[Перевод] Почему Discord переходит с Go на Rust

Rust становится первоклассным языком в самых разных областях. Мы в Discord успешно используем его и на серверной, и на клиентской стороне. Например, на стороне клиента в конвейере кодирования видео для Go Live, а на стороне сервера для функций Elixir NIF (Native Implemented Functions).
Недавно мы резко улучшили производительность одной службы, переписав её с Go на Rust. В этой статье объясним, почему для нас имело смысл переписать службу, как мы это сделали и насколько повысилась производительность.
Наша компания построена вокруг одного продукта, поэтому начнём с некоторого контекста, что именно мы перевели с Go на Rust. Это служба чтения состояний (Read States). Её единственная задача — отслеживать, какие каналы и сообщения вы прочитали. Доступ к Read States осуществляется при каждом подключении к Discord, при каждой отправке сообщения и при каждом чтении сообщения. Короче говоря, состояния читаются постоянно и находятся на «горячем пути». Мы хотим убедиться, что Discord всегда быстро работает, поэтому чтение состояний должно происходить быстро.
Реализация службы на Go не соответствовала всем требованиям. Большую часть времени она работала быстро, но каждые несколько минут начинались сильные задержки, заметные для пользователей. После изучения ситуации мы определили, что задержки объясняются ключевыми особенностями Go: его моделью памяти и сборщиком мусора (GC).
Чтобы объяснить, почему Go не соответствует нашим целевым показателям производительности, сначала нужно обсудить структуры данных, масштаб, шаблоны доступа и архитектуру сервиса.
Для хранения информации о состояниях мы используем структуру данных, которая так и называется: Read State. В Discord их миллиарды: по одному состоянию для каждого пользователя на каждый канал. У каждого состояния несколько счётчиков, которые необходимо атомарно обновлять и часто сбрасывать в ноль. Например, один из счётчиков — это количество @mention в канале.
Для быстрого обновления атомарного счетчика на каждом сервере Read States имеется кэш «последних состояний» (Least Recently Used, LRU). В каждом кэше миллионы пользователей и десятки миллионов состояний. Кэш обновляется сотни тысяч раз в секунду.
Для сохранности кэш синхронизируется с кластером базы данных Cassandra. При вытеснении ключа из кэша мы заносим состояния этого пользователя в БД. В будущем мы планируем обновлять базу в течение 30 секунд при каждом обновлении состояния. Это десятки тысяч записей в БД каждую секунду.
На графике внизу — время отклика и нагрузка на CPU в пиковый промежуток времени для службы Go1. Видно, что задержки и всплески нагрузки на CPU происходят примерно каждые две минуты.
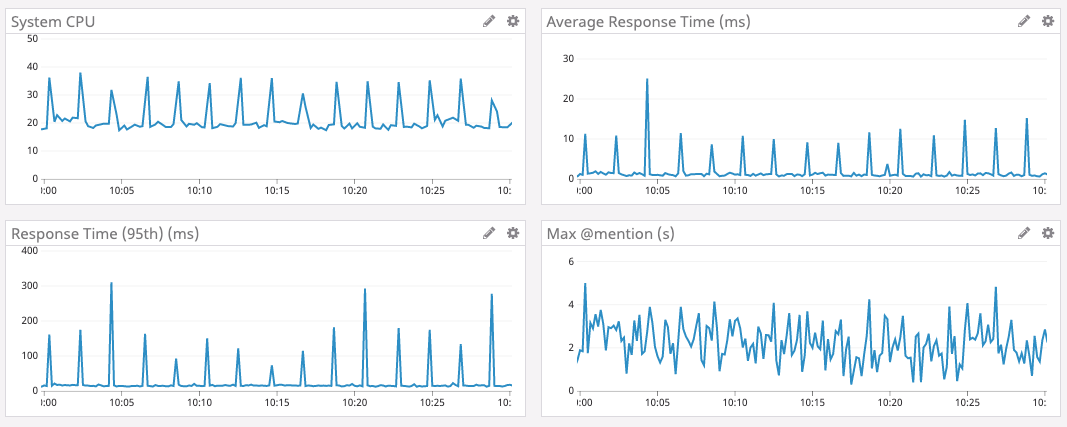
В Go память не освобождается сразу при вытеснении ключа из кэша. Вместо этого периодически запускается сборщик мусора, который ищет неиспользуемые участки памяти. Это большая работа, которая может замедлить выполнение программы.
Очень похоже, что периодические подтормаживания нашей службы связаны со сборкой мусора. Но мы написали очень эффективный код Go с минимальным количеством выделений памяти. Там не должно оставаться много мусора. В чём же дело?
Покопавшись в исходном коде Go, мы узнали, что Go принудительно запускает сборку мусора минимум каждые две минуты. Независимо от размера кучи, если GC не запускался две минуты, Go принудительно его запустит.
Мы решили, что если запускать GC чаще, то можно избежать этих пиков с большими задержками, поэтому мы поставили точку вывода (endpoint) в службе, чтобы на лету изменять значение GC Percent. К сожалению, настройка GC Percent ни на что не повлияла. Как такое могло случиться? Оказывается, GC не хотел запускаться чаще, потому что мы недостаточно часто выделяли память.
Мы стали копать дальше. Оказалось, что настолько большие задержки возникают не из-за огромного количества высвобождаемой памяти, а потому что сборщик мусора сканирует весь кэш LRU, чтобы проверить всю память. Тогда мы решили, что если уменьшить кэш LRU, то объём сканирования уменьшится. Поэтому мы добавили в службу ещё один параметр, чтобы изменять размер кэша LRU, и изменили архитектуру, на каждом сервере разбив LRU на много отдельных кэшей.
Так и вышло. С меньшими кэшами пиковые задержки уменьшились.
К сожалению, компромисс с уменьшением кэша LRU поднял 99-й процентиль (то есть увеличилось среднее значение для выборки из 99% задержек, исключая пиковые). Это связано с тем, что уменьшение кэша уменьшает вероятность, что Read State пользователя будет в кэше. Если его здесь нет, то мы должны обратиться к БД.
Проведя большой объём нагрузочного тестирования на разных размерах кэша, мы вроде нашли приемлемую настройку. Пусть и не идеальное, но это было удовлетворительное решение, поэтому мы надолго оставили службу работать так.
В то же время мы очень успешно внедряли Rust в других системах Discord, и в итоге приняли коллективное решение писать фреймворки и библиотеки для новых сервисов только на Rust. А эта служба казалась отличным кандидатом для переноса на Rust: она небольшая и автономная, а мы надеялись, что Rust исправит эти всплески с задержками и в конечном сделает сервис приятнее для пользователей2.
Rust невероятно быстр и эффективно работает с памятью: в отсутствие среды выполнения и сборщика мусора он подходит для высокопроизводительных служб, встроенных приложений и легко интегрируется с другими языками.3
У Rust нет сборщика мусора, поэтому мы решили, что не будет и этих задержек, как у Go.
В управлении памятью он использует довольно уникальный подход с идеей «владения» памятью. Если вкратце, Rust отслеживает, кто имеет право читать из памяти и записывать туда. Он знает, когда программа использует память, и немедленно освобождает её, как только память больше не нужна. Rust принудительно применяет правила памяти во время компиляции, что практически исключает возможность ошибок памяти во время выполнения.4 Вам не нужно вручную отслеживать память. Об этом позаботится компилятор.
Таким образом, в версии Rust, когда состояние Read State исключается из кэша LRU, память освобождается немедленно. Эта память не сидит и не ждёт сборщика мусора. Rust знает, что она больше не используется, и немедленно освобождает её. Нет никакого процесса в рантайме для сканирования, какую память освободить.
Но была одна проблема с экосистемой Rust. На момент внедрения нашей службы в стабильной ветке Rust не было приличный асинхронных функций. Для сетевой службы асинхронное программирование является обязательным требованием. Сообщество разработало несколько библиотек, но с нетривиальным подключением и очень глупыми сообщениями об ошибках.
К счастью, команда Rust усердно работала над упрощением асинхронного программирования, и оно уже было доступно на нестабильном канале (Nightly).
Discord никогда не боялся осваивать перспективные новые технологии. Например, мы были одними из первых пользователей Elixir, React, React Native и Scylla. Если какая-то технология выглядит перспективной и даёт нам преимущество, то мы готовы столкнуться с неминуемой трудностью внедрения и нестабильностью передовых инструментов. Это одна из причин, как мы настолько быстро достигли аудитории в 250 миллионов пользователей c менее чем 50-ю программистами в штате.
Внедрение новых асинхронных функций с нестабильного канала Rust — ещё один пример нашей готовности принять новую, многообещающую технологию. Инженерная команда решила внедрить нужные функции, не дожидаясь их поддержки в стабильной версии. Вместе с другими представителями сообщества мы преодолели все возникшие проблемы, и теперь асинхронный Rust поддерживается в стабильной ветке. Наша ставка окупилась.
Просто переписать код было несложно. Мы начали с грубой трансляции, потом сократили его в тех местах, где это имело смысл. Например, у Rust отличная система типов с обширной поддержкой дженериков (для работы с данными любого типа), поэтому мы спокойно выбросили код Go, который компенсировал отсутствие дженериков. Кроме того, модель памяти Rust учитывает безопасность памяти в разных потоках, так что мы выбросили защитные горутины.
Нагрузочное тестирование сразу показало отличный результат. Быстродействие службы на Rust оказалось таким же высоким, как у версии Go, но без этих всплесков повышения задержки!
Что характерно, мы практически не оптимизировали версию Rust. Но даже с самой простой оптимизацией Rust смог превзойти тщательно настроенную версию Go. Это красноречивое доказательство, насколько легко писать эффективные программы на Rust по сравнению с глубоким погружением в Go.
Но наc не удовлетворил простой статус-кво по производительности. После небольшого профилирования и оптимизации мы превзошли Go по всем показателям. Задержка, CPU и память — всё стало лучше в версии Rust.
Оптимизации производительности Rust включали в себя:
- Переход на BTreeMap вместо HashMap в кэше LRU для оптимизации использования памяти.
- Замену первоначальной библиотеки метрик на версию с поддержкой современного параллелизма Rust.
- Уменьшение количества копий в памяти.
Удовлетворённые, мы решили развернуть сервис.
Запуск прошёл довольно гладко, поскольку мы проводили нагрузочные испытания. Мы подключили службу к одному тестовому узлу, обнаружили и исправили несколько пограничных случаев. Вскоре после этого накатили новую версию на весь серверный парк.
Результаты показаны ниже.
Фиолетовый график — Go, синий — Rust.
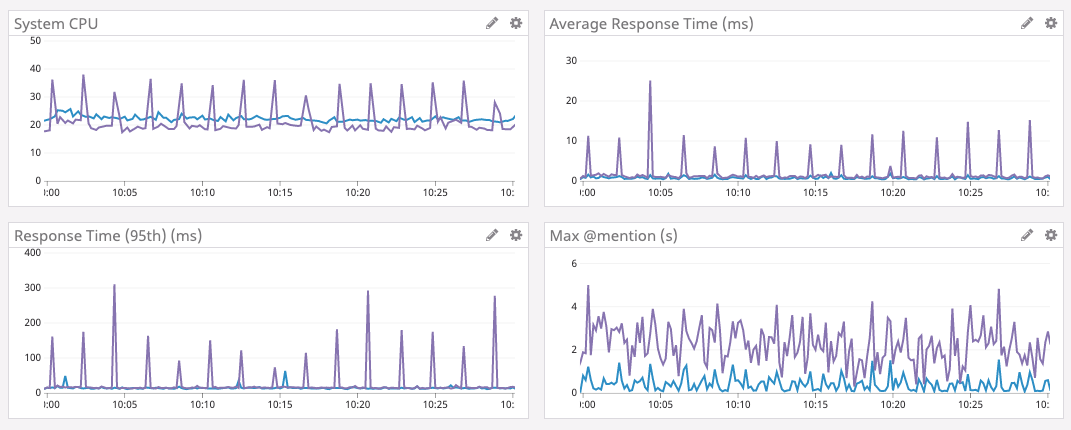
Когда служба успешно отработала нескольких дней, мы решили снова увеличить кэша LRU. Как упоминалось выше, в версии Go это нельзя было сделать, потому что возрастало время на сборку мусора. Поскольку мы больше не занимаемся сборкой мусора, можно увеличить кэш в расчёте на ещё больший рост производительности. Итак, мы нарастили память на серверах, оптимизировали структуру данных на меньшее использование памяти (для удовольствия) и увеличили объём кэша до 8 миллионов состояний Read State.
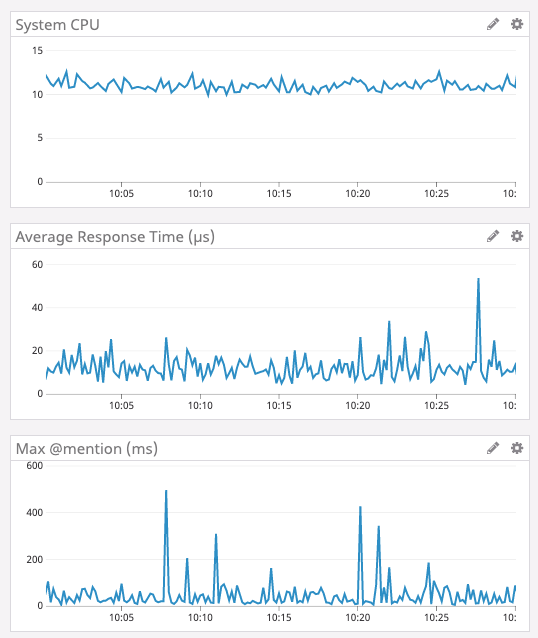
Приведённые ниже результаты говорят сами за себя. Обратите внимание, что среднее время теперь измеряется в микросекундах, а максимальная задержка @mention измеряется в миллисекундах.
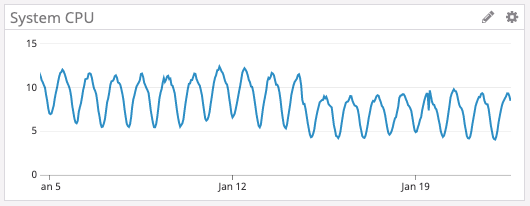
Наконец, у Rust замечательная экосистема, которая быстро развивается. Например, недавно вышла новая версия асинхронной среды выполнения, которую мы используем, — Tokio 0.2. Мы обновились, и без каких-то усилий с нашей стороны автоматически снизили нагрузку на CPU. На графике ниже можете видеть, как нагрузка снизилась примерно с 16-го января.
На данный момент Discord использует Rust во многих частях программного стека: для GameSDK, захвата и кодирования видео в Go Live, в Elixir NIF, нескольких бэкенд-сервисах и много где ещё.
При запуске нового проекта или программного компонента мы обязательно рассматриваем возможность использования Rust. Конечно, только там, где это имеет смысл.
Кроме производительности, Rust даёт разработчикам много других преимуществ. Например, его типобезопасность и проверка заимствования переменных (borrow checker) сильно упрощают рефакторинг по мере изменения требований к продукту или внедрения новых функций языка. Экосистема и инструментарий превосходны и быстро развиваются.
Забавный факт: команда Rust для координации тоже использует Discord. Есть даже очень полезный сервер сообщества Rust, где и мы иногда общаемся в чате.
Сноски
- Графики взяты из Go версии 1.9.2. Мы пробовали версии 1.8, 1.9 и 1.10 без каких-либо улучшений. Первоначальная миграция с Go на Rust была завершена в мае 2019 года. [вернуться]
- Для ясности, мы не советуем переписывать всё на Rust без причины. [вернуться]
- Цитата с официального сайта. [вернуться]
- Конечно, пока вы не используете unsafe. [вернуться]
