[Перевод] Как в Twitch проводят A/B тестирование

Эксперименты — одна из центральных функций научного подразделения сайта потокового видео Twitch. Мы работаем в тесном контакте с менеджерами по продукции, чтобы тестировать новые идеи и функции. В прошлом мы использовали собственные инструменты для проведения А/В-экспериментов в сети и на наших мобильных приложениях. Недавно мы попробовали новый подход для проведения экспериментов на нашем приложении для Android, используя функцию поэтапного развёртывания из Google Play.
Поэтапное развёртывание позволяет разработчикам выпустить новую сборку к некоторому подмножеству пользовательской базы. Вместо того чтобы реализовывать A/B-логику внутри самого приложения, разработчики, вводя блоки «if», поддерживающие отдельные кодовые пути обработки и управления, могут создать две отдельные версии и развернуть их одновременно. Эта особенность полезна при проведении серьёзных изменений в каком-нибудь приложении, например, при редизайне пользовательского интерфейса. Отрицательная сторона поэтапных развёртываний — отсутствие управления A/B-разветвлениями для экспериментов. Поэтапное развёртывание используют обычно в следующих случаях:
1.Тестирование устойчивости нового релиза;
2. Измерение использования новых функций.
Так как новую версию приложения получает только некоторое подмножество пользователей, то эта функция — отличный способ опробовать новые идеи и откатить их при возникновении каких-либо проблем. Она также позволяет разработчикам измерить использование новых функций в приложении Android. В Twitch имеется дополнительный вариант использования:
3. Измерение влияния нового релиза на имеющиеся характеристики
Мы хотели бы использовать поэтапные развёртывания для измерения влияния новых релизов на существующий набор характеристик, таких как, например, ежедневные активные пользователи Эта особенность особенно полезна при проведении серьёзных изменений некоторых приложениях, где внедрение А/В-логики для нескольких версий приложения в каком-то одном двоичном файле представляется сложным.
Нашим первоначальным подходом было использование А/B-тестирования с функцией поэтапного развёртывания. В таком подходе магазин Google Play выбирает подмножество пользователей, которым предоставляется право на тестовую версию приложения. Пользователи, получившие такое право и обновившие — автоматически или вручную — приложение до новой версии, помечаются как тестовая группа. Пользователи, не перешедшие на новую версию, помечаются как контрольная группа; эта группа может иметь в своём составе пользователей, которые получили право на тестовую версию приложения, но не установили обновление. Пользователи, перешедшие на новую версию лишь через какой-то фиксированный интервал времени (в нашем эксперименте — 1 неделя), не входили в эксперимент, поскольку они перекрывали обе группы.
Google Play использует рандомизированный подход для выбора различных групп эксперимента, и мы можем измерять ключевые характеристики по этим группам. Однако мы обнаружили смещения в данных, которые препятствовали применению наших стандартных подходов для A/B-тестирования.

График выше показывает среднее количество суточных сеансов на одного активного пользователя для наших тестовой и контрольной групп из поэтапного развёртывания. Видно, что пользователи с новой версией приложения были более активными, чем другие пользователи перед экспериментом, что означало нарушение ключевого условия A/B-тестирования: рандомизированная выборка должна минимизировать смещение, выравнивая воздействие всех других факторов.
Поскольку данное условие не выполнялось, необходимо было использовать другой способ измерения результатов наших экспериментов и доведения их до наших менеджеров по продукции. Необходимо было ответить на следующие вопросы:
- Новый релиз положительно влияет на наши ключевые характеристики?
- Изменение является существенным?
- Насколько велико изменение?
Обычно мы сравниваем результаты, получаемые для тестовой и контрольной групп за какой-то интервал времени после выпуска экспериментальной версии. Чтобы определить изменения в пользовательских группах с поэтапным развёртыванием, мы измеряли ключевые характеристики у экспериментальных групп до и после нового релиза и сравнивали результаты этих групп. Для анализа использовались два подхода:
- Анализ на основе временных рядов;
- Оценка методом «разность разностей».
Мы использовали первый подход для оценки абсолютных изменений в ключевых характеристиках, применяя данные агрегированного уровня, а второй подход — для тестирования значимости на наборе характеристик, применяя данные пользовательского уровня. Оба подхода используются для расчёта смещений таким способом, что поэтапные развёртывания представляют пользователей.
Смещения поэтапного развёртывания
Одна из проблем, известных при использовании поэтапного развёртывания на Google Play, состоит в том, что пользователю для обновления до нового бинарного релиза (APK) может потребоваться несколько дней. Мы использовали норму отбора 10% для нашей тестовой сборки, и пользователям потребовалось около 2 недель, чтобы придти к этому значению. График внизу показывает степень принятия нового APK, где под этим понимается отношение числа пользователей, обновивших версию, к полному числу активных пользователей.

Мы обнаружили, что включение новых пользователей ведёт к более быстрому изменению степени принятия, но мы исключили этих пользователей из нашего анализа. Оба метода — на основе временных рядов и «разность разностей» — основываются на данных, собранных для каждого пользователя до запуска эксперимента, а новые пользователи не имеют таких данных. Для эксперимента, подробно описанного в этой статье далее, мы включили только тех пользователей, которые перешли на новую версию в течение 1 недели, что дало степень принятия 8,3%.
Чтобы попытаться объяснить различия (смещения) в данных, мы рассмотрели множество переменных, которые могут быть ответственными за это. Следующие переменные не имели значения для групповых пользователей:
- Страна;
- Модель устройства
Различия для групп показали такие переменные как начальный месяц для пользователя и количество предыдущих обновлений. Отличие для пользователей, которые уже проводили обновления, было неудивительным, поскольку пользователи должны были иметь обновления, чтобы быть включёнными в тестовую группу.

Анализ на основе временных рядов
Одной из характеристик, измеренной в нашем эксперименте поэтапного развёртывания, было среднее число сеансов в расчёте на одного активного пользователя. Чтобы оценить абсолютную величину различия этой характеристики у тестовой и контрольной групп, мы использовали пакет CausalImpact R, осуществляющий байесовское моделирование на основе временных рядов. В этом подходе происходит оценка временных рядов тестовой группы, если нет мешающего воздействия, и эта оценка используется для прогнозирования относительных и абсолютных изменений характеристик. Ключевое условие этого подхода — отсутствие влияния каких-либо осуществляемых изменений на контрольную группу.

Количество сеансов для тестовой и контрольной (пунктир) групп
Графики вверху показывают временные зависимости для тестовой и контрольной групп. Сплошная линия представляет собой среднее количество сеансов для тестовой группы, которое до эксперимента превышало таковое для контрольной группы. Мы использовали интервал две недели до и после выхода релиза для измерения ключевых характеристик.
library(CausalImpact)
data <- read.csv(data, file = "DailySessions.csv")
# Создание DataFrame и отображение входных данных
ts <- cbind(data$test, data$control)
matplot(ts, type = "l")
# Использование интервала две недели до и после выхода релиза и отображение результатов
pre.period <- c(1, 14)
post.period <- c(15, 30)
impact <- CausalImpact(ts, pre.period, post.period)
# Отображение результатов и объяснение итога
plot(impact, c("original", "pointwise"))
summary(impact, "report")Мы использовали пакет CausalImpact R для оценки влияния версии нового приложения на нашу характеристику сеанса. Приведённый выше фрагмент кода показывает, как использовать этот пакет для построения оценки тестовой группы. В данном эксперименте относительное увеличение количества суточных сеансов в расчёте на одного активного пользователя составило +4% с доверительным 95%-интервалом [+2%, +5%].
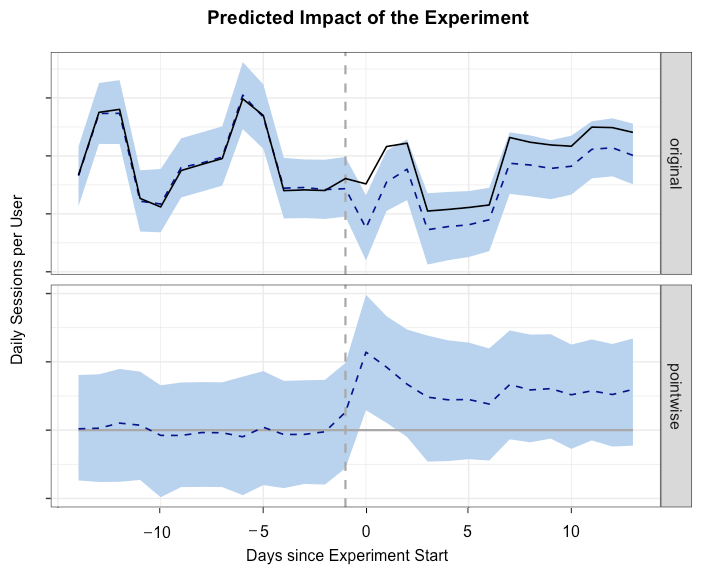
Спрогнозированное воздействие эксперимента
Такой подход полезен, если есть только агрегированные данные. Чтобы выяснить воздействие различных переменных независимо от временной компоненты, мы использовали бутстреппинг.
Оценка методом «разность разностей»
Проводя эксперименты в Twitch, мы обычно отслеживаем некоторый набор характеристик. Бутстреппинг — мощный процесс ресамплинга, который позволяет нашим специалистам измерять изменения характеристик с доверительными интервалами. В нашем эксперименте поэтапного развёртывания мы использовали бутстреппинг для измерения «разности разностей» между нашими тестовой и контрольной группами.
library(boot)
data <- read.csv("UserSessions.csv")
# Функция для расчёта "разности разностей"
run_DiD <- function(data, indices){
d <- data[indices,]
new <- mean(d$postval[d$group=='Test'])/
mean(d$priorval[d$group=='Test'])
old <-mean(d$postval[d$expgroup=='Control'])/
mean(d$priorval[d$expgroup=='Control'])
return((new - old)/old * 100.0)
}
# Выполнение бутстреппинга и выведение результатов
boot_est <- boot(data, run_DiD, R=1000, parallel="multicore", ncpus = 8)
quantile(boot_est$t, c(0.025, 0.975))
plot(density(boot_est$t), xlab = "% Increase vs. Control")Для каждого пользователя мы измерили полное количество сеансов за 14 дней до выхода тестовой версии и за 14 дней после выхода. Затем на тысячах точек мы рассчитали средние значения разности между значениями до и после выхода версии и определили процентное различие между тестовой и контрольной группами. Для этих вычислений мы использовали пакет boot R, как показано выше. Данная модель показала увеличение +5,4% общего количества сеансов в расчёте на одного пользователя с доверительным 95%-интервалом [+3,9%, +6,9%].
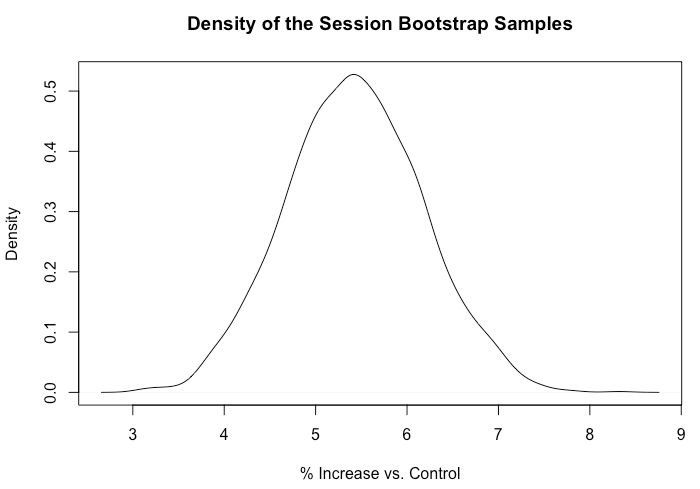
Плотность наборов объектов с повторениями сеансов
Резюме
Мы обнаружили различия данных при использовании функции поэтапного развёртывания Google и применили новые методы для проведения экспериментов с этой функцией. Оба использованных подхода показали, что новый релиз приложения привёл к заметному увеличению количества сеансов в расчёте на одного пользователя. Метод временных рядов приносит пользу в случаях наличия только данных агрегированного уровня, а подход бутстреппинга полезен для тестирования разных значений независимо от временной компоненты. Функция поэтапного развёртывания даёт механизм для тестирования новых сборок, но она не работает со стандартными подходами А/В-тестирования. Дальнейшая информация имеется в Causal Impact и A/B Testing в Facebook.
