[Перевод] Лучшие новые библиотеки Python за 2022 год
В пост включены библиотеки, которые были запущены или приобрели популярность в этом году, хорошо поддерживаются, а также просто классные и достойные внимания. Подборка в значительной степени ориентирована на библиотеки по ИИ и науке о данных, но сюда так же включен ряд библиотек, которые могут быть полезны для целей, не связанных с наукой о данных.
Без лишних слов, давайте начнем!
Ruff — быстрый линтер
Ruff
Есть ли кто-нибудь, кто не использовал линтеры в 2022 году?
За прошедшие годы сообщество признало, что линтеры являются важной частью процесса разработки программного обеспечения. Они анализируют исходный код на предмет потенциальных ошибок и проблем со стилем, предоставляя ценные отзывы и предложения по улучшению. В конечном итоге, они помогают разработчикам писать более чистый и эффективный код. Чтобы максимально использовать этот процесс, важно иметь быстрый и эффективный линтер. Именно здесь на помощь приходит Ruff.
Ruff — это чрезвычайно быстрый Python-линтер, написанный на языке Rust. Он в 10–100 раз быстрее существующих линтеров и может быть установлен через pip.

В дополнение к линтингу, Ruff может использоваться как продвинутый инструмент преобразования кода, способный обновлять аннотации типов, переписывать определения классов, сортировать импорты и многое другое.
Это мощный инструмент, способный заменить множество других инструментов, включая Flake8, isort, pydocstyle, yesqa, eradicate и даже подмножество pyupgrade и autoflake, при этом работая ну очень быстро.
Определенно стоит добавить в свой арсенал в 2023 году!
python-benedict — словарь на стероидах
python-benedict
Словари являются важной структурой данных в Python, но работа со сложными словарями может оказаться непростой задачей. Встроенный тип dict является мощным, но ему не хватает многих функций, облегчающих доступ и работу с вложенными значениями или преобразование словарей в различные форматы данных и обратно. Если вы столкнулись с трудностями при работе со словарями в Python, python-benedict может стать тем решением, которое вы искали.
benedict наследуется от встроенного типа dict, что означает, что он полностью совместим с существующими словарями и может быть использован в качестве замены в большинстве случаев.
Одной из ключевых особенностей benedict является поддержка keylists и keypaths. Это упрощает доступ к значениям в сложных словарях и работу с ними без необходимости вручную копаться во вложенных уровнях. Например:
d = benedict()
# set values by keypath
d['profile.firstname'] = 'Fabio'
d['profile.lastname'] = 'Caccamo'
print(d) # -> { 'profile':{ 'firstname':'Fabio', 'lastname':'Caccamo' } }
print(d['profile']) # -> { 'firstname':'Fabio', 'lastname':'Caccamo' }
# check if keypath exists in dict
print('profile.lastname' in d) # -> True
# delete value by keypath
del d['profile.lastname']В дополнение, benedict также предоставляет широкий спектр ярлыков ввода-вывода для работы с различными форматами данных. Вы можете легко читать и записывать словари в такие форматы, как JSON, YAML и INI, а также в более специализированные форматы, такие как CSV, TOML и XML. Кроме того, он поддерживает множество операций ввода-вывода, таких как filepath (чтение/запись), url (только чтение) и s3 (чтение/запись).
Memray — профайлер памяти
Memray

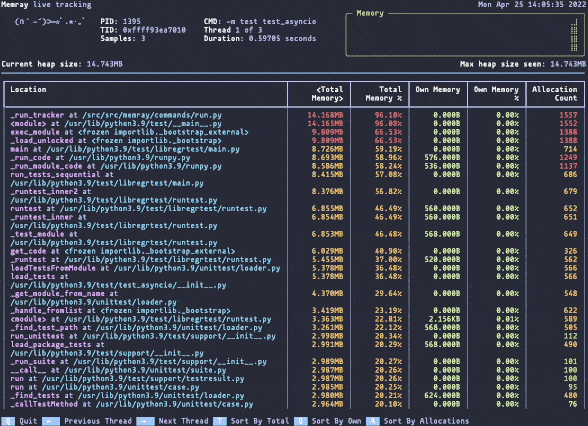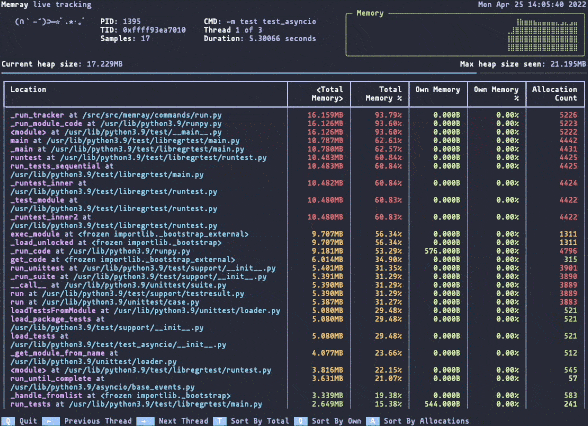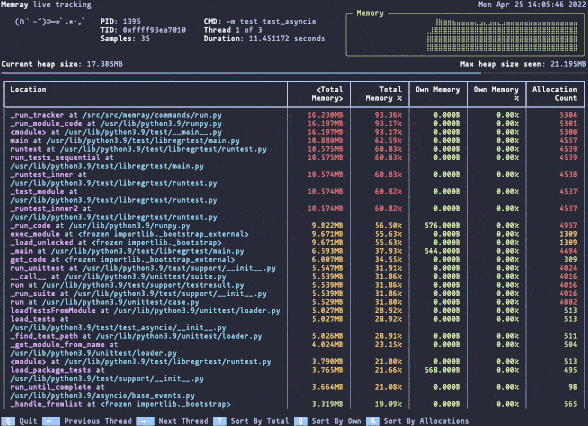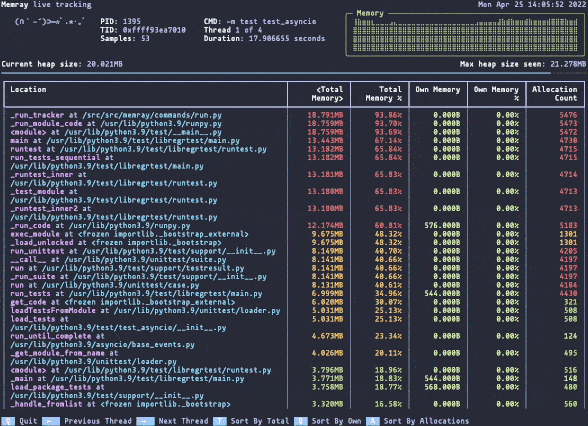
Оптимизация использования памяти в ваших системах жизненно важна для повышения их производительности и стабильности. Утечки памяти могут привести к тому, что программы будут потреблять все большее количество памяти, снижать общую производительность системы и в конечном итоге аварийно завершаться. Хотя Python не собирает мусор и в целом прост в работе, он не защищает вас от этих проблем. Ничто не предотвращает circular dependcy или недостижимые объекты; тем более, если мы говорим о расширениях C/C++.
Профайлер памяти может помочь вам выявить и устранить эти проблемы, что делает его незаменимым инструментом для оптимизации использования памяти в ваших программах. Именно здесь на помощь приходит Memray!
Это профайлер памяти, который отслеживает выделение памяти в коде Python, родных модулях расширения и самом интерпретаторе Python, обеспечивая всестороннее представление об использовании памяти. Memray генерирует различные отчеты, включая графики, чтобы помочь вам проанализировать собранные данные и выявить такие проблемы, как утечки и «горячие точки». Он работает быстро и с Python и собственными потоками, что делает его универсальным инструментом для отладки проблем с памятью в многопоточных программах.
Codon — Python компилятор с использованием LLVM
Codon

Мы все любим Python за его простоту и удобство использования, но иногда нам нужно немного больше скорости выполнения. Даже со всеми оптимизациями, интерпретаторы Python (например, CPython) не слишком производительны. Когда нужно еще больше увеличить производительность, на помощь приходят компиляторы. Они преобразуют наш Python-код в машинный код, который может быть непосредственно выполнен процессором, минуя шаг интерпретатора и давая нам серьезный прирост производительности.
Codon — это высокопроизводительный компилятор Python, который может даже конкурировать с C/C++ по скорости, с ускорением в 10–100 раз и более (single thread). Он может быть использован в коде Python с помощью декоратора @codon.jit или путем вызова обычных функций и библиотек Python из Codon.
Бесплатного сыра не бывает, поэтому вам, скорее всего, придется внести некоторые изменения в ваш Python-код, чтобы он мог быть скомпилирован Codon. Но ограничения, которые Codon накладывает на язык, в конечном итоге позволяют добиться прироста производительности. Тем не менее, компилятор подскажет вам, выдавая подробные сообщения об ошибках, которые определят и помогут вам устранить несовместимость.

LangChain — строим приложения с помощью Large Language Models (LLM)
LangChain
В этом году генеративный ИИ взял мир штурмом. Большую часть этого процесса составляют большие языковые модели (LLM).
Много кода, который мы написали за последние годы для решения проблем ИИ, мы можем просто выбросить и заменить на LLM (например, GPT-3 или его эволюции — InstructGPT или ChatGPT — T5, или любой другой), и мы стали свидетелями рождения нового языка программирования для интерфейса LLM: текстовые подсказки (prompt engineering).
Именно для того, чтобы помочь использовать всю мощь LLM, и существует LangChain.
Во-первых: при любом серьезном использовании LLM, как правило, не нужно думать о подсказках как о чем-то единичном, а скорее как о комбинации вещей: шаблоны, пользовательский ввод и примеры ввода/вывода, которые LLM может взять за основу. LangChain помогает упростить это «управление подсказками», предоставляя интерфейсы для прямого построения различных подсказок на основе отдельных компонентов.
Во-вторых, для построения подсказок иногда необходимо вводить внешние знания (или даже другие модели). Например, представьте, что вам нужно выполнить запрос к базе данных, чтобы извлечь имя клиента для персонализированного электронного письма. Это и есть концепция цепочек, и LangChain предоставляет для этого унифицированный интерфейс.
Кроме того, существует концепция получения и дополнения данных, чтобы LLM мог работать с вашими собственными данными, а не с «общими» данными, на которых обучаются модели.
С помощью LangChain можно сделать еще много чего интересного, например, подготовиться к переходу на другую модель/провайдера без изменения кода.
Безусловно, это инновационный инструмент, который, как мы ожидаем, получит большое развитие в 2023 году!
Fugue — легкий distributed computing
fugue
Если вы знакомы с Pandas или SQL, вы знаете, что эти инструменты отлично подходят для работы с небольшими и средними наборами данных. Но при работе с большими объемами данных для их эффективной обработки часто требуется распределенная вычислительная среда, такая как Spark. Дело в том, что Spark — это совсем другой зверь, нежели Pandas или SQL. Синтаксис и концепции совершенно разные, и перенос кода с одного на другой может оказаться сложной задачей. Именно здесь на помощь приходит Fugue.
Fugue — это библиотека, облегчающая работу с такими фреймворками распределенных вычислений, как Spark, Dask и Ray. Она предоставляет единый интерфейс для распределенных вычислений, который позволяет выполнять код на Python, pandas и SQL на Spark, Dask и Ray с минимальными изменениями.
Лучшей отправной точкой является использование функции transform () в Fugue. Она позволяет распараллелить выполнение одной функции, перенеся ее на Spark, Dask или Ray. Вот пример, где функция map_letter_to_food () передается в механизм выполнения Spark:
import pandas as pd
from typing import Dict
from pyspark.sql import SparkSession
from fugue import transform
input_df = pd.DataFrame({"id":[0,1,2], "value": (["A", "B", "C"])})
map_dict = {"A": "Apple", "B": "Banana", "C": "Carrot"}
def map_letter_to_food(df: pd.DataFrame, mapping: Dict[str, str]) -> pd.DataFrame:
df["value"] = df["value"].map(mapping)
return df
spark = SparkSession.builder.getOrCreate()
# use Fugue transform to switch execution to spark
df = transform(input_df,
map_letter_to_food,
schema="*",
params=dict(mapping=map_dict),
engine=spark
)
print(type(df))
df.show()
+---+------+
| id| value|
+---+------+
| 0| Apple|
| 1|Banana|
| 2|Carrot|
+---+------+ Fugue позволяет поддерживать единую кодовую базу для проектов Spark, Dask и Ray, где логика и исполнение полностью разделены, что избавляет программистов от необходимости изучать каждый из различных фреймворков.
У библиотеки также есть несколько других интересных функций и растущее сообщество, так что обязательно ознакомьтесь с ней!
Diffusers — генеративные модели AI
Diffusers

2022 год навсегда останется в памяти как год, когда генеративный ИИ преодолел границы сообщества ИИ и вышел за его пределы. В значительной степени это произошло благодаря diffusion моделям, которые привлекли к себе большое внимание благодаря своим впечатляющим возможностям в создании высококачественных изображений. DALL-E 2, Imagen и Stable Diffusion — вот лишь несколько примеров diffusion моделей, которые произвели фурор в этом году. Их результаты вызвали обсуждение и восхищение своей способностью генерировать изображения, которые расширяют границы того, что ранее считалось возможным — даже экспертами в области ИИ.
Библиотека Hugging Face’s Diffusers представляет собой набор инструментов и методов для работы с такими моделями, включая модель Stable Diffusion, которая оказалась особенно эффективной при создании высокореалистичных и детализированных изображений. Библиотека также включает инструменты для оптимизации производительности моделей генерации изображений и анализа результатов экспериментов по генерации изображений.
Начать использовать эту библиотеку для генерации текста в изображение можно, просто добавив эти несколько строк кода:
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]LineaPy — jupyter notebookи в продакшне
LineaPy
Jupyter — чрезвычайно полезный инструмент для создания прототипов и разработки кода. Они позволяют легко смешивать код, графики, медиа и интерактивные виджеты в одном документе, что облегчает документирование и понимание кода в процессе его разработки. Jupyter являются идеальной игровой площадкой для экспериментов с кодом и тестирования идей, что может быть особенно удобно для задач анализа данных и машинного обучения. Но по мере развития идей, когда человек доволен результатом и хочет запустить код в продакшн, начинают проявляться проблемы.
Код в блокнотах не всегда может быть структурирован таким образом, чтобы его было легко развернуть в проде. Нужно взять и переписать код в другом месте, желательно следуя лучшим практикам? Это наиболее распространенный подход, но его недостаток в том, что если позже вы захотите что-то улучшить или отладить, вы потеряете интерактивность блокнота. Поэтому теперь вам придется вести и блокнот, и отдельный продакшн код, что далеко не идеально.
Есть путь к лучшему, благодаря LineaPy.
LineaPy — это библиотека Python, которая помогает быстро перейти от создания прототипов к созданию надежных конвейеров данных. Она берет ваш беспорядочный блокнот и помогает очистить и рефакторить код, облегчая его запуск в системе оркестрирования или планировщиках заданий, таких как cron, Apache Airflow или Prefect.
Он также помогает в воспроизводимости: в нем есть концепция «артефактов», в которых заключены как данные, так и код, что может помочь вам отследить, как были получены значения. На высоком уровне LineaPy отслеживает последовательность выполнения кода, чтобы сформировать полное понимание кода и его контекста.
И что самое интересное? Его очень просто интегрировать, и он может работать в среде Jupyter всего с двумя строками кода!
Обязательно ознакомьтесь с документацией, которая отлично демонстрирует проблемы, решаемые инструментом, на очень полных примерах.
whylogs — мониторинг моделей
whylogs
По мере того как модели искусственного интеллекта начинают приносить реальную пользу бизнесу, их поведение в продакшне должно постоянно контролироваться, чтобы убедиться, что ценность сохраняется в течение долгого времени. То есть необходимо иметь способ определить, что прогнозы модели надежны и точны и что входные данные, которые подаются на модель, не сильно отклоняются от данных, которые использовались для ее обучения.
Но мониторинг моделей не ограничивается только моделями ИИ — он может быть применен к любому виду моделей, включая статистические и математические модели.
whylogs — это библиотека с открытым исходным кодом, которая позволяет регистрировать и анализировать любые данные. Она предоставляет ряд функций, начиная с возможности генерировать сводки наборов данных: профили whylogs.
Профили собирают статистику по исходным данным, такую как распределение, недостающие значения и многие другие настраиваемые метрики. Они вычисляются локально с помощью библиотеки и даже могут быть объединены для анализа в распределенных и потоковых системах. Они формируют представление данных, которое удобно тем, что не нужно раскрывать сами данные, а только метрики, полученные из них — что хорошо для обеспечения конфиденциальности.
Профили легко генерируются. Например, чтобы сгенерировать профиль из Pandas DataFrame, нужно сделать следующее:
import whylogs as why
import pandas as pd
#dataframe
df = pd.read_csv("path/to/file.csv")
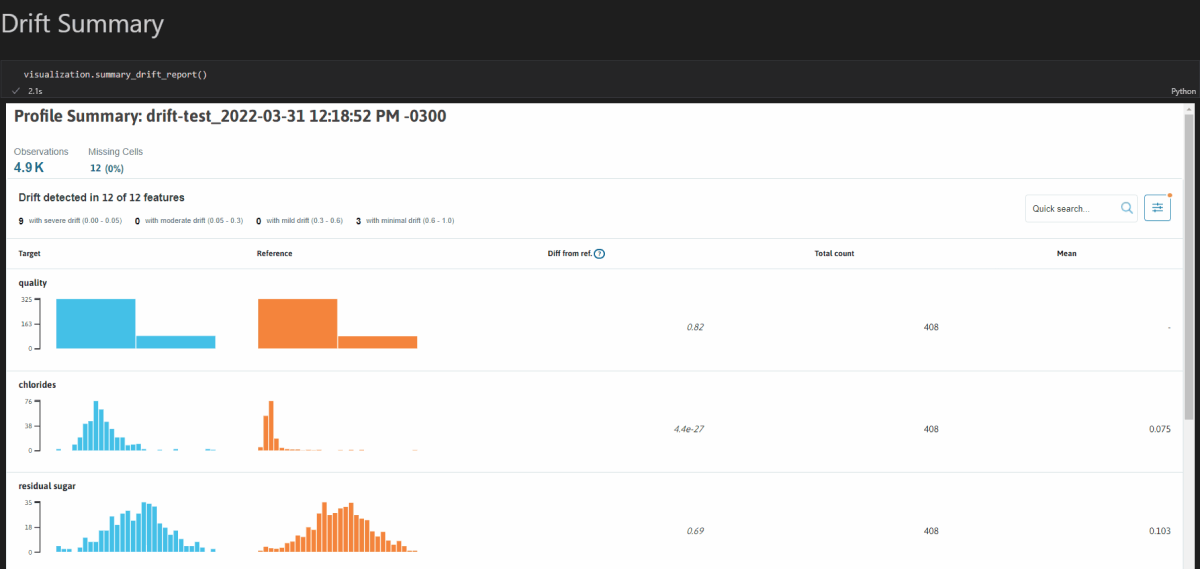
results = why.log(df)Но профили полезны лишь настолько, насколько вы решите с ними работать. Для этого визуализация просто необходима. Вы можете установить модуль viz, используя pip install «whylogs[viz]», который может создавать интерактивные отчеты для вас. Вот пример отчета о изменении природы данных внутри Jupyter Notebook:
Mito — excel таблички внутри jupyer notebookов
Mito
В эпоху науки о данных многие люди переходят от анализа данных вручную в таблицах к написанию кода для этого. Но нельзя отрицать, что таблицы являются привлекательным инструментом, предоставляя упорядоченный интерфейс для редактирования и мгновенную обратную связь, позволяющую быстро проводить эксперименты.
Мы постоянно работаем с таблицами. Но если мы хотим повторить тот же эксперимент с новыми данными, мы должны начать с нуля! Код намного лучше справляется с этой задачей, экономя наше драгоценное время.
Можем ли мы получить лучшее из двух миров? Познакомьтесь с Mito.
Mito — это библиотека, позволяющая работать с данными в электронном виде в Jupyter Notebook. Она позволяет импортировать и редактировать файлы CSV и XLSX, создавать поворотные таблицы и графики, фильтровать и сортировать данные, объединять наборы данных и выполнять множество других задач по работе с данными.
И самая важная особенность: Mito будет генерировать Python-код, соответствующий каждому вашему редактированию!

Mito также поддерживает использование формул в стиле Excel и предоставляет сводную статистику для столбцов данных. Он разработан как первый инструмент в наборе инструментов науки о данных, что означает, что он создан как удобный инструмент для исследования и анализа данных.
Инструменты, подобные Mito, снижают барьер входа в мир науки о данных, позволяя людям, знакомым с таким программным обеспечением, как Excel или Google Sheets (почти все?), быстро начать создавать код.
Еще больше примеров использования ML в современных сервисах можно посмотреть в моем телеграм канале. Я пишу про ML, стартапы и релокацию в UK для IT специалистов.
