[Перевод] Мёртв ли последовательный ввод-вывод в эпоху накопителей NVMe?
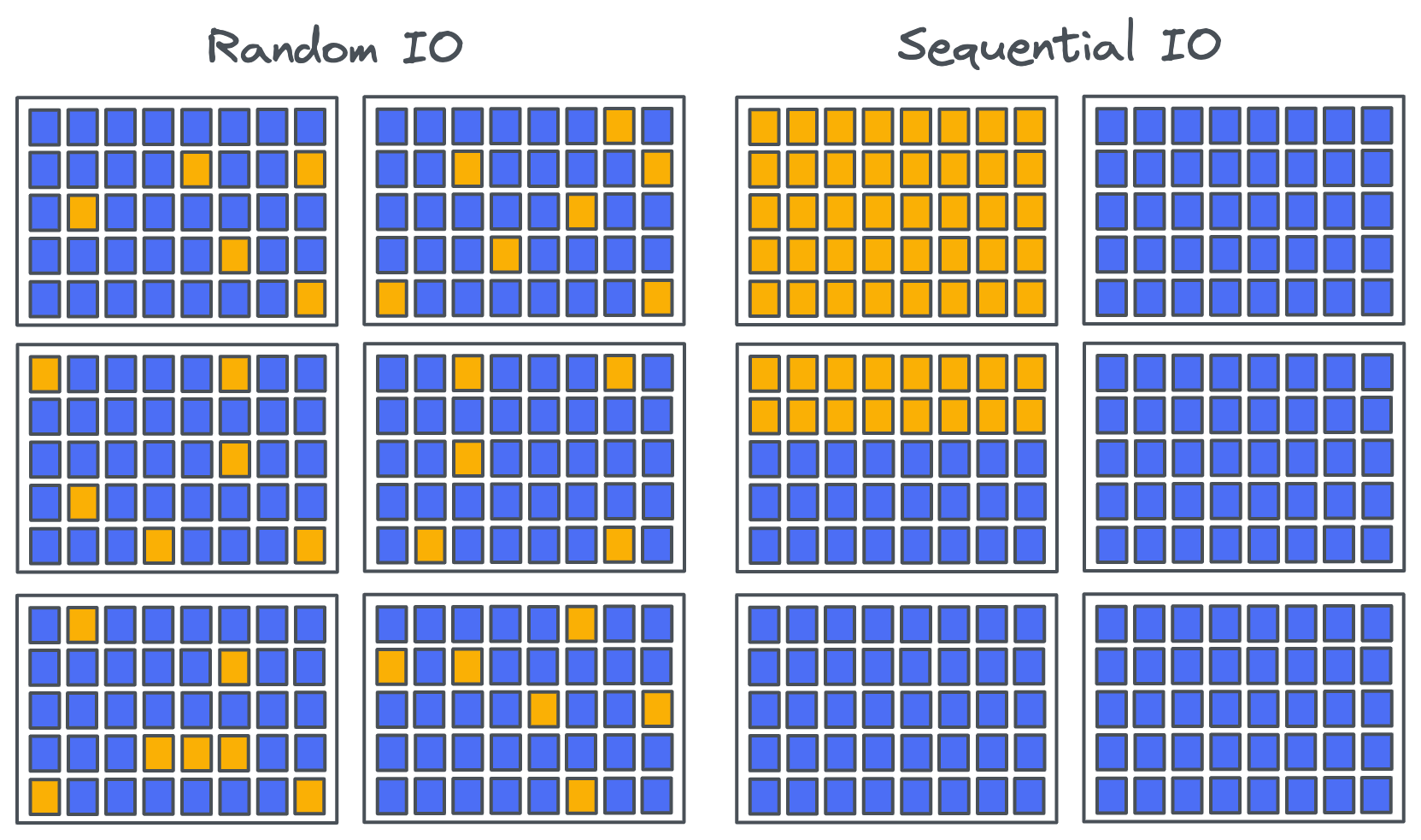
Две системы, которые я хорошо знаю (Apache BookKeeper и Apache Kafka) проектировались в эпоху дисковых накопителей: жёстких дисков, или HDD. Жёсткие диски хорошо справляются с последовательным вводом-выводом, но не очень хороши в произвольном вводе-выводе из-за относительно большого времени поиска. Неудивительно, что и Kafka, и BookKeeper проектировались с расчётом на последовательный ввод-вывод.
И Kafka, и BookKeeper — это распределённые системы логирования, поэтому можно представить, что последовательный ввод-вывод будет стандартным режимом для системы хранения логов с возможностью только дополнения. Но последовательный и произвольный ввод-вывод находятся в спектре, где на одном краю расположен чисто последовательный, а на другом — чисто произвольный ввод-вывод. Если у вас есть пять тысяч файлов, которые вы дописываете небольшими циклическими операциями записи, и выполняете fsync, то это не такой уж последовательный паттерн доступа, он находится ближе к произвольному вводу-выводу. То есть если вы только дополняете логи, это не означает автоматически, что вы получаете последовательный ввод-вывод.
Итак, в эпоху HDD проектировщики систем встраивали в свои системы последовательный ввод-вывод. Apache BookKeeper активно стремится организовать последовательный ввод-вывод, обеспечивая наличие только одного активного файла за раз. Он делает это, попеременно записывая данные из различных логических логов в один физический лог. Подобное чередование хорошо подходит для записи, однако чтение становится проблемой, потому что мы больше не можем получить последовательные операции чтения. Для решения этой проблемы BookKeeper записывает данные дважды: один раз в хорошо оптимизированный лог с упреждающей записью (Write-Ahead-Log, WAL), а затем в долговременное хранилище, оптимизированное под чтение. Чтобы это долговременное хранилище было оптимизировано под чтение, BookKeeper накапливает записанные элементы в большой кэш записи, а затем периодически сортирует кэш и записывает его в один активный файл (за раз). Сортировка по идентификатору лога и идентификатору элемента гарантирует, что связанные данные записываются в смежные блоки, что делает чтение более последовательным. Нам нужно лишь добавить индекс, который может указывать на эти смежные блоки.
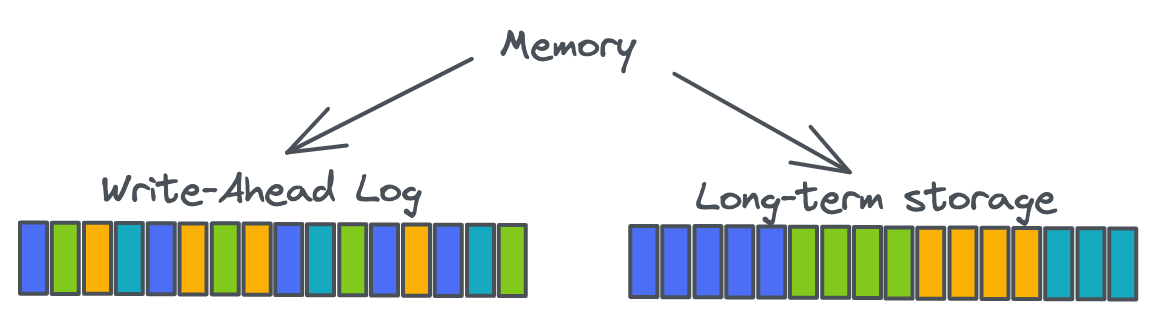
Обычно WAL помещается на один диск, а долговременное хранилище — на другой. Операции записи в WAL являются чисто последовательными и операции записи в долговременное хранилище являются чисто последовательными. Операции чтения иногда могут попасть в индекс, но обычно тоже являются последовательными. При одном активном WAL BookKeeper может выполнять fsync примерно каждую 1 мс, и это не становится слишком затратным — мы просто выполняем запись в один файл за раз. Можно увеличить масштаб и WAL, и долговременного хранилища, добавив ещё дисков и создав больше инстансов WAL и движка долговременного хранилища, каждый со своим пулом потоков.
Apache Kafka для реализации последовательного ввода-вывода использует другой подход. Он за раз отображает один раздел на один активный файл сегментов, что поначалу кажется ужасным. Если брокер хостит 1000 разделов, то за раз будет выполнять запись в 1000 файлов. Это может быть затратным, особенно в случае HDD. Для решения этой проблемы у Kafka есть два важных архитектурных элемента. Во-первых, он спроектирован так, чтобы выполнять запись на диск асинхронно, для сброса данных на диск он использует страничный кэш; это приводит к тому, что на диск записываются более крупные (последовательные) блоки данных. Это снижает затраты на запись в такое большое количество открытых файлов. Кроме того, асинхронная запись на диск небезопасна, если не реализовать протокол репликации для обработки произвольной утери головы лога. При асинхронной записи на диск можно потерять часть последних записанных элементов, например, при сбое сервера. Недавно я писал о механизме восстановления Kafka, встроенном в его протокол репликации, который позволяет использовать эту асинхронную запись логов.
▍ Эпоха NAND-памяти
Но не устарела ли подобная этика проектирования в современном мире SSD? Высокопроизводительные SSD могут обеспечивать высокую пропускную способность и низкие задержки при рабочих нагрузках с произвольным вводом-выводом. Значит ли это, что мы можем отказаться от последовательного ввода-вывода? Должны ли мы проектировать распределённые системы хранения логов так, чтобы они использовали произвольный ввод-вывод, таким образом освободив себя от необходимости придумывания трюков для обеспечения последовательного ввода-вывода?
Накопители SSD, в том числе и NVMe, действительно не зависят от паттернов доступа ввода-вывода. Alibaba Cloud написал два интересных поста о факторах, влияющих на производительность накопителей NVMe. Интересный аспект накопителей NVMe заключается в объёме необходимого обслуживания, например, в выравнивании износа и сборке мусора.
Выравнивание износа предотвращает исчерпание ресурса блоков NAND из-за слишком большого количества циклов чтения и записи. Оно осуществляется перенесением «горячих» данных в менее изношенные блоки. Сборка мусора — это ещё один процесс обслуживания, при котором контроллер накопителя переписывает блоки данных, если причиной фрагментации стала нехватка свободных блоков.
Внутри накопителя NVMe данные записываются в страницы (обычно размером 4 КБ), а страницы принадлежат блокам (обычно по 128 страниц на блок).
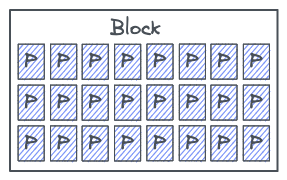
Контроллер накопителя может выполнять запись напрямую в пустые страницы, но не может перезаписать страницу. Кроме того, контроллер может переписывать только блоки целиком, но не отдельные страницы. Когда контроллер хочет перезаписать страницу, он просто выполняет запись в доступную пустую страницу, обновляет таблицу отображения логических и физических блоков, а старую страницу помечает как недействительную. Эти недействительные страницы накапливаются и в них невозможно выполнять запись, поэтому контроллер периодически должен выполнять обслуживание для работы с недействительными страницами. Этот процесс называется сборкой мусора (garbage collection, GC). Без GC место на накопителе бы быстро закончилось, потому что все блоки были бы заполнены действительными и недействительными страницами.
GC работает так: она считывает блок и перезаписывает все действительные страницы в пустой блок, обновляет таблицу отображения и стирает исходный блок.
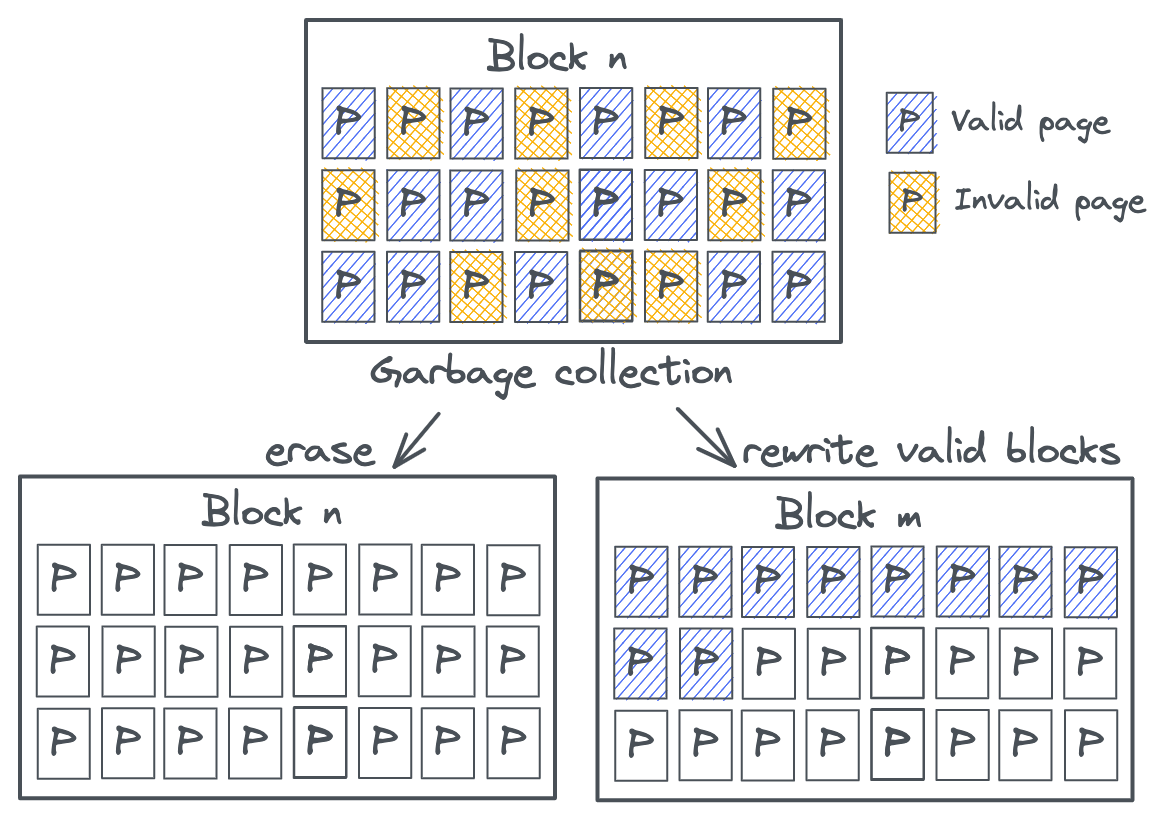
Такое переписывание приводит к увеличению объёма записи, потому что на каждую записанную страницу приходится определённый объём перезаписи. Весь этот бэкенд-трафик в накопителе снижает производительность и срок эксплуатации накопителя.
Простое удаление файла не стирает все страницы в накопителе. Эти страницы помечаются как недействительные и процесс GC постепенно очищает эти недействительные страницы.
Это значит, что если запись выполняется на весь диск, то пропускная способность будет ограничена пропускной способностью процесса GC — чем больше работы нужно делать GC, тем меньше пропускная способность и выше задержки дисковых операций.
И здесь становится актуальным вопрос сравнения последовательного и произвольного ввода-вывода. Последовательный ввод-вывод заполняет блоки целиком, а произвольный ввод-вывод склонен разбрасывать операции записи по блокам, фрагментируя все файлы по нескольким блокам. На пустом накопителе эта разница не имеет значения, потому что есть множество свободных блоков. Однако, если в течение дней и недель накопитель находился под нагрузкой, эта фрагментация начинает сильно влиять на GC.
Последовательный ввод-вывод обеспечивает меньшую нагрузку на GC, потому что он заполняет блоки целиком, а при удалении файла из файловой системы недействительным становится весь блок. Процессу GC не приходится переписывать страницы блока, образованного из одних недействительных страниц. Он просто удаляет блок. Однако при произвольном вводе-выводе все блоки содержат смесь действительных и недействительных данных, так что перед стиранием блока под новые операции записи необходимо переписать имеющиеся действительные блоки. Именно поэтому коэффициент увеличения объёма записи нагрузок с последовательным вводом-выводом близок к 1, а у произвольного ввода-вывода обычно гораздо выше.
В конечном итоге на накопителе окажется много незарезервированных блоков, содержащих смесь простаивающих и используемых страниц. На этом этапе новые операции записи с большой вероятностью будут приводить к серьёзному увеличению объёма записи и снижению производительности, потому что контроллер перемещает используемые страницы в другие очищенные блоки. Операция записи в одну страницу может привести к каскадной очистке и перемещению многих сотен других страниц.
▍ На помощь приходит over-provisioning
Но не всё так плохо для произвольного ввода-вывода. Затраты на GC можно снизить, предоставив накопителю дополнительное место, зарезервированное только для него самого, что позволит ему использовать GC. Чем меньше свободного места есть на накопителе, тем выше коэффициент увеличения объёма записи и сильнее снижение производительности. Обычно, когда количество действительных данных на накопителе превышает 50%, мы начинаем наблюдать снижение производительности при произвольном вводе-выводе, которое усиливается при процессе заполнения накопителя до 100%.
Over-provisioning (OP) — это концепция резервирования места только под контроллер накопителя. Например, при OP в 7% контроллер накопителя получает для себя 7% ёмкости и операционная система не может выполнять туда запись. SSD корпоративного уровня имеют определённый процент встроенного over-provisioning, а у накопителей NVMe хранилища локального инстанса AWS его нет. Существуют различные способы самостоятельной реализации OP. Можно просто оставить часть диска без раздела или использовать инструмент наподобие hdparm.
Дальнейшее увеличение пространства для over-provisioning может снизить бэкенд-трафик GC, но за это придётся расплачиваться снижением плотности записи и повышением затрат. Проблема увеличения объёма записи и её чувствительности к нагрузкам с произвольным вводом-выводом уже давно была известна производителям флэш-памяти и флэш-накопителей. Однако это ограничение часто оказывается незамеченным и многие люди не знают о нём.
В статье 2010 года The Fundamental Limit of Flash Random Write Performance: Understanding, Analysis and Performance Modelling (X.-Y. Hu, R. Haas) рассматриваются взаимодействия и ограничения, имеющиеся у среднего размера записи, контроллеров, алгоритмов сбора мусора и произвольного ввода-вывода. Исследователи выяснили, что при произвольном вводе-выводе производительность может стремительно снижаться, когда накопитель использован примерно на 2/3 от своего объёма. Как показано на рисунке 7 статьи, даже варьирование размера полезной нагрузки записи минимально влияет на показатель замедления.
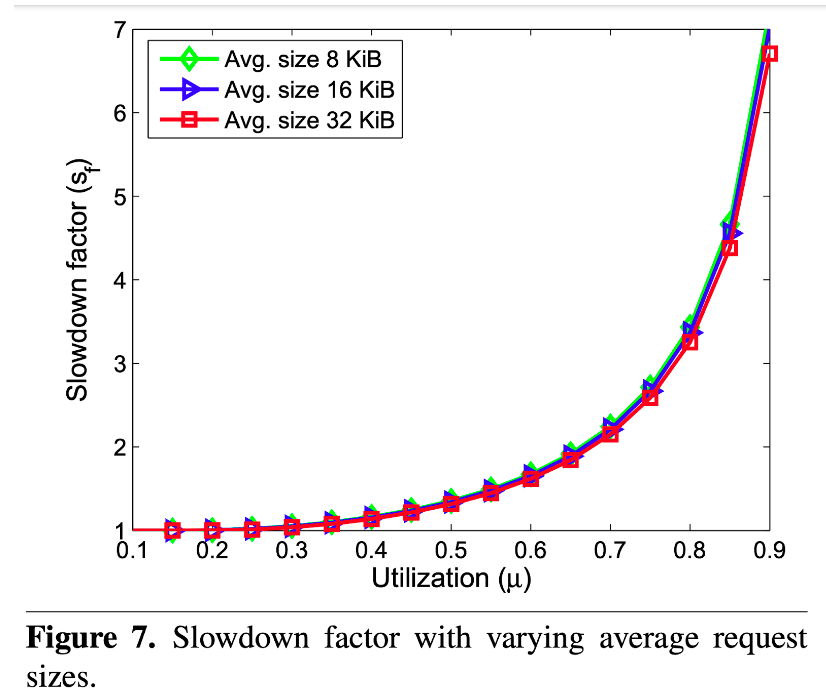
Технология накопителей NVMe всё ещё развивается, но мы по-прежнему сталкиваемся с этими фундаментальными проблемами фрагментации и обслуживания. Авторы The Fundamental Limit of Flash Random Write Performance завершают свою статью следующим наблюдением:
«Плохая производительность произвольной записи флэш-SSD и замедление производительности накопителей могут быть вызваны или артефактами проектирования/реализации, которые можно устранить в процессе совершенствования технологий, или фундаментальными ограничениями вследствие уникальных характеристик флэш-памяти. Выявление и понимание фундаментальных ограничений флэш-SSD пригодится не только для создания более совершенных флэш-SSD, но и для оптимальной интеграции флэш-памяти в современную иерархию памяти и накопителей».
Мне кажется важной эта часть вывода, особенно потому, что она была написана тринадцать лет назад. Технологии с тех пор тоже сильно улучшились: сильно повысилась плотность накопителей, улучшились контроллеры и алгоритмы GC. Но даже самые современные накопители NAND страдают от тех же фундаментальных проблем: фрагментации страниц и необходимости сборки мусора.
В более современной статье Improving I/O Performance via Address Remapping in NVMe interface за 2022 год рассматриваются способы решения проблемы произвольного ввода-вывода при помощи алгоритма перераспределения, транслирующего произвольный ввод-вывод в последовательный, что даёт довольно многообещающие экспериментальные результаты.
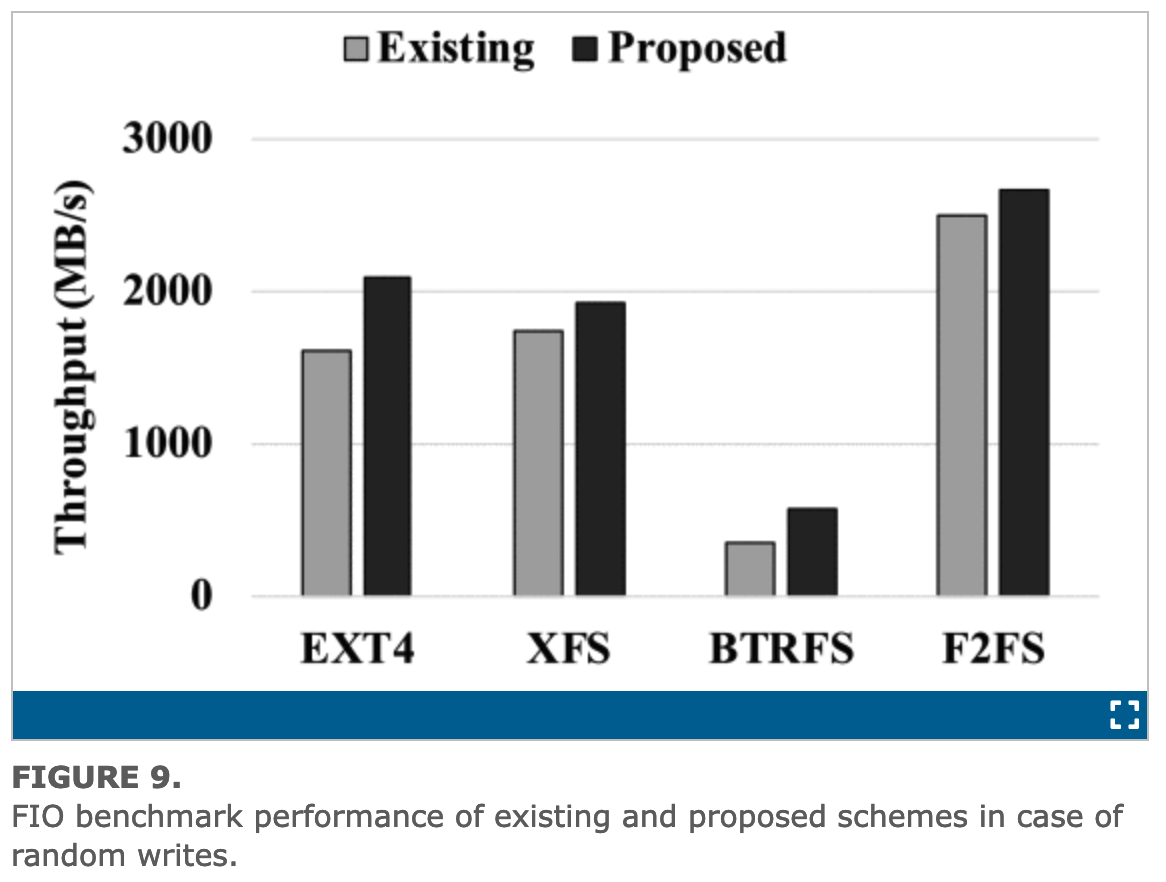
На представленном выше изображении показана производительность произвольных операций записи на 8-ядерном Intel Core i9–9900K с 16 ГБ памяти и NVMe SSD Samsung PM1725b.
В статье также имеется обширный раздел «Related works», в котором представлены ссылки на множество других интересных исследований оптимизации производительности накопителей NVMe.
▍ Возвращаясь к исходному вопросу
Итак, я вернусь к вопросу о том, мёртв ли последовательный ввод-вывод в эпоху накопителей NVMe и ко второму вопросу о том, устарели ли сегодня Apache Kafka и Apache BookKeeper, спроектированные под последовательный ввод-вывод. Мне кажется, преимущества последовательного ввода-вывода по-прежнему актуальны даже в новую эпоху флэш-памяти NAND. Последовательный ввод-вывод механически больше подходит для всех типов накопителей и в частности для SSD, он снижает коэффициент увеличения объёма записи, что в свою очередь повышает производительность, позволяя использовать бОльшую часть объёма накопителя (потому что over-provisioning менее важен) и увеличить срок службы накопителя.
Существует гораздо больше аспектов производительности накопителей SSD, чем я упомянул в этом посте. Ниже представлены ссылки на интересные статьи с обсуждениями производительности SSD.
▍ Дополнительное чтение
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх
