[Перевод] Очередь недоставленных сообщений для обработки ошибок в Apache Kafka
Любому надёжному конвейеру потоковой обработки данных нужны механизмы обнаружения и обработки ошибок. В этой статье вы узнаете, как реализовать обработку ошибок с помощью очереди недоставленных сообщений (Dead Letter Queue) в инфраструктуре Apache Kafka. Мы рассмотрим несколько вариантов: кастомная реализация, Kafka Streams, Kafka Connect, Spring Framework и Parallel Consumer. Вы увидите, как Uber, CrowdStrike и Santander Bank реализуют надёжные механизмы обработки ошибок в реальном времени и в огромном масштабе.

Сегодня многие организации выбирают Apache Kafka для интеграции систем. Даже в облачных проектах потоковая обработка данных с Kafka используется как нативная облачная платформа интеграции как услуга (iPaaS).
Что такое очередь недоставленных сообщений?
Очередь недоставленных сообщений (Dead Letter Queue, DLQ) в системе обмена сообщениями или на платформе потоковой обработки данных отвечает за хранение сообщений, которые не были успешно обработаны. Система не отбрасывает сообщение, а перемещает его в очередь недоставленных.
В шаблонах интеграции корпоративных приложений (Enterprise Integration Patterns, EIP) это называется канал недоставленных сообщений (Dead Letter Channel). Это синонимы.
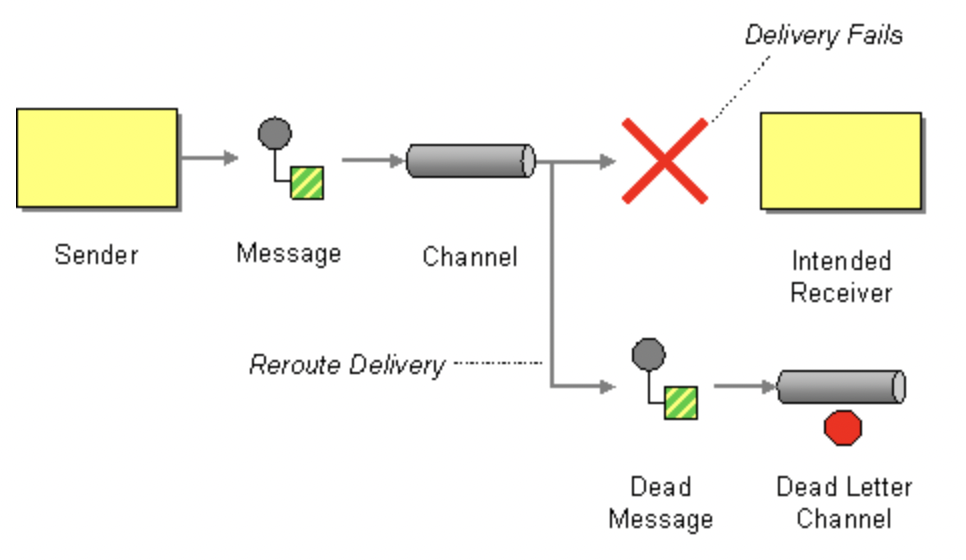
В этой статье мы будем говорить только о сообщениях в Apache Kafka. Если сообщение попало в DLQ в Kafka, скорее всего, у него неправильный формат или недопустимое/отсутствующее содержимое. Например, приложение ждёт целое число, а получает строку и выдаёт ошибку. В динамичной среде сообщение может быть не доставлено, например, потому что топик не существует.
Другие брокеры сообщений, вроде IBM MQ, TIBCO EMS или RabbitMQ, работают не так, как распределённый лог коммитов, как в Kafka. В этих брокерах DLQ используется иначе. Например, в системе MQ у каждого сообщения есть свой срок жизни (TTL).
В Kafka же, если сообщение попало в DLQ, скорее всего, у него неправильный формат или недопустимое/отсутствующее содержимое.
Альтернативы очереди недоставленных сообщений в Apache Kafka
Очередь недоставленных сообщений — это один или несколько топиков Kafka, которые получают и хранят сообщения, не обработанные в стандартном потоке из-за ошибки. Этот механизм позволяет продолжить поток сообщений, даже если одно сообщение не было доставлено.
Умные конечные точки и глупые брокеры
Архитектура Kafka не поддерживает DLQ в брокерах. Kafka намеренно построена на тех же принципах, что и современные микросервисы, в частности, на принципе умные конечные точки и глупые брокеры. Поэтому Kafka так хорошо масштабируется по сравнению с традиционными брокерами сообщений. Фильтрация и обработка ошибок происходит на стороне клиента.
Такая изоляция платформы потоковой обработки данных поддерживает чёткое деление на предметные области. Каждый микросервис или приложение реализуют свою логику с помощью своей технологии, парадигмы коммуникаций и обработки ошибок.
В традиционном промежуточном слое и очередях сообщений эту логику предоставляет сам брокер. Это затрудняет масштабирование и лишает гибкости команды в предметных областях, потому что логику интеграции может реализовать только команда промежуточного слоя.
Кастомная реализация очереди недоставленных сообщений в Kafka на любом языке программирования
Очередь недоставленных сообщений в Kafka не зависит от фреймворка. У некоторых компонентов уже есть готовые функции обработки ошибок и очереди недоставленных сообщений, но мы можем легко написать логику очереди недоставленных сообщений для приложений Kafka на любом языке (Java, Go, C++, Python и т. д.).
Исходный код для реализации DLQ содержит блок try-catch для обработки ожидаемых и непредвиденных исключений. Если все нормально, сообщение обрабатывается. Если возникло исключение, сообщение отправляется в специальный топик Kafka с DLQ.
В заголовок сообщения добавляется причина сбоя. Ключ и значение должны оставаться без изменений, чтобы потом можно было повторно обработать сообщение и проанализировать сбой.
Готовые реализации для очереди недоставленных сообщений в Kafka
Нам не всегда нужно создавать очередь недоставленных сообщений самим — во многих компонентах и фреймворках она уже реализована.
В своём приложении мы обычно можем контролировать ошибки и исправлять код, но при интеграции со сторонними приложениями могут появляться ошибки, с которыми мы ничего не можем сделать. В этих случаях DLQ особенно важна, и она входит в некоторые фреймворки.
Встроенная очередь недоставленных сообщений в Kafka Connect
Kafka Connect отвечает за интеграцию, входит в опенсорс-версию Kafka и не требует дополнительных зависимостей (кроме самих соединителей, которые мы развёртываем в кластере Connect).
По умолчанию задачи Kafka Connect останавливаются, когда происходит ошибка из-за поступления недопустимого сообщения (например, если используется конвертер JSON, когда нужен AVRO). Альтернатива — просто удалить проблемное сообщение, чтобы не прерывать обработку.
Настроить DLQ в Kafka Connect очень просто — мы задаём значения для двух параметров конфигурации: errors.tolerance и errors.deadletterqueue.topic.name:

В этой статье приводятся примеры кода для DLQ.
Можно даже использовать Kafka Connect для обработки сообщения с ошибкой из DLQ. Просто разверните ещё один коннектор, который будет потреблять сообщения из топика DLQ. Например, приложение обрабатывает сообщения в формате Avro и вдруг поступило сообщение в JSON. Коннектор берет сообщение JSON из очереди и преобразует его в Avro, чтобы его можно было обработать повторно, и на этот раз успешно:

В Kafka Connect нет очереди недоставленных сообщений для коннектора-источника.
Обработка ошибок в приложении Kafka Streams
Kafka Streams — это библиотека потоковой обработки для Kafka. Она похожа на другие фреймворки потоковой обработки, вроде Apache Flink, Storm, Beam и другие, но специально для Kafka, так что мы можем построить полноценное решение для потоковой обработки данных в единой надёжной и масштабируемой инфраструктуре.
Если вы разрабатываете приложения Kafka на Java и в экосистеме JVM, лучше используйте Kafka Streams, а не стандартный клиент Java для Kafka. Почему?
Kafka Streams — это просто обёртка для API Java продюсеров и консьюмеров со множеством встроенных дополнительных функций.
И то и другое — это библиотеки (JAR-файлы), внедрённые в приложение Java.
Обе библиотеки входят в опенсорс-версию Kafka без дополнительных зависимостей и изменения лицензии.
Многие проблемы уже решены «из коробки» и позволяют создавать зрелые сервисы потоковой обработки (функции потоковой обработки, встроенное хранилище stateful, скользящие окна, интерактивные запросы, обработка ошибок и многое другое).
Одна из встроенных функций Kafka Streams — дефолтный обработчик исключений десериализации, с помощью которого можно устранять исключения, если у записи возникли проблемы с десериализацией. Повреждённые данные, неверная логика сериализации или необработанные типы записей могут приводить к ошибкам. Эта функция не называется очередью недоставленных сообщений, но решает ту же проблему из коробки.
Обработка ошибок со Spring Kafka и Spring Cloud Stream
Платформа Spring отлично сочетается с Apache Kafka. Она предлагает много шаблонов, чтобы нам не пришлось писать стандартный код. Spring-Kafka и Spring Cloud Stream Kafka поддерживают разные варианты обработки ошибок и повторных попыток, включая повторные попытки по времени или по количеству, очереди недоставленных сообщений и т. д.
Платформа Spring предлагает очень много функций, но она тяжеловата и требует дополнительного обучения. Это отличный вариант, если вы создаёте проект с нуля или уже используете Spring для других проектов.
Есть много хороших статей с примерами и вариантами конфигурации. Есть даже официальный пример использования очередей недоставленных сообщений в Spring Cloud Stream. В Spring можно создавать логику, например DLQ, с помощью простых аннотаций. Кто-то обожает такой подход, кто-то не любит. Просто знайте, что такой вариант есть.
Масштабируемая обработка ошибок с помощью Parallel Consumer для Apache Kafka
Многие организации используют очередь недоставленных сообщений, чтобы обрабатывать сбои подключения к внешним веб-сервисам или базам данных. Некоторые приложения не могут нормально продолжать работу, если истекает время ожидания запросов или Kafka не может отправлять запросы параллельно. Parallel Consumer отлично решает проблему.
Parallel Consumer для Apache Kafka — это опенсорс-проект, который предоставляется по лицензии Apache 2.0. Это обёртка для Apache Kafka с обработкой очередей на стороне клиента, упрощённым API консьюмера и продюсера, параллелизмом на уровне ключей и расширяемой неблокирующей обработкой ввода-вывода.
С помощью этой библиотеки можно обрабатывать сообщения параллельно через один консьюмер Kafka, то есть можно увеличить параллелизм без увеличения количества партиций в топике. Часто это помогает повысить пропускную способность и сократить задержку, потому что мы снижаем нагрузку на брокеры Kafka. Такой подход открывает нам новые возможности, вроде крайнего параллелизма, внешнего обогащения данных и создания очередей.
Главное преимущество — обработка/повторение вызовов к веб-сервисам и базам данных в одном приложении консьюмера Kafka. При использовании параллелизации нам не приходится ограничиваться одним запросом за раз:
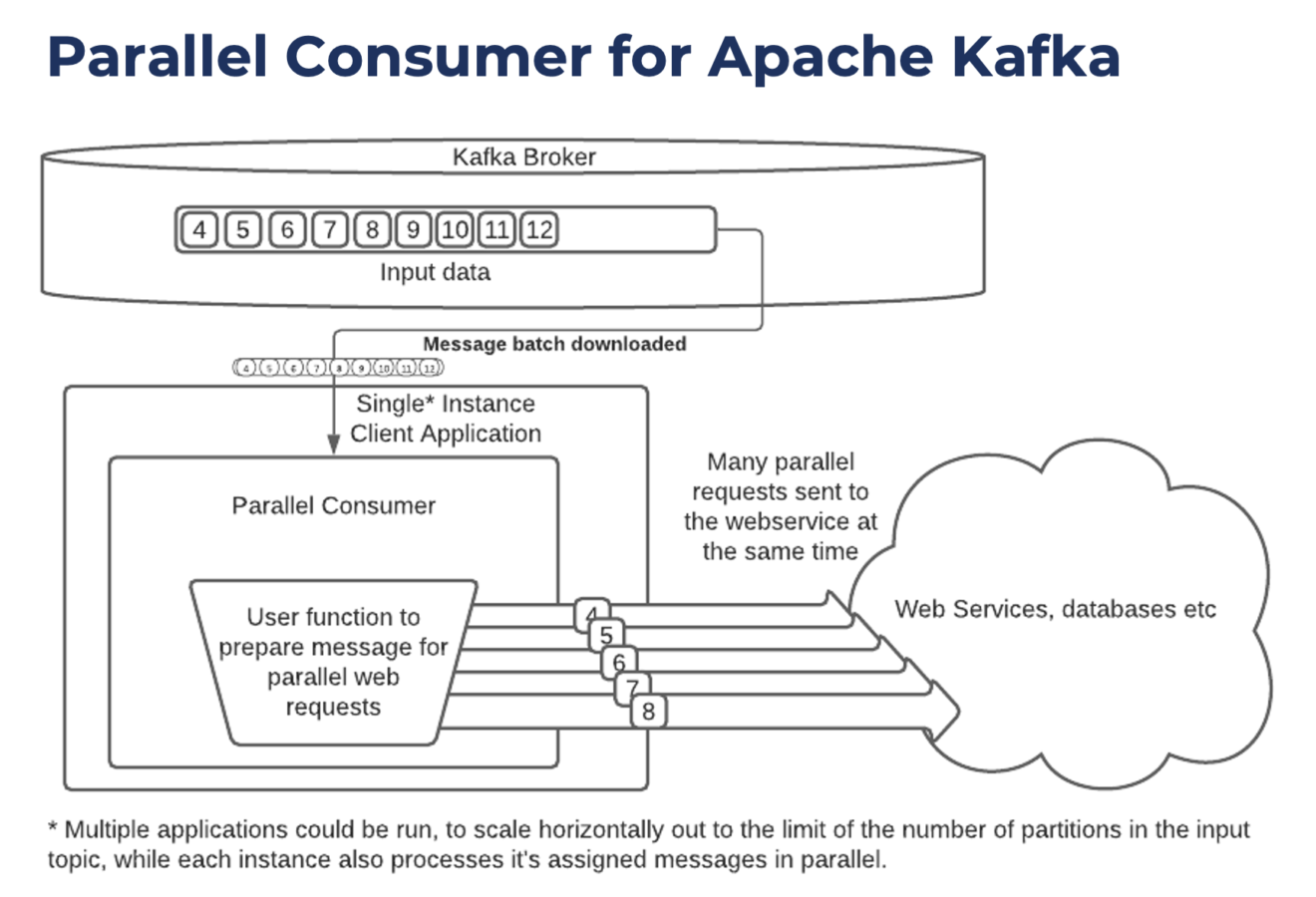
У клиента Parallel Consumer есть эффективная логика повторных попыток, которая включает настраиваемые задержки и динамическую обработку ошибок. Сообщения с ошибками можно отправлять в очередь недоставленных сообщений.
Получение сообщений из очереди недоставленных
Недостаточно просто отправить недопустимое сообщение в очередь недоставленных сообщений. Его ещё нужно обработать или хотя бы отследить.
Очередь недоставленных сообщений — это отличный способ убрать ошибку из основного потока обработки, чтобы обработать её отдельно.
Существует множество стратегий обработки ошибок. Давайте рассмотрим несколько рекомендаций.
Стратеги обработки ошибок
Когда сообщение попадает в очередь недоставленных сообщений, у нас есть несколько вариантов дальнейших действий:
Повторная обработка. Некоторые сообщения в DLQ нужно снова обработать, когда проблема будет решена. Чтобы решить проблему, можно использовать автоматический скрипт, исправить сообщение вручную или вернуть продюсеру ошибку с просьбой повторно отправить исправленное сообщение.
Удаление сообщений (после анализа). Иногда сообщения с ошибками могут быть обычным делом, но их стоит изучить, прежде чем удалять. Например, можно составлять графики ошибок на дашборде.
Расширенная аналитика. Чтобы не обрабатывать каждое сообщение в DLQ, можно анализировать входящие данные и извлекать из них полезную информацию в реальном времени. Например, простое приложение ksqlDB может с помощью потоковой обработки вычислять среднее количество проблемных сообщений в час или другие информативные показатели.
Остановка рабочего процесса. Если проблемные сообщения должны возникать редко, мы можем останавливать весь рабочий процесс из-за сбоя одного сообщения. Это решение может приниматься системой или человеком. Разумеется, останавливать рабочий процесс можно и в приложении Kafka, которое выдаёт ошибку. DLQ может уведомлять о проблеме нужные команды.
Игнор. Мы можем не делать ничего — пусть очередь недоставленных сообщений просто наполняется. Кажется, что это неправильно, но в некоторых случаях это лучший вариант. Например, если мы мониторим общее поведение приложения Kafka. У топика Kafka в любом случае есть срок хранения данных, и сообщения будут удалены, когда он закончится. Просто настройте его в зависимости от своих потребностей и отслеживайте топик DLQ на предмет неожиданного поведения (например, слишком быстрое заполнение).
Рекомендации по очереди недоставленных сообщений в Apache Kafka:
Определите бизнес-процесс для обработки недопустимых сообщений (автоматически или вручную).
Реальность: часто никто не обрабатывает сообщения в DLQ.
Альтернатива 1: оповещения должны приходить владельцам данных, а не команде по инфраструктуре.
Альтернатива 2: оповещения должны приходить команде по системе записи, чтобы они знали, что с данными возникла проблема и нужно их исправить или отправить заново.
Если никого это не волнует и никто не жалуется, возможно, вам вообще не нужна DLQ. Просто игнорируйте эти сообщения, чтобы не усложнять инфраструктуру, экономить деньги и не перегружать сеть.
Создайте дашборд с оповещениями для нужных команд по удобным каналам (электронная почта, Slack).
Определите приоритет обработки ошибок для разных топиков Kafka (остановка рабочего процесса, удаление сообщения, повторная обработка).
Отправляйте в DLQ только сообщения, для которых невозможны повторные попытки, — проблемами с подключением должно заниматься приложение-консьюмер.
Сохраняйте исходные сообщения в DLQ (с дополнительными заголовками, например сообщением об ошибке, временем ошибки, именем приложения, где произошла ошибка и т. д.). Такой подход упрощает повторную обработку и устранение неполадок.
Подумайте, сколько вам нужно топиков для очереди недоставленных сообщений. Нужно найти компромисс. Если хранить все ошибки в одной DLQ, это затруднит дальнейший анализ и повторную обработку.
Не забывайте, что DLQ нарушает гарантированный порядок обработки и затрудняет обработку офлайн. Так что Kafka DLQ подходит не для всех сценариев.
Когда ТОЧНО не надо использовать очередь недоставленных сообщений в Kafka?
DLQ для обработки обратного давления (back pressure). Не стоит с помощью DLQ регулировать объём сообщений при пиковых нагрузках. Хранилище за логом Kafka автоматически обрабатывает обратное давление. Консьюмер, если он правильно настроен, извлекает данные с удобной для себя скоростью. По возможности настройте эластичное масштабирование для консьюмеров. Если хранилище заполнено, это его проблемы, DLQ тут никак не поможет.
DLQ для сбоев соединения. Если отправлять сообщения в DLQ в случае сбоя соединения (даже после нескольких повторных попыток), пользы не будет, потому что следующее сообщение тоже не пройдёт. Лучше исправить проблемы с соединением. Сообщения могут храниться в обычном топике столько, сколько это необходимо (в пределах заданного периода хранения).
Schema Registry для управления данными и предотвращения ошибок
Наконец давайте обсудим, как отказаться от очереди недоставленных сообщений или хотя бы меньше от неё зависеть.
С помощью Schema Registry для Kafka можно гарантировать корректный формат сообщений в продюсерах Kafka:

Schema Registry проверяет схему на стороне клиента. В некоторых реализациях, например Confluent Server, также выполняется проверка на стороне брокера, чтобы отклонить недопустимые или вредоносные сообщения от продюсера, который не использует Schema Registry.
Примеры использования очереди недоставленных сообщений в Kafka
Давайте посмотрим, как Uber, CrowdStrike и Santander Bank используют очередь недоставленных сообщений в инфраструктуре Kafka. Помните, что это примеры очень зрелых проектов. Не везде требуется такая степень сложности.
Uber — надёжная повторная обработка с помощью очереди недоставленных сообщений
В распределённых системах повторных попыток не избежать. Причин много — проблемы с сетями, репликацией или даже зависимыми сервисами. Масштабные сервисы должны быть готовы обрабатывать такие сбои с минимальным ущербом для остальных рабочих процессов.
Учитывая масштаб и скорость работы Uber все системы должны быть максимально отказоустойчивыми и стабильными, с продуманной обработкой сбоев. Для этого Uber широко использует Apache Kafka в огромных масштабах.
Например, команда Uber по страхованию расширила использование Kafka в имеющейся архитектуре на основе событий, чтобы использовать неблокирующую повторную обработку запросов и очереди недоставленных сообщений для независимой и наблюдаемой обработки событий без прерывания потока сообщений в реальном времени. Такая стратегия поддерживает надёжную работу добровольной программы страхования водителей от травм, которая рассчитывает взнос по километражу.
Вот пример обработки ошибок в Uber. Ошибки чередуются с повторными попытками, пока сообщение не попадает в DLQ:

См. очень подробную статью о том, как Uber использует очереди недоставленных сообщений.
CrowdStrike — обработка ошибок для триллионов событий
CrowdStrike — компания в сфере информационной безопасности с головным офисом в Остине, штат Техас. Она предлагает решения для защиты облачных рабочих нагрузок и конечных точек, анализа угроз и реагирования на кибератаки.
Инфраструктура CrowdStrike обрабатывает триллионы событий ежедневно с помощью Apache Kafka. В этой статье можно подробнее почитать о том, как использовать Kafka для ситуационной осведомлённости и анализа угроз.
CrowdStrike дает три рекомендации по реализации очередей недоставленных сообщений и обработке ошибок:
Храните проблемные сообщения в подходящей системе. Определите инфраструктуру и код для записи и извлечения недоставленных сообщений. CrowdStrike использует хранилище объектов S3 для больших объёмов сообщений с ошибками. Tiered Storage для Kafka решает эту проблему из коробки, без дополнительного интерфейса хранилища (например, Infinite Storage в Confluent Cloud).
Автоматизируйте процессы. Устраняйте ошибки с помощью инструментов, а не вручную, чтобы не допустить ещё больше ошибок при исправлении ситуации.
Документируйте бизнес-процессы и привлекайте нужные команды. Стандартизируйте и задокументируйте процесс, чтобы упростить себе работу. Не все инженеры обязаны знать стратегию организации по обработке недоставленных сообщений.
На такой крупной платформе информационной безопасности, как у CrowdStrike, данные должны обрабатываться в реальном времени и в огромном масштабе. К ошибкам это тоже относится. А вдруг в систему поступит сообщение с вредоносным содержимым (вроде JavaScript-эксплойта)? Тут не обойтись без обработки ошибок в реальном времени через очередь недоставленных сообщений.
Santander Bank — обновлённый почтовый сервис на основе повторных попыток и DLQ
У Santander Bank были серьёзные проблемы с синхронной обработкой больших объёмов данных в почтовом приложении. Они перестроили архитектуру и создали независимую и масштабируемую систему, которую назвали Santander Mailbox 2.0.
В основе решения лежит генерация событий на базе Apache Kafka:

Главной проблемой в новой асинхронной архитектуре на основе событий была обработка ошибок. Santander решили проблему с помощью повторных попыток и топиков Kafka c DLQ:
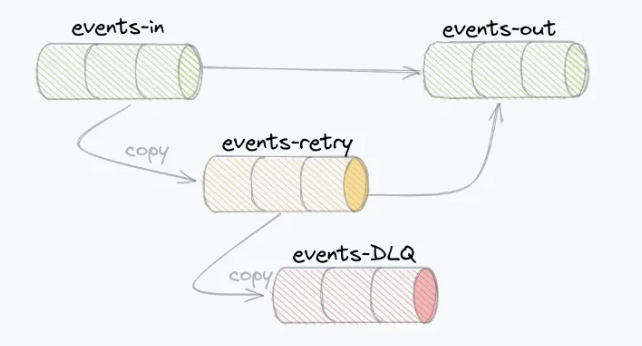
Партнер Santander по интеграции рассказал об этом на Kafka Summit.
Надёжная и масштабируемая обработка ошибок в Apache Kafka
Без механизмов обработки ошибок невозможно создать надёжные конвейеры и платформы потоковой обработки данных. Есть разные пути решения этой задачи. Например, кастомная реализация очереди недоставленных сообщений или применение уже используемых платформ, вроде Kafka Streams, Kafka Connect, платформы Spring или Parallel Consumer для Kafka.
Примеры Uber, CrowdStrike и Santander Bank показывают, что реализовать обработку ошибок не всегда просто. Нужно тщательно все обдумать с самого начала, ещё на этапе проектирования нового приложения или архитектуры. Потоковая обработка данных в реальном времени с помощью Apache Kafka принесёт пользу только в том случае, если мы будем правильно обрабатывать непредвиденное поведение. Очередь недоставленных сообщений подойдёт для многих сценариев.
Если хотите больше узнать про Kafka и прокачаться в ней, у Слёрма есть 2 курса:
— Курс «Apache Kafka База»: познакомимся с технологией, научимся настраивать распределённый отказоустойчивый кластер, отслеживать метрики, равномерно распределять нагрузку.
— Видеокурс «Apache Kafka для разработчиков». Это углублённый интенсив с практикой на Java или Golang и платформой Spring+Docker+Postgres. Интенсив даёт понимание, как организовать работу микросервисов и повысить общую надежность системы.
Купить комплектом 2 курса выгоднее на 30%: https://slurm.club/3Elhcek
