[Перевод] Модели угроз в дифференциальной приватности

Это перевод второй статьи из серии публикаций по дифференциальной приватности.
На прошлой неделе, в первой статье цикла — «Дифференциальная приватность — анализ данных с сохранением конфиденциальности (введение в серию)» — мы рассмотрели базовые концепции и случаи применения дифференциальной приватности. Сегодня же мы рассмотрим возможные варианты построения систем в зависимости от ожидаемой модели угроз.
Развёртывание системы, удовлетворяющей принципам дифференциальной приватности, — нетривиальная задача. В качестве примера, в нашей следующей публикации мы рассмотрим простую программу на Python, реализующую добавление шума по Лапласу прямо в функции, обрабатывающей чувствительные данные. Но для того, чтобы это заработало, нам необходимо собрать все требуемые данные на одном сервере.
А что, если сервер хакнут? В этом случае дифференциальная приватность нам не поможет, ведь она защищает только данные, полученные в результате работы программы!
При развёртывании систем на основе принципов дифференциальной приватности важно учитывать модель угроз: от каких противников мы хотим защитить систему. Если эта модель включает в себя злоумышленников, способных целиком скомпрометировать сервер с конфиденциальными данными, то нам нужно изменить систему так, чтобы она противостояла подобным атакам.
То есть архитектуры систем, соблюдающих дифференциальную приватность, должны учитывать и приватность, и безопасность. Приватность контролирует то, что можно извлечь из возвращенных системой данных. А безопасность можно считать противоположной задачей: это контроль за доступом к части данных, но она не даёт никаких гарантий касательно их содержания.
Центральная модель дифференциальной приватности
Наиболее часто используемая модель угроз в работах по дифференциальной приватности — центральная модель дифференциальной приватности (или просто «центральная дифференциальная приватность»).
Главный компонент — доверенное хранилище данных (trusted data curator). Каждый источник передаёт ему свои конфиденциальные данные, а оно собирает их в одном месте (например, на сервере). Хранилище является доверенным, если мы предполагаем, что оно обрабатывает наши чувствительные данные самостоятельно, никому их не передает и не может быть никем скомпрометировано. Иными словами, мы считаем, что сервер с конфиденциальными данными не может быть взломан.
В рамках центральной модели мы обычно добавляем шум к ответам на запросы (реализацию с механизмом Лапласа мы рассмотрим в следующей статье). Преимуществом этой модели является возможность добавить минимально возможное значение шума, таким образом сохранив максимальную точность, допустимую по принципам дифференциальной приватности. Ниже показана схема процесса. Мы поместили «барьер приватности» между доверенным хранилищем данных и аналитиком так, чтобы вовне могли попасть только результаты, удовлетворяющие заданным условиям дифференциальной приватности. Таким образом, аналитик не обязан быть доверенным.
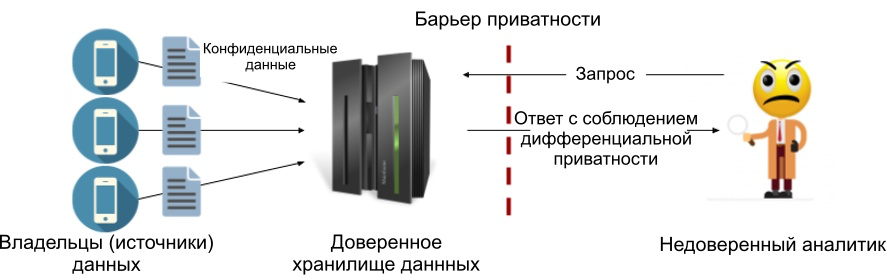
Рисунок 1: Центральная модель дифференциальной приватности.
Недостаток центральной модели в том, что она требует наличия именно доверенного хранилища, а многие из них на самом деле таковыми не являются. На самом деле отсутствие доверия к потребителю данных обычно является главной причиной для использования принципов дифференциальной приватности.
Локальная модель дифференциальной приватности
Локальная модель дифференциальной приватности позволяет избавиться от доверенного хранилища данных: каждый источник (или владелец данных) сам добавляет шум в свои данные, прежде чем передать их в хранилище. Это значит, что в хранилище никогда не окажется чувствительной информации, а значит и нет необходимости в его доверенности. Рисунок ниже демонстрирует устройство локальной модели: в ней барьер приватности находится между каждым владельцем данных и хранилищем (которое может быть как доверенным, так и нет).
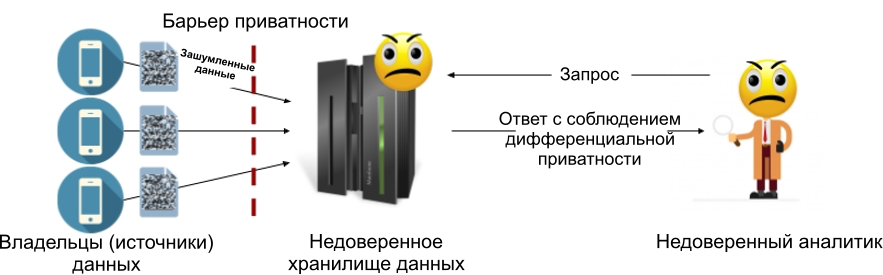
Рисунок 2: Локальная модель дифференциальной приватности.
Локальная модель дифференциальной приватности позволяет избежать основной проблемы центральной модели: если хранилище данных будет взломано, то хакеры получат доступ только к зашумленным данным, которые уже соответствуют требованиям дифференциальной приватности. Это основная причина, из-за которой локальная модель была выбрана для таких систем, как Google RAPPOR [1] и система сбора данных Apple [2].
Обратная сторона медали? Локальная модель предоставляет меньшую точность, чем центральная. В локальной модели каждый источник самостоятельно добавляет шум, чтобы удовлетворять собственным условиям дифференциальной приватности, так что суммарный шум от всех участников намного больше шума в центральной модели.
В конечном счете, такой подход оправдан только для запросов с очень стойким трендом (сигналом). Apple, например, использует локальную модель для оценки популярности эмодзи, но результат оказывается полезен только для наиболее популярных эмодзи (где тренд наиболее выраженный). Обычно эту модель не применяют для более сложных запросов, вроде тех, что используются в Бюро переписи США [10] или машинном обучении.
Гибридные модели
Центральная и локальная модели имеют как преимущества, так и недостатки, и сейчас основные усилия направлены на то, чтобы взять у них всё самое лучшее.
Например, можно использовать модель с перемешивателем (shuffling model), реализованную в системе Prochlo [4]. Она содержит недоверенное хранилище данных, много отдельных владельцев данных и несколько частично доверенных перемешивателей. Каждый источник сначала добавляет небольшое количество шума в свои данные, а затем отправляет их перемешивателю, который добавляет еще шума перед отправкой в хранилище данных. Суть в том, что перемешиватели вряд ли «вступят в сговор» (или будут взломаны одновременно) с хранилищем данных или друг с другом, так что небольшого шума, добавленного источниками, будет достаточно для гарантии приватности. Каждый перемешиватель может работать с несколькими источниками, как и в центральной модели, так что небольшое количество его шума будет гарантировать приватность и для результирующего массива данных.
Модель с перемешивателем является компромиссом между локальной и центральной моделями: она позволяет добавить меньше шума, чем локальная, но больше, чем центральная.
Также можно комбинировать дифференциальную приватность с криптографией, как в проколе конфиденциального вычисления (secure multiparty computation, MPC) или в полностью гомоморфном шифровании (fully homomorphic encryption, FHE). FHE позволяет выполнять вычисления с зашифрованными данными без их предварительной расшифровки, а MPC позволяет группе участников безопасно выполнять запросы по распределённым источникам без раскрытия их данных. Вычисление дифференциально приватных функций с помощью криптобезопасных (или просто безопасных) вычислений — многообещающий путь по достижению точности центральной модели со всеми преимуществами локальной. Причем в этом случае использование безопасных вычислений снимает необходимость иметь доверенное хранилище. Недавние работы [5] демонстрируют обнадеживающие результаты от комбинирования MPC и дифференциальной приватности, вбирая в себя большинство достоинств обоих подходов. Правда, в большинстве случаев безопасные вычисления на несколько порядков медленнее, чем локально выполненные, что особенно важно для больших массивов данных или сложных запросов. Сейчас безопасные вычисления находятся в активной фазе разработки, так что их производительность стремительно возрастает.
А дальше?
В следующей статье мы взглянем на наш первый open-source инструмент для применения концепций дифференциальной приватности на практике. Посмотрим и на другие инструменты, как доступные новичкам, так и применимые для очень больших баз данных, таких как у Бюро переписи США. Будем пробовать подсчитать данные по населению с соблюдением принципов дифференциальной приватности.
Подписывайтесь на наш блог и не пропустите перевод следующей статьи. Уже совсем скоро.
Источники
[1] Erlingsson, Úlfar, Vasyl Pihur, and Aleksandra Korolova. «Rappor: Randomized aggregatable privacy-preserving ordinal response.» In Proceedings of the 2014 ACM SIGSAC conference on computer and communications security, pp. 1054–1067. 2014.
[2] Apple Inc. «Apple Differential Privacy Technical Overview.» Accessed 7/31/2020. https://www.apple.com/privacy/docs/Differential_Privacy_Overview.pdf
[3] Garfinkel, Simson L., John M. Abowd, and Sarah Powazek. «Issues encountered deploying differential privacy.» In Proceedings of the 2018 Workshop on Privacy in the Electronic Society, pp. 133–137. 2018.
[4] Bittau, Andrea, Úlfar Erlingsson, Petros Maniatis, Ilya Mironov, Ananth Raghunathan, David Lie, Mitch Rudominer, Ushasree Kode, Julien Tinnes, and Bernhard Seefeld. «Prochlo: Strong privacy for analytics in the crowd.» In Proceedings of the 26th Symposium on Operating Systems Principles, pp. 441–459. 2017.
[5] Roy Chowdhury, Amrita, Chenghong Wang, Xi He, Ashwin Machanavajjhala, and Somesh Jha. «Cryptε: Crypto-Assisted Differential Privacy on Untrusted Servers.» In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, pp. 603–619. 2020.
