[Перевод] Повторная обработка данных на платформе управления цифровыми ресурсами в Netflix

Netflix ушел, а технологии остались. Поэтому мы решили перевести оригинальную статью за авторством Meenakshi Jindal о том, как стриминговый сервис обрабатывает данные с помощью Apache Kafka.
Введение
Netflix создал платформу управления цифровыми медиаресурсами (AMP) как централизованный сервис для организации, хранения и обнаружения цифровых медиаресурсов, созданных в процессе производства фильма. Студии используют этот сервис для хранения своих мультимедийных ресурсов, которые затем проходят через цикл валидации, версионирования, контроля доступа, совместного использования и запуска настроенных рабочих процессов, таких как инспекция, создание прокси и т. д.
Платформа эволюционировала от поддержки студийных приложений до дата-сайенс, машинного обучения для обнаружения метаданных, а также создания различных фактов данных.
В процессе этой эволюции довольно часто появляются запросы на обновление существующих метаданных цифровых ресурсов или добавление новых метаданных для новых функций. Паттерн растет со временем; особенно это чувствуется, когда необходимо получить доступ к метаданным существующих ресурсов и обновить их. Поэтому Netflix разработал конвейер данных, который можно использовать для извлечения метаданных существующих ресурсов и последующей обработки для каждого нового варианта использования.
Этот фреймворк позволил оперативно развивать и адаптировать приложение к любым непредсказуемым (но неизбежным) изменениям, запрашиваемым клиентами платформы. Операции с производственными ресурсами выполняются параллельно с повторной обработкой старых данных. Никаких простоев.
Некоторые поддерживаемые варианты использования в повторной обработке данных приведены ниже.
Варианты использования
Real Time API (поддерживаемые базой данных Cassandra) для доступа к метаданным ресурсов не подходят для аналитики в машинном обучении и дата-сайенс. Конвейер данных создается для сохранения данных ресурсов в Apache Iceberg параллельно с Cassandra и Elasticsearch, однако для построения фактов данных в Iceberg-е нужен полный набор данных, а не только последняя версия. Таким образом, данные о существующих ресурсах считываются и копируются в таблицы Iceberg без остановки производства.
Схема управления версиями разработана для поддержки основных и младших версий обновлений метаданных и взаимодействий ресурсов. Поддержка этой функции потребовала значительного обновления дизайна таблиц данных (включая новые таблицы и обновление существующих столбцов). Уже имеющиеся данные были обновлены для обеспечения обратной совместимости, причем подобное обновление не повлияло на существующий производственный трафик.
Обновление версии Elasticsearch включает в себя обратно несовместимые изменения, поэтому все данные о цифровых ресурсах считываются из основного источника правды и переиндексируются в новых индексах.
Стратегия шардирования данных в Elasticsearch была обновлена, чтобы обеспечить низкую задержку поиска (это описано в блоге Netflix).
Для поддержки различных наборов запросов велась разработка инвертированных индексов Cassandra.
Для медиаресурсов настраиваются автоматизированные рабочие процессы (например, инспекция). Эти процессы необходимо запускать и для уже имеющихся цифровых ресурсов.
Схема ресурсов была усовершенствована, что потребовало повторной переиндексации всех данных в Elasticsearch для поддержки запросов поиска/статистики по новым областям.
Массовое удаление ресурсов, связанных с названиями, для которых истекла лицензия.
Обновление или добавление метаданных к существующим ресурсам из-за определенных регрессий в клиентском приложении/внутри самого сервиса.
Поток конвейера повторной обработки данных
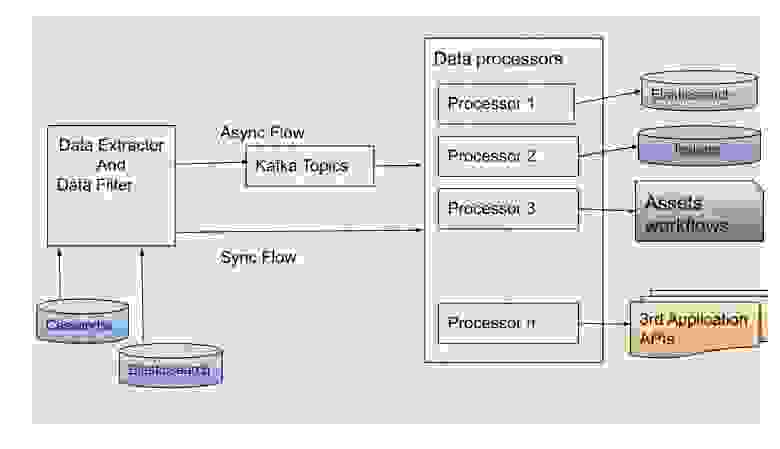 Рис. 1. Поток конвейера повторной обработки данных
Рис. 1. Поток конвейера повторной обработки данных
Технология извлечения данных
Cassandra — это основное хранилище данных сервиса управления цифровыми ресурсами. С хранилищем SQL было легко получить доступ к существующим данным с пагинацией независимо от размера. Но в хранилищах данных No-SQL, как Cassandra, концепции пагинации нет.
В новых версиях Cassandra реализованы некоторые возможности для пагинации (такие как PagingState и COPY), но у каждой имеются свои ограничения. Чтобы избежать ненужной привязки к подобным ограничениям, таблицы были разработаны так, что данные можно получать самым эффективным способом уже с пагинацией.
Данные в основном считываются либо по типам схемы ресурсов, либо по временным интервалам в зависимости от даты создания ресурсов. Шардирование, целиком основанное на типах, могло создать слишком широкие строки (учитывая, что у типов наподобие VIDEO может быть гораздо больше ресурсов по сравнению, например, с TEXT). Поэтому для шардирования на узлах Cassandra используются и типы ресурсов, и временные интервалы, основанные на дате создания. Ниже приведен пример определения первичных ключей и ключей кластеризации таблиц:
 Рисунок 2. Структура таблицы Cassandra
Рисунок 2. Структура таблицы Cassandra
В зависимости от типа ресурса происходит извлечение областей, основанное на дате создания. Затем уже из этих областей извлекается список ID ресурсов с использованием временных интервалов и типов. ID ресурса определен как тип данных Cassandra Timeuuid. Мы используем Timeuuid, потому их можно отсортировать и использовать для пагинации.
В качестве первичного ключа таблицы для поддержки пагинации может быть использован любой сортируемый ID. Например, размер страницы равен N. Первые N строк извлекаются из таблицы. Следующая страница извлекается из таблицы с ограничением в N, ID ресурса < последнего извлеченного ID.
 Рис. 3. Запрос на извлечение данных в Cassandra
Рис. 3. Запрос на извлечение данных в Cassandra
Уровни данных могут быть разработаны на основе различных бизнес-объектов, которые используются для чтения этих данных из областей. При этом первичный ID таблицы должен быть сортируемым для нужд пагинации.
Иногда приходится повторно обрабатывать определенный набор ресурсов только на основе какого-то поля в Payload. Для чтения ресурсов по времени или типу можно применить Cassandra, а затем дополнительно отфильтровывать ресурсы, которые удовлетворяют пользовательским критериям. Вместо этого Netflix использует Elasticsearch для поиска самых высокопроизводительных ресурсов.
После извлечения ID ресурса одним из способов для каждого ID создается событие, которое обрабатывается синхронно или асинхронно в зависимости от варианта использования. Для асинхронной обработки события направляются в топики Apache Kafka.
Процессор данных
Процессор данных предназначен для обработки данных в зависимости от варианта использования. Определяются различные процессоры, которые могут быть расширены в зависимости от меняющихся требований. Обработка может происходить синхронно или асинхронно.
Синхронный поток. В зависимости от типа события может быть вызван конкретный процессор непосредственно для отфильтрованных данных. Как правило, этот поток используется для небольших наборов данных.
Асинхронный поток. Процессор данных использует события, отправленные экстрактором данных. Топик Apache Kafka настроен как брокер сообщений. В зависимости от варианта использования необходимо контролировать количество событий, обрабатываемых за единицу времени. Например, чтобы переиндексировать все данные в Elasticsearch из-за смены шаблона, предпочтительно переиндексировать данные с определенным RPS, чтобы избежать любого влияния на текущий производственный процесс. Преимущество асинхронности заключается в управлении потоком обработки событий при помощи подсчета консьюмеров Кафки или контролирования размера пула потоков для каждого консьюмера. Плюс, процесс обработки событий может быть остановлен в любой момент путем отключения консьюмеров в случае, если это каким-либо образом мешает производственному потоку. Для быстрой обработки событий Netflix использует разнообразные настройки консьюмеров Apache Kafka и Java Executor Thread Pool. Записи из топиков Кафки обрабатываются асинхронно в несколько потоков. В зависимости от типа процессора события могут обрабатываться в большом объеме при условии правильных настроек размера Consumer Poll и пула потоков.
Каждый из упомянутых выше вариантов использования выглядит по-разному, но все они используют идентичный процесс повторной обработки для извлечения старых данных. Многие приложения проектируют конвейеры для обработки новых данных;, но настройка такого конвейера обработки для существующих данных поддерживает работу с новыми функциями через внедрение нового процессора. Этот конвейер можно запустить в любое время при помощи фильтров данных и типа процессора данных (который определяет фактическое необходимое действие).
Обработка ошибок
Ошибки — часть разработки ПО. Но в данном случае разработка должна вестись наиболее аккуратно, поскольку повторная обработка больших объемов данных будет выполняться параллельно с производственным трафиком. В Netflix кластеры экстрактора и процессора данных отделены от основного производственного кластера, чтобы избежать любого влияния на текущие операции с ресурсами в производственной среде. Такие кластеры могут иметь разные конфигурации пулов потоков для чтения и записи из базы данных, уровни ведения журнала и конфигурацию взаимодействия с внешними зависимостями.
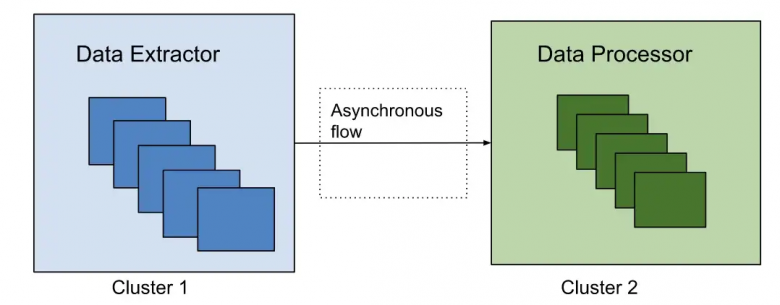 Рисунок 4: Обработка кластеров
Рисунок 4: Обработка кластеров
Процессоры данных разработаны специально, чтобы продолжать обработку событий даже в случае некоторых ошибок. Например, неожиданный Payload в старых данных.
В случае ошибки при обработке события консьюмеры Apache Kafka распознают событие как обработанное и отправляют его в другую очередь после нескольких повторных попыток. В противном случае консьюмеры продолжат попытки снова обработать то же сообщение и заблокируют обработку других событий в топике.
В Netflix производится повторная обработка данных в очереди недоставленных сообщений после устранения основной причины возникшей проблемы. Специалисты собирают метрики отказов, чтобы позже проверить и исправить, настраивают оповещения и постоянно отслеживают производственный трафик, на который может повлиять массовая повторная обработка старых данных. Если подобное влияние будет замечено, должна существовать возможность замедлить или остановить повторную обработку в любой момент. С разными кластерами процессоров данных сделать это легко: достаточно уменьшить количество инстансов, обрабатывающих события (или же сократить кластер до 0 инстансов в случае, если требуется полный стоп).
Лучшие практики
В зависимости от размера данных и варианта использования обработка может повлиять на производственный поток. Поэтому необходимо определить оптимальные пределы обработки событий и соответствующим образом настроить потоки консьюмеров.
Если процессор данных вызывает внешние службы, стоит проверить пределы обработки этих служб, поскольку массовая обработка данных может создать непредвиденный лишний трафик и, тем самым, проблемы с масштабируемостью/доступностью.
Бэкэнд-обработка может происходить от нескольких секунд до нескольких минут. Следует обновить параметры Tiemout консьюмера Apache Kafka соответствующим образом, иначе другой консьюмер может попытаться снова обработать то же событие после истечения времени ожидания обработки.
Прежде чем запускать обработку полного набора данных, сначала имеет смысл протестировать модуль процессора данных на небольшом объеме данных.
Важно собирать метрики успешной обработки и ошибок, потому что иногда старые данные могут иметь некие пограничные случаи, не обработанные процессорами должным образом. Для сбора и мониторинга таких показателей Netflix использует платформу Atlas.
Если хочется подробнее изучить Apache Kafka
Курс от Слёрма Apache Kafka База состоит из 29 онлайн-уроков с доступом на 2 года и практических заданий на боевых стендах. Можно учиться самостоятельно по видеокурсу, можно присоединиться к потоку с 16 января. Но только в потоке есть АМА-сессии, сертификация и закрытый чат со спикером.
Посмотреть программу и записаться: https://slurm.club/3XvVA4W
До 19 января можно пройтинаш мини-тестиз 9 вопросовпо основам Kafka и получить скидку 30% на обучение в потоке.
