PostgreSQL Antipatterns: работаем с отрезками в «кровавом энтерпрайзе»
В различных бизнес-приложениях регулярно возникает необходимость решить какую-либо задачу с отрезками/интервалами. Самое сложное в них — понять, что это именно одна из таких задач.

Как правило, они отчаянно маскируются, и даже у нас в СБИС их найти можно в абсолютно разных сферах управления предприятием: контроле рабочего времени, оценке загрузки линий АТС или даже в бухгалтерском учете.
«Отличие enterprise [решения] от всего остального — он всегда идёт от запросов бизнеса и решает какую-то бизнес-задачу.» [src]
Вот и давайте посмотрим, какие именно прикладные задачи и как можно решить с помощью PostgreSQL и сократить время анализа данных с нескольких секунд на бизнес-логике до десятков миллисекунд, умея эффективно применять следующие алгоритмы непосредственно внутри SQL-запроса:
- поиск отрезков, пересекающих точку/интервал
- слияние отрезков по максимальному перекрытию
- подсчет количества отрезков в каждой точке
Отрезки в точке
Начнем наши исследования с самой простой задачи — обнаружения отрезков, пересекающих конкретную точку. В бизнес-задачах, как правило, такие отрезки имеют какой-то временной характер — то есть границами являются или date, или timestamp.
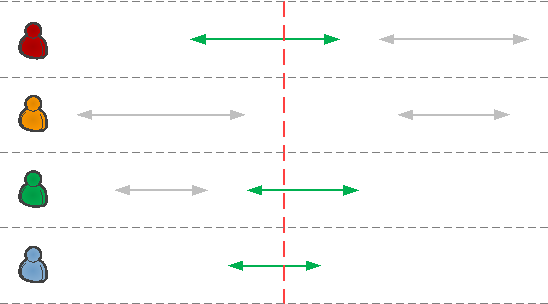
Типичная бизнес-задача: «кто из сотрудников был на больничном в прошлый понедельник?», «можно ли сейчас уйти на обед?» или даже «кто из контрагентов должен нам на начало этого года?».
Сгенерируем тестовую модель «больничных» для отладки наших запросов:
CREATE TABLE ranges(
owner
integer
, dtb -- начало отрезка
date
, dte -- окончание отрезка
date
);
INSERT INTO ranges(
owner
, dtb
, dte
)
SELECT
(random() * 1e3)::integer
, dtb
, dtb + (random() * 1e2)::integer
FROM
(
SELECT
now()::date - (random() * 1e3)::integer dtb
FROM
generate_series(1, 1e5)
) T;
Попробуем выяснить, кто из сотрудников числился на больничном в новогоднюю ночь.
BETWEEN + btree
Как правило, первый вариант запроса будет выглядеть как-то так:
SELECT
*
FROM
ranges
WHERE
'2020-01-01'::date BETWEEN dtb AND dte;
Но понятно, что без индекса работать это будет долго и плохо, поэтому неискушенный разработчик действует по принципу «какие поля в запросе вижу, те в индекс и добавляю»:
CREATE INDEX ON ranges(dtb, dte);
И… это не работает примерно никак, потому что мы все равно перебрали всю таблицу (100K записей, из которых 95K отбросили): 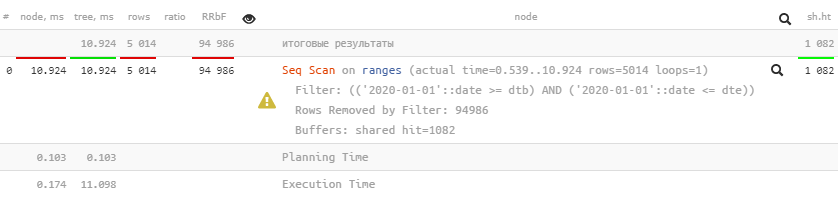
Чтобы понять «почему», достаточно представить визуально, как именно должен работать такой индекс, как мы делали это в статье «DBA: находим бесполезные индексы»: значение dtb ограничено только справа, dte — только слева, в результате имеем два «диапазонных» ключа, которые совместно по btree работают плохо.
*range + GiST
Но, конечно же, эффективное решение есть — это использование возможностей диапазонных типов и GiST-индексов:
CREATE INDEX ON ranges
USING gist( -- используем "пространственный" GiST-индекс
daterange(dtb, dte, '[]') -- формируем диапазон дат
);
Наш запрос теперь нужно модифицировать к такому виду:
SELECT
*
FROM
ranges
WHERE
daterange(dtb, dte, '[]') @> '2020-01-01'::date; -- значение входит в диапазон
С помощью подходящего индекса мы сократили время работы запроса в 3 раза.
Отрезки по группе
Но зачем нам все 5K записей «больничных»? Ведь, как правило, нас интересуют только коллеги по отделу — то есть какая-то конкретная группа отрезков, которую надо отфильтровать из общего набора.
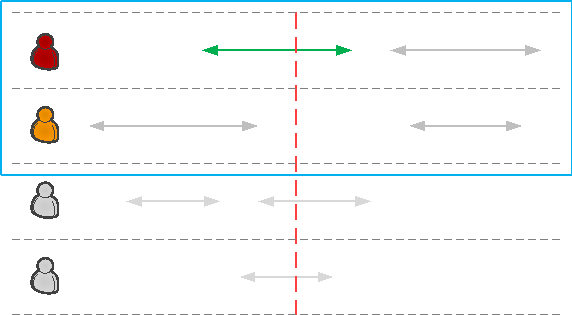
Поэтому усложним задачу и добавим в нашу модель принадлежность одному из отделов:
ALTER TABLE ranges ADD COLUMN segment integer;
UPDATE ranges SET segment = (random() * 1e2)::integer;SELECT
*
FROM
ranges
WHERE
segment = 1 AND
daterange(dtb, dte, '[]') @> '2020-01-01'::date;
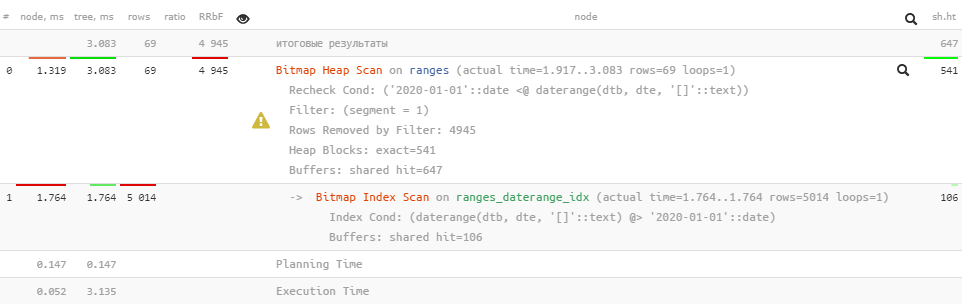
Индекс, конечно, по-прежнему используется, но теперь получается, что 99% данных мы вычитываем зря — 4945 строк отбрасывается при проверке сегмента.
Решение очевидно — добавим нужное нам поле в индекс, да?…
CREATE INDEX ON ranges USING gist(segment, daterange(dtb, dte, '[]'));
-- ОШИБКА: для типа данных integer не определён класс операторов по умолчанию для метода доступа "gist"
-- HINT: Вы должны указать класс операторов для индекса или определить класс операторов по умолчанию для этого типа данных.
Увы, нет — GiST-индекс «просто так» не поддерживает операции над скалярными типами. Зато если подключить расширение btree_gist — научится:
CREATE EXTENSION btree_gist;
CREATE INDEX ON ranges USING gist(segment, daterange(dtb, dte, '[]'));
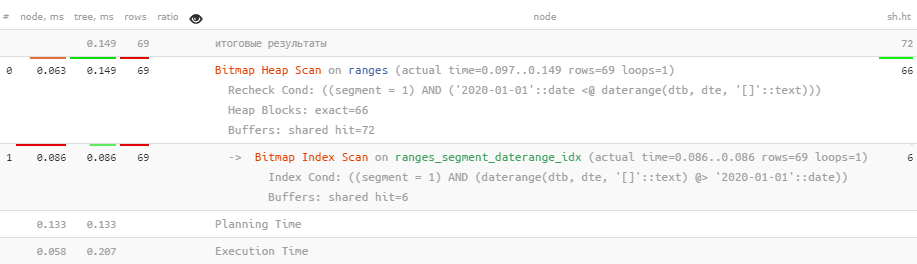
Наш запрос избавился от всех неиндексных фильтраций и стал в 20 раз быстрее! До кучи, еще и читать стал в 10 раз меньше данных (buffers).
Отрезки на интервале
Но пересечение отрезков с точкой требуется гораздо реже, чем пересечение отрезков с интервалом.
Типичная бизнес-задача:»кто ходил в отпуск в этом месяце? »,»какие задачи в моем календаре на сегодня? »
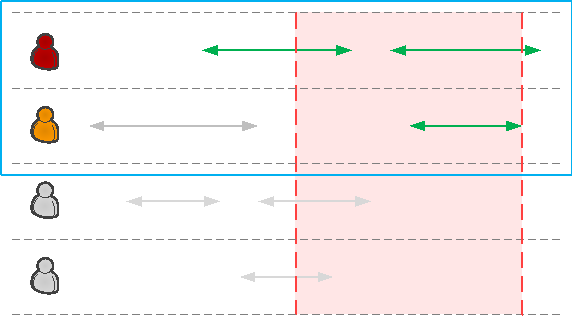
Собственно, все нужные для этого индексы у нас уже есть, осталось правильно записать условие:
SELECT
*
FROM
ranges
WHERE
segment = 1 AND
daterange(dtb, dte, '[]') && daterange('2020-01-01', '2020-02-01', '[)'); -- пересечение отрезков, без включения правой границы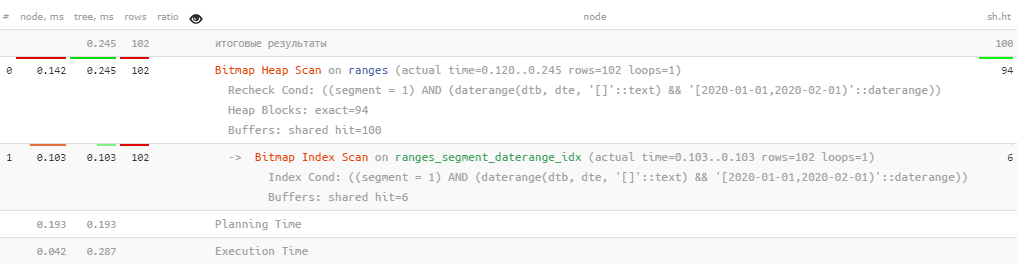
Объединение отрезков
Допустим, мы нашли когда и кто ходил в отпуск —, а теперь хотим узнать, когда же именно «команда играла в сокращенном составе». Для этого нам придется найти объединение отрезков по максимальному перекрытию.
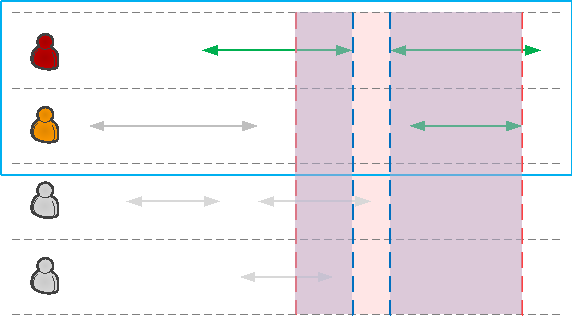
Если бы мы знали заранее все интервалы, участвующие в объединении, то могли бы просто написать через оператор »+»:
SELECT int4range('[0,2]') + int4range('[1,3]');
-- [0,4)
К сожалению, для наборов интервалов штатной функции агрегации вроде range_agg пока не реализовано. Ее, конечно, можно создать самостоятельно, но как-то это и выглядит страшно, и базу засоряет лишними сущностями — поэтому сделаем это обычным SQL-запросом.
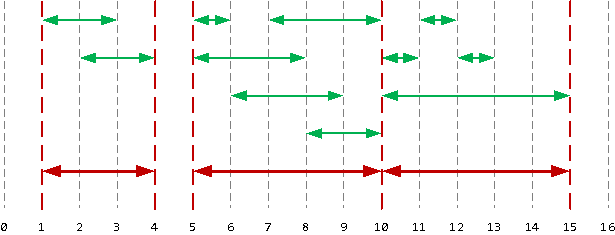
Вариант, работающий даже в версии 8.4, приведен в PostgreSQL Wiki:
WITH rng(s, e) AS (
VALUES
( 1, 3)
, ( 2, 4)
, ( 5, 6)
, ( 5, 8)
, ( 6, 9)
, ( 7, 10)
, ( 8, 10)
, (10, 11)
, (10, 15)
, (11, 12)
, (12, 13)
)
SELECT
min(s) s
, max(e) e
FROM
(
SELECT
s
, e
, max(new_start) OVER(ORDER BY s, e) left_edge
FROM
(
SELECT
s
, e
, CASE
WHEN s < max(le) OVER(ORDER BY s, e) THEN
NULL
ELSE
s
END new_start
FROM
(
SELECT
s
, e
, lag(e) OVER(ORDER BY s, e) le
FROM
rng
) s1
) s2
) s3
GROUP BY
left_edge;
Но план у него выглядит не слишком приятно — сортировка, три WindowAgg, группировка:

И обратите внимание, что в точке 10 он не «сливает» касающиеся интервалы, хотя обычно это требуется — как в нашей задаче про отпуска.
Давайте сконструируем запрос, который нас устроит:
- Отсортируем все отрезки по паре
(начало, конец). - Для каждого «начала» вычислим, стоит ли оно правее максимального из предшествующих ему «концов». Если левее вообще ничего нет или самый правый «конец» из предыдущих все равно левее — это точка начала искомого интервала.
- Отнесем все отрезки в группы по количеству предшествующих им найденных «начал».
- В каждой группе берем наименьшее из «начал» и «наибольший» из концов — это и есть искомый непрерывный интервал.
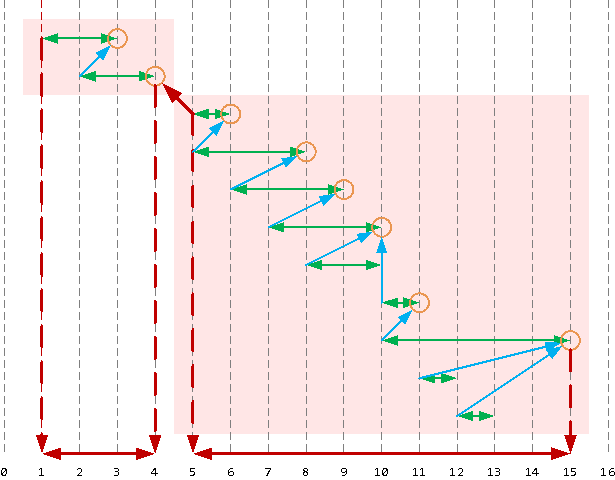
WITH rng(s, e) AS (
VALUES
( 1, 3)
, ( 2, 4)
, ( 5, 6)
, ( 5, 8)
, ( 6, 9)
, ( 7, 10)
, ( 8, 10)
, (10, 11)
, (10, 15)
, (11, 12)
, (12, 13)
)
SELECT -- min/max по группе
min(s) s
, max(e) e
FROM
(
SELECT
*
, sum(ns::integer) OVER(ORDER BY s, e) grp -- определение групп
FROM
(
SELECT
*
, coalesce(s > max(e) OVER(ORDER BY s, e ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), TRUE) ns -- начало правее самого правого из предыдущих концов == разрыв
FROM
rng
) t
) t
GROUP BY
grp;
Ну, и одно выполнение WindowAgg нам удалось отыграть: 
Длина объединенных отрезков
Если же перед нами не стоит цели вычислять сами целевые отрезки, а нужна только их суммарная длина, то можно сократить количество WindowAgg до единственного узла:
- Для каждого отрезка вычисляем максимум «концов» всех предыдущих.
- Берем разность между концом отрезка и большим из начала отрезка и найденного «конца».
- Осталось только просуммировать полученные разности.
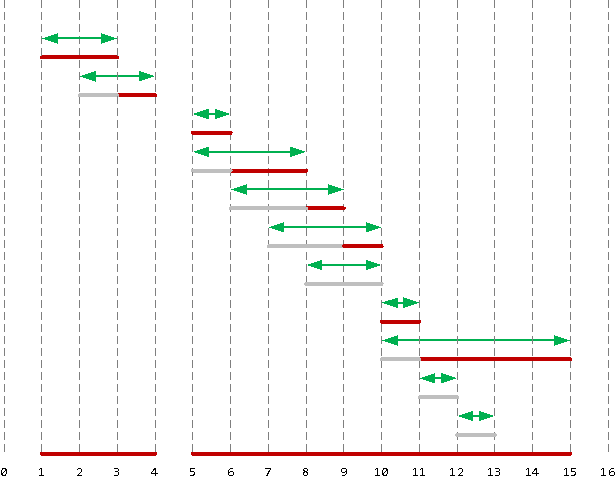
WITH rng(s, e) AS (
VALUES
( 1, 3)
, ( 2, 4)
, ( 5, 6)
, ( 5, 8)
, ( 6, 9)
, ( 7, 10)
, ( 8, 10)
, (10, 11)
, (10, 15)
, (11, 12)
, (12, 13)
)
SELECT
sum(delta)
FROM
(
SELECT
*
, greatest(
e - greatest(
max(e) OVER(ORDER BY s, e ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING)
, s
)
, 0
) delta
FROM
rng
) T;
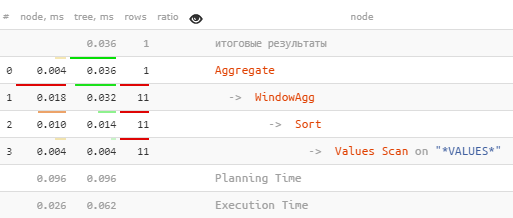
Спасибо imschur за этот вариант оптимизации.
Подсчет отрезков на каждом интервале
Итак, мы смогли узнать, сколько всего времени у нас работали не все сотрудники. Но ведь их отсутствовало разное количество в разные промежутки времени —, а сколько именно когда?
Типичная бизнес-задача: анализ и распределение нагрузки — например, между операторами call-центра:»Сколько звонков мы обслуживаем одновременно? Сколько для этого нужно операторов в ночной смене? »
- Присвоим каждому «началу» отрезка вес +1, а каждому «концу» — -1.
- Просуммируем накопительно значения в каждой точке — это и есть количество отрезков на интервале, начинающемся с этой точки и вплоть до следующей по порядку.
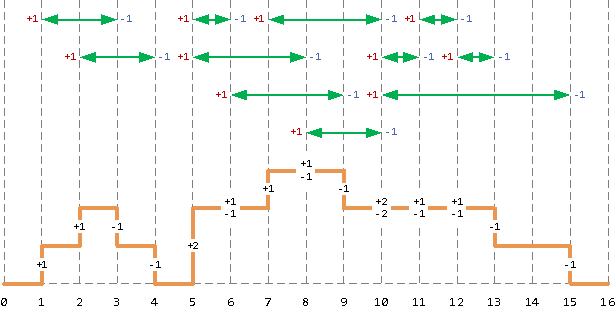
WITH rng(s, e) AS (
VALUES
( 1, 3)
, ( 2, 4)
, ( 5, 6)
, ( 5, 8)
, ( 6, 9)
, ( 7, 10)
, ( 8, 10)
, (10, 11)
, (10, 15)
, (11, 12)
, (12, 13)
)
SELECT DISTINCT ON(p) -- уникализация до единственного значения в точке
p
, sum(v) OVER(ORDER BY p) qty -- накопительная сумма
FROM
(
SELECT
s p
, +1 v
FROM
rng
UNION ALL
SELECT
e p
, -1 v
FROM
rng
) T
ORDER BY
1;
На этом сегодня все. Если знаете еще какие-то полезные нетривиальные алгоритмы работы с отрезками для решения бизнес-задач — напишите в комментариях.
