[Перевод] Механизмы выделения памяти в Go
Когда я впервые попытался понять то, как работают средства выделения памяти в Go, то, с чем я хотел разобраться, показалось мне таинственным чёрным ящиком. Как и в случае с любыми другими технологиями, самое важное здесь скрывается за множеством слоёв абстракций, сквозь которые нужно пробраться для того, чтобы что-то понять.

Автор материала, перевод которого мы публикуем, решил добраться до сути средств выделения памяти в Go и рассказать об этом.
Физическая и виртуальная память
Всем средствам для выделения памяти приходится работать с адресным пространством виртуальной памяти, которым управляет операционная система. Давайте посмотрим на то, как работает память, начав с самого низкого уровня — с ячеек памяти.
Вот как можно представить ячейку оперативной памяти.
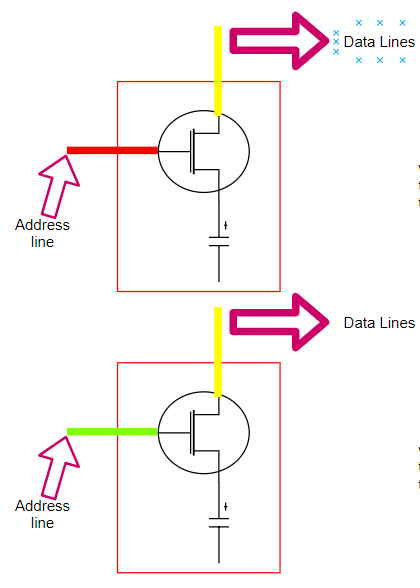
Схема ячейки памяти
Если, очень упрощённо, представить себе ячейку оперативной памяти и то, что её окружает, то у нас получится следующее:
- Линия адреса (транзистор играет роль переключателя) — это то, что даёт доступ к конденсатору (линии данных).
- Когда в линии адреса появляется сигнал (красная линия), линия данных позволяет осуществлять запись данных в ячейку памяти, то есть — зарядку конденсатора, что даёт возможность сохранить в нём логическое значение, соответствующее 1.
- Когда сигнала в линии адреса нет (зелёная линия), линия данных не позволяет записывать данные в ячейку памяти, то есть конденсатор остаётся незаряженным, в результате в нём оказывается логическое значение 0.
- Когда процессору нужно прочитать значение из памяти, сигнал подаётся по линии адреса (переключатель закрывается). Если конденсатор заряжен, то сигнал идёт по линии данных (считывается 1), в противном случае сигнал по линии данных не идёт (считывается 0).

Схема взаимодействия физической памяти и процессора
Шина данных ответственна за транспортировку данных между процессором и физической памятью.
Теперь поговорим о линии адреса и об адресуемых байтах.

Линии шины адреса между процессором и физической памятью
- Каждому байту в оперативной памяти назначается уникальный числовой идентификатор (адрес). Надо отметить, что число присутствующих в памяти физических байтов не равно числу адресных линий.
- Каждая линия адреса может задавать 1-битовое значение, поэтому она указывает на один бит в адресе некоего байта.
- На нашей схеме имеется 32 линии адреса. В результате каждый адресуемый байт, в качестве адреса, использует 32-битное число. [ 00000000000000000000000000000000 ] — младший адрес памяти. [ 11111111111111111111111111111111 ] — старший адрес памяти.
- Так как каждый байт имеет 32-битный адрес, наше адресное пространство состоит из 232 адресуемых байт (4 Гб).
В результате оказывается, что число адресуемых байт зависит от общего количество адресных линий. Например, если имеется 64 линии адреса (процессоры x86–64), можно адресовать 264 байт (16 эксабайт) памяти, но большинство архитектур, в которых используются 64-битные указатели, на самом деле, используют 48-битные линии адреса (AMD64) и 42-битные линии адреса (Intel), что, теоретически, позволяет оснащать компьютеры 256 терабайтами физической памяти (Linux позволяет, на архитектуре x86–64, при использовании адресных страниц 4 уровня, выделять процессам до 128 ТБ адресного пространства, Windows позволяет выделять до 192 ТБ).
Так как размер физической оперативной памяти ограничен, каждый процесс выполняется в собственной «песочнице» — в так называемом «виртуальном адресном пространстве», называемом виртуальной памятью.
Адреса байтов в виртуальном адресном пространстве не соответствуют тем адресам, которые процессор использует для обращения к физической памяти. В результате нужна система, позволяющая преобразовывать виртуальные адреса в физические. Взглянем на то, как выглядят виртуальные адреса памяти.
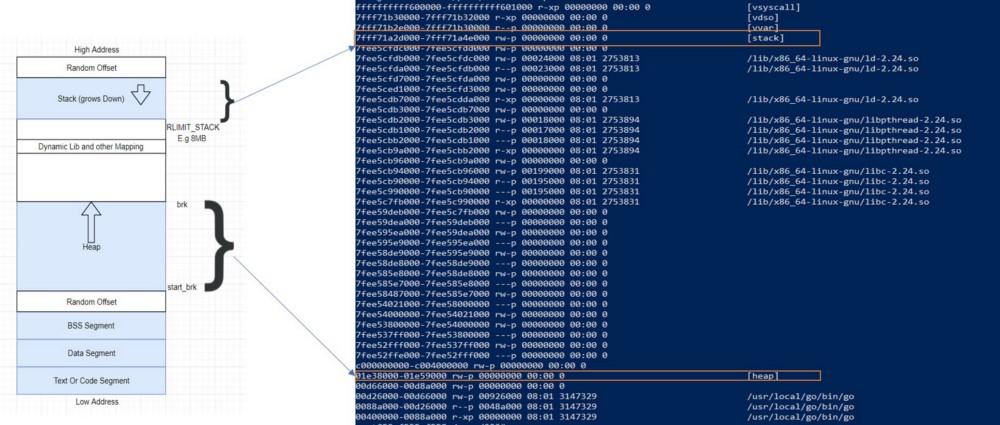
Представление виртуального адресного пространства
В итоге, когда процессор выполняет инструкцию, которая ссылается на адрес памяти, первым шагом является перевод логического адреса в линейный адрес. Это преобразование выполняется блоком управления памятью.
Упрощённое представление взаимосвязи виртуальной и физической памяти
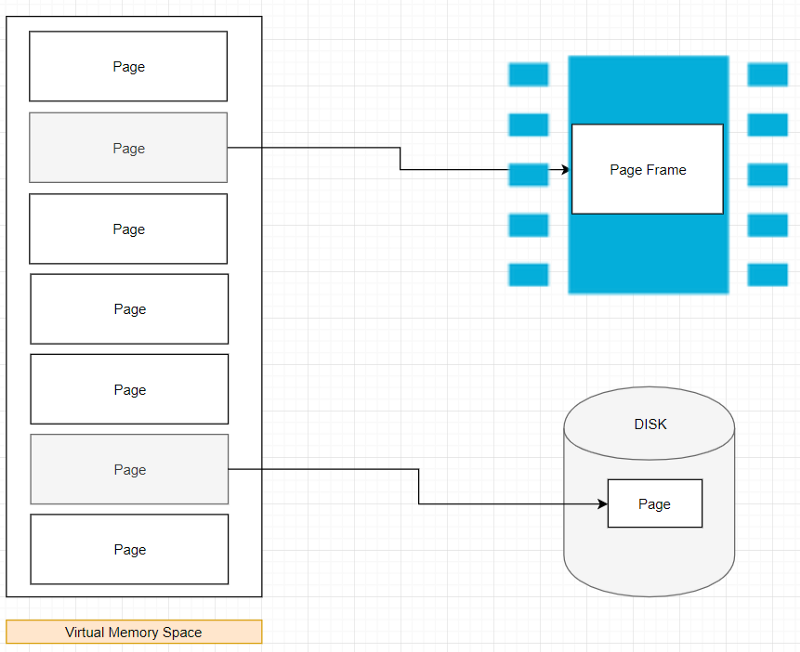
Так как логические адреса слишком велики для того, чтобы удобно было бы работать с ними по отдельности (это зависит от различных факторов), память организуется в структуры, называемые страницами. При этом виртуальное адресное пространство делится на небольшие области, страницы, которые в большинстве ОС имеют размер 4 Кб, хотя обычно этот размер можно изменить. Это — наименьшая единица управления памятью в виртуальной памяти. Виртуальная память ничего не хранит, она просто задаёт соответствие между адресным пространством программы и физической памятью.
Процессы видят лишь адреса виртуальной памяти. Что происходит, если программе нужно больше динамической памяти (такую память ещё называют heap memory, или «кучей»)? Вот пример простого кода на ассемблере, в котором у системы запрашивается дополнительная динамически распределяемая память:
_start:
mov $12, %rax # номер системного вызова brk
mov $0, %rdi # 0 - неверное значение, нужно получить текущую позицию
syscall
b0:
mov %rax, %rsi # теперь rsi указывает на начало кучи, которую мы выделим
mov %rax, %rdi # переместим верх кучи сюда ...
add $4, %rdi # .. плюс 4 байта, которые мы выделяем
mov $12, %rax # снова обращаемся к brk
syscall
Вот как это можно представить в виде схемы.

Увеличение динамически распределяемой памяти
Программа запрашивает дополнительную память, пользуясь системным вызовом brk (sbrk / mmap и так далее). Ядро обновляет сведения о виртуальной памяти, но при этом в физической памяти новые страницы пока не представлены, и здесь наблюдается отличие между виртуальной и физической памятью.
Средство выделения памяти
После того, как мы, в общих чертах, обсудили работу с виртуальным адресным пространством, поговорили о том, как выполняется запрос дополнительной динамической памяти (памяти в куче), нам легче будет говорить о средствах для выделения памяти.
Если в куче достаточно памяти для удовлетворения запросов нашего кода, то средство выделения памяти может выполнять эти запросы, не обращаясь к ядру. В противном случае ему приходится увеличивать размер кучи с использованием системного вызова (с помощью brk, например), запрашивая при этом большой блок памяти. В случае с malloc «большой» означает размер, описываемый параметром MMAP_THRESHOLD, который, по умолчанию, равен 128 Кб.
Однако у средства выделения памяти есть больше обязанностей, нежели простое выделение памяти. Одна из важнейших его обязанностей заключается в уменьшении внутренней и внешней фрагментации памяти, и в том, чтобы выделять блоки памяти как можно быстрее. Предположим, что наша программа последовательно выполняет запросы на выделение непрерывных блоков памяти с использованием функции вида malloc(size), после чего эта память освобождается с использованием функции вида free(pointer).
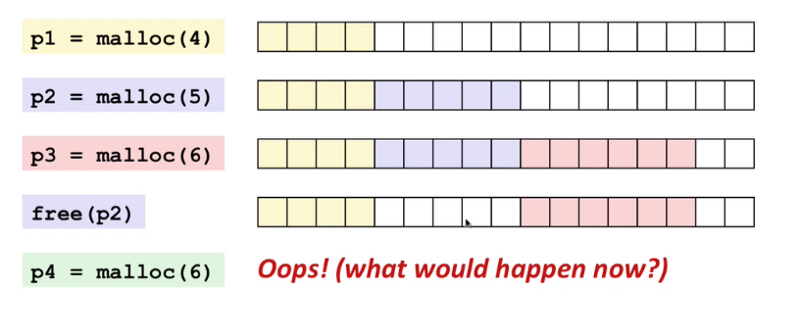
Демонстрация внешней фрагментации
На предыдущей схеме, на шаге p4, у нас нет достаточного количества последовательно расположенных блоков памяти для выполнения запроса на выделение шести таких блоков, хотя общий объём свободной памяти сделать это позволяет. Такая ситуация приводит к фрагментации памяти.
Как уменьшить фрагментацию памяти? Ответ на этот вопрос зависит от конкретного алгоритма выделения памяти, от того, какая базовая библиотека используется для работы с памятью.
Сейчас мы рассмотрим средство для выделения памяти TCMalloc, на котором основаны механизмы выделения памяти Go.
TCMalloc
В основе TCMalloc лежит идея разделения памяти на несколько уровней ради уменьшения фрагментации памяти. Внутри TCMalloc управление памятью делится на две части: работа с памятью потоков и работа с кучей.
▍Память потоков
Каждая страница памяти разбивается на последовательность фрагментов определённых размеров, выбираемых в соответствии с классами размеров. Это позволяет уменьшить фрагментацию. В результате в распоряжении каждого потока оказывается кэш для маленьких объектов, который позволяет очень эффективно выделять память под объекты, размер которых меньше или равен 32 Кб.
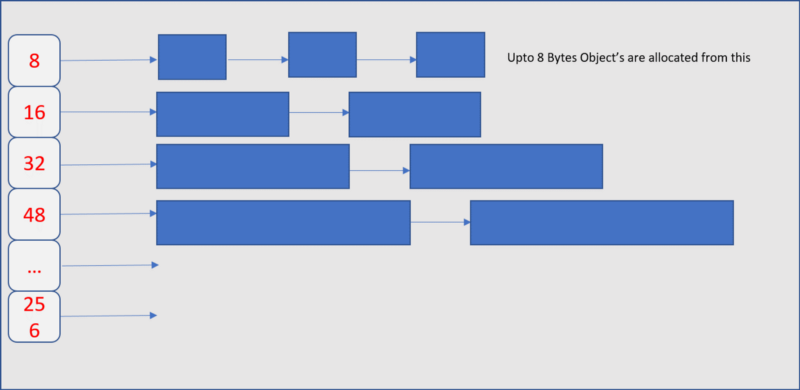
Кэш потока
▍Куча
Куча, управляемая TCMalloc, представляет собой коллекцию страниц, в которой набор последовательных страниц может быть представлен в виде диапазона страниц (span). Когда нужно выделить память под объект, размер которого превышает 32 Кб, для выделения памяти используется куча.

Куча и работа со страницами
Когда для размещения в памяти маленьких объектов места не хватает, за памятью обращаются к куче. Если и в куче недостаточно свободной памяти — дополнительная память запрашивается у операционной системы.
В результате представленная модель работы с памятью поддерживает пул памяти пользовательского пространства, её применение значительно улучшает эффективность выделения и освобождения памяти.
Надо отметить, что средство выделения памяти Go изначально было основано на TCMalloc, но оно немного от него отличается.
Средство выделения памяти Go
Мы знаем, что среда выполнения Go планирует выполнение горутин на логических процессорах. Подобно этому, версия TCMalloc, используемая в Go, делит страницы памяти на блоки, размеры которых соответствуют определённым классам размеров, которых существует 67.
Если вы не знакомы с планировщиком Go — здесь можно о нём почитать.
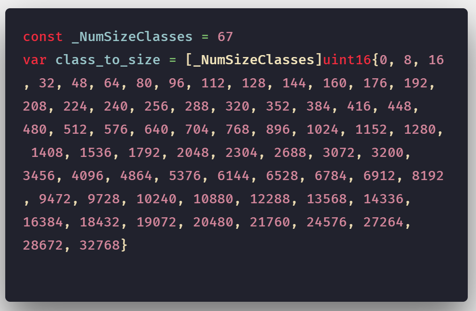
Классы размеров в Go
Так как минимальным размером страницы в Go является 8192 байта (8 Кб), если такую страницу разделить на блоки, размером 1 Кб, то мы получим 8 таких блоков.

Страница размером 8 Кб разделена на блоки, соответствующие классу размера 1 Кб
Подобными последовательностям страниц в Go управляют с использованием структуры, называемой mspan.
▍Структура mspan
Структура mspan представляет собой двусвязный список, объект, который содержит начальный адрес страницы, сведения о размере страницы и количество страниц, входящих в него.

Структура mspan
▍Структура mcache
Как и TCMalloc, Go предоставляет каждому логическому процессору локальный кэш для потоков, известный как mcache. В результате, если горутина нуждается в памяти, она может получить её непосредственно из mcache. Для этого не нужно выполнять блокировки, так как в любой момент времени на одном логическом процессоре выполняется лишь одна горутина.
Структура mcache содержит, в виде кэша, структуры mspan различных классов размера.
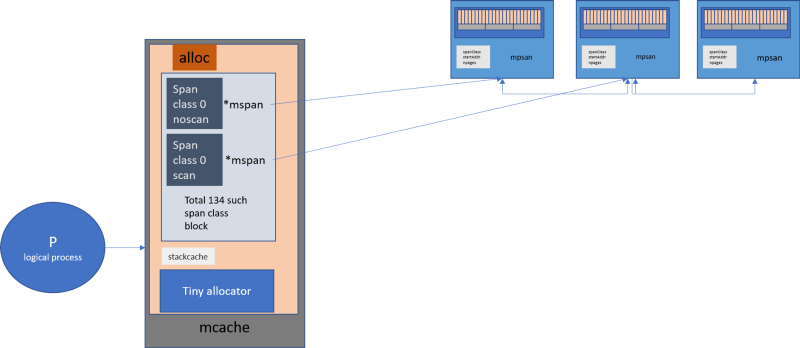
Взаимодействие между логическим процессором, mcache и mspan в Go
Так как у каждого логического процессора есть собственный mcache, при выделении памяти из mcache нет необходимости в блокировках.
Каждый класс размера может быть представлен одним из следующих объектов:
- Объект scan — это объект, который содержит указатель.
- Объект noscan — это объект, в котором нет указателя.
Одной из сильных сторон такого подхода является то, что когда выполняется сборка мусора, noscan-объекты обходить не нужно, так как они не содержат объектов, под которые выделена память.
Что же попадает в mcache? Объекты, размер которых не превышает 32 Кб, попадают прямо в mcache с использованием mspan соответствующего класса размера.
Что происходит в том случае, если в mcache нет свободной ячейки? Тогда получают новый mspan нужного класса размера из списка объектов mspan, который называется mcentral.
▍Структура mcentral
Структура mcentral собирает все диапазоны страниц определённого класса размера. Каждый объект mcentral содержит два списка объектов mspan.
- Список объектов mspan, в которых нет свободных объектов, или тех mspan, которые имеются в mcache.
- Список объектов mspan, в которых есть свободные объекты.
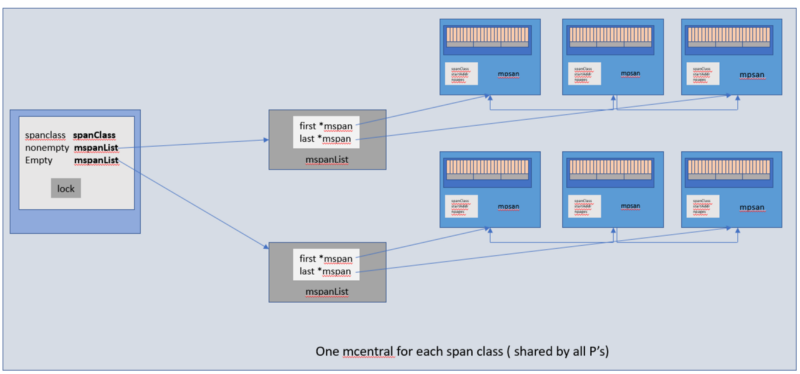
Структура mcentral
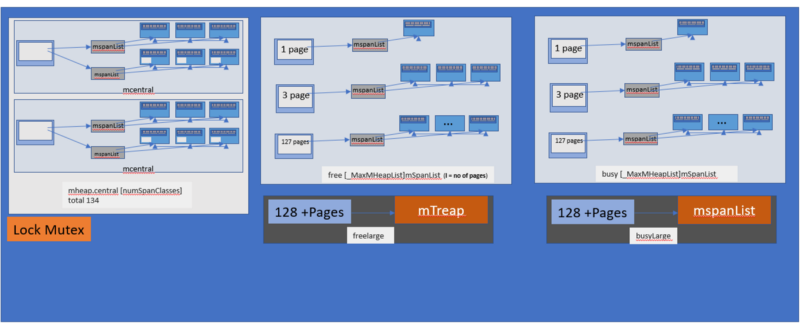
Каждая структура mcentral существует внутри структуры mheap.
▍Структура mheap
Структура mheap представлена объектом, который занимается в Go управлением кучей. Существует всего один такой глобальный объект, владеющий виртуальным адресным пространством.
Структура mheap
Как видно из вышеприведённой схемы, структура mheap содержит массив структур mcentral. Этот массив содержит структуры mcentral для всех классов размеров.
central [numSpanClasses]struct {
mcentral mcentral
pad [sys.CacheLineSize unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte
}
Так как у нас есть структура mcentral для каждого класса размера, когда mcache запрашивает структуру mspan из mcentral, на индивидуальном уровне mcentral применяется блокировка, в результате одновременно могут быть обслужены и запросы от других mcache, запрашивающих структуры mspan других размеров.
Выравнивание (pad) позволяет обеспечить то, что структуры mcentral отделены друг от друга количеством байтов, соответствующих значению CacheLineSize. В результате у каждого mcentral.lock имеется собственная строка кэша, что позволяет избежать проблем, связанных с ложным совместным использованием памяти.
Что происходит в том случае, если список mcentral пуст? Тогда mcentral получает последовательность страниц из mheap для выделения фрагментов памяти требуемого класса размера.
free[_MaxMHeapList]mSpanList— это массив spanList. Структура mspan в каждом spanList состоит из 1 ~ 127 (_MaxMHeapList — 1) страниц. Например, free[3] — это связанный список структур mspan, содержащих 3 страницы. Слово «free» в данном случае указывает на то, что речь идёт о пустом списке, память в котором не выделена. Список может быть, в противоположность пустому, списком, в котором память выделена (busy).freelarge mSpanList— это список свободных структур mspan. Количество страниц на элемент (то есть, mspan) более 127. Для поддержки такого списка используется структура данных mtreap. Список занятых структур mspan называется busylarge.
Объекты, размер, которых превышает 32 Кб, считаются большими объектами, память под них выделяется прямо из mheap. Запросы на выделение памяти под такие объекты выполняются с использованием блокировки, в результате в некий заданный момент времени может быть обработан подобный запрос лишь от одного логического процессора.
Процесс выделения памяти под объекты
- Если размер объекта превышает 32 Кб, он признаётся большим, память под него выделяется непосредственно из mheap.
- Если размер объекта меньше 16 Кб, используется механизм mcache, который называется tiny allocator.
- Если размер объекта находится в пределах 16–32 Кб, то выясняется, какой класс размера (sizeClass) нужно использовать, затем в mcache выделяется подходящий блок.
- Если в sizeClass, соответствующем mcache, нет доступных блоков, производится обращение к mcentral.
- Если у mcentral нет свободных блоков, тогда обращаются к mheap и выполняется поиск наиболее подходящего mspan. Если размер памяти, необходимый приложению, оказывается большим, чем можно выделить, запрошенный размер памяти будет обработан так, чтобы можно было бы возвратить столько страниц, сколько нужно программе, сформировав новую структуру mspan.
- Если имеющейся у приложения виртуальной памяти всё равно не хватает, производится обращение к операционной системе за новым набором страниц (запрашивается минимум 1 МБ памяти).
На самом деле, на уровне операционной системы, Go запрашивает выделение даже более крупных фрагментов памяти, называемых аренами. Единовременное выделение больших фрагментов памяти позволяет найти компромисс между объёмом памяти, выделенной приложению, и затратными в плане производительности обращениями к операционной системе.
Память, запрашиваемая в куче, выделяется из арены. Рассмотрим этот механизм.
Виртуальная память Go
Взглянем на использование памяти простой программой, написанной на Go:
func main() {
for {}
}

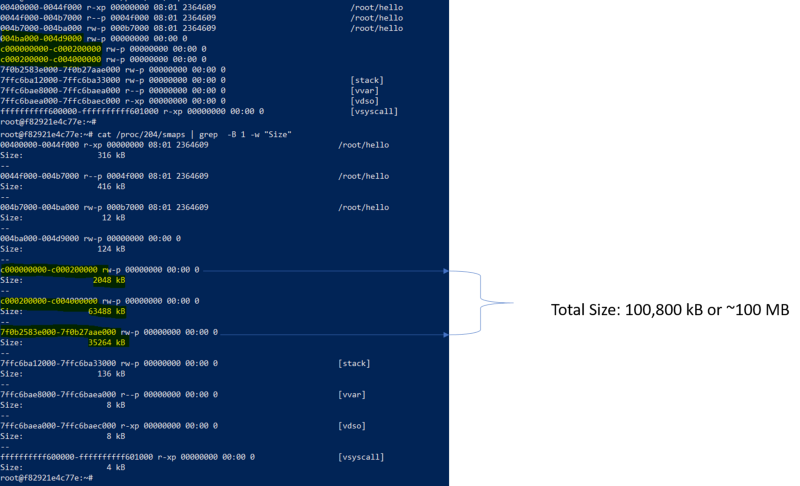
Сведения о процессе программы
Виртуальное адресное пространство даже такой простой программы составляет примерно 100 МБ, в то время как показатель RSS равняется всего 696 Кб. Для начала попытаемся выяснить причину такого расхождения.
Данные по map и smap
Тут можно видеть области памяти, размер которых примерно равен 2 МБ, 64 МБ, 32 МБ. Что это за память?
▍Арены
Оказывается, что виртуальная память в Go состоит из набора арен. Исходный размер памяти, предназначенный для кучи, соответствует одной арене, то есть — 64 МБ (это актуально для Go 1.11.5).
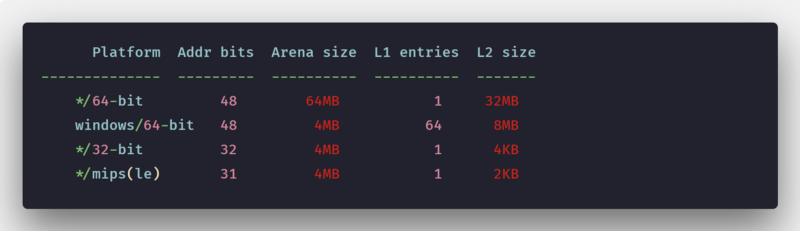
Текущий размер арены в различных системах
В результате память, необходимая для текущих нужд программы, выделяется небольшими порциями. Этот процесс начинается с одной арены размером 64 МБ.
Те числовые показатели, о которых мы тут говорим, не стоит принимать за некие абсолютные и неизменные значения. Они могут меняться. Раньше, например, Go резервировал непрерывное виртуальное пространство заранее, на 64-битных системах размер арены составлял 512 ГБ (тут интересно подумать о том, что произойдёт, если реальная потребность в памяти окажется настолько большой, что соответствующий запрос будет отвергнут mmap?).
Собственно говоря, кучей мы называем набор арен. В Go арены воспринимаются как фрагменты памяти, разделённые на блоки размером 8192 байта (8 Кб).

Одна арена размером 64 МБ
В Go есть ещё пара разновидностей блоков — span и bitmap. Память под них выделяется за пределами кучи, они хранят метаданные арен. Они, в основном, используются при сборке мусора.
Вот общая схема работы механизмов выделения памяти в Go.

Общая схема механизмов выделения памяти в Go
Итоги
В целом можно отметить, что в этом материале мы описали подсистемы работы с памятью Go в весьма общих чертах. Основной идеей работы подсистемы памяти в Go является выделение памяти с использованием различных структур и кэшей разных уровней. При этом учитывается размер объектов, для которых выделяется память.
Представление единого блока непрерывных адресов памяти, получаемого от операционной системы, в виде многоуровневой структуры, повышает эффективность работы механизма выделения памяти за счёт того, что такой подход позволяет избежать блокировок. Выделение ресурсов с учётом размеров объектов, которые нужно хранить в памяти, позволяет уменьшить фрагментацию, и, после освобождения памяти, позволяет ускорить сборку мусора.
Уважаемые читатели! Сталкивались ли вы с проблемами, вызванными неправильной работой с памятью в программах, написанных на Go?

