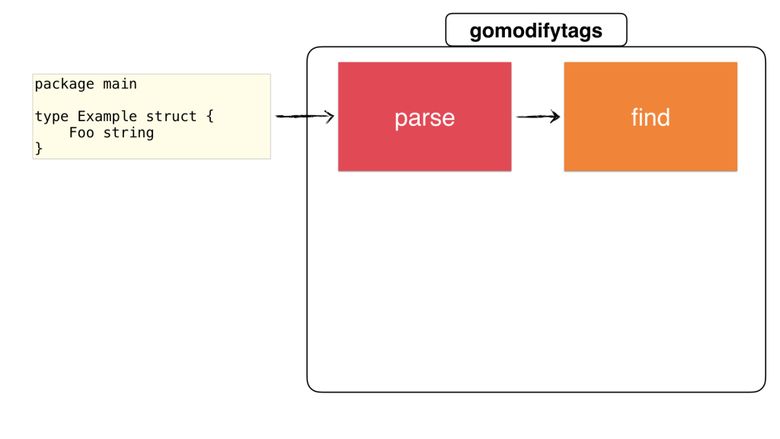
[Перевод] Полное руководство по написанию утилиты для Go

Некоторое время назад я начал делать утилиту, которая упростила бы мне жизнь. Она называется gomodifytags. Утилита автоматически заполняет поля структурных тегов (struct tag) с помощью имён полей. Пример:
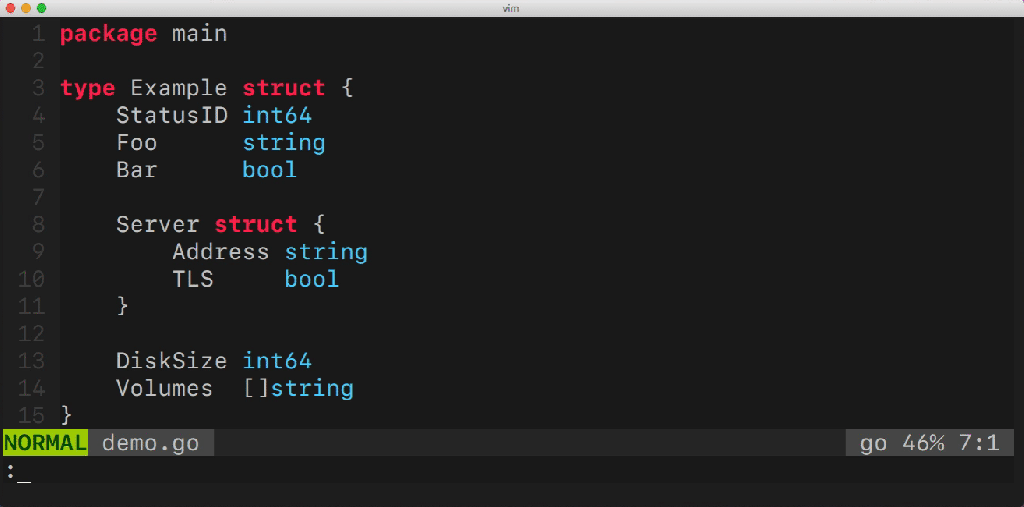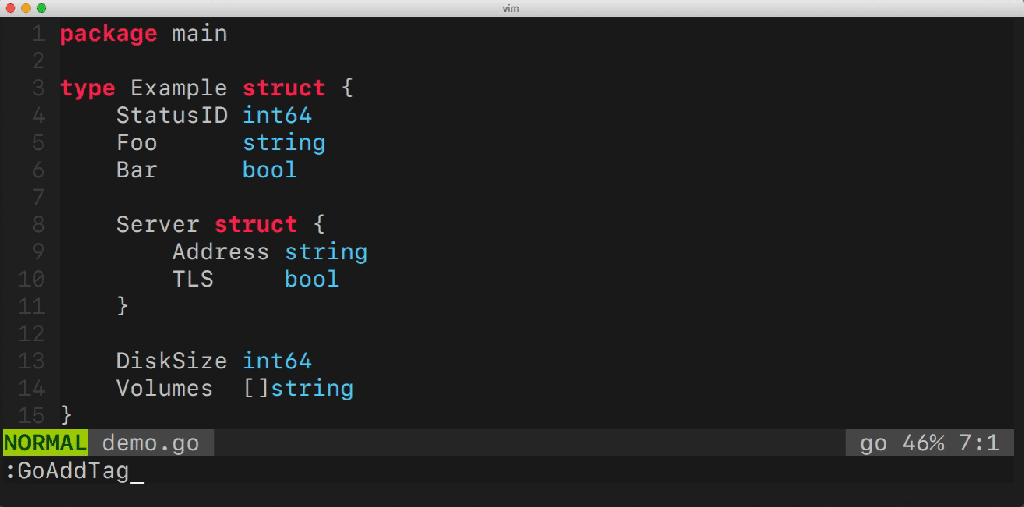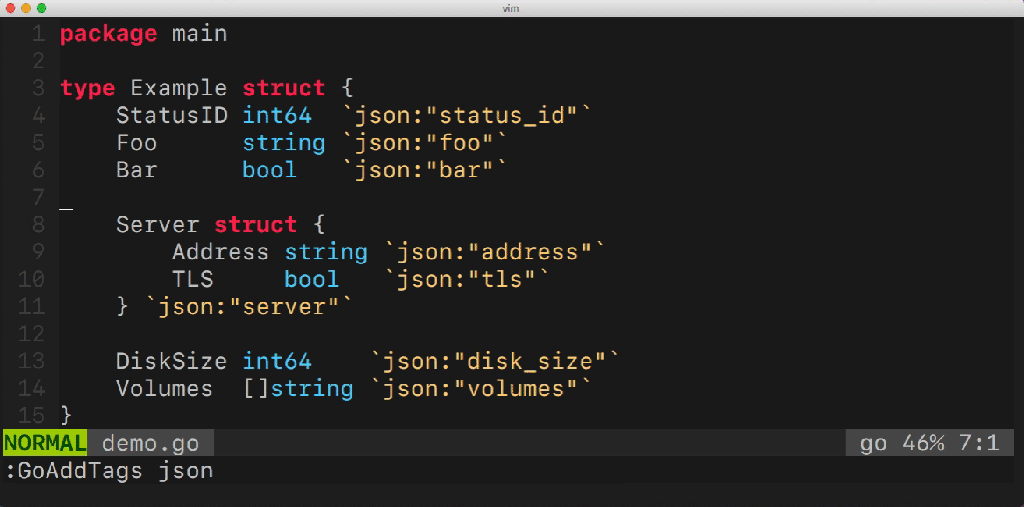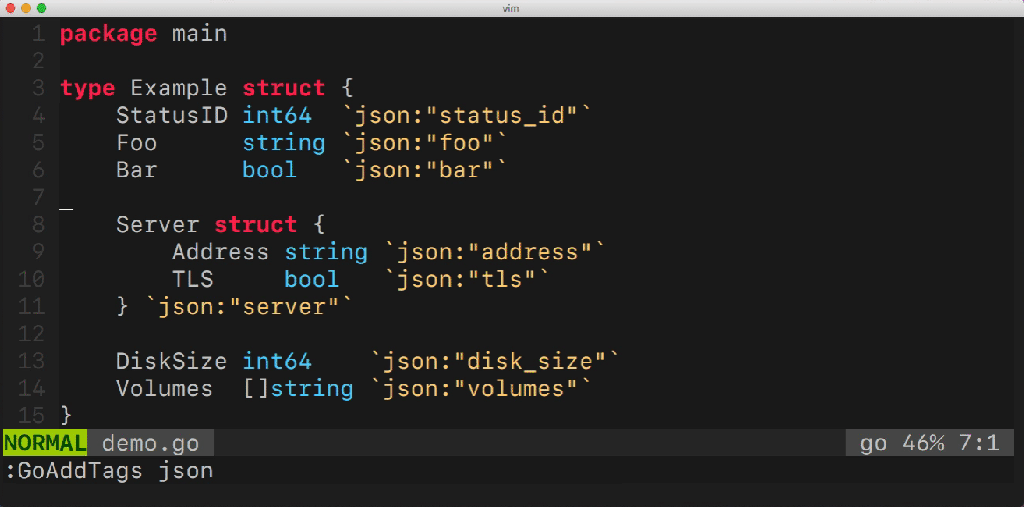
Эта утилита облегчает управление многочисленными полями структуры. Она умеет добавлять и удалять теги, управлять их опциями (например, omitempty), определять правила трансформации (snake_case, camelCase и пр.) и многое другое. Как эта утилита работает? Какие Go-пакеты она использует? Наверное, у вас есть много вопросов.
В этой очень длинной статье я подробно расскажу о том, как написать и собрать такую утилиту. Здесь вы найдёте много советов и хитростей, а также кода на Go.
Налейте кофе и начинайте читать!
Сначала разберёмся, что должна сделать утилита:
- Считать исходный файл, понять его, преобразовать в Go-файл.
- Найти соответствующую структуру.
- Получить имена полей.
- Обновить структурные теги с учётом имён полей (в соответствии с правилом трансформации, например snake_case).
- И наконец, внести эти изменения в файл или выдать их программисту в другом, удобном виде.
Начнём с определения структурного тега, а потом последовательно будем строить утилиту, изучая ее части и их взаимодействие друг с другом.

Тег value (к примеру, его содержимое json:"foo") не упомянут в официальной спецификации. Но в пакете reflect есть неофициальная спецификация, которая определяет этот тег в формате, который также используют пакеты stdlib (вроде encoding/json). Сделано это через тип reflect.StructTag:
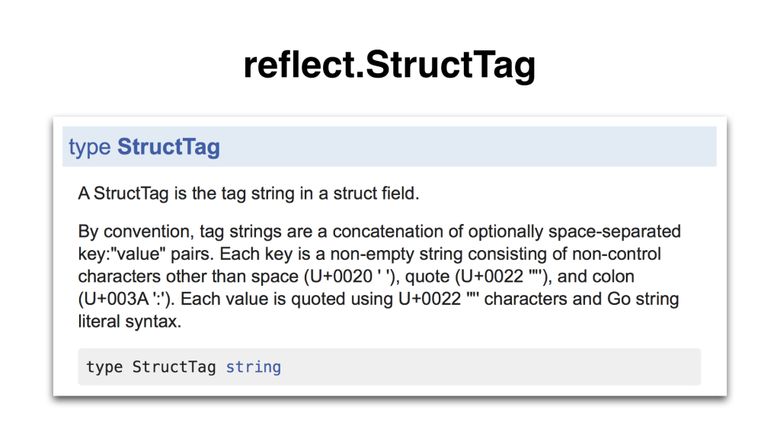
Определение непростое, давайте разберёмся в нём:
- Структурный тег — это строковый литерал (потому что относится к строковому типу).
- Ключ — строковый литерал, не заключённый в кавычки.
- Значение — строковый литерал, заключённый в кавычки.
- Ключ и значение разделены двоеточием (:). Всё вместе называется парой ключ-значение.
- Структурный тег может содержать несколько пар ключ-значение (при желании). Пары разделяются пробелами.
- Настройка опций не описана в определении. Пакеты вроде encoding/json считывают значения в виде списка, где в качестве разделителей используются запятые. Всё, что идёт после первой запятой, — часть опций. Например, в списке »foo, omitempty, string» перечислены значение «foo» и опции [«omitempty», «string»].
- Поскольку структурный тег — это строковый литерал, его нужно взять в двойные кавычки или обратные апострофы (левые одинарные кавычки).
Повторим все эти правила:

В определении структурных тегов есть много неочевидных подробностей
Теперь мы знаем, что собой представляет структурный тег, и можем легко изменить его, как нам нужно. Вопрос в том, как теперь его отпарсить, чтобы легко изменить? К счастью, reflect.StructTag также имеет метод, позволяющий парсить тег и возвращать значения для заданного ключа. Пример:
package main
import (
"fmt"
"reflect"
)
func main() {
tag := reflect.StructTag(`species:"gopher" color:"blue"`)
fmt.Println(tag.Get("color"), tag.Get("species"))
}Выводит на экран:
blue gopherЕсли ключ не существует, возвращается пустая строка.
Очень полезно, однако есть ограничения, делающие эту возможность бесполезной для нас, поскольку нам нужно более гибкое решение. Список ограничений:
- Не распознаёт ошибки в теге (например, ключ в кавычках, значение без кавычек и т. д.).
- Не распознаёт семантику опций.
- Не умеет проходить по существующим тегам или возвращать их. Нужно знать заранее, какие теги мы хотим изменить. А если имя неизвестно?
- Невозможно изменять существующие теги.
- Нельзя с нуля сконструировать новые структурные теги.
Я написал свой Go-пакет, который исправляет все перечисленные недостатки и предоставляет API, позволяющий легко менять любые части структурного тега.

Пакет называется structtag, его можно скачать отсюда: github.com/fatih/structtag. Пакет умеет аккуратно парсить и изменять теги. Ниже приведён полностью рабочий пример, можете скопировать его и протестировать:
package main
import (
"fmt"
"github.com/fatih/structtag"
)
func main() {
tag := `json:"foo,omitempty,string" xml:"foo"`
// parse the tag
tags, err := structtag.Parse(string(tag))
if err != nil {
panic(err)
}
// iterate over all tags
for _, t := range tags.Tags() {
fmt.Printf("tag: %+v\n", t)
}
// get a single tag
jsonTag, err := tags.Get("json")
if err != nil {
panic(err)
}
// change existing tag
jsonTag.Name = "foo_bar"
jsonTag.Options = nil
tags.Set(jsonTag)
// add new tag
tags.Set(&structtag.Tag{
Key: "hcl",
Name: "foo",
Options: []string{"squash"},
})
// print the tags
fmt.Println(tags) // Output: json:"foo_bar" xml:"foo" hcl:"foo,squash"
}Теперь мы умеем парсить структурный тег, изменять его и создавать новый. Теперь нужно изменить корректный исходный Go-файл. В приведённом примере тег уже есть, а как нам его получить из существующей Go-структуры?
Ответ: через AST. AST (Abstract Syntax Tree, абстрактное синтаксическое дерево) позволяет извлечь из исходного кода любой идентификатор (узел). Ниже показано упрощённое дерево структурного типа:

Базовое представление структурного типа Go ast.Node
В этом дереве можно извлекать любой идентификатор и манипулировать им — строкой, скобкой и т. д. Каждый из них представлен AST-узлом. Например, можно изменить имя поля с «Foo» на «Bar», заменив представляющий его узел. То же самое и со структурным тегом.
Чтобы получить Go AST, нужно отпарсить исходный файл и преобразовать его в AST. Всё это делается в один этап.
Для парсинга файла воспользуемся пакетом go/parser (чтобы построить дерево всего файла), а затем с помощью пакета go/ast пройдём по дереву (можно и вручную, но это тема для отдельной статьи). Вот полностью работающий пример:
package main
import (
"fmt"
"go/ast"
"go/parser"
"go/token"
)
func main() {
src := `package main
type Example struct {
Foo string` + " `json:\"foo\"` }"
fset := token.NewFileSet()
file, err := parser.ParseFile(fset, "demo", src, parser.ParseComments)
if err != nil {
panic(err)
}
ast.Inspect(file, func(x ast.Node) bool {
s, ok := x.(*ast.StructType)
if !ok {
return true
}
for _, field := range s.Fields.List {
fmt.Printf("Field: %s\n", field.Names[0].Name)
fmt.Printf("Tag: %s\n", field.Tag.Value)
}
return false
})
}Результат выполнения:
Field: Foo
Tag: `json:"foo"`Что мы делаем:
- С помощью единственной структуры определяем пример корректного Go-пакета.
- Используем пакет go/parser для парсинга этой строки. Также пакет может прочитать с диска файл (или весь пакет).
- После разбора файла переходим к нашему узлу (приписанному к файлу переменной) и ищем AST-узел, определённый *ast.StructType (см. схему AST). Посредством функции
ast.Inspect()проходим вниз по дереву. Функция перебирает все узлы, пока не находит неверное значение. Получается очень удобно, потому что нам не нужно запоминать узлы. - Выводим на экран имя поля структуры и структурный тег.
Теперь мы умеем решать две важные задачи. Во-первых, мы знаем, как парсить исходный Go-файл и извлекать структурный тег (с помощью go/parser). Во-вторых, мы умеем парсить структурный тег и изменять его так, как нам нужно (с помощью github.com/fatih/structtag).
Теперь можно начать собирать нашу утилиту (gomodifytags) с помощью двух этих умений. Она должна:
- Получать конфигурацию, в которой указано, какую структуру нужно изменить.
- Находить и изменять эту структуру.
- Выводить результат.
Поскольку gomodifytags будет чаще всего исполняться редакторами, мы станем передавать конфигурацию через CLI-флаги. Второй этап состоит из нескольких шагов, таких как парсинг файла, поиск корректной структуры и её изменение (посредством AST). Наконец, мы выведем результат либо в исходный Go-файл, либо через какой-то протокол (вроде JSON, об этом поговорим ниже).
Упрощённая основная функция gomodifytags:

Давайте подробно рассмотрим каждый шаг. Я постараюсь рассказать попроще. Хотя здесь всё то же самое, и, закончив читать, вы сможете разобраться с исходным кодом безо всякой помощи (ссылки на исходники приведены в конце руководства).
Начнём с получения конфигурации. Ниже показана конфигурация, в которой есть вся необходимая информация.
type config struct {
// first section - input & output
file string
modified io.Reader
output string
write bool
// second section - struct selection
offset int
structName string
line string
start, end int
// third section - struct modification
remove []string
add []string
override bool
transform string
sort bool
clear bool
addOpts []string
removeOpts []string
clearOpt bool
}Конфигурация состоит из трёх разделов.
В первом собраны настройки, описывающие, как и какой файл нужно прочитать. Это можно сделать через имя файла из локальной файловой системы или напрямую из stdin (обычно применяется при работе в редакторах). Также в первом разделе указано, как выводить результаты (в исходный Go-файл или JSON) и нужно ли переписать файл вместо вывода в stdout.
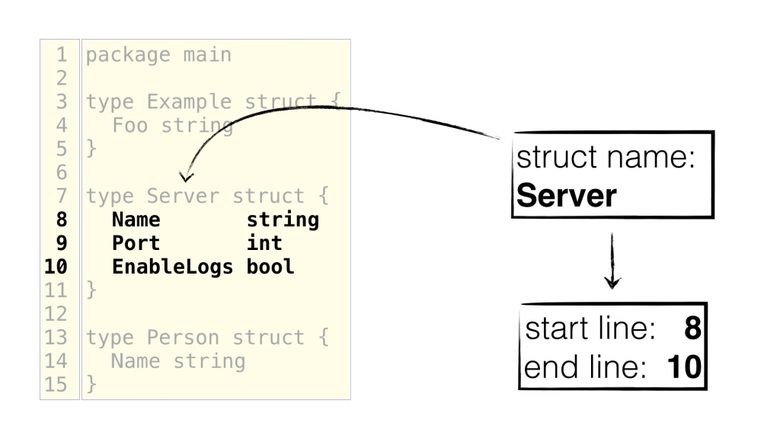
Во втором разделе указано, как выбирать структуру и её поля. Это можно сделать разными способами: с помощью смещения (позиции курсора), имени структуры, одной строки (которая просто выбирает поле) или диапазона строк. В конце нужно обязательно извлечь начальную и конечную строки. Ниже показано, как мы выбираем структуру по её имени, а затем извлекаем начальную и конечную строки, чтобы выбрать правильные поля:
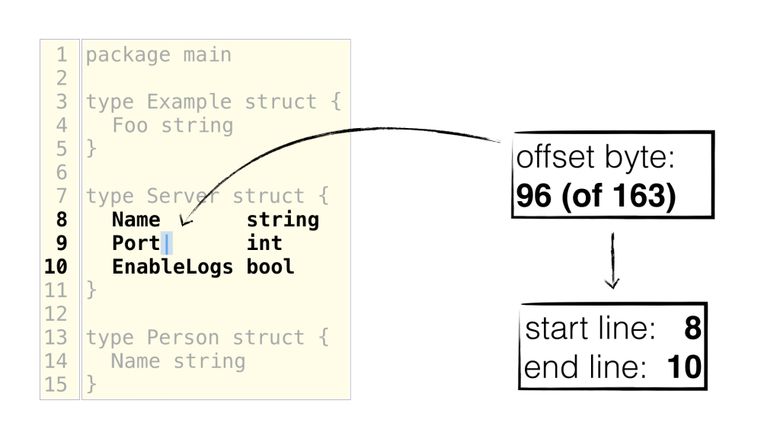
В то же время редакторам удобнее использовать байтовое смещение. На иллюстрации ниже курсор стоит сразу за именем поля "Port", откуда можно легко получить начальную и конечную строки:
Третий раздел конфигурации посвящён передаче данных нашему пакету structtag. После чтения всех полей конфигурация передаётся в пакет structtag, который позволяет парсить структурный тег и изменять его части. Но при этом поля структуры не перезаписываются и не обновляются.
А как нам получить конфигурацию? Возьмём пакет flag, создадим флаги для каждого поля в конфигурации и привяжем к ним. Например:
flagFile := flag.String("file", "", "Filename to be parsed")
cfg := &config{
file: *flagFile,
}Сделаем то же самое для каждого поля в конфигурации. Полный список определений флагов можно найти в текущем мастере gomodifytag.
Получив конфигурацию, выполним базовую проверку:
func main() {
cfg := config{ ... }
err := cfg.validate()
if err != nil {
log.Fatalln(err)
}
// continue parsing
}
// validate validates whether the config is valid or not
func (c *config) validate() error {
if c.file == "" {
return errors.New("no file is passed")
}
if c.line == "" && c.offset == 0 && c.structName == "" {
return errors.New("-line, -offset or -struct is not passed")
}
if c.line != "" && c.offset != 0 ||
c.line != "" && c.structName != "" ||
c.offset != 0 && c.structName != "" {
return errors.New("-line, -offset or -struct cannot be used together. pick one")
}
if (c.add == nil || len(c.add) == 0) &&
(c.addOptions == nil || len(c.addOptions) == 0) &&
!c.clear &&
!c.clearOption &&
(c.removeOptions == nil || len(c.removeOptions) == 0) &&
(c.remove == nil || len(c.remove) == 0) {
return errors.New("one of " +
"[-add-tags, -add-options, -remove-tags, -remove-options, -clear-tags, -clear-options]" +
" should be defined")
}
return nil
}Если проверка выполняется в одной функции, то её проще тестировать.
Перейдём к парсингу файла:
В начале мы уже говорили о том, как парсить файл. В данном случае парсингом занимается метод в структуре config. На самом деле все методы — часть этой структуры:
func main() {
cfg := config{}
node, err := cfg.parse()
if err != nil {
return err
}
// continue find struct selection ...
}
func (c *config) parse() (ast.Node, error) {
c.fset = token.NewFileSet()
var contents interface{}
if c.modified != nil {
archive, err := buildutil.ParseOverlayArchive(c.modified)
if err != nil {
return nil, fmt.Errorf("failed to parse -modified archive: %v", err)
}
fc, ok := archive[c.file]
if !ok {
return nil, fmt.Errorf("couldn't find %s in archive", c.file)
}
contents = fc
}
return parser.ParseFile(c.fset, c.file, contents, parser.ParseComments)
}Функция parse умеет только парсить исходный код и возвращать ast.Node. Всё очень просто, если мы передаём файл, в нашем случае используется функция parser.ParseFile(). Обратите внимание на token.NewFileSet(), создающую тип *token.FileSet. Мы храним её в c.fset, но также передаём в функцию parser.ParseFile(). Почему?
Потому что fileset используется для хранения информации о расположении каждого узла независимо для каждого файла. Позднее это будет очень полезно для получения точного расположения ast.Node. (Обратите внимание, что ast.Node использует компактную информацию о расположении под названием token.Pos. Если расшифровать token.Pos с помощью функции token.FileSet.Position(), то получим token.Position, содержащую больше информации.)
Идём дальше. Ситуация становится интересней, если передавать исходный файл через stdin. Поле config.modified — это io.Reader для лёгкого тестирования, но на самом деле мы передаём stdin. А как определить, что мы хотим читать из stdin?
Мы спрашиваем пользователя, хочет ли он передавать контент через stdin. В этом случае пользователю нужно передать флаг --modified (это булев флаг). Если он передаёт, то мы просто прикрепляем stdin к c.modified:
flagModified = flag.Bool("modified", false,
"read an archive of modified files from standard input")
if *flagModified {
cfg.modified = os.Stdin
}Если вы снова посмотрите на функцию config.parse(), то увидите, что она проверяет прикреплённость поля .modified. Stdin — произвольный поток данных, который нужно парсить в соответствии с выбранным протоколом. В нашем случае мы предполагаем, что архив содержит:
- Имя файла, потом новую строку.
- Размер файла в десятичном выражении, потом новую строку.
- Содержимое файла.
Раз мы знаем размер файла, то можем спокойно парсить содержимое. Если что-то окажется больше по размеру, то просто остановим парсинг.
Такой подход используется в нескольких других утилитах (например, guru, gogetdoc и др.), он очень удобен для редакторов, потому что те могут передавать содержимое модифицированных файлов без сохранения в файловой системе. Поэтому и «модифицированных».
Итак, у нас есть узел, давайте искать структуру:
В основной функции мы собираемся вызывать функцию findSelection() с ast.Node, который мы пропарсили на предыдущем шаге:
func main() {
// ... parse file and get ast.Node
start, end, err := cfg.findSelection(node)
if err != nil {
return err
}
// continue rewriting the node with the start&end position
}Функция cfg.findSelection() на основе конфигурации возвращает начальную и конечную позиции структуры, а также порядок выбора структуры. Она проходит по заданному узлу и возвращает начальную и конечную позиции (как объяснялось в разделе про конфигурацию):
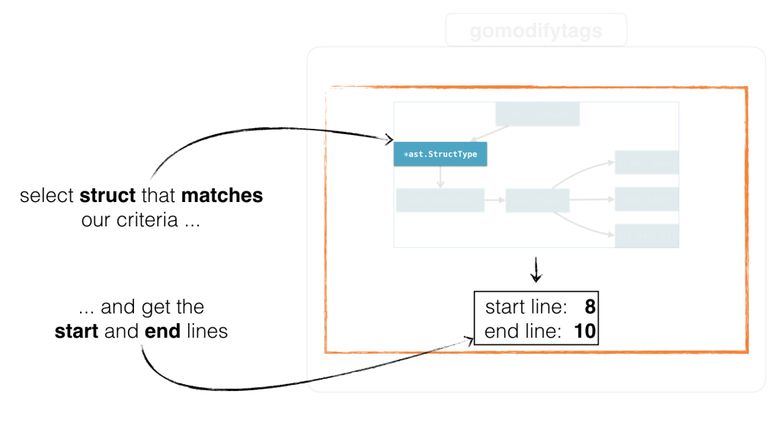
Затем функция переберёт все узлы, пока не найдёт *ast.StructType, и вернёт в файл её начальную и конечную позиции.
Но как это делается? Вспомните, что у нас есть три режима. Выбор по строке, по смещению и по имени структуры:
// findSelection returns the start and end position of the fields that are
// suspect to change. It depends on the line, struct or offset selection.
func (c *config) findSelection(node ast.Node) (int, int, error) {
if c.line != "" {
return c.lineSelection(node)
} else if c.offset != 0 {
return c.offsetSelection(node)
} else if c.structName != "" {
return c.structSelection(node)
} else {
return 0, 0, errors.New("-line, -offset or -struct is not passed")
}
}Выбирать по строке легче всего. Мы просто возвращаем само значение флага. Если пользователь передал флаг "--line 3,50", то функция возвращает (3, 50, nil). Она просто выделяет значение и преобразует его в целые числа (и заодно проверяет):
func (c *config) lineSelection(file ast.Node) (int, int, error) {
var err error
splitted := strings.Split(c.line, ",")
start, err := strconv.Atoi(splitted[0])
if err != nil {
return 0, 0, err
}
end := start
if len(splitted) == 2 {
end, err = strconv.Atoi(splitted[1])
if err != nil {
return 0, 0, err
}
}
if start > end {
return 0, 0, errors.New("wrong range. start line cannot be larger than end line")
}
return start, end, nil
}Этот режим используют редакторы, когда вы выбираете группу строк и выделяете (подсвечиваете) их.
Выбор по смещению и по имени структуры требует больше работы. Сначала нужно собрать все имеющиеся структуры, чтобы можно было вычислить смещение или поискать по имени. Итак, собираем все структуры:
// collectStructs collects and maps structType nodes to their positions
func collectStructs(node ast.Node) map[token.Pos]*structType {
structs := make(map[token.Pos]*structType, 0)
collectStructs := func(n ast.Node) bool {
t, ok := n.(*ast.TypeSpec)
if !ok {
return true
}
if t.Type == nil {
return true
}
structName := t.Name.Name
x, ok := t.Type.(*ast.StructType)
if !ok {
return true
}
structs[x.Pos()] = &structType{
name: structName,
node: x,
}
return true
}
ast.Inspect(node, collectStructs)
return structs
}Функция ast.Inspect() проходит вниз по AST и ищет структуры.
Сначала нам нужна *ast.TypeSpec, чтобы можно было извлечь имя. Поиск *ast.StructType даст нам саму структуру, но не её имя. Поэтому мы используем тип structType, содержащий имя и узел структуры, это удобно. Поскольку позиция каждой структуры уникальна, мы возьмём позицию в качестве ключа для привязки.
Теперь у нас есть все структуры, и мы можем вернуть начальную и конечную позиции для режимов со смещением и именем структуры. В первом случае проверим, попадает ли смещение внутрь заданной структуры:
func (c *config) offsetSelection(file ast.Node) (int, int, error) {
structs := collectStructs(file)
var encStruct *ast.StructType
for _, st := range structs {
structBegin := c.fset.Position(st.node.Pos()).Offset
structEnd := c.fset.Position(st.node.End()).Offset
if structBegin <= c.offset && c.offset <= structEnd {
encStruct = st.node
break
}
}
if encStruct == nil {
return 0, 0, errors.New("offset is not inside a struct")
}
// offset mode selects all fields
start := c.fset.Position(encStruct.Pos()).Line
end := c.fset.Position(encStruct.End()).Line
return start, end, nil
}Мы используем collectStructs() для сбора и последующего итерирования по структурам. Помните, что мы сохранили начальный token.FileSet, который использовали для парсинга файла?
Теперь он поможет нам получить информацию о смещении из каждого отдельного узла структуры (расшифруем в token.Position и получим поле .Offset). Мы просто проверяем и итерируем, пока не найдём нашу структуру (в данном случае с именем encStruct):
for _, st := range structs {
structBegin := c.fset.Position(st.node.Pos()).Offset
structEnd := c.fset.Position(st.node.End()).Offset
if structBegin <= c.offset && c.offset <= structEnd {
encStruct = st.node
break
}
}С помощью этой информации можно извлечь начальную и конечную позиции найденной структуры:
start := c.fset.Position(encStruct.Pos()).Line
end := c.fset.Position(encStruct.End()).LineТу же самую логику применяем при выборе имени структуры. Просто вместо проверки, оказывается ли смещение внутри заданной структуры, мы проверяем имя структуры, пока не найдём нужную:
func (c *config) structSelection(file ast.Node) (int, int, error) {
// ...
for _, st := range structs {
if st.name == c.structName {
encStruct = st.node
}
}
// ...
}Получили начальную и конечную позиции, переходим к модифицированию полей структуры:

В нашей основной функции вызовем функцию cfg.rewrite() с узлом, который распарсили на предыдущем шаге:
func main() {
// ... find start and end position of the struct to be modified
rewrittenNode, errs := cfg.rewrite(node, start, end)
if errs != nil {
if _, ok := errs.(*rewriteErrors); !ok {
return errs
}
}
// continue outputting the rewritten node
}Это ключевая часть утилиты. Функция rewrite переписывает поля всех структур между начальной и конечной позициями.
// rewrite rewrites the node for structs between the start and end
// positions and returns the rewritten node
func (c *config) rewrite(node ast.Node, start, end int) (ast.Node, error) {
errs := &rewriteErrors{errs: make([]error, 0)}
rewriteFunc := func(n ast.Node) bool {
// rewrite the node ...
}
if len(errs.errs) == 0 {
return node, nil
}
ast.Inspect(node, rewriteFunc)
return node, errs
}Как видите, мы опять используем ast.Inspect() для прохождения вниз по дереву для заданного узла. Внутри функции rewriteFunc мы переписываем теги каждого поля (подробнее об этом поговорим дальше).
Поскольку функция, возвращённая ast.Inspect(), не возвращает ошибку, мы создадим схему ошибок (определим с помощью переменной errs), а затем будем собирать их, проходя вниз по дереву и обрабатывая поля. Давайте разберёмся с rewriteFunc:
rewriteFunc := func(n ast.Node) bool {
x, ok := n.(*ast.StructType)
if !ok {
return true
}
for _, f := range x.Fields.List {
line := c.fset.Position(f.Pos()).Line
if !(start <= line && line <= end) {
continue
}
if f.Tag == nil {
f.Tag = &ast.BasicLit{}
}
fieldName := ""
if len(f.Names) != 0 {
fieldName = f.Names[0].Name
}
// anonymous field
if f.Names == nil {
ident, ok := f.Type.(*ast.Ident)
if !ok {
continue
}
fieldName = ident.Name
}
res, err := c.process(fieldName, f.Tag.Value)
if err != nil {
errs.Append(fmt.Errorf("%s:%d:%d:%s",
c.fset.Position(f.Pos()).Filename,
c.fset.Position(f.Pos()).Line,
c.fset.Position(f.Pos()).Column,
err))
continue
}
f.Tag.Value = res
}
return true
}Помните, что эта функция вызывается для каждого узла AST. Поэтому мы ищем только узлы типа *ast.StructType. Потом начинаем итерировать по полям структуры.
Здесь мы снова используем наши любимые переменные start и end. Этот код определяет, хотим ли мы модифицировать поле. Если его позиция находится между start—end, то продолжаем, в противном случае не обращаем внимания:
if !(start <= line && line <= end) {
continue // skip processing the field
}Далее проверяем, есть ли тег. Если поле тега пустое (nil), мы его инициализируем с пустым тегом. Позднее это поможет избежать путаницы в функции cfg.process():
if f.Tag == nil {
f.Tag = &ast.BasicLit{}
}Прежде чем продолжать, позвольте объяснить кое-что интересное. gomodifytags пытается получить имя поля и обработать его. А если поле анонимное?
type Bar string
type Foo struct {
Bar //this is an anonymous field
}В таком случае у поля нет имени, и тогда мы предполагаем имя поля исходя из имени типа:
// if there is a field name use it
fieldName := ""
if len(f.Names) != 0 {
fieldName = f.Names[0].Name
}
// if there is no field name, get it from type's name
if f.Names == nil {
ident, ok := f.Type.(*ast.Ident)
if !ok {
continue
}
fieldName = ident.Name
}Получив имя поля и значение тега, можно начать обработку поля. За обработку отвечает функция cfg.process() (если есть имя поля и значение тега). Она возвращает результат (в нашем случае это форматирование структурного тега), который мы используем для перезаписи существующего значения тега:
res, err := c.process(fieldName, f.Tag.Value)
if err != nil {
errs.Append(fmt.Errorf("%s:%d:%d:%s",
c.fset.Position(f.Pos()).Filename,
c.fset.Position(f.Pos()).Line,
c.fset.Position(f.Pos()).Column,
err))
continue
}
// rewrite the field with the new result,i.e: json:"foo"
f.Tag.Value = resЕсли помните structtag, то здесь фактически возвращается String ()-представление экземпляра тега. Прежде чем вернуть конечное представление тега, мы воспользуемся разными методами пакета structtag для желаемого модифицирования структуры. Упрощённый обзор:
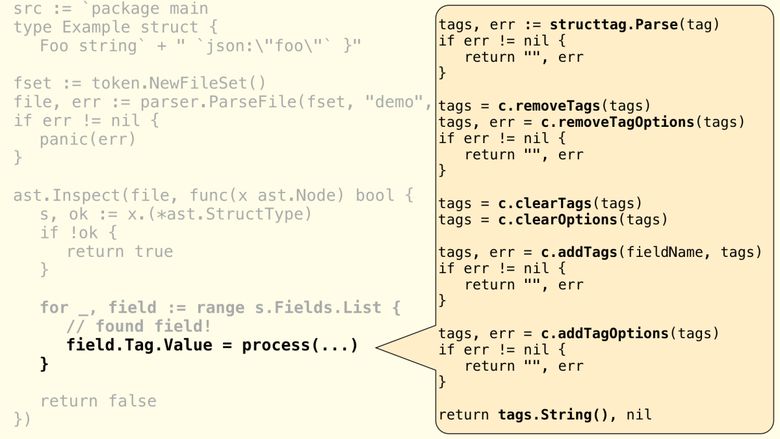
Пакет structtag используется для модифицирования каждого поля
Допустим, нужно расширить функции removeTags() внутри process(). Эта функция использует приведённую ниже конфигурацию для создания массива тегов (имён ключей), которые будут стёрты:
flagRemoveTags = flag.String("remove-tags", "", "Remove tags for the comma separated list of keys")
if *flagRemoveTags != "" {
cfg.remove = strings.Split(*flagRemoveTags, ",")
}Внутри removeTags() мы проверяем, использовал ли кто-нибудь --remove-tags. В данном случае удалить теги поможет метод tags.Delete() из structtag:
func (c *config) removeTags(tags *structtag.Tags) *structtag.Tags {
if c.remove == nil || len(c.remove) == 0 {
return tags
}
tags.Delete(c.remove...)
return tags
}Тот же подход применяется ко всем отдельным функциям внутри cfg.Process().
Мы переписали узел, поговорим о финальной части: выводе и форматировании результата.

В основной функции мы вызываем функцию cfg.format() с узлом, который был переписан на предыдущем шаге:
func main() {
// ... rewrite the node
out, err := cfg.format(rewrittenNode, errs)
if err != nil {
return err
}
fmt.Println(out)
}Мы выводим stdout. У этого решения есть ряд преимуществ. Во-первых, можно сделать пробный прогон — ничего не изменится, но зато мы сразу увидим результат. Во-вторых, stdout можно скомпоновать, чтобы переадресовать куда угодно, и даже использовать для перезаписи самой утилиты.
Давайте рассмотрим функцию format():
func (c *config) format(file ast.Node, rwErrs error) (string, error) {
switch c.output {
case "source":
// return Go source code
case "json":
// return a custom JSON output
default:
return "", fmt.Errorf("unknown output mode: %s", c.output)
}
}У нас два режима вывода данных.
Первый режим («исходный код») выводит ast.Node в Go-формате. Так делается по умолчанию, очень удобно, если вы используете утилиту из командной строки или хотите увидеть изменения в своём файле.
Второй режим («JSON») более продвинутый и специально придуман для других сред (особенно для редакторов). В этом режиме выходные данные кодируются на основе этой структуры:
type output struct {
Start int `json:"start"`
End int `json:"end"`
Lines []string `json:"lines"`
Errors []string `json:"errors,omitempty"`
}Обзор входных данных и соответствующих выходных (без ошибок):

Вернёмся к функции format(). Как уже говорилось, у нас есть два режима. Режим «исходный код» использует пакет go/format для форматирования AST обратно в корректный Go-код. Этот пакет применяют многие официальные утилиты, например gofmt. Вот как реализован режим «исходный код»:
var buf bytes.Buffer
err := format.Node(&buf, c.fset, file)
if err != nil {
return "", err
}
if c.write {
err = ioutil.WriteFile(c.file, buf.Bytes(), 0)
if err != nil {
return "", err
}
}
return buf.String(), nilПакет format принимает io.Writer и форматирует его. Поэтому мы создали промежуточный буфер (var buf bytes.Buffer), который может пригодиться для перезаписи файла, когда пользователь передаёт флаг -write. После форматирования возвращаем строковое представление буфера, содержащее отформатированный исходный код Go.
Режим JSON ещё интереснее. Поскольку мы возвращаем часть исходного кода, нам нужно вернуть именно так, как она выглядит. То есть со всеми комментариями. Но дело в том, что при использовании format.Node() для вывода одиночной структуры не получится вывести и комментарии, если они lossy.
Что такое lossy-комментарии? Посмотрите пример:
type example struct {
foo int
// this is a lossy comment
bar int
}Каждое поле относится к типу *ast.Field. В этой структуре есть поле *ast.Field.Comment, содержащее комментарий для определённого поля.
Но к какому полю относится комментарий в этом примере? К foo или bar?
Поскольку определить это невозможно, такие комментарии называются свободными. Если вывести эту структуру с помощью функции format.Node(), то вот что вы получите:
type example struct {
foo int
bar int
}Дело в том, что lossy-комментарии являются частью *ast.File и отделены от дерева. Они выводятся лишь тогда, когда мы выводим весь файл. Это можно обойти, если сначала вывести весь файл, а затем отрезать конкретные строки, которые нужно вернуть в виде JSON:
var buf bytes.Buffer
err := format.Node(&buf, c.fset, file)
if err != nil {
return "", err
}
var lines []string
scanner := bufio.NewScanner(bytes.NewBufferString(buf.String()))
for scanner.Scan() {
lines = append(lines, scanner.Text())
}
if c.start > len(lines) {
return "", errors.New("line selection is invalid")
}
out := &output{
Start: c.start,
End: c.end,
Lines: lines[c.start-1 : c.end], // cut out lines
}
o, err := json.MarshalIndent(out, "", " ")
if err != nil {
return "", err
}
return string(o), nilТаким образом можно вывести все комментарии.
Вот и всё!
Мы закончили создание нашей утилиты, а это просто пошаговая диаграмма, описывающая всё сделанное:
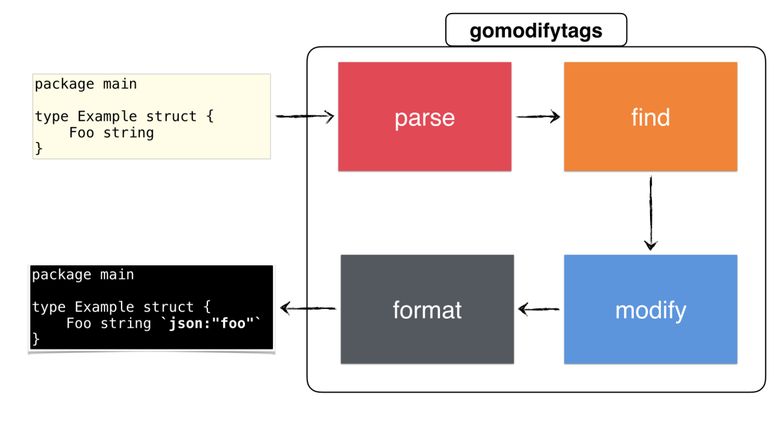
Кратко о gomodifytags
Напомню:
- Мы посредством CLI-флагов извлекли конфигурацию.
- Начали парсить файл с помощью пакета
go/parser, чтобы извлечьast.Node. - Потом искали (проходя вниз по дереву) начальную и конечную позицию для соответствующей структуры, чтобы узнать, какие поля нужно модифицировать.
- Найдя позиции, снова пошли вниз по
ast.Nodeи переписали каждое поле между начальной и конечной позициями (с помощью пакета structtag). - Затем отформатировали переписанный узел в виде либо корректного исходного кода Go, либо JSON для редакторов.
Сегодня gomodifytags облегчает жизнь тысячам разработчиков, он успешно используется в нескольких редакторах и плагинах:
- vim-go
- atom
- vscode
- acme
Исходный код
Также я подробнее рассказал о своём пакете на конференции Gophercon 2017
