[Перевод] Парсинг JSON — это минное поле

JSON — это стандарт де-факто, когда заходит речь о (де)сериализации, обмене данными в сети и мобильной разработке. Но насколько хорошо вы знакомы с JSON? Все мы читаем спецификации и пишем тесты, испытываем популярные JSON-библиотеки для своих нужд. Я покажу вам, что JSON — это идеализированный формат, а не идеальный, каким его многие считают. Я не нашёл и двух библиотек, ведущих себя одинаково. Более того, я обнаружил, что крайние случаи и зловредная полезная нагрузка могут привести к багам, падениями и DoS, в основном потому, что JSON-библиотеки основаны на спецификациях, которые со временем развиваются, что оставляет многие вещи плохо или вообще не задокументированными.
2. Тестирование парсинга
2.1. Структура
2.2. Числа (Numbers)
2.3. Массивы
2.4. Объекты
2.5. Строки
2.6. Двойственные значения RFC 7159
3. Архитектура тестирования
4. Результаты тестирования
4.1. Полные результаты
4.2. C-парсеры
4.3. Objective-C-парсеры
4.4. Apple (NS)JSONSerialization
4.5. Freddy (Swift)
4.6. Bash JSON.sh
4.7. Другие парсеры
4.8. JSON Checker
4.9. Регулярные выражения
5. Контент парсинга
6. STJSON
7. Заключение
8. Приложение
1. Спецификации JSON
JSON — стандарт де-факто сериализации при передаче данных по HTTP, лингва франка для обмена данными между гетерогенными приложениями как в веб-, так и в мобильной разработке.
В 2001 году Дуглас Крокфорд разработал такую короткую и простую спецификацию JSON, что это породило возникновение визитных карточек, на обратной стороне которых печатали полную грамматику JSON.

JSON используют практически все пользователи интернета и программисты, но лишь немногие действительно пришли к согласию относительно того, как должен работать JSON. Краткость грамматики оставляет многие аспекты неопределёнными. К тому же существует несколько спецификаций и их мутных интерпретаций.
Крокфорд решил не версионировать JSON:
Вероятно, моим самым смелым дизайн-решением стал отказ от присвоения JSON номерных версий, поэтому отсутствует механизм внесения изменений. Мы застряли с JSON: что бы ни представляла собой его текущая форма, он только такой.
Кроме того, JSON определяется как минимум в шести разных документах:
- 2002 — json.org и визитки.
- 2006 — IETF RFC 4627, устанавливает application/json MIME тип среды.
- 2011 — ECMAScript 262, раздел 15.12.
- 2013 — ECMA 404. Как сообщил Тим Брей (редактор RFC 7159), ECMA поторопилась с релизом, потому что:
Кто-то сказал рабочей группе ECMA, что IETF спятила и собралась переписать JSON без оглядки на совместимость и поломку всего интернета, и с этой ужасной ситуацией нужно срочно что-то делать. <...> Это не имеет никакого отношения к жалобам, которые повлияли на ревизию со стороны IETF.
- 2014 — IETF RFC 7158. Создаёт спецификацию «Standard Tracks» вместо «Informational»; позволяет использовать скаляры (ничего, кроме массивов и объектов) вроде 123 и true на root-уровне, как и ECMA; предостерегает от применения неудачных решений вроде повторяющихся ключей или сломанных Unicode-строк, хотя и не запрещает их явно.
- 2014 — IETF RFC 7159. Выпущен для исправления опечатки в RFC 7158, который был датирован мартом 2013-го вместо марта 2014-го.
Несмотря на ясность, RFC 7159 содержит несколько допущений и оставляет немало плохо освещённых моментов.
В частности, в RFC 7159 упоминается, что целью разработки JSON было создать «подмножество JavaScript», но на самом деле это не так. Например, JSON позволяет использовать неэкранированные (unescaped) символы конца строки из Unicode U+2028 LINE SEPARATOR и U+2029 PARAGRAPH SEPARATOR. Но спецификация JavaScript гласит, что строковые значения не могут содержать символы конца строки (ECMA-262 — 7.8.4 String Literals), и вообще к этим символам относятся U+2028 и U+2029 (7.3 Line Terminators). Тот факт, что эти два символа могут использоваться в JSON-строках без экранирования, а в JS они вообще не подразумеваются, говорит о том, что JSON не является подмножеством JavaScript, несмотря на обозначенные цели разработки.
Также RFC 7159 не проясняет, как JSON-парсер должен обращаться с предельными числовыми значениями (extreme number values), искажёнными Unicode-строками, одинаковыми объектами или глубиной рекурсии. Одни тупиковые ситуации явно оставлены без реализаций, а другие страдают от противоречивых высказываний.
Чтобы проиллюстрировать неточность RFC 7159, я написал сборник тестовых JSON-файлов и задокументировал, как конкретные JSON-парсеры их обрабатывают. Ниже вы увидите, что не всегда легко решить, стоит ли парсить тот или иной тестовый файл. В своих изысканиях я обнаружил, что все парсеры ведут себя по-разному, и это может приводить к серьёзным проблемам с совместимостью.
2. Тестирование парсингаДалее я объясню, как создать тестовые файлы для проверки поведения парсеров, расскажу о некоторых интересных тестах и обосную, должны ли парсеры, соответствующие критериям RFC 7159, принимать или отвергать файлы — либо же решать самостоятельно.
Имена файлов начинаются с буквы, которая говорит об ожидаемом результате:
y(yes) — успешный парсинг;n(no) — ошибка парсинга;i(implementation) — зависит от реализации.
Также из файлов будет понятно, какой именно компонент парсера подвергался тестированию.
Например, n_string_unescaped_tab.json содержит ["09"] — это массив со строкой, включающей в себя символ TAB 0x09, который ДОЛЖЕН быть экранирован (u-escaped) согласно спецификациям JSON. Файл тестирует парсинг строк, поэтому в названии содержится string, а не structure, array или object. Согласно RFC 7159 это невалидное строковое значение, поэтому в имени файла присутствует n.
Обратите внимание, что несколько парсеров не допускают скаляров на верхнем уровне ("test"), поэтому я встроил строки в массивы (["test"]).
Больше 300 тестовых файлов вы можете найти в репозитории JSONTestSuite.
В большинстве своём файлы я делал вручную по мере чтения спецификаций, стараясь уделить внимание крайним ситуациям и неоднозначным моментам. Я также пытался использовать наработки из чужих тестовых наборов, найденных в интернете (в основном json-test-suite и JSON Checker), но обнаружил, что большинство из них покрывают только базовые ситуации.
Наконец, я генерировал JSON-файлы с помощью фаззингового ПО American Fuzzy Lop. Затем убрал избыточные тесты, приводящие к одному результату, а потом сократил количество оставшихся, чтобы получилось наименьшее количество символов, дающих результаты (см. раздел 3).
2.1. Структура
Скаляры — очевидно, что необходимо парсить скаляры наподобие 123 или «asd». На практике многие популярные парсеры всё ещё реализуют RFC 4627 и не станут парсить одиночные значения. Таким образом, есть основные тесты, например:
y_structure_lonely_string.json "asd"
Замыкающие запятые (trailing commas), например
[123,] или {"a":1,}, не являются частью грамматики, поэтому такие файлы не должны проходить тесты, верно? Но дело в том, что RFC 7159 позволяет парсерам поддерживать «расширения» (раздел 9), хотя пояснений насчёт них не даётся. На практике замыкающие запятые — распространённое расширение. Поскольку это не часть JSON-грамматики, парсеры не обязаны поддерживать их, так что имена файлов начинаются с n.n_object_trailing_comma.json {"id":0,}
n_object_several_trailing_commas.json {"id":0,,,,,}
Комментарии тоже не часть грамматики. Крокфорд убрал их из ранних спецификаций. Но это ещё одно распространённое расширение. Некоторые парсеры допускают использование комментариев, замыкающих
[1]//xxx или даже встроенных [1,/*xxx*/2].y_string_comments.json ["a/*b*/c/*d//e"]
n_object_trailing_comment.json {"a":"b"}/**/
n_structure_object_with_comment.json {"a":/*comment*/"b"}
Незамкнутые структуры. Тесты покрывают все ситуации, когда имеются открытые и не закрытые (или наоборот) структуры, например
[ или [1,{,3]. Очевидно, что это ошибка и тесты не должны быть пройдены.n_structure_object_unclosed_no_value.json {"":
n_structure_object_followed_by_closing_object.json {}}
Вложенные структуры. Структуры иногда содержат другие структуры, массивы — другие массивы. Первый элемент может быть массивом, чей первый элемент — тоже массив, и так далее, словно матрёшка
[[[[[]]]]]. RFC 7159 позволяет парсерам устанавливать ограничение на максимальную глубину вложенности (раздел 9).Несколько парсеров не ограничивают глубину и в какой-то момент просто падают. Например, Xcode упадёт, если открыть файл .json, содержащий тысячу символов [. Вероятно, потому, что в выделителе синтаксических элементов JSON не реализовано ограничение глубины.
$ python -c "print('['*100000)" > ~/x.json
$ ./Xcode ~/x.json
Segmentation fault: 11
Пробелы. Грамматика RFC 7159 позволяет использовать в их качестве
0x20 (пробел), 0x09 (табуляцию), 0x0A (перевод строки) и 0x0D (возврат каретки). Пробелы допускаются до и после «структурных символов» (structural characters) []{}:,. Так что 20[090A]0D пройдёт тесты. И напротив, файл не пройдёт тесты, если мы включим в него все виды пробелов, которые не разрешены явно, например форму ввода 0x0C или [E281A0] — UTF-8 обозначение для соединителя слов U+2060 WORD JOINER.n_structure_whitespace_formfeed.json [0C]
n_structure_whitespace_U+2060_word_joiner.json [E281A0]
n_structure_no_data.json
2.2. Числа
NaN и Infinity. Строки, описывающие специальные числа, наподобие
NaN или Infinity, не являются частью грамматики JSON. Но некоторые парсеры их принимают, расценивая как «расширения» (раздел 9). В тестовых файлах также проверяются отрицательные формы -NaN и -Infinity.n_number_NaN.json [NaN]
n_number_minus_infinity.json [-Infinity]
Шестнадцатеричные числа — RFC 7159 не допускает их использования. Тесты содержат числа вроде
0xFF, и такие файлы не должны проходить парсинг.n_number_hex_2_digits.json [0x42]
Диапазон и точность —, а что насчёт чисел из огромного количества цифр? Согласно RFC 7159, «JSON-парсер ДОЛЖЕН принимать все виды текстов, соответствующих грамматике JSON» (глава 9). Но в том же параграфе говорится: «Реализация может ограничивать диапазон и точность чисел». Так что мне непонятно, могут ли парсеры выдавать ошибку, сталкиваясь со значениями наподобие
1e9999 или 0.0000000000000000000000000000001.y_number_very_big_negative_int.json [-237462374673276894279832(...)
Экспоненциальные представления — их парсинг может быть на удивление трудной задачей (см. главу с результатами). Есть и валидные (
[0E0], [0e+1]), и невалидные варианты ([1.0e+], [0E] и [1eE2]).n_number_0_capital_E+.json [0E+]
n_number_.2e-3.json [.2e-3]
y_number_double_huge_neg_exp.json [123.456e-789]
2.3. Массивы
Большинство крайних ситуаций, связанных с массивами, — это проблемы с открыванием/закрыванием и ограничением вложенности. Они рассмотрены в разделе 2.1 (Структуры). Тесты пройдут
[[] и [[]]], а не пройдут ] или [[]]].n_array_comma_and_number.json [,1]
n_array_colon_instead_of_comma.json ["": 1]
n_array_unclosed_with_new_lines.json [1,0A10A,1
2.4. Объекты
Повторяющиеся ключи. В разделе 4 RFC 7159 говорится: «В пределах объекта должны быть уникальные имена». Это не предотвращает парсинг объектов, в которых один ключ появляется несколько раз
{"a":1,"a":2}, но позволяет парсерам самим решать, что делать в таких случаях. В разделе 4 даже упоминается, что »[некоторые] реализации сообщают об ошибке или сбое во время парсинга объекта», без уточнения, соответствует ли сбой парсинга положениям RFC, в особенности этому: «JSON-парсер ДОЛЖЕН принимать все виды текстов, соответствующих грамматике JSON». Варианты таких особых случаев включают в себя одинаковый ключ: одно и то же значение {"a":1,"a":1}, а также ключи или значения, чья одинаковость зависит от способа сравнения строк. Например, ключи могут быть разными в двоичном выражении, но эквивалентными в соответствии с нормализацией Inicode NFC: {"C3A9:"NFC","65CC81":"NFD"}, здесь оба ключа обозначают «é». Также в тесты включена проверка {"a":0,"a":-0}.
y_object_empty_key.json {"":0}
y_object_duplicated_key_and_value.json {"a":"b","a":"b"}
n_object_double_colon.json {"x"::"b"}
n_object_key_with_single_quotes.json {key: 'value'}
n_object_missing_key.json {:"b"}
n_object_non_string_key.json {1:1}
2.5. Строки
Кодировка файла. «JSON-текст ДОЛЖЕН быть в кодировке UTF-8, UTF-16 или UTF-32. По умолчанию используется UTF-8» (раздел 8.1).
Так что для прохождения тестов необходима одна из трёх кодировок. Тексты в UTF-16 и UTF-32 также должны содержать старшие и младшие варианты.
Сбойные тесты включают в себя строки в кодировке ISO-Latin-1.
y_string_utf16.json FFFE[00"00E900"00]00
n_string_iso_latin_1.json ["E9"]
Маркер последовательности байтов (Byte Order Mark). Хотя в разделе 8.1 заявлено: «Реализации НЕ ДОЛЖНЫ добавлять маркер последовательности байтов в начало JSON-текста», потом мы видим: «Реализации… МОГУТ игнорировать наличие маркера, а не рассматривать его как ошибку».
Сбойные тесты включают в себя лишь отметки в кодировке UTF-8, без другого контента. Тесты, результаты которых зависят от реализации, включают в себя UTF-8 BOM с UTF-8 строкой, а также UTF-8 BOM с UTF-16 строкой и UTF-16 BOM с UTF-8 строкой.
n_structure_UTF8_BOM_no_data.json EFBBBF
n_structure_incomplete_UTF8_BOM.json EFBB{}
i_structure_UTF-8_BOM_empty_object.json EFBBBF{}
Управляющие символы должны быть изолированы и определены как
U+0000 в виде U+001F (раздел 7). Сюда не входит символ 0×7F DEL, который может быть частью других определений управляющих символов (см. раздел 4.6, Bash JSON.sh). Поэтому тесты должен пройти ["7F"].n_string_unescaped_ctrl_char.json ["a\09a"]
y_string_unescaped_char_delete.json ["7F"]
n_string_escape_x.json ["\x00"]
Экранирование. «Все символы могут быть экранированы» (раздел 7), например \uXXXX. Но некоторые — кавычки, обратный слеш и управляющие символы — ДОЛЖНЫ быть экранированы. В сбойные тесты включены символы экранирования без экранируемых значений или со значениями с незавершённым экранированием. Примеры:
["\"], ["\, [\.y_string_allowed_escapes.json ["\"\\/\b\f\n\r\t"]
n_structure_bad_escape.json ["\
Символ экранирования может использоваться для представления кодовых точек (codepoints) на базовом многоязычном уровне (Basic Multilingual Plane, BMP) (
\u005C). Успешные тесты включают в себя нулевой символ (zero character) \u0000, который может приводить к проблемам в парсерах на С. Сбойные тесты включают в себя заглавную U \U005C, нешестнадцатеричные экранированные значения \u123Z и значения с незавершённым экранированием \u123.y_string_backslash_and_u_escaped_zero.json ["\u0000"]
n_string_invalid_unicode_escape.json ["\uqqqq"]
n_string_incomplete_escaped_character.json ["\u00A"]
Экранированные не Unicode-символы
Кодовые точки вне BMP представлены экранированными суррогатами в кодировке UTF-16: +1D11E становится \uD834\uDD1E. Успешные тесты включают в себя одиночные суррогаты, поскольку они валидны с точки зрения JSON-грамматики. Опечатка 3984 в RFC 7159 породила проблему грамматически корректных экранированных кодовых точек, которые не являются Unicode-символами (\uDEAD), или несимволов с U+FDD0 по U+10FFFE.
В то же время дополненная форма Бэкуса — Наура (ABNF, Augmented Backus — Naur form) не допускает использования не соответствующих Unicode кодовых точек (раздел 7) и требует соответствия Unicode (раздел 1).
Редакторы решили, что грамматика не должна ограничиваться и что достаточно предупредить пользователей о «непредсказуемости» (RFC 7159, раздел 8.2) поведения парсеров. Иными словами, парсеры ДОЛЖНЫ парсить u-экранированные несимволы, но результат непредсказуем. В таких случаях имена файлов начинаются с префикса i_ (зависит от реализации). Согласно стандарту Unicode, неверные кодовые точки должны быть заменены на символ замены U+FFFD REPLACEMENT CHARACTER. Если вы уже сталкивались со сложностью Unicode, то вас не удивит, что замена необязательна к исполнению и может делаться разными способами (см. Unicode PR #121: Рекомендованные методики для символов замены). Поэтому одни парсеры используют символы замены, а другие оставляют экранированную форму или генерируют не Unicode-символ (см. раздел 5 — Содержимое парсинга).
y_string_accepted_surrogate_pair.json ["\uD801\udc37"]
n_string_incomplete_escaped_character.json ["\u00A"]
i_string_incomplete_surrogates_escape_valid.json ["\uD800\uD800\n"]
i_string_lone_second_surrogate.json ["\uDFAA"]
i_string_1st_valid_surrogate_2nd_invalid.json ["\uD888\u1234"]
i_string_inverted_surrogates_U+1D11E.json ["\uDd1e\uD834"]
Обычные (raw) не Unicode-символы
В предыдущем разделе мы обсудили не Unicode — кодовые точки, возникающие в строках (\uDEAD). Эти точки являются валидным Unicode в u-экранированной форме, но не декодируются в Unicode-символы.
Парсеры также должны обрабатывать обычные байты, не кодирующие Unicode-символы. Например, в UTF-8 байт FF не является Unicode-символом. Следовательно, строковое значение, содержащее FF, — это не строка в кодировке UTF-8. В таком случае парсер должен просто отказаться её парсить, потому что «Строковое значение — это последовательность Unicode-символов в количестве от нуля и более» (RFC 7159, раздел 1) и «JSON-текст ДОЛЖЕН быть представлен в кодировке Unicode» (RFC 7159, раздел 8.1).
y_string_utf8.json ["€?"]
n_string_invalid_utf-8.json ["FF"]
n_array_invalid_utf8.json [FF]
Двусмысленности RFC 7159
Помимо специфических случаев, которые мы рассмотрели, практически невозможно установить, соответствует ли парсер требованиям RFC 7159, по причине сказанного в разделе 9:
JSON-парсер ДОЛЖЕН принимать все тексты, соответствующие грамматике JSON. JSON-парсер МОЖЕТ принимать не JSON формы или расширения.
Пока всё понятно. Все грамматически правильные входные данные ДОЛЖНЫ парситься, и парсеры могут сами решать, принимать ли другой контент.
Реализации могут ограничивать:
- размер принимаемого текста;
- максимальную глубину вложенности;
- диапазон и точность чисел;
- длину строковых значений и их набор символов.
Все эти ограничения звучат разумно (за исключением, возможно, символов), но противоречат слову «ДОЛЖЕН» из предыдущей цитаты. RFC 2119 предельно ясно объясняет его значение:
ДОЛЖЕН. Это слово, как и «ТРЕБУЕТСЯ» или «СЛЕДУЕТ», означает обязательное требование спецификации.
RFC 7159 допускает ограничения, но не задаёт минимальные требования. Поэтому технически парсер, который не может парсить строку длиннее трёх символов, всё ещё соответствует требованиям RFC 7159.
Кроме того, в разделе 9 RFC 7159 от парсеров требуется ясно документировать ограничения и/или позволить использовать пользовательские конфигурации. Но эти конфигурации могут приводить к проблемам с совместимостью, поэтому лучше останавливаться на минимальных требованиях.
Такой недостаток конкретики на фоне допускаемых ограничений практически не позволяет точно сказать, соответствует ли парсер RFC 7159. Ведь можно парсить контент, не соответствующий грамматике (это «расширения»), и отклонять контент, соответствующий грамматике (это «ограничения» парсера).
3. Архитектура тестированияЯ хотел посмотреть, как на самом деле поведут себя парсеры, вне зависимости от того, как они должны себя вести. Поэтому выбрал несколько JSON-парсеров и настроил всё так, чтобы можно было скармливать им свои тестовые файлы.
Поскольку я Cocoa-разработчик, большинство парсеров написаны на Swift и Objective-C. Но есть и достаточно произвольно выбранные парсеры на C, Python, Ruby, R, Lua, Perl, Bash и Rust. В основном я старался охватить разнообразные по возрасту и популярности языки.
Некоторые парсеры позволяют усиливать или ослаблять строгость ограничений, настраивать поддержку Unicode или использовать специфические расширения. Я стремился всегда конфигурировать парсеры, чтобы они работали как можно ближе к наиболее строгой интерпретации RFC 7159.
Python-скрипт run_tests.py прогонял через каждый парсер каждый тестовый файл (или одиночный тест, если файл передаётся в виде аргумента). Обычно парсеры были в обёртках и возвращали 0 в случае успеха и 1 в случае неудачи парсинга. Был предусмотрен отдельный статус для падения парсера, а также таймаут — 5 секунд. По сути, я превратил JSON-парсеры в JSON-валидаторы.
run_tests.py сравнивал возвращаемое значение по каждому тесту с ожидаемым результатом, отражённым в префиксе имени файла. Если они не совпадали или когда префикс был i (зависит от реализации), run_tests.py записывал в журнал (results/logs.txt) строку определённого формата:
Python 2.7.10 SHOULD_HAVE_FAILED n_number_infinity.json

Затем run_tests.py считывал журнал и генерировал HTML-таблицы с результатами (results/parsing.html).
В каждой строке находятся результаты для одного из файлов. Парсеры представлены в колонках. Для разных результатов предусмотрены разные цвета заливки ячеек:

Тесты отсортированы по результатам. Это облегчает поиск схожих результатов и удаление избыточных.
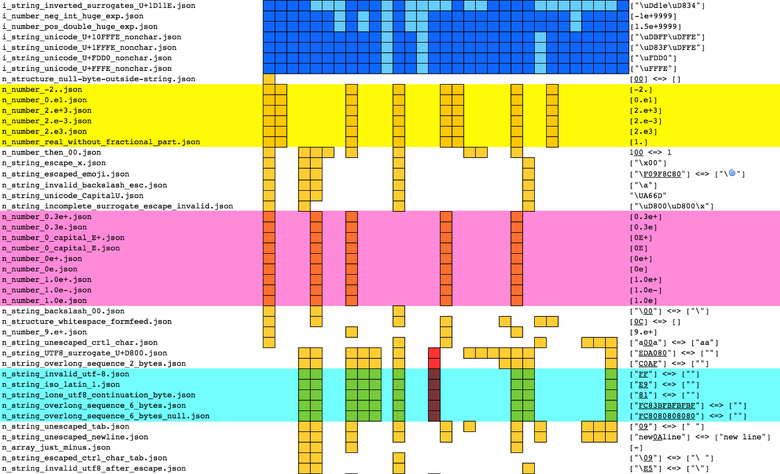
4.1. Полные результаты
Полные результаты тестирования можно найти здесь: seriot.ch/json/parsing.html. Тесты отсортированы по схожести результатов. В
run_tests.py есть опция, позволяющая выводить «сокращённые результаты» (pruned results): когда набор тестов даёт одинаковые результаты, то сохраняется только первый тест. Файл с сокращёнными данными доступен тут: www.seriot.ch/json/parsing_pruned.html.Падения (красный цвет) — самая серьёзная проблема, поскольку парсинг неконтролируемых входных данных подвергает риску весь процесс. Тесты «ожидалось успешное выполнение» (коричневый цвет) также очень опасны: неконтролируемые входные данные могут не дать отпарсить весь документ. Менее опасны тесты «ожидался сбой выполнения» (жёлтый цвет). Они говорят о «расширениях», которые нельзя отпарсить. Так что всё станет работать до тех пор, пока парсер не будет заменён другим, который не умеет парсить эти «расширения».

Дальше я рассмотрю и прокомментирую самые примечательные результаты.
4.2. C-парсеры
Я выбрал пять C-парсеров:
- github.com/zserge/jsmn
- github.com/akheron/jansson
- github.com/rustyrussell/ccan
- github.com/DaveGamble/cJSON
- github.com/udp/json-parser
Краткая сравнительная таблица:

Больше подробностей можно найти в таблице полных результатов.
4.3. Objective-C-парсеры
Я выбрал три Objective-C-парсера, очень популярных на заре iOS-разработки, особенно потому, что Apple до iOS 5 не выпускала NSJSONSerialization. Все три парсера было интересно протестировать, поскольку они использовались при разработке многих приложений.
- github.com/johnezang/JSONKit
- github.com/TouchCode/TouchJSON
- github.com/stig/json-framework aka SBJSON
Краткая сравнительная таблица:
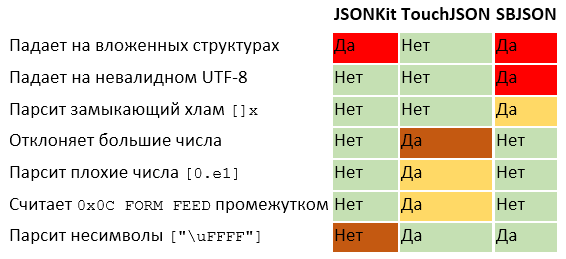
SBJSON выжил после появления NSJSONSerialization, он до сих пор поддерживается, его можно скачать через CocoaPods. Поэтому в заявке #219 я зарепортил падение, когда парсил не UTF-8 строки наподобие [«FF»].
*** Assertion failure in -[SBJson4Parser parserFound:isValue:], SBJson4Parser.m:150
*** Terminating app due to uncaught exception 'NSInternalInconsistencyException', reason: 'Invalid parameter not satisfying: obj'
*** First throw call stack:
(
0 CoreFoundation 0x00007fff95f4b4f2 __exceptionPreprocess + 178
1 libobjc.A.dylib 0x00007fff9783bf7e objc_exception_throw + 48
2 CoreFoundation 0x00007fff95f501ca +[NSException raise:format:arguments:] + 106
3 Foundation 0x00007fff9ce86856 -[NSAssertionHandler handleFailureInMethod:object:file:lineNumber:description:] + 198
4 test_SBJSON 0x00000001000067e5 -[SBJson4Parser parserFound:isValue:] + 309
5 test_SBJSON 0x00000001000073f3 -[SBJson4Parser parserFoundString:] + 67
6 test_SBJSON 0x0000000100004289 -[SBJson4StreamParser parse:] + 2377
7 test_SBJSON 0x0000000100007989 -[SBJson4Parser parse:] + 73
8 test_SBJSON 0x0000000100005d0d main + 221
9 libdyld.dylib 0x00007fff929ea5ad start + 1
)
libc++abi.dylib: terminating with uncaught exception of type NSException
4.4. Apple (NS)JSONSerialization
developer.apple.com/reference/foundation/nsjsonserialization
NSJSONSerialization появился с iOS 5, и с тех пор это стандартный JSON-парсер на OS X и iOS. Он доступен на Objective-C и был переписан на Swift: NSJSONSerialization.swift. В Swift 3 префикс NS отбросили.
Ограничения и расширения
У JSONSerialization есть незадокументированные ограничения:
- Он не парсит большие числа:
[123123e100000] - Он не парсит u-экранированные ошибочные кодовые точки:
["\ud800"]
У JSONSerialization есть незадокументированное расширение:
- Он парсит замыкающие запятые:
[1,]и{"a":0,}
Самым проблемным я считаю ограничение, связанное с кодовыми точками, особенно у такого популярного парсера. Попытка парсинга неконтролируемого контента может привести к сбою парсинга.
Падение при сериализации
Этот раздел больше про JSON-парсинг, а не JSON-разработку. Но я решил упомянуть про это падение, с которым столкнулся, когда JSONSerialization записывал Double.nan. Как вы помните, NaN не соответствует грамматике JSON, поэтому JSONSerialization должен был выдать ошибку, а не обрушить весь процесс.
do {
let a = [Double.nan]
let data = try JSONSerialization.data(withJSONObject: a, options: [])
} catch let e {
}
SIGABRT
*** Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: 'Invalid number value (NaN) in JSON write'
4.5. Freddy (Swift)
Freddy (https://github.com/bignerdranch/Freddy) — это настоящий JSON-парсер, написанный на Swift 3. Я говорю «настоящий», потому что несколько GitHub-проектов заявляют себя как Swift JSON-парсеры, хотя на самом деле используют Apple JSONSerialization и просто мапят JSON-контент в объект-модели.
Freddy интересен тем, что написан знаменитой группой Cocoa-разработчиков и эксплуатирует безопасность типов Swift с помощью использования Swift-перечислений для представления разных JSON-узлов (Array, Dictionary, Double, Int, String, Bool и Null).
Но Freddy выпущен в январе 2016-го, он ещё молод и забагован. Мой тестовый набор продемонстрировал, что парсер падает на незакрытых структурах вроде [1, и {"a":, и на строке в виде одиночного пробела » ». Я открыл заявку #199, и баг пофиксили за один день!
Также я обнаружил, что "0e1" ошибочно отклоняется парсером, о чём написал в заявке #198, и этот баг тоже пофиксили за один день.
Тем не менее по состоянию на 18 октября Freddy всё ещё падает при парсинге ["\. О баге я сообщил в заявке #206.
В этой таблице отражена эволюция поведения Freddy:

4.6. Bash JSON.sh
Я тестировал github.com/dominictarr/JSON.sh, версию от 12 августа 2016 года.
В этом Bash-парсере регулярные выражения отвечают за поиск управляющих символов, которые, согласно RFC 7159, ДОЛЖНЫ быть экранированы с помощью обратных слешей. Но у Bash и JSON разные представления о том, что такое управляющие символы.
Регулярные выражения для сопоставления управляющих символов используют синтаксис :cntlr:. Это сокращённая форма [\x00-\x1F\x7F]. Но по правилам грамматики JSON 0x7F DEL не относится к управляющим символам и может не экранироваться.
00 nul 01 soh 02 stx 03 etx 04 eot 05 enq 06 ack 07 bel
08 bs 09 ht 0a nl 0b vt 0c np 0d cr 0e so 0f si
10 dle 11 dc1 12 dc2 13 dc3 14 dc4 15 nak 16 syn 17 etb
18 can 19 em 1a sub 1b esc 1c fs 1d gs 1e rs 1f us
20 sp 21 ! 22 " 23 # 24 $ 25 % 26 & 27 '
28 ( 29 ) 2a * 2b + 2c , 2d — 2e . 2f /
30 0 31 1 32 2 33 3 34 4 35 5 36 6 37 7
38 8 39 9 3a : 3b ; 3c < 3d = 3e > 3f ?
40 @ 41 A 42 B 43 C 44 D 45 E 46 F 47 G
48 H 49 I 4a J 4b K 4c L 4d M 4e N 4f O
50 P 51 Q 52 R 53 S 54 T 55 U 56 V 57 W
58 X 59 Y 5a Z 5b [ 5c \ 5d ] 5e ^ 5f _
60 ` 61 a 62 b 63 c 64 d 65 e 66 f 67 g
68 h 69 i 6a j 6b k 6c l 6d m 6e n 6f o
70 p 71 q 72 r 73 s 74 t 75 u 76 v 77 w
78 x 79 y 7a z 7b { 7c | 7d } 7e ~ 7f del
В результате JSON.sh не может парсить
["7F"]. Я зарепортил этот баг. Также JSON.sh не ограничивает глубину вложенности и падает при парсинге 10 000 символов открывания массива [. Об этом я тоже сообщил. $ python -c "print('['*100000)" | ./JSON.sh
./JSON.sh: line 206: 40694 Done tokenize
40695 Segmentation fault: 11 | parse
4.7. Другие парсеры
Помимо C / Objective-C и Swift, я тестировал парсеры и из других окружений. Вот краткий обзор их расширений и ограничений с выборкой из полных результатов тестирования. Таблица призвана показать, что не найдётся и двух парсеров, которые полностью совпадают во мнении, что хорошо и что плохо.
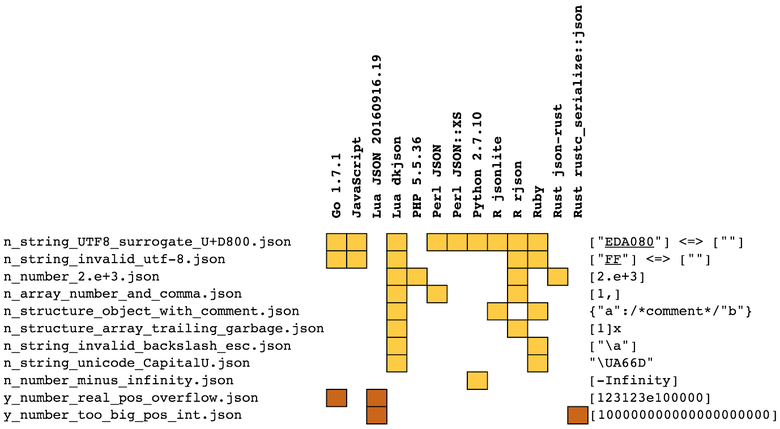
Ссылки на протестированные парсеры:
- Lua JSON 20160728.17 regex.info/blog/lua/json (наслаждайтесь качеством комментариев в исходном коде)
- Lua dkjson 2.5.1 github.com/LuaDist/dkjson
- Go 1.7.1, json mobule golang.org/pkg/encoding/json
- Python 2.7.10, json module docs.python.org/2.7/library/json.html
- JavaScript, macOS 10.12
- Perl JSON metacpan.org/pod/JSON
- Perl JSON: XS metacpan.org/pod/JSON: XS
- PHP 5.6.24, macOS 10.12
- R rjson cran.r-project.org/web/packages/rjson/index.html
- R jsonlite github.com/jeroenooms/jsonlite
- Rust json-rust github.com/maciejhirsz/json-rust
- Rust rustc_serialize: json doc.rust-lang.org/rustc-serialize/rustc_serialize/json
По многочисленным просьбам я также добавил Java-парсеры, которые не отражены в краткой таблице, но присутствуют в полных результатах:
- Java Gson 2.7 github.com/google/gson
- Java Jackson 2.8.4 github.com/FasterXML/jackson
- Java Simple JSON 1.1.1 code.google.com/archive/p/json-simple
JSON-модуль Python парсит
NaN и -Infinity как числа. Это можно исправить, настроив опции parse_constant у функции, выбрасывающей исключение, как показано ниже. Но такое решение встречается редко, поэтому я не использовал его в тестах и позволил парсеру ошибочно парсить эти числовые константы.def f_parse_constant(o):
raise ValueError
o = json.loads(data, parse_constant=f_parse_constant)
4.8. JSON Checker
JSON-парсер преобразует JSON-документ в другое представление. Если входные данные являются некорректным JSON, то парсер возвращает ошибку.
Некоторые программы не преобразуют входные данные, а просто сообщают о корректности или некорректности JSON. Такие программы — это JSON-валидаторы.
Одна из них написана на С и называется JSON_Checker. Её можно скачать с www.json.org/JSON_checker, и с ней даже идёт тестовый набор (маленький):
JSON_Checker — это pushdown automaton программа, которая очень быстро определяет синтаксическую корректность JSON-текста. Она может использоваться для фильтрования входных данных или для проверки выходных данных на синтаксическую корректность. JSON_Checker можно адаптировать для создания очень быстрого JSON-парсера.
Хотя JSON_Checker формально не является референсной реализацией, всё же можно ожидать, что он уточнит требования JSON-спецификации или хотя бы корректно их реализует.
К сожалению, JSON_Checker нарушает спецификации, определённые на том же сайте. Например, он парсит [1.], [0.e1], что не соответствует грамматике JSON.
Более того, JSON_Checker отклоняет [0e1], совершенно валидное JSON-число. Это самый серьёзный баг, потому что из-за наличия числа 0e1 может быть отклонён весь документ.
Элегантность реализации JSON_Checker в качестве pushdown automaton не отменяет ошибочности кода, но хотя бы таблица перехода состояний облегчает обнаружение ошибок, особенно когда вы добавляете состояния в схему того, что является числом.

Баг 1: отклонение 0e1. В коде состоянию ZE, достигнутому после парсинга 0, не хватает переходов к E1 с помощью чтения e или E. Это можно исправить, добавив два отсутствующих перехода.
Баг 2: принятие [1.]. В одних случаях, например после 0., грамматика требует наличия цифры. А в других, например после 1., не требует.
JSON_Checker всё ещё определяет одно состояние FR, а не два. Это можно исправить, заменив на схеме красное состояние FR новым состоянием F0 или frac0. Тогда после 1. парсер будет требовать цифру.

Ряд других парсеров (Obj-C TouchJSON, PHP, R rjson, Rust json-rust, Bash JSON.sh, C jsmn и Lua dkjson) тоже ошибочно парсят [1.]. Как этот баг распространился из JSON_Checker? Просто разработчики парсеров и тестеры используют его в качестве референса, как это советуется на json.org.
4.9. Регулярные выражения
Могут ли регулярные выражения проверять соответствие входных данных грамматике JSON? Посмотрите, например, на попытку найти самое короткое регулярное выражение. Проблема в том, что без серьёзного тестирования очень трудно узнать, увенчались ли успехом действия регулярных выражений.
Я нашёл на StackOverflow одно из лучших регулярных выражений на Ruby для валидации JSON:
JSON_VALIDATOR_RE = /(
# define subtypes and build up the json syntax, BNF-grammar-style
# The {0} is a hack to simply define them as named groups here but not match on them yet
# I added some atomic grouping to prevent catastrophic backtracking on invalid inputs
(? -?(?=[1-9]|0(?!\d))\d+(\.\d+)?([eE][+-]?\d+)?){0}
(? true | false | null ){0}
(? " (?>[^"\\\\]* | \\\\ ["\\\\bfnrt\/] | \\\\ u [0-9a-f]{4} )* " ){0}
(? \[ (?> \g (?: , \g )* )? \s* \] ){0}
(? \s* \g \s* : \g ){0}
(? Оно не может парсить валидный JSON, например:
- u-экранированные кодовые точки, включая валидные:
["\u002c"] - обратный слеш, экранированный обратным слешем:
["\\a"]
Также оно парсит следующие расширения (а это баг для JSON-валидатора):
- True с заглавной буквы:
[True] - неэкранированный управляющий символ:
["09"]
5. Контент парсинга
В RFC 7159 (раздел 9) сказано:
JSON-парсер преобразует JSON-текст в другое представление.
Вся вышеперечисленная архитектура тестирования говорит лишь о том, будет ли парсер парсить JSON-документ, но ничего не сообщает о представлении получившегося контента.
Например, можно без ошибки отпарсить u-экранированный неправильный Unicode-символ ("\uDEAD"), но каким будет результат? Символ замены или что-то другое? В RFC 7159 об этом ни слова.
А что насчёт экстремальных чисел вроде 0.00000000000000000000001 и -0? Их можно отпарсить, но что мы получим? RFC 7159 не разделяет целочисленные и значения с плавающей запятой или 0 и –0. Там даже не сказано, можно ли конвертировать числа в строки.
Или как быть с объектами, содержащими одинаковые ключи ({"a":1,"a":2})? Или одинаковые ключи и значения ({"a":1,"a":1})? А как парсер должен сравнивать ключи объекта? В двоичном представлении или в нормальной Unicode-форме, как NFC? В RFC нет ответа.
Во всех этих случаях парсеры могут делать с выходными данными что угодно. Отсюда — проблемы с совместимостью (подумайте, что может пойти не так, если вы решите поменять свой привычный JSON-парсер на другой).
Учитывая вышесказанное, давайте проведём тестирования на неопределённость представления после парсинга. Эти тесты нужны только для понимания, как могут различаться выходные данные парсеров. В отличие от проверки парсинга, эти тесты трудно автоматизировать. Так что результаты получены с помощью анализа журналов выражений (log statements) и/или отладчиков.
Ниже представлен список некоторых разительных отличий между финальными представлениями после парс
