[Перевод] О том, что происходит, когда в поиске Google используют слово «vs»
Случалось у вас такое: ищете что-нибудь в Google и вводите после искомого слова «vs», надеясь на то, что поисковик автоматически предложит вам что-то, немного похожее на то, что вам нужно?
Ввод «vs» после искомого слова
Со мной такое бывало.
Как оказалось, это — большое дело. Это — приём, который, при поиске альтернативы чему-либо, способен сэкономить массу времени.
Я вижу 3 причины, по которым этот приём отлично себя показывает в том случае, если его используют для поиска сведений о технологиях, неких разработках и концепциях, в которых хотят разобраться:
- Лучший способ изучить что-то новое заключается в том, чтобы выяснить, чем это, новое, похоже на то, что уже известно, или чем новое от известного отличается. Например, в списке предложений, появляющемся после «vs», можно увидеть что-то такое, о чём можно сказать: «А, так, оказывается, то, что я ищу, похоже на это, мне уже знакомое».
- Это — простой приём. Для того чтобы им воспользоваться нужно, в буквальном смысле, несколько секунд.
- Слово «vs» — это чёткое указание, говорящее Google о том, что пользователя интересует прямое сравнение чего-то с чем-то. Тут можно воспользоваться и словом «or», но оно далеко не так сильно выражает намерение сравнить что-то с чем-то. Поэтому, если воспользоваться «or», Google выдаст список предложений, в котором более вероятно появление чего-то постороннего.
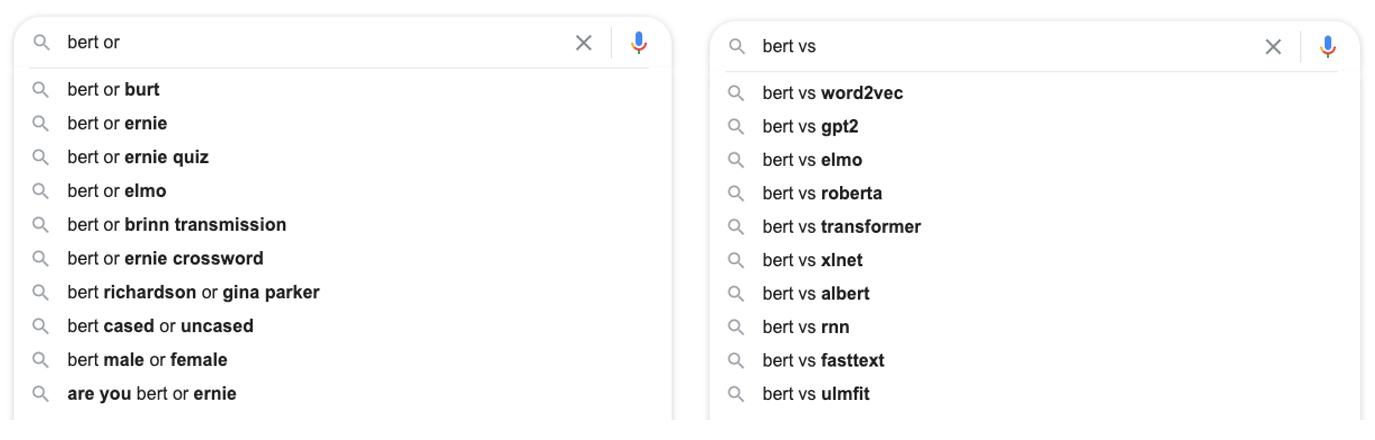
Обрабатывая запрос «bert or», Google выдаёт предложения, касающиеся «Улицы Сезам». А запрос «bert vs» даёт подсказки по Google BERT
Это заставило меня задуматься. А что если взять те слова, что Google предложил после ввода «vs», и поискать по ним, тоже добавляя после них «vs»? Что если повторить это несколько раз? Если так, можно получить симпатичный сетевой граф связанных запросов.
Например, он может выглядеть так.
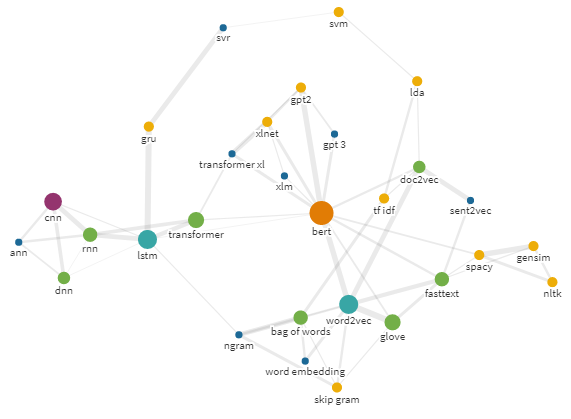
Эго-граф для запроса bert с радиусом 25
Это — весьма полезная методика создания ментальных карт технологий, разработок или идей, отражающих взаимосвязь подобных сущностей.
Расскажу о том, как строить такие графы.
Автоматизация сбора «vs»-данных из Google
Вот ссылка, которую можно использовать для того чтобы получить от Google предложения по автозавершению запроса в формате XML. Эта возможность не выглядит как API, предназначенный для широкого использования, поэтому, вероятно, не стоит слишком сильно налегать на эту ссылку.
http://suggestqueries.google.com/complete/search?&output=toolbar&gl=us&hl=en&q=
URL-параметр output=toolbar указывает на то, что нас интересуют результаты в формате XML, gl=us задаёт код страны, hl=en позволяет указать язык, а конструкция q= — это как раз то, для чего нужно получить результаты автозавершения.
Для параметров gl и hl используются стандартные двухбуквенные идентификаторы стран и языков.
Давайте со всем этим поэкспериментируем, начав поиск, скажем, с запроса tensorflow.
Первый шаг работы заключается в том, чтобы обратиться по указанному URL, воспользовавшись следующей конструкцией, описывающей запрос: q=tensorflow%20vs%20. Вся ссылка при этом будет выглядеть так:
http://suggestqueries.google.com/complete/search?&output=toolbar&gl=us&hl=en&q=tensorflow%20vs%20
В ответ мы получим XML-данные.
Что делать с XML?
Теперь нужно проверить полученные результаты автозавершения на соответствие некоему набору критериев. С теми, которые нам подойдут, мы продолжим работу.

Проверка полученных результатов
Я, при проверке результатов, пользовался следующими критериями:
- Рекомендованный поисковый запрос не должен содержать текст исходного запроса (то есть —
tensorflow). - Рекомендация не должна включать в себя запросы, которые были признаны подходящими ранее (например —
pytorch). - Рекомендация не должна включать в себя несколько слов «vs».
- После того, как найдено 5 подходящих поисковых запросов, все остальные уже не рассматриваются.
Это — лишь один из способов «очистки» полученного от Google списка рекомендаций по автозавершению поискового запроса. Я, кроме того, иногда вижу пользу в том, чтобы выбирать из списка только рекомендации, состоящие исключительно из одного слова, но использование этого приёма зависит от каждой конкретной ситуации.
Итак, используя этот набор критериев, мы получили 5 следующих результатов, каждому из которых присвоен определённый вес.
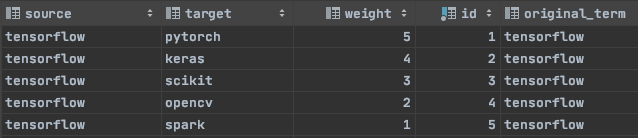
5 результатов
Следующая итерация
Затем эти 5 найденных рекомендаций подвергают такой же обработке, какой был подвергнут исходный поисковый запрос. Их передают API с использованием слова «vs» и опять выбирают 5 результатов автозавершения, соответствующих вышеозначенным критериям. Вот результат такой обработки вышеприведённого списка.

Поиск результатов автозавершения для уже найденных слов
Этот процесс можно продолжать, изучая ещё не исследованные слова из столбца target.
Если провести достаточно много итераций подобного поиска слов, получится довольно большая таблица, содержащая сведения о запросах и о весах. Эти данные хорошо подходят для визуализации в виде графа.
Эго-графы
Сетевой граф, который я вам показывал в начале статьи, это — так называемый эго-граф (ego graph), построенный, в нашем случае, для запроса tensorflow. Эго-граф — это такой граф, все узлы которого находятся на каком-то расстоянии от узла tensorflow. Это расстояние не должно превышать заданного расстояния.
А как определяется расстояние между узлами?
Давайте сначала посмотрим на готовый граф.

Эго-граф для запроса tensorflow с радиусом 22
Вес ребра (weight), соединяющего запрос A и B, мы уже знаем. Это — ранг рекомендации из списка автозавершения, изменяющийся от 1 до 5. Для того чтобы сделать граф неориентированным, можно просто сложить веса связей между вершинами, идущими в двух направлениях (то есть — от A к B, и, если такая связь есть, от B к A). Это даст нам веса рёбер в диапазоне от 1 до 10.
Длина ребра (distance), таким образом, будет вычисляться по формуле 11 — вес ребра. Мы выбрали здесь число 11 из-за того, что максимальный вес ребра — 10 (ребро будет иметь такой вес в том случае, если обе рекомендации появляются на самом верху списков автозавершения друг для друга). В результате минимальным расстоянием между запросами будет 1.
Размер (size) и цвет (color) вершины графа определяется количеством (count) случаев, в которых соответствующий запрос появляется в списке рекомендаций. В результате получается, что чем больше вершина — тем важнее представляемая ей концепция.
Рассматриваемый эго-граф имеет радиус (radius) 22. Это означает, что добраться до каждого запроса, начиная с вершины tensorflow, можно, пройдя расстояние, не превышающее 22. Взглянем на то, что произойдёт, если увеличить радиус графа до 50.

Эго-граф для запроса tensorflow с радиусом 50
Интересно получилось! Этот граф содержит большинство базовых технологий, о которых надо знать тем, кто занимается искусственным интеллектом. При этом названия этих технологий логически сгруппированы.
И всё это построено на основе одного единственного ключевого слова.
Как рисовать подобные графы?
Я, для рисования такого графа, использовал онлайн-инструмент Flourish.
Этот сервис позволяет строить сетевые графики и другие диаграммы с помощью простого интерфейса. Полагаю, на него вполне стоит взглянуть тем, кого интересует построение эго-графов.
Как создать эго-граф с заданным радиусом?
Для создания эго-графа с заданным радиусом можно воспользоваться Python-пакетом networkx. В нём есть очень удобная функция ego_graph. Радиус графа указывают при вызове этой функции.
import networkx as nx
#Формат исходных данных
#nodes = [('tensorflow', {'count': 13}),
# ('pytorch', {'count': 6}),
# ('keras', {'count': 6}),
# ('scikit', {'count': 2}),
# ('opencv', {'count': 5}),
# ('spark', {'count': 13}), ...]
#edges = [('pytorch', 'tensorflow', {'weight': 10, 'distance': 1}),
# ('keras', 'tensorflow', {'weight': 9, 'distance': 2}),
# ('scikit', 'tensorflow', {'weight': 8, 'distance': 3}),
# ('opencv', 'tensorflow', {'weight': 7, 'distance': 4}),
# ('spark', 'tensorflow', {'weight': 1, 'distance': 10}), ...]
#Построить исходный полный граф
G=nx.Graph()
G.add_nodes_from(nodes)
G.add_edges_from(edges)
#Построить эго-граф для 'tensorflow'
EG = nx.ego_graph(G, 'tensorflow', distance = 'distance', radius = 22)
#Найти двусвязные подграфы
subgraphs = nx.algorithms.connectivity.edge_kcomponents.k_edge_subgraphs(EG, k = 3)
#Получить подграф, содержащий 'tensorflow'
for s in subgraphs:
if 'tensorflow' in s:
break
pruned_EG = EG.subgraph(s)
ego_nodes = pruned_EG.nodes()
ego_edges = pruned_EG.edges()
Я, кроме того, воспользовался тут ещё одной функцией — k_edge_subgraphs. Она применяется для удаления некоторых результатов, которые не соответствуют нашим нуждам.
Например, storm — это опенсорсный фреймворк для распределённых вычислений в реальном времени. Но это — ещё и персонаж из вселенной Marvel. Как вы думаете, какие поисковые подсказки «победят», если ввести в Google запрос «storm vs»?
Функция k_edge_subgraphs находит группы вершин, которые невозможно разделить, выполнив k или меньшее число действий. Как оказалось, тут хорошо показывают себя значения параметров k=2 и k=3. Остаются, в итоге, только те подграфы, которым принадлежит tensorflow. Это позволяет обеспечить то, что мы не слишком удаляемся от того, с чего начали поиск, и не уходим в слишком далёкие области.
Использование эго-графов в жизни
Давайте отойдём от примера с tensorflow и рассмотрим другой эго-граф. В этот раз — граф, посвящённый ещё кое-чему такому, что меня интересует. Это — шахматный дебют, получивший название «Испанская партия» (Ruy Lopez chess opening).
▍Исследование шахматных дебютов

Исследование «Испанской партии» (ruy lopez)
Наша методика позволила быстро обнаружить самые распространённые идеи дебютов, что может помочь исследователю шахмат.
Теперь давайте рассмотрим другие примеры использования эго-графов.
▍Здоровое питание
Капуста! Вкуснятина!
Но что если у вас возникло желание заменить прекрасную, несравненную капусту на что-то другое? Вам в этом поможет эго-граф, построенный вокруг капусты (kale).
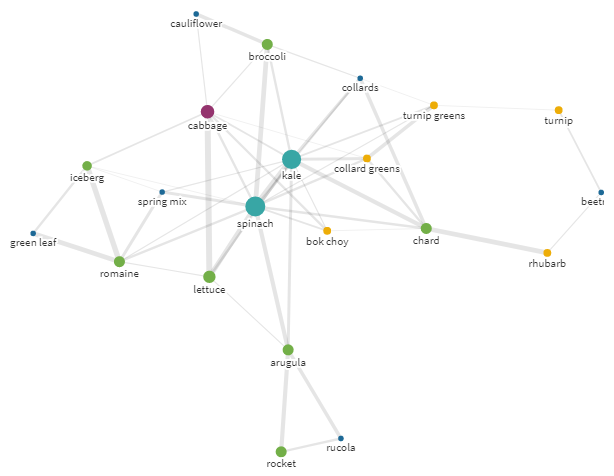
Эго-граф для запроса kale с радиусом 25
▍Покупаем собаку
Собак так много, а времени так мало… Мне нужна собака. Но какая? Может — что-то вроде пуделя (poodle)?
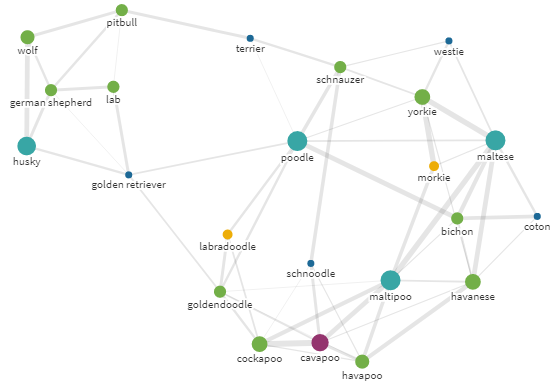
Эго-граф для запроса poodle с радиусом 18
▍Ищем любовь
Собака и капуста ничего не меняют? Нужно найти свою вторую половину? Если так — вот маленький, но весьма самодостаточный эго-граф, который может в этом помочь.

Эго-граф для запроса coffee meets bagel с радиусом 18
▍Что делать, если приложения для знакомств ничем не помогли?
Если приложения для знакомств оказались бесполезными, стоит, вместо того, чтобы в них зависать, посмотреть сериал, запасшись мороженым со вкусом капусты (или со вкусом недавно обнаруженной рукколы). Если вам нравится сериал «The Office» (безусловно, тот, что снят в Великобритании), то вам могут понравиться и некоторые другие сериалы.

Эго-граф для запроса the office с радиусом 25
Итоги
На этом я завершаю рассказ об использовании слова «vs» в поиске Google и об эго-графах. Надеюсь, вам всё это хотя бы немного поможет в поиске любви, хорошей собаки и здоровой еды.
Пользуетесь ли вы какими-нибудь необычными приёмами при поиске в интернете?


