[Перевод] Machine learning в анализе логов Netflix

Представьте лог на 2,5 гигабайта после неудачной сборки. Это три миллиона строк. Вы ищете баг или регрессию, которая обнаруживается на миллионной строке. Вероятно, найти одну такую строку вручную просто невозможно. Один из вариантов — diff между последней успешной и упавшей сборкой в надежде на то, что баг пишет в журналы необычные строки. Решение Netflix быстрее и точнее LogReduce — под катом.
Netflix и строка в стоге лога
Стандартный md5 diff работает быстро, но выводит не меньше сотни тысяч строк-кандидатов на просмотр, поскольку показывает различия строк. Разновидность logreduce — нечёткий diff с применением поиска k ближайших соседей находит около 40 000 кандидатов, но отнимает один час. Решение ниже находит 20 000 строк-кандидатов за 20 минут. Благодаря волшебству открытого ПО это всего около сотни строк кода на Python.
Решение — комбинация векторных представлений слов, которые кодируют семантическую информацию слов и предложений, и хеша с учетом местоположения (LSH — Local Sensitive Hash), который эффективно распределяет приблизительно близкие элементы в одни группы и далёкие элементы в другие группы. Комбинирование векторных представлений слов и LSH — великолепная идея, появившаяся менее десяти лет назад.
Примечание: мы выполняли Tensorflow 2.2 на CPU и с немедленным выполнением для трансферного обучения и scikit-learnNearestNeighborдля k ближайших соседей. Существуют сложные приближенные реализации ближайших соседей, что были бы лучше для решения проблемы ближайших соседей на основе модели.
Векторное представление слов: что это и зачем?
Сборка мешка слов с k категориями (k-hot encoding, обобщение унитарного кодирования) — типичная (и полезная) отправная точка дедупликации, поиска и проблем сходства неструктурированного и полуструктурированного текста. Такой тип кодирования мешка со словами выглядит как словарь с отдельными словами и их количеством. Пример с предложением «log in error, check log».
{"log": 2, "in": 1, "error": 1, "check": 1}
Такое кодирование также представляется вектором, где индекс соответствует слову, а значение — количеству слов. Ниже показывается фраза «log in error, check log» в виде вектора, где первая запись зарезервирована для подсчета слов «log», вторая — для подсчета слов «in» и так далее:
[2, 1, 1, 1, 0, 0, 0, 0, 0, ...]
Обратите внимание: вектор состоит из множества нулей. Нули — это все остальные слова в словаре, которых нет в этом предложении. Общее число возможных векторных записей или размерность вектора — это размер словаря вашего языка, который часто составляет миллионы слов или более, но сжимается до сотен тысяч с помощью искусныхтрюков.
Посмотрим на словарь и векторные представления фразы «problem authentificating». Слова, соответствующие первым пяти векторным записям, вообще не появляются в новом предложении.
{"problem": 1, "authenticating": 1}
Получается:
[0, 0, 0, 0, 1, 1, 0, 0, 0, ...]
Предложения «problem authentificating» и «log in error, check log» семантически похожи. То есть они по существу одно и то же, но лексически настолько различны, насколько это возможно. У них нет общих слов. В разрезе нечёткого diff мы могли бы сказать, что они слишком похожи, чтобы выделять их, но кодирование md5 и документ, обработанный k-hot с kNN этого не поддерживает.
Сокращение размерности использует линейную алгебру или искусственные нейронные сети для размещения семантически похожих слов, предложений или строк лога рядом друг с другом в новом векторном пространстве. Применяются векторные представления. В нашем примере «log in error, check log» может иметь пятимерный вектор для представления:
[0.1, 0.3, -0.5, -0.7, 0.2]
Фраза «problem authentificating» может быть
[0.1, 0.35, -0.5, -0.7, 0.2]
Эти векторы близки друг к другу в смысле таких мер, как косинусное сходство, в отличие от их векторов мешка со словами. Плотные низкоразмерные представления действительно полезны для коротких документов, например, строк сборки или системного лога.
На самом деле вы заменили бы тысячи или более размерностей словаря всего лишь представлением в 100 размерностей, богатыми информацией (а не пятью). Современные подходы к снижению размерности включают разложение по сингулярным значениям матрицы совместной встречаемости слов (GloVe) и специализированные нейронные сети (word2vec, BERT, ELMo).
А как насчет кластеризации? Вернёмся к логу сборки
Мы шутим, что Netflix — сервис производства логов, который иногда стримит видео. Логирование, стримы, обработка исключений — это сотни тысяч запросов в секунду. Поэтому масштабирование необходимо, когда мы хотим применять прикладное ML в телеметрии и логировании. По этой причине мы внимательны к масштабированию дедупликации текста, к поиску семантического сходства и обнаружению текстовых выбросов. Когда проблемы бизнеса решаются в реальном времени, другого пути нет.
Наше решение включает представление каждой строки в векторе низкой размерности и при необходимости «точную настройку» или одновременное обновление модели встраивания, назначение ее кластеру и определение линий в разных кластерах как «разных». Хеширование с учетом местоположения — вероятностный алгоритм, который позволяет назначать кластеры за константное время и выполнять поиск ближайших соседей за почти константное время.
LSH работает путем сопоставления векторного представления с набором скаляров. Стандартные алгоритмы хеширования стремятся избегать коллизий между любыми двумя совпадающими входами. LSH стремится избежать коллизий, если входные данные находятся далеко друг от друга и продвигает их, если они разные, но расположены близко друг к другу в векторном пространстве.
Вектор представления фразы «log in error, check error» может быть сопоставлен с двоичным числом 01. Затем 01 представляет кластер. Вектор «problem authentificating» с большой вероятностью также может быть отображен в 01. Так LSH обеспечивает нечёткое сравнение и решает обратную задачу — нечёткое различие. Ранние приложения LSH были над многомерными векторными пространствами из набора слов. Мы не смогли придумать ни одной причины, по которой он не работал бы с пространствами векторного представления слов. Есть признаки, что другие думали так же.

Выше изображено использование LSH при размещении символов в той же группе, но в перевернутом виде.
Работа, которую мы сделали для применения LSH и векторных представлений в разрезе обнаружение текстовых выбросов в логах сборки, теперь позволяет инженеру просматривать небольшую часть строк лога, чтобы выявить и исправить ошибки, потенциально критичные для бизнеса. Также он позволяет достичь семантической кластеризации практически любой строки лога в режиме реального времени.
Теперь этот подход работает в каждой сборке Netflix. Семантическая часть позволяет группировать кажущиеся непохожими элементы на основе их значения и отображать эти элементы в отчетах о выбросах.
Несколько примеров
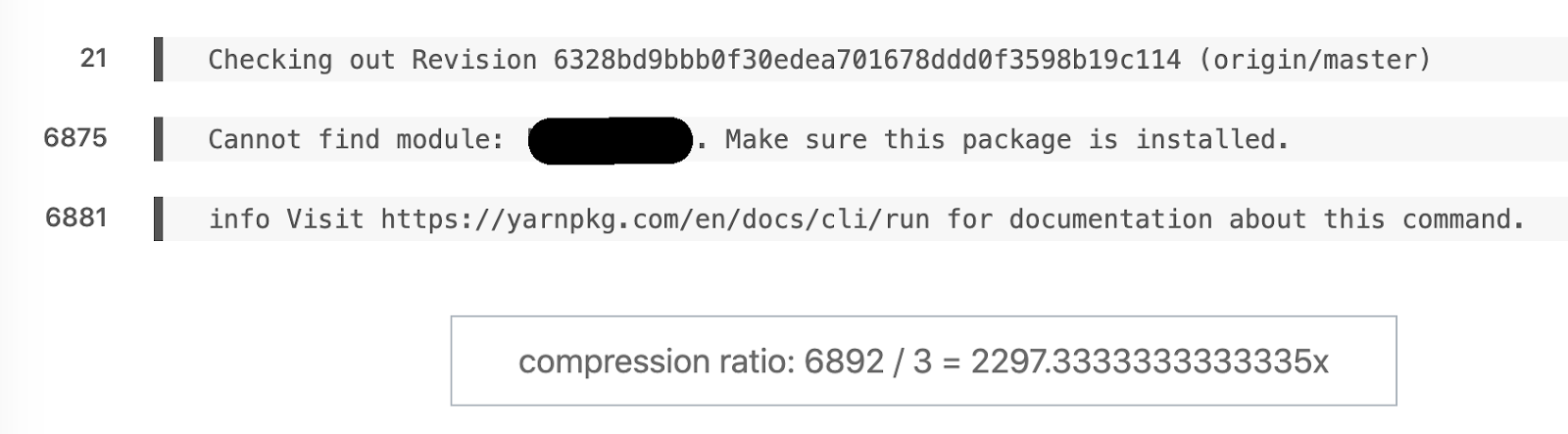
Любимый пример семантического diff. 6892 строк превратились в 3.
Другой пример: эта сборка записала 6044 строки, но в отчете осталась 171. Основная проблема всплыла почти сразу на строке 4036.

Конечно, быстрее проанализировать 171 строку, чем 6044. Но как вообще мы получили такие большие логи сборок? Некоторые из тысяч задач сборки — это стресс-тесты для потребительской электроники выполняются в режиме трассировки. Трудно работать с таким объёмом данных без предварительной обработки.

Коэффициент сжатия: 91366/455 = 205,3.
Есть разные примеры, отражающие семантические различия между фреймворками, языками и сценариями сборки.
Заключение
Зрелость продуктов и SDK с открытым исходным кодом для трансферного обучения позволило решить проблему семантического поиска ближайшего соседа с помощью LSH в очень небольшом количестве строк кода. Мы заинтересовались особыми преимуществами, которые привносят в приложение трансферное обучение и точная настройка. Мы рады возможности решать такие проблемы и помогать людям делать то, что они делают, лучше и быстрее.
Мы надеемся, что вы подумаете о том, чтобы присоединиться к Netflix и стать одним из замечательных коллег, чью жизнь мы облегчаем с помощью машинного обучения. Вовлеченность — основная ценность Netflix, и мы особенно заинтересованы в формировании разных точек зрения в технических командах. Поэтому, если вы занимаетесь аналитикой, инженерией, наукой о данных или любой другой областью и имеете опыт, нетипичный для отрасли, мы особенно хотели бы услышать вас!
Если у вас есть какие-либо вопросы о возможностях в Netflix, обращайтесь к авторам в LinkedIn: Stanislav Kirdey, William High
А как вы решаете проблему поиска в логах?
Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя онлайн-курсы SkillFactory:Eще курсы

