[Перевод] Нейросеть для определения лиц, встроенная в смартфон
 Apple начала использовать глубинное обучение для определения лиц начиная с iOS 10. С выпуском фреймворка Vision разработчики теперь могут использовать в своих приложениях эту технологию и многие другие алгоритмы машинного зрения. При разработке фреймворка пришлось преодолеть значительные проблемы, чтобы сохранить приватность пользователей и эффективно работать на железе мобильного устройства. В статье обсуждаются эти проблемы и описывается, как работает алгоритм.
Apple начала использовать глубинное обучение для определения лиц начиная с iOS 10. С выпуском фреймворка Vision разработчики теперь могут использовать в своих приложениях эту технологию и многие другие алгоритмы машинного зрения. При разработке фреймворка пришлось преодолеть значительные проблемы, чтобы сохранить приватность пользователей и эффективно работать на железе мобильного устройства. В статье обсуждаются эти проблемы и описывается, как работает алгоритм.
Введение
Впервые определение лиц в публичных API появилось во фреймворке Core Image через класс CIDetector. Эти API работали и в собственных приложениях Apple, таких как Photos. Самая первая версия CIDetector использовала для определения метод на базе алгоритма Виолы — Джонса [1]. Последовательные улучшения CIDetector были основаны на достижениях традиционного машинного зрения.
С появлением глубинного обучения и его применения к проблемам машинного зрения точность систем определения лиц сделала значительный шаг вперёд. Нам пришлось полностью переосмыслить наш подход, чтобы извлечь выгоду из этой смены парадигмы. По сравнению с традиционным машинным зрением модели в глубинном обучении требуют на порядок больше памяти, намного больше дискового пространства и больше вычислительных ресурсов.
По состоянию на сегодняшний день типичный высокопроизводительный смартфон — не жизнеспособная платформа для моделей зрения с глубинным обучением. Большинство игроков в индустрии обходят это ограничение применяя облачные API. Там картинки отправляются для анализа на сервер, где система глубинного обучения выдаёт результат в определении лиц. В облачных сервисах обычно работают мощные десктопные GPU с большим объёмом доступной памяти. Очень большие сетевые модели, а потенциально и целые ансамбли больших моделей могут работать на серверной стороне, позволяя клиентам (в том числе мобильным телефонам) использовать преимущества крупных архитектур глубинного обучения, которые нереально запустить локально.
Apple iCloud Photo Library — облачное решение для хранения фото и видео. Каждое фото и видео перед отправкой в iCloud Photo Library шифруется на устройстве и может быть расшифровано только на устройстве с соответствующим аккаунтом iCloud. Поэтому для работы систем машинного зрения на глубинном обучении нам пришлось внедрять алгоритмы непосредственно в iPhone.
Здесь предстояло решить несколько задач. Модели глубинного обучения приходится поставлять в составе операционной системы, занимая ценное пространство NAND. Их нужно загружать в оперативную память и отнимать значительные вычислительные ресурсы GPU и/или CPU. В отличие от облачных сервисов, где ресурсы можно выделить исключительно для задач машинного зрения, на устройстве вычисления делят системные ресурсы с другими работающими приложениями. Наконец, вычисления должны быть достаточно эффективными для обработки большой коллекции фотографий Photos в разумное время, но без значительного энергопотребления или нагрева.
В остальной части статьи обсуждается наш подход к использованию алгоритмов для определения лиц в системе глубинного обучения и как нам успешно удалось преодолеть сложности, чтобы достичь максимальной точности определения. Мы обсудим:
- как мы полностью использовали наши GPU и CPU (с помощью BNNS и Metal);
- оптимизации памяти для вывода нейросети, загрузки изображений и кэширования;
- как мы реализовали нейросеть таким образом, чтобы не мешать работе множеству других одновременно выполняемых задач на iPhone.
Переход от метода Виолы — Джонса к глубинному обучению
Когда мы начали работать над глубинным обучением для определения лиц в 2014 году, глубокие свёрточные нейросети (ГСНС) только начали показывать многообещающие результаты в задачах обнаружения объектов. Наиболее известным среди всех была модель OverFeat [2], которая продемонстрировала некоторые простые идеи и показала, что ГСНС достаточно эффективны в обнаружении объектов на изображениях.
Модель OverFeat выводила соответствие между полностью соединённым слоями нейросети и свёрточными слоями с валидными свёртками фильтров в тех же пространственных измерениях, что и входные данные. Эта работа наглядно показала, что сеть бинарной классификации с фиксированным рецептивным полем (например, 32×32 с естественным шагом в 16 пикселей) может потенциально использоваться для изображений произвольного размера (например, 320×320) и производить карту соответствующего размера на выходе (в данном примере 20×20). Научная статья с описанием OverFeat также содержала чёткие рецепты, как производить более плотные выходные карты, эффективно уменьшая шаг нейросети.
Мы изначально основали архитектуру на некоторых идеях из статьи по OverFeat, результатом чего стала полностью свёрточная сеть (см. рис. 1) с многозадачной целью:
- бинарная классификация для предсказания присутствия или отсутствия лица во входных данных;
- регрессия для предсказания параметров ограничивающего прямоугольника, который наилучшим образом локализует лицо во входных данных.
Мы экспериментировали с разными вариантами обучения такой нейросети. Например, простая процедура обучения заключалась в создании большого набора данных с тайлами изображений фиксированного размера, который соответствовал минимальному валидному размеру входных данных, так что каждый тайл генерировал один результат на выходе нейросети. Набор данных для обучения идеально сбалансирован, так что на половине тайлов есть лицо (положительный класс), а на другой половине нет (отрицательный класс). Для каждого положительного тайла указывались истинные координаты (x, y, w, h) лица. Мы обучили нейросеть оптимизироваться для описанной выше многозадачной цели. После обучения нейросеть научилась предсказывать наличие лица на изображении и в случае положительного ответа выдавала координаты и масштаб лица в кадре.
Рис. 1. Усовершенствованная архитектура ГСНС для определения лиц
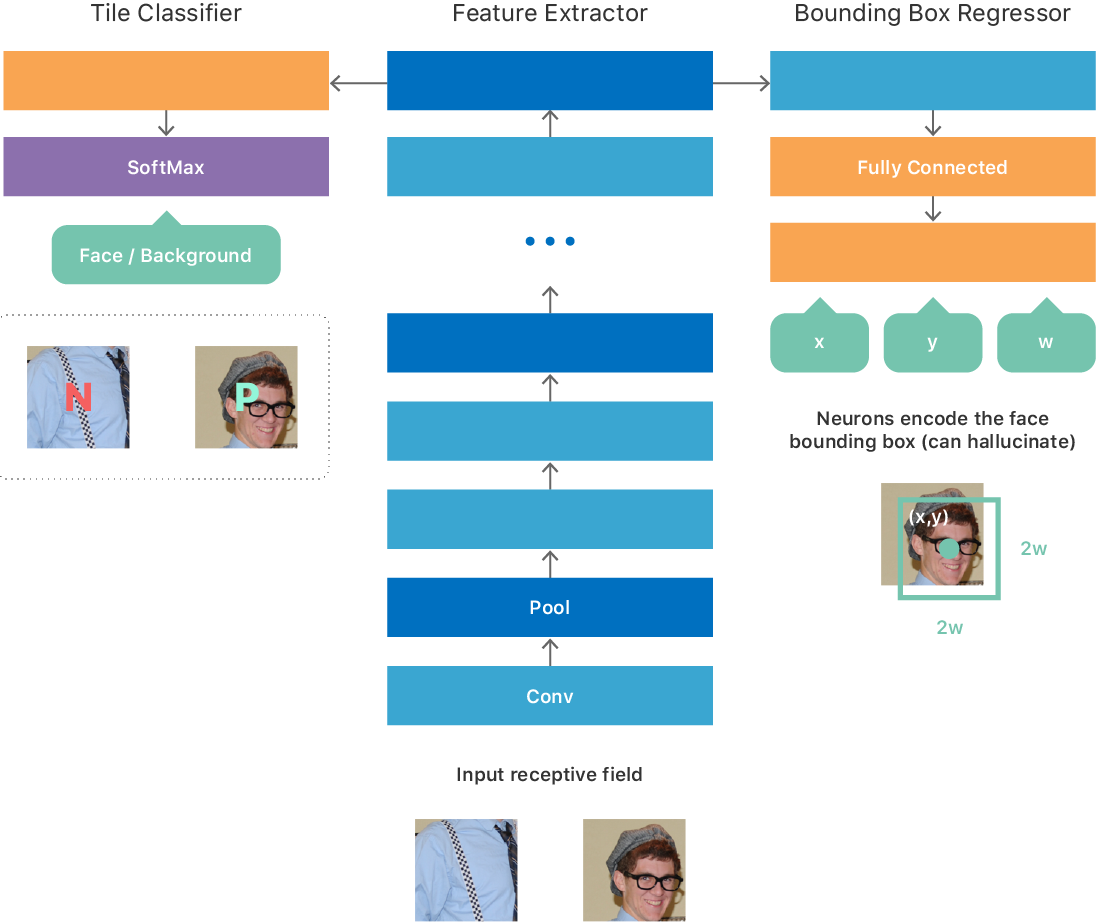
Поскольку сеть полностью свёрточная, она может эффективно обработать изображение произвольного размера и сделать выходную карту 2D. Каждая точка на карте соответствует тайлу входного изображения и содержит предсказание нейросети относительно присутствия или отсутствия лица на этом тайле, а также его местоположение/масштаб (см. вход и выход ГСНС на рис. 1).
С такой нейросетью можно построить довольно стандартный конвейер обработки для определения лиц. Он состоит из многомасштабной пирамиды изображений, нейросети определения лиц и модуля постобработки. Многомасштабная пирамида требуется, чтобы обрабатывать лица всех размеров. Нейросеть применяется на каждом уровне пирамиды, откуда извлекаются кандидаты на распознавание (см. рис. 2). Модуль постобработки затем объединяет кандидатов со всех масштабов для выдачи списка ограничивающих рамок, которые соответствуют окончательному предсказанию нейросети по лицам на изображении.
Рис. 2. Процесс определения лиц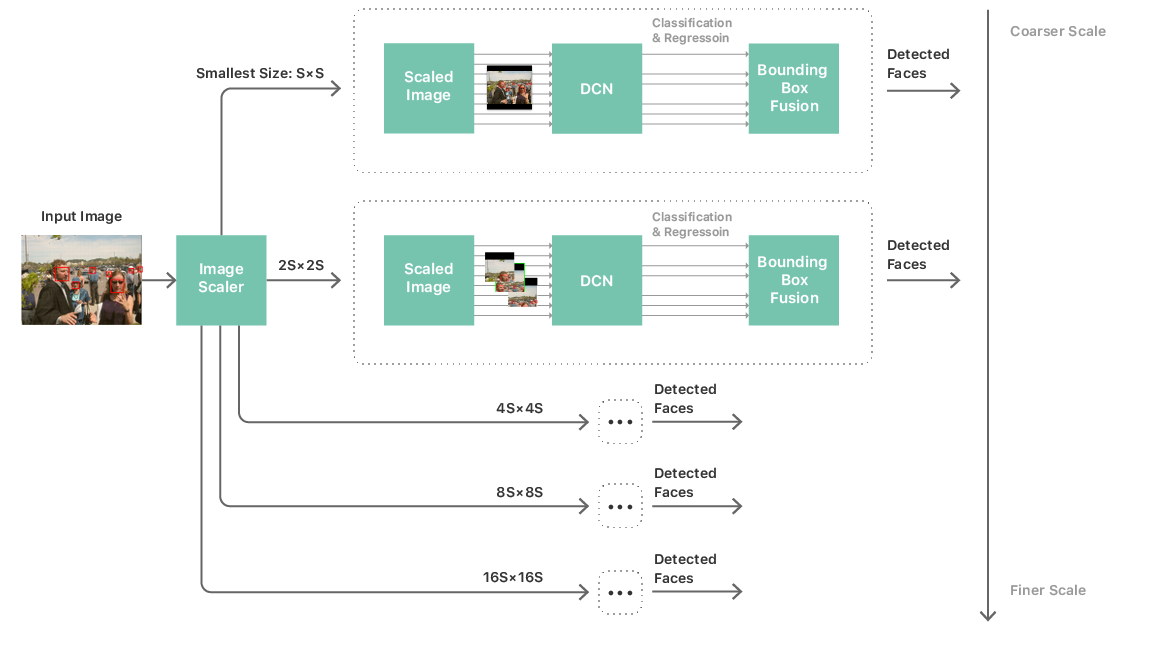
Такая стратегия сделала более реальной запуск глубинной свёрточной нейросети и полное сканирование изображения на мобильном железе. Но сложность и размер нейросети оставались основными узкими местами в производительности. Решить эту проблему означало не только ограничить нейросеть простой топологией, но и ограничить количество слоёв, количество каналов на слой и размер ядра свёрточных фильтров. Эти ограничения подняли важную проблему: наши нейросети, которые обеспечивали приемлемую точность, далеки от простоты: в большинстве из них больше 20-ти слоёв плюс несколько модулей типа сеть-в-сети [3]. Использование таких сетей в описанном выше фреймворке сканирования изображений абсолютно невозможно из-за неприемлемой производительности и энергопотребления. На самом деле мы даже не сможем загрузить нейросеть в память. Задача сводится к тому, как обучить простую и компактную нейросеть, способную имитировать поведение точных, но очень сложных сетей.
Мы решили использовать подход, неформально известный как обучение «учитель-ученик» [4]. Такой подход предоставляет механизм для обучения второй тонкой-и-глубокой нейросети («ученик»), так что она очень близко соответствует выходным результатам большой сложной нейросети («учитель»), которую мы обучали как описано выше. Нейросеть-ученик состоит из простой повторяющейся структуры конволюций 3×3 и слоёв подвыборки, а её архитектура адаптирована для максимального использования нашего движка вывода нейросети (см. рис. 1).
Теперь наконец-то у нас есть алгоритм глубокой нейросети определения лиц, пригодный для запуска на мобильном железе. Мы повторили несколько циклов обучения и получили модель нейросети достаточно точную для выполнения поставленных задач. Хотя эта модель точна и способна работать на мобильном устройстве, остался ещё огромный объём работы, чтобы на практике сделать возможным развёртывание модели на миллионах пользовательских устройств.
Оптимизация конвейера обработки изображений
Практические соображения по поводу глубинного обучения в значительной степени повлияли на выбор архитектуры простой в использовании платформы для разработчиков, которую мы называем Vision. Вскоре стало очевидно, что для создания отличного фреймворка недостаточно только отличных алгоритмов. Пришлось сильно оптимизировать конвейер обработки изображений.
Мы не хотели, чтобы разработчики думали о масштабировании, преобразовании цветов или источниках изображений. Определение лиц должно хорошо работать независимо от того, используется ли поток из камеры в реальном времени, видеообработка, файлы с диска или из веба. Оно должно работать независимо от вида и формата картинки.
Нас беспокоили энергопотребление и использование памяти, особенно в процессе стриминга и захвата изображения. Потребление памяти беспокоило нас в том числе в случае обработки 64-мегапиксельных панорам. Мы решили эти проблемы используя декодирование с частичной субдискретизацией и автоматический тайлинг. Это позволило запускать задачи машинного зрения на больших изображениях даже с нестандартным соотношением сторон.
Ещё одной проблемой стало соответствие цветовых пространств. У Apple широкий набор API, но мы не хотели загружать разработчиков работой по выбору цветового пространства. Это берёт на себя фреймворк Vision, таким образом понижая порог вхождения для успешного внедрения машинного зрения в любое приложение.
Vision также оптимизирован путём эффективного повторного использования и обработки промежуточных звеньев. Определение лиц, определение координат лиц и некоторые другие задачи компьютерного зрения — все они работают на одном скалированном промежуточном изображении. Абстрагируя интерфейс до уровня алгоритмов и найдя оптимальное место для обработки изображения или буфера, Vision способен создавать и кэшировать промежуточные изображения — так улучшается производительность разнообразных задач компьютерного зрения даже без вмешательства разработчика.
Обратное тоже верно. С перспективы центрального интерфейса мы можем направить разработку алгоритма в таком направлении, чтобы оптимизировать повторное или совместное использование промежуточных данных. В Vision реализовано несколько разных и независимых алгоритмов машинного зрения. Чтобы разные алгоритмы хорошо работали вместе, они совместно используют одинаковые входные разрешения и цветовые пространства где только возможно.
Оптимизация производительности для мобильного железа
Удовольствие простого в использовании фреймворка быстро улетучится, если API для определения лиц не способен работать в реальном времени или в фоновых системных процессах. Пользователи ожидают, что определение лиц работает автоматически и незаметно во время обработки фотоальбомов или срабатывает немедленно после съёмки кадра. Они не хотят, чтобы из-за этого уменьшался заряд батареи или тормозила система. Мобильные устройства Apple работают в многозадачном режиме. Поэтому фоновый процесс машинного зрения не должен значительно влиять на остальные системные функции.
Мы реализовали несколько стратегий для уменьшения потребления памяти и использования GPU. Для уменьшения использования памяти мы выделяем промежуточные слои наших нейросетей, анализируя вычислительный граф. Это позволяет присвоить несколько слоёв одному буферу. Будучи полностью детерминированной, такая техника тем не менее снижает потребление памяти не влияя на производительность или фрагментацию в памяти, и её можно применять как для CPU, так и для GPU.
Детектор Vision работает с пятью нейросетями (по одной для каждого уровня разномасштабной пирамиды, как показано на рис. 2). Для этих пяти нейросетей указываются общие веса и параметры, но у них разный формат входных и выходных данных и промежуточных слоёв. Для ещё большего снижения потребления памяти мы запускаем алгоритм оптимизации памяти на совместном графе, составленном пятью этими сетями, что значительно уменьшает потребление памяти. Также все нейросети вместе используют одни и те же буфера с весами и параметрами, опять же уменьшая количество выделяемой памяти.
Для достижения лучшей производительности мы используем полностью свёрточную природу нейросети: все масштабы динамически меняются для соответствия разрешению входного изображения. По сравнению с альтернативным подходом — подгонкой изображения под квадратную сетку нейросети (проложенную пустыми полосами) — подгонка нейросети под размер изображения позволяет кардинально уменьшить общее количество операций. Поскольку в результате такой перекройки не меняется топологий операций и благодаря высокой производительности остальной части распределителя динамическое изменение формы не потребляет больше ресурсов, чем аллокация.
Чтобы гарантировать интерактивность и отсутствие подтормаживаний UI во время работы глубинной нейросети в фоновом процессе, мы разделили рабочие задания для GPU для каждого слоя нейросети, чтобы каждое задание выполнялось не дольше одной миллисекунды. Это позволяет драйверу менять контексты, вовремя выделяя ресурсы для задач с более высоким приоритетом, таких как анимация UI, что сокращает, а иногда полностью исключает выпадение кадров.
Все вместе эти стратегии гарантируют, что пользователю понравится локальная работа машинного зрения с низкой задержкой и в приватном режиме, хотя он даже не знает, что нейросети на смартфоне ежесекундно выполняют несколько сотен миллиардов операций с плавающей запятой.
Использование фреймворка Vision
Удалось ли нам достичь поставленной цели и разработать высокопроизводительный, простой в использовании API для определения лиц? Можете попробовать фреймворк Vision и сами решить. Вот ресурсы для начала:
- Презентация с WWDC: «Фреймворк Vision: разработка на Core ML»
- Справка по фреймворку Vision
- Руководство «Core ML и Vision: машинное обучение в iOS 11» [5]
Литература
[1] Viola, P., Jones, M.J. Robust Real-time Object Detection Using a Boosted Cascade of Simple Features. Опубликовано в Proceedings of the Computer Vision and Pattern Recognition Conference, 2001. ↑
[2] Sermanet, Pierre, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, Yann LeCun. OverFeat: Integrated Recognition, Localization and Detection Using Convolutional Networks. arXiv:1312.6229 [Cs], декабрь 2013-го. ↑
[3] Lin, Min, Qiang Chen, Shuicheng Yan. Network In Network. arXiv:1312.4400 [Cs], декабрь 2013-го. ↑
[4] Romero, Adriana, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, Yoshua Bengio. FitNets: Hints for Thin Deep Nets. arXiv:1412.6550 [Cs], декабрь 2014-го. ↑
[5] Tam, A. Core ML and Vision: Machine learning in iOS Tutorial. Получено с www.raywenderlich.com, сентябрь 2017-го. ↑
