[Перевод] Миграция критически важного трафика в больших масштабах без простоев

Сотни миллионов пользователей ежедневно заходят на Netflix, ожидая получить непрерывный иммерсивный пользовательский опыт. Вместе с тем в организации правильного опыта участвуют множество систем и служб. Чтобы оправдать и превзойти ожидания клиентов, эти бэкенд-системы постоянно совершенствуются и оптимизируются.
При миграции систем одна из главных задач — обеспечить плавный переход трафика на обновлённую архитектуру без негативного влияния на пользовательский опыт. В этой публикации мы рассмотрим инструменты, техники и стратегии, которые мы использовали для достижения этой цели.
Бэкенд для стримингового продукта использует высокораспределённую архитектуру микросервисов, поэтому миграции также происходят в разных точках графа вызовов службы. Они могут происходить на пограничной API-системе, обслуживающей клиентские устройства, между пограничными и среднеуровневыми сервисами или со среднеуровневых сервисов в хранилища данных. Ещё одним важным фактором является то, что миграция может происходить на API с отслеживанием состояния или на тех API, которые не фиксируют данные о запросах и являются идемпотентными.
Мы разделили инструменты и методы, которые использовались для облегчения этих миграций, на две высокоуровневые фазы. Первая фаза включает в себя проверку функциональной корректности, масштабируемости и производительности, а также обеспечение устойчивости новых систем перед миграцией. Вторая фаза включает в себя перенос трафика на новые системы таким образом, чтобы снизить риск возникновения инцидентов, а также обеспечить постоянный мониторинг и подтверждение того, что мы выполняем важнейшие показатели, отслеживаемые на нескольких уровнях. К ним относятся измерения качества пользовательского опыта (Quality-of-Experience, QoE) на уровне клиентских устройств, соглашения об уровне обслуживания (Service-Level-Agreements, SLA) и ключевые показатели эффективности (KPI) на уровне бизнеса.
В этой статье мы подробно рассмотрим тестирование с помощью воспроизведённого трафика — универсальную методику, которую мы применяли на этапе предварительной проверки для нескольких инициатив по миграции. В следующей части статьи мы сосредоточимся на втором этапе и более подробно рассмотрим некоторые тактические шаги, которые мы используем для контролируемой миграции трафика.
Тестирование с помощью воспроизведённого трафика
Под воспроизведённым трафиком мы имеем в виду продакшен-трафик, который клонируется и перенаправляется на другой маршрут в графе вызовов служб. Это позволяет тестировать новые/обновлённые системы в условиях, имитирующих реальные продакшен условия. При такой стратегии тестирования мы выполняем копию (повторное воспроизведение) продакшен трафика для существующей и новой версий системы, чтобы провести соответствующие проверки. Этот подход имеет ряд преимуществ:
- Тестирование с помощью воспроизведённого трафика позволяет проводить масштабное тестирование в «песочнице», при этом не оказывая существенного влияния на продакшен трафик и пользовательский опыт.
- Используя клонированный реальный трафик, мы можем проверить разнообразие входных данных от широкого спектра различных физических устройств и различных версий ПО на этих устройствах. Это особенно важно для сложных API, которые имеют множество различающихся точек входных данных. Воспроизведённый трафик обеспечивает охват и покрытие, необходимые для проверки способности системы обрабатывать редко используемые комбинации входных данных и пограничные случаи.
- Эта техника облегчает проверку по нескольким направлениям. Она позволяет утверждать функциональную корректность, а также предоставляет механизм для нагрузочного тестирования системы, настройки системы и параметров масштабирования для оптимального функционирования.
- Моделируя реальную продакшен среду, мы можем охарактеризовать производительность системы в течение длительного периода времени с учётом ожидаемых и неожиданных изменений в структуре трафика. Это позволяет получить представление о диапазонах доступности и задержки в различных условиях продакшена.
- Платформа помогает убедиться в том, что соответствующие метрики, логирование и оповещения созданы до миграции.
Решение для воспроизведения трафика
Решение для тестирования с помощью воспроизведённого трафика состоит из двух основных компонентов.
- Дублирование трафика и корреляция: на начальном этапе необходимо реализовать механизм клонирования и перенаправления продакшен трафика на вновь созданный маршрут, а также процесс анализа корреляции ответов оригинального и альтернативного маршрутов.
- Сравнительный анализ и отчётность: после дублирования и корреляции трафика нам понадобится механизм для сравнения и анализа ответов, полученных от двух маршрутов, а также исчерпывающий отчёт по результатам анализа.
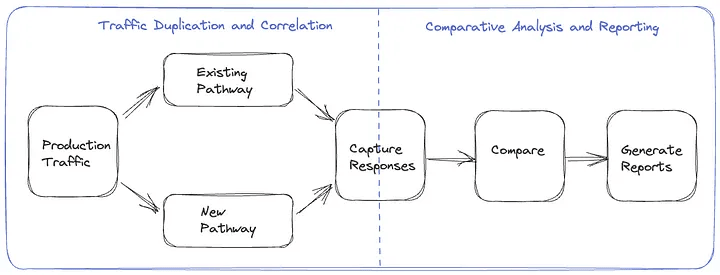
Фреймворк тестирования с помощью воспроизведённого трафика
В ходе миграций мы пробовали разные подходы к дублированию и записи трафика, внося в них улучшения. Среди них есть варианты, когда генерация воспроизведённого трафика организуется на устройстве, на сервере и с помощью специального сервиса. Мы рассмотрим эти способы в следующих разделах.
Организация на устройстве
В этом варианте устройство выполняет запрос на продакшен маршрут и на маршрут с записью трафика, а затем игнорирует ответ от маршрута с записью трафика. Эти запросы выполняются параллельно, чтобы свести к минимуму возможную задержку на маршруте продакшена. Выбор маршрута с записью трафика на внутреннем сервере может определяться URL-адресом, который устройство использует при выполнении запроса, или конкретными параметрами запроса в логике маршрутизации на соответствующем уровне графа вызовов служб. Устройство также включает уникальный идентификатор с идентичными значениями на обоих маршрутах, который используется для анализа корреляции ответов от двух маршрутов. Ответы могут быть записаны в наиболее оптимальном месте в графе вызовов служб или самим устройством — зависит от конкретной миграции.
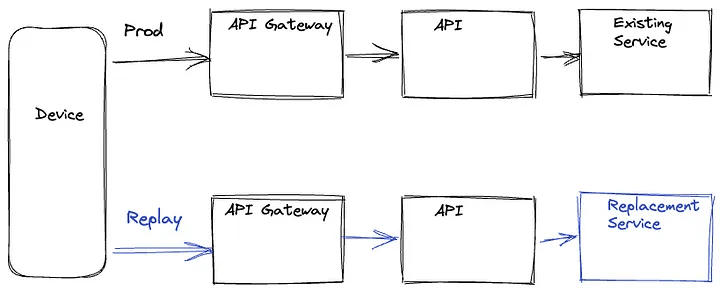
Device Driven воспроизведение
Очевидным недостатком device-driven подхода является то, что мы тратим ресурсы устройств. Также существует риск влияния на QoE устройства, особенно на устройствах с низким уровнем ресурсов. Добавление разветвлённой логики и сложности в код устройства может создать зависимости от циклов релиза приложений, которые обычно происходят медленнее, чем циклы релиза сервисов, что приведёт к узким местам в миграции. Более того, если позволить устройству выполнять непроверенные ветки кода на стороне сервера, это может привести к раскрытию поверхности атаки на систему.
Организация на сервере
Для решения проблем, связанных с device-driven подходом, мы использовали другой вариант, при котором проблемы воспроизведения полностью решаются на бэкенде. Воспроизведённый трафик клонируется и передаётся в верхнеуровневый сервис. Верхнеуровневый сервис вызывает одновременно существующие рабочие службы и новые службы на замену старым, чтобы свести к минимуму увеличение задержки на продакшен маршруте. Верхнеуровневый сервис записывает ответы на двух маршрутах вместе с идентификатором с общим значением, которое используется для сопоставления ответов. Эта операция записи также выполняется асинхронно, чтобы минимизировать любое влияние на задержку на продакшен маршруте.
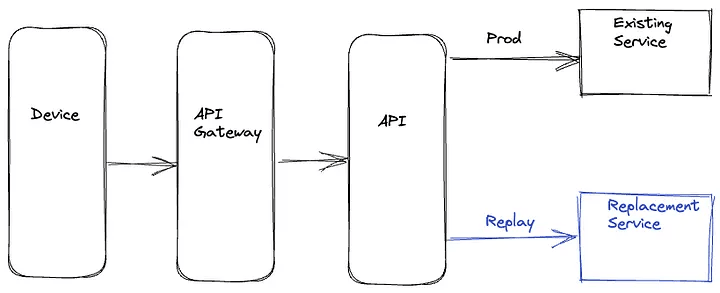
Server Driven воспроизведение
Преимущество server-driven подхода заключается в том, что вся сложность логики воспроизведения инкапсулируется в бэкэнд, и ресурсы устройства не расходуются впустую. Кроме того, поскольку эта логика находится на стороне сервера, мы можем быстрее итерировать любые необходимые изменения. Однако мы всё равно вставляем логику, связанную с воспроизведением, рядом с продакшен кодом, который обрабатывает бизнес-логику — это может привести к ненужному усложнению. Кроме того, возрастает риск того, что баги в логике воспроизведения могут повлиять на продакшен код и метрики.
Выделенный сервис
Последний подход, который мы использовали, заключается в полной изоляции всех компонентов трафика повторного воспроизведения в отдельном выделенном сервисе. При таком подходе мы асинхронно записываем запросы и ответы для сервиса, который необходимо обновить или заменить, в автономный поток событий. Довольно часто такое протоколирование запросов и ответов уже происходит для получения оперативной информации. Затем мы используем Mantis, распределённый потоковый процессор, для записи этих запросов и ответов и воспроизведения запросов для нового сервиса или кластера, внося при этом необходимые коррективы в запросы. После воспроизведения запросов эта специальная служба также записывает ответы из продакшен маршрута и маршрута с записью трафика.
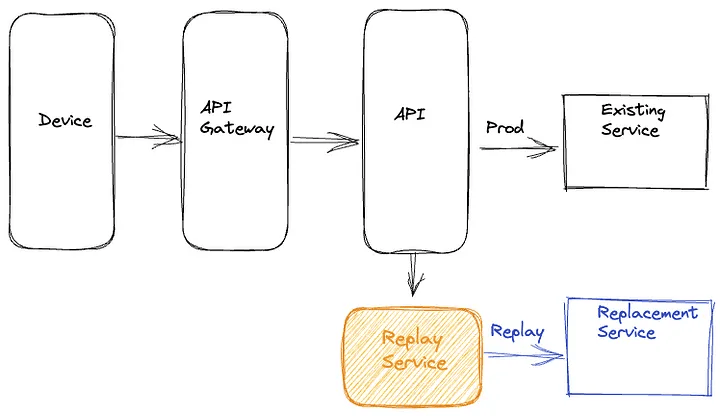
Выделенный Replay Service
При таком подходе логика воспроизведения сосредоточена в изолированной, выделенной кодовой базе. Помимо того, что такой подход не потребляет ресурсы устройства и не влияет на его QoE, он также уменьшает связь между бизнес-логикой продакшена и логикой воспроизведения трафика на бэкенде. Кроме того, он позволяет отделить любые обновления фреймворка воспроизведения от циклов выпуска устройств и сервисов.
Анализ воспроизведённого трафика
После того как мы запустили воспроизведённый трафик и записали статистически значимый объём ответов, мы готовы к сравнительному анализу и созданию отчётов. Учитывая масштаб данных, генерируемых с помощью воспроизведённого трафика, мы записываем ответы с обеих сторон в экономичное холодное хранилище с помощью технологии Apache Iceberg. Затем мы можем создать автономные распределённые задачи пакетной обработки для сравнения ответов на продакшен маршруте и маршруте с записью трафика, а также создания подробных отчётов по результатам анализа.
Нормализация
В зависимости от характера мигрируемой системы, ответы могут перед сравнением нуждаться в предварительной обработке. Например, если некоторые поля в ответах представляют собой временные метки, они будут различаться. Аналогично, если в ответах есть несортированные списки, лучше перед сравнением их сортировать. В некоторых сценариях миграции возможны преднамеренные изменения в ответах, генерируемых обновлённой службой или компонентом. Например, поле, которое в исходном маршурте было списком, в новом маршруте представлено в виде пар ключ-значение. В таких случаях мы можем применить определённые преобразования к ответу на маршрут воспроизведения, чтобы смоделировать ожидаемые изменения. Исходя из особенностей системы и соответствующих ответов, могут существовать и другие специфические преобразования, которые можно применить к ответам перед их сравнением.
Сравнение
После нормализации мы сравниваем ответы с двух сторон и проверяем, совпадают ли они или нет. Пакетное задание создаёт высокоуровневую сводку, которая фиксирует некоторые ключевые метрики сравнения. К ним относятся общее количество ответов с обеих сторон, количество ответов, объединённых идентификатором корреляции, совпадения и несовпадения. В сводке также фиксируется количество пройденных и непройденных ответов на каждом маршруте. Эта сводка даёт хорошее представление об анализе и общем коэффициенте совпадений на маршруте продакшена и маршруте воспроизведения. Кроме того, в случае несоответствий мы записываем нормализованные и ненормализованные ответы с обеих сторон в другую большую таблицу данных вместе с другими важными параметрами, такими как разница. Мы используем этот дополнительный журнал для отладки и выявления первопричины проблем, которые приводят к несоответствиям. Как только мы обнаружим и устраним эти проблемы, мы сможем использовать процесс повторного тестирования, чтобы снизить процент несоответствий до приемлемого уровня.
Lineage
При сравнении ответов распространённым источником шума является использование недетерминированных или неэдемпотентных данных о зависимостях для генерации ответов на продакшен маршруте и маршруте с записью трафика. Например, представьте себе полезную нагрузку ответа, которая доставляет медиапотоки для сеанса воспроизведения. Служба, отвечающая за генерацию этой полезной нагрузки, обращается к службе метаданных, которая предоставляет все доступные потоки для данного названия. Добавление или удаление потоков может быть вызвано различными факторами — например, выявлением проблем с конкретным потоком, включением поддержки нового языка или введением нового кодирования. Следовательно, есть вероятность расхождений в наборах потоков, используемых для определения полезной нагрузки на продакшен маршрут и маршрут с записью трафика. Это приводит к расхождениям в ответах.
Для решения этой проблемы составляется полный свод версий данных или контрольных сумм для всех зависимостей, участвующих в генерации ответа, называемый lineage («цепочка данных»). Несоответствия можно выявить и отбросить, сравнив историю откликов как при продакшен, так и при повторных ответах в автоматизированных заданиях, анализирующих отклики. Такой подход снижает влияние шума и обеспечивает точное и надёжное сравнение между продакшен ответами и ответами воспроизведения.
Сравнение трафика в реальном времени
Альтернативным методом записи ответов и проведения сравнения оффлайн является сравнение в реальном времени. При таком подходе мы выполняем разветвление (forking) воспроизведённого трафика на верхнеуровневом сервисе, как описано в разделе «Организация на сервере». Сервис, который разветвляет и клонирует повторный трафик, напрямую сравнивает ответы на продакшен маршруте и маршруте с записью трафика и записывает соответствующие метрики. Этот вариант возможен, если полезная нагрузка ответа не очень сложная, так что сравнение не приводит к значительному увеличению задержек, или если мигрируемые сервисы не находятся на критическом маршруте. Запись в логи производится выборочно в случаях, когда старый и новый ответы не совпадают.

Анализ воспроизведённого трафика
Нагрузочное тестирование
Помимо функционального тестирования, воспроизведённый трафик позволяет нам провести стресс-тестирование обновлённых компонентов системы. Мы можем регулировать нагрузку на маршрут с записью трафика, управляя объёмом воспроизводимого трафика и коэффициентами горизонтального и вертикального масштабирования нового сервиса. Такой подход позволяет оценить производительность новых сервисов при различных условиях трафика. Мы можем увидеть, как при изменении коэффициента нагрузки изменяется доступность, задержка и другие показатели производительности системы, такие как потребление процессора, потребление памяти, скорость сборки мусора и так далее. Нагрузочное тестирование системы с помощью этой техники позволяет выявить «горячие точки» производительности, используя реальные профили продакшен трафика. Оно помогает выявить утечки памяти, взаимные блокировки (deadlocks), проблемы с кэшированием и другие системные проблемы. Также позволяет настроить пулы потоков, пулы соединений, таймауты соединений и другие параметры конфигурации. Кроме того, он помогает определить разумные политики масштабирования и оценить связанные с этим затраты, а также подразумевает более широкий компромисс между затратами и рисками.
Системы с сохранением состояний
Мы широко использовали тестирование воспроизведения для обеспечения уверенности в миграциях с использованием систем без состояния и идемпотентных систем. Тестирование воспроизведения также может подтвердить правильность миграций, связанных с системами с сохранением состояний, но при этом необходимо принять дополнительные меры.
Продакшен маршрут и маршрут с записью трафика должны иметь отдельные и изолированные хранилища данных, которые находятся в идентичных состояниях, прежде чем разрешить воспроизведение трафика. Кроме того, должны быть воспроизведены все различные типы запросов, которые управляют стейт-машиной.
На этапе записи, помимо ответов, мы также хотим зафиксировать состояние, связанное с конкретным ответом. Соответственно, на этапе анализа мы хотим сравнить как ответ, так и связанное с ним состояние в машине состояний. Учитывая общую сложность использования тестирования воспроизведения в системах с сохранением состояния, мы применяем в таких сценариях другие техники. Одну из них мы рассмотрим в следующей статье этого цикла.
Заключение
В Netflix мы применяем тестирование с помощью воспроизведения трафика для многочисленных проектов по миграции. Один из недавних кейсов — проверка обширной реархитектуры пограничных API, которые управляют компонентом воспроизведения нашего продукта. Другой пример — миграция сервиса среднего уровня с REST на gRPC. В обоих случаях тестирование с помощью воспроизведения трафика способствовало всестороннему функциональному тестированию, нагрузочному тестированию и настройке системы в масштабе с использованием реального продакшен трафика. Такой подход позволил нам выявить заковыристые проблемы и быстро укрепить доверие по отношению к этим существенным изменениям.
По завершении тестирования с помощью воспроизведения трафика мы готовы приступить к внедрению этих изменений в продакшен. В одной из следующих статей мы рассмотрим некоторые методы, которые мы используем для постепенного внедрения значительных изменений в систему на продакшене, контролируя риски и наращивая уверенность с помощью метрик на разных уровнях.

