[Перевод] Краткая история масштабирования LinkedIn
Примечание переводчика: Мы в «Латере» занимаемся созданием биллинга для операторов связи. Мы будем писать об особенностях системы и деталях ее разработки в нашем блоге на Хабре (например, об обеспечении отказоустойчивости), но почерпнуть что-то интересное можно и из опыта других компаний. Сегодня мы представляем вашему вниманию адаптированный перевод заметки главного инженера LinkedIn Джоша Клемма о процессе масштабирования инфраструктуры социальной сети.
Сервис LinkedIn был запущен в 2003 году с целью создания и поддержания сети деловых контактов и расширения возможностей поиска работы. За первую неделю в сети зарегистрировалось 2 700 человек. Спустя несколько лет число продуктов, клиентская база и нагрузка на серверы заметно выросли.
Сегодня в LinkedIn насчитывается более 350 миллионов пользователей по всему миру. Мы проверяем десятки тысяч веб-страниц каждую секунду, каждый день. На мобильные устройства сейчас приходится более 50% нашего трафика по всему миру. Пользователи запрашивают данные из наших бэкенд-систем, которые, в свою очередь, обрабатывают по несколько миллионов запросов в секунду. Как же мы этого добились?
Ранние годы: Leo
Мы начали создавать сайт LinkedIn так же, как сегодня создаются многие другие сайты — в виде монолитного приложения, которое справляется со всеми задачами. Это приложение получило название Leo. На нем размещались веб-сервлеты, которые обслуживали все веб-страницы, учитывали бизнес-логику и обеспечивали связь с несколькими базами данных LinkedIn.
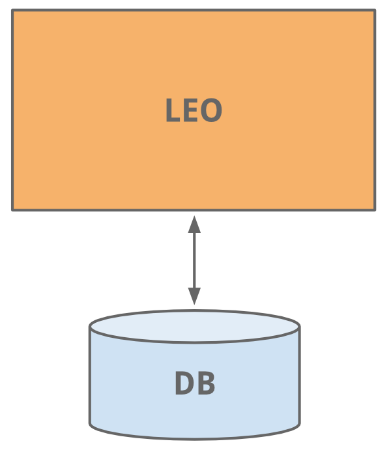
Старая добрая разработка веб-сайтов — все так легко и просто
Граф пользователей
В социальной сети, прежде всего, необходимо наладить связь между ее пользователями. Для повышения эффективности и производительности нам нужно было создать систему, которая бы запрашивала данные о связях в имеющемся графе, а сама хранилась в памяти сети. При таком новом подходе к использованию профилей, систему необходимо было масштабировать независимо от Leo. Так у нас появилась отдельная система для нашего графа пользователей, которую мы назвали Cloud: она стала первым сервисом LinkedIn. Этот отдельный сервис и приложение Leo мы связали при помощи технологии RPC (удаленный вызов процедур), реализованной на Java.
Примерно в это же время мы задумались о необходимости создания поисковой системы. Наш сервис на основе графа пользователей стал передавать информацию в новую поисковую службу на базе Lucene.
Копии базы данных
По мере роста сайта рос и Leo: наряду с его значимостью и влиянием увеличивалась и сложность приложения. К снижению сложности привело распределение нагрузки, так как в работе находилось несколько экземпляров Leo. Тем не менее, повышенная нагрузка влияла на работу важнейшей системы LinkedIn — базы данных профилей ее пользователей.
Самым простым решением было обычное вертикальное масштабирование: мы добавили больше процессоров и памяти в систему. Так мы выиграли немного времени, но нужно было проводить дальнейшее масштабирование. База данных профилей отвечала как за чтение данных, так и за их запись, поэтому было создано несколько дочерних копий (Slave) базы данных, которые синхронизировались с основной базой данных (Master) при помощи самой первой версии Databus (теперь и с открытым исходным кодом). Эти копии были предназначены для чтения всех данных, и мы выстроили логику для того, чтобы определять, когда безопаснее и целесообразнее считывать данные с реплики, чем с основной базы данных.
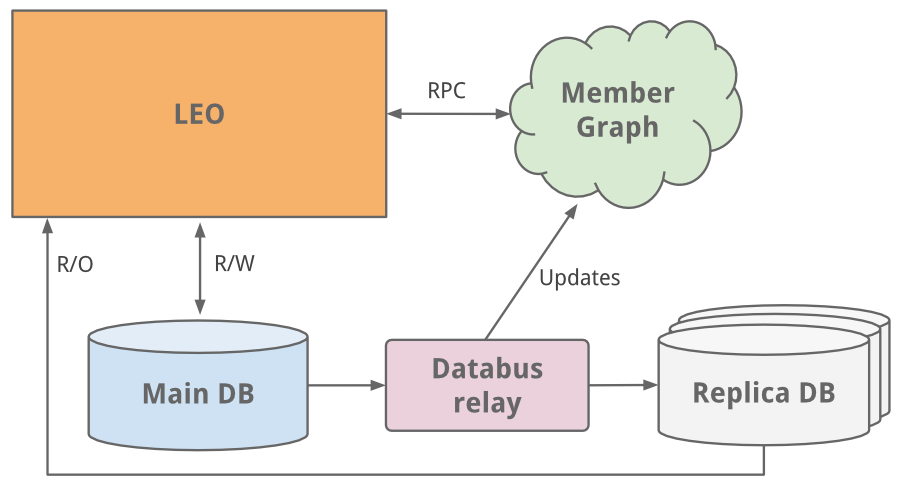
* В связи с тем, что модель Master-Slave являлась среднесрочным решением, мы решили провести секционирование баз данных
Наш сайт привлекал все больше и больше трафика, в связи с чем наше монолитное приложение Leo стало часто зависать. Найти и устранить причину, а также отладить приложение с новым кодом было не так-то просто. Высокая отказоустойчивость очень важна для LinkedIn. Поэтому было ясно, что нам необходимо «убить Leo» и разбить его на множество мелких сервисов, обладающих рядом функций и при этом не хранящих информацию о предыдущем состоянии.

«Убить Leo» — таков был девиз нашей компании на протяжении нескольких лет…
Сервис-ориентированная архитектура
В ходе разработки стали выделяться микросервисы для связи API-интерфейсов и бизнес-логики — примером служат наши платформы для поиска, общения и создания профилей и групп. Позднее для таких областей, как подбор персонала и общий профиль, были выделены уровни представления. Вне приложения Leo были созданы абсолютно новые сервисы для новых продуктов. С течением времени в каждой функциональной области формируется свой вертикальный стек.
Мы установили фронтенд-серверы, чтобы можно было извлекать данные из разных доменов, учитывать логику представления и создавать HTML-страницы с помощью технологии JSP (JavaSever Pages). Кроме того, мы разработали сервисы на промежуточном уровне, чтобы с их помощью предоставлять доступ к данным через API, и бэкенд-сервисы хранения данных пользователей, чтобы обеспечить надежный доступ к базе/базам данных. К 2010 году у нас уже насчитывалось более 150 отдельных сервисов. Сегодня их число превышает 750.
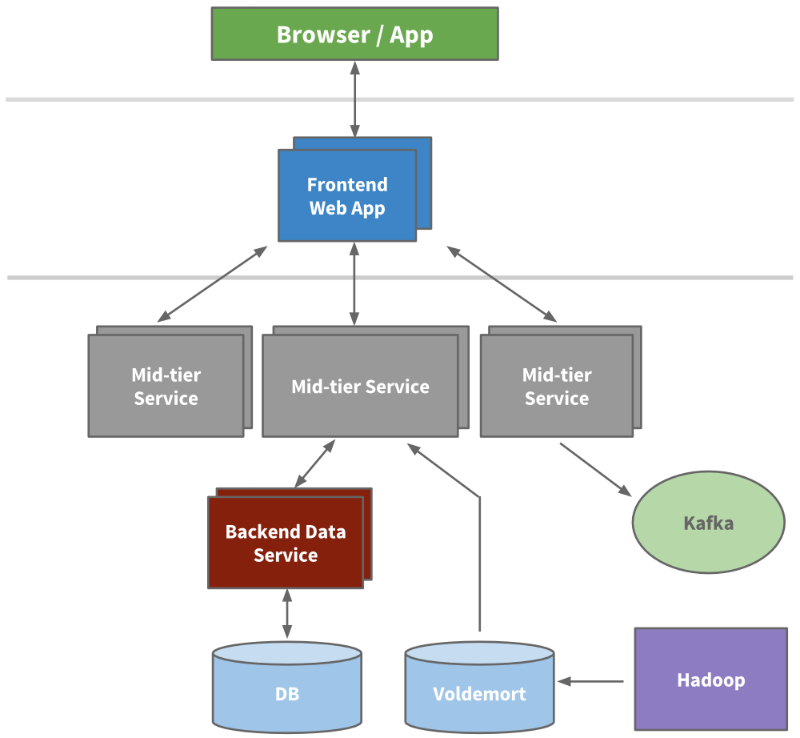
Пример сервис-ориентированной архитектуры в LinkedIn
Так как состояния не сохраняются, масштабирование можно провести путем запуска новых экземпляров любого из сервисов и использования выравнивателя нагрузки. Мы начали активно следить за тем, какую нагрузку может выдержать каждый из сервисов, предварительно выделив все необходимые ресурсы и подготовив средства наблюдения за производительностью.
Кэширование
Компания переживала бурный рост и планировала расширяться дальше. Мы знали, что можем снизить общую нагрузку, увеличив число уровней кэш-памяти. Во многих приложениях стали вводиться промежуточные уровни кэша, как, например, в случаях с Memcached и Couchbase. Также мы увеличили кэш наших баз данных и стали пользоваться хранилищем Voldemort с предварительно вычисляемыми результатами, когда это было необходимо.
Со временем мы удалили многие промежуточные уровни кэша. В них хранились данные, извлеченные из различных доменов. На первый взгляд кэширование кажется очевидным способом снижения нагрузки, однако сложность инвалидации и структуры графа вызовов оказывается чрезмерно высокой. Максимально близкое расположение кэш-памяти к хранилищам данных сокращает время ожидания, позволяет проводить горизонтальное масштабирование и снижает когнитивную нагрузку.
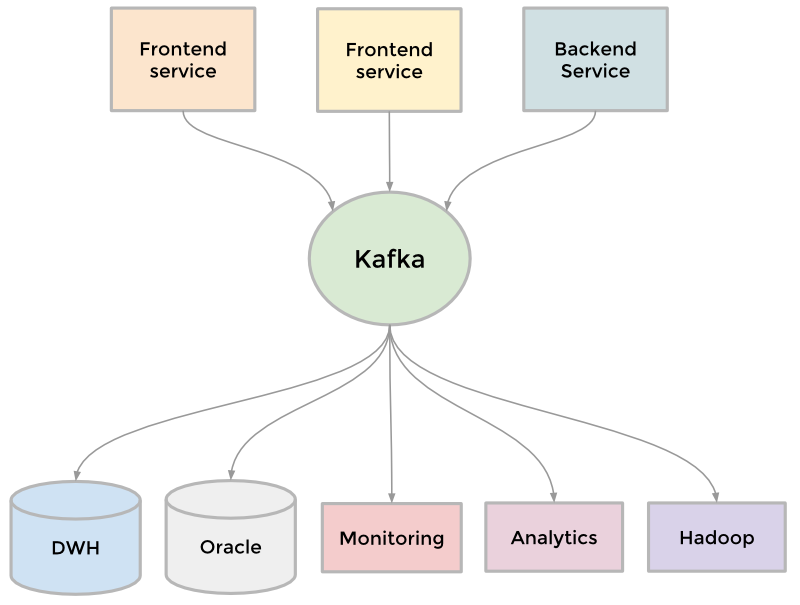
Kafka
Чтобы собрать растущие объемы данных воедино, LinkedIn разработал несколько типов конвейеров для передачи потока данных и их организации в очереди. К примеру, нам нужно было передавать данные в хранилище, отправлять пакеты данных между рабочими процессами Hadoop для проведения анализа, собирать логи каждого сервиса и различные статистические показатели, например, количество просмотров страниц, создать систему очередей в своей системе обмена сообщениями inMail, а также выдавать актуальную информацию о пользователях сразу после обновления их профилей.
По мере расширения сайта появлялось все больше конвейеров. Сайт нуждался в масштабировании, следовательно, и каждый отдельный конвейер также нуждался в масштабировании. Чем-то нужно было жертвовать. В итоге мы разработали распределенную систему обмена сообщениями под названием Kafka. Она стала универсальным конвейером, основанным на принципе хранения проведенных операций и учитывающим возможность увеличения скорости и масштабируемость. Kafka предоставляла практически моментальный доступ к любому хранилищу данных, помогала в работе с вакансиями при помощи Hadoop, позволяла нам проводить анализ в режиме реального времени, значительно улучшила мониторинг нашего сайта и систему оповещения, а также дала возможность визуально отображать графы вызовов и следить за их изменениями. Сегодня Kafka обрабатывает более 500 миллиардов запросов в день.
Kafka как универсальное средство передачи данных
InVersion
Масштабирование можно рассматривать с разных точек зрения, в том числе с организационной. В конце 2011 года LinkedIn запустил внутренний проект под названием InVersion. Благодаря ему мы приостановили разработку отдельных функций: он позволил всей компании сосредоточиться на оборудовании, инфраструктуре, внедрении и продуктивности разработчиков. В результате мы достигли определенного уровня гибкости, необходимой для разработки новых масштабируемых продуктов, которые у нас есть сегодня.
Наши дни: Rest.li
После того, как мы перешли с Leo на сервис-ориентированную архитектуру, API-интерфейсы наших команд, доступ к которым осуществлялся через RPC на Java, оказались несовместимыми и тесно связанными с уровнем представления. Со временем ситуация только ухудшалась. Чтобы решить проблему, мы создали новую модель API и назвали ее Rest.li. Rest.li стала шагом в сторону архитектуры, ориентированной на модель данных. Она строилась на единой модели RESTful API, не хранящей состояния: этой моделью теперь могла пользоваться вся компания.
В итоге наши новые API-интерфейсы на JSON, который стал использоваться вместо HTTP, упростили работу с клиентскими приложениями, написанными не на Java. Сегодня большинство разработчиков LinkedIn программирует на Java, но в компании есть масса клиентов на Python, Ruby, Node.js, и C++, разработанных как штатными сотрудниками, так и программистами из поглощенных LinkedIn компаний.
Отказ от RPC сделал нас менее зависимыми от уровней представления и избавил нас от проблем совместимости с предыдущими версиями. Плюс ко всему, использование службы динамического обнаружения устройств (D2) вместе с Rest.li позволило нам автоматизировать процессы балансировки нагрузки, обнаружения устройств и масштабирования клиентского API каждого сервиса.
На данный момент в LinkedIn имеется более 975 ресурсов на основе модели Rest.li, а наши дата-центры обрабатывают более 100 миллиардов запросов Rest.li в день.
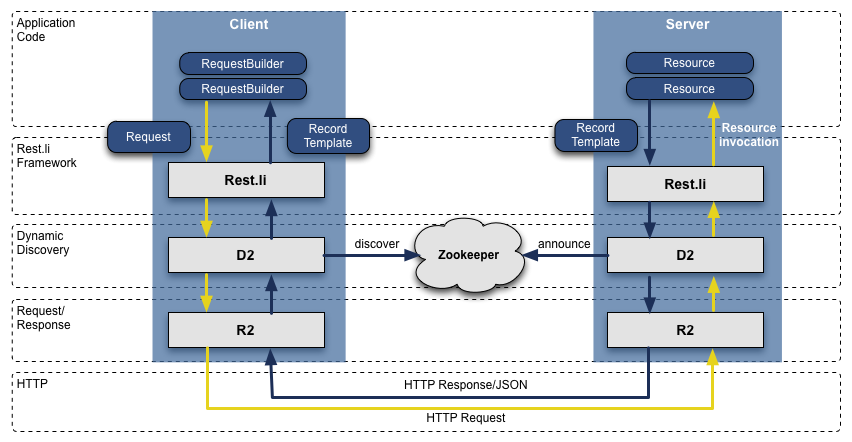
Стек Rest.li R2/D2
Суперблоки
Сервис-ориентированные архитектуры идеально подходят для того, чтобы разделять домены и масштабировать сервисы независимо друг от друга. Но есть и негативный аспект. Многие наши приложения обрабатывают данные самых разных типов, совершая, таким образом, по несколько сотен обращений к клиентской части. Все эти обращения обычно сводят к понятиям «графа вызовов» и «разветвления». К примеру, каждое обращение к странице профиля вызывает не только данные профиля: это и фотографии, и контакты, и группы, а также информация о подписках, публикациях в блоге и степенях связности нашего графа, рекомендации и многое другое. Этим графом было довольно сложно управлять, и сложность его постепенно увеличивалась.
Мы воспользовались принципом суперблока, который заключается в формировании группы бэкенд-сервисов с единым доступом к API. Благодаря этому принципу команда наших специалистов занимается оптимизацией блока, одновременно следя за графом вызовов каждого клиента.
Многопользовательские дата-центры
Будучи международной компанией с растущей клиентской базой, мы должны проводить масштабирование, задействуя в обработке трафика более одного дата-центра. Мы начали решать эту проблему еще несколько лет назад: вначале обслуживанием общих профилей клиентов стали заниматься два дата-центра — в Лос-Анджелесе и Чикаго.
После их испытания мы решили заняться улучшением своих сервисов, чтобы наладить репликацию данных, обратную связь из различных источников, события односторонней репликации данных и соединение пользователя с более близким к нему/ней дата-центром.
Большинство наших баз данных хранятся в Espresso — современном многопользовательском хранилище данных нашей компании. Оно было построено с учетом требований многопользовательских дата-центров. Espresso предоставляет поддержку по принципу Master-Master и отвечает за более сложные технологии репликации.
Наличие нескольких дата-центров чрезвычайно важно для поддержания работы сайта и высокой отказоустойчивости. Нам приходится избегать наличия даже малейших неполадок не только в каждом отдельном сервисе, но и на всем сайте. Сегодня в распоряжении LinkedIn имеется три основных дата-центра и несколько дополнительных точек присутствия по всему миру.
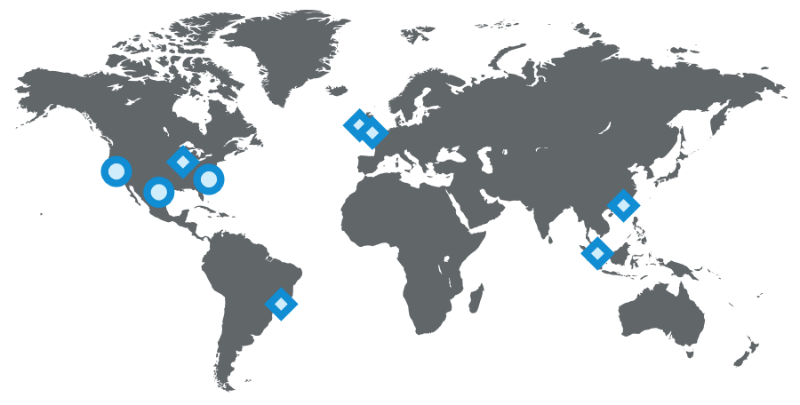
Расположение разных типов оборудования LinkedIn по состоянию на 2015 год (кружочками обозначены дата-центры, ромбиками — точки присутствия)
Чего еще мы добились?
Как вы понимаете, на деле провести масштабирование гораздо сложнее. За эти несколько лет наши команды разработчиков и инженеров проделали титаническую работу, из которой стоит выделить несколько отдельных проектов.
Многие особо важные системы нашей компании имеют свою богатую историю развития в процессе масштабирования. Отдельно стоит выделить граф пользователей (наш первый сервис вне приложения Leo), поиск (наш второй сервис), новостную ленту, платформу для общения и серверное приложение для отображения профилей пользователей.
Мы разработали информационную инфраструктуру для долгосрочного роста. Впервые мы это ощутили после создания Databus и Kafka. Затем появились Samza для работы с потоками данных, Espresso и Voldemort в качестве инструментов для хранения, Pinot для анализа наших систем и другие пользовательские решения. Помимо прочего, наше оборудование стало значительно лучше, так что разработчики теперь могут самостоятельно пользоваться этой инфраструктурой.
Мы разработали оффлайн-систему управления бизнес-процессами, используя Hadoop и хранилища данных Voldemort, чтобы заранее предоставлять такую информацию, как «Люди, которых вы можете знать», «Похожие профили», «Успешные выпускники» и местонахождение профиля.
Мы пересмотрели свой подход к фронтенду, добавив шаблоны клиентской части («Страница профиля», «Страницы университетов»). Они добавляют интерактивности приложениям, запрашивая с серверов только те объекты, которые частично или полностью написаны на JSON. Кроме этого, шаблоны попадают в кэш сети CDN (сеть доставки контента) и браузера. Мы также начали использовать BigPipe и фреймворк Play, изменив свою модель с потокового веб-сервера на неблокирующий и асинхронный.
Поверх кода приложений мы ввели несколько уровней прокси-серверов, используя Apache Traffic Server и HAProxy для балансировки нагрузки, соединения с дата-центром, безопасности, «умной» маршрутизации, рендеринга серверной части и много другого.
И вдобавок ко всему мы продолжаем увеличивать производительность своих серверов, оптимизируя оборудование, проводя настройку усовершенствованной системы памяти и используя новейшие среды выполнения Java.
