[Перевод] Миф о RAM и O(1)

Городская библиотека Стокгольма. Фото minotauria.
В этой статье я хочу рассказать о том, что оценивать время обращения к памяти как O (1) — это очень плохая идея, и вместо этого мы должны использовать O (√N). Вначале мы рассмотрим практическую сторону вопроса, потом математическую, на основе теоретической физики, а потом рассмотрим последствия и выводы.
Введение
Если вы изучали информатику и анализ алгоритмической сложности, то знаете, что проход по связному списку это O (N), двоичный поиск это O (log (N)), а поиск элемента в хеш-таблице это O (1). Что, если я скажу вам, что все это неправда? Что, если проход по связному списку на самом деле O (N√N), а поиск в хеш-таблице это O (√N)?
Не верите? Я вас сейчас буду убеждать. Я покажу, что доступ к памяти это не O (1), а O (√N). Этот результат справедлив и в теории, и на практике. Давайте начнем с практики.
Измеряем
Давайте сначала определимся с определениями. Нотация «О» большое применима ко многим вещам, от использования памяти до запущенных инструкций. В рамках этой статьи мы O (f (N)) будет означать, что f (N) — это верхняя граница (худший случай) по времени, которое необходимо для получения доступа к N байтов памяти (или, соответственно, N одинаковых по размеру элементов). Я использую Big O для анализа времени, но не операций, и это важно. Мы увидим, что центральный процессор подолгу ждет медленную память. Лично меня не волнует, что делает процессор пока ждет. Меня волнует лишь время, как долго выполняется та или иная задача, поэтому я ограничиваюсь определением выше.
Еще одно замечание: RAM в заголовке означает произвольный доступ (random memory accesses) в целом, а не какой-то конкретный тип памяти. Я рассматриваю время доступа к информации в памяти, будь это кэш, DRAM или swap.
[Вот простая программа], которая проходит по связному списку размером N. Размеры — от 64 элементов до 420 миллионов элементов. Каждый узел списка содержит 64-битный указатель и 64 бит данных. Узлы перемешаны в памяти, поэтому каждый доступ к памяти — произвольный. Я измеряю проход по списку несколько раз, а потом отмечаю на графике время, которое понадобилось для доступа к элементу. Мы должны получить плоский график вида O (1). Вот что получается в реальности:
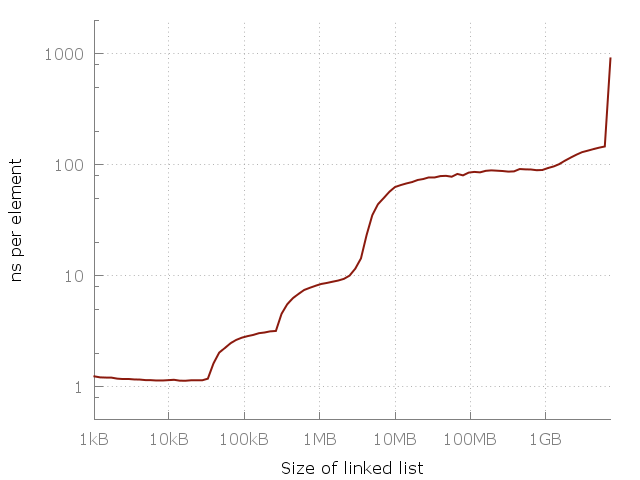
Сложность доступа к элементу в связном списке. Доступ к произвольному элементу в 100-мегабайтном списке примерно в 100 раз медленнее, чем доступ к элементу в 10-килобайтном списке.
Заметьте, что это в этом графике используется логарифмическая шкала на обоих осях, так что разница на самом деле громадная. От примерно одной наносекунды на элемент мы дошли до целой микросекунды! Но почему? Ответ, конечно, это кэш. Системная память (RAM) на самом деле довольно медленная, и для компенсации умные компьютерные проектировщики добавить иерархию более быстрых, более близких и более дорогих кэшей для ускорения операций. В моем компьютере есть три уровня кэшей: L1, L2, L3 размером 32 кб, 256 кб и 4 мб, соответственно. У меня 8 гигабайт оперативной памяти, но когда я запускал этот эксперимент, у меня было только 6 свободных гигабайт, так что в последних запускал был своппинг на диск (SSD). Вот тот же график, но с указанием размеров кэшей.
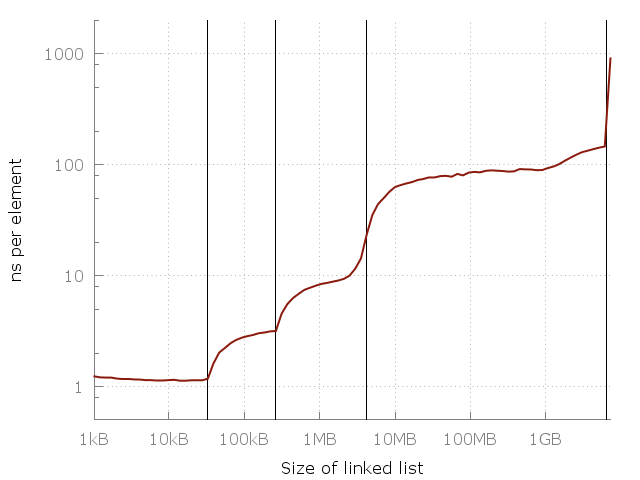
Вертикальные линии указывают на L1 = 32 кб, L2 = 256 кб, L3 = 4 мб и 6 гигабайт свободной памяти.
На этом графике видна важность кэшей. Каждый слой кэша в несколько раз быстрее предыдущего. Это реальность современной архитектуры центрального процессора, будь это смартфон, лаптоп или мэйнфрейм. Но где здесь общий паттерн? Можно ли поместить на этот график простое уравнение? Оказывается, можем!
Посмотрим внимательнее, и заметим, что между 1 мегабайтом и 100 мегабайтами примерно 10-кратное замедление. И такое же между 100 мегабайтами и 10 гигабайтами. Похоже, что каждое 100-кратное увеличение использованной памяти дает 10-кратное замедление. Давайте добавим это на график.
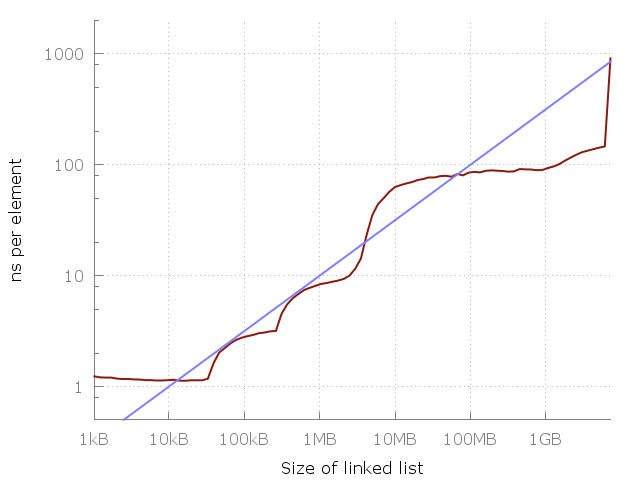
Голубая линия это O (√N).
Голубая линия это график указывает на O (√N) стоимость каждого доступа к памяти. Кажется, отлично подходит, да? Конечно, это моя конкретная машина, и на вашей картина может выглядеть иначе. Тем не менее, уравнение очень легко запомнить, так что, может быть, его стоит использовать как грубое правило.
Вы, наверное, спрашиваете, а что там дальше, правее графика? Продолжается ли повышение или график становится плоским? Ну, он становится плоским на некоторое время, пока на SSD есть достаточно свободного места, после чего программе придется переключиться на HDD, потом на дисковый сервер, потом на далекий дата-центр, и так далее. Каждый скачок создаст новый плоский участок, но общая тенденция на повышение, думаю, продолжится. Я не продолжал свой эксперимент из-за нехватки времени и отсутствия доступа к большому дата-центру.
«Но эмпирический метод нельзя использовать для определения границ Big-O», — скажете вы. Конечно! Может быть, есть теоретическая граница у задержки при доступе к памяти?
Круглая библиотека
Позвольте описать мысленный эксперимент. Допустим, вы — библиотекарь, работающий в круглой библиотеке. Ваш стол — в центре. Время, необходимое вам для получения любой книги, ограничено расстоянием, которое нужно пройти. И в худшем случае это радиус, потому что нужно дойти до самого края библиотеки.
Допустим, ваша сестра работает в другой подобной библиотеке, но у нее (у библиотеки, не сестры :), — прим. пер.) радиус в два раза больше. Иногда ей нужно пройти в два раза больше. Но у ее библиотеки площадь в 4 раза больше, чем у вашей, и в ней помещается в 4 раза больше книг. Количество книг пропорционально квадрату радиуса: N∝ r². И так как время T доступа к книге пропорционально радиусу, то N∝ T² или T∝√N или T=O (√N).
Это грубая аналогия с центральным процессором, которому нужно получить данные из свой библиотеки — оперативной памяти. Конечно, скорость «библиотекаря» важна, но тут мы ограничены скоростью света. Например, за один цикл 3-гигагерцового процессора свет преодолевает расстояние 10 см. Так что для похода туда и обратно, любая мгновенно доступная память должна быть не дальше 5 сантиметров от процессора.
Хорошо, сколько информации мы можем разместить в рамках определенного расстояния r от процессора? Выше мы говорили о круглой плоской библиотеке, но что, если она будет сферической? Количество памяти, которая поместится в сферу, будет пропорциональна кубу радиуса — r³. В реальности компьютеры достаточно плоские. Это отчасти вопрос форм-фактора и отчасти вопрос охлаждения. Возможно, когда-нибудь мы научимся строить и охлаждать трехмерные блоки памяти, но пока практическое ограничение количества информации N в пределах радиуса r будет N ∝ r². Это справедливо и для совсем далеких хранилищ, вроде дата-центров (которые распределены по двумерной поверхности планеты).
Но можно ли, теоретически, улучшить картину? Для этого нужно немного узнать про черные дыры и квантовую физику!
Теоретическая граница
Количество информации, которую можно поместить в сфере радиусом r, можно вычислить с помощью [границы Бекенштейна]. Это количество прямо пропорционально радусу и массе: N ∝ r·m. Насколько массивна может быть сфера? Ну, что является самым плотным во вселенной? Черная дыра! [Оказывается], что масса черной дыры пропорциональна радиусу: m ∝ r. То есть количество информации, которую можно поместить в сфере радиусом r это N ∝ r². Мы пришли к выводу, что количество информации ограничено площадью сферы, а не объемом!
Вкратце: если попытаться засунуть очень большой кэш L1 в процессор, то он в конце концов схлопнется в черную дыру, что помешает вернуть результат вычисления пользователю.
Получается, что N ∝ r² это не только практическая, но и теоретическая граница! То есть законы физики устанавливают лимит на скорость доступа к памяти: чтобы получить N битов данных, нужно передавать сообщение на расстояние, пропорциональное O (√N). Иными словами, каждое 100-кратное увеличение задачи ведет за собой 10-кратное увеличение времени доступа к одному элементу. И именно это показал наш эксперимент!
Немного истории
В прошлом процессоры были намного медленнее памяти. В среднем, поиск по памяти был быстрее самого вычисления. Распространенной практикой было хранить в памяти таблицы для синусов и логарифмов. Но времена изменились. Производительность процессоров росла намного быстрее скорости памяти. Современные процессоры большую часть своего времени просто ждут память. Именно поэтому существует столько уровней кэша. Я считаю, что эта тенденция будет сохраняться еще долгое время, поэтому важно переосмыслить старые истины.
Вы можете сказать, что вся суть Big-O в абстракции. Она необходима, чтобы отвязаться от таких деталей архитектуры как задержка памяти. Это верно, но я утверждаю, что O (1) это неправильная абстракция. В частности, Big-O нужно для абстракции константных множителей, но доступ к памяти это не константная операция. Ни в теории, ни в практике.
В прошлом любой доступ к памяти в компьютерах был одинаково дорогим, поэтому O (1). Но это больше не так, и уже достаточно давно. Я считаю, что пора думать об этом иначе, забыть про доступ к памяти за O (1) и заменить его на O (√N).
Последствия
Стоимость обращения к памяти зависит от размера, который запрашивается — O (√N), где N это размер памяти, к котором происходит обращение при каждом запросе. Значит, если обращение происходит к одному и тому же списку или таблице, то следующее утверждение верно:
Проход по связному списку это O (N√N) операция. Двоичный поиск это O (√N). Получение из ассоциативного массива это O (√N). На самом деле, любой произвольный поиск в любой базе данных это в лучшем случае O (√N).
Стоит заметить, что действия, производимые между операциями, имеют значение. Если ваша программа работает с памятью размером N, то любой произвольный запрос к памяти будет O (√N). Так что проход по списку размером K будет стоить O (K√N). При повторном проходе (сразу, без обращения к другой памяти) стоимость будет O (K√K). Отсюда важный вывод: если вам нужно обращаться к одному и тому же участку памяти несколько раз, то минимизируйте промежутки между обращениями.
Если же вы делаете проход по массиву размером K, то стоимость будет O (√N + K), потому что только первое обращение будет произвольным. Повторный проход будет O (K). Отсюда другой важный вывод: если планируете делать проход, то используйте массив.
Существует одна большая проблема: многие языки не поддерживают настоящие массивы. Языки вроде Java и многие скриптовые языки хранят все объекты в динамической памяти, и массив там это на самом деле массив указателей. Если вы делаете проход по такому массиву, то производительность будет не лучше, чем при проходе по связному списку. Проход по массиву объектов в Java стоит O (K√N). Это можно компенсировать созданием объектов в правильном порядке, тогда распределитель памяти, надеюсь, разместит их в памяти по порядку. Но если вам нужно создавать объекты в разное время или перемешивать их, то ничего не получится.
Вывод
Методы обращения к памяти — это очень важно. Нужно всегда стараться обращаться к памяти предсказуемым способом, и минимизировать произвольные обращения к памяти. Здесь нет ничего нового, конечно, но это стоит повторить. Надеюсь, вы возьмете на вооружение новый инструмент для размышлений о кэше: обращение к памяти стоит O (√N). В следующий раз, когда будете оценивать сложность, вспомните об этой идее.
Комментарии (1)
 deniskreshikhin
deniskreshikhin
7 сентября 2016 в 12:39
+1↑
↓
Странно, почему нет «юмор» в тегах?
